状态管理是应用程序设计中的一个重要话题。从文件访问到关系数据库到键/值存储,大多数应用程序都需要以这种或那种方式处理状态。云中的状态管理带来了它自己独特的挑战,我们将在本章中讨论。Dapr 状态管理旨在提供一个简单的状态 API,帮助你处理这些挑战,同时编写干净的、与平台无关的状态处理代码。
状态管理
拨打客户服务热线可能是一个痛苦的经历 —— 你在线路上等待数十分钟,你花更多时间解释你的情况,你躲避所有旨在阻止你取消订单或订阅的剧本动作,然后电话断开。在又一次漫长的等待之后,你终于被重新连接上了,然后你需要和一个新的代理重新开始。
当你打电话时,一些客户服务部门首先打开一个案件。如果电话被切断,你可以重新连接并继续你的工作,因为新的客服人员会对之前的电话发生的情况有一些了解。这往往仍然是一个乏味的经历,但能够恢复而不是重新开始绝对是一个进步。
在一个复杂的交易过程中,支持案例编号作为一个持久的记录。当交易由多个代理处理时,交易状态由案例编号来延续。这是一个有状态的服务的行为,这也是本章的重点。
无状态 vs. 有状态
网络服务可以被分为两大类:无状态和有状态。无状态的服务在请求之间不维护上下文信息。例如,通过搜索引擎进行的搜索是一个独立的请求。搜索引擎所需要的只是搜索模式;它不需要任何额外的上下文信息来进行搜索。如果你在发出搜索后被断开连接,你需要在重新连接时重新提交搜索查询,因为搜索引擎并不记得你以前的搜索。
一个有状态的服务在一个可能跨越多个请求的事务中维护上下文信息。例如,当你向你的在线购物车添加物品时,网络服务器会跟踪你的购物车中的物品,这样你就可以继续购物,并在以后检查出所有物品。
区分有状态服务和无状态服务的另一个方法是状态被保存的地方。一个保存状态的服务不一定是有状态的服务。例如,考虑一个更新学生记录数据库的学生记录管理系统。每个 CRUD(创建、读取、更新、删除)操作都是一个独立的请求;如果一个操作在中途失败,你需要重新提交请求。然而,如果服务维护了计算节点本身的上下文信息,它就变成了有状态的。
在本章的其余部分,我们将把在计算节点上保存状态的服务视为有状态服务。我们使用这个定义是因为在计算节点上托管一个具有本地状态的服务与托管一个无状态的服务是完全不同的。
为什么无状态服务在云中更受青睐?
许多云平台对无状态服务有强烈的偏好。这是因为无状态服务自然符合云计算的特点。
伸缩一个无状态服务
一个搜索引擎是由成千上万的后台服务器支持的。当一个请求被发出时,它要经过一个负载平衡器,并被路由到这些服务器中的任何一个。哪个服务器最终处理该请求并不重要,因为处理该请求所需的一切都由该请求本身携带。拥有多个服务器来分担工作负荷被称为扩展,这是在云中扩展的主要手段。
:::info 企业内部系统通常通过扩大规模来(Scale up)进行扩展,这涉及到增加现有服务器的容量以匹配增加的工作量。 :::
在云计算中,扩大规模并没有理论上的限制。如果你需要(并且负担得起),你可以扩展到数千台服务器,当你不再需要那么多服务器时,你也可以将其缩减。能够在任何时候扩展和退出被称为弹性(Elasticity),它是云计算相对于内部数据中心的最大价值主张之一。
无状态服务通常可以利用多层次的缓存,如内容交付网络(CDN)和服务器端的缓存。回到搜索引擎的例子,搜索引擎可以缓存流行的搜索结果,这样它就不需要回到后端数据库去检索它们。对于一个重读系统,缓存可以极大地提高可扩展性和性能。
无状态服务的可用性
云平台使用商品服务器,与你在企业内部数据中心的高端服务器相比,它们的故障概率更高。由于云中的服务器数量庞大,有些服务器会仅仅因为概率问题而失败 —— 失败的服务器可能是处理你的工作负载的服务器。因此,人们说,在云中,失败是常态,你必须接受失败。处理这种失败的最简单方法是有备份。
负载平衡器后面的服务器作为彼此的备份。当一台服务器发生故障时,它被从负载平衡器上取下进行修复,而其他服务器则继续为用户请求提供服务。当你在负载平衡器后面增加一个新的服务器时,你有效地在你的服务可用性上增加了一个 “9”。假设你有两台相同的服务器,每台服务器的可用性为 90%。把它们连接到负载平衡器后面,就可以得到 99% 的可用性,而增加第三个服务器就可以得到 99.9% 的可用性。
Serverless
由于哪台物理服务器最终会处理一个请求并不重要,因此作为一个应用编写者,你不需要关心这些服务器在哪里以及如何托管。如果你能保证在任何时候都有所需的计算和存储能力,你就根本不需要担心底层的基础设施,这就是无服务器的承诺。为了以可持续的方式实现这一承诺,云平台需要在其可用资源上有效地分配工作负载。调度无状态服务要比调度有状态服务容易得多,这一点我们稍后会看到。因此,许多无服务器平台只支持无状态服务。
托管有状态服务的挑战
托管有状态服务带来了一些实际的挑战。因为一个有状态的服务在一个可能跨越多个请求的事务中持有上下文信息,一个事务中的所有请求都需要只由持有该上下文状态的服务器来处理,以确保一致性。这种限制给工作负载调度带来了额外的状态管理复杂性,使得大规模托管有状态服务成为一项更加困难的任务。
有状态的服务可用性
当一个服务器发生故障时,它将失去它在内存中持有的上下文信息。即使服务器在其本地磁盘上持有状态,当它发生故障时,其他服务器将无法从它那里检索到状态。为了确保有状态的服务可用性,状态需要被复制到多个服务器上,这样当一个服务器发生故障时,其他服务器可以使用自己的状态副本继续进行交易。
