- KubeSphere + Kubernetes + DevOps + KubeVirt + KubeKey
- 1 使用 KubeKey 部署与运维K8S 与 KubeSphere 集群
- 2 DevOps 基础与实践
- 3 Kubernetes 集群与云原生应用管理
- 停止Master节点上的服务
- 在其他集群Master节点运行
- 查看K8s集群中Node节点状态
- 停止Master节点上的服务
- 在其他集群Master节点运行
- 查看K8s集群中Node节点状态
- 停止kubernetes kubelet
- 停止etcd节点
- 停止docker服务
- 检查集群状态
- 查看集群节点etcd状态
- 3.2 Helm 及 Helm 应用仓库简介
- 3.3 Kubernetes 多集群管理与使用
- 4 微服务部署与流量治理
- 5 Kubernetes 云原生可观测性
- 5.1 集群与应用日志
- 5.1.1 生产部署最佳实践
- 5.1.2 日志检索与落盘日志收集
- 5.1.3 常见问题以及解决方法
- 5.1.3.1 如何将日志存储改为外部 Elasticsearch 并关闭内部 Elasticsearch
- 5.1.3.2 如何在启用 X-Pack Security 的情况下将日志存储改为 Elasticsearch
- 5.1.3.3 如何修改日志数据保留期限
- 5.1.3.4 无法使用工具箱找到某些节点上工作负载的日志
- 5.1.3.5 工具箱中的日志查询页面在加载时卡住
- 5.1.3.6 工具箱显示今天没有日志记录
- 5.1.3.7 在工具箱中查看日志时,报告内部服务器错误
- 5.1.3.8 如何让 KubeSphere 只收集指定工作负载的日志
- 在查看容器实时日志的时候,控制台上看到的实时日志要比 kubectl log -f xxx 看到的少
- 5.2 监控与告警
- 5.3 审计与事件
- 5.4 计量计费
- 5.1 集群与应用日志
- 6 KubeVirt 虚拟机负载管理
- 7 CKA 与 CKS 备考经验分享
KubeSphere + Kubernetes + DevOps + KubeVirt + KubeKey
思维导图:思维导图
1 使用 KubeKey 部署与运维K8S 与 KubeSphere 集群
1.1 KubeKey 介绍
Kubernetes 官方搭建 K8S 集群的自动化工具:kubeadm,kops,kubespray
Reference:生产环境 | Kubernetes第三方搭建 K8S 集群的自动化工具:KubeKey
1.1.1 kubeadm,kops,kubespray 的方式
官方文档中标记的注意事项:
- 选择合适的部署工具(包括容器运行时)
- 管理证书
- 为 apiserver 配置负载均衡器
- 外置并备份 etcd 服务
- 创建多个控制平面(多 Master)
- 跨区域(异地容灾备份)
- 持续管理集群
1.1.2 KubeKey 的介绍
KubeKey(由 Go 语言开发)是一种全新的安装工具。提供灵活的安装选择。
例如集群大小上可以选择:
- all-in-one 集群(单节点集群)
- 高可用集群
安装结果上可以选择
- 仅安装 Kubernetes / K3S
- 同时安装 Kubernetes / K3S 和 KubeSphere
1.1.3 为什么选择 KubeKey
- Go 语言开发,运行速度快,不用提前准备和配置安装工具的环境
- 支持多种安装选项
- 自动化多节点并行安装,提高安装效率
- 使用方式简单
- 代码可扩展性强,方便二次开发
1.1.4 KubeKey 支持矩阵
操作系统环境:
- Ubuntu 16.04 ,18.04,20.04
- Debian Buster,Stretch
- CentOS / RHEL 7
- SUSE Linux Enterprise Server 15
(推荐 Linux 内核版本在 4.15 以上)
Kubernetes 版本:
- v1.15 至 v1.22
KubeSphere 版本
- v2.1.1 至 v3.2.0
KubeKye 会不断更新以支持最新版本的 Kubernetes 和 KubeSphere
1.1.5 安装要求与建议
集群最小资源要求:
- 2 核 CPU
- 4 GB 运行内存
- 20 GB 存储空间
操作系统要求:
- 所有节点能够 ssh 访问
- 所有节点时钟同步
- 所有节点 sudo / curl / openssl 可以使用
- 建议关闭 selinux 或者设置为宽容模式,可参考文档kubekey/turn-off-SELinux_zh-CN.md at master · kubesphere/kubekey (github.com)
- 建议关闭集群内的防火墙或者按照文档kubekey/network-access.md at master ·kubesphere/kubekey (github.com)设置网络访问策略
1.1.6 获取 KubeKey
下载 KubeKey:
# 如果您能正常访问 GitHub/Googleapiscurl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.1 sh -# 如果您访问 GitHub/Googleapis 受限export KKZONE=cncurl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.1 sh -
源码编译:
git clone https://github.com/kubesphere/kubekey.gitcd kubekey./build.sh
1.1.7 KubeKey 使用方式
# All-in-One# 创建集群./kk create cluster --with-kubernetes v1.21.5 --with-kubesphere v3.2.1# 删除集群./kk delete cluster# 升级集群./kk upgrade --with-kubernetes v1.22.1
# 高级模式# https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md# 创建 Kubekey 配置文件./kk create config -f config.yaml# 安装集群依赖组件./kk init os -f config.yaml# 创建集群./kk create cluster -f config.yaml# 删除集群./kk delete cluster -f config.yaml# 升级集群./kk upgrade cluster -f config.yaml
1.2 部署高可用 Kubernetes 集群
1.2.1 集群部署概览
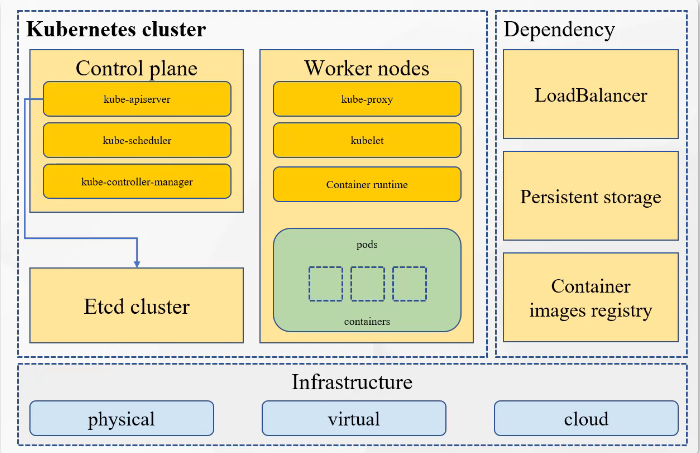
Kubernetes 集群的基础设施可以搭建在物理机,虚拟机以及云服务器(公有云,私有云,混合云)上。
Control plane(Master):kube-apiserver,kube-scheduler,kube-controller manager
Worker Node(Worker):kube-proxy,kubelet,container runtime(Docker,podman等容器管理工具)
Etcd Cluster:集群数据库
LoadBalancer:负载均衡器,高可用部署下可以对 kube-apiserver 有负载均衡能力,其次在 Kubernetes Service 对象有 LoadBalancer 模式之后,Service 会自动创建负载均衡器并挂载到 Service 上。(可能会依赖云厂商的插件)
Persistent storage:持久化存储,业务跑在 Kubernetes 上,需要对业务的数据进行持久化。
Container assets Registry:容器镜像仓库。
1.2.2 高可用集群部署(External loadbalancer外部负载均衡模式)

高可用集群部署(External loadbalancer外部负载均衡模式):部署 ETCD 集群,上层为多 Master 集群,再上层为负载均衡器(keepalived + haproxy)高可用,所有的工作节点通过访问 VIP以及通过
Keepalived 和 Haproxy组成的负载均衡器来访问 Master 集群节点。(常见的高可用部署)使用 Keepalived 和 HAproxy 创建高可用 Kubernetes 集群 (kubesphere.com.cn)
1.2.3 高可用集群部署(Internal loadbalancer内部负载均衡模式)

高可用集群部署(Internal loadbalancer内部负载均衡模式):在每个工作节点(Worker Node)上起 haproxy,将控制平面中Master节点的apiserver等各种组件代理到Worker Node节点本地上,Worker Node通过访问本地地址来访问Kubernetes 的控制平面。
不需要准备额外的负载均衡器,不需要占用额外的资源,可以快速简单方便的部署一套K8S高可用集群模式。
1.2.4 使用 KubeKey 部署高可用集群
| 节点名称 | 节点地址 | 节点角色 |
|---|---|---|
| lb01 | 10.0.0.11 | Keepalived & HAproxy |
| lb02 | 10.0.0.12 | Keepalived & HAproxy |
| Master01 | 10.0.0.51 | master、etcd |
| Master02 | 10.0.0.52 | master、etcd |
| Master03 | 10.0.0.53 | master、etcd |
| Node01 | 10.0.0.54 | worker |
| Node02 | 10.0.0.55 | worker |
| 10.0.0.253 | vip(虚拟 IP 地址) |
1.2.4.1 使用 Kubekey 部署外部负载均衡模式(LB节点独立存在)
Keepalived 提供 VRPP 实现,并允许您配置 Linux 机器使负载均衡,预防单点故障。HAProxy 提供可靠、高性能的负载均衡,能与 Keepalived 完美配合。
由于
lb1和lb2上安装了 Keepalived 和 HAproxy,如果其中一个节点故障,虚拟 IP 地址(即浮动 IP 地址)将自动与另一个节点关联,使集群仍然可以正常运行,从而实现高可用。若有需要,也可以此为目的,添加更多安装 Keepalived 和 HAproxy 的节点。使用 Keepalived 和 HAproxy 创建高可用 Kubernetes 集群 (kubesphere.com.cn)
- HAproxy
# 1.lb01 和 lb02 安装 Keepalived 和 HAproxy。$ yum install keepalived haproxy psmisc -y# 2.Node01 和 Node02 配置负载均衡# 在两台用于负载均衡的机器上运行以下命令以配置 Proxy(两台机器的 Proxy 配置相同):$ vim /etc/haproxy/haproxy.cfg# 以下是示例配置,供您参考(请注意 server 字段。请记住 6443 是 apiserver 端口):...# KubeSphere HAproxy Startfrontend kube-apiserverbind *:6443mode tcpoption tcplogdefault_backend kube-apiserver# KubeSphere HAproxy End# KubeSphere HAproxy backend Startbackend kube-apiservermode tcpoption tcplogoption tcp-checkbalance roundrobindefault-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100server kube-apiserver-1 10.0.0.51:6443 check on-marked-down shutdown-sessions # Replace the IP address with your own.server kube-apiserver-2 10.0.0.52:6443 check on-marked-down shutdown-sessions # Replace the IP address with your own.server kube-apiserver-3 10.0.0.53:6443 check on-marked-down shutdown-sessions # Replace the IP address with your own.# KubeSphere HAproxy backend End...# 3.保存文件并运行以下命令以重启 HAproxy。$ systemctl restart haproxy# 4.使 HAproxy 在开机后自动运行:$ systemctl enable --now haproxy# 5.确保您在另一台机器上也配置启动了 HAproxy。(配置文件lb1 与 lb2相同)
- Keepalived
# 两台机器上必须都安装 Keepalived,但在配置上略有不同。# 1.运行以下命令以配置 Keepalived。$ vim /etc/keepalived/keepalived.conf# 以下是示例配置 (lb1),供您参考:global_defs {notification_email {}#router_id LVS_DEVEL#vrrp_skip_check_adv_addr#vrrp_garp_interval 0#vrrp_gna_interval 0}# KubeSphere Keepalive Startvrrp_script chk_haproxy {script "killall -0 haproxy"interval 2weight 2}vrrp_instance haproxy-vip {state MASTERpriority 100interface eth0 # Network cardvirtual_router_id 60advert_int 1authentication {auth_type PASSauth_pass 1111}unicast_src_ip 10.0.0.11 # The IP address of this machineunicast_peer {10.0.0.12 # The IP address of peer machines}virtual_ipaddress {10.0.0.253/24 # The VIP address}track_script {chk_haproxy}}# KubeSphere Keepalive End# 备注# 对于 interface 字段,您必须提供自己的网卡信息。您可以在机器上运行 ifconfig 以获取该值。# 为 unicast_src_ip 提供的 IP 地址是您当前机器的 IP 地址。对于也安装了 HAproxy 和 Keepalived 进行负载均衡的其他机器,必须在字段 unicast_peer 中输入其 IP 地址。# 3.保存文件并运行以下命令以重启 Keepalived。$ systemctl restart keepalived# 4.使 Keepalived 在开机后自动运行:$ systemctl enable --now keepalived# 5.确保您在另一台机器 (lb2) 上也配置了 Keepalived。$ vim /etc/keepalived/keepalived.conf# KubeSphere Keepalive Startvrrp_script chk_haproxy {script "killall -0 haproxy"interval 2weight 2}vrrp_instance haproxy-vip {state BACKUPpriority 90interface eth0 # Network cardvirtual_router_id 60advert_int 1authentication {auth_type PASSauth_pass 1111}unicast_src_ip 10.0.0.12 # The IP address of this machineunicast_peer {10.0.0.11 # The IP address of peer machines}virtual_ipaddress {10.0.0.253/24 # The VIP address}track_script {chk_haproxy}}# KubeSphere Keepalive End
- 验证高可用
在开始创建 Kubernetes 集群之前,请确保已经测试了高可用。
# 1.在机器 lb1 上,运行以下命令:ip addr# 2.如上图所示,虚拟 IP 地址已经成功添加。模拟此节点上的故障:systemctl stop keepalived# 3.再次检查浮动 IP 地址,您可以看到该地址在 lb1 上消失了。# 4.理论上讲,若配置成功,该虚拟 IP 会漂移到另一台机器 (lb2) 上。在 lb2 上运行以下命令,这是预期的输出:ip addr# 5.高可用已经配置成功。
- 使用 KubeKey 创建 Kubernetes 集群和KubeSphere 集群
# https://github.com/kubesphere/kubekey# 首先运行以下命令,以确保您从正确的区域下载 KubeKey。$ export KKZONE=cn# 运行以下命令来下载 KubeKey:$ curl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.1 sh -# 备注# 下载 KubeKey 之后,如果您将其转移到访问 Googleapis 受限的新机器上,请务必再次运行 export KKZONE=cn,然后继续执行以下步骤。$ chmod +x kk# 生成kubesphere的模板文件$ ./kk create config -f config-sample.yaml...spec:hosts:- {name: master01, address: 10.0.0.51, internalAddress: 10.0.0.51, user: root, password: magedu}- {name: master02, address: 10.0.0.52, internalAddress: 10.0.0.52, user: root, password: magedu}- {name: master03, address: 10.0.0.53, internalAddress: 10.0.0.53, user: root, password: magedu}- {name: node01, address: 10.0.0.54, internalAddress: 10.0.0.54, user: root, password: magedu}- {name: node02, address: 10.0.0.55, internalAddress: 10.0.0.55, user: root, password: magedu}roleGroups:etcd:- master01- master02- master03master:- master01- master02- master03worker:- node01- node02controlPlaneEndpoint:##Internal loadbalancer for apiservers#internalLoadbalancer: haproxy # 该模式为内部负载均衡模式,默认该模式关闭,开启该模式需要将address参数内地址清空domain: lb.kubesphere.local # 负载均衡器默认的内部访问域名address: "10.0.0.253" # 该地址为外部负载均衡的VIP地址,自定义设置,输入VIP地址,则需要将internalLoadbalancer参数注释port: 6443...# 全部机器安装conntrack$ yum install -y conntrack# 使用kk部署,若需要部署kubesphere$ ./kk create cluster -f config-sample.yaml --with-kubesphere v3.2.1# 运行以下命令以检查安装日志$ kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
- 相关报错解决:
## 机器初始化时必须将机器的 SELinux 和 防火墙功能全部关闭# The connection to the server localhost:8080 was refused - did you specify the right host or port?# 解决方法:$ mkdir -p $HOME/.kube$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config$ sudo chown $(id -u):$(id -g) $HOME/.kube/config# No etcd config found. Assuming external etcd# 解决方法:重新部署集群,并添加:$ iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
1.2.4.2 使用 Kubekey 部署内部负载均衡模式(节点内部高可用LB)
KubeKey 的高可用模式实现方式称作本地负载均衡模式。具体表现为 KubeKey 会在每一个工作节点上部署一个负载均衡器(HAproxy),所有主节点的 Kubernetes 组件连接其本地的 kube-apiserver ,而所有工作节点的 Kubernetes 组件通过由 KubeKey 部署的负载均衡器反向代理到多个主节点的 kube-apiserver 。这种模式相较于专用到负载均衡器来说效率有所降低,因为会引入额外的健康检查机制,但是如果当前环境无法提供外部负载均衡器或者虚拟 IP(VIP)时这将是一种更实用、更有效、更方便的高可用部署模式。
# https://github.com/kubesphere/kubekey# 首先运行以下命令,以确保您从正确的区域下载 KubeKey。$ export KKZONE=cn# 运行以下命令来下载 KubeKey:$ curl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.1 sh -# 备注# 下载 KubeKey 之后,如果您将其转移到访问 Googleapis 受限的新机器上,请务必再次运行 export KKZONE=cn,然后继续执行以下步骤。chmod +x kk# 生成kubesphere的模板文件$ ./kk create config -f config-sample.yaml --with-kubernetes v1.21.5 --with-kubesphere v3.2.1...spec:hosts:- {name: master01, address: 10.0.0.51, internalAddress: 10.0.0.51, user: root, password: magedu}- {name: master02, address: 10.0.0.52, internalAddress: 10.0.0.52, user: root, password: magedu}- {name: master03, address: 10.0.0.53, internalAddress: 10.0.0.53, user: root, password: magedu}- {name: node01, address: 10.0.0.54, internalAddress: 10.0.0.54, user: root, password: magedu}- {name: node02, address: 10.0.0.55, internalAddress: 10.0.0.55, user: root, password: magedu}roleGroups:etcd:- master01- master02- master03master:- master01- master02- master03worker:- node01- node02controlPlaneEndpoint:##Internal loadbalancer for apiserversinternalLoadbalancer: haproxy # 该模式为内部负载均衡模式,默认该模式关闭,开启该模式需要将address参数内地址清空domain: lb.kubesphere.local # 负载均衡器默认的内部访问域名address: "" # 该地址为外部负载均衡的VIP地址,自定义设置,输入VIP地址,开启该地址后,则需要将internalLoadbalancer参数注释port: 6443...# 全部机器安装conntrack$ yum install -y conntrack# 使用kk部署,若需要部署kubesphere$ ./kk create cluster -f config-sample.yaml --with-kubesphere v3.2.1# 运行以下命令以检查安装日志$ kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
1.3 KubeKey 集群配置文件详解
- Kubernetes 集群配置
参考文档:
https://github.com/kubesphere/kubekey/blob/master/docs/config-example.md
https://github.com/kubesphere/kubekey/blob/master/apis/kubekey/v1alpha2/network_types.go
- KubeSphere 集群配置
参考文档:
https://github.com/kubesphere/ks-installer/blob/master/deploy/cluster-configuration.yaml
# KK 生成集群配置文件(Kubernetes集群) --> ./kk create config -f config-sample.yaml# KK 生成集群配置文件(Kubernetes & KubeSphere集群) --> ./kk create config --with-kubesphere v3.2.1 -f config-sample.yaml# Kubernetes 集群配置参考官方文档:# --> https://kubesphere.com.cn/docs/installing-on-linux/introduction/vars/# --> https://kubesphere.com.cn/docs/installing-on-linux/introduction/multioverview/apiVersion: kubekey.kubesphere.io/v1alpha1 # 使用的API版本号kind: Cluster # 资源类型为 Clustermetadata: # 元数据name: config-sample # 集群名称为 config-samplespec: # 集群详细信息hosts: # 集群节点配置信息- {name: node1, address: 172.16.0.2, internalAddress: 172.16.0.2, user: ubuntu, password: Qcloud@123}- {name: node2, address: 172.16.0.3, internalAddress: 172.16.0.3, user: ubuntu, password: Qcloud@123}roleGroups: # 节点角色配置etcd: # Etcd 部署节点- node1master: # Kubernetes 部署控制平面- node1worker: # Kubernetes 部署工作节点- node1- node2controlPlaneEndpoint:##Internal loadbalancer for apiservers#internalLoadbalancer: haproxy # Kubernetes 集群内部负载均衡器domain: lb.kubesphere.local # Kubernetes 负载均衡器默认的内部访问域名address: "" # Kubernetes 集群外部负载均衡器IPport: 6443 # 监听地址kubernetes:version: v1.21.5 # Kubernetes 版本号clusterName: cluster.local # Kubernetes 集群名network:plugin: calico # Kubernetes 使用的网络插件kubePodsCIDR: 10.233.64.0/18 # Kubernetes Pod 网络层kubeServiceCIDR: 10.233.0.0/18 # Kubernetes Service 网络层registry:registryMirrors: [] # 配置 Docker 仓库镜像以加速下载insecureRegistries: [] # 设置不安全镜像仓库的地址addons: [] # 设置不安全镜像仓库的地址
1.4 Kubernetes 增删集群节点
1.4.1 增加集群节点
步骤:
# 修改 config-sample.yaml 文件添加相应节点的信息,并设置节点的角色- {name: lb01, address: 10.0.0.11, internalAddress: 10.0.0.11, user: root, password: magedu}roleGroups:worker:- lb01# 执行命令$ ./kk add nodes -f config-sample.yaml# 验证是否节点添加成功$ kubectl get nodes
1.4.2 删除集群节点
步骤
# 执行命令# ./kk delete node (节点名称) -f config-sample.yaml$ ./kk delete node lb01 -f config-sample.yaml
1.5 Kubernetes 集群证书管理
1.5.1 查看集群证书是否到期
# 执行命令$ ./kk certs check-expiration -f config-sample.yaml$ ./kk certs check-expirationINFO[13:32:47 CST] Listing cluster certs ...CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY NODEapiserver.crt Jan 01, 2023 07:36 UTC 364d ca master01apiserver-kubelet-client.crt Jan 01, 2023 07:36 UTC 364d ca master01front-proxy-client.crt Jan 01, 2023 07:36 UTC 364d front-proxy-ca master01admin.conf Jan 01, 2023 07:36 UTC 364d master01controller-manager.conf Jan 01, 2023 07:36 UTC 364d master01scheduler.conf Jan 01, 2023 07:36 UTC 364d master01CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME NODEca.crt Dec 30, 2031 07:36 UTC 9y master01front-proxy-ca.crt Dec 30, 2031 07:36 UTC 9y master01INFO[13:32:48 CST] Successful.
1.5.2 更新集群证书
# 集群证书位置$ ls /etc/kubernetes/pki/# 执行命令更新证书$ ./kk certs renew -f config-sample.yaml
1.6 KubeSphere 启用可插拔组件
1.7 Kubernetes 节点管理
2 DevOps 基础与实践
2.1 DevOps 基础
2.1.1 DevOps 的起源
- KubeSphere DevOps
- KubeSphere DevOps - S2i 简介
2.1.2 DevOps 的定义与价值
DevOps 是一系列做法和工具,可以使 IT 和软件开发团队之间的流程实现自动化。其中,随着敏捷软件开发日趋流行,持续集成 (CI) 和持续交付 (CD) 已经成为该领域一个理想的解决方案。在 CI/CD 工作流中,每次集成都通过自动化构建来验证,包括编码、发布和测试,从而帮助开发者提前发现集成错误,团队也可以快速、安全、可靠地将内部软件交付到生产环境。
2.1.3 Jenkins 与 CI/CD 简介
- JenKins 简介
Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件项目可以进行持续集成。
Jenkins功能包括:
1、持续的软件版本发布/测试项目。
2、监控外部调用执行的工作。
- CI / CD 简介
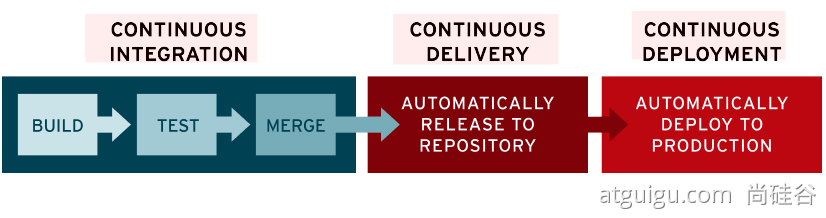
1.CONTINUOUS INTEGRATION:当代码完成以后,进入 BUILD 代码构建,TEST 代码测试,MERGE 合并到代码库中。这些步骤将以持续化自动化的方式完成。
持续集成CI2.CONTINUOUS DELIVERY:
持续交付CD,将代码制品或者镜像发布到仓库中。3.CONTINUOUS DEPLOYMENT:
持续部署CD,将代码制品从仓库中拉取下来,开始进行部署。
2.2 DevOps 原则
2.2.1 Git 版本控制与基本概念
- 什么是版本控制
版本控制是一种记录一个或者若干文件内容变化,以便将来查阅特定版本修订情况的系统。成员每一次的修改的记录均会被系统所记录到文件中,有助于回溯和追踪历史修改。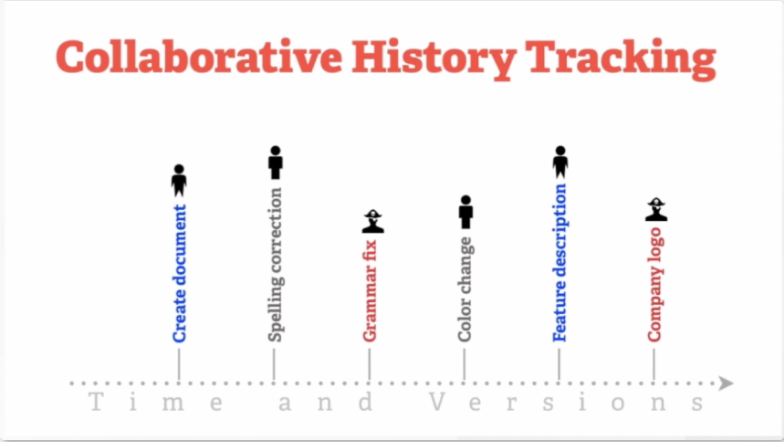
- 什么是 Git
- Git 简介
Git 是一种分布式版本控制系统(Linus Torvalds 发明),与 SVN 类似的集中化版本控制系统相比,集中化版本控制系统虽然能够令多个团队成员一起协作开发,但是有时如果中央服务器宕机的话,谁也无法在宕机期间提交更新和协同开发。甚至有时,中央服务器磁盘故障,恰巧有没有做备份或者备份不及时,那就有可能丢失数据的风险。
- 为什么要用 Git
能够对文件版本控制和多人协作开发拥有强大的分支特性,所以能够灵活的以不同的工作流协同开发分布式版本控制系统,即使协作服务器宕机,也能继续提交代码或者文件到本地仓库,当协作服务器恢复正常工作时,再将本地仓库同步到远程仓库。当团队中某个成员完成某个功能时,通过 pull request 操作来通知其他团队成员,其他团队成员能够 review code 后再合并代码。
- Git 特性:
几乎所有操作都是本地执行;直接记录快照,而非差异比较;时刻保持数据完整性;
- Git 有三种状态,你的文件可能处于其中之一:
- 已提交(
committed):表示数据已经安全的保存在本地数据库中。 - 已修改(
modified):已经修改了文件,但是还没有保存到本地数据库中 - 已暂存(
staged):表示对一个已经修改的文件的当前版本做了标记,使其包含在了下次的提交中
- 已提交(
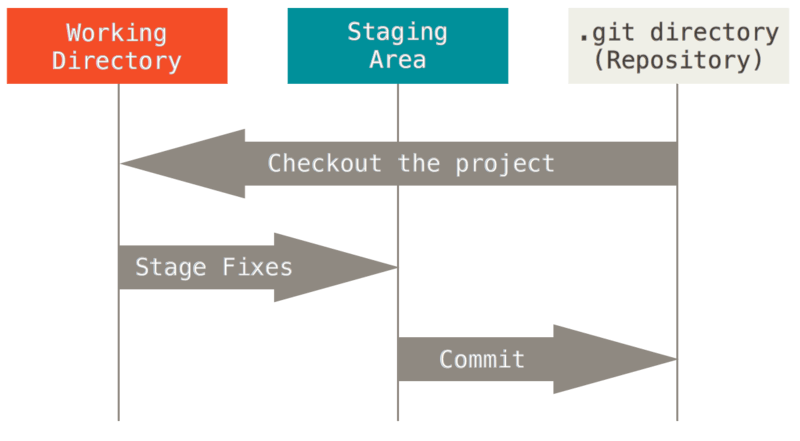
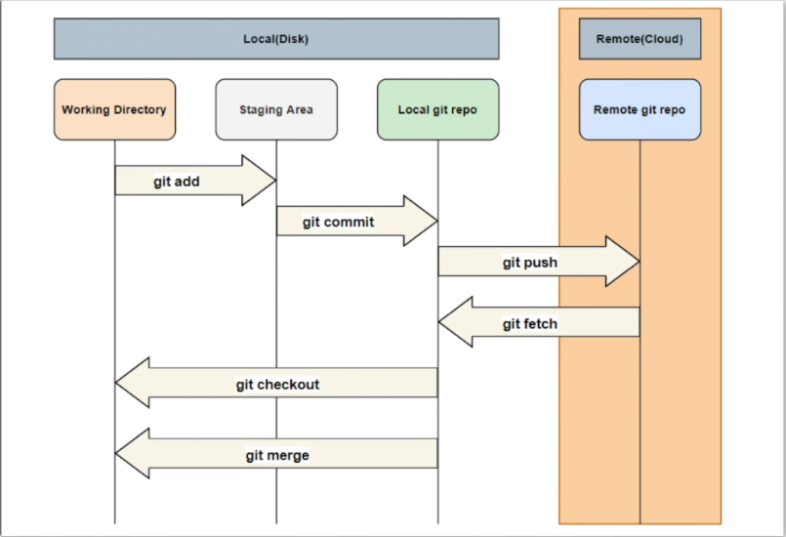
- Git 的使用流程
- 在 Git 版本控制的目录下修改某个文件
- 使用
git add命令对修改后的文件快照,保存到暂存区域 - 使用
git commit命令提交更新,将保存在暂存区域的文件快照永久转储到 Git 目录中- 安装 Git
- 安装 Git
- Git (git-scm.com)
- Git 官方文档:https://git-scm.com/book/zh/v2/
- Git 简明指南:http://rogerdudler.github.io/git-guide/index.za.html
2.2.2 Git 基本命令使用示例
创建仓库
- git init
- git clone
- git config
保存修改
- git add
- git commit
查看仓库
- git status
- git log -oneline
重写 Git 历史记录
- git commit —amend
- git rebase
- git reflog
Git 相关参考资料
- Git 官方文档:
https://git-scm.com/book/zh/v2/- Git 简明指南:
http://rogerdudler.github.io/git-guide/index.zh.html- 如何使用 GitHub Codespacs:
https://www.bilibili.com/video/BV15q4y157Uy?spm_id_from=333.999.0.0- 图解 Git:
http://marklodato.github.io/visual-git-guide/index-zh-cn.html- Git 版本控制与工作流:
https://www.jianshu.com/p/67afe711c731
范例:常用命令
# 1.在个人 GitHub 中创建仓库# 2.本地拉取 GitHub 仓库$ git clone https://github.com/Dragon-zw/git-sample.git(HTTPS地址)# 3.添加或修改仓库文件内容,修改完毕后,使用 Git 保存修改$ git add . (当前仓库路径)# 4.查看仓库修改$ git status# 5.提交修改$ git commit -s -m "this is a commit"

