1. 内存管理
如果想知道Python的内存管理到底是什么样的,那么就需要知道Python在创建对象的时候底层都干了什么。
1.1 两个重要的结构体
include/object.h
#define _PyObject_HEAD_EXTRAstruct _object *_ob_next;struct _object *_ob_prev;#define PyObject_HEAD PyObject ob_base;#define PyObject_VAR_HEAD PyVarObject ob_base;typedef struct _object {_PyObject_HEAD_EXTRA // 用于构造双向链表Py_ssize_t ob_refcnt; // 引用计数器struct _typeobject *ob_type; // 数据类型} PyObject;typedef struct {PyObject ob_base; // PyObject对象Py_ssize_t ob_size; /* Number of items in variable part,即:元素个数 */} PyVarObject;
以上两个结构体PyObject和PyVarObject就是Python中创建对象的基石了,那这两个结构体中都有什么呢?
- PyObject
- _PyObject_HEAD_EXTRA:用于构造双向链表。
- ob_refcnt:引用计数器。
- *ob_type:数据类型。
- PyVarObject
- ob_base:PyObject结构体对象,即:包含PyObject结构体中的三个元素。
- ob_size:内部元素个数。
- 3个宏定义
- _PyObject_HEAD_EXTRA:代指两个指针,用于构造双向链表
- PyObject_HEAD:代指PyObject结构体
- PyObject_VAR_HEAD:代指PyVarObject结构体
Python在创建对象的时候,一般都是由PyObject和PyVarObject这两个结构体构造,一般由单个元素组成的对象(float),由PyObject结构体负责构造,由多个元素组成的对象(string、int、list、tuple、dict、set、自定义类),由PyVarObject结构体负责构造,因为由多个元素组成的对象需要维护一个ob_size,即元素个数。
下面是Python中每个类型所对应的C结构体:
float类型
typedef struct {PyObject_HEADdouble ob_fval;} PyFloatObject;
list类型
typedef struct {PyObject_VAR_HEAD/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */PyObject **ob_item;/* ob_item contains space for 'allocated' elements. The number* currently in use is ob_size.* Invariants:* 0 <= ob_size <= allocated* len(list) == ob_size* ob_item == NULL implies ob_size == allocated == 0* list.sort() temporarily sets allocated to -1 to detect mutations.** Items must normally not be NULL, except during construction when* the list is not yet visible outside the function that builds it.*/Py_ssize_t allocated;} PyListObject;
tuple类型 ```c typedef struct { PyObject_VAR_HEAD PyObject *ob_item[1];
/* ob_item contains space for ‘ob_size’ elements.
- Items must normally not be NULL, except during construction when
- the tuple is not yet visible outside the function that builds it. */ } PyTupleObject;
include/tupleobject.h
- dict类型```ctypedef struct {PyObject_HEADPy_ssize_t ma_used;PyDictKeysObject *ma_keys;PyObject **ma_values;} PyDictObject;
set类型
typedef struct {PyObject_HEADPy_ssize_t fill; /* Number active and dummy entries*/Py_ssize_t used; /* Number active entries *//* The table contains mask + 1 slots, and that's a power of 2.* We store the mask instead of the size because the mask is more* frequently needed.*/Py_ssize_t mask;/* The table points to a fixed-size smalltable for small tables* or to additional malloc'ed memory for bigger tables.* The table pointer is never NULL which saves us from repeated* runtime null-tests.*/setentry *table;Py_hash_t hash; /* Only used by frozenset objects */Py_ssize_t finger; /* Search finger for pop() */setentry smalltable[PySet_MINSIZE];PyObject *weakreflist; /* List of weak references */} PySetObject;
string类型
typedef struct {PyObject_HEADPy_ssize_t length; /* Number of code points in the string */Py_hash_t hash; /* Hash value; -1 if not set */struct {unsigned int interned:2;/* Character size:- PyUnicode_WCHAR_KIND (0):* character type = wchar_t (16 or 32 bits, depending on theplatform)- PyUnicode_1BYTE_KIND (1):* character type = Py_UCS1 (8 bits, unsigned)* all characters are in the range U+0000-U+00FF (latin1)* if ascii is set, all characters are in the range U+0000-U+007F(ASCII), otherwise at least one character is in the rangeU+0080-U+00FF- PyUnicode_2BYTE_KIND (2):* character type = Py_UCS2 (16 bits, unsigned)* all