为了实现这种状态复制,我们需要解决几个问题。首先,我们需要想出一个策略来挑选参与复制的服务器。一个常见的做法是挑选一些服务器来组成一个复制集。只要复制集中的法定人数(通常是一个奇数的子集)对状态的组成有共识,状态就是可用的。当我们做出选择时,我们必须考虑这些服务器的负载,以避免某些服务器过载。我们可能还想确保这些服务器相隔足够远(比如在不同的服务器机架上,或者在不同的故障域中),以便它们不太可能一起故障。在我们做出最初的选择后,我们仍然需要实现额外的机制来动态地调整我们的选择。例如,当一个副本集的规模低于最低要求的法定规模时,因为有太多的服务器不可用,我们需要招募新的服务器并将它们加入到副本集中。
第二,我们需要决定一个复制策略。如果我们使用强一致性模型,每一个状态的更新在提交之前都需要经过法定人数成员的确认。这就拖慢了系统的速度。或者,我们可以使用最终一致性模型,在这种模型中,复制是异步发生的。在这样的模型中,用户请求被路由到一个主服务器,其状态服务器被周期性地复制到辅助服务器。如果主服务器发生故障,一个辅助服务器会被提升到主服务器的位置。由于状态复制是异步的,当主服务器故障时,任何正在运行的请求都会丢失,系统状态将恢复到以前的状态,用恢复点目标(RPO,Recovery Point Objective)衡量。在没有集中式协调器的情况下,选择一个主站是很棘手的。当多个成员意外地同时被选为主站时(例如由于网络分区),我们就会出现 “脑裂” 的情况,可能会导致状态损坏等问题。
最后但并非最不重要的是,由于服务器将同时为多个租户和多个并发事务提供服务,我们必须确保这些事务是相互隔离的,这既是为了安全也是为了性能。例如,交易的复制应该独立进行,这样一个复杂的交易就不会拖累其他交易。另外,一个租户不应该能够偷看其他租户的交易,无论是意外还是故意。这就要求对状态数据进行细粒度的访问控制,一直到事务级别。
现在应该很明显,确保有状态服务的可用性是一个比确保无状态服务的可用性复杂得多的问题。事实上,有效的状态复制和领导者选举是最困难的分布式计算问题之一。
伸缩有状态服务
与无状态服务不同,有状态服务要求事务中的所有请求都被路由到同一个副本集。因此,有状态服务的负载均衡器不能盲目地将请求分配给所有可用的服务器。相反,它必须记住哪些请求属于哪些副本集。当一个有状态的服务被扩展时,它通常被分割成不同的分区(Partition)。一个复制集被限制在一个分区里。当系统需要为一个副本集招募一个新的服务器时,它只在同一分区的服务器中搜索。这使得复制集的管理更加有效,特别是在大型集群中。
我们可以选择一些分区策略,包括静态和动态的。按区域 ID 分区是静态分区的一个例子,按一致哈希分区是动态分区的一个例子。动态分区可以随着可用服务器数量的变化而调整。当一个新的服务器加入集群时,分区被重新分配以利用额外的容量;当集群缩小时,分区被压缩到剩余的资源中。
当使用分区时,分区 ID 可以被计入请求路径以协助路由。例如,到一个分区的 foo 服务的请求路径可能看起来像:https://<host>/<partition>/foo。
这种路由方案要求负载均衡器支持分区路由。如果负载均衡器不支持分区路由,可能会出现额外的一跳。例如,如果一个打算给分区 A 的请求被路由到分区 B 的服务器,该服务器需要将请求转发到分区 A 的服务器。
分区上的工作量可能变得不平衡。当一些繁忙的分区被请求压得喘不过气来时,其他空闲的分区就会保持休眠状态,从而浪费了计算资源。一些先进的调度器支持资源平衡,它动态地重新安排服务器节点上的分区,使服务器的负载均匀。不过,移动一个分区是很昂贵的,因为它必须带着它的状态数据。因此,调度器必须在减少移动次数和保持服务器之间的资源消耗平衡之间找到一个平衡。
关键是,扩展有状态的服务也很难。
将有状态服务转换为无状态服务
将有状态的服务转换为无状态的服务是很简单的,你只需要将状态外部化到一个单独的数据存储中,比如一个复制的数据库。使用外部状态存储对系统性能有不利的影响,因为所有的状态操作都变成了远程调用,这比本地状态操作慢了好几个数量级。然而,在现代网络中,除非系统对增加的响应时间极为敏感,否则这种延迟通常是可以容忍的。
图 2-1 说明了如何通过外部化状态将有状态服务转换为无状态服务。左边的是一个由三个实例组成的有状态服务。每个实例在本地提交状态,状态在集群中被复制和协调。在右边,状态被转移到一个外部状态存储中,它被复制到多个副本中以获得高可用性。实例可以持有本地缓存以提高性能,有不同的缓存更新策略,如穿透写(Write-through)、环绕写(Write-around)和回写(Write-back)。
图 2-1. 有状态的服务(左)与有状态的无状态服务(右)对比
右边的架构比左边的架构更复杂,而且通常性能较差。然而,这种设计的一个主要好处是,服务实例变得无状态,因此在云中更容易管理。
Dapr 状态管理
Dapr 通过一个可靠的状态端点为服务带来状态管理。这允许将有状态的服务转变为无状态的服务,正如我们所看到的,这更容易管理。开发者可以通过一个简单的 Dapr 状态 API 来保存和检索状态。Dapr 支持一个可插拔的架构,允许用户服务与不同的状态存储绑定,如 Redis、Azure Cosmos DB、Cassandra、AWS DynamoDB 和 Google Cloud Spanner。
并发模型
Dapr 兼容的状态存储需要使用 ETag 来支持乐观的并发性。当一个状态项被检索时,它与一个 ETag 相关联。当一个服务实例试图更新状态项时,新更新的状态项必须在数据存储中带有相同的 ETag。乐观的并发性假设,对状态存储的大多数更新可以独立进行,因为通常有一个特定状态项的单一突变器。当多个服务实例试图更新同一个状态项时,第一个写入者将获胜,因为它持有匹配的 ETag。其他的更新尝试将会失败,而这些服务实例将需要检索最新的状态并再次尝试。如果客户端省略了 ETag,状态存储应该恢复到最后写入获胜(Last Write Win),这意味着最后收到的写入请求取代了以前的请求。
一致性模式