2.3 DevOps 核心技术以及常见生态工具简介
2.3.1 DevOps 元素周期表
2.3.2 DevOps 流程

2.4 持续集成 / 技术交付全流程工具的落地
2.4.1 DevOps 生命周期
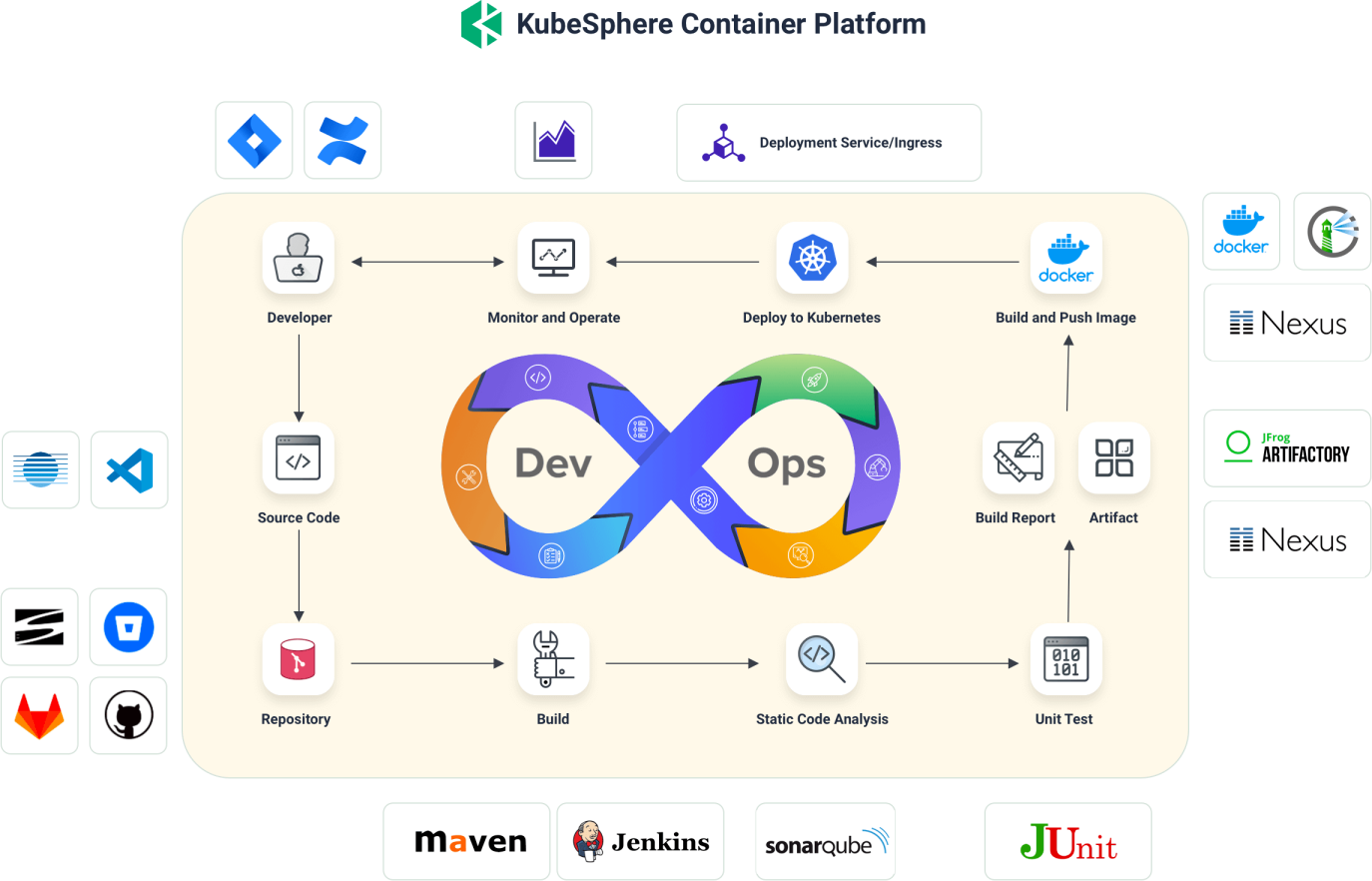
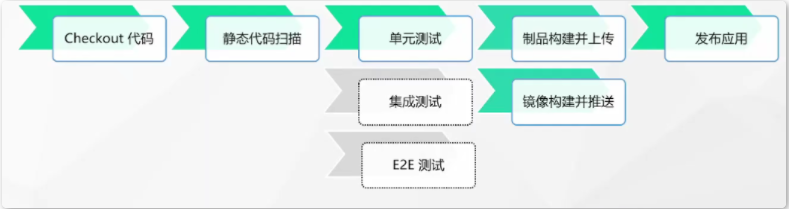
2.4.2 DevOps 流水线准备
- 实验准备
- 0.1 搭建好 KubeSphere 3.2.1 (及以上版本)并启用 DevOps 可插拔组件
- 0.2 搭建 SonarQube 并配置到 KubeSphere
将 SonarQube 集成到流水线 (kubesphere.com.cn)
- 1 创建 DevOps 项目(企业空间)
devops-workspace
- 2 创建项目和DevOps项目
- 3 Fork Demo 仓库
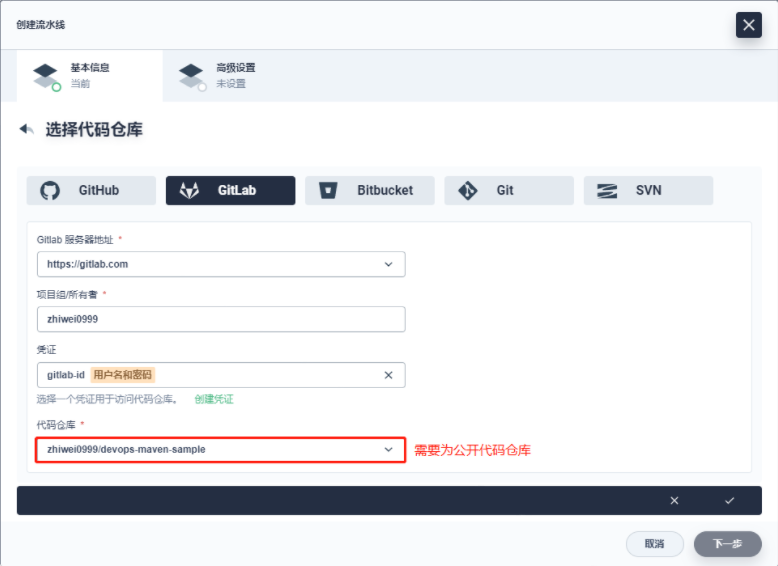
https://gitlab.com/ks-devops/devops-maven-sample 修改 SonarQube 分支下的 Jenkinsfile-online
- 4 创建流水线所需要的凭证信息
dockerhub-id
sonar-token
demo-kubeconfig
gitlab-id
- 5 创建多分支流水线
devops-maven-sample
# 项目:kubesphere-sample-dev :开发环境kubesphere-sample-prod :生产环境
# DevOps项目:demo
范例:安装 SonarQube 并配置到 KubeSphere
SonarQube 是一种主流的代码质量持续检测工具。您可以将其用于代码库的静态和动态分析。SonarQube 集成到 KubeSphere 流水线后,如果在运行的流水线中检测到问题,您可以直接在仪表板上查看常见代码问题,例如 Bug 和漏洞。
安装 SonarQube 服务器
要将 SonarQube 集成到您的流水线,必须先安装 SonarQube 服务器。
请先安装 Helm,以便后续使用该工具安装 SonarQube。例如,运行以下命令安装 Helm 3:
curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
查看 Helm 版本。
备注
有关更多信息,请参见 Helm 文档。执行以下命令安装 SonarQube 服务器。
helm upgrade --install sonarqube sonarqube --repo https://charts.kubesphere.io/main -n kubesphere-devops-system --create-namespace --set service.type=NodePort
备注
请您确保使用 Helm 3 安装 SonarQube Server。-
获取 SonarQube 控制台地址
执行以下命令以获取 SonarQube NodePort。
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services sonarqube-sonarqube) export NODE_IP=$(kubectl get nodes --namespace kubesphere-devops-system -o jsonpath="{.items[0].status.addresses[0].address}") echo http://$NODE_IP:$NODE_PORT

