对象存活判断
当一个对象不再被任何已存活的对象引用时,对象被视为已死亡。
一、标记阶段:引用计数算法
1. 思路概述
- 每个对象保存一个整形的引用计数器属性。
- 对A对象增加引用时,将A的引用计数器值+1;
- 引用失效时,引用计数器值-1;
- 当对象引用计数器值为0时,表示对象A不可能再被使用,可进行回收。
2. 优势
- 实现简单,垃圾对象便于辨识;
- 判定效率高,回收没有延迟性。
3. 劣势
- 存储空间开销
- 需要单独的字段存储计数器值。
- 时间开销
- 每次赋值都需要更新计数器,伴随加法和减法操作。
无法处理循环引用
- Java中有循环引用的情况,该算法无法解决,所以没有采用该算法。
- 补充:Python解决循环依赖方案。
- 手动解除:合适的时机,将引用计数器手动置为0;
- 弱引用(weakref):Python提供标准库。
- 举例:单循环链表。 ```java /**
- 循环引用问题探究
- -XX:+PrintGCDetails
- 操作:打开或关闭{@link System#gc()} 方法;
- 结果:GC信息,内存占用不同;
- 结论:Java未使用引用计数算法;
*
- @author Jinhua
- @version 1.0
@date 2021/4/29 21:04 / public class RefCountGc { /*
- 唯一作用:占内存 / private final byte[] bigSize = new byte[5 2024 * 1024];
RefCountGc reference = null;
public static void main(String[] args) { RefCountGc r1 = new RefCountGc(); RefCountGc r2 = new RefCountGc();
// 互相引用 r1.reference = r2; r2.reference = r1; // 释放外部引用 r1 = null; r2 = null; // 打开或关闭gc方法,观察是否会执行GC System.gc(); } } ```
二、标记阶段:可达性分析算法
1. 别名
- 根搜索算法
- 追踪性垃圾收集
2. 特点
- 简单高效**;
- 有效解决循环引用问题,防止内存泄漏。
3. 根对象集合(GC Roots)
1) 约束定义
- 一组必须活跃的引用。
2) 主要GC Roots
- 虚拟机栈(Java Stack)中的引用对象。
- 本地方法栈(Native Method Stack)内的JNI引用的对象。
- 方法区静态属性引用的对象。
- 被同步锁synchronized持有的对象。