Dapr 要求状态存储默认支持最终一致性。一个状态存储也可以选择支持强一致性写入。例如,默认的 Dapr Redis 状态存储实现使用最终一致性。然而,如果客户端发送了一个带有强一致性标志的请求,Dapr 会等待,直到所有的副本都确认了写入请求,才会转向调用者。
为了编写旨在与多个数据存储一起工作的应用程序,你应该假设状态存储支持最终一致性。一些框架喜欢强一致性,因为强一致性更容易推理。然而,我们认为最终一致性对分布式系统来说更自然,而且它已被广泛采用。因此,Dapr 选择了最终一致性作为默认行为。
批量操作和事务
Dapr 要求数据存储确保单个插入、更新或删除操作的事务性隔离。Dapr 状态 API 也定义了批量读取、批量删除和批量更新操作,但它并没有强制要求这些操作作为一个单一的事务来处理。
Dapr 定义了一个单独的事务性存储接口,该接口支持将多个数据库操作作为独立的事务处理。一个支持事务性存储接口的存储被称为事务性状态存储。交易状态存储需要支持行为者编程模型(详见 第 5 章)。
多个状态存储
Dapr 支持同一集群上的多个状态存储。每个存储由一个存储名称来标识,并被配置为 Dapr 组件。例如,当你写一个数字音乐库时,你可以把专辑信息保存在 Cosmos DB 中,而把实际的音频文件保存在 Blob 存储中。在撰写本文时,Dapr 不支持跨多个状态存储的转换操作。你的应用程序应该使用一个单一的状态存储作为单一的事实来源,并使用其他存储来保存相关数据。
重试策略
Dapr 有一个简单的重试库,可以根据线性重试策略或指数回退重试策略自动重试失败的操作。重试策略包含一个时间间隔和一个最大阈值。一个数据操作在给定的时间间隔内被重试,直到达到最大重试阈值。一个线性重试策略有固定的时间间隔。指数重试策略有指数增长的间隔,定义为 间隔i = 初始间隔 × 2i,其中 间隔i 是数据操作第 1 次尝试后的间隔。
Dapr 状态 API
Dapr 定义了一个基于键/值范式的简单状态 API,如下面的代码片段所示:
type Store interface {Init(metadata Metadata) errorDelete(req *DeleteRequest) errorBulkDelete(req []DeleteRequest) errorGet(req *GetRequest) (*GetResponse, error)Set(req *SetRequest) errorBulkSet(req []SetRequest) error}
一个事务状态存储实现了一个额外的 TransactionalStore 接口:
type TransactionalStore interface {Init(metadata Metadata) errorMulti(reqs []TransactionalRequest) error}
你可以给每个请求附加额外的选项。Dapr 为每个操作定义了一些预定义的属性。它还允许在请求中附加一个键/值图,并将其原封不动地传递给底层数据存储。这种设计允许数据存储在基本 API 的基础上提供额外的功能。然而,当你利用存储的特定属性时,你的代码在不同的状态存储中的可移植性就会降低。
Dapr 要求数据存储在最佳尝试的基础上实现附加的操作。因此,使用任何附加选项都可能影响你的应用程序的可移植性。你应该参考存储的实现细节来做出选择。
键结构
所有的状态存储都应该遵循相同的密钥方案。对于一般状态,键的格式是 <Dapr ID>||<state key>。对于行为者状态,键的格式是 <App ID>||<Actor type>||<Actor ID>||<state key>。当你调用 Dapr 状态 API 时,你提供了状态键。Dapr 会自动把 Dapr 的 ID 加在前面。例如,发送至 Dapr ID dapr1 的状态请求和状态键 mystate 使用 dapr1||mystate 作为实际密钥来访问底层状态存储。
Get 请求
获取请求有一个一致性选项,其值可以是最终的,也可以是强的。一些状态存储,如 Azure Cosmos DB,支持一致性读取,这意味着从任何数据库服务中的任何读取都能保证反映最新提交的写入。
Dapr 状态存储返回一个带有 Data 属性和 ETag 属性的响应。前者包含实际数据,后者包含相应的 ETag。Dapr 并没有定义一个规范的 ETag 格式。当你把一个数据元素从一个存储空间迁移到另一个存储空间时,你应该把写到第二个存储空间当作一个新的没有 ETag 的 Set 请求。
如果没有找到请求的密钥,Dapr 会返回一个 204 响应。如果状态存储丢失或配置错误,它会返回 400,如果数据库服务器有任何其他意外的错误,它会返回 500。
要通过 Dapr 发送一个 Get 请求,你要向 http://local:<Dapr port>/v1.0/state/<state store name>/<key>—— 例如:http://localhost:3600/v1.0/state/mystatestore/key-1。
Set 请求
一个 Set 请求由以下字段组成:
key:要更新的值的键。value:新的数据值。etag:与该值相关的已知 ETag。这个 ETag 是由以前的 Get 请求返回的。options:包括以下选项。concurrency:first-write或last-writeconsistency:eventual或strongretryPolicy:一个重试策略,由inteval、threshold和pattern组成;pattern可以是linear或exponential。
:::info 你可能已经注意到,Dapr 没有定义一个插入操作。这是因为在一个分布式系统中,每个插入操作都应该是一个 Upsert 操作,它根据给定的键是否存在来执行事务性的插入或更新。 :::