- 您可以获得如下输出(本示例中端口号为
31377,可能与您的端口号不同):http://10.77.1.201:31377
配置 SonarQube 服务器
步骤 1:访问 SonarQube 控制台
- 执行以下命令查看 SonarQube 的状态。请注意,只有在 SonarQube 启动并运行后才能访问 SonarQube 控制台。
$ kubectl get pod -n kubesphere-devops-system NAME READY STATUS RESTARTS AGE devops-jenkins-68b8949bb-7zwg4 1/1 Running 0 84m s2ioperator-0 1/1 Running 1 84m sonarqube-postgresql-0 1/1 Running 0 5m31s sonarqube-sonarqube-bb595d88b-97594 1/1 Running 2 5m31s
- 在浏览器中访问 SonarQube 控制台
http://<Node IP>:<NodePort>。 - 点击右上角的 Log in,然后使用默认帐户
admin/admin登录。
备注
取决于您的实例的部署位置,您可能需要设置必要的端口转发规则,并在您的安全组中放行该端口,以便访问 SonarQube。
步骤 2:创建 SonarQube 管理员令牌 (Token)
- 点击右上角字母 A,然后从菜单中选择 My Account 以转到 Profile 页面。

- 点击 Security 并输入令牌名称,例如
kubesphere。
- 点击 Generate 并复制此令牌。

警告
如提示所示,您无法再次查看此令牌,因此请确保复制成功。
步骤 3:创建 Webhook 服务器
- 执行以下命令获取 SonarQube Webhook 的地址。
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services devops-jenkins) export NODE_IP=$(kubectl get nodes --namespace kubesphere-devops-system -o jsonpath="{.items[0].status.addresses[0].address}") echo http://$NODE_IP:$NODE_PORT/sonarqube-webhook/
- 预期输出结果:
http://10.77.1.201:30180/sonarqube-webhook/
- 依次点击 Administration、Configuration 和 Webhooks 创建一个 Webhook。

- 点击 Create。

- 在弹出的对话框中输入 Name 和 Jenkins Console URL(即 SonarQube Webhook 地址)。点击 Create 完成操作。

步骤 4:将 SonarQube 配置添加到 ks-installer
- 执行以下命令编辑
ks-installer。kubectl edit cc -n kubesphere-system ks-installer
- 搜寻至
devops。添加字段sonarqube并在其下方指定externalSonarUrl和externalSonarToken。devops: enabled: true jenkinsJavaOpts_MaxRAM: 2g jenkinsJavaOpts_Xms: 512m jenkinsJavaOpts_Xmx: 512m jenkinsMemoryLim: 2Gi jenkinsMemoryReq: 1500Mi jenkinsVolumeSize: 8Gi sonarqube: # Add this field manually. externalSonarUrl: http://10.77.1.201:31377 # The SonarQube IP address. externalSonarToken: 00ee4c512fc987d3ec3251fdd7493193cdd3b91d # The SonarQube admin token created above.
- 完成操作后保存此文件。
步骤 5:将 SonarQube 服务器添加至 Jenkins
- 执行以下命令获取 Jenkins 的地址。
export NODE_PORT=$(kubectl get --namespace kubesphere-devops-system -o jsonpath="{.spec.ports[0].nodePort}" services devops-jenkins) export NODE_IP=$(kubectl get nodes --namespace kubesphere-devops-system -o jsonpath="{.items[0].status.addresses[0].address}") echo http://$NODE_IP:$NODE_PORT
- 您可以获得以下输出,获取 Jenkins 的端口号。
http://10.77.1.201:30180
- 请使用地址
http://<Node IP>:30180访问 Jenkins。安装 KubeSphere 时,默认情况下也会安装 Jenkins 仪表板。此外,Jenkins 还配置有 KubeSphere LDAP,这意味着您可以直接使用 KubeSphere 帐户(例如admin/P@88w0rd)登录 Jenkins。有关配置 Jenkins 的更多信息,请参见 Jenkins 系统设置。
备注
取决于您的实例的部署位置,您可能需要设置必要的端口转发规则,并在您的安全组中放行端口30180,以便访问 Jenkins。 - 点击左侧导航栏中的系统管理。
- 向下翻页找到并点击系统配置。
- 搜寻到 SonarQube servers,然后点击 Add SonarQube。
- 输入 Name 和 Server URL (
http://<Node IP>:<NodePort>)。点击添加,选择 Jenkins,然后在弹出的对话框中用 SonarQube 管理员令牌创建凭证(如下方第二张截图所示)。创建凭证后,从 Server authentication token 旁边的下拉列表中选择该凭证。点击应用完成操作。

备注
如果点击添加按钮无效(Jenkins 已知问题),您可以前往系统管理下的 Manage Credentials 并点击 Stores scoped to Jenkins 下的 Jenkins,再点击全局凭据 (unrestricted),然后点击左侧导航栏的添加凭据,参考上方第二张截图用 SonarQube 管理员令牌添加凭证。添加凭证后,从 Server authentication token 旁边的下拉列表中选择该凭证。
步骤 6:将 sonarqubeURL 添加到 KubeSphere 控制台
您需要指定 sonarqubeURL,以便可以直接从 KubeSphere 控制台访问 SonarQube。
- 执行以下命令:
kubectl edit cm -n kubesphere-system ks-console-config
- 搜寻到
data.client.enableKubeConfig,在下方添加devops字段并指定sonarqubeURL。client: enableKubeConfig: true devops: # 手动添加该字段。 sonarqubeURL: http://10.77.1.201:31377 # SonarQube IP 地址。
- 保存该文件。
步骤 7:重启服务
执行以下命令。
kubectl -n kubesphere-devops-system rollout restart deploy devops-apiserver
kubectl -n kubesphere-system rollout restart deploy ks-console
为新项目创建 SonarQube Token
您需要一个 SonarQube 令牌,以便您的流水线可以在运行时与 SonarQube 通信。
- 在 SonarQube 控制台上,点击 Create new project。

- 输入项目密钥,例如
java-demo,然后点击 Set Up。
- 输入项目名称,例如
java-sample,然后点击 Generate。
- 创建令牌后,点击 Continue。

- 分别选择 Java 和 Maven。复制下图所示绿色框中的序列号,如果要在流水线中使用,则需要在凭证中添加此序列号。

在 KubeSphere 控制台查看结果
您使用图形编辑面板创建流水线或使用 Jenkinsfile 创建流水线之后,可以查看代码质量分析的结果。
- DevOps 凭证配置信息
DOCKER_CREDENTIAL_ID = 'dockerhub-id' //dockerhubID (需要创建凭证)
GITHUB_CREDENTIAL_ID = 'github-id' //githubID,暂时不需要使用
KUBECONFIG_CREDENTIAL_ID = 'demo-kubeconfig' //demo-kubeconfig K8S配置文件信息 (需要创建凭证)
REGISTRY = 'docker.io' //ghcr.io Github容器镜像仓库
DOCKERHUB_NAMESPACE = 'dragonzw' // Change me, Dockerhub用户名 (需要创建凭证)
SONAR_CREDENTIAL_ID = 'sonar-token' //sonar-token凭证 (需要创建凭证)
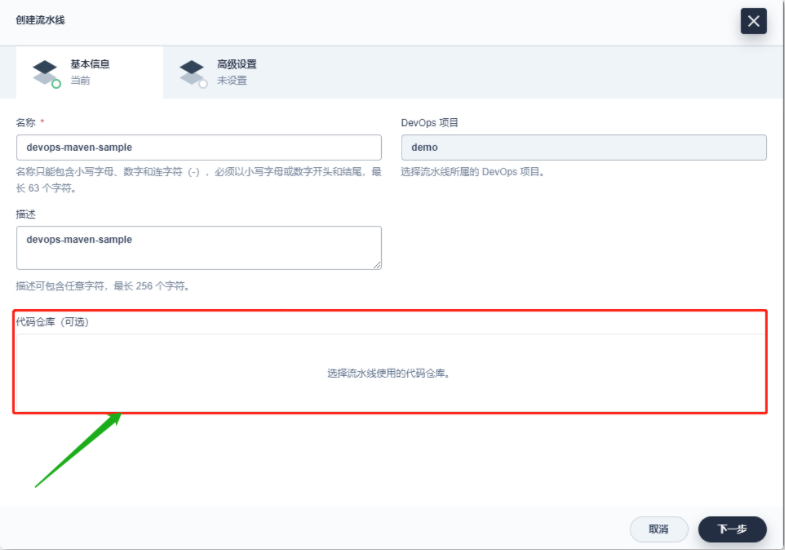
- 创建 DevOps 流水线(使用 GitLab 代码仓库)
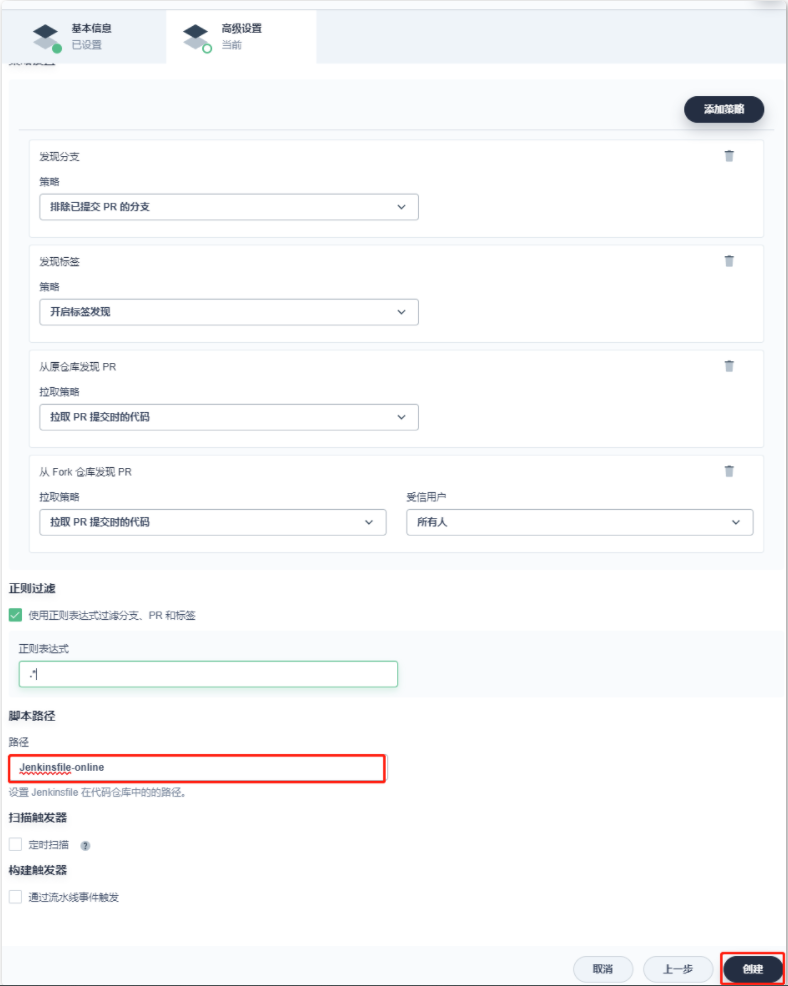
- 设置流水线的高级设置
2.4.3 DevOps 单元测试
2.4.4 DevOps 质量扫描
将 SonarQube 集成到流水线 (kubesphere.com.cn) 将 Harbor 集成到流水线 (kubesphere.com.cn)
使用 sonarqube 进行代码质量扫描
2.4.5 DevOps 制品管理
2.4.6 DevOps 自动测试构建
2.4.7 DevOps 自动部署
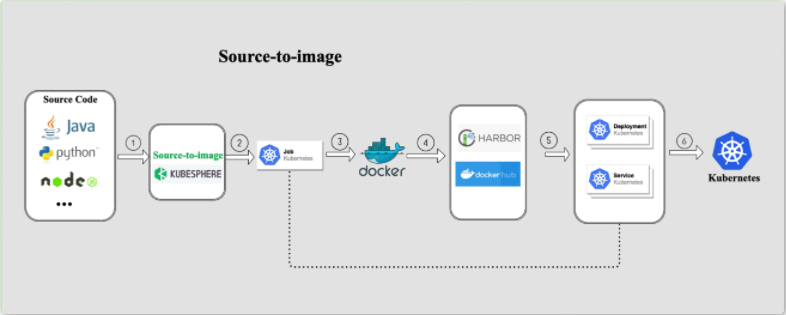
2.5 使用 KubeSphere DevOps 自动构建镜像与发布应用
2.5.1 使用 Source-to-Image 发布应用
2.5.2 使用 Binary-to-Image 发布应用
2.5.3 使用 Jenkinsfile 创建流水线
2.6 ArgoCD 实践(GitOps)
2.6.1 功能介绍以及学前导读
2.6.2 实验环境安装-1
2.6.3 实验环境安装-2
2.6.4 安装 ArgoCD 以及基本功能讲解
2.6.5 自建应用模拟开发场景
2.6.6 GitHub 实现自动化部署
2.6.7 数据加密之 sealed secret
2.6.8 钩子就是这么用的
2.6.9 app of apps 模式
2.6.10 多集群添加
2.6.11 ApplicationSet 理论知识
2.6.12 ApplicationSet 生成器
2.6.13 管理员配置讲解
2.7 在 KubeSphere 上实践 DevOps 流水线
2.7.1 尚医通项目实战
2.7.1.1 项目架构分析
2.7.1.2 流水线代码检出
2.7.1.3 流水线参数化构建
2.7.1.4 流水线镜像推送
2.7.1.5 流水线环境部署
3 Kubernetes 集群与云原生应用管理
3.1 KubeSphere 单集群日常运维最佳实践
3.1.1 集群备份与恢复
目的
- 备份源环境的多节点 KubeSphere 集群 A,在目标环境上恢复此多节点 KubeSphere 集群。
前提
- 源集群 A(Master , Node1 , Node2):已经部署 KubeSphere-v3.0.0(及以上版本)
- 目标集群 B(Master , Node1 , Node2):已经部署 Kubernetes-v1.17.9(及以上版本)
- 独立的对象存储 Minio(虚机)
- 虚机操作系统:CentOS 7
备份架构与原理
- 备份恢复架构图
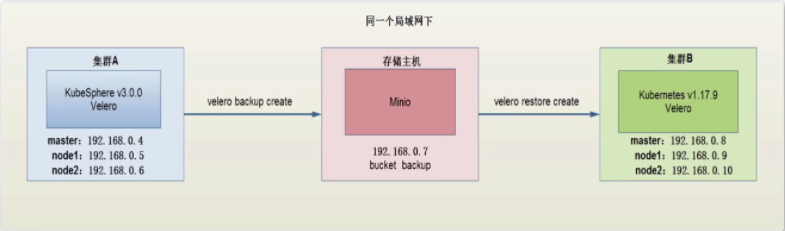
- Velero备份原理图
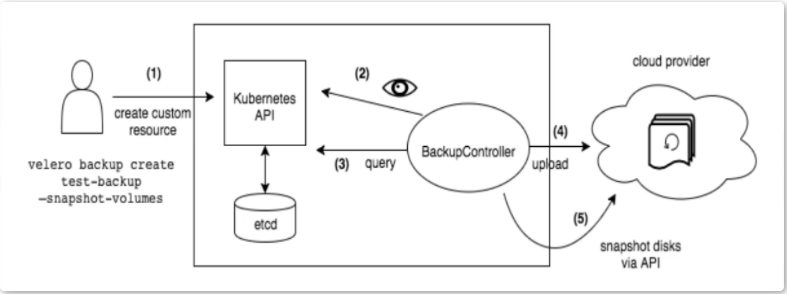
当本地用户客户端发送备份指令,Kubernetes API 就会生成一个BackupController 资源对象,API检测到以后,会进行备份过程,并记录到etcd数据库集群中。BackupController 对象将查询到的数据备份到云端的存储中。所不同的是,我们使用Minio 进行存储。
Velero 简介
- Velero 提供了备份和恢复Kubernetes 集群资源和持久卷的工具,可以在云上或本地运行。Velero可对集群进行备份与恢复,以防数据丢失;也可将集群资源迁移到其他集群,如将生产集群复制到备份集群。
- Restic是Velero的开源备份组件,用于备份和恢复Kubernetes卷,备份前,卷必须被注释。备份pv数据时,不支持卷类型为hostpath。
- velero-plugin-for-aws:v1.1.0是阿里云插件,后端主要支持兼容S3的存储,本节课程我们使用minio对象存储。
Velero 支持的后端存储
- Velero支持两种关于后端存储的CRD,分别是BackupStorageLocation和VolumeSnapshotLocatio
- BackupStorageLocation主要用来定义Kubernetes集群资源的数据存放位置,即集群对象数据,不是PVC的数据。后端存储主要支持兼容S3的存储,比如Minio 等。
- VolumeSnapshotLocation主要用来给PV做快照,需要云厂商提供插件,还需要使用CSI等存储机制这里我们使用专门的备份工具 Restic,把PV数据备份到minio。
对象存储 Minio 简介
Minio是一个基于Apache License v2.0开源协议的对象存储服务。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。
Minio是一个非常轻量的服务,可以很简单的和其他应用的结合,类似NodeJS, Redis或者MySQL
操作概览
- 配置对象存储Minio
- 在集群A,B上部署Velero
- 部署验证服务(wordpress)
- 备份KubeSphere集群A
- 在集群B还原KubeSphere
- 验证服务
3.1.1.1 单节点模式
docker 运行Minio
$ mkdir -pv /private/mnt/data
$ docker run -p 9000:9000 -p 9090:9090 \
--name minio1 \
-v /private/mnt/data:/data \
--privileged=true \
-e "MINIO_ACCESS_KEY=minio" \
-e "MINIO_SECRET_KEY=minio123" \
minio/minio server /data --console-address ":9090" -address ":9000" &
运行 velero
$ wget https://github.com/vmware-tanzu/velero/releases/download/v1.5.2/velero-v1.5.2-linux-amd64.tar.gz
$ tar -zxvf velero-v1.5.2-linux-amd64.tar.gz
$ cd velero-v1.5.2-linux-amd64
$ cp -av velero /usr/local/bin/.
# 创建velero凭证
$ cat > credentail-velero <<-'EOF'
[default]
aws_access_key_id = minio
aws_secret_access_key = minio123
EOF
$ velero install \
--provider aws \
--bucket backup \
--use-restic \
--secret-file ./credentail-velero \
--use-volume-snapshots=false \
--plugins velero/velero-plugins-for-aws:v1.1.0 \
--backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://10.0.0.51:9000
$ kubectl get pod -n velero velero
3.1.1.2 多节点模式
3.1.1.3 KubeSphere 管理节点 HA 模式
3.1.1.4 KubeSphere 多集群模式
3.1.2 集群重启与恢复
3.1.2.1 Kubernetes Master 节点启停
目的:通过演示停止,启动 Master 节点的过程,说明 Master 节点启停过程和注意事项,便于日常节点维护或者资源回收
场景:
- 在实际工作中,可能某个Master 节点需要维护,迁移,我们需要平滑的停止,启动该节点,尽量减少启停中对集群造成的影响
1、前提
- Kubernetes集群为使用kubekey安装
- 为了确保Kubernetes集群能够安全恢复,请在操作前对Kubernetes数据进行备份。详情请参考“备份与恢复”章节。
- 为了确保重启Master节点期间Kubernetes集群能够使用,集群中Master节点数量要大于等于3。
2、提示
- 若启停的 Master节点上有etcd服务,在启停该Master节点期间,请勿对集群资源进行任何操作,包括添加、更新、删除等,否则会导致启停节点的etcd数据失效。
3、K8s 节点启停类型与场景
- Worker 节点启停
- Worker 节点启停,详情见 Worker 节点启停
