import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as npfrom scipy.stats import normfrom sklearn.preprocessing import StandardScalerfrom scipy import statsimport warningswarnings.filterwarnings('ignore')%matplotlib inline
train_names = ["date","price","bedroom_num","bathroom_num","house_area","park_space","floor_num","house_score","covered_area","basement_area","yearbuilt","yearremodadd","lat","long"]df_train = pd.read_csv("D:\Python\kc_train.csv",names=train_names)
df_train.columns
Index([‘date’, ‘price’, ‘bedroom_num’, ‘bathroom_num’, ‘house_area’,
‘park_space’, ‘floor_num’, ‘house_score’, ‘covered_area’,
‘basement_area’, ‘yearbuilt’, ‘yearremodadd’, ‘lat’, ‘long’],
dtype=’object’)
df_train['price'].describe()
count 1.000000e+04
mean 5.428749e+05
std 3.729258e+05
min 7.500000e+04
25% 3.225000e+05
50% 4.507000e+05
75% 6.450000e+05
max 6.885000e+06
Name: price, dtype: float64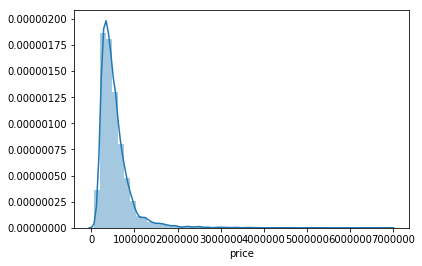
#skewness and kurtosis计算偏度与峰度:print("Skewness: %f" % df_train['price'].skew())print("Kurtosis: %f" % df_train['price'].kurt())
Skewness: 3.898737
Kurtosis: 29.356202
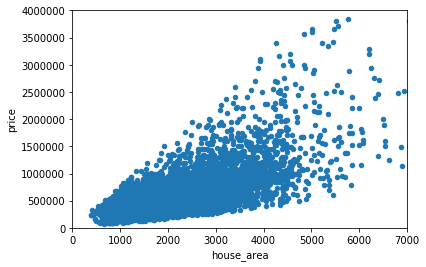
#居住面积平方英尺var = 'house_area'data = pd.concat([df_train['price'], df_train[var]], axis=1)data.plot.scatter(x=var, y='price', xlim=(0,7000), ylim=(0,4000000));
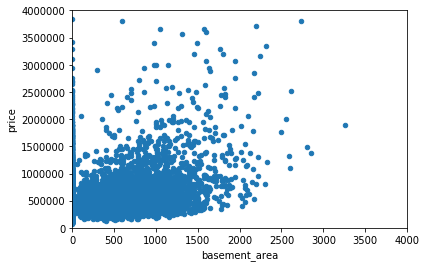