characters are in the range U+0000-U+FFFF (BMP)* at least one character is in the range U+0100-U+FFFF- PyUnicode_4BYTE_KIND (4):* character type = Py_UCS4 (32 bits, unsigned)* all characters are in the range U+0000-U+10FFFF* at least one character is in the range U+10000-U+10FFFF*/unsigned int kind:3;unsigned int compact:1;unsigned int ascii:1;unsigned int ready:1;unsigned int :24;} state;wchar_t *wstr; /* wchar_t representation (null-terminated) */} PyASCIIObject;typedef struct {PyASCIIObject _base;Py_ssize_t utf8_length; /* Number of bytes in utf8, excluding the* terminating \0. */char *utf8; /* UTF-8 representation (null-terminated) */Py_ssize_t wstr_length; /* Number of code points in wstr, possible* surrogates count as two code points. */} PyCompactUnicodeObject;typedef struct {PyCompactUnicodeObject _base;union {void *any;Py_UCS1 *latin1;Py_UCS2 *ucs2;Py_UCS4 *ucs4;} data; /* Canonical, smallest-form Unicode buffer */} PyUnicodeObject;
string类型有点繁琐,也看不太懂,估计是处理和编码相关的逻辑;
int类型 ```c // longintrepr.h
struct _longobject { PyObject_VAR_HEAD digit ob_digit[1]; };
// longobject.h
/ Long (arbitrary precision) integer object interface / typedef struct _longobject PyLongObject; / Revealed in longintrepr.h /
/*
- python3中没有long类型,只有int类型,但py3内部的int是基于long实现。
- python3中对int/long长度没有限制,因其内部不是用long存储而是使用类似于“字符串”存储。 */
- 自定义类```ctypedef struct _typeobject {PyObject_VAR_HEADconst char *tp_name; /* For printing, in format "<module>.<name>" */Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation *//* Methods to implement standard operations */...} PyTypeObject;
1.2 内存管理
下边以float和list为例,来看下Python到底是如何管理内存的。
1.2.1 创建float对象时,C源码执行流程
/* Special free listfree_list is a singly-linked list of available PyFloatObjects, linkedvia abuse of their ob_type members.*/static PyFloatObject *free_list = NULL;static int numfree = 0;PyObject *PyFloat_FromDouble(double fval){PyFloatObject *op = free_list;if (op != NULL) {free_list = (PyFloatObject *) Py_TYPE(op);numfree--;} else {// 第一步:根据float类型大小,为float对象开辟内存。op = (PyFloatObject*) PyObject_MALLOC(sizeof(PyFloatObject));if (!op)return PyErr_NoMemory();}// 第二步:在为float对象开辟的内存中进行初始化。/* Inline PyObject_New */(void)PyObject_INIT(op, &PyFloat_Type);// 第三步:将值赋值到float对象开辟的内存中。op->ob_fval = fval;// 第四步:返回已经创建的float对象的内存地址(引用/指针)return (PyObject *) op;}
第一步:根据float类型大小,为float对象开辟内存空间
static PyMemAllocatorEx _PyObject = {#ifdef PYMALLOC_DEBUG&_PyMem_Debug.obj, PYDBG_FUNCS#elseNULL, PYOBJ_FUNCS#endif};void *PyObject_Malloc(size_t size){/* see PyMem_RawMalloc() */if (size > (size_t)PY_SSIZE_T_MAX)return NULL;// 开辟内存return _PyObject.malloc(_PyObject.ctx, size);}
第二步:在为float对象开辟的内存中进行初始化
/* Macros trading binary compatibility for speed. See also pymem.h.Note that these macros expect non-NULL object pointers.*/#define PyObject_INIT(op, typeobj) \( Py_TYPE(op) = (typeobj), _Py_NewReference((PyObject *)(op)), (op) )
/* Head of circular doubly-linked list of all objects. These are linked* together via the _ob_prev and _ob_next members of a PyObject, which* exist only in a Py_TRACE_REFS build.*/static PyObject refchain = {&refchain, &refchain};/* Insert op at the front of the list of all objects. If force is true,* op is added even if _ob_prev and _ob_next are non-NULL already. If* force is false amd _ob_prev or _ob_next are non-NULL, do nothing.* force should be true if and only if op points to freshly allocated,* uninitialized memory, or you've unlinked op from the list and are* relinking it into the front.