你可以通过 BulkSet 方法执行批量设置操作。如前所述,批量操作不是作为一个孤立的事务来处理的,这意味着它可能部分地成功。不过,你可以给批量操作附加一个重试策略。
要通过 Dapr 发送一个 Set 请求,请将一个键/值对的 JSON 数组发送到 http://localhost:<Dapr port>/v1.0/state/<state store name>。
Delete 请求
删除请求和批量删除请求与设置请求类似,除了并发选项,在这种情况下并不相关。
要通过 Dapr 发送一个删除请求,请发送一个 DELETE 请求到 http://localhost:<Dapr port>/v1.0/state/<state store name>/<key>。请求头可以选择包含一个 If-Match 头,其中包含已知的 ETag。
事务请求
你可以向事务性状态存储提交事务性请求。该请求是一个上移操作或删除操作的列表。在一个事务性请求中的所有操作作为一个整体成功或失败 —— 要么所有操作都被执行,要么没有操作被执行。在写这篇文章的时候,你不能把重试策略附加到一个事务性请求上。
使用 Dapr 状态 API 工作
使用 Dapr 状态 API 的工作是直接的,如下面更新订单状态的 Node.js 示例代码所示:
const state = [{ key: "order", value: data }];fetch("http://localhost:3500/v1.0/state/statestore", {method: "POST",body: JSON.stringify(state),headers: {"Content-Type": "application/json"}}).then((response) => {if (!response.ok) {throw "Failed to persist state.";}});
图 2-2 显示了使用 Dapr 状态 API 的数据流。读取和设置状态是通过 Dapr 端点的简单 HTTP 调用完成的。
图 2-2. 使用 Dapr 状态 API
Dapr 状态 API 是一个非常简单的面向键/值的 API。我们(和社区)根据反馈和客户的要求,对包括或不包括的功能做了一些选择。本节涵盖了一些 Dapr 状态 API 不提供的功能,但可以通过其他方式实现。
数据处理方面的考虑
Dapr 并不执行数据转换、加密或压缩。你有两个选择来实现这些:通过一个自定义的数据存储实现或通过一个自定义的中间件。自定义中间件可能是最好的选择,因为它可以在不同的数据存储中执行一致的操作 —— 而且有可能在你阅读这篇文章时,一些这样的中间件实现已经可用。需要注意的一点是,在这种情况下,你的自定义中间件应该只响应与状态相关的路由。
:::tips 由于中间件是一个 Dapr 组件,你可以在你的中间件描述文件中使用密码参考。这允许你安全地存储你的秘密,如加密密钥在你喜欢的密码存储。我们将在 第 4 章 中更详细地讨论安全性。 :::
Dapr 并不限制数据的大小。然而,每个数据存储都有自己的限制和对其存储数据的约束。一个数据存储可能也会对每个时间单位的请求数施加速率限制。Dapr 并不处理这些差异。这取决于开发人员是否能适应特定数据存储的限制。
Dapr 使用一个简单的字符串键。为了支持分区,你可以配置多个状态存储,每个都指向一个不同的分区。例如,你可以为 Azure Cosmos DB 的不同集合配置不同的状态存储连接,或者为 Amazon S3 的不同桶配置不同的状态存储连接。独立的状态存储对静态分区很有用。对于动态分区,你可以使用一个自定义的存储实现或一个自定义的中间件来实现你的分区逻辑。
Dapr 不支持对一个值的部分更新。新的值需要被完整地发布,以便更新它的任何部分。你需要使用一个自定义的状态存储或中间件来支持通过提交差值来更新数据。
数据查询和聚合
许多客户 —— 尤其是物联网客户 —— 都表示需要在许多键上运行灵活的查询和聚合。在写这篇文章的时候,我们还在争论 Dapr 应该提供什么样的查询 API 或聚合 API。然而,Dapr 的状态存储设计的一个好处是,它不使用专有的状态格式。你可以直接在后端状态存储上操作,实现复杂的查询和聚合。
对后端存储的只读访问通常是安全的。但是直接通过状态存储突变数据可能是危险的。你的代码需要以 Dapr 维护 ETag 的方式来维护 ETag,否则 Dapr 可能会感到困惑并拒绝合法的更新请求。建议你在后端存储上应用适当的 RBAC,以避免来自未经授权的应用程序或用户的意外更新。
状态存储
Dapr 最初与两个状态存储一起发货。Redis 和 Azure Cosmos DB。自从最初公布以来,社区已经贡献了许多其他的状态存储,包括:
- HashiCorp Consul
- Etcd
- Cassandra
- Memcached
- MongoDB
- ZooKeeper
- Google Cloud Firestore
- AWS DynamoDB
- Couchbase
在写这篇文章的时候,更多的状态存储正在实现中。本节提供了关于一些可用的状态存储的额外细节。我们希望这些信息在你尝试实现你自己的 Dapr 兼容的状态存储时是有帮助的。
Redis
Redis 是一个内存数据结构存储。它提供了一个在集群上的存储解决方案,在性能和可靠性之间有一个很好的平衡,而且它很容易配置。这就是为什么 Redis 是 Dapr 的默认状态存储。
