就像任何分布式系统一样,Kubernetes 依靠网络来提供服务之间的连接,以及连接外部用户和暴露的工作负载。
事实证明,在传统应用架构中管理网络总是相当困难。在许多组织中,存在职责分离 — 开发人员将创建他们的应用程序,而运维人员将负责运行它们。很多时候,随着应用的发展,网络基础设施的需求会发生变化。在最好的情况下,应用程序根本无法运行,运营商将采取纠正措施。然而,在最坏的情况下,网络安全等领域会出现重大漏洞。
Kubernetes 允许开发人员定义网络资源和策略,这些资源和策略可以与他们的应用部署清单同时存在。这些资源和策略可能会被集群管理员很好地扩展,并且可以利用任何数量的使用通用抽象层的最佳技术实现。通过将开发人员从网络工作的细节中解脱出来,并将基础设施的需求与应用的需求结合起来,我们可以更好地保证我们的应用能够以一致和安全的方式交付。
容器网络接口(CNI)
在我们谈论如何将用户与容器化工作负载连接起来之前,我们需要了解 Pod 如何与其他 Pod 通信。这些 Pod 可能被安置在同一个节点上,也可能跨过同一个子网的节点,甚至可能在不同子网的节点上,甚至可能位于不同的数据中心。如图 10-1 所示,不管网络管道是什么样的,我们的目标是以无缝、可路由的方式连接 Pod。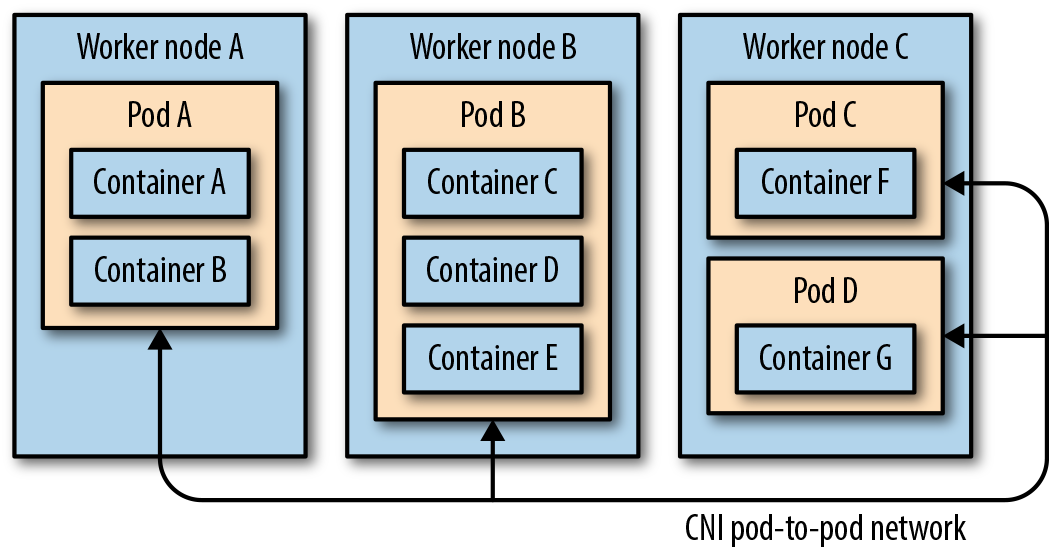
图 10-1 CNI 网络
Kubernetes 使用 CNI 规范与网络接口。这个开放规范的目标是规范容器编排平台如何将容器与底层网络连接起来,并以可插拔的方式进行。目前有几十种解决方案,每种解决方案都有自己的架构和功能。大多数是开源解决方案,但在云原生生态系统中也有来自一些不同供应商的专有解决方案。无论您在什么环境下部署集群,肯定会有一个插件来满足您的需求。
虽然 Kubernetes 内的联网有多个方面,但 CNI 的作用只是促进 Pod 与 Pod 之间的连接。这种情况的发生方式比较简单。容器运行时(如 Docker)调用 CNI 插件可执行文件(如 Calico)向容器的网络命名空间添加或删除接口。这些接口被称为沙盒接口。
正如你所记得的,每个 Pod 都被分配了一个 IP 地址,CNI 插件负责将其分配和分配给 Pod。
:::info
你可能会问自己:“如果一个 Pod 可以有多个容器,那么 CNI 如何知道要连接哪一个?” 如果你曾经查询过 Docker,以列出在给定 Kubernetes 节点上运行的容器,你可能会注意到一些与你的每个 Pod 相关联的 pause 容器。这些暂停容器在计算上没有任何意义。它们只是作为每个 Pod 的容器网络的占位符。因此,在单个 Pod 的生命周期中,它们是第一个被启动的容器,也是最后一个死亡的容器。
:::
插件代表容器运行时执行了所需的任务后,它就像其他 Linux 进程一样,返回执行状态。0 表示成功,任何其他返回代码表示失败。作为成功操作的一部分,CNI 插件还将返回插件在此过程中操纵的 IP、路由和 DNS 条目的详细信息。
除了将容器连接到网络外,CNI 还具有 IP 地址管理(IPAM)的功能。IPAM 确保 CNI 始终清楚地了解哪些地址在使用中,以及那些可用于配置新接口的地址。
选择 CNI 插件
当选择在您的环境中使用的 CNI 插件时,有两个主要的考虑因素需要记住。
你的网络拓扑结构是什么?