* Note that objects are normally added to the list via _Py_NewReference,* which is called by PyObject_Init. Not all objects are initialized that* way, though; exceptions include statically allocated type objects, and* statically allocated singletons (like Py_True and Py_None).*/void_Py_AddToAllObjects(PyObject *op, int force){if (force || op->_ob_prev == NULL) {op->_ob_next = refchain._ob_next;op->_ob_prev = &refchain;refchain._ob_next->_ob_prev = op;refchain._ob_next = op;}}void_Py_NewReference(PyObject *op){_Py_INC_REFTOTAL;// 对新开辟的内存中的的引用计数器初始化为1。op->ob_refcnt = 1;// 将新开辟的内存的指针添加到一个双向链表refchain中。_Py_AddToAllObjects(op, 1);_Py_INC_TPALLOCS(op);}
所以,float类型每次创建对象时都会把对象放到 refchain 的双向链表中。
1.2.2 float对象被引用时
>>> f = 2.2>>> ff = f
这个过程比较简单,在给对象创建新引用时,会执行对其引用计数器+1的动作。
/*The macros Py_INCREF(op) and Py_DECREF(op) are used to increment or decrementreference counts. Py_DECREF calls the object's deallocator function whenthe refcount falls to 0; forobjects that don't contain references to other objects or heap memorythis can be the standard function free(). Both macros can be usedwherever a void expression is allowed. The argument must not be aNULL pointer. If it may be NULL, use Py_XINCREF/Py_XDECREF instead.The macro _Py_NewReference(op) initialize reference counts to 1, andin special builds (Py_REF_DEBUG, Py_TRACE_REFS) performs additionalbookkeeping appropriate to the special build.#define Py_INCREF(op) (_Py_INC_REFTOTAL _Py_REF_DEBUG_COMMA((PyObject *)(op))->ob_refcnt++)
1.2.3 销毁float对象时
f = 5.20# 主动删除对象del f"""主动del删除对象时,会执行对象销毁的动作。一个函数执行完毕之后,其内部局部变量也会有销毁动作,如:def func():f = 2.22func()"""
当进行销毁对象动作时,先后会执行如下代码:
The macros Py_INCREF(op) and Py_DECREF(op) are used to increment or decrementreference counts. Py_DECREF calls the object's deallocator function whenthe refcount falls to 0; forobjects that don't contain references to other objects or heap memorythis can be the standard function free(). Both macros can be usedwherever a void expression is allowed. The argument must not be aNULL pointer. If it may be NULL, use Py_XINCREF/Py_XDECREF instead.The macro _Py_NewReference(op) initialize reference counts to 1, andin special builds (Py_REF_DEBUG, Py_TRACE_REFS) performs additionalbookkeeping appropriate to the special build.#define Py_DECREF(op) \do { \PyObject *_py_decref_tmp = (PyObject *)(op); \if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA \--(_py_decref_tmp)->ob_refcnt != 0) \_Py_CHECK_REFCNT(_py_decref_tmp) \else \_Py_Dealloc(_py_decref_tmp); \} while (0)
void_Py_Dealloc(PyObject *op){// 第一步:调用float类型的tp_dealloc,进行内存的销毁destructor dealloc = Py_TYPE(op)->tp_dealloc;// 第二步:在refchain双向链表中移除_Py_ForgetReference(op);(*dealloc)(op);}
第一步,调用float类型的tp_dealloc进行内存的销毁。
按理此过程说应该直接将对象内存销毁,但float内部有缓存机制,所以他的执行流程是这样的:
- float内部缓存的内存个数已经大于等于100,那么在执行
del val的语句时,内存中就会直接删除此对象。 - 未达到100时,那么执行
del val语句,不会真的在内存中销毁对象,而是将对象放到一个free_list的单链表中,以便以后的对象使用。 ```c / Special free list free_list is a singly-linked list of available PyFloatObjects, linked via abuse of their ob_type members. /
ifndef PyFloat_MAXFREELIST
define PyFloat_MAXFREELIST 100
endif
static int numfree = 0; static PyFloatObject *free_list = NULL;
PyTypeObject PyFloat_Type = { PyVarObject_HEAD_INIT(&PyType_Type, 0) “float”, sizeof(PyFloatObject), 0,
// tp_dealloc表示执行float_dealloc方法(destructor)float_dealloc, /* tp_dealloc */0, /* tp_print */0, /* tp_getattr */0, /* tp_setattr */0, /* tp_reserved */...