- JVM内部的引用。
- 基本数据类型对应的Class对象。
- 常驻的异常对象。
- 系统类加载器。
- 反映JVM内部情况的对象。如JMXBean,JVMIT中注册的回调,本地代码缓存等。
3) 其他GC Roots
除了上述固定的GC Roots外,根据用户所选用的垃圾收集器以及当前回收的内存区域不同,其他对象引用可临时加入GC Roots。比如分代收集和局部回收(Partial GC)。
- 如果只针对堆空间某一块区域GC(比如Young区),必须考虑内存区域是虚拟机是自己的实现细节,而不是内存封闭的,这个区域的对象可能被其他区域的对象所引用,必须将关联区域的对象一并加入GC Roots集合中。
4) 小技巧
Root采用栈方式存放变量和指针, 如果是一个指针,保存了堆内存里面的对象,自己又不在堆内存,则它应该被包含于GC Roots。
4. 思路概述
- 以根对象集合(GC Roots)为起始点,按自顶向下方法搜索所连接目标是否可达。
- 经过可达性分析后,存活对象都会被根对象直接或间接关联,搜索走过的路径称为引用链(Reference Chain)。
- 目标对象没有任何引用链相连,则是不可达的,意味着对象已经死亡可被回收。
5. 一致性
- 分析工作中需要保证引用关系在一个快照中进行,才能保证分析结果准确性。
- 所以,GC进行时会停止用户线程,以保证一致性。
- 即使是号称几乎不发生停顿的CMS收集器,枚举根节点也是必须要停顿的。
三、对象的finalization机制
方法原型
public class Object {protected void finalize() throws Throwable {}}
1. 作用
提供对象被销毁之前自定义处理逻辑。
- 套接字关闭。
- 文件关闭。
- 数据库连接关闭。
2. 说明
- 不要主动调用该方法。
- 可能导致对象复活;
- 方法执行时机无保障,完全由GC线程决定。
- 糟糕的重写finalize()会严重影响GC的性能。
- 功能上来讲,finalize()方法与C++的析构函数比较相似。但Java中是基于GC的自动内存管理机制,本质上有不同。
3. 对象的状态
- finalize() 方法的存在,导致JVM的对象处于三种可能的状态。从根节点开始进行可达性分析,一个无法触及的对象可能在某一个条件下复活自己:
- 可触及的。
- 经过可达性分析可以找到该对象。
- 可复活的。
- 对象的所有引用都被释放,但是对象有可能在finalize中复活。
- 不可触及的。
- 对象的finalize()方法被调用,并且没有复活,则进入不可触及状态。
- 不可触及的对象不可能被复活,因为finalize()方法只会被调用一次。
