分库分表时机
分库分表虽然常放在一起说,但其实是为了解决两部分需求。
分库是为了解决单库的资源瓶颈。比如磁盘,cpu,内存,连接数等等
分表是为了解决单表数据量过大的问题。单表数据量过大会导致索引树过大,即使能走索引sql性能也不会太高,还有大表DDL问题。就个人经验而言,对于Mysql来说,单行大小不超过50kb,数据量超过1000w就应该分表;单行大小超过100kb,数据量500w左右就应该分表。
分库分表方案
分库分表方案其实和单纯的分表方案考虑点很类似,为了画图和描述简洁,下面围绕分表方案讨论。
当我们要开始考虑分表方案时,脑子里要有一些思考点:
- 数据切分方式
- 数据切分维度
- 数据扩容
- 客户端路由还是代理层路由
数据切分方式
range切分方式
range切分也就是按范围切分。比如id在0~10000范围放在表1,10001~20000范围放在表2。同理也可以按时间范围拆分。这样切分的优点就是扩展性特别好,我们只要提前创建日后要用到的表就可以了,完全不用迁移数据。
range切分方式在实际中用的比较少,主要原因是数据均衡问题太严重。比如按时间切分,请求集中在新数据上,导致某一表过热。或者比如range范围是1000w,新表刚开始可能只有很少的数据量,这样数据就不均衡。
按时间range切分是单表数据过大的一种过度方案,也是我们常说的冷热数据隔离。也许你会有印象,某段时间的淘宝和京东只能查看最近三个月的订单。再往后的订单就要去历史订单列表按日期范围查询。
hash切分方式
hash切分简单来说就是根据路由key取模,数据分布很均匀。缺点是数据扩容时比较麻烦,需要迁移数据。并且为了实现高扩展性,可能会导致整体架构比较复杂。
数据切分维度
实际生产中我们一个业务表可能会有很多查询维度。如何满足各个维度的查询需求是个必须考虑而且又很麻烦的问题。
订单业务是典型的多维度场景,我们就以订单业务为例子,介绍下该问题的解决思路和方案。
关注订单表的角色有用户,商家和后台运营人员。订单表的数据结构大致如下:
Order(oid, buyer_uid, seller_uid, time,...);
其中:
(1)oid为订单ID,主键;
(2)buyer_uid为买家uid;
(3)seller_uid为卖家uid;
(4)time, 相当于订单的各种时间属性;
如果数据按照oid来切分,buyer_uid和seller_uid维度的查询需要遍历多个库;如果按照buyer_uid来切分,seller_uid的查询需要遍历多个库;seller_uid切分类似。似乎没有万全的方案。
我们先来分析下查询需求。
第一类,前台访问,典型的有三类需求:
(1)订单实体查询:通过oid查询订单实体,90%流量属于这类需求;
(2)用户订单列表查询:通过buyer_uid分页查询用户历史订单列表,9%流量属于这类需求;
(3)商家订单列表查询:通过seller_uid分页查询商家历史订单列表,1%流量属于这类需求;
前台访问的特点是什么呢?
吞吐量大,服务要求高可用,用户对订单的访问一致性要求高,商家对订单的访问一致性要求相对较低,可以接受一定时间的延时。
第二类,后台访问,根据产品、运营需求,访问模式各异:
(1)按照时间,价格,商品,详情来进行查询;
后台访问的特点是什么呢?
运营侧的查询基本上是批量分页的查询,由于是内部系统,访问量很低,对可用性的要求不高,对一致性的要求也没这么严格,允许秒级甚至十秒级别的查询延时。
我们可以根据前台和后台查询需求的差异性,我们采用前后台分离架构。
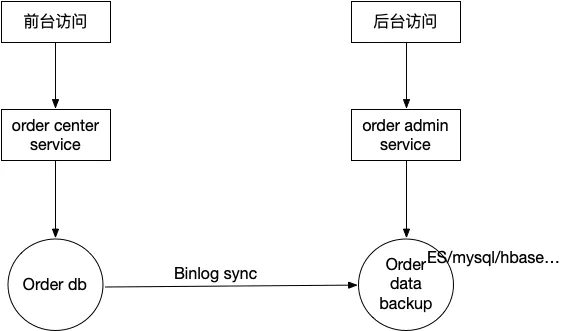
订单前后台架构设计.png
这样好处很多:
- server层和存储层都分离,可以避免后台业务影响前台
- 前后台面向的角色不一样,业务领域很大可能存在差异,前后台分离让各端都只用关心自己的业务领域
- 前后台查询需求差异,各端可以各自做技术选型和设计,互不影响
按照上述架构图,可以满足后台查询需求。咱们接着探讨前台查询需求。我们逐个分析前台查询的多维度需求。
(1)oid维度和buyer_uid维度。一对多的业务场景。一对多最有效率的做法是基因法。
什么是基因法?