您的网络拓扑结构在很大程度上决定了您最终能够在环境中部署的内容。例如,如果您要部署到公有云内的多个可用性区域,您可能需要实施支持某种形式的封装(也称为覆盖网络)的插件。哪些功能对您的组织来说是必须的?
你需要考虑哪些功能对你的部署很重要。如果对Pod之间的相互 TLS 有硬性要求,你可能会希望使用提供这种功能的插件。同样的道理,并不是每个插件都能提供对 NetworkPolicy 的支持。在你部署集群之前,一定要评估插件提供的功能。
:::info CNI 并不是强制 Pod 之间相互 TLS 的唯一机制。通过称为服务网格的 Sidecar 模式,集群管理员可以要求工作负载只能通过启用 TLS 的本地代理进行通信。服务网格不仅可以提供端到端加密,还可以启用更高级别的功能,如电路断路、蓝/绿部署和分布式跟踪。它还可以为最终用户透明地启用。 :::
kube-proxy
即使有了 Pod-to-Pod 网络,如果 Kubernetes 不提供一些比 IP-to-IP 直接连接更多的抽象,那么 Kubernetes 在连接性方面还是比较原始的。如果一个 Deployment 有多个副本,因此有多个服务 IP,我们会如何处理这种情况?我们是否只需选择其中一个 IP,并希望它不会在未来某个时间点被删除?用一个虚拟 IP 来引用这些副本不是更好吗?而且,再进一步,有一个 DNS 记录不是更好吗?
所有这些都可以通过我们在第二章中介绍的 Kubernetes 服务资源来实现。通过 Service 资源,我们为 Pod 集合所暴露的网络服务分配一个虚拟 IP。后面的 Pod 使用 Pod 选择器来发现和连接。
:::info 许多 Kubernetes 的新手通常认为 Pod 的集合(即 Deployment)和服务之间的关系是一对一的。因为服务是通过标签选择器的方式与 Pod 连接的,任何具有相应标签的 Pod 都被认为是一个服务端点。该功能允许您混合和匹配支持的 Pod,甚至可以启用高级部署,如蓝/绿和金丝雀发布。 :::
在幕后,让这一切成为可能的 Kubernetes 组件是 kube-proxy 进程,kube-proxy 通常作为一个特权容器进程运行,它负责管理这些虚拟服务 IP 地址的连接。
:::tips 代理这个名字是一个历史渊源的误区:kube-proxy 最初是用用户空间代理实现的。后来这种情况发生了变化,在最常见的情况下,kube-proxy 只是在每个节点上操纵 iptables 规则。这些规则会将指向服务 IP 的流量重定向到任何一个支持的端点 IP 上。由于 kube-proxy 是一个控制器,它观察状态变化,并在任何修改后调整到适当的状态。 :::
如果我们看一下集群中已经定义的服务,我们就可以了解到 kube-proxy 在幕后是如何工作的:
$ kubectl get svc -n kube-system kubernetes-dashboardNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEkubernetes-dashboard ClusterIP 10.104.154.139 <none> 443/TCP 40d$ kubectl get ep -n kube-system kubernetes-dashboardNAME ENDPOINTS AGEkubernetes-dashboard 192.168.63.200:8443,192.168.63.201:8443 40d$ sudo iptables-save | grep KUBE | grep "kubernetes-dashboard"-A KUBE-SEP-3HWS5OGCGRHMJ23K -s 192.168.63.201/32 -m comment --comment \"kube-system/kubernetes-dashboard:" -j KUBE-MARK-MASQ-A KUBE-SEP-3HWS5OGCGRHMJ23K -p tcp -m comment --comment \"kube-system/kubernetes-dashboard:" -m tcp -j DNAT \--to-destination 192.168.63.201:8443-A KUBE-SEP-XWHZMKM53W55IFOX -s 192.168.63.200/32 -m comment --comment \"kube-system/kubernetes-dashboard:" -j KUBE-MARK-MASQ-A