};
static void float_dealloc(PyFloatObject *op) { // 检测是否是float类型 if (PyFloat_CheckExact(op)) {
// 检测缓冲池个数是否大于100个if (numfree >= PyFloat_MAXFREELIST) {// 如果大于100个,则在内存中销毁对象PyObject_FREE(op);return;}// 否则,缓冲池个数+1// 并将要销毁的数据加入到free_list的单项链表中,以便以后创建float类型使用。numfree++;Py_TYPE(op) = (struct _typeobject *)free_list;free_list = op;}elsePy_TYPE(op)->tp_free((PyObject *)op);
}
**第二步**,在refchain双向链表中移除```c/* Head of circular doubly-linked list of all objects. These are linked* together via the _ob_prev and _ob_next members of a PyObject, which* exist only in a Py_TRACE_REFS build.*/static PyObject refchain = {&refchain, &refchain};void_Py_ForgetReference(PyObject *op){#ifdef SLOW_UNREF_CHECKPyObject *p;#endifif (op->ob_refcnt < 0)Py_FatalError("UNREF negative refcnt");if (op == &refchain ||op->_ob_prev->_ob_next != op || op->_ob_next->_ob_prev != op) {fprintf(stderr, "* ob\n");_PyObject_Dump(op);fprintf(stderr, "* op->_ob_prev->_ob_next\n");_PyObject_Dump(op->_ob_prev->_ob_next);fprintf(stderr, "* op->_ob_next->_ob_prev\n");_PyObject_Dump(op->_ob_next->_ob_prev);Py_FatalError("UNREF invalid object");}#ifdef SLOW_UNREF_CHECKfor (p = refchain._ob_next; p != &refchain; p = p->_ob_next) {if (p == op)break;}if (p == &refchain) /* Not found */Py_FatalError("UNREF unknown object");#endifop->_ob_next->_ob_prev = op->_ob_prev;op->_ob_prev->_ob_next = op->_ob_next;op->_ob_next = op->_ob_prev = NULL;_Py_INC_TPFREES(op);}
综上所述,float对象在创建对象时会把为其开辟内存并初始化引用计数器为1,然后将其加入到名为 refchain 的双向链表中;float对象在增加引用时,会执行 Py_INCREF在内部会让引用计数器+1;最后执行销毁float对象时,会先判断float内部free_list中缓存的个数,如果已达到100个,则直接在内存中销毁,否则不会真正销毁而是加入free_list单链表中,以后后续对象使用,销毁动作的最后再在refchain中移除即可。
1.2.4 验证
从上边三小节中可以看出Python在销毁一个对象后,不会直接将内存空间释放掉,而是会将它加入一个叫free_list的一个单向链表中,下面执行几行代码来验证下是不是这样的:
>>> f = 5.20>>> id(f)1932934517168>>> del f>>> ff = 10.22>>> id(ff)1932934517168
上边代码中,第1~4行是一个float对象的创建到销毁过程,按道理讲,5.20这个对象被销毁了,内存空间也会被释放出来对吧,那下一次再创建一个float对象时,并不一定会用那块内存,也就是说f和ff两个变量所指向的内存地址并不一定是相同的。那再看第5~7行,很显然,它俩得地址用的是同一个,那这就很好解释free_list这个东西了。当一个对象被销毁时,并不会直接释放内存,而是先放到free_list中,当下次需要创建同等类型的对象时,就直接从free_list中取出一个就行。也就是说Python在内存管理中,会用到缓存。
2. 垃圾回收
众所周知,python的垃圾回收机制为:引用计数为主,标记清除、分代回收为辅。那么引用计数、标记清除、分代回收都是什么意思呢?
