1、多进程/多线程链接处理模型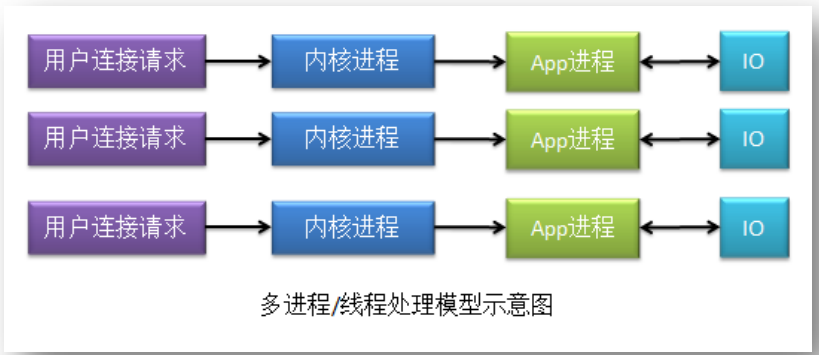
在该模型下,一个用户连接请求会由一个内核进程处理,而一个内核进程会创建一个应用程序进程,即 app 进程来处理该连接请求。应用程序进程在调用 IO 时,采用的是 BIO 通讯方式,即应用程序进程在未获取到 IO 响应之前是处于阻塞态的。
优点:内核进程不存在对app进程的竞争
弊端:请求多的时候,需要创建很多app进程,创建进程的过程是十分消耗资源的,所以该模型不能处理高并发。app进程中使用的用于链接请求数据是从内核进程复制过来的,没有使用零拷贝,因此效率低,消耗资源。
2、多路复用处理模型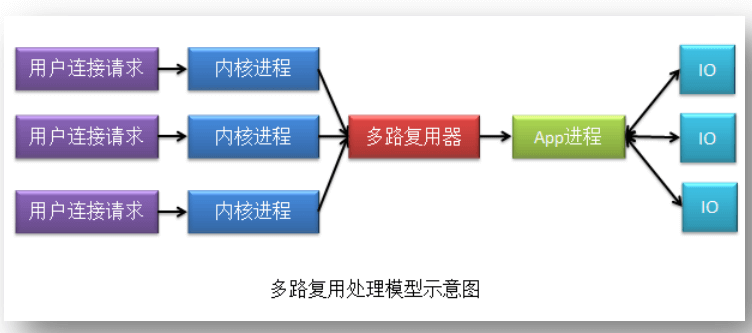
在该模型下,只有一个 app 进程来处理内核进程事务,且 app 进程一次只能处理一个内核进程事务。故这种模型对于内核进程来说,存在对 app 进程的竞争。
在前面的“多进程/多线程连接处理模型”中我们说过,app 进程只要被创建了就会执行内核进程事务。那么在该模型下,应用程序进程应该执行哪个内核进程事务呢?谁的准备就绪了,app 进程就执行哪个。但 app 进程怎么知道哪个内核进程就绪了呢?需要通过“多路复用器”来获取各个内核进程的状态信息。那么多路复用器又是怎么获取到内核进程的状态信息的呢?不同的多路复用器,其算法不同。常见的有三种:select、poll 与 epoll。
1)select多路复用器
select 多路复用器是采用轮询的方式,一直在轮询所有的相关内核进程,查看它们的进程状态。若已经就绪,则马上将该内进程放入到就绪队列。否则,继续查看下一个内核进程状态。在处理内核进程事务之前,app 进程首先会从内核空间中将用户连接请求相关数据复制到用户空间。在处理内核进程事务之前,app 进程首先会从内核空间中将用户连接请求相关数据复制到用户空间。
该多路复用器的缺陷有以下几点:
A、对所有内核进程采用轮询的方式效率会很低,因为大部分时间,内核进程都不属于就绪状态,只有少部分是就绪状态,所以这种轮询结果大多数都是无意义的。
B、由于就绪队列底层由数组实现,所以其能处理的内核进程数量是有限制的,即其能处理的最大并发数量是有限制的。
C、从内核空间复制到用户空间,会有一定的系统开销。
2)poll多路复用器
poll 多路复用器的工作原理与 select 几乎相同,不同的是,由于其就绪队列由链表实现,所以,其对于要处理的内核进程数量理论上是没有限制的,即其能够处理的最大并发连接数量是没有限制的(当然,要受限于当前系统中进程可以打开的最大文件描述符数 ulimit,后面会讲到)。
3)epoll多路复用器
epoll 多路复用是对 select 与 poll 的增强与改进。其不再采用轮询方式了,而是采用回调方式实现对内核进程状态的获取:一旦内核进程就绪,其就会回调 epoll 多路复用器,进入到多路复用器的就绪队列(由链表实现)。所以 epoll 多路复用模型也称为 epoll 事件驱动模型。
另外,应用程序所使用的数据,也不再从内核空间复制到用户空间了,而是使用 mmap零拷贝机制,大大降低了系统开销。
当内核进程就绪信息通知了 epoll 多路复用器后,多路复用器就会马上对其进行处理,将其马上存放到就绪队列吗?不是的。根据处理方式的不同,可以分为两种处理模式:LT模式与 ET 模式。
A、LT模式,LT,Level Triggered,水平触发模式。即内核进程会不断的通知多路复用器已经处于就绪状态,直到多路复用器将其放入就绪队列,或是用户请求链接取消。这种方式相对相率低,但是不会丢失请求。
B、ET模式,ET,Edge Triggered,边缘出发模式。即内核进程仅会通知多路复用器一次,如果多路复用器没有将其加入就绪队列,这该次请求会被丢弃。这种方式效率高,但是请求会丢失。

若有收获,就点个赞吧
0 人点赞