- 对象仅在不可触及状态时候才能被回收。
4. 代码演示
/*** GC过程,可复活对象的演示<p>** @author Jinhua* @version 1.0* @date 2021/4/30 14:18*/public class CanReliveObj {public static CanReliveObj obj;@Overrideprotected void finalize() throws Throwable {super.finalize();System.out.println("调用当前类的finalize() 方法");obj = this;}@SneakyThrowspublic static void main(String[] args) {obj = new CanReliveObj();// 第一次自救obj = null;System.gc();System.out.println("第一次GC完成!");// finalizer优先级低,暂停一下Thread.sleep(2_000L);String result = Objects.nonNull(obj) ? "第一次自救成功!" : "第一次自救失败...";System.out.println(result);// 第二次自救obj = null;System.gc();System.out.println("第二次GC完成!");// finalizer优先级低,暂停一下Thread.sleep(2_000L);result = Objects.nonNull(obj) ? "第二次自救成功!" : "第二次自救失败...";System.out.println(result);}}
四、MAT与JProfiler的GC Roots溯源
1. MAT查看Gc Roots
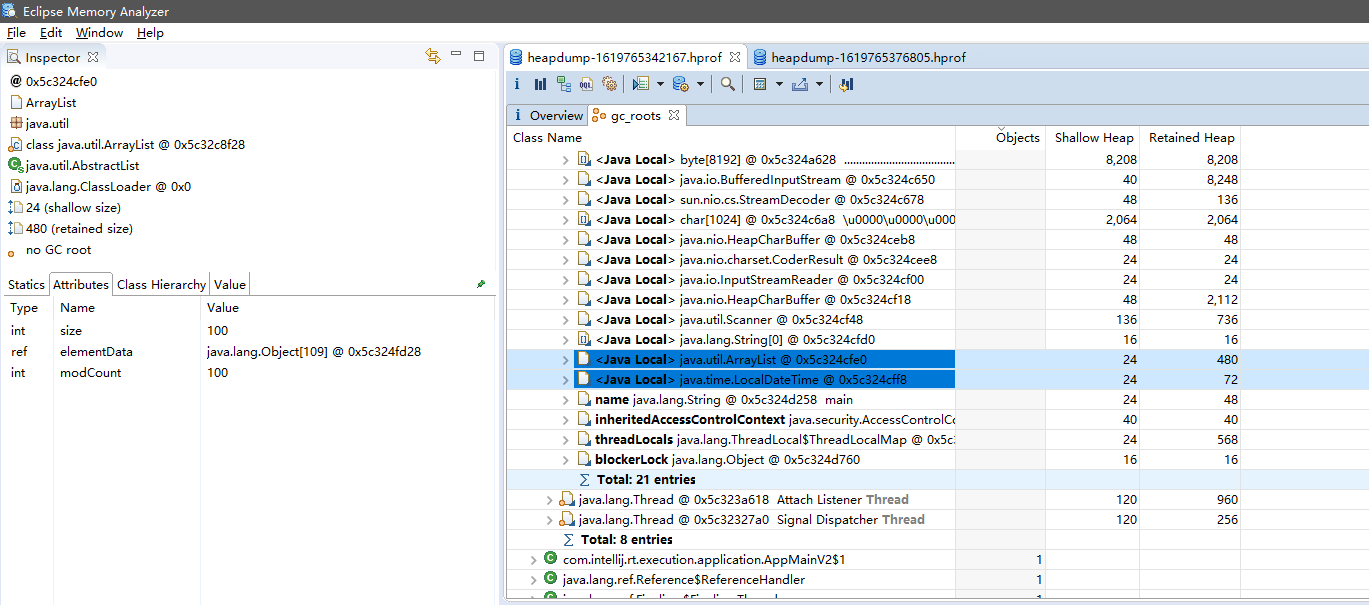
2. JProfiler查看Gc Roots
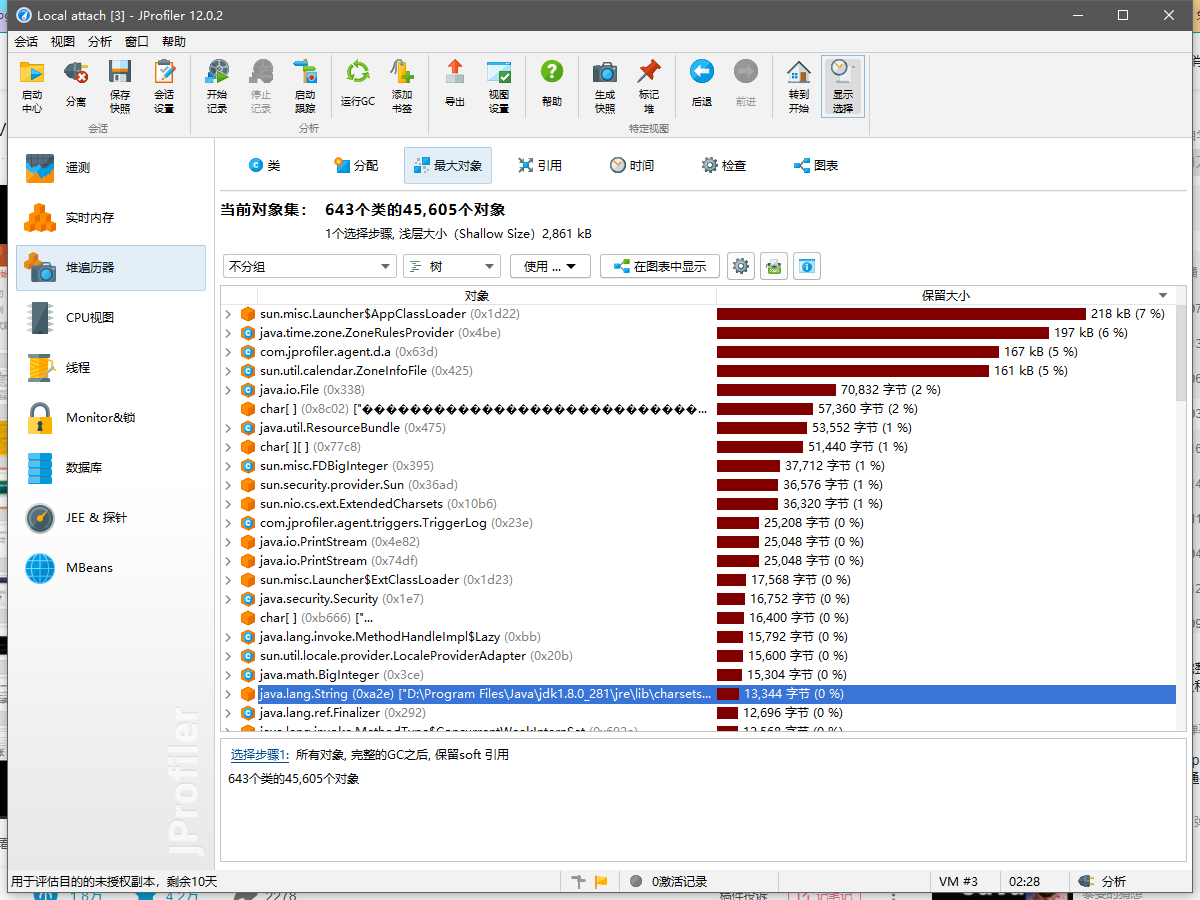
举例:OOM时候生成dump文件并查看
/*** 堆内存溢出生成dump文件<p> * -Xms8M -Xmx8M -XX:+HeapDumpOnOutOfMemoryError** @author Jinhua* @version 1.0* @date 2021/4/30 15:34*/public class HeapOom {private final byte[] bytes = new byte[1024 * 1024];@SuppressWarnings("all")public