- Master 节点启停
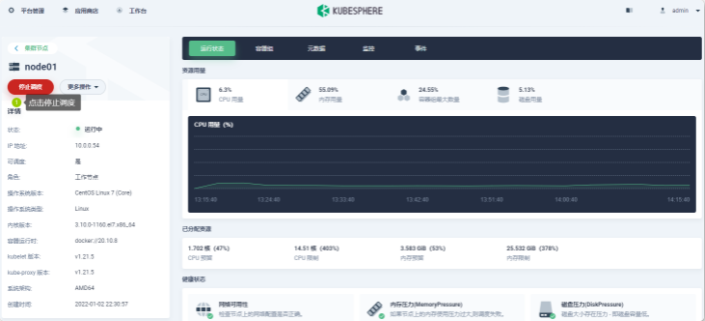
- Master 节点启停
4、操作概览
- 登录KubeSphere
- 备份数据
- 停止Master节点调度
- 驱逐Master节点上的工作负载
$ kubectl drain master03 --ignore-daemonsets --delete-local-data
- 停止Master节点
在其他集群Master节点运行
$ kubectl get nodes
查看K8s集群中Node节点状态
- 恢复Master节点
-
```shell
# 停止Master节点上的服务
$ systemctl start docker
$ systemctl start etcd
$ systemctl start kubelet
# 在其他集群Master节点运行
$ kubectl get nodes
# 查看K8s集群中Node节点状态
- 允许Master节点调度
Reference:节点管理 (kubesphere.com.cn)
3.1.2.2 Kubernetes Worker 节点启停
1、目的
本课程通过演示停止、启动Worker节点的过程,说明Worker节点启停过程和注意事项。
2、场景
- 在实际工作中,可能某个Worker节点需要维护、迁移,我们需要平滑的停止、启动该节点,尽量减少启停中对集群、业务造成的影响。
3、提示
摘除Worker节点操作中,该Worker节点上的工作负载将被驱逐到其他节点上,请确保集群资源充足。
K8s 节点启停类型与场景
- Worker 节点启停
- Worker 节点启停
- Master 节点启停
- Master 节点启停,详情见 Master 节点启停
4、操作概览
- 登录KubeSphere
- 停止Worker节点调度
- 驱逐Worker节点上的工作负载
$ kubectl drain master03 --ignore-daemonsets --delete-local-data
- 停止Docker、Kubelet等服务
在其他集群Master节点运行
$ kubectl get nodes
查看K8s集群中Node节点状态
- 恢复Worker节点
-
```shell
# 停止Master节点上的服务
$ systemctl start docker
$ systemctl start etcd
$ systemctl start kubelet
# 在其他集群Master节点运行
$ kubectl get nodes
# 查看K8s集群中Node节点状态
- 允许Worker节点调度
- 允许Worker 节点调度的步骤与 Master 节点允许调度一致。
3.1.2.3 Kubernetes 集群启停
目的
本课程通过演示重启集群的过程,说明重启集群过程和注意事项,用于集群维护。
场景
在实际工作中,计划内的机房断电、断网等特殊情况可能发生,在此之前我们需要平滑地停止Kubernetes集群,在环境恢复正常后再平滑地启动集群,从而避免集群出现异常。
1、前提
- Kubernetes集群为使用kubekey安装
- 为了确保Kubernetes集群能够安全恢复,请在操作前对Kubernetes数据进行备份。详情请参考“备份与恢复”章节。
- 控制节点能够通过ssh使用root 用户登录到任何节点上并执行命令。
2、提示
- 重启集群为高风险操作,请确认是否必要且有完备的重启方案。
- 启停Kubernetes集群期间不要对集群进行任何其他操作。
- 重启后请认真检查集群状态,确保集群所有节点都已就绪。
3、K8s 集群启停类型与场景
- 集群启停
Kubernetes集群启停,用于紧急情况下停止集群,防止集群异常。
- 多集群启停
多集群即联邦集群,为Kubesphere提供的管理多个集群解决方案,多集群启停用于特殊情况下停止和恢复集群,防止集群异常,详情请看“多集群启停”。
4、操作概览
- 登录Kubernetes
- 控制节点备份数据
- 停止所有节点
停止etcd节点
$ etcdnodes=’master01 master02 master03’ $ for etcdnode in ${etcdnodes[@]};do echo “=== Stop etcd on $etcdnode ===”;ssh root@$etcdnode systemctl stop etcd;done
停止docker服务
$ for node in ${nodes[@]};do echo “=== Stop docker on $node ===”;ssh root@$node systemctl stop docker;done
- 恢复所有节点
-
```shell
$ nodes=$(kubectl get nodes -oname | awk -F[/] '{print $2}')
# 停止kubernetes kubelet
$ for node in ${nodes[@]};do echo "=== Stop kubelet on $node ===";ssh root@$node systemctl start kubelet;done
# 停止etcd节点
$ etcdnodes='master01 master02 master03'
$ for etcdnode in ${etcdnodes[@]};do echo "=== Stop etcd on $etcdnode ===";ssh root@$etcdnode systemctl start etcd;done
# 停止docker服务
$ for node in ${nodes[@]};do echo "=== Stop docker on $node ===";ssh root@$node systemctl start docker;done
查看集群节点etcd状态
$ etcdctl —endpoints=${ETCD_LISTEN_CLIENT_URLS} \ —ca-file=${ETCD_TRUSTEN_CA-FILE} \ —cert-file=${ETCD_CERT_FILE} \ —key-file=${ETCD_KEY_FILE} \ cluster-health
- 常见问题排查
> - ETCD集群启动失败
> - 部分节点加入集群失败
> - 部分pod不断重启
<a name="58381ce6"></a>
##### 3.1.3 在 KubeSphere 中调试应用
目的:了解常见的 KubeSphere 的排错工具和方法
场景:在实际工作中,您部署的应用会发生一些问题,我们可以通过工具查看日志,分析事件来进行排查。在本次课程中,我们将通过模拟故障来进行演示。
本次用于演示的KS 是在QingCloud公有云上搭建的5节点集群(3Master + 2 Worker )
KubeSpere 版本为V3.0.0
本次实验环境您可以参考在线指南:
参考Deploy KubeSphere on QingCloud lnstance章节来部署环境。
参考Role and Member Management创建好项目管理员并绑定项目
操作概览
- 登录Kubesphere容器平台
- 创建一个部署,并增加健康检查
- 创建一个服务并绑定容器,nodeport 外网访问方式
- 模拟故障
- 使用工具箱查看日志、调度情况和事件
所使用的 yaml 文件
```yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: nginx
namespace: demo-project
labels:
app: nginx
annotations:
deployment.kubernetes.io/revision: '1'
kubesphere.io/creator: admin
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
creationTimestamp: null
labels:
app: nginx
spec:
volumes:
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: container-5vr093
image: nginx
ports:
- name: tcp-80
containerPort: 80
protocol: TCP
resources:
limits:
cpu: '1'
memory: 200Mi
volumeMounts:
- name: host-time
readOnly: true
mountPath: /etc/localtime
livenessProbe:
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 5
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 10
timeoutSeconds: 1
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
serviceAccountName: default
serviceAccount: default
securityContext: {}
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
通过本节课程,您了解了Kubesphere容器平台应用增加健康检查的方法,并了解了如何利用日志和事件工具来进行定位问题。
3.1.4 KubeSphere 应用调度
目的
本课程通过定向调度策略将应用部署在指定的宿主机上。
场景
在实际环境中,不同的服务会对资源有不同的要求,根据实际需求,我们需要将这些应用部署到特定的服务器,从而提升服务性能和服务器资源使用率。
应用调度类型与场景
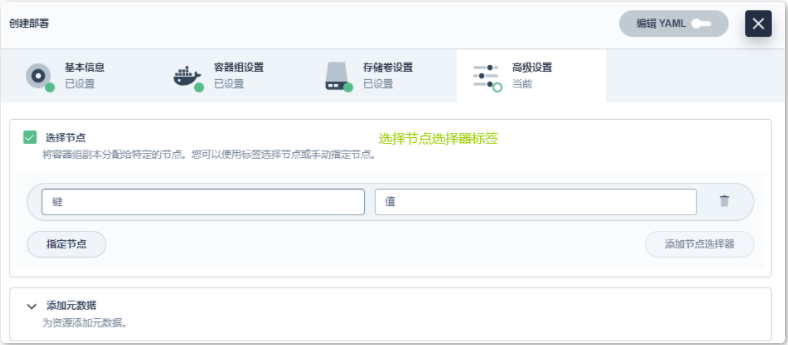
- nodeSelector定向调度
nodeSelector.是节点选择约束的最简单推荐形式。nodeSelector是 PodSpec.的个字段。通过设置label相关策略将pod关联到对应label的节点上。
- nodeName定向调度
nodeName是节点选择约束的最简单方法,但是由于其自身限制,通常不使用它。nodeName是 PodSpec.的一个字段。如果指定nodeName,,调度器将优先在指定的node 上运行pod。
- nodeAffinity定向调度
nodeAffinity,类似于nodeSelector,使用nodeAttinlty.可以根据卫m的 labelS PR制Pod 能够调度到哪些节点,当前nodeAffinity有软亲和性和硬亲和性两种类型,
节点亲和性与nodeSelector.相比,亲和/反亲和功能极大地扩展了可以表达约束的类型。增强了如下能力︰
- 语言更具表现力
- 在调度器无法满足要求时,仍然调度该pod
操作概览
- 登录KubeSphere
- 给worker节点添加label
- 使用nodeSelector调度应用
- 使用nodeName.调度应用
- 使用Affinity调度应用
- 无法调度异常排查
kind: Deployment
apiVersion: apps/v1
metadata:
name: nodename-assign-pod
namespace: demo-project
labels:
app: nodename-assign-pod
annotations:
deployment.kubernetes.io/revision: '2'
kubesphere.io/creator: admin
spec:
replicas: 1
selector:
matchLabels:
app: nodename-assign-pod
template:
metadata:
creationTimestamp: null
labels:
app: nodename-assign-pod
spec:
containers:
- name: container-4cp83l
image: nginx
ports:
- name: tcp-80
containerPort: 80
protocol: TCP
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
serviceAccountName: default
serviceAccount: default
nodeName: master02 # 需要添加的类型
securityContext: {}
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
- 可以根据Pod的亲和性和反亲和性进行调度
亲和性:软亲和性就代表即使Node节点不符合标准也可以进行调度,属于是尽可能的进行调度。软亲和性主要设置权重,使Pod更倾向于运行在匹配的节点上。当没有节点满足亲和性要求时,Pod将会运行在其他的节点上。
kind: Deployment
apiVersion: apps/v1
metadata:
name: nodeaffinity-assign-pod
namespace: demo-project
labels:
app: nodeaffinity-assign-pod
annotations:
deployment.kubernetes.io/revision: '1'
kubesphere.io/creator: admin
spec:
replicas: 1
selector:
matchLabels:
app: nodeaffinity-assign-pod
template:
metadata:
creationTimestamp: null
labels:
app: nodeaffinity-assign-pod
spec:
volumes:
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: container-urhi1n
image: nginx
ports:
- name: tcp-80
containerPort: 80
protocol: TCP
resources:
limits:
cpu: '1'
memory: 1Gi
requests:
cpu: '1'
memory: 1Gi
volumeMounts:
- name: host-time
readOnly: true
mountPath: /etc/localtime
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
serviceAccountName: default
serviceAccount: default
securityContext: {}
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions: # 匹配节点标签env:dev
- key: env
operator: In
values:
- dev
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
- 通过增加Deployment的副本数,可以发现当指定的节点没有足够的资源时,Pod 仍然会调度到其他的节点中。
亲和性:硬亲和性只会将Pod部署在满足亲和性要求的节点上
kind: Deployment
apiVersion: apps/v1
metadata:
name: nodeaffinity-assign-pod
namespace: demo-project
labels:
app: nodeaffinity-assign-pod
annotations:
deployment.kubernetes.io/revision: '2'
kubesphere.io/creator: admin
spec:
replicas: 1
selector:
matchLabels:
app: nodeaffinity-assign-pod
template:
metadata:
creationTimestamp: null
labels:
app: nodeaffinity-assign-pod
spec:
volumes:
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: container-urhi1n
image: nginx
ports:
- name: tcp-80
containerPort: 80
protocol: TCP
resources:
limits:
cpu: '1'
memory: 1Gi
requests:
cpu: '1'
memory: 1Gi
volumeMounts:
- name: host-time
readOnly: true
mountPath: /etc/localtime
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
serviceAccountName: default
serviceAccount: default
securityContext: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬亲和
nodeSelectorTerms:
- matchExpressions:
- key: env
operator: In
values:
- test
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
- Pod 只会调度到指定的Node节点,当节点的资源不足时,将不会进行调度。Pod也将无法创建
3.1.5 创建并部署 WordPress
Reference:创建并部署 WordPress (kubesphere.com.cn)
WordPress(使用 PHP 语言编写)是免费、开源的内容管理系统,用户可以使用 WordPress 搭建自己的网站。完整的 WordPress 应用程序包括以下 Kubernetes 对象,由 MySQL 作为后端数据库。

