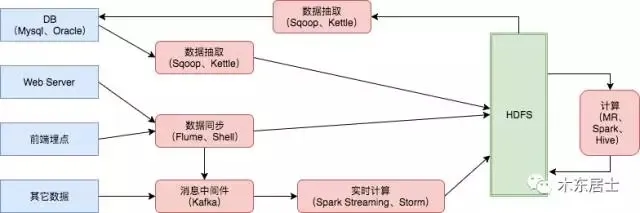
数仓的理论
- Nginx的日志 -> Flume抽取 -> 到HDFS
- MySql的数据 -> Sqoop抽取 -> 到Hive
- Hive的数据 -> Sqoop抽取 -> 到MySql
- HDFS不规整的数据 -> Hadoop/Saprk处理 -> 重新存入HDFS
- Hive表 -> Hive计算 -> 新Hive表
1和2:数据转移和转换,从一个存储引擎到另一个存储引擎。
3和4:数据的加工。
数据流
设计
分类
- 离线数据 : 一般T+1或小时级,Sqoop, Flume, MR
- 实时数据 : 一般分钟级以下,Spark Streaming, Flink
- 离线+实时 结合 : Lambda架构
实际案例
一、场景
- 数据源主要为 Mysql,希望实时同步 Mysql 数据到大数据集群中(肯定是越快越好)。
- 目前每日 20 亿数据,可遇见的一段时间后的规模是 100 亿每日以上。
能快速地查到最新的数据,这里包含两部分含义:从 Mysql 到大数据集群的速度快、从大数据集群中查询的速度要快。
二、方案选型
遇到这个场景的时候,根据经验我们主要考虑下面两个点:数据抽取引擎和存储引擎。
数据抽取引擎
这里我们主要考虑两种方案:
Sqoop 定时抽取 Mysql 数据到 HDFS 中,可以每天全量抽取一份,也可以隔段时间就抽取一份变更的数据。
- Canal 监听 Mysql 的 binlog 日志,相当于是 Mysql 有一条数据久变动,我们就抽取一条数据过来。
优缺点的对比也很明显:
- Sqoop 相对比较通用一些,不管是 Mysql 还是 PostgreSql都可以用,而且很成熟。但是实时性较差,每次相当于是启动一个 MR 的任务。
- Canal 速度很快,但是只能监听 Mysql 的日志。
存储引擎
存储引擎主要考虑 HDFS、Hbase 和 ES。
一般情况下,HDFS 我们尽量都会保存一份。主要纠结的就是 Hbase 和 ES。本来最初是想用 Hbase 来作为实时查询的,但是由于考虑到会有实时检索的需求,就暂定为ES三、方案设计
最终,我们使用了下面的方案。
- 使用 Canal 来实时监听 Mysql 的数据变动
- 使用 Kafka 作为消息中间件,主要是为了屏蔽数据源的各种变动。比如以后即使用 Flume 了,我们架构也不用大变
数据落地,有一份都会落地 HDFS,这里使用 Spark Streaming,算是准实时落地,而且方便加入处理逻辑。在 落地 ES 的时候可以使用 Spark Streaming,也可以使用 Logstach,这个影响不大
四、一些问题
有两个小问题列一下。
小文件,分钟级别的文件落地,肯定会有小文件的问题,这里要考虑的是,小文件的处理尽量不要和数据接入流程耦合太重,可以考虑每天、每周、甚至每月合并一次小文件。
- 数据流的逻辑复杂度问题,比如从 Kafka 落地 HDFS 会有一个取舍的考虑,比如说,我可以在一个 SS 程序中就分别落地 HDFS 和 ES,但是这样的话两条流就会有大的耦合,如果 ES 集群卡住,HDFS 的落地也会受到影响。但是如果两个隔开的话,就会重复消费同一份数据两次,会有一定网络和计算资源的浪费。

若有收获,就点个赞吧
0 人点赞