#地下室面积平方英尺var = 'basement_area'data = pd.concat([df_train['price'], df_train[var]], axis=1)data.plot.scatter(x=var, y='price',xlim=(0,4000), ylim=(0,4000000));
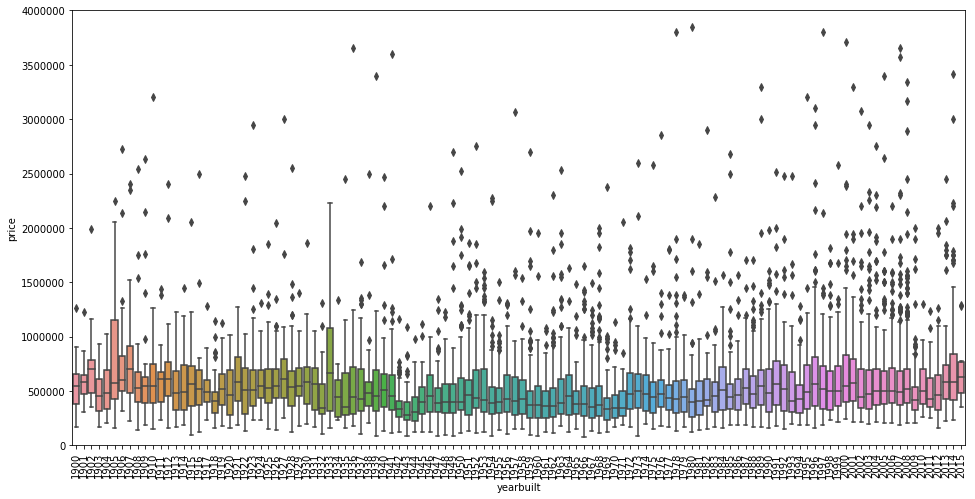
#原施工日期var = 'yearbuilt'data = pd.concat([df_train['price'], df_train[var]], axis=1)f, ax = plt.subplots(figsize=(16, 8))fig = sns.boxplot(x=var, y="price", data=data)fig.axis(ymin=0, ymax=4000000);plt.xticks(rotation=90);
#bedroom_numvar = 'bedroom_num'data = pd.concat([df_train['price'], df_train[var]], axis=1)f, ax = plt.subplots(figsize=(8, 6))fig = sns.boxplot(x=var, y="price", data=data)fig.axis(ymin=0, ymax=4000000);
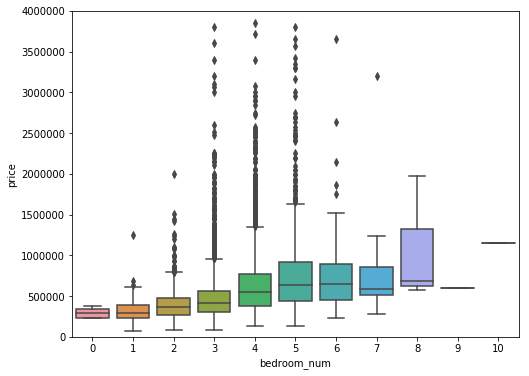
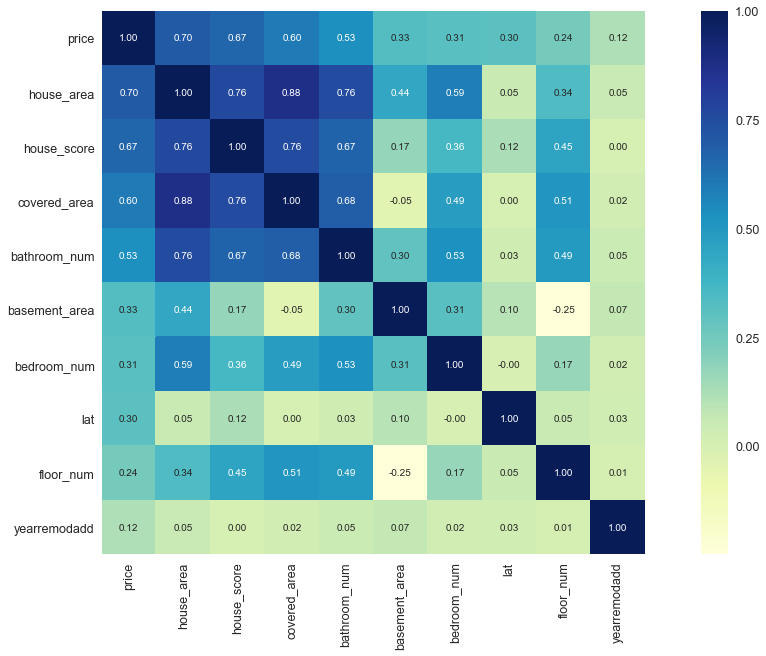
#选出与价格因素最相近的10个特征,观察它们的相关性。k = 10corrmat = df_train.corr()cols = corrmat.nlargest(k, 'price')['price'].indexcm = np.corrcoef(df_train[cols].values.T)sns.set(font_scale=1.25)plt.figure(figsize = (20,10))hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values,cmap='YlGnBu')plt.show()
#选出与价格因素最相近的13个特征,观察它们的相关性。k = 13corrmat = df_train.corr()cols = corrmat.nlargest(k, 'price')['price'].indexcm = np.corrcoef(df_train[cols].values.T)sns.set(font_scale=1.25)plt.figure(figsize = (20,10))hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values,cmap='YlGnBu')plt.show()
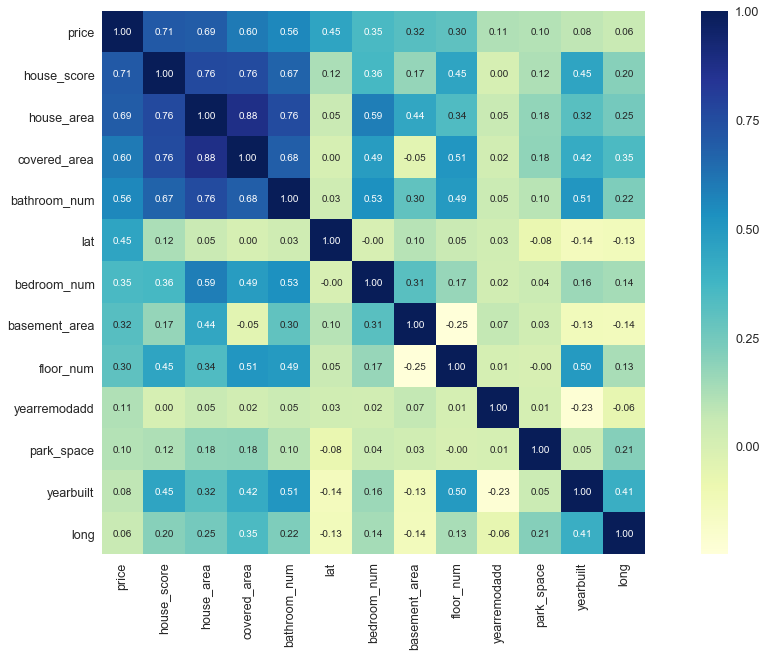