步骤 1:创建密钥
创建 MySQL 密钥
环境变量 WORDPRESS_DB_PASSWORD 是连接到 WordPress 数据库的密码。在此步骤中,您需要创建一个密钥来保存将在 MySQL Pod 模板中使用的环境变量。
- 使用
project-regular帐户登录 KubeSphere 控制台,访问demo-project的详情页并导航到配置。在保密字典中,点击右侧的创建。 - 输入基本信息(例如,将其命名为
mysql-secret)并点击下一步。在下一页中,选择类型为 Opaque(默认),然后点击添加数据来添加键值对。输入如下所示的键 (Key)MYSQL_ROOT_PASSWORD和值 (Value)123456,点击右下角 √ 进行确认。完成后,点击创建按钮以继续。
创建 WordPress 密钥
按照以上相同的步骤创建一个名为 wordpress-secret 的 WordPress 密钥,输入键 (Key) WORDPRESS_DB_PASSWORD 和值 (Value) 123456。创建的密钥显示在列表中。
步骤 2:创建存储卷
- 访问存储下的存储卷,点击创建。
- 输入卷的基本信息(例如,将其命名为
wordpress-pvc),然后点击下一步。 - 在存储卷设置中,需要选择一个可用的存储类型,并设置访问模式和存储卷容量。您可以直接使用默认值,点击下一步继续。
- 在高级设置中,您无需添加额外的配置,点击创建完成即可。
步骤 3:创建应用程序
添加 MySQL 后端组件
- 导航到应用负载下的应用,选择自制应用 > 创建。
- 输入基本信息(例如,在应用名称一栏输入
wordpress),然后点击下一步。 - 在服务设置中,点击创建服务以在应用中设置组件。
- 设置组件的服务类型为有状态服务。
- 输入有状态服务的名称(例如 mysql)并点击下一步。
- 在容器组设置中,点击添加容器。
- 在搜索框中输入
mysql:5.6,按下回车键,然后点击使用默认端口。由于配置还未设置完成,请不要点击右下角的 √ 按钮。
备注
在高级设置中,请确保内存限制不小于 1000 Mi,否则 MySQL 可能因内存不足而无法启动。 - 向下滚动到环境变量,点击引用配置文件或密钥。输入名称
MYSQL_ROOT_PASSWORD,然后选择资源mysql-secret和前面步骤中创建的密钥MYSQL_ROOT_PASSWORD,完成后点击 √ 保存配置,最后点击下一步继续。 - 选择存储卷设置中的添加存储卷模板,输入存储卷名称 (
mysql) 和挂载路径(模式:读写,路径:/var/lib/mysql)的值。
完成后,点击 √ 保存设置并点击下一步继续。 - 在高级设置中,可以直接点击添加,也可以按需选择其他选项。
- 现在,MySQL 组件已经添加完成。
添加 WordPress 前端组件
- 再次点击创建服务,选择无状态服务。输入名称
wordpress并点击下一步。 - 与上述步骤类似,点击添加容器,在搜索栏中输入
wordpress:4.8-apache并按下回车键,然后点击使用默认端口。 - 向下滚动到环境变量,点击引用配置文件或密钥。这里需要添加两个环境变量,请根据以下截图输入值:
- 对于
WORDPRESS_DB_PASSWORD,请选择在步骤 1 中创建的wordpress-secret和WORDPRESS_DB_PASSWORD。 - 点击添加环境变量,分别输入
WORDPRESS_DB_HOST和mysql作为键 (Key) 和值 (Value)。
- 对于
警告
对于此处添加的第二个环境变量,该值必须与步骤 5 中创建 MySQL 有状态服务设置的名称完全相同。否则,WordPress 将无法连接到 MySQL 对应的数据库。
点击 √ 保存配置,再点击下一步继续。
- 在存储卷设置中,点击挂载存储卷,并选择存储卷。
- 选择上一步创建的
wordpress-pvc,将模式设置为读写,并输入挂载路径/var/www/html。点击 √ 保存,再点击下一步继续。 - 在高级设置中,可以直接点击添加创建服务,也可以按需选择其他选项。
- 现在,前端组件也已设置完成。点击下一步继续。
- 您可以路由设置中设置路由规则(应用路由 Ingress),也可以直接点击创建。
- 创建后,应用将显示在应用列表中。
步骤 4:验证资源
在工作负载中,分别检查部署和有状态副本集中 wordpress-v1 和 mysql-v1 的状态。如果它们的运行状态为运行中,就意味着 WordPress 已经成功创建。
步骤 5:通过 NodePort 访问 WordPress
- 若要在集群外访问服务,请首先导航到服务。点击
wordpress右侧的三个点后,选择编辑外部访问。 - 在访问方式中选择
NodePort,然后点击确定。 - 点击服务进入详情页,可以在端口处查看暴露的端口。
- 通过
{Node IP}:{NodePort}访问此应用程序,可以看到下图:
备注
在访问服务之前,请确保安全组中的端口已打开。
3.2 Helm 及 Helm 应用仓库简介
- Helm 及应用仓库简介
- 如何开发一个 Helm 应用
- KubeSphere 应用开发
- 应用仓库管理
- 应用管理
3.2.1 Helm 及应用仓库简介
在 Helm 之前,用户如果需要在K8S部署应用,用户首先需要编写一系列的源码文件,这些源码文件包含这些应用所需要的所有资源,比如运行环境,所需要的类型,暴露的端口等。并且容易部署出错,即时部署成功,也会再后续的版本更新迭代中容易出错。
- Helm 是 Kubernetes 的包管理器
- 类似于 Ubuntu 的 apt-get,CentOS 的 yum,用于管理Charts
- Helm Charts 是用来封装 Kubernetes 应用程序的一系列 YAML 文件
- 安装 Helm
- 在 https://github.com/helm/helm 上下载二进制文件
将二进制文件拷贝到操作系统的环境变量中。
# 直接执行安装
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
- 应用仓库:管理和分发 Helm Charts
安装 Harbor
# Step1:添加一个chart 仓库
$ helm repo add bitnami https://charts.bitnami.com/bitnami
$ helm repo add harbor https://helm.goharbor.io
# Step2:下载远程安装包到本地
$ helm fetch harbor/harbor
$ ls
harbor-1.8.1.tgz
$ tar -xvf harbor-1.8.1.tgz
$ cd harbor/
# Step3:修改values.yaml
$ vim values.yaml
expose:
type: nodePort
tls:
enabled: false
...
nodePort:
ports:
http:
port: 80
nodePort: 30882
https:
port: 443
nodePort: 30883
externalURL: http://<本机IP地址>:30882
# 查看模板信息
$ helm template .
# /etc/hosts 文件修改
tee >> /etc/hosts <<-'EOF'
# Harbor hosts BEGIN
10.0.0.51 harbor
# Harbor hosts END
EOF
# Step4:安装harbor并且为此创建一个harbor命名空间
$ cd ..
$ kubectl create namespace harbor
$ helm install my-harbor harbor -n harbor
NAME: my-harbor
LAST DEPLOYED: Fri Feb 11 10:23:23 2022
NAMESPACE: harbor
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Please wait for several minutes for Harbor deployment to complete.
Then you should be able to visit the Harbor portal at
For more details, please visit https://github.com/goharbor/harbor
$ helm list -n harbor
# 直到 harbor 命名空间中Pod全部running
$ kubectl get pod -n harbor
$ kubectl get svc -n harbor
# Step5:登录Harbor,默认账号密码:admin/Harbor12345
# 若登录有问题,需要修改values.yaml
$ vim values.yaml
externalURL: http://192.168.0.9:30002 # 使用您自己的 IP 地址。
# 我们也可以用helm push命令把本地的chart推送到harbor:
# 添加helm push命令:
helm --help 查看push命令是否已经安装
helm plugin install https://github.com/chartmuseum/helm-push
# 或者我们可以把stable仓库的chart下载下来,push到我们自己的仓库中:
helm fetch stable/mysql
Reference:
https://helm.sh/zh/docs/helm/helm_push/
3.2.2 如何开发一个 Helm 应用
- helm create helllo-chart # 创建Chart目录
chart.yaml:声明了当前 Chart 的名称,版本等基本信息
values.yaml:提供应用安装的默认参数
tempates/:包含应用部署所需要的使用的YAML文件,比如:Deployment 和 Service等
charts/:当前 Charts 所依赖的其他Chart
- helm template hello-chart:渲染chart并输出
- helm install hello hello-chart/ -n default:安装hello-chart
- helm package hello-chart:打包Chart
将Chart推送到应用仓库
$ helm create hello-chart
Creating hello-chart
$ ls
hello-chart
$ cd hello-chart/
$ ls -l
total 16
drwxr-xr-x 2 root root 4096 Feb 11 14:14 charts # 当前 Charts 所依赖的其他Chart
-rw-r--r-- 1 root root 1147 Feb 11 14:14 Chart.yaml # 声明了当前 Chart 的名称,版本等基本信息
drwxr-xr-x 3 root root 4096 Feb 11 14:14 templates # 包含应用部署所需要的使用的YAML文件,比如:Deployment 和 Service等
-rw-r--r-- 1 root root 1878 Feb 11 14:14 values.yaml # 提供应用安装的默认参数
$ vim values.yaml
replicaCount: 2
# helm部署测试
$ helm install first-chart hello-chart/ -n default
# 查看helm部署状态
$ helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
first-chart default 1 2022-04-10 15:40:52.686849723 +0800 CST deployed hello-chart-0.1.0 1.16.0
$ kubectl get pod
$ kubectl get svc
# 测试访问
# 升级测试Helm
$ cd hello-chart/
$ vim Chart.yaml
version: 0.2.0
$ vim values.yaml
service:
type: NodePort
nodePort: 30888
$ vim templates/service.yaml
spec:
type: {{ .Values.service.type }}
ports:
- port: {{ .Values.service.port }}
targetPort: http
protocol: TCP
name: http
nodePort: {{ .Values.service.nodePort }}
$ helm upgrade first-chart hello-chart -ndefault
# 打包helm
$ helm package hello-chart
3.2.3 KubeSphere 应用全生命周期实践
- 应用生命周期:
- 开发中:开发中的
- 待发布:已开发完成,等待应用商店管理员审核通过
- 已审核通过:应用商店管理员审核通过
- 审核未通过:应用商店管理员审核通过
- 已上架:已经上架到应用商店
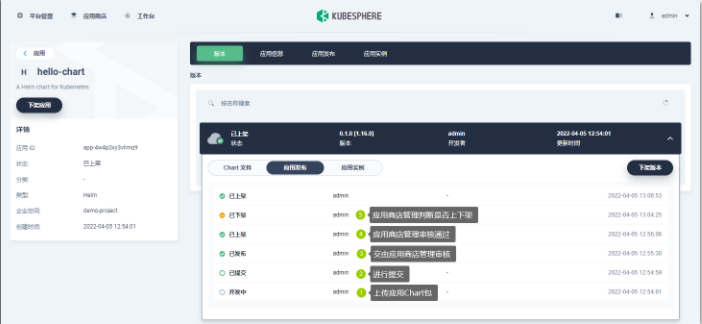
- 已下架:从应用商店下架
3.2.4 KubeSphere 应用仓库管理
Reference:
当您在 Kubernetes 上安装 KubeSphere 时,需要先在 cluster-configuration.yaml 文件中启用应用商店。
- 下载 cluster-configuration.yaml 文件,执行以下命令打开并编辑该文件。
vi cluster-configuration.yaml
- 在
cluster-configuration.yaml文件中,搜索openpitrix,并将enabled的false改为true。完成后保存文件。openpitrix: store: enabled: true # 将“false”更改为“true”。
- 执行以下命令开始安装: ```shell kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.2.1/kubesphere-installer.yaml
kubectl apply -f cluster-configuration.yaml
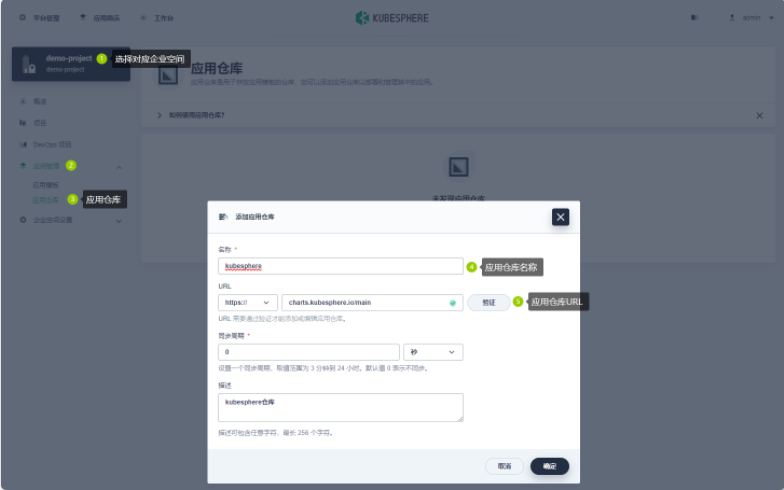
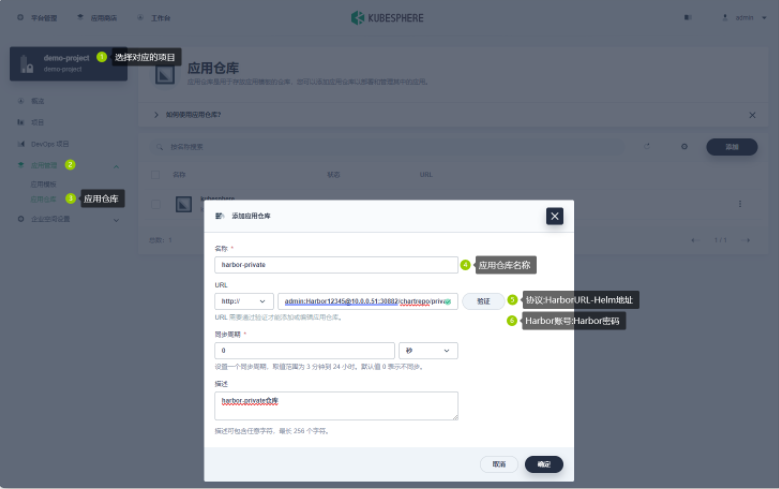
- 在企业空间中创建应用仓库
- 添加应用仓库
-
```http
- https://chart.kubesphere.io/main
- admin:Harbor12345@10.0.0.51:30882/chartrepo/privare
# 【使用的协议 http://】
- 手动更新应用仓库
- 应用仓库自动同步远程仓库
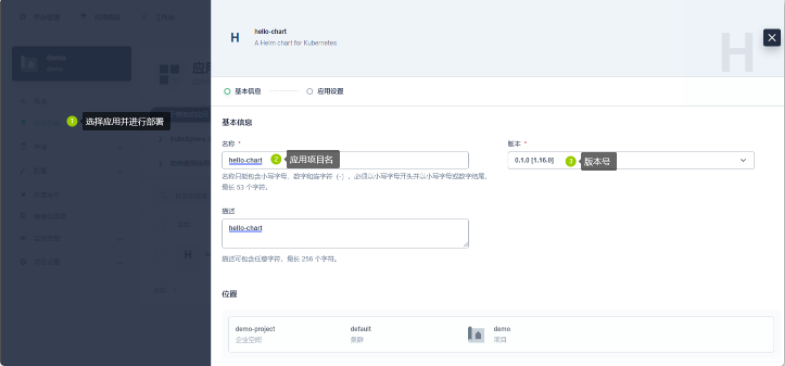
3.2.5 KubeSphere 应用管理场景
- 部署 hello-chart 应用
- 在KubeSphere 项目中进行应用部署
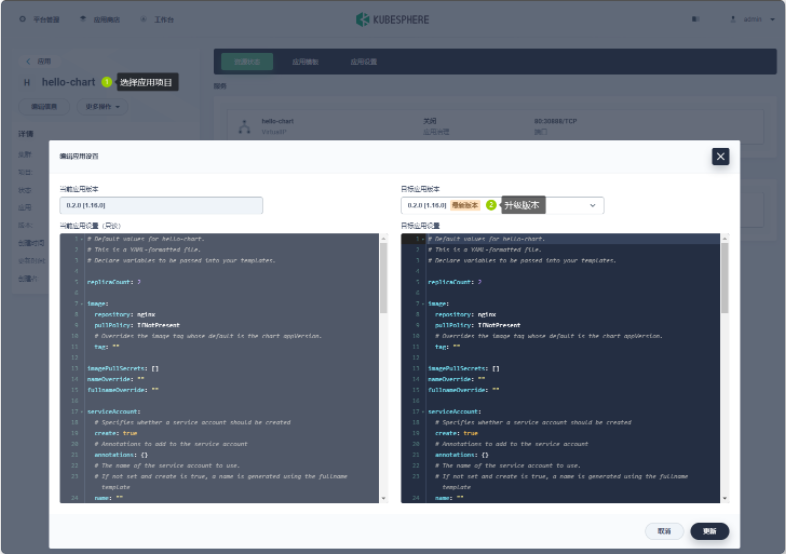
- 升级 hello-chart 应用
- 在KubeSphere 项目中进行应用升级

- 删除 hello-chart 应用
- KubeSphere 项目中进行应用删除
3.3 Kubernetes 多集群管理与使用
3.3.1 Kubernetes Federation 介绍
Kubernetes Federation v1 最早的多集群项目,由 K8s 社区提出和维护
Federation v1在Kubernetes v1.3左右时,就已经着手设计( Design Proposal ),并在后面几个版本中发布了相关的组件与命令行工具( kubefed ),用于帮助使用者快速建立联邦集群,并在Kubernetes v1.6时,进入了Beta阶段。
但Federation v1 在进入Beta 后,就没有更进一步的发展,一直到Kubernetes v1.11 左右正式被弃用( 由于灵活性和API成熟度的问题 )。主要原因有:
- 控制平面组件会因为发生问题,而影响整体集群效率;
- 无法兼容新的 Kubernetes API 资源
- 无法有效再多个集群管理权限,如不支持RBAC
- 联邦层级的设定与策略依赖API资源的 Annotations 内容,使得弹性不佳。
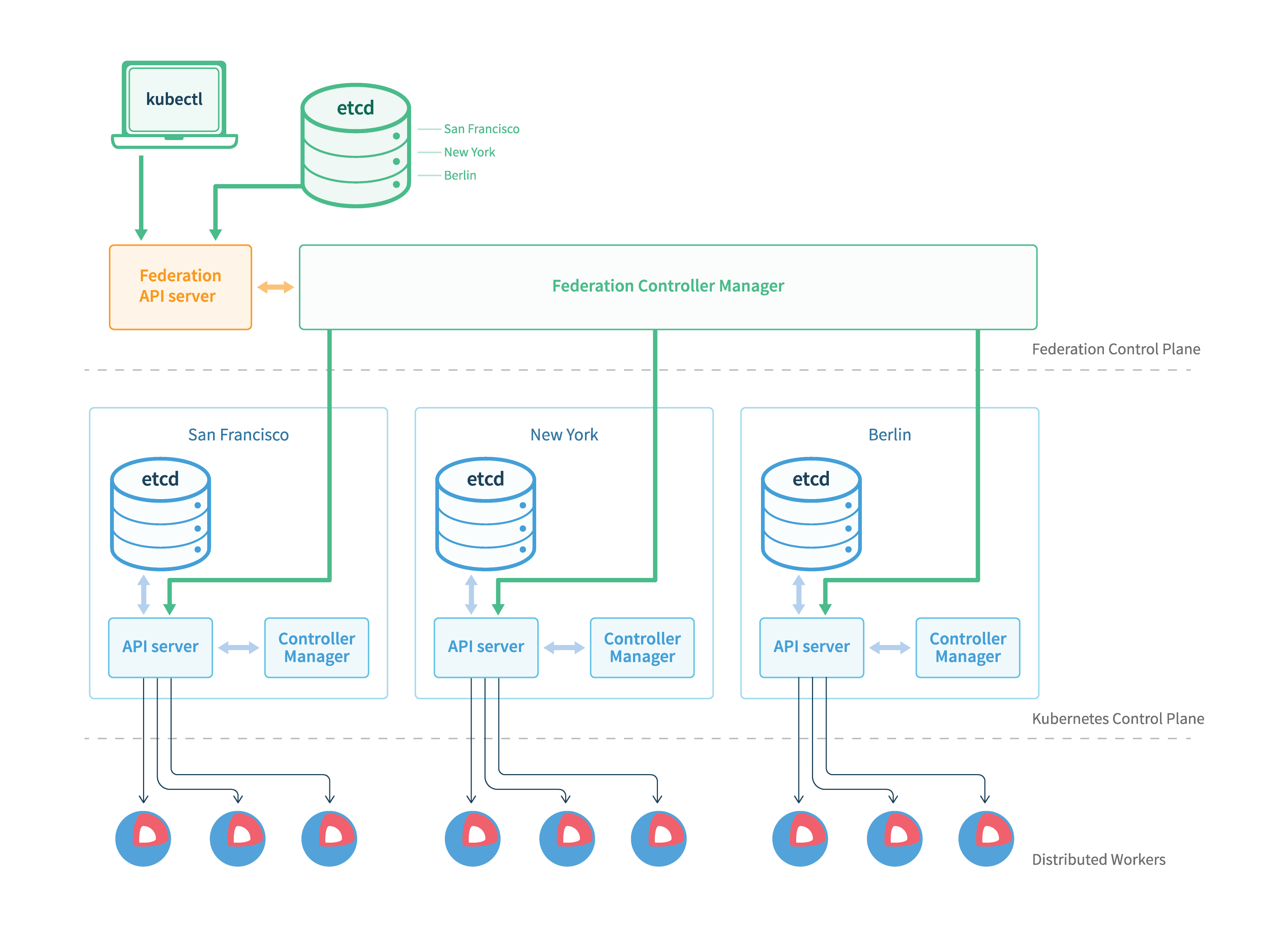
从上图架构中得知Federation v1 的设计沿用类似Kubernetes 控制平面架构,其主要组件有以下:
- federation-apiserver :提供Federation API资源,只支持部分Kubernetes API resources。
对外提供统一的资源管理入口 - federation-controller-manager :协调不同集群之间的状态,如同步Federated资源与策略,并建立Kubernetes组件至对应集群上。
提供多个集群之间的资源调度和状态同步 - etcd :储存Federation的状态。
与 Kubernetes etcd功能一致,只是专门为 Kuebrnetes Federation服务
在 v1 版本中我们要创建一个联邦资源的大致步骤如下:把联邦资源的所有配置信息都写到资源对象 annotations 里,整个创建流程与 K8s 类似,将资源创建到 Federation API Server,之后 Federation Controller Manager 会根据 annotations 里面的配置将该资源创建到各子集群中;下面一个 ReplicaSet 的示例:
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: nginx-us
annotations:
federation.kubernetes.io/replica-set-preferences: |
{
"rebalance": Ture,
"clusters": {
"us-east1-b": {
"minReplicas": 2,
"maxReplicas": 4,
"weight": 1
},
"us-contral1-b": {
"minReplicas": 2,
"maxReplicas": 4,
"weight": 1
}
}
}
spec:
replicas: 4
template:
metadata:
labels:
regions: nginx-us
spec:
containers:
name: nginx
image: nginx:1.19
v1 版本灵活性差,主要是每次新增一种联邦资源的类型的话,都是需要 federation:v1 仓库的提交新增的 rebalance 类型概念,federation 再来发布版本。资源对象会携带 federation.kubernetes.io/replica-set-preferences 注解类型的信息,十分的臃肿。缺少独立的 API 对象控制。
有了 v1 版本的经验和教训之后,社区提出了新的集群联邦架构:Federation v2。
Reference:
v2 版本利用 CRD 实现了整体功能,通过定义多种自定义资源(CR),从而省掉了 v1 中的 API Server;
v2 版本由两个组件构成:
- admission-webhook:提供了准入控制
- controller-manager:处理自定义资源以及协调不同集群的状态
在 v2 版本中创建一个联邦资源的大致流程如下: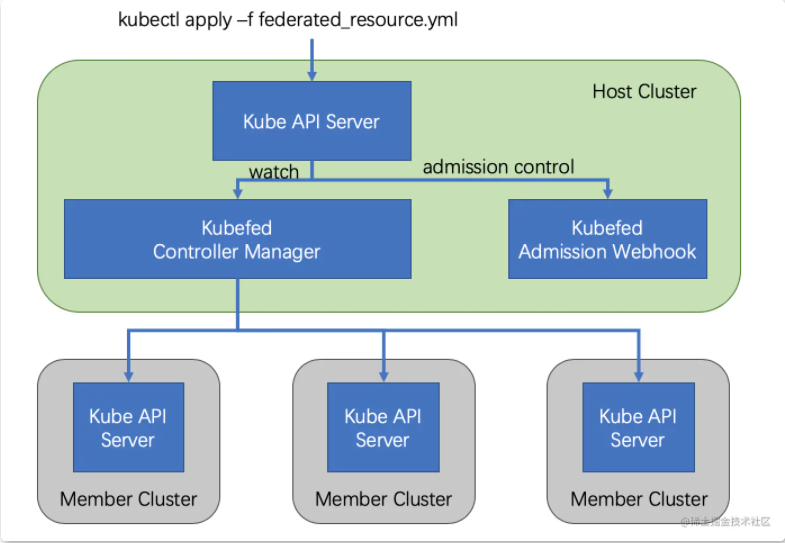
将 Federation Resource 创建到 Host 集群的 API Server 中,之后 controller manager 会介入将相应资源分发到不同的集群中,分发的规则等都卸载整个 Federation Resource 对象里面
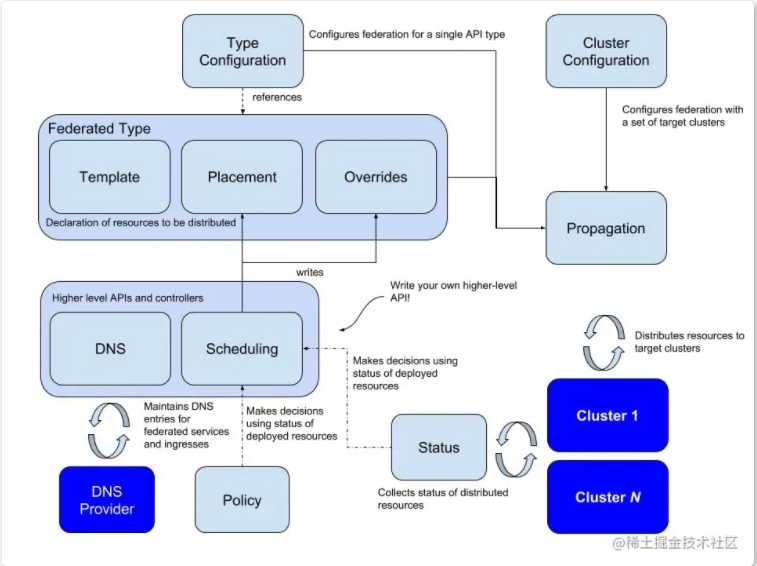
在逻辑上,Federation v2 分成两大部分:configuration(配置)和 propagation(分发);configuration 主要包含两个配置:Cluster Configuration(集群配置) 和 Type Configuration(类型配置)。
configuration 主要包含两个配置:
- Type configuration:用来描述将被联邦托管的资源类型
- Cluster configuration:用来保存被联邦托管的集群的 API 认证信息
对于 Type configuration,联邦 v2 是下足了功夫,包含三个关键部分:
- Templates 用于描述被联邦的资源
- Placement 用来描述将被部署的集群
- Overrides 允许对部分集群的部分资源进行覆写
- Cluster Configuration(集群配置):
保存被联邦集群托管的 API Server 资源信息。可以通过kubefedctl命令行工具进行 join 和 unjoin来加入和删除集群。会产生一个 KubeFedCluster CR 的自定义资源来存储集群的相关信息。主要有三个关键的资源信息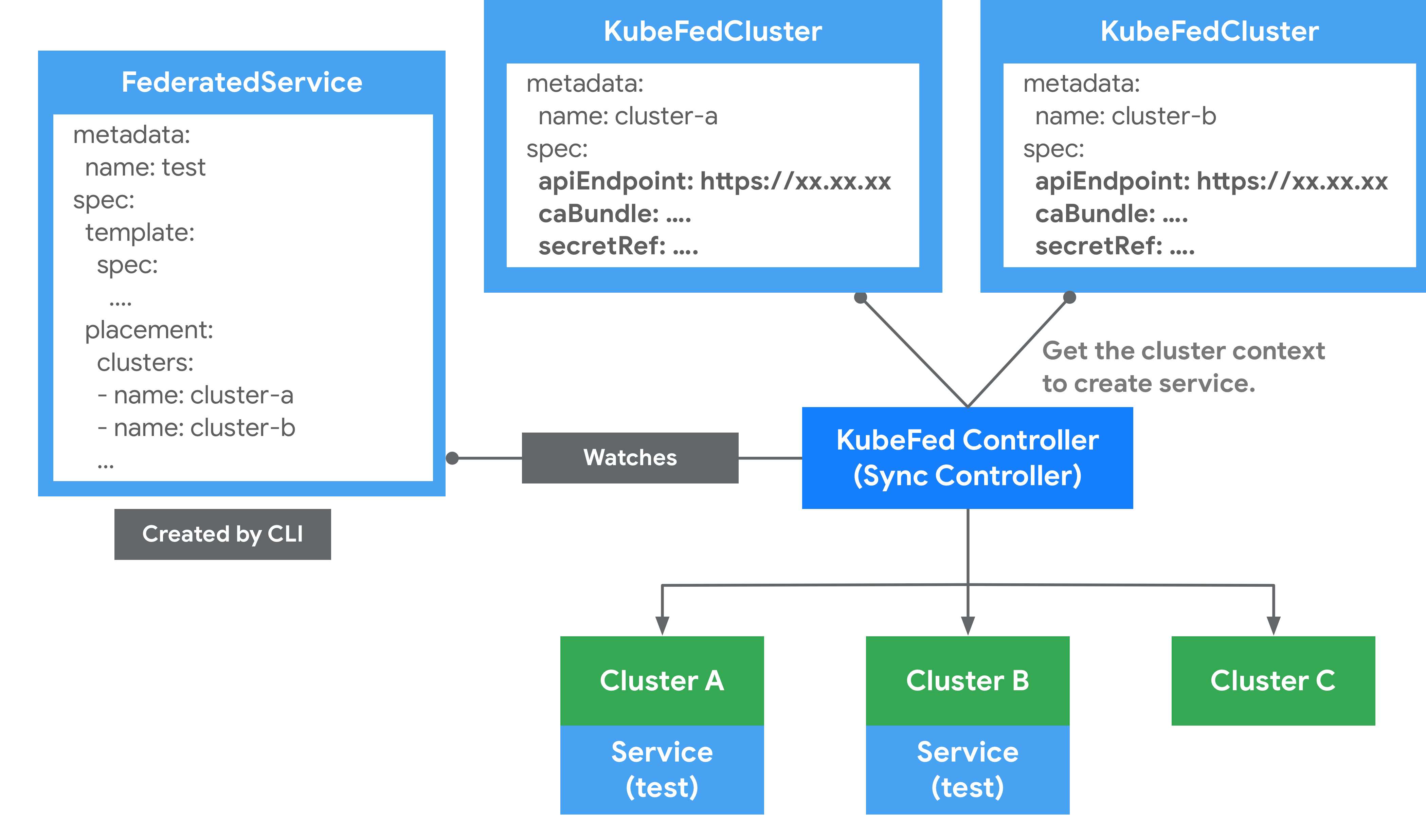
- apiEndpoint:被联邦集群托管的 API Server 地址
- caBundle:证书的信息
- secretRef:Token 的信息,访问 API Server 凭证的信息
在Federation 中,会区分Host 与Member 两种类型集群。
Type Configuration(类型配置):
针对要用于联邦集群管理的 K8s API 的定义。如果要新增加一种要被联邦集群托管的资源的话,就需要建立一个新的 Federation XX的CRD,用来描述对应资源的结构和分发策略(需要被分发到哪些集群上);Federation Resource CRD 主要包括三个部分:
- Templates 用于描述被联邦的资源
- Placement 用来描述将被部署的集群,若没有配置,则不会分发到任何集群中
- Overrides 允许对部分集群的部分资源进行覆写
kubefedctl join <集群名称> --cluster-context <要接入集群的 context 名称> --host-cluster-context <HOST 集群的 context>
- Host :用于提供KubeFed API与控制平面的集群。
- Member :通过KubeFed API注册的集群,并提供相关身份凭证来让KubeFed Controller能够存取集群。Host集群也可以作为Member被加入。
3.3.2 KubeSphere 多集群介绍
Kubernetes 从1.8 版本起就声称单集群最多可以支持 5000 个节点和 15万个 Pod,实际上应该很少有公司会部署如此庞大的一个单集群,很多情况下因为各种各样的原因我们可能会部署多个集群,但是又想将它们统一起来的管理,这个时候就需要用到集群联邦(Federation)。
集群联邦的一些典型应用场景:
- 高可用:在多个集群上部署应用,可以最大限度的减少集群故障带来的影响
- 避免厂商锁定:可以将应用负载发布在多个厂商的集群上并在有需要时直接迁移到其他厂商
- 故障隔离:拥有多个小集群可能会比单个大集群更有利于故障隔离。
KubeSphere 多集群中定义了两个概念,Host 集群指的是装了 kubefed 的集群,属于 Control Plane,Member 集群指的是被管控集群,Host 集群与 Member 集群之间属于联邦关系。
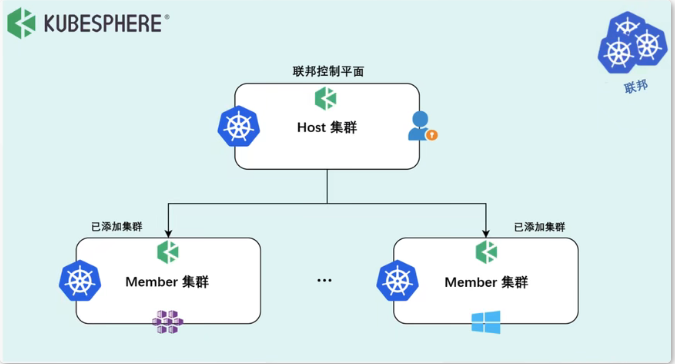
KubeSphere 提供了用户可以统一管理多个集群和增加新的集群WebUI界面。
KubeSphere 在导入集群的时候提供了两种方式:
- 第一种是直接连接,这种情况要求 Host 和 Member 集群网络可达,只需要提供一个 kubeconfig 文件就可以直接集群加入进来。
第二种是代理连接,对于 Host 集群到 Member 集群网络不可达的情况,目前 kubefed 还没有办法做到联邦,因此KubeSphere 开源了 Tower 组件,实现了私有云场景下集群联邦的管理,用于只需要在私有集群创建一个 agent 就可以实现集群联邦。
这里展示了 Tower 的工作流程。在 Member 集群内部起一个 agent 以后,Member 集群会去连接Host 集群的 Tower Server,Server 收到这个连接请求后会直接监听一个 Controller 预先分配好的端口,建立一个隧道,这样就可以通过这个隧道从 Host 集群往 Member 集群分发资源。
Proxy <------> Agent |--> ks-apiserver
|--> kube-apiserver
Reference:
3.3.2.1 直接连接
准备主成员集群
如果已经安装了独立的 KubeSphere 集群,您可以编辑集群配置,将 clusterRole 的值设置为 host。
- 选项 A - 使用 Web 控制台:
使用admin帐户登录控制台,然后进入集群管理页面上的 CRD,输入关键字ClusterConfiguration,然后转到其详情页面。编辑ks-installer的 YAML 文件,方法类似于启用可插拔组件。 - 选项 B - 使用 Kubectl:
kubectl edit cc ks-installer -n kubesphere-system
在ks-installer的 YAML 文件中,搜寻到multicluster,将clusterRole的值设置为host,然后点击确定(如果使用 Web 控制台)使其生效:
multicluster:
clusterRole: host
要设置主集群名称,请在 ks-installer 的 YAML 文件中的 multicluster.clusterRole 下添加 hostClusterName 字段:
multicluster:
clusterRole: host
hostClusterName: <主集群名称>
备注
- 建议您在准备主集群的同时设置主集群名称。若您的主集群已在运行并且已经部署过资源,不建议您再去设置主集群名称。
- 主集群名称只能包含小写字母、数字、连字符(-)或者半角句号(.),必须以小写字母或数字开头和结尾。
您需要稍等片刻待该更改生效。
您可以使用 kubectl 来获取安装日志以验证状态。运行以下命令,稍等片刻,如果主集群已准备就绪,您将看到成功的日志返回。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
准备成员集群
为了通过主集群管理,您需要使它们之间的 jwtSecret 相同。因此,您首先需要在主集群中执行以下命令来获取它。
kubectl -n kubesphere-system get cm kubesphere-config -o yaml | grep -v "apiVersion" | grep jwtSecret
命令输出结果可能如下所示:
jwtSecret: "ZnVMb2UuBtZ4jDmtSfTRjp9VnybOc6As"
如果已经安装了独立的 KubeSphere 集群,您可以编辑集群配置,将 clusterRole 的值设置为 member。
- 选项 A - 使用 Web 控制台:
使用admin帐户登录控制台,然后进入集群管理页面上的 CRD,输入关键字ClusterConfiguration,然后转到其详情页面。编辑ks-installer的 YAML 文件,方法类似于启用可插拔组件。 - 选项 B - 使用 Kubectl:
kubectl edit cc ks-installer -n kubesphere-system
在 ks-installer 的 YAML 文件中对应输入上面所示的 jwtSecret:
authentication:
jwtSecret: ZnVMb2UuBtZ4jDmtSfTRjp9VnybOc6As
向下滚动并将 clusterRole 的值设置为 member,然后点击确定(如果使用 Web 控制台)使其生效:
multicluster:
clusterRole: member
您需要稍等片刻待该更改生效。
您可以使用 kubectl 来获取安装日志以验证状态。运行以下命令,稍等片刻,如果已准备就绪,您将看到成功的日志返回。
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
导入成员集群
- 以
admin身份登录 KubeSphere 控制台,转到集群管理页面点击添加集群。 - 在导入集群页面,输入要导入的集群的基本信息。您也可以点击右上角的编辑模式以 YAML 格式查看并编辑基本信息。编辑完成后,点击下一步。
- 在连接方式,选择直接连接 Kubernetes 集群,复制 kubeconfig 内容并粘贴至文本框。您也可以点击右上角的编辑模式以 YAML 格式编辑的 kubeconfig。
备注请确保主集群的任何节点都能访问 kubeconfig 中的
server地址。
vim ~/.kube/config
- 点击创建,然后等待集群初始化完成。

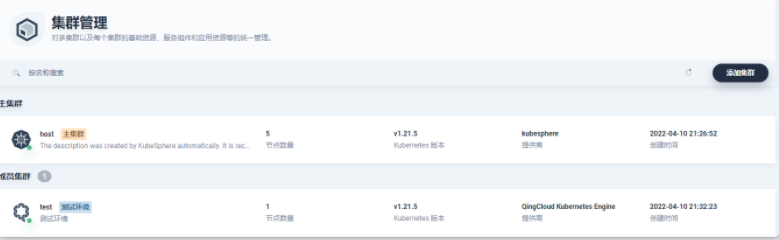
- KubeSphere 多集群连接管理
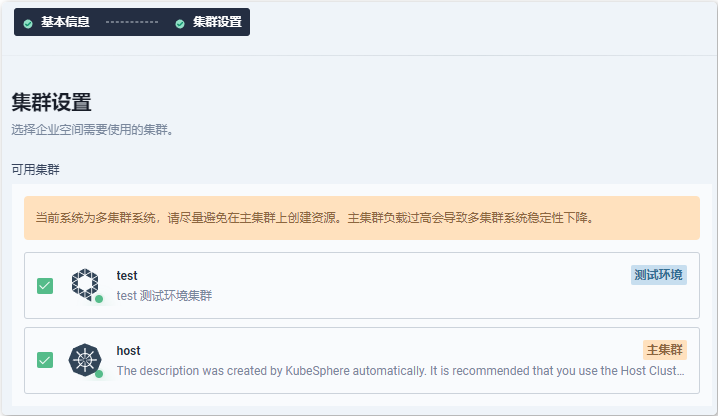
- 多集群连接成功
3.3.3 Kubernetes 跨多集群的应用发布
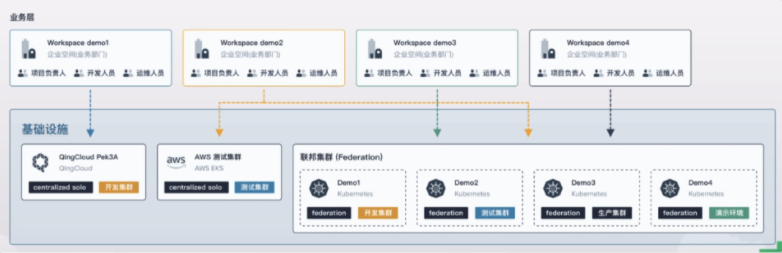
在KubeSphere 中企业空间是最小的租户单元,企业空间提供了跨集群、跨项目(即Kubernetes 中的命名空间)共享资源的能力。企业空间中的成员可以在授权集群中创建项目,并通过邀请授权的方式参与项目协同。
用户是KubeSphere的帐户实例,可以被设置为平台层面的管理员参与集群的管理,也可以被添加到企业空间中参与项目协同。
多级的权限控制和资源配额限制是KubeSphere 中资源隔离的基础,奠定了多租户最基本的形态。
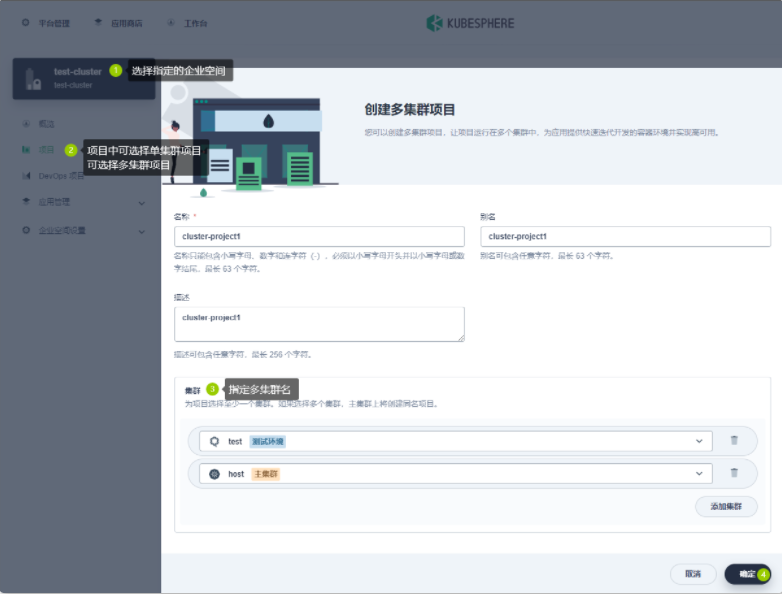
- 创建多集群企业空间
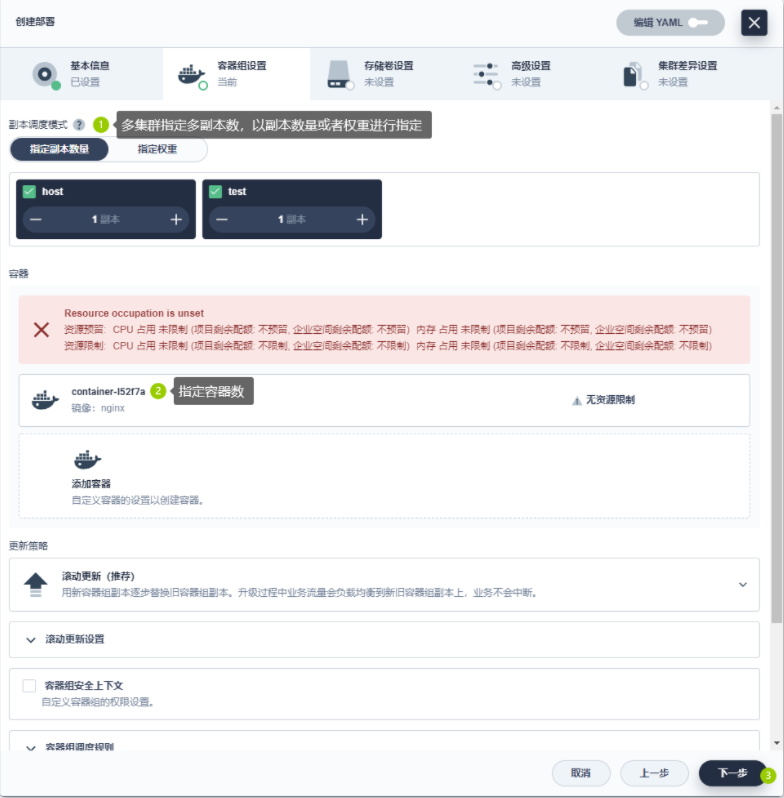
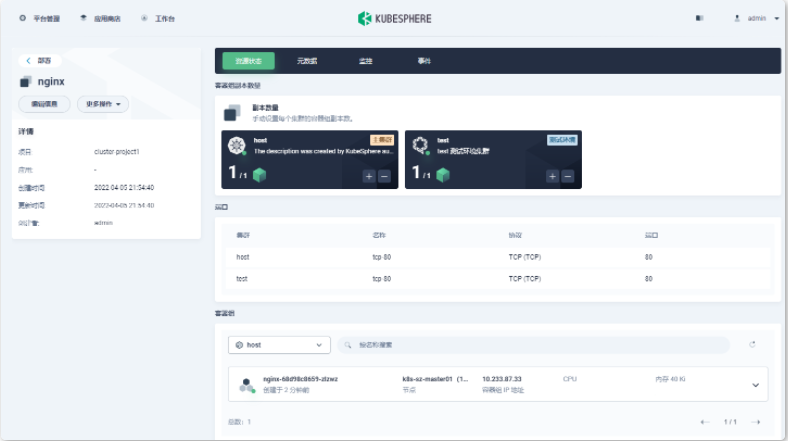
- 在多集群企业空间下创建多集群项目
4 微服务部署与流量治理
4.1 微服务最佳实践
4.1.1 Spring-cloud-kubernetes 基础概念
Spring Cloud微服务应用最为核心的部分包括服务注册中心、配置中心、应用网关等等。比如RuoYiCloud 就选择了nacos 作为微服务应用的服务注册中心和配置中心。
https://github.com/yangzongzhuan/RuoYi https://doc.ruoyi.vip/ruoyi-cloud/
大家熟知的spring cloud和K8s在核心功能上有很大一部分交集,比如K8s中 service 为我们提供了服务注册、负载均衡的能力,configmap和secret为我们提供了配置管理相关的功能,我们还可以使用ingress controller作为项目的网关,这些功能组件似乎在Spring cloud 中也有很多实际的应用,由此引申出我们接下来的课程。
我会以一个简短的demo进行展开,给大家带来Spring Cloud微服务在K8s 环境中的最佳实践,借助Spring Cloud社区开源的spring-cloud-kubernetes这个项目,我们可以将K8s 当作SpringCloud微服务应用的注册中心、配置中心,以此来简化微服务应用的整体架构,更好的和云原生环境进行融合。
对Spring Cloud还不太熟悉的同学可以先看看往期的课程。
spring-cloud-kubernetes是Spring Cloud社区为K8s环境,提供的开箱即用的服务发现、配置分发的方案。
该项目实现了的Spring Cloud中几个核心的接口,允许开发者在Kubernetes上构建和运行SpringCloud应用。贴出具体的项目链接,大家课后可以仔细阅读相关文档。
https://github.com/spring-cloud/spring-cloud-kubernetes
https://spring.io/projects/spring-cloud-kubernetes
4.1.1.1 Starters
通过导入spring-cloud-starter-kubernetes可以为我们提供开箱即用的功能,服务发现和配置管理两部分内容。可以通过添加不同的依赖包,启用不同的功能特性。
1.该项目实现了Springcloud中 Discovery Client 接口,可以从K8s的service中获取endpoint信息,实现服务注册与服务发现功能
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-fabric8</artifactId>
</dependency>
2.可以从K8s的ConfigMap、Secret中动态加载应用配置,并实现reload
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-config</artifactId>
