milvus
https://github.com/milvus-io/milvus
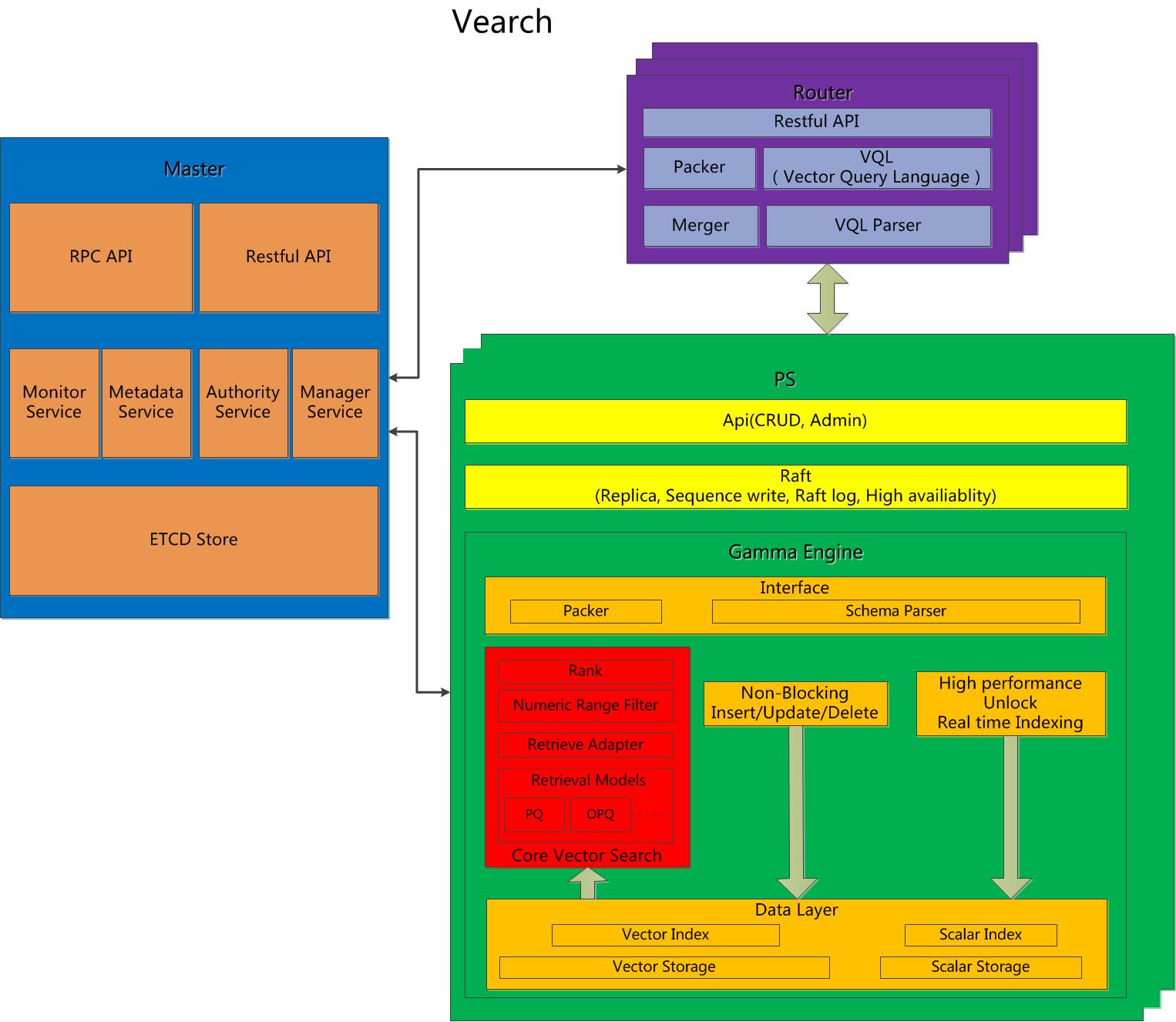
vearch
Vearch 是一个可扩展的分布式系统,用于深度学习向量的高效相似性搜索。
https://github.com/vearch/vearch
- 一个文档一个向量。
- 一个文档多个向量。
- 一个文档有多个数据源和向量。
- 数值场过滤
支持添加和搜索的批量操作。
由 C++ 实现的 Gamma 引擎保证了矢量的快速检测。
- 支持内积和L2方法计算向量距离。
- 支持内存和磁盘数据存储,支持超大数据规模。
- 基于raft协议的数据多副本存储。
nmslib
非度量空间库 (NMSLIB):一个高效的相似性搜索库和一个工具包,用于评估通用非度量空间的 k-NN 方法。
https://github.com/nmslib/nmslib
Non-Metric Space Library (NMSLIB) 是一个高效的跨平台相似度搜索库,也是一个评估相似度搜索方法的工具包。核心库并没有任何第三方依赖。它最近越来越受欢迎。特别是,它已成为Amazon Elasticsearch Service的一部分。
该项目的目标是创建一个有效且全面的工具包,用于在通用和非度量空间中进行搜索。尽管该库包含各种度量空间访问方法,但我们主要关注通用和近似搜索方法,特别是非度量空间的方法。NMSLIB 可能是第一个原则上支持非度量空间搜索的库。
NMSLIB 是一个可扩展的库,这意味着可以添加新的搜索方法和距离函数。NMSLIB 可以直接在 C++ 和 Python 中使用(通过 Python 绑定)。此外,还可以构建查询服务器,可以从 Java(或 Apache Thrift 支持的其他语言)中使用。Java 有一个本地客户端,也就是说,它可以在许多平台上运行而无需安装 C++ 库。
faiss
Faiss 是一个用于高效相似性搜索和密集向量聚类的库。它包含在任意大小的向量组中搜索的算法,直到可能不适合 RAM 的向量组。它还包含用于评估和参数调整的支持代码。Faiss 是用 C++ 编写的,带有 Python/numpy 的完整包装器。一些最有用的算法是在 GPU 上实现的。它由Facebook AI Research开发。
https://github.com/facebookresearch/faiss
Faiss 包含多种相似性搜索方法。它假设实例表示为向量并由整数标识,并且可以将向量与 L2(欧几里得)距离或点积进行比较。与查询向量相似的向量是那些与查询向量具有最低 L2 距离或最高点积的向量。它还支持余弦相似度,因为这是归一化向量的点积。
大多数方法,如基于二进制向量和紧凑量化代码的方法,只使用向量的压缩表示,不需要保留原始向量。这通常是以降低搜索精度为代价的,但这些方法可以扩展到单个服务器上主内存中的数十亿个向量。
GPU 实现可以接受来自 CPU 或 GPU 内存的输入。在具有 GPU 的服务器上,GPU 索引可用作 CPU 索引的直接替换(例如,替换IndexFlatL2为GpuIndexFlatL2),并且自动处理到/从 GPU 内存的复制。但是,如果输入和输出都驻留在 GPU 上,结果会更快。支持单 GPU 和多 GPU 使用。

若有收获,就点个赞吧
0 人点赞