2.1 引用计数
2.1.1 原理
还记得python在创建对象的时候,其实就相当于实例化一个C中的结构体,然后将创建的对象再放到refchain这个环形双向链表中,比如创建一个float类型的对象,python底层会实例化一个PyFloatObject对象,而PyFloatObject中有一个属性为ob_refcnt,这个就是计数器,比如:
当在python中创建一个a = 5.20这样的float类型的对象时,5.20这个对象对应的ob_refcnt就会加1
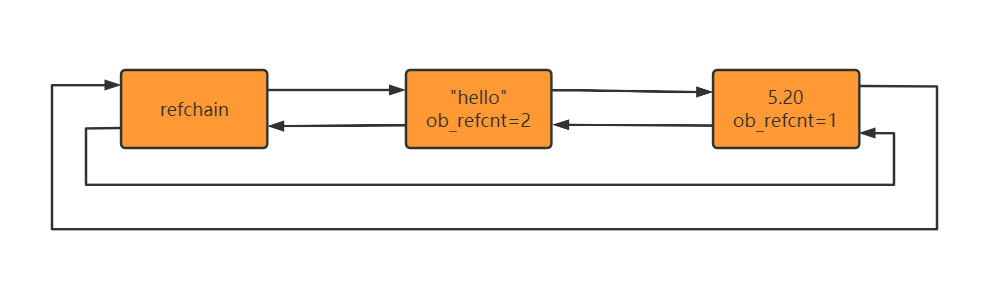
环形双向链表refchain
>>> import sys>>> a = 5.20>>> sys.getrefcount(a)2 # 这里为什么会是2,是因为a被当做参数传入了getrefcount函数中,所以它的引用计数器也会加1
那还有什么时候引用计数器会加一呢?一般有以下几种情况:
- 对象被创建 a=14
- 对象被引用 b=a
- 对象被作为参数,传到函数中 func(a)
- 对象作为一个元素,存储在容器中 List=[a, ‘a’, ‘b’, 2]
那什么情况下引用计数器会减一呢?
- 当该对象的别名被显式销毁时 del a
- 当该对象的引别名被赋予新的对象, a=26
- 一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
- 将该元素从容器中删除时,或者容器被销毁时。
当一个对象的引用计数为0的时候,Python就会启动垃圾回收,将这个引用计数为0的对象从内存中释放,这就是引用计数(暂不考虑上边提到的**free_list**缓存情况)。
2.1.2 优点
- 高效
- 运行期没有停顿 可以类比一下Ruby的垃圾回收机制,也就是 实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
- 对象有确定的生命周期
-
2.1.3 缺点
维护引用计数消耗资源,维护引用计数的次数和引用赋值成正比,而不像mark and sweep等基本与回收的内存数量有关。
- 无法解决循环引用的问题。A和B相互引用而再没有外部引用A与B中的任何一个,它们的引用计数都为1,但显然应该被回收。
什么是循环引用呢?
