1. 索引的优点
- 大大减少服务器扫描的数据量
- 帮助服务器避免排序和临时表 ?
- 将随机io变成顺序io
2. 索引的用处
- 快速查找where子句对应的行;
- 多个索引列存在,如果此时的where子句能够匹配多个索引,那么优化器能够判断得到并使用能让该子句最高效的索引;
- 如果表具有多列索引,则优化器会使用索引列的最左前缀一个或几个列来查找行;
- 表连接也可以使用索引;
- 可直接查找对应索引列的min和max;(已经排好序成B+树,底层双向链表,可直接获取最大最小值)
- 如果排序和分组在可用的索引的最左前缀上完成的,则可以直接获取排序好的信息;
某种情况下,可以直接获取数据值,而不需要获取完整的数据行;(索引覆盖)
3. 索引类别 ?
主键索引
- 唯一索引
- 普通索引
- 全文索引
- 组合索引
4. 某些特定概念
- 回表
- 索引覆盖
- 最左匹配
- 构建索引树时的排序方式
- 获取时的检索方式
索引下推
哈希
- B+树
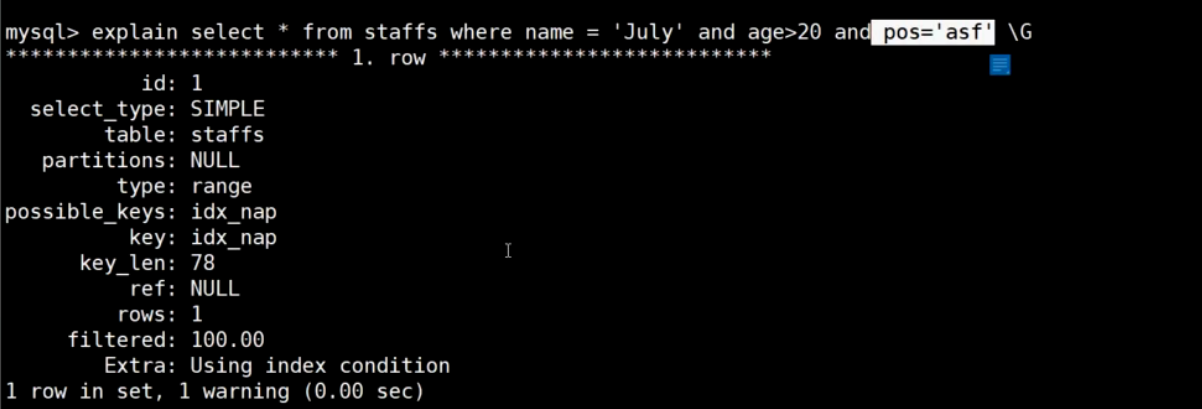
注意:innodb采用自适 应哈希,优化器会自动调整是否使用B+树或哈希,人为不可控;
6. 索引匹配方式
- 全值匹配
- 最左匹配
- 匹配列前缀
- like的字符串最前缀使用通配符就是最典型案例;
- 由于字符串匹配都是遵循从最左边开始匹配,第一个值是任意字符,导致无法锁定第一个值,不遵循最左原则,无法使用索引;
- like的字符串最前缀使用通配符就是最典型案例;
- 匹配范围值
- 精确匹配某一列并范围匹配另一列
- 只访问索引(不访问数据行)
执行计划中
key_len:使用到的索引列的长度(占用字节数),可以用来判断使用的索引个数(并不是where中所有字段都会使用索引)
key_len的计算方式:
- 关于不同编码方式对应一个长度字符串的占用大小:
- utf-8:3字节
- GBK:2字节
- 拉丁:1字节
- key_len计算方式:varchar的长度之和 对应编码的单位大小 + 每个varchar类型字段需要多占用2个字节 varchar类型字段个数 + 其他类型占用字节数(比如:一个int占用4字节)
- 基于哈希表实现,只有精确匹配索引所有列的查询才有效;
- mysql中,只有memory存储引擎显式支持哈希索引,innodb支持自适应哈希;
- 哈希索引自身只需要存储对应的hash值,所以索引的结构十分紧凑,这让哈希索引查找的速度非常快;
- 哈希索引的限制:
- 哈希索引中只存储哈希值和行指针,而不存储字段值,所以不存在索引覆盖这种情况,所有查询必然会查到最终的数据行;
- 哈希索引并不是通过索引值来进行排序,而是通过哈希算法对索引字段进行计算得到哈希值来进行排序,所以哈希索引无法进行排序,无法使用范围查询;
- 使用哈希索引必须全值匹配,无法使用部分列匹配查找;
- 哈希索引一般情况下访问速度非常快,除非存在比较严重的哈希冲突情况,当出现哈希冲突时,需要遍历链表中击中各个行指针,逐个进行IO和匹配,找到所有符合条件的行;
- 哈希冲突严重,维护的代价也会很高;
某种特殊情况:需要存储大量url(较长的字符串),如果使用B+数结构索引,所占用的空间会非常大,每页存储的索引值和指针相对减少,造成树所容纳的数据量减少,树层级变大,造成io次数变多,且本身长字符串在检索时所消耗的时间就更长,所以整体检索效率降低很多;
or是否走索引?