Dapr 使用哈希值(Hash)而不是集合(Set)来保存数据。使用哈希值的主要原因是将一个数据元素及其相关的 ETag 作为一个单元。在撰写本文时,Redis 并不支持 ETag,所以 Dapr 使用一个不断递增的版本号作为 ETag。为了确保数据元素的更新和 ETag 的维护被当作一个单一的事务来处理,Dapr 使用 Lua 脚本来执行所有的 Set 和 Delete 请求,因为 Redis 在一个单一的事务中执行 Lua 脚本的所有命令。例如,下面的 Lua 脚本被用来更新一个键:
local var1 = redis.pcall("HGET", KEYS[1], "version");if type(var1) == "table" thenredis.call("DEL", KEYS[1]);end;if not var1 or type(var1) == "table" orvar1 == "" or var1 == ARGV[1] or ARGV[1] == "0" thenredis.call("HSET", KEYS[1], "data", ARGV[2])return redis.call("HINCRBY", KEYS[1], "version", 1)elsereturn error("failed to set key " .. KEYS[1])end
要查询与 Dapr ID myapp 相关的所有状态,使用这个查询:KEYS myapp*。
要从一个名为 balance 的特定键中获取数据,请使用下面的查询(注意,在这种情况下你需要在 Dapr ID 前加上前缀):HGET myapp||balance data。
要获得相关的 ETag,请使用这个:HGET myapp||balance version。
Azure Cosmos DB
Azure Cosmos DB 是一个全球分布的多模型数据库服务。它支持通过多个流行的 API 对同一数据集进行操作,包括 SQL、MongoDB、Cassandra、Gremlin 等。
Dapr 使用 Cosmos DB 的 SQL API 来保存状态数据。一个 Cosmos DB 状态存储是为 Cosmos DB 数据库上的一个特定集合而建立的。要使用多个集合,你需要为每个集合定义一个单独的状态存储。
要查询与Dapr ID myapp 相关的所有状态,使用这个 SQL 查询(假设 Cosmos DB 集合被命名为 states):
SELECT * FROM states WHERE CONTAINS(states.id, 'myapp||')
要从一个名为 balance的特定键中获取数据,请使用以下查询:
SELECT * FROM states WHERE states.id = 'myapp||balance'
为了获得 ETag,请使用系统的 _etag 列:
SELECT states._etag FROM states WHERE states.id = 'myapp||balance'
你也可以使用 Cosmos DB 的聚合函数来执行更高级的查询。例如,下面的查询计算了 states集合中所有值的总和(假设数据被保存在一个 value域中):
SELECT VALUE SUM(s.value) FROM states s
此外,你可以使用支持 Cosmos DB 的各种数据可视化和分析工具。例如,你可以使用 Power BI Cosmos DB 连接器,在 Power BI 中导入和可视化你的状态数据。
因为 Cosmos DB 是一个全球分布的数据存储,你可以利用它来部署全球分布的有状态服务。例如,图 2-3 显示了一个部署在多个 Azure 区域的服务。服务实例在 Azure 流量管理器后面连接起来,根据与最终用户的距离或到该地区的延迟等指标,将用户路由到不同的地区。因为在这种情况下,两个 Dapr 实例共享相同的 ID,它们可以各自读取和写入数据,就像在本地区域数据库中一样。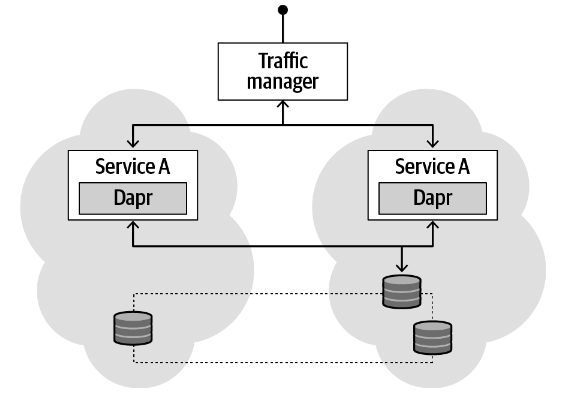
图 2-3. 使用 Cosmos DB 的全球分布式状态存储
Etcd
Etcd 是一个分布式的、可靠的键/值存储。Kubernetes 使用 etcd 作为本地状态存储。Etcd 维护多个修订的值。每个存储的键/值对都是不可改变的。对现有键的突变性操作会创建新的修订版。你可以使用修订号作为 ETags;但是,当你写回一个数据元素时,由于 etcd 没有加强版本检查,你需要使用 txn 命令,或者在你的客户端代码中 —— 比如在 Dapr 状态存储实现中 —— 完成这个工作。因为这个检查和下面的突变在没有附加锁机制的情况下不是事务性的,而锁往往对系统性能有负面影响,所以在编写本文时,公认的 etcd 存储实现不对更新进行 ETag 检查,如下面代码所示:
func (r *ETCD) Set(req *state.SetRequest) error {ctx, cancelFn := context.WithTimeout(context.Background(), r.operationTimeout)defer cancelFn()var vStr stringb, ok := req.Value.([]byte)if ok {vStr = string(b)} else {vStr, _ = r.json.MarshalToString(req.Value)}_, err := r.client.Put(ctx, req.Key, vStr)if err != nil {return err}return nil}
所以,严格来说,现有的实现并不完整。这个问题在 components-contrib 仓库中被问题号 #169 跟踪。请查看该问题的状态,了解最新的细节。你可以使用 etcd 的命令行工具 etcdctl 来查询你的 etcd 存储。要查询与 Dapr ID myapp 相关的所有状态,请使用以下命令(假设 ENDPOINTS 指向 etcd 主机端点,用逗号分隔):