KUBE-SEP-XWHZMKM53W55IFOX -p tcp -m comment --comment \"kube-system/kubernetes-dashboard:" -m tcp -j DNAT \--to-destination 192.168.63.200:8443-A KUBE-SERVICES ! -s 192.168.0.0/16 -d 10.104.154.139/32 -p tcp -m comment \--comment "kube-system/kubernetes-dashboard: cluster IP" -m tcp --dport 443 \-j KUBE-MARK-MASQ-A KUBE-SERVICES -d 10.104.154.139/32 -p tcp -m comment --comment \"kube-system/kubernetes-dashboard: cluster IP" -m tcp --dport 443 \-j KUBE-SVC-XGLOHA7QRQ3V22RZ-A KUBE-SVC-XGLOHA7QRQ3V22RZ -m comment --comment \"kube-system/kubernetes-dashboard:" -m statistic --mode random \--probability 0.50000000000 -j KUBE-SEP-XWHZMKM53W55IFOX-A KUBE-SVC-XGLOHA7QRQ3V22RZ -m comment --comment \"kube-system/kubernetes-dashboard:" -j KUBE-SEP-3HWS5OGCGRHMJ23K
这可能有点难懂,所以我们来分析一下。在这个场景中,我们正在查看 kubernetes-dashboard ClusterIP 服务。我们看到它的 ClusterIP 为 10.104.154.139,Pod 端点为 192.168.63.200:8443 和 192.168.63.201:8443。在这里,kube-proxy 创建了一些 iptables 规则来反映每个节点的这种状态。这些规则实际上是说,任何来自 Pod CIDR (192.168.0.0/16)的数据包,如果目的地是 TCP 端口 443 上的 dashboard ClusterIP (10.104.154.139/32),就应该随机重定向到容器端口 8443 上托管 dashboard 容器的下游 Pod 之一。
这样一来,每个节点上的每个 Pod 都能通过 kube-proxy 守护进程对 iptables 规则的操作,与定义的 Service 进行通信。
:::info iptables 是业内最常见的实现。在 Kubernetes 1.9 中,增加了一个新的 IP 虚拟服务器(IPVS)实现。这不仅性能更强,而且还提供了多种可以利用的负载均衡算法。 :::
服务发现
在任何存在高度动态进程调度的环境中,我们都希望有一种手段能够可靠地发现服务端点的位置。许多集群技术都是如此,Kubernetes 也不例外。幸运的是,有了 Service 资源,我们就有了一个很好的地方,可以从中实现 Service 发现。
DNS
在 Kubernetes 中发现服务的最常见方式是通过 DNS。虽然 Kubernetes 组件本身没有原生的 DNS 控制器,但可以利用一些附加控制器为 Service 资源提供 DNS 记录。
在这个领域,部署最广泛的两个附加组件是由社区维护的 KubeDNS 和 CoreDNS 控制器。这些控制器从 API Server 观察 Pod 和 Service 状态,进而自动定义一些不同的 DNS 记录。这两个控制器的区别主要在于实现 — CoreDNS 控制器使用 CoreDNS 作为实现,而 KubeDNS 则利用 dnsmasq。
每个 Service 在创建后,都会得到一个与虚拟 Service IP 相关联的 DNS A 记录,其形式为 <service name>.<namespace>.svc.cluster.local:
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 35d
# kubectl run --image=alpine dns-test -it -- /bin/sh
If you dont see a command prompt, try pressing enter.
