本章主要内容来源于秦朋先生编著的《PHP7内核剖析》这本书籍,感兴趣的小伙伴可以购买该书,进行系统性学习。
概述
在PHP中,数组的底层实现是散列表(Hashtable,也称作哈希表),是根据关键码值(Key Value)而直接进行访问的数据结构,它的Key和value之间存在一个映射函数。
它不以关键字比较为基本操作,直接根据“内存起始位置+偏移值”进行寻址,也就是说,他是直接通过key映射到内存地址上去的,从而加快了查找速度。在理想情况下,查找的期望时间复杂度为O(1)。
散列表结构
typedef struct _zend_array zend_array;typedef struct _zend_array HashTable;struct _zend_array {zend_refcounted_h gc;union {struct {ZEND_ENDIAN_LOHI_4(zend_uchar flags,zend_uchar _unused,zend_uchar nIteratorsCount,zend_uchar _unused2)} v;uint32_t flags;} u;uint32_t nTableMask;Bucket *arData;uint32_t nNumUsed;uint32_t nNumOfElements;uint32_t nTableSize;uint32_t nInternalPointer;zend_long nNextFreeElement;dtor_func_t pDestructor;};typedef struct _Bucket {zval val;zend_ulong h; /* hash value (or numeric index) */zend_string *key; /* string key or NULL for numerics */} Bucket;
根据鸟哥相关博客的介绍,PHP7重新设计时,考虑到Hashtable使用的太多,新设计的结构体未必能Cover所有的场景,所以新定义了一个结构体叫zend_array,经过努力最后虽然能够完全替代Hashtable,但还是保留了两个名字,互为Alias,所以两者完全相同,没有任何区别。
数组成员:
- gc:引用计数信息,用于内存管理。
- u:主要用于一些辅助作用。
- nTableMask:这个值在散列函数根据key的hash code映射元素的存储位置时用到,他的值实际就是nTableSize的负数,即nTableMask = -nTableSize,用位运算表示的话则为nTableMask = ~nTableSize+1。
- arData:散列表中保存存储元素(Bucket)的数组,其内存是连续的,arData指向数组的起始位置。
- nNumUsed:数组当前使用的Bucket数,但是这些Bucket并不都是数组有效的元素,因为当我们删除一个数组元素时并不会马上将其从数组中移除,而只是将这个元素的类型标为IS_UNDEF,只有在数组容量超限,需要进行扩容时才会删除。
- nNumOfElements:数组中有效元素的数量,所以nNumUsed >= nNumOfElements。