$ etcdctl --endpoints=$ENDPOINTS get myapp –prefix
要从一个名为 balance的特定键中获取数据,请使用以下查询:
$ etcdctl --endpoints=$ENDPOINTS get myapp||balance --print-value-only
Apache Cassandra
Cassandra 是一个可扩展的 NoSQL 数据库,具有高可用性和可靠性。它采用对等的分布式系统架构,每个节点都能接受读写请求。它使用 Gossip 协议来保持各节点之间的数据同步。
Cassandra 是一个基于列的数据库。Cassandra 中数据的最外层容器被称为键空间(Keyspace)。在一个键空间中,你可以定义列族(又称表),它是行的有序集合的容器。每一行又是一个有序的列的集合。在目前的实现中,Dapr 状态存储映射到你的 Cassandra 数据库中的一个特定表。
您可以使用 Cassandra 查询语言(CQL)对 Cassandra 数据库进行查询。例如,要在一个表中插入(或更新)一条带有键列和值列的记录,请使用以下查询:
INSERT INTO mytable (key, value) VALUES ('myapp||balance', 1000)
要想通过给定的键取回该列,请使用以下查询:
SELECT value FROM mytable WHERE key = 'myapp||balance'
而要按一个键删除一行,请使用:
DELETE FROM mytable WHERE key = 'myapp||balance'
图 2-4 显示了 Cassandra 的简化数据模型,以及在前面的例子中实体是如何被映射到 Dapr 状态的 API 结构中的。
图 2-4. Cassandra 数据模型
Couchbase
Couchbase 是一个 NoSQL 文档数据库,它支持一个完整的 REST API 来管理基于 JSON 的文档和自定义视图。它使用一种叫做 Compare and Swap(CAS)的数据结构来表示一个项目的当前状态。CAS 值的工作方式与 ETag 相同:如果用户提供的 CAS 值与当前数据库中的内容相符,则允许更新操作;否则操作失败,用户必须用最新的 CAS 值重新尝试。
Couchbase 将文档组织成桶。一个 Dapr 状态存储与一个特定的 Couchbase 桶相关联。除了 REST API 之外,Couchbase 还支持一种名为 N1QL(发音为 “nickel”)的查询语言。例如,要按 ID 查询文档,你可以使用这样的查询:
SELECT * FROM bucket1 USE KEYS myapp||balance
你可以使用 N1QL 的 ARRAY_AGG 函数来聚合整个文档的数据,或者你可以定义一个 MapReduce 视图,其中包含一个将文档投射到所需形状的 Map 函数和一个将数据聚合到一起的可选 Reduce 函数。例如,你可以使用一个内置的 _sum Reduce 函数来计算数据值的总和,这相当于以下的自定义实现:
function(key, values, rereduce) {var sum = 0;for(i=0; i < values.length; i++) {sum = sum + values[i];}return(sum);}
自定义状态存储
Dapr 状态存储是 Dapr 组件,正如你在之前的章节中所看到的,它是由组件清单描述的。
如果你没有注意到,当你使用 dapr init 命令时,Dapr CLI 会自动创建一个包含两个 YAML 文件的组件文件夹:redis.yaml,它定义了一个默认的基于 Redis 的状态存储,以及 redis_messagebus.yaml,它使用 Redis Streams 定义了一个发布/订阅主干。
一个状态存储定义包含一个名称、一个类型和一个键/值对的集合,指定连接信息和数据存储的可配置选项,如自动生成的 redis.yaml 文件所示:
apiVersion: dapr.io/v1alpha1kind: Componentmetadata:name: statestorespec:type: state.redismetadata:- name: redisHostvalue: localhost:6379- name: redisPasswordvalue: ""
一个自定义的状态存储是以同样的方式配置的。要编写一个自定义的状态存储,你要遵循编写一个自定义 Dapr 组件的一般步骤:
- 在 Dapr components-contrib 代码仓库中实现你的自定义组件;
- 更新 Dapr 运行时以注册你的自定义组件类型;
- 为您的组件创建清单文件;
- 在 Kubernetes 上运行时,将清单文件作为 CRD 定义部署到 Kubernetes,或在本地运行时将文件复制到
components文件夹; - 根据自定义组件的类型,你可能需要修改或创建一个用户的 Dapr 配置来使用该组件。对于自定义状态存储,你可以跳过这一步,因为 Dapr 会根据它们的名字自动拾取自定义状态存储。
实现状态 API
你的自定义状态存储应该放在 https://oreil.ly/TT-1v 文件夹下。为你的状态存储创建一个单独的文件夹。如果你正在使用云平台(如 Azure 或 GCP)的管理状态存储,你应该将自定义存储放在该平台的相关文件夹下。
你的存储应该实现状态存储的 API。如果它打算被用作行为者状态存储,它也需要实现事务性存储 API。下面的章节描述了这些方法的预期行为。