static void main(String[] args) {List<HeapOom> oList = new ArrayList<>();int count = 0;try {while (true) {oList.add(new HeapOom());count++;}// oom发生时,会在当前工程的目录下生成dump文件} catch (Throwable ex) {System.out.println("count = " + count);ex.printStackTrace();}}}
五、清除阶段:标记-清除(Mark-Sweep)算法
1. 背景
标记-清除(Mark-Sweep)
- 非常基础和常见的垃圾收集算法。
- 在1960年被J.McCarthy等人提出并应用于Lisp语言。
2. 执行过程
当堆中有效内存空间(Availble memory)将被耗尽的时候,就会停止整个程序(Stop the world)(即是停止用户线程),然后进行两项工作:
- 标记
- Collector从引用根节点开始遍历,标记所有被引用对象,一般是在对象头中记录为可达的对象。
- 清除
- Collector对堆内存进行线性遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收。
注意,这里的清除并不是真的置空,而是把垃圾对象地址保存为列表。需要分配的时候,再判断空间是否充足,并直接覆盖。
3. 优劣分析
1) 优点
- 常见,易于理解;
2) 缺点
- 效率不算高。
- 用户体验差。GC时候停止用户线程。
- 内存碎片。仅做了清除,未整理内存空间。
六、清除阶段:复制算法
1. 核心思想
- 将空间分为两份,每次只使用其中一份。
- 垃圾回收时候,将正在使用中的内存中的活对象复制到未被使用的内存块中,完成复制后,清除正在使用的内存块中的所有对象,交换两个内存的角色,完成垃圾回收。
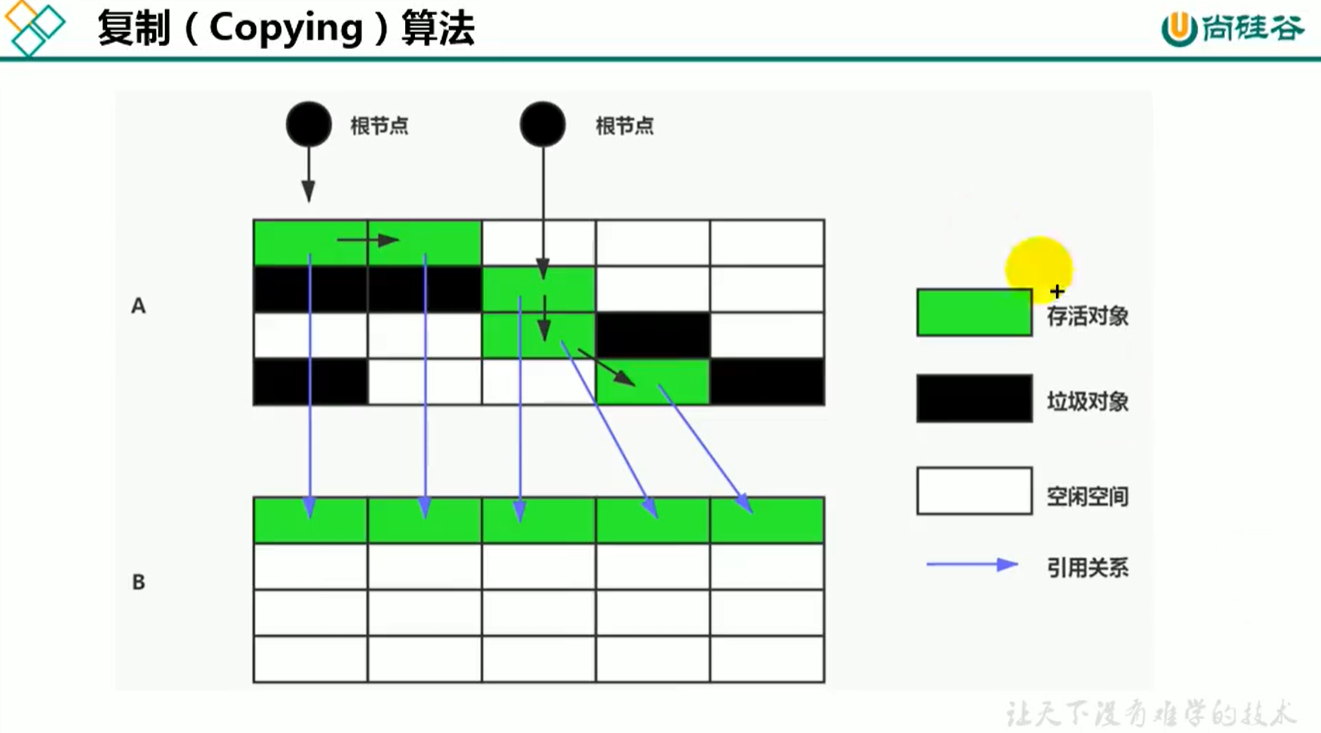
2. 优劣分析
1) 优势
- 无标记和清除过程,实现简单,运行高效。
- 复制后保证空间连续性,不会出现碎片空间。
2) 劣势
- 需要两倍的内存空间。
- 对于G1这种,拆分成大量region的GC,复制而不是移动,意味着GC需要维护region之间的对象引用关系。不论是内存占用或是时间开销都不小。
3) 适用场景
鉴于复制是耗时的操作,应该较少进行,系统中的存活对象占比应该很低才行。
- 新生代中,一次通常可以回收70%~99%的空间,回收的性价比高。
七、清除阶段:标记-压缩算法
1. 背景