- 看具体情况而言;
- 组合索引使用or,必然不走索引;
- 单列的索引,使用or能够走索引,比如:primary index;
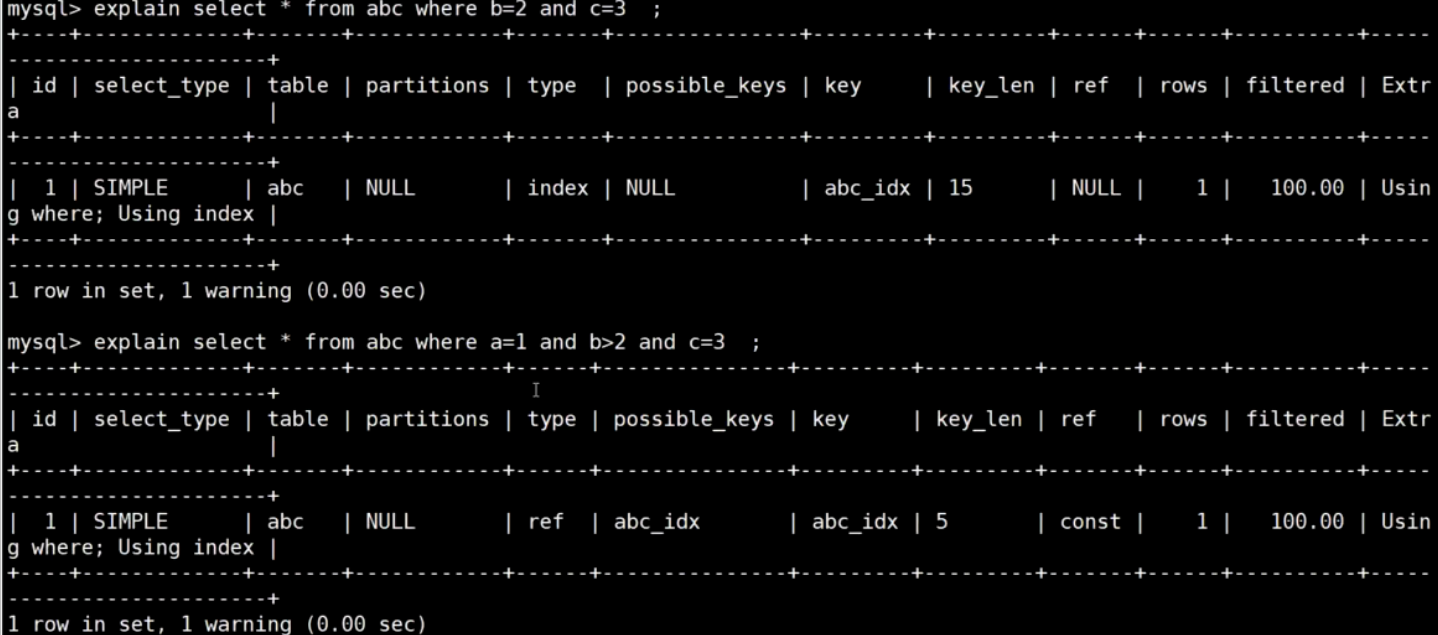
- 当所查询字段都在索引列上直接显示,那么最左原则失效,也能起到索引作用;
- 此情况如果与某些条件一起,比如:like,>,<,… 这些会使得最左原则重新起作用;
- 但是使用范围查询,范围查询字段后面的字段无法起索引作用;
9. extra额外信息

10. 聚簇索引与非聚簇索引
并非某种具体的索引类型,而是数据的存储方式。
- 聚簇索引:
- 索引与数据行绑定在一起;
- innodb持久层,采用对数据的存储,采用一个文件存储索引和数据;
优点:
- 将数据行与索引绑定,检索效率快;
- 存在覆盖索引概念,可以直接在当前索引树中索引值中获取所要查询的字段,不需要查找真正的数据行;
缺点:
- 聚簇索引提高了IO效率(存放于同一个文件),如果数据全部在内存,聚簇索引没什么优势;
- 插入的速度严重依赖于插入顺序,非主键自增的插入可能造成频繁页分裂,影响速度;
- 更新聚簇索引的索引值代价很高,因为涉及行的移动,且可能导致页分裂;
- 行比较稀疏的情况下,聚簇索引可能导致全表扫描效率变低;
- 非聚簇索引
- myisam则是分开使用两个文件分别存储(一个文件存储数据文件地址和偏移量,另一个文件存储表数据);// 应用于小内存环境比较有优势,因为小内存环境无法将数据load到内存(innodb的性能无法发挥),那么在索引文件中找到key对应的value,也就是数据文件的地址和指针偏移量,可以直接io到数据,不需要随机查找;
- 覆盖索引
- 如果一个索引包含所有要查询的字段值,就称为索引覆盖;
- 并不是所有存储引擎都支持覆盖索引,memory不支持覆盖索引(因为不存储索引值);
优势:
- 对于直接查询索引值,效率非常高;
- 索引通常小于数据行的大小,如果只需要访问索引就能获取数据,那么将极大减少数据的访问量;
- 对于myisam存储引擎只会在内存中缓存索引(key)和数据地址(value),所以访问数据需要一次系统调用,去访问另一个数据文件,可能严重影响性能;
- 对于innodb,如果想要获取主键值,由于覆盖索引的存在会特别迅速;
11. 注意点
如果写好最合适的sql代码:
- 使用索引查询时,尽量在where条件中不要使用表达式逻辑运算或者函数操作,将计算放在业务层而不是数据库层面;
- 尽量使用主键查询;因为主键查询不会涉及到回表,可直接获取完整的行数据。
- 当索引字段值都比较长,可以使用前缀索引;
- 排序操作尽量利用索引排序(已排好序,可直接获取,不需要使用额外空间或资源进行排序);
- 关于使用order by,遵循最左原则,如果中间隔开则无法使用索引排序,如果前面使用范围>,<,也无法使用索引排序,如果使用desc逆序排序,也无法使用索引排序;
- union,all,in,or都能够使用索引,但是推荐使用in;
- 范围列可以使用索引
,<,>=,<=,between都能使用索引
- 范围列可以使用索引,但是范围列后面的字段无法使用索引,也就是说索引最多只能用于一个范围列;
- 避免强制类型转换;
- 某个字符串类型字段在sql中没有使用’’符号,会触发隐式的自动类型转换;
- 更新频繁,数据区分度(选择度)不高的不宜建立索引;