Init 方法
Init 方法解析了状态存储的元数据并建立了与底层存储的连接。你可以将连接或连接的客户端作为你的存储实现的私有变量进行缓存,因为 Dapr 为每个注册的状态存储创建了一个单子实例。这意味着所有对特定状态存储的请求都由同一个状态存储实例处理。如果底层状态存储使用连接池,你可能不需要缓存连接,而是应该在每次请求时建立一个新的连接。底层数据存储将从其连接池中重用一个连接来执行请求的操作。
Get 方法
Get 方法返回与请求的键相关的值。它应该返回一个 GetResponse 结构,该结构的 Data 属性包含所请求的数据,ETag 属性包含相应的 ETag。如果没有找到密钥,你应该返回一个空的 GetResponse 实例。你应该把任何意外的错误返回给 Dapr 运行时。
Set 方法
Set 方法插入或更新与请求的键相关的值。该方法应该在同一更新交易中维护相应的 ETag。你的方法应该使用 retry.go 中的 SetWithRetries 方法,重用 Dapr 重试库来处理瞬时错误。如果并发选项被设置为 state.LastWrite,你的代码应该跳过 ETag 检查。否则,如果请求所附的 ETag 与数据库中的当前 ETag 不同,代码应该拒绝该请求。
Delete 方法
删除方法从底层状态存储中删除一个键。你的代码应该执行与 Set 方法类似的 ETag 检查,并且应该使用 DeleteWithRetries 方法,以遵守附加的重试策略。
BulkDelete 和 BulkSet 方法
BulkDelete 和 BulkSet 方法分批进行删除和设置操作。然而,并不要求在一个孤立的跨行动中进行这些操作。下面的示例代码来自默认的 Redis 存储实现。
func (r *StateStore) BulkDelete(req []state.DeleteRequest) error {for _, re := range req {err := r.Delete(&re)if err != nil {return err}}return nil}
Multi 方法
为了实现一个事务性存储,你需要实现一个额外的方法,Multi,它接收多个 Set 和/或 Delete 操作,并将它们作为一个单一的事务处理。下面的代码片段来自 Redis 存储的实现。正如你所看到的,该方法将请求收集到一个数组中,并使用 Redis 客户端的 SendTransaction 方法将所有请求作为一个事务发送。
func (r *StateStore) Multi(operations []state.TransactionalRequest) error {redisReqs := []redis.Request{}for _, o := range operations {if o.Operation == state.Upsert {req := o.Request.(state.SetRequest)b, _ := r.json.Marshal(req.Value)redisReqs = append(redisReqs, redis.Req("SET", req.Key, b))} else if o.Operation == state.Delete {req := o.Request.(state.DeleteRequest)redisReqs = append(redisReqs, redis.Req("DEL", req.Key))}}_, err := r.client.SendTransaction(context.Background(), redisReqs)return err}
除了这个方法之外,你还应该定义一个 New* 方法来创建一个新的状态存储实例。这个方法在 Dapr 边车初始化时被 Dapr 的组件加载器使用。下面的代码样本也是来自默认的 Redis 实现:
func NewRedisStateStore() *StateStore {return &StateStore{json: jsoniter.ConfigFastest,}}
一旦你完成了你的代码,从 component-contribute 根目录下运行 make test,并确保在进入下一步之前事情能被编译。
更新组件注册表
在你的拉动请求被接受之前,你需要更新你的 Dapr 项目中的组件参考,以使用你的本地版本。要做到这一点,请修改 Dapr 仓库根目录下的 go.mod 文件,并添加一个替换指令,将对 github.com/dapr/components-contrib 软件包的引用重定向到你的本地文件夹。比如说:
replace github.com/dapr/components-contrib v0.0.0-20191014200624-99461da9580e => ../components-contrib
接下来,在 pkg/components/state/loader.go 修改状态存储组件加载器。
:::info
当你在其他组件类型上工作时,你需要为这些其他组件类型修改相应的组件加载器。例如,要修改发布/订阅的加载器,请修改 pkg/components/pubsub/loader.go 文件。
:::
修改 Load 方法,增加一个新的 RegisterStateStore 调用,如下所示,它注册了一个新的 foo 存储类型(注意在清单文件中,存储类型有一个 state. 前缀,所以完整的类型名称是 state.foo)。
RegisterStateStore("foo", func() state.Store {return etcd.NewFoo()})