- nTableSize:数组的总容量,arData的内存大小就是根据这个值确定的,它的大小是2的幂次方,最小为8,依次按16、32、64……递增。
- nInternalPointer:内部指针,用于遍历。
- nNextFreeElement:自动确定数值索引使用的,从0开始,每次使用后增加1。
- pDestructor:当删除或者覆盖数组中某个元素时,如果提供这个函数句柄,则在删除或者覆盖后调用次函数,对旧元素进行清理。
Bucket结构比较简单,主要用来保存元素的key和value,还有一个整型的h,它的含义是hash code,如果元素是数值索引,那么它的值就是数值索引的值;如果是字符串,那么这个值就是根据字符串key通过time33算法计算得出的散列值。
Bucket成员:
- val:存储的具体value,这里是嵌入了一个zval,而不是一个指针。
- h:hash code
- key:存储元素的key。
底层实现
散列表主要由两部分组成:存储元素数组、散列函数。
一个简单的散列函数可以采用取模的方式,但是这种方式有一个问题就是结果具有随机性,它是无序的。PHP中的数组除了具有散列表的特点,还有一个特别的地方,那就是它是有序的,数组中各元素的顺序与其插入的顺序一致。
为了实现散列表的有序性,PHP中的散列表在实现方式上做了调整,通过在散列函数和元素数组之间加一层映射表,这个映射表也是一个数组,大小和存储元素的数组相同,它存储的元素类型是整型,用于保存元素在实际存储的有序数组中的下标:元素按照先后顺序依次插入实际存储数组,然后将其数组下标按照散列函数散列出来的位置存储在新加的映射表中,如下图所示: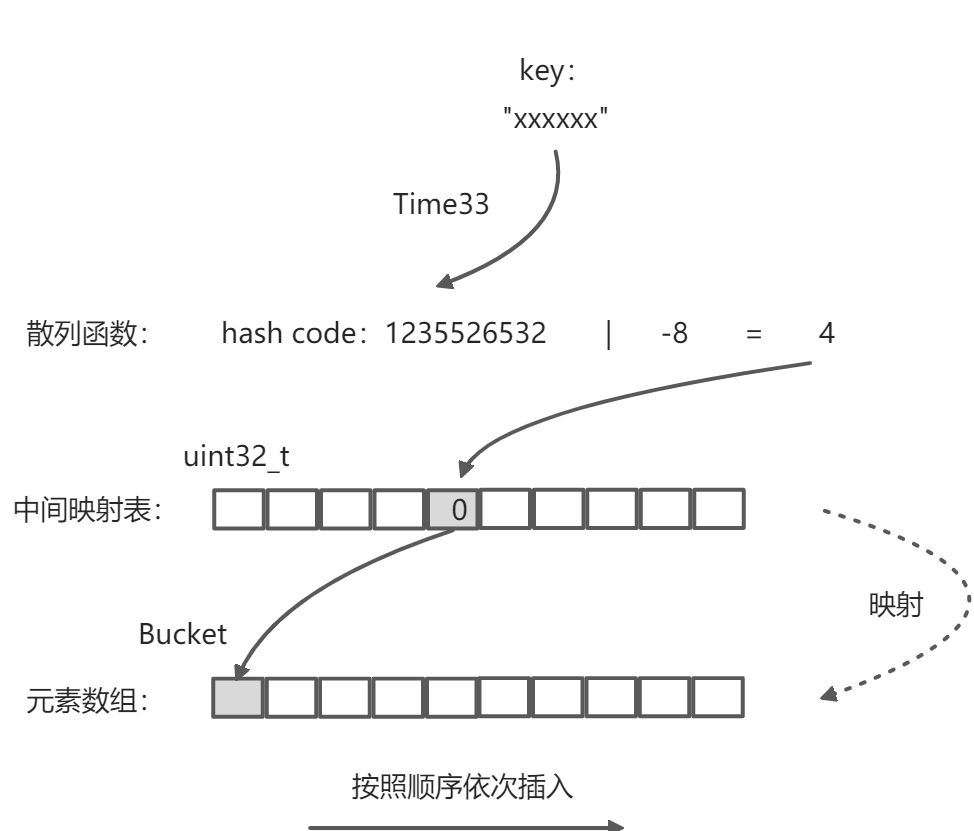
在PHP数组的结构中并没有发现中间这个映射表,事实上,它是与arData放在一起。在数组初始化时并不仅仅分配用于存储Bucket的内存,还会分配相同数量的unit32_t大小的空间,这两块空间是一起分配的,然后将arData偏移到存储元素数组的位置,而这个中间映射表可以通过arData向前访问到。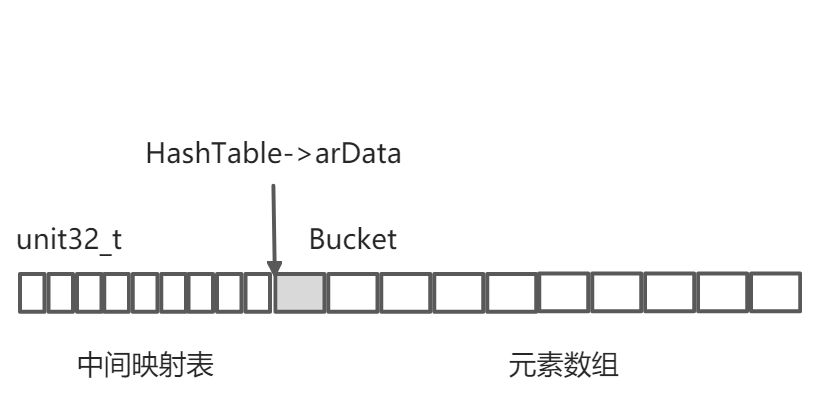
散列函数
散列函数的作用是根据key映射出元素的存储位置。PHP采用如下的方式计算散列值:
nIndex = key->h | nTableMask;
前面讲到nTableMask是nTableSize的负数,在计算机中负数存储的是补码,进行或运算,因为散列表的大小为2的幂次方,所以通过或运算可以得到[-1,nTableMask]之间的散列值。
数组初始化
数组的初始化主要是对HashTable中的成员进行设置,初始化时并不会立即分配arData的内存,arData的内存在插入第一个元素的时候才会分配。
初始化操作由_zend_hash_init()函数处理,函数如下:
static zend_always_inline void _zend_hash_init_int(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent){GC_SET_REFCOUNT(ht, 1);GC_TYPE_INFO(ht) = IS_ARRAY | (persistent ? (GC_PERSISTENT << GC_FLAGS_SHIFT) : (GC_COLLECTABLE << GC_FLAGS_SHIFT));HT_FLAGS(ht) = HASH_FLAG_UNINITIALIZED;ht->nTableMask = HT_MIN_MASK;HT_SET_DATA_ADDR(ht, &uninitialized_bucket);ht->nNumUsed = 0;ht->nNumOfElements = 0;ht->nInternalPointer = 0;ht->nNextFreeElement = 0;ht->pDestructor = pDestructor;ht->nTableSize = zend_hash_check_size(nSize);}ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent){_zend_hash_init_int(ht, nSize, pDestructor, persistent);}
可以看到,初始化操作只设置了散列表的大小以及其他一些成员的初值,无法用来存储元素。
哈希冲突
散列表中不同元素的key可能计算得到相同的哈希值,这些具有相同哈希值的元素在插入散列表时就会发生冲突,因为映射表只能存储一个元素。常见的解决办法就是把冲突的Bucket串成链表,这样一来中间映射表映射出的就不再是一个Bucket,而是一个Bucket链表,查找时需要遍历这个链表,逐个比较Key,从而找到目标元素,PHP实现的散列表也是采用这种方法解决哈希冲突。
HashTable中的Bucket会记录与它冲突的元素在arData数组中的存储位置,本质上这是一个链表。
在设置映射表时,如果发现中间映射表已经有元素占用,那么将映射表中的值更新为新的Bucket的存储位置,然后将已经存在的值保存到新Bucket中,这样每次都会把冲突的元素插到开头。
数组扩容
前面我们提到过,数组最多可存储nTableSize个元素,当数组空间已满但还要继续插入的时候,就需要进行扩容操作,PHP的数组实现了自动扩容。
扩容的过程大体如下:
- 检查数组中已经删除的元素所占的比例,如果比例达到阈值则触发重建索引的操作,这个过程会把删除的Bucket移除,然后把后面的Bucket往前移补上空缺的Bucket。
- 没有达到阈值,则会分配一个原数组大小2倍的新数组,然后把原数组的元素复制到新数组上,最后重建索引。
阈值并不是一个固定的值,是由下面公式判断的:
ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5)
将旧数组复制到新数组时,只复制存储的元素,不会复制中间映射表,因为扩容后旧的映射表已经无法使用了,key-value的映射关系需要重新计算,这一步骤为重建索引。重建索引的过程还会把已删除的Bucket移除,移除后这个Bucket之后的所有元素全部向前移动一个位置,所以重建索引后数组中所有元素全部紧密排列在一起。

若有收获,就点个赞吧
0 人点赞