</dependency>
3.一键启用所有特性
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-all</artifactId>
</dependency>
4.1.1.2 服务发现
其中spring-cloud-starter-kubernetes-fabric8 项目为Kubernetes提供了客户端服务发现的实现。可以从客户端按名称查询Kubernetes 中的service关联的endpoint(这里需要参考K8s中服务的相关概念),客户端如果运行在K8s集群中则可以直接访问这些endpoint,还可以在此基础之上实现负载均衡。
我们可以通过以下命令查看服务的具体信息,查看K8s 中service具体关联的endpoint。
kubectl get services
kubectl get endpoint
K8s通过service提供了服务发现(server side)的能力(请参阅:
https://kubernetes.io/docs/concepts/services-networking/service/#discovering-services)。使用原生的K8s 服务发现可确保与其他工具(如lstio)的兼容性,Istio是一种能够实现负载均衡、熔断器、故障切换等功能的服务网格工具,我的同事也会在本期课程中进行展开讲解。
服务的调用方只需要引用在集群中可以解析的域名,比如 kubernetes.default.svc。通常格式如下;
{service-name}.inamespace}.svc.icluster}.local
4.1.1.3 配置管理
通常我们会使用application.yaml、application-profile.yaml文件对Spring Boot应用进行配置,配置文件中包含了一些应用配置相关的键值对。
在K8s 中我们可以直接使用ConfigMap挂载配置文件到运行的pod中,或者使用spring-cloud-starter-kubernetes-fabric8-config 将对应的配置文件加载到应用程序中,配置文件还支持reload特性,可以在不重启情况下进行配置变更。
4.1.1.4 负载均衡
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-loadbalancer</artifactId>
</dependency>
该项目提供了基于K8s service、endpoint的负载均衡实现。
4.1.1.5 选主
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-kubernetes-leader</artifactId>
</dependency>
该项目使用K8s ConfigMap实现了Spring lntegration的选主API。
在多副本需要主备切换的情况下有非常大的帮助,不用从头去实现选主功能,极大的简化了开发工作。
4.1.2 在 KubeSphere 上部署 Spring Cloud 全家桶以及示例应用
4.2 Service Mesh 基础概念
4.2.1 微服务概念回顾
- 微服务概念回顾
- 传统微服务架构面临的挑战
- Service Mesh 概念与架构
- lstio核心对象解读
- KubeSphere服务网格实战
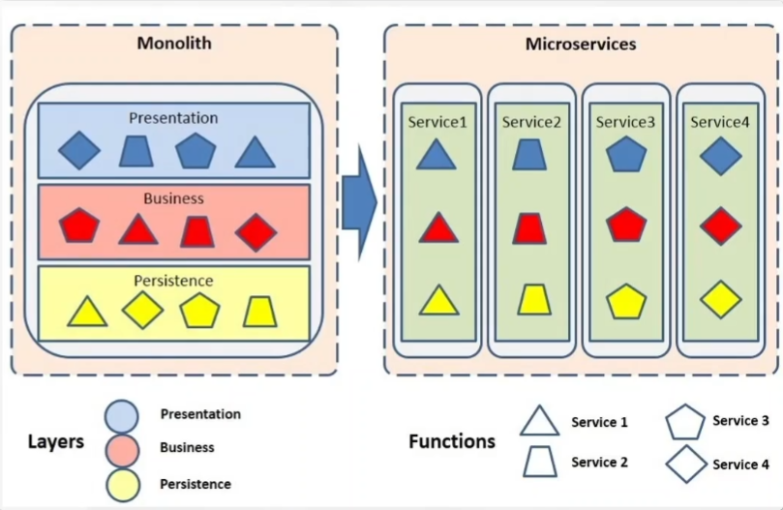
微服务,又叫微服务架构,是一种软件架构方式。它将应用构建成一系列按业务领域划分模块的、小的自治服务。
微服务的特点:
- 高度可维护和可测试性
- 松耦合
- 独立部署
- 围绕业务能力进行组织
4.2.2 传统微服务架构的挑战
SpringCloud、Dubbo、Tars、其他
- 过于绑定特定技术栈
- 多语言支持受限
- 代码侵入度过高
- 老旧系统维护难
4.2.3 Service Mesh 的概念和架构
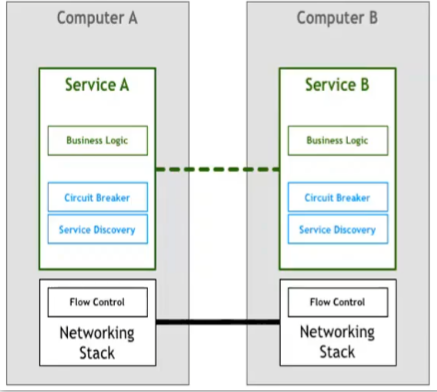
传统的微服务架构一般采用SDK的方式,让其基础设施功能成为一个SDK,使其业务代码进行解耦。当服务治理的相关组件从我们的应用中独立之后。
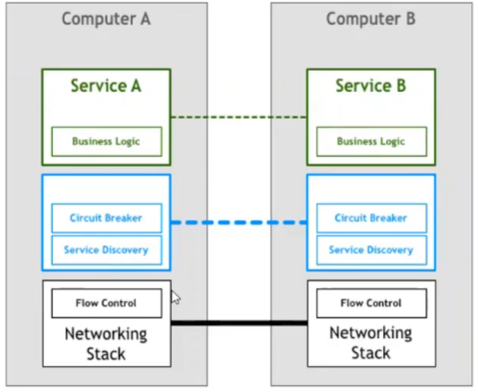
服务治理的相关组件是否能下沉到Spring底层,由于服务治理本身不属于操作系统,而且在操作系统层开发网络栈相对难度也十分大。
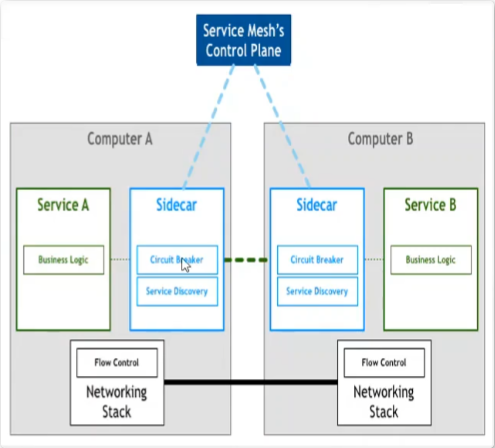
Sidecar 其实就是网络代理。业务的流入与流出以及网络请求首先由Sidecar 进行拦截。经过处理后在通过网络层进行转发;Sidecar 模式实现了对业务代码的0入侵。并且与开发语言和技术栈无关。实现了完全的隔离。为部署和升级带来了便利。
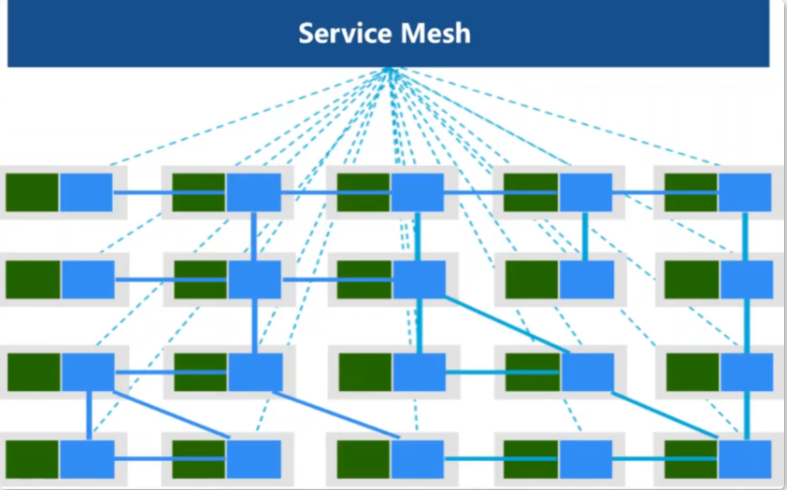
服务网格是用于处理服务间通信的专用基础设施层,它负责通过包含现代云原生应用程序的复杂服务拓扑来可靠地传递请求。实际上,服务网格通常通过一组轻量级网络代理来实现,这些代理与应用程序代码一起部署,而不需要感知应用程序本身。 ——Willian Morgan Buoyant CEO
4.2.4 Istio 实践
4.2.4.1 istio 简介
Istio 扩展了 Kubernetes,使用功能强大的 Envoy 服务代理建立一个可编程的、应用程序感知的网络。Istio 可同时使用 Kubernetes 和传统工作负载,为复杂的部署带来标准的通用流量管理、遥测和安全性。
流量管理:部署服务间路由、故障恢复和负载平衡等功能。
可观察性:提供流量和服务性能的端到端视图。
安全:跨服务参与加密、基于角色的访问和身份验证。
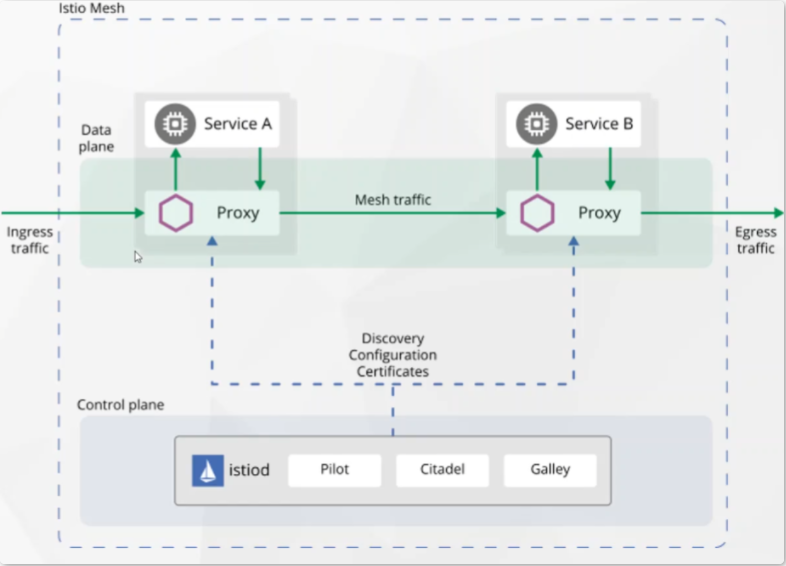
Istio 由控制平面和数据平面两部分组成。
- 数据平面 由一组智能代理(Envoy)组成,被部署为 Sidecar。这些代理负责协调和控制微服务之间的所有网络通信。它们还收集和报告所有网格流量的遥测数据。
- 控制平面 管理并配置代理来进行流量路由。
Istio 流量治理实现
- Istio 安装
- 创建服务端与客户端工作负载
- 实现灰度发布
4.2.4.2 istio 安装
# 查看kubectl版本
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.5", GitCommit:"aea7bbadd2fc0cd689de94a54e5b7b758869d691", GitTreeState:"clean", BuildDate:"2021-09-15T21:10:45Z", GoVersion:"go1.16.8", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.5", GitCommit:"aea7bbadd2fc0cd689de94a54e5b7b758869d691", GitTreeState:"clean", BuildDate:"2021-09-15T21:04:16Z", GoVersion:"go1.16.8", Compiler:"gc", Platform:"linux/amd64"}
$ curl -L https://istio.io/downloadIstio | ISTIO_VERSION=1.13.2 TARGET_ARCH=x86_64 sh -
- 安装目录包含:
samples/目录下的示例应用程序bin/目录下的[istioctl](https://istio.io/latest/zh/docs/reference/commands/istioctl)客户端二进制文件 .
- 将
istioctl客户端加入搜索路径(Linux or macOS):$ export PATH=$PWD/bin:$PATH
对于本次安装,我们采用 demo 配置组合。 选择它是因为它包含了一组专为测试准备的功能集合,另外还有用于生产或性能测试的配置组合。
istioctl install --set profile=demo -y
给命名空间添加标签,指示 Istio 在部署应用的时候,自动注入 Envoy 边车代理:
$ kubectl label namespace default istio-injection=enabled
namespace/default labeled
# 查看所有的istio-system资源
$ kubectl get all -n istio-system
# 安装额外的插件
$ kubectl apply -f samples/addons/
$ kubectl -n istio-system patch svc kiali -p '{"spec":{"type":"NodePort","ports":[{"port":20001,"protocal":"TCP","targetPort":20001,"nodePort":30001}]}}'
部署 [Bookinfo](https://istio.io/latest/zh/docs/examples/bookinfo/) 示例应用:
$ kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
# 重新运行前面的命令,在执行下面步骤之前,要等待并确保所有的 Pod 达到此状态: 就绪状态(READY)的值为 2/2 、状态(STATUS)的值为 Running 。 基于你平台的不同,这个操作过程可能会花费几分钟的时间。
# 验证方方面面均工作无误。运行下面命令,通过检查返回的页面标题,来验证应用是否已在集群中运行,并已提供网页服务:
$ kubectl exec "$(kubectl get pod -l app=ratings -o jsonpath='{.items[0].metadata.name}')" -c ratings -- curl -s productpage:9080/productpage | grep -o "<title>.*</title>"
$ kubectl get pod details-v1-79f774bdb9-lnbg6 -oyaml | less
# 把应用关联到 Istio 网关:
$ cat samples/bookinfo/networking/bookinfo-gateway.yaml
$ kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yaml
$ kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}'
# 访问http://NodePort:端口/productpage
curl http://10.0.0.51:30588/productpage
确保配置文件没有问题:
$ istioctl analyze
4.2.4.3 Bookinfo 演示
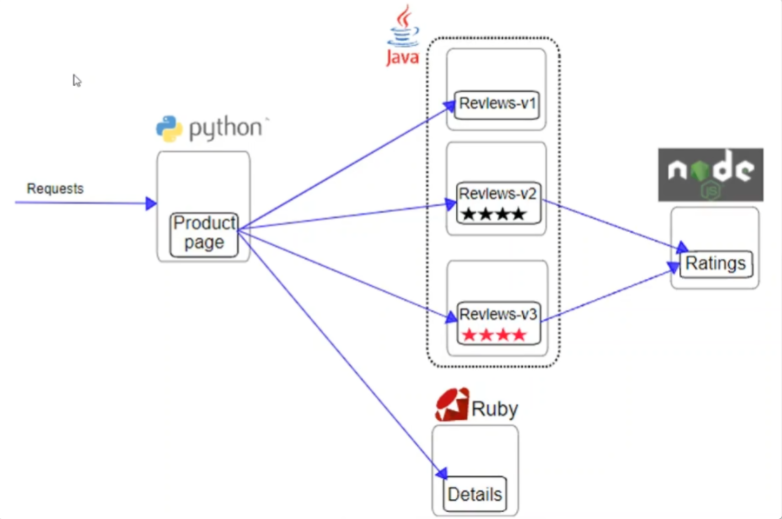
前端
- Product Page
后端
- Review
- Ratings
- Detail
Reference:https://github.com/istio/istio/tree/master/samples/bookinfo/src
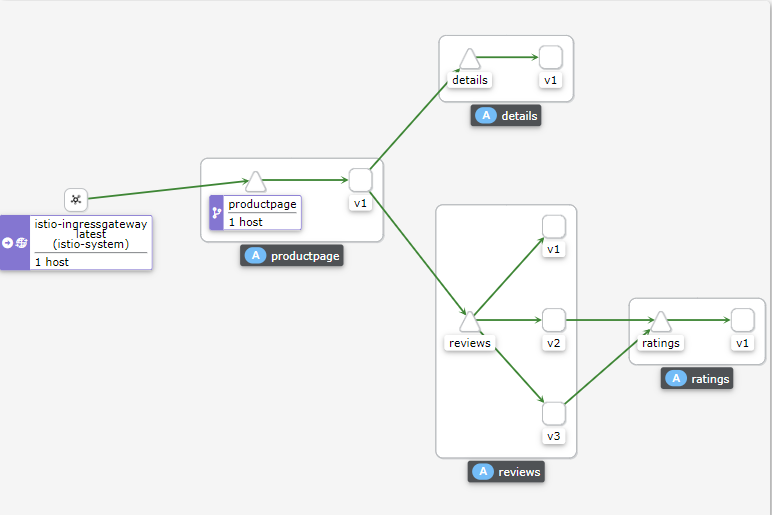
4.2.4.4 istio 核心概念解读
apiversion: networking.istio.io/v1alpha3
kind : virtualservice
metadata:
name: reviews
spec:
hosts:
- reviews
http:
- match:
- headers :
end-user:
exact: jason
route:
- destination:
host: reviews
subset: v2
- route:
- destination:
host: reviews
subset: v3
apiversion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: reviews-destination-rule
spec:
host: reviews
trafficPolicy:
loadealancer:
simple: RANDOM
subsets:
- name: v1
labels:
version: v1
- name: v2
labels:
version: v2
trafficPolicy:
loadBalancer:
simple: ROUND_ROBIN
- name: v3
labels:
version: v3
- 虚拟服务
- 目标规则
- 网关
- 服务入口
- Sidecar
4.2.4.5 虚拟服务于目标规则使用
$ kubectl get deployment --show-labels
NAME READY UP-TO-DATE AVAILABLE AGE LABELS
details-v1 1/1 1 1 18m app=details,version=v1
nginx-01 1/1 1 1 19d app=nginx-01
productpage-v1 1/1 1 1 18m app=productpage,version=v1
ratings-v1 1/1 1 1 18m app=ratings,version=v1
reviews-v1 1/1 1 1 18m app=reviews,version=v1
reviews-v2 1/1 1 1 18m app=reviews,version=v2
reviews-v3 1/1 1 1 18m app=reviews,version=v3
$ kubectl apply -f samples/bookinfo/networking/destination-rule-all.yaml
# istio 需要使用MutatingAdmissionWebhook,ValidatingAdmissionWebhook kube-apiserver的参数
- --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,DefaultTolerationSeconds,MutatingAdmissionWebhook,ValidatingAdmissionWebhook,ResourceQuota,NodeRestriction
- --enable-aggregator-routing=true
$ kubectl apply -f samples/bookinfo/networking/destination-rule-all.yaml
$ kubectl get destinationrules.networking.istio.io reviews -o yaml
$ kubectl apply -f samples/bookinfo/networking/virtual-service-all-v1.yaml
$ kubectl get virtualservices.networking.istio.io
$ kubectl apply -f samples/bookinfo/networking/virtual-service-reviews-test-v2.yaml
$ kubectl get virtualservices.networking.istio.io
4.3 Service Mesh 最佳实践
4.3.1 在 KubeSphere 上启用服务治理
$ kubectl -n kubesphere-system edit cc ks-installer
servicemesh:
enabled: true
# 输入以下命令以检查安装结果。
$ kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l app=ks-install -o jsonpath='{.items[0].metadata.name}') -f
admin 账号登录到 KubeSphere 平台中”系统组件”查看Istio 的功能是否健康运行
- 在 KubeSphere 平台创建新的项目
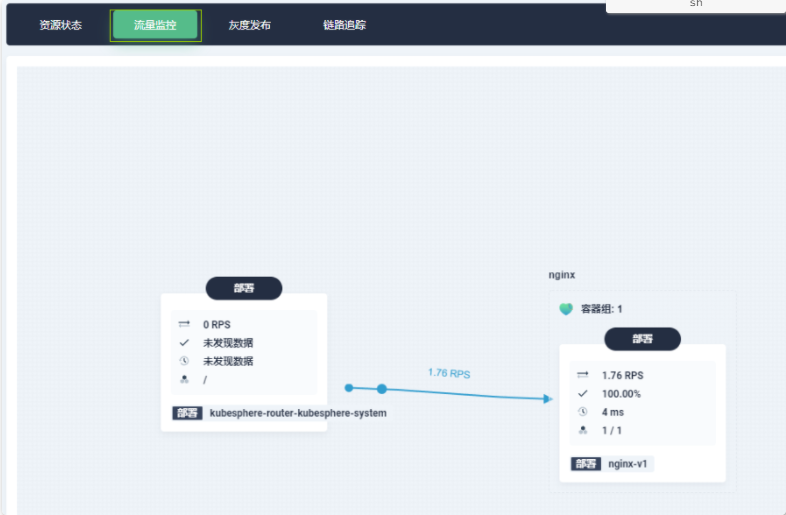
# 持续向服务发起请求
watch -n1 curl http://nginx.istio.10.0.0.200.nip.io:31291/
4.3.2 KubeSphere 灰度发布实践
Reference:
蓝绿部署