#打印出相关性的排名print(corrmat["price"].sort_values(ascending=False))
price 1.000000
house_score 0.705110
house_area 0.694800
covered_area 0.601667
bathroom_num 0.556525
lat 0.451337
bedroom_num 0.352195
basement_area 0.318296
floor_num 0.299244
yearremodadd 0.113862
park_space 0.103211
yearbuilt 0.082579
long 0.055840
date 0.002005
Name: price, dtype: float64
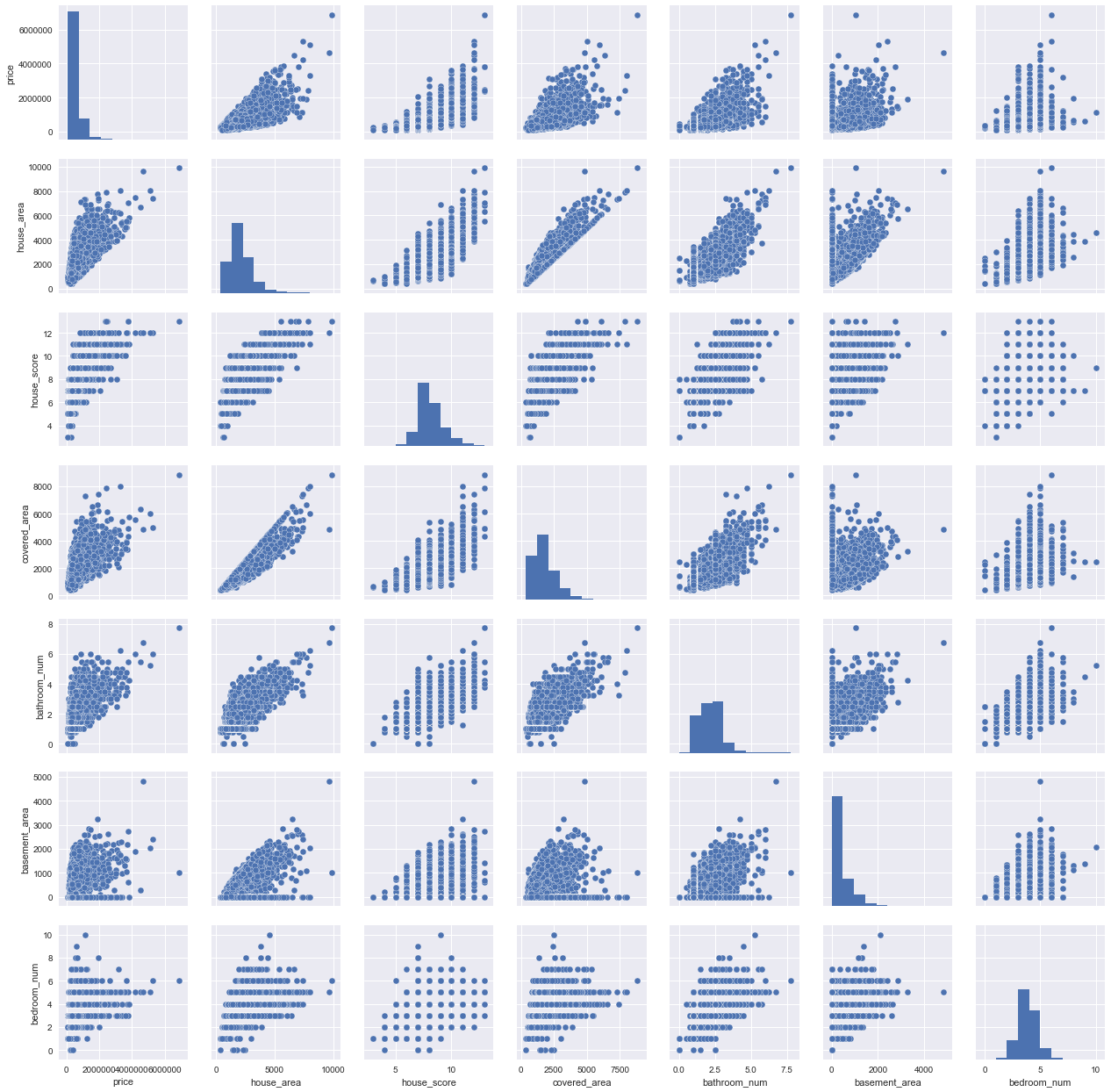
#scatterplotsns.set()cols = ['price', 'house_area', 'house_score', 'covered_area', 'bathroom_num', 'basement_area', 'bedroom_num']sns.pairplot(df_train[cols], size = 2.5)plt.show();
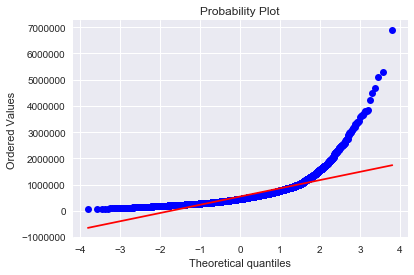
#转换前的数据分布sns.distplot(df_train['price'] , fit=norm);(mu, sigma) = norm.fit(df_train['price'])print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))#分布图plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')plt.ylabel('Frequency')plt.title('price distribution')#QQ图fig = plt.figure()res = stats.probplot(df_train['price'], plot=plt)plt.show()
mu = 542874.93 and sigma = 372907.12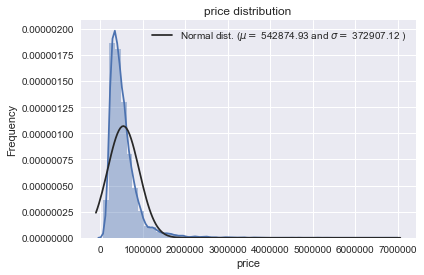
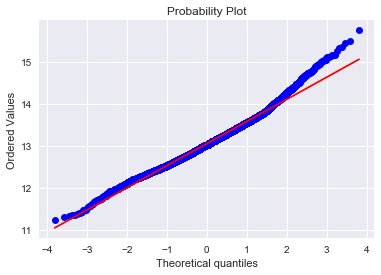
#转换后的数据分布:#对数变换log(1+x)df_train["price"] = np.log1p(df_train["price"])#看看新的分布sns.distplot(df_train["price"] , fit=norm);# 参数(mu, sigma) = norm.fit(df_train["price"])print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))#画图plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')plt.ylabel('Frequency')plt.title('price distribution')#QQ图fig = plt.figure()res = stats.probplot(df_train["price"], plot=plt)plt.show()