>>> list_a = [1,2,3]>>> list_b = [4,5,6]>>> list_a.append(list_b) # 这个时候 list_a = [1,2,3, [4,5,6]]>>> list_b.append(list_a) # list_b = [4,5,6,[1,2,3]]>>> del list_a>>> del list_b
上边例子中,执行到第4行的时候,[1,2,3]和[4,5,6]的ob_refcnt都等于2, 然后执行完第5、6行del list_a del list_b的时候,[1,2,3]和[4,5,6]的ob_refcnt等于1,其实这个时候已经没有外部变量去引用它俩了,按道理讲,这两个对象就应该被回收的。但是引用计数的特点是:当一个对象的引用数为0时,Python才会将此对象释放掉。这就是引用计数的一个明显的缺点。
2.2 标记清除
既然引用计数的一个明显缺点就是无法解决循环引用问题,那必然不能放任它不管,那就引出来标记清除这个东东了。
什么是标记清除呢?其实标记清除就是Python在内存中又维护了一个链表,这个链表的作用就是将可能会产生循环引用的对象再次放到另一个链表中,可能会产生循环引用的对象有:list、tuple、set、dict、自定义类。如下图所示: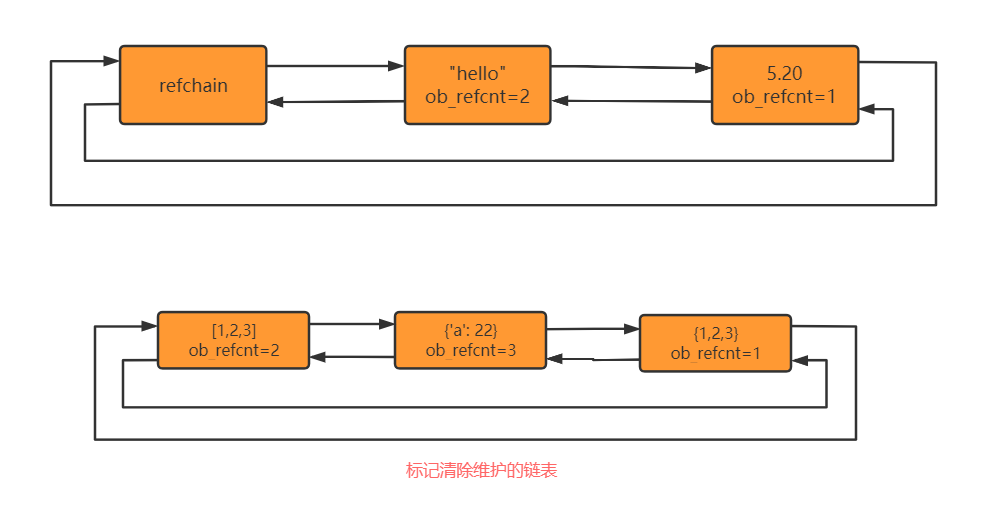
当我们在Python中创建了一个可能会产生循环引用的对象的时候,比如一个list,底层不只是将这个list对象放入refchain中还会将它放入另一个链表中,这个链表就是负责标记清除使用的,然后再检查这个链表中有没有循环引用的,如果有,则让双方的ob_refcnt各自减1。这时如果ob_refcnt减1之后等于0了,那就会将它的内存释放。那么问题来了,这个标记清除的链表什么时候检查呢?不急,因为还有个东西叫分代回收。
2.3 分代回收
分代回收就是对标记清除的链表进行优化,将可能产生循环引用的对象放入3个链表中,分别称为0代、1代、2代,每代都可以存储对象和阈值,当达到阈值时,就会对相应的链表中的每个对象做一次扫描,循环引用的计数器各自减1并且销毁引用计数器为0的对象。
下边是分代回收的C源码:
// 分代的C源码#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = {/* PyGC_Head, threshold, count */{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};
特别注意:0代和1、2代的threshold和count表示的意义不同。