- 更新会变更B+树,频繁更新会降低数据库性能,因为需要进行索引树的维护涉及频繁数据迁移,页分裂,页合并造成额外开销影响服务器性能;
- 对于性能这种选择性低的字段建立索引无意义,不能用于有效的过滤数据;
- 一般区分度在80%以上适合建议索引;count(distinct(列名))/count(*)
- 索引列不能为空;因为null在判断时间null = null 不成立,所以在检索时,使用 is null,is not null并不能得到预期结果;
- 当需要进行表连接的时候,最好不要超过三张,否则效率明显降低;需要join的字段,数据类型必须一致,否则索引失效;
- 能使用limit尽量使用limit;虽然explain里面的rows可能显示全表扫描,但是实际情况并不如此,使用limit时,rows值的参考价值不大;
- 单表索引建议控制在5个以内;
- 组合索引的字段个数不建议超过5个;
- 关于优化:
- 索引并不是越多越好;
- 避免过早优化,避免在不了解系统的情况下进行优化;
- 优化必须考虑表结构,数据量,具体的业务环境等等,而不是单纯地看sql语句;
三大范式主要是为了必须数据的冗余存储;
性能监控
- show profile for query 1;
- 查看performance_schema库(mysql自带的关于性能监控的库)
- 查看information_schema
- schema与数据类型优化


调优:
- 预调优
- 根据实际情况,数据量,具体的业务环境,设计合适的表结构,字段属性,给属性设置好是否唯一以及合适的长度;
- 根据实际数据量和访问情况,决定是否做集群,是否做数据库备份,做主从复制包括主从复制做低时延优化,读写分离,分库分表;
- 预先根据一般查询的条件,以及字段的唯一性、类型决定选择哪些字段建立索引,怎样组合成合适的符合索引;
- 字段值区分度高的优先建立索引,字段类型为整型的优先建立索引,字段值经常作为查询条件优先建立索引,字段更新频率低的优先建立索引;
- 单表索引设置在5个以内;索引多,数据更新对索引树的维护需要很大的开销;
- 单复合索引,字段设置在5个以内;索引列多,检索时,要匹配的信息就更多,效率受影响;
- 设置查询的SQL语句,遵循最左原则,尽量匹配更多的索引字段,不在where条件里面使用函数式计算或者一些隐式的自动类型转换,范围查询时,尽量使用索引列中的字段并且较靠后的字段;注意like的通配符使用;避免使用is null,is not null;
- 观察索引监控
- 能够根据mysql自带的参数查看索引的调用情况,包括:读取索引第一个条目的次数,通过索引获取数据的次数,。。。
- 可以外挂监控,观测sql执行的时间;如果发现sql语句执行时间异常可以尝试修改sql;
- 碰到实际问题
- 预调优并不能解决所有问题,所以当碰到实际问题时需要再次进行处理;
- 可以使用explain执行计划,通过执行计划查看sql的执行过程的小步骤,查看它执行的type类型,查看是否使用到索引,使用到哪些索引字段,索引匹配了多少长度,使用使用覆盖索引,外部文件排序,是否使用到临时表;
- 优化:可以调整sql的查询条件,避免一些让索引失效的操作,选择建立好的索引里面的各个索引列,尽可能多的根据最左原则,匹配更多的索引字段,条件需要查询的目标字段,以尽可能实现覆盖索引;

若有收获,就点个赞吧
0 人点赞