mu = 13.05 and sigma = 0.53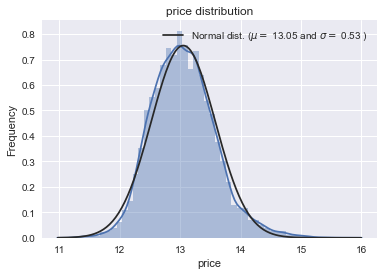
#特征缩放data = df_train.astype('float')x = data.drop('price',axis=1)y = data['price']from sklearn.preprocessing import MinMaxScalerscaler = MinMaxScaler()newX= scaler.fit_transform(x)newX = pd.DataFrame(newX, columns=x.columns)newX.head()
#先将数据集分成训练集和测试集from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(newX, y, test_size=0.2, random_state=21)
#模型建立from sklearn import metricsdef RF(X_train, X_test, y_train, y_test): #随机森林from sklearn.ensemble import RandomForestRegressormodel= RandomForestRegressor(n_estimators=200,max_features=None)model.fit(X_train, y_train)predicted= model.predict(X_test)mse = metrics.mean_squared_error(y_test,predicted)return (mse/10000)def LR(X_train, X_test, y_train, y_test): #线性回归from sklearn.linear_model import LinearRegressionLR = LinearRegression()LR.fit(X_train, y_train)predicted = LR.predict(X_test)mse = metrics.mean_squared_error(y_test,predicted)return (mse/10000)
print('RF mse: ',RF(X_train, X_test, y_train, y_test))print('LR mse: ',LR(X_train, X_test, y_train, y_test))
RF mse: 3.5241062705249253e-06
LR mse: 7.1541094041807234e-06

若有收获,就点个赞吧
0 人点赞