一个数取余2的n次方,那么余数就是这个数的二进制的最后n位数。所有我们可以位操作符把高位清零就可以得到余数。
int mod = number & ~(-1 << n)
所以,n的取舍关系到分库的数量或者分表的数量,即2^n 个库或表。故我们把二进制的最后n位数,即上述代码中的mod称为分库分表因子。
所以,需要生成的新id只要最后末尾放入分库或分表因子就达到了我们的目的。
回到例子,通过buyer_uid分库,假设分为16个库,采用buyer_uid%16的方式来进行数据库路由,所谓的模16,其本质是buyer_uid的最后4个bit决定这行数据落在哪个库上,这4个bit,就是分库基因。
在订单数据oid生成时,oid末端加入分库基因,让同一个buyer_uid下的所有订单都含有相同基因,落在同一个分库上。
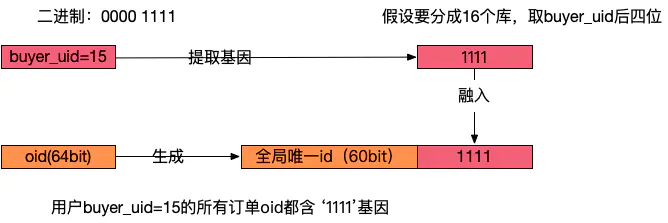
分库基因法.png
(2)buyer_id维度和seller_uid维度。多对多的业务场景。多对多的业务场景只能用数据冗余法。也就是同步一份数据专门给seller_uid维度的需求使用。数据同步的方法有很多,代码层面实时同步同步,代码层面实时异步同步,离线同步,binlog同步等。binglog同步是最推荐的,目前业界主流的canal, databus都很成熟,但是还是有一些技术门槛的,还是要根据业务和现状选择方案。
订单这个例子算是分析完了。多维度切分问题还有一种常用的方案——映射表方案。表中维护着路由key和其他key的映射关系,处理其他key维度的查询过程大致如下:
- 在映射表中找到该key对应的路由key
- 根据拿着路由key,根据路由算法找到对应的库/表
- 用路由key去相应的库/表中查数据
- 结果返回给客户端
映射表方案本身也有潜在的单表数据量过大的问题。所以,如果我们对数据的总量有个比较明确的认识,那么可以考虑用映射表方案。比如说像用户表业务,表主要字段如下:
user(uid, email, mobile, username,…);
一般用户登录场景既可以通过mobile_no,又可以通过email,还可以通过username进行登录。但是一些用户相关的API,又都包含user_id,那么可能需要根据这4个column都进行分库分表。
基因法对于这个例子不可行,因为没有合适的字段提取基因因子。这四个维度都是面向用户的,数据冗余法不太合适,把问题复杂化了。
对于大部分公司来说有几亿用户数据已经是极限了。几亿数据的映射表Mysql还是能抗的。映射表方案是可行的。
数据扩容
扩容是另一个很麻烦的问题。传统的扩容方案往往需要挂公告停机迁移数据。这里介绍一种不停机扩容方案——双倍扩容方案。
不停机扩容.png
如上图,我们要把原本的两个库扩容为四个库,总体来说需要三步。
- 新建db2,作为db0从库同步数据;新建db3,作为db1从库同步数据
2.当db2和db3数据同步完成后,去掉主从关系,并且修改client路由配置并reload。由于是成倍扩容,所以
原 ID%2=0 => db0 相当于 ID%4=0 => db0, ID%4=2 => db2;
原 ID%2=1 => db1相当于 ID%4=1 => db1, ID%4=3 => db3。
3.这一步之前,db0,db2有原db0的所有数据;db1,db3有原db1的所有数据。择机去除db0,db2,db1,db3多余的数据。
扩容完成,期间最多需要client重启一下reload新的路由配置。
客户端路由还是代理层路由
本节只从架构思想角度论述下两种方案的优劣,不打算介绍具体中间件。我一直认为架构思想是最重要的,各种中间件和语言都只是思想的具体呈现。
- 客户端路由
优点:
a. 架构简单
b. 要求业务方必须了解分库分表的细节
缺点:
a. 客户端配置稍微复杂些
b. 分库分表方案变动,业务方需要调整配置甚至代码 代理层路由
优点:
a. 客户端对分库分表无感知,像访问一个表一样访问多个表
缺点:
a. 客户端和数据库之前多了一层代理层,性能会略受影响,架构复杂度略微上升
b. 客户端对分库分表无感知,业务方程序尤其是新人可能以为是在操作一个表,这可能会导致业务方程序员犯一些严重的错误。(我一直认为对于偏业务的需求,基础架构部门不要替业务部门做太多事情,很多时候业务方程序员有必要去了解相关细节)为什么不推荐分区表?
不推荐分区表主要是因为分区表如下的三个特性:
Mysql 在第一次打开分区表的时候,需要访问所有的分区;
- 在 Mysql server 层,认为这是同一张表,因此所有分区共用同一个 MDL 锁;
这意味着当我对其中一个分区做DDL操作时,所有分区都会加MDL锁。 - 在引擎层,认为这是不同的表,因此 非MDL 锁,会根据分区表规则,只访问必要的分区,也就是只可能锁访问的分区。
- 应用层认为这是同一张表,所以业务程序员可能由于不了解分区表细节而犯错。

若有收获,就点个赞吧
0 人点赞