/ # nslookup kubernetes
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
对于无头服务(Headless Service),记录略有不同:
# kubectl run --image=alpine headless-test -it -- /bin/sh
If you dont see a command prompt, try pressing enter.
/ # nslookup kube-headless
Name: kube-headless
Address 1: 192.168.136.154 ip-192-168-136-154.ec2.internal
Address 2: 192.168.241.42 ip-192-168-241-42.ec2.internal
在这种情况下,用户看到的不是服务 ClusterIP 的 A 记录,而是一个 A 记录的列表,用户可以酌情使用。
:::info
无头服务是指 clusterIP=None 的 ClusterIP 服务。当你想定义一个服务,但又不要求它由 kube-proxy 管理时,就可以使用这些服务。由于您仍然可以访问服务的端点,如果您想实现自己的服务发现机制,您可以利用这一点。
:::
环境变量
除了 DNS 之外,还有一个不太常用的功能,但还是要注意的是使用自动注入的环境变量进行服务发现。当 Pod 启动时,描述当前命名空间中 ClusterIP 服务的变量集合将被添加到进程环境中。
# kubectl get svc test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test ClusterIP 10.102.163.244 <none> 8080/TCP 9m
TEST_SERVICE_PORT_8080_8080=8080
TEST_SERVICE_HOST=10.102.163.244
TEST_PORT_8080_TCP_ADDR=10.102.163.244
TEST_PORT_8080_TCP_PORT=8080
TEST_PORT_8080_TCP_PROTO=tcp
TEST_SERVICE_PORT=8080
TEST_PORT=tcp://10.102.163.244:8080
TEST_PORT_8080_TCP=tcp://10.102.163.244:8080
:::warning 这种机制可以在没有 DNS 功能的情况下使用,但有一个重要的注意事项要记住。因为进程环境是在 Pod 启动时填充的,使用此方法的任何服务发现都需要在 Pod 启动前定义必要的服务资源。此方法不考虑 Pod 启动后对服务的任何更新。 :::
网络策略
无论是否使用 Kubernetes,确保用户工作负载安全的一个关键方面涉及确保服务只暴露给适当的消费者。例如,如果你正在开发一个需要数据库后端的 API,典型的部署模式将是只将 API 端点暴露给外部消费者。对数据库的访问只能从 API 服务本身进行。这种在 OSI 模型第 3 层和第 4 层的服务隔离有助于确保限制攻击的表面区域。传统上,这些类型的限制是通过某种类型的防火墙来实现的,在 Linux 系统上,这种策略通常是通过 IPTables 来执行的。
IPTables 规则,在正常情况下,只能由服务器管理员操纵,并且是在其执行的节点上的本地规则。这对于那些希望拥有自服务能力来保障服务安全的 Kubernetes 用户来说,带来了一点问题。
幸运的是,Kubernetes 提供了 NetworkPolicy 资源,供用户定义与自己工作负载相关的第 3 层和第 4 层规则。NetworkPolicy 资源提供了入口和出口规则,可以应用于命名空间、Pod,甚至是普通的 CIDR 块。
:::info 请注意,NetworkPolicy 只能在 CNI 插件支持该功能的环境中定义。Kubernetes API Server 会很乐意接受你的 NetworkPolicy 声明,但由于没有控制器来协调声明的状态,所以不会颁布任何策略。例如,Flannel 可以为 Pod 与 Pod 之间的通信提供一个覆盖网络,但它不包括策略代理。出于这个原因,许多希望 Flannel 的覆盖功能与 NetworkPolicy 能力的人都转向了 Canal,它将 Flannel 的覆盖功能与 Calico 的策略引擎相结合。 :::
一个典型的 NetworkPolicy 清单可能看起来像这样:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: backend-policy
namespace: api-backend
spec:
podSelector:
matchLabels:
role: db
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