运行 make test,以确保所有的东西都能构建,并且所有现有的测试用例仍然通过。
当你运行 make build 或 make test 时,Dapr 二进制文件会在 ./dist 文件夹下生成。你可以使用这些二进制文件进行本地测试。验证你的自定义组件是否到位的一个简单方法是启动更新的 Dapr 二进制文件:dapr run --app-id test echo "test"。
观察 Dapr 日志中的第一个条目,你会看到 Dapr 已经加载了所有发现的组件。如果你的组件没有显示在列表中,或者你观察到一些例外情况,你需要仔细检查你的组件代码和注册代码。
== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="starting Dapr Runtime -- version edge -- commit v0.3.0-rc.0-24-g5faf977-dirty"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="log level set to: info"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="standalone mode configured"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="dapr id: rust-web"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="loaded component uppercase (middleware.http.uppercase)"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="loaded component statestore (state.redis)"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="loaded component messagebus (pubsub.redis)"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="starting Dapr Runtime -- version edge -- commit v0.3.0-rc.0-24-g5faf977-dirty"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="log level set to: info"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="standalone mode configured"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="dapr id: rust-web"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="loaded component uppercase (middleware.http.uppercase)"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="loaded component statestore (state.redis)"== DAPR == time="2019-12-28T13:26:13-08:00" level=info msg="loaded component messagebus (pubsub.redis)"
为了在 Kubernetes 上测试新的二进制文件,你需要生成一个新的 Dapr Docker 镜像,并将 Dapr 重新部署到你的 Kubernetes 集群上。幸运的是,Dapr 提供了一些构建脚本来促进这一过程:
- 首先,为 Linux 构建二进制文件:
make build-linux; 然后构建 Docker 镜像:
$ export DAPR_REGISTRY=docker.io/<your Docker account>$ export DAPR_TAG=dev$ make docker-build$ make docker-push
如果你以前用 Helm 或构建脚本部署过 Dapr,请先用 Helm 将其删除:
helm delete dapr --purge;- 最后,部署新的 Dapr 构建:
make docker-deploy-k8s。
总结
Dapr 为应用程序提供了一个简单的基于键/值的状态 API 来存储状态。该 API 隐藏了底层数据存储的细节,因此操作上的问题被应用开发者抽象出来。
Dapr 使用一个模块化的架构,允许新的状态存储作为 Dapr 组件被插入。它将 Redis 作为默认的状态存储,但社区已经贡献了一个不断增长的数据存储列表,涵盖了许多流行的开源选项和云平台。
Dapr 支持不同的并发模型和一致性模型,它允许额外的元数据被附加到请求上,以利用存储的特定功能。尽管状态访问代码通常是可移植的,但在决定使用哪种状态存储时,你需要了解存储实现之间的微妙差异以及特殊存储的限制。你可以用一个自定义的中间件进一步定制状态处理,该中间件可以应用额外的数据转换,如加密/解密、压缩和规范化。
在下一章,我们将把重点转移到集成上。我们将讨论 Dapr 如何实现各种消息传递模式,你可以用它来构建松散耦合、消息驱动的微服务应用,以及你如何使用这些模式来与传统系统和其他云服务集成。

若有收获,就点个赞吧
0 人点赞