- 0代,count表示0代链表中对象的数量,threshold表示0代链表对象个数阈值,超过则执行一次0代扫描检查。
- 1代,count表示0代链表扫描的次数,threshold表示0代链表扫描的次数阈值,超过则执行一次1代扫描检查。
- 2代,count表示1代链表扫描的次数,threshold表示1代链表扫描的次数阈值,超过则执行一2代扫描检查。
例子:
第一步:当创建对象age=19时,会将对象添加到refchain链表中。
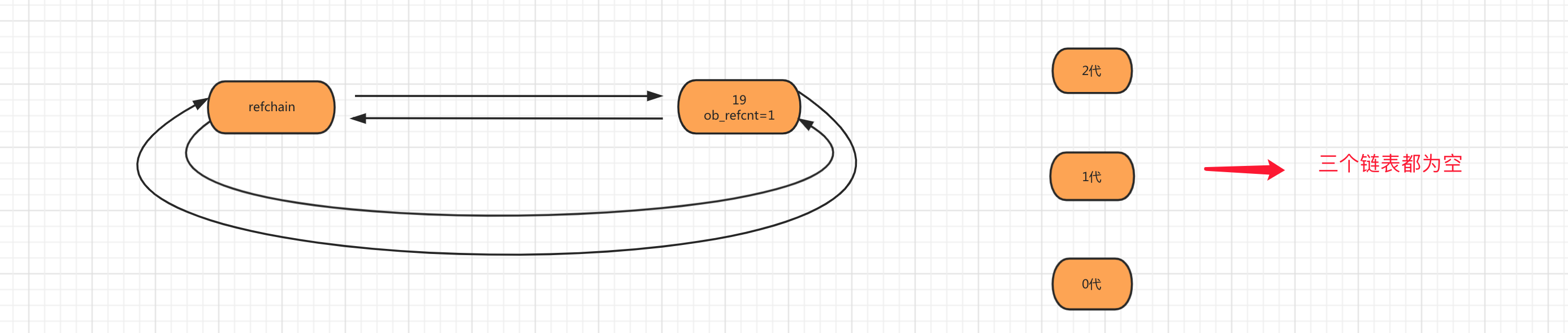
第二步:当创建对象num_list = [11,22]时,会将列表对象添加到 refchain 和 generations 0代中。
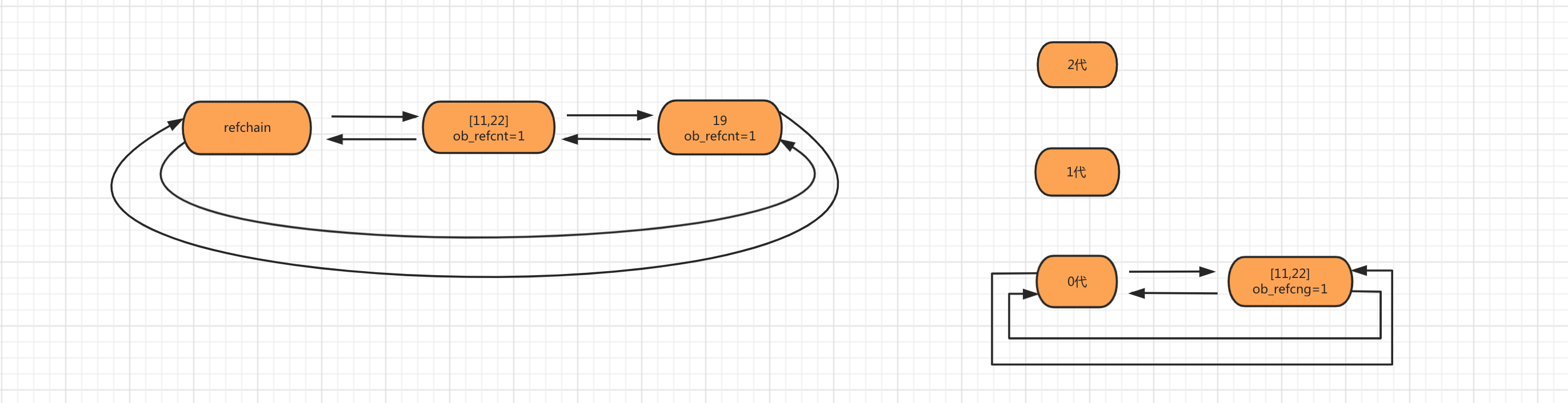
第三步:新创建对象使generations的0代链表上的对象数量大于阈值700时,要对链表上的对象进行扫描检查。
当0代大于阈值后,底层不是直接扫描0代,而是先判断2、1是否也超过了阈值。
- 如果2、1代未达到阈值,则扫描0代,并让1代的 count + 1 。
- 如果2代已达到阈值,则将2、1、0三个链表拼接起来进行全扫描,并将2、1、0代的count重置为0.
- 如果1代已达到阈值,则讲1、0两个链表拼接起来进行扫描,并将所有1、0代的count重置为0.
对拼接起来的链表在进行扫描时,主要就是剔除循环引用和销毁垃圾,详细过程为:
- 扫描链表,把每个对象的引用计数器拷贝一份并保存到
gc_refs中,保护原引用计数器。 - 再次扫描链表中的每个对象,并检查是否存在循环引用,如果存在则让各自的
gc_refs减 1 。 - 再次扫描链表,将
gc_refs为 0 的对象移动到unreachable链表中;不为0的对象直接升级到下一代链表中。 - 处理
unreachable链表中的对象的 析构函数 和 弱引用,不能被销毁的对象升级到下一代链表,能销毁的保留在此链表。- 析构函数,指的就是那些定义了
__del__方法的对象,需要执行之后再进行销毁处理。 - 弱引用,
- 析构函数,指的就是那些定义了
- 最后将
unreachable中的每个对象销毁并在refchain链表中移除(不考虑缓存机制)。
至此,垃圾回收的过程结束。
TODO: 问题:在分代回收的链表中,如何判断每个对象是否有循环引用呢?
**
参考:

若有收获,就点个赞吧
0 人点赞