- 老年代存活对象占比高,不适用复制算法。
- 老年代不适用【标记-清除】算法,效率低,产生碎片空间。
- 改进【标记-清除】算法,产生【标记-压缩算法】。
2. 执行过程

- 标记
从根结点开始标记所有被引用的结点 - 压缩
将存活对象压缩到内存的另一端,按顺序排放。 - 清理
清理边界外的所有空间。
3. 分析
- 标记-清除算法是非移动式的,而标记-压缩算法是移动式的。
- 包含了碎片整理过程,分配时候只需要提供一个初始内存即可。
1) 优势
- 消除内存碎片,分配内存只需一个初始地址。
- 消除了复制算法中,内存减半的高额代价。
2) 劣势
- 效率低于复制算法(用时间换了空间)。
- 移动对象的同时,如果对象被其他对象引用,则还需调整引用地址。
- 移动过程中,需要挂起用户线程。
八、清除算法小结
| 算法 | 标记-清除 (Mark-Sweep) |
标记-压缩 (Mark-Compact) |
复制 (Copying) |
|---|---|---|---|
| 速度 | 中等 | 最慢 | 最快 |
| 空间开销 | 1倍 | 1倍 | 2倍 |
| 碎片空间产生 | 是 | 否 | 否 |
| 移动对象 | 否 | 是 | 是 |
九、分代收集算法
- 不同生命周期的对象,采取不同的收集方式,以提高回收效率。
- 目前几乎所有GC都是采用分代收集算法(Generational Collection)执行垃圾回收。
| 内存区域 | 年轻代(Young Gen) | 老年代(Old Gen) | 永久代(Perm Gen) |
| —- | —- | —- | —- |
| 区域大小 | 小 | 中 | 大 |
| 对象情况 | 1) 生命周期短;
2) 存活率低 | 1) 生命周期长;
2) 存活率高 | 1) 生命周期更长;
2) 存活率更高 | | 回收情况 | 频繁 | 较少 | 一般不执行回收 | | 采用算法 | 复制算法(Copying) | 1) 标记-清除(Mark-Sweep)
2) 标记-清除 与 标记-压缩(混合实现作为补偿) | |
十、增量收集算法、分区算法
1. 增量收集算法
1) 基本思想
- 减少用户线程挂起的时间,每次仅回收一部分内存空间。
- 着力于线程间的处理。
- 基于标记-清除和复制算法。
2) 缺点
- 频繁切换用户线程和垃圾回收线程,垃圾回收总体成本上升,造成系统吞吐量下降。
3. 分区算法
1) 基本思想
为了更高控制用户线程挂起的时间,将一块大的内存区域分割成多个小块,每次合理回收若干个小区间,而不是整个堆空间。
写在最后
这些只是基本的算法思路,实际GC实现过程很复杂,并行和并发兼备。

若有收获,就点个赞吧
0 人点赞