project: api-midtier
- podSelector:
matchLabels:
role: api-management
ports:
- protocol: TCP
port: 3306
egress:
- to:
- ipBlock:
cidr: 10.3.4.5/32
ports:
- protocol: TCP
port: 22
阅读和制作这些 NetworkPolicy 资源可能需要一点时间来适应,但是一旦你掌握了模式,这可以成为一个非常强大的工具供你使用。
在这个例子中,我们正在声明一个策略,它将被放置在 api-backend Namespace中所有带有 role=db 标签的 Pod 上。入口规则允许流量从带有 project=api-midtier 标签的 Namespace 或带有 role=api-management 标签的 Pod 进入 3306 端口。此外,我们限制了从 role=db Pod 到 10.3.4.5 的 SSH 服务器的出站流量,或者说出站流量。也许我们会用这个来进行 rsync 备份到外部可用的位置。
虽然这些规则比较特殊,但我们也可以为任何给定的 Namespace 创建广泛的允许全部或拒绝全部策略,包括入口和出口流量。例如,下面的策略(也许是最有趣的)为一个 Namespace 创建了一个默认的拒绝入口策略:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
- Ingress
:::info 需要注意的是,默认情况下,对 Pod 没有网络限制。只有通过 NetworkPolicy,我们才能开始锁定 Pod 的互联性。 :::
服务网格
理解工作负载之间的网络流可以是一项复杂的工作。在最简单的情况下,一个单一的 Pod 副本与一个容器是由 Service 资源前置的。在这种情况下,我们只需要通过查看容器的应用日志来分析流量的来源。
然而,在微服务环境中,通常典型的情况是,流量通过 Ingress 进入集群,Ingress 由 Service 支持,Service 再由任意数量的 Pod 复制支持。此外,这些 Pod 本身也可能连接到其他集群服务和各自的支持 Pod。正如你可能看到的,这些流程很快就变得错综复杂,这就是服务网格解决方案可能会有帮助的地方。
服务网格简单来说就是一个 “智能” 代理的集合,可以帮助用户满足各种东西向或 Pod 对 Pod 的网络需求。这些代理可以作为应用 Pod 中的Sidecar 容器运行,也可以作为 DaemonSet 运行,它们是节点本地的基础设施组件,可以被特定节点上的任何一个 Pod 利用。只需配置您的 Pod 将其流量代理到这些服务网格代理(通常使用环境变量),您的 Pod 现在是网状的一部分。
:::info 你是以 Sidecar 还是 DaemonSet 的形式部署,通常由你选择的服务网格技术和/或集群上的资源可用性决定。由于这些代理以 Pod 的形式运行,它们确实会消耗集群资源,因此,您需要决定这些资源是否应该共享或与 Pod 关联。 :::
服务网格解决方案通常提供共同的功能:
- 流量管理:大多数服务网状解决方案包括一些针对驱动特定服务的传入请求的功能。这可以实现诸如金丝雀和蓝/绿部署等高级模式。此外,一些解决方案是协议感知的。它们不是作为一个 “哑巴 “的第 4 层代理,而是有能力反省更高级别的协议,并做出智能的代理决策。例如,如果某个上游对 HTTP 请求的响应速度较慢,那么代理可以将该后端的权重低于响应的上游。
- 可观察性:当将微服务部署到 Kubernetes 集群时,Pod 之间的互联性会很快变得难以理解。随着越来越多的 Pod 之间相互通信,你应该如何调试用户报告的连接性问题?如何找到响应缓慢的应用?大多数服务网格解决方案都提供了分布式跟踪的自动机制(通常基于 OpenTracing 标准)。以一种透明的方式,您可以唯一地跟踪单个请求的流向。
- 安全性:在底层网络不提供默认加密的环境中(这对于大多数 CNI 插件来说很常见),服务网格可以通过为所有东西向流量提供相互 TLS 进行干预。这可能是有利的,因为政策可能会被强制执行,从而使所有连接在默认情况下是安全的。
Istio、Linkerd 和 Conduit 等项目是常用的服务网格解决方案。如果刚才提到的功能符合你的用例,可以考虑一下这些项目。
总结
任何分布式系统中的网络总是很复杂。Kubernetes 通过在 OSI 网络堆栈的多个层次上提供精心构思的抽象来简化这一关键能力。通常情况下,这些抽象是通过经过试验和测试的网络技术实现的,这些技术已经被可靠地利用了几十年。然而,由于这些抽象旨在为功能提供一个通用接口,因此作为集群管理员,您可以自由利用最适合您需求的实现。当将您的应用程序的网络要求与其部署清单结合起来时,部署复杂、稳定和安全的应用程序架构就会容易得多。

若有收获,就点个赞吧
0 人点赞