蓝绿部署会创建一个相同的备用环境,在该环境中运行新的应用版本,从而为发布新版本提供一个高效的方式,不会出现宕机或者服务中断。通过这种方法,KubeSphere 将所有流量路由至其中一个版本,即在任意给定时间只有一个环境接收流量。如果新构建版本出现任何问题,您可以立刻回滚至先前版本。

金丝雀发布
金丝雀部署缓慢地向一小部分用户推送变更,从而将版本升级的风险降到最低。具体来讲,您可以在高度响应的仪表板上进行定义,选择将新的应用版本暴露给一部分生产流量。另外,您执行金丝雀部署后,KubeSphere 会监控请求,为您提供实时流量的可视化视图。在整个过程中,您可以分析新的应用版本的行为,选择逐渐增加向它发送的流量比例。待您对构建版本有把握后,便可以把所有流量路由至该构建版本。

流量镜像
流量镜像复制实时生产流量并发送至镜像服务。默认情况下,KubeSphere 会镜像所有流量,您也可以指定一个值来手动定义镜像流量的百分比。常见用例包括:
- 测试新的应用版本。您可以对比镜像流量和生产流量的实时输出。
- 测试集群。您可以将实例的生产流量用于集群测试。
- 测试数据库。您可以使用空数据库来存储和加载数据。
5 Kubernetes 云原生可观测性
5.1 集群与应用日志
- 生产部署最佳实践
- 日志检索与日志落盘
- 常见问题和解决方法
5.1.1 生产部署最佳实践
Reference:KubeSphere 日志系统
KubeSphere为日志收集、查询和管理提供了一个强大的、全面的、易于使用的日志系统。它涵盖了不同层级的日志,包括租户、基础设施资源和应用。用户可以从项目、工作负载、容器组和关键字等不同维度对日志进行搜索。与Kibana相比,KubeSphere基于租户的日志系统中,每个租户只能查看自己的日志,从而可以在租户之间提供更好的隔离性和安全性。除了KubeSphere自身的日志系统,该容器平台还允许用户添加第三方日志收集器,如Elasticsearch、Kafka和l Fluentd。
日志收集路径如下:
从2.1.0版本开始,KubeSphere解耦了一些核心功能组件。这些组件设计成了可插拔式,您可以在安装之前或之后启用它们。如果您不启用它们,KubeSphere 会默认以最小化进行安装部署。
不同的可插拔组件部署在不同的命名空间中。您可以根据需求启用任意组件
安装示例:
- 单节点启用日志组件
- 单节点containerd环境启用日志组件
- 多节点启用日志组件
在 cluster-configuration.yaml 文件中,搜索 logging,并将 enabled 的 false 改为 true,以启用日志系统。完成后保存文件。
logging:
enabled: true # 将“false”更改为“true”。
containerruntime: docker
Fluent Bit是一个开源的日志处理器和转发器,它允许您从不同的来源收集任何数据,如指标和日志,用过滤器过滤它们,并将它们发送到多个目的地。
- 轻量
- 高性能
- 插件丰富
- ……
5.1.2 日志检索与落盘日志收集
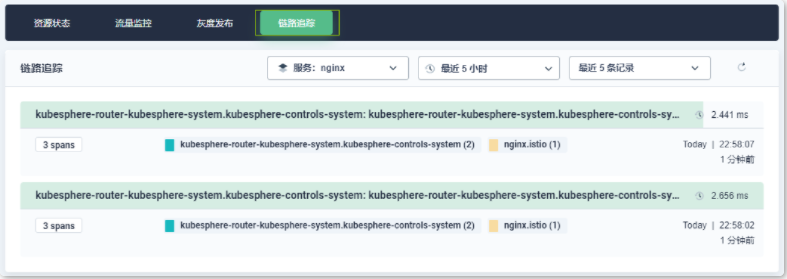
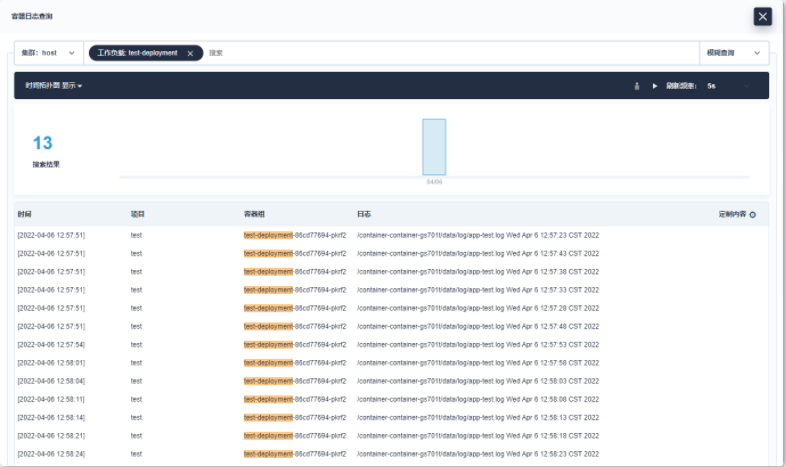
您可以从日志查询界面看到日志数量的时间直方图、集群选择下拉列表以及日志查询栏
您可以点击搜索栏并输入搜索条件,可以按照关键字、项目、工作负载、容器组、容器或时间范围搜索事件(例如,输入时间范围:最近10分钟来搜索最近10分钟的事件)。或者,点击时间直方图中的柱状图,KubeSphere会使用该柱状图的时间范围进行日志查询。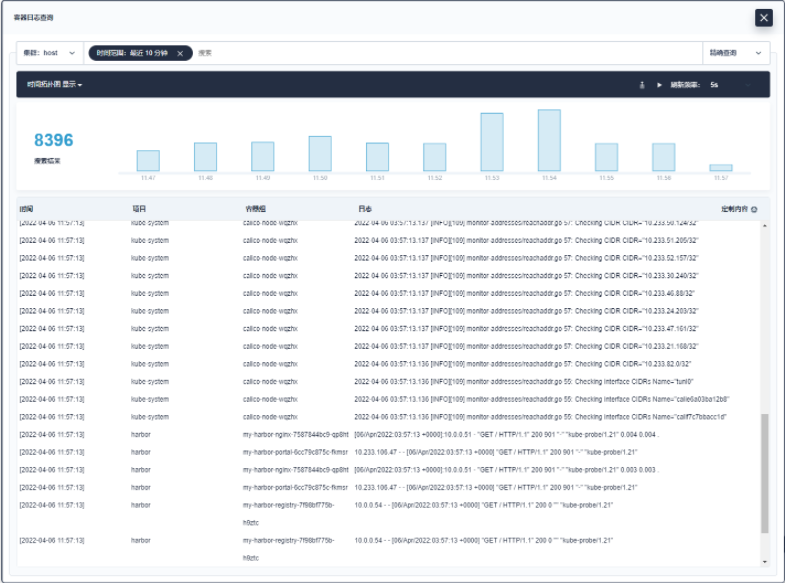
您可以输入多个条件来缩小搜索结果。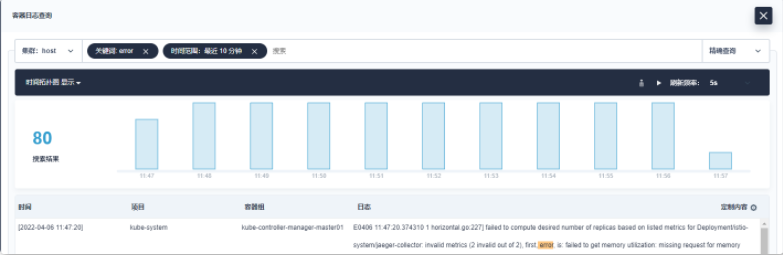
- 落盘日志收集功能:对于将日志以文件形式保存在 Pod 挂盘上的应用,支持开启落盘日志收集功能。
1.以 project-admin身份登录KubeSphere的 Web控制台,进入项目。
2.在左侧导航栏中,选择项目设置中的日志收集,点击已开启以启用该功能。
3.在左侧导航栏中,选择应用负载中的工作负载。在部署选项卡下,点击创建。
4.在出现的对话框中,设置部署的名称(例如 demo-deployment),再点击下一步。收
5.在容器组设置下,点击添加容器。
6.在搜索栏中输入alpine,以该镜像(标签:latest)作为示例。
7.向下滚动并勾选启动命令。在运行命令和参数中分别输入以下值,点击√,然后点击下一步。运行命令
/bin/sh
参数
-c,if [ ! -d /datalog ];then mkdir -p /data/log,fi; while true; do date >>/data/log/app-test.log; sleep 30;done
8.在存储卷设置选项卡下,切换启用收集存储卷上的日志,点击挂载存储卷。
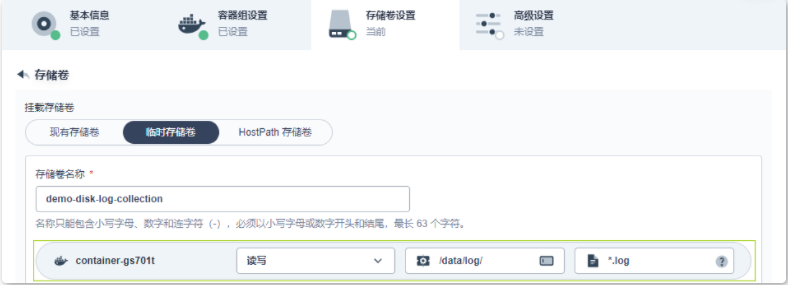
9.在临时存储卷选项卡下,输入存储卷名称(例如 demo-disk-log-collection),并设置访问模式和路径。点击√,然后点击下一步继续。
10.点击高级设置中的创建以完成创建。
5.1.3 常见问题以及解决方法
Reference:日志 (kubesphere.com.cn)
5.1.3.1 如何将日志存储改为外部 Elasticsearch 并关闭内部 Elasticsearch
如果您使用的是 KubeSphere 内部的 Elasticsearch,并且想把它改成您的外部 Elasticsearch,请按照以下步骤操作。如果您还没有启用日志系统,请参考 KubeSphere 日志系统直接设置外部 Elasticsearch。
- 首先,请执行以下命令更新 KubeKey 配置:
kubectl edit cc -n kubesphere-system ks-installer
- 将
es.elasticsearchDataXXX、es.elasticsearchMasterXXX和status.logging的注释取消,将es.externalElasticsearchUrl设置为 Elasticsearch 的地址,将es.externalElasticsearchPort设置为其端口号。以下示例供您参考:apiVersion: installer.kubesphere.io/v1alpha1 kind: ClusterConfiguration metadata: name: ks-installer namespace: kubesphere-system ... spec: ... common: es: # elasticsearchDataReplicas: 1 # elasticsearchDataVolumeSize: 20Gi # elasticsearchMasterReplicas: 1 # elasticsearchMasterVolumeSize: 4Gi elkPrefix: logstash logMaxAge: 7 externalElasticsearchUrl: <192.168.0.2> externalElasticsearchPort: <9200> ... status: ... # logging: # enabledTime: 2020-08-10T02:05:13UTC # status: enabled ...
- 重新运行
ks-installer。kubectl rollout restart deploy -n kubesphere-system ks-installer
- 运行以下命令删除内部 Elasticsearch,请确认您已备份内部 Elasticsearch 中的数据。
helm uninstall -n kubesphere-logging-system elasticsearch-logging
- 如果启用了 Istio,需要修改 Jaeger 配置。
$ kubectl -n istio-system edit jaeger ... options: es: index-prefix: logstash server-urls: http://elasticsearch-logging-data.kubesphere-logging-system.svc:9200 # 修改为外部地址
5.1.3.2 如何在启用 X-Pack Security 的情况下将日志存储改为 Elasticsearch
KubeSphere 暂不支持启用 X-Pack Security 的 Elasticsearch 集成,此功能即将推出。
5.1.3.3 如何修改日志数据保留期限
您需要更新 KubeKey 配置并重新运行 ks-installer。
- 执行以下命令:
kubectl edit cc -n kubesphere-system ks-installer
- 将
status.logging的注释取消,将es.logMaxAge的值设置为所需保留期限(默认为 7 天)。apiVersion: installer.kubesphere.io/v1alpha1 kind: ClusterConfiguration metadata: name: ks-installer namespace: kubesphere-system ... spec: ... common: es: ... logMaxAge: <7> ... status: ... # logging: # enabledTime: 2020-08-10T02:05:13UTC # status: enabled ...
- 重新运行
ks-installer。kubectl rollout restart deploy -n kubesphere-system ks-installer
5.1.3.4 无法使用工具箱找到某些节点上工作负载的日志
如果您采用多节点安装部署 KubeSphere,并且使用符号链接作为 Docker 根目录,请确保所有节点遵循完全相同的符号链接。日志代理以守护进程集的形式部署到节点上。容器日志路径的任何差异都可能导致该节点上日志收集失败。
若要找出节点上的 Docker 根目录路径,您可以运行以下命令。请确保所有节点都适用相同的值。
docker info -f '{{.DockerRootDir}}'
5.1.3.5 工具箱中的日志查询页面在加载时卡住
如果您发现日志查询页面在加载时卡住,请检查您所使用的存储系统。例如,配置不当的 NFS 存储系统可能会导致此问题。
5.1.3.6 工具箱显示今天没有日志记录
请检查您的日志存储卷是否超过了 Elasticsearch 的存储限制。如果是,请增加 Elasticsearch 的磁盘存储卷容量。
5.1.3.7 在工具箱中查看日志时,报告内部服务器错误
如果您在工具箱中看到内部服务器错误,可能有以下几个原因:
- 网络分区
- 无效的 Elasticsearch 主机和端口
- Elasticsearch 健康状态为红色
5.1.3.8 如何让 KubeSphere 只收集指定工作负载的日志
KubeSphere 的日志代理由 Fluent Bit 所提供,您需要更新 Fluent Bit 配置来排除某些工作负载的日志。若要修改 Fluent Bit 输入配置,请运行以下命令:
kubectl edit input -n kubesphere-logging-system tail
更新 Input.Spec.Tail.ExcludePath 字段。例如,将路径设置为 /var/log/containers/*_kube*-system_*.log,以排除系统组件的全部日志。
有关更多信息,请参见 Fluent Bit Operator。
在查看容器实时日志的时候,控制台上看到的实时日志要比 kubectl log -f xxx 看到的少
主要有以下几个原因:
- 当实时去查看容器日志时,Kubernetes 是分 chunk 形式返回,Kubernetes 大概 2 分钟左右会返回一次数据,比较慢
- 未开启‘实时查看’时看到的末尾部分,在实时查看时,被划分在下次返回的部分中,现象看起来像是日志缺失
5.2 监控与告警
5.2.1 Prometheus 基础概念与上手实践
5.2.1.1 Prometheus 安装使用
cat > /etc/prometheus/prometheus.yml <<-'EOF'
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
#- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
# prometheus抓取的监控的信息
- job_name: 'prometheus'
static_configs:
- targets: ["localhost:9090"]
EOF
$ docker run --name prometheus --net=host -d \
-v /etc/prometheus:/etc/prometheus prom/prometheus
$ docker logs -f prometheus

- Exporter 概念:是一个相对开放的概念;从侠义上来看可以是独立运行的程序,独立于监控目标以外。从广义上来看可以内置在监控目标当中的,软件本身通过 URL 暴露 Prometheus 格式的 metrics。只要能够向Prometheus提供标准格式的监控数据。
Prometheus 安装使用 - Node Exporter
$ wget https://github.com/prometheus/node_exporter/releases/download/v1.3.0/node_exporter-1.3.0.linux-arm64.tar.gz
$ tar zxf node_exporter-1.3.0.linux-arm64.tar.gz
$ cd node_exporter-1.3.0.linux-arm64
$ ./node_exporter
- 抓取 Node Exporter 数据
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
#采集node exporter监控数据
- job_name : "node"
static_configs:
- targets: ["localhost:9100"]
$ docker restart prometheus
5.2.1.2 PromQL 介绍
1、瞬时向量(Instant vector)
—组时间序列,每个时间序列包含单个样本,它们共享相同的时间戳。也就是说,表达式的返回值中只会包含该时间序列中的最新的一个样本值。
2、区间向量(Range vector)
一组时间序列,每个时间序列包含一段时间范围内的样本数据。
3、标量(Scalar)
浮点型的数据值。
4、字符串(String)
PromQL 介绍 - 瞬时向量
- 包含所有时间序列
- 只增不减,Counter
- =:选择与提供的字符串完全相同的标签。
- !=:选择与提供的字符串不相同的标签。
- =~:选择正则表达式与提供的字符串(或子字符串)相匹配的标签。
- !~∶选择正则表达式与提供的字符串(或子字符串)不匹配的标签。
http_requests_total
{__name__="http_requests_total"}
http_requests_total{job="prometheus", code="200"}
http_requests_total{status_code=~"2.*")
PromQL 介绍 - 区间向量
- 定义时间选择的范围
- 单位:s, m, h, d, w , y
区间范围内的平均增长速率
通过区间向量中最后两个两本数据来计算区间向量的增长速率
http_requests_total{job="prometheus"][5m]
rate(http_requests_total[5m])
irate(http_requests_total[5m])
PromQL 介绍 - 简单指标类型
服务的请求数、已完成的任务数、错误发生的次数
进程数量、内存使用率、温度、并发请求的数量
Counter (计数器) :只增不减
Guage(仪表盘)∶可随意变化
PromQL 介绍 - 复杂指标类型
常规的指标类型数值是以样本的数值来表示的。
Histogram
样本的值分布在bucket 中的数量,命名为
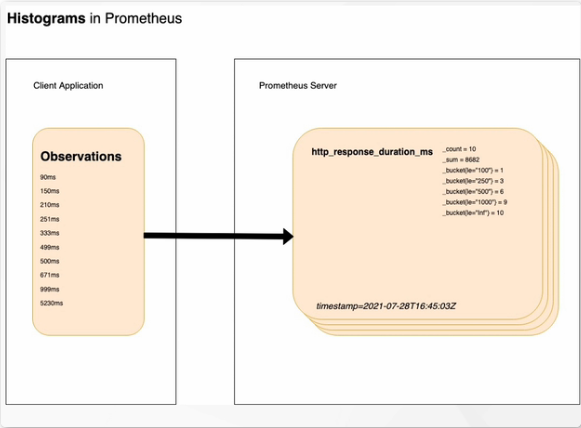
<basename>_bucket{le="<上边界>"}
http_response_duration_ms _bucket{le="100"}=1 表示样本的值在100范围之内,样本的数量为1个。
http_response_duration_ms _bucket{le="250"}=3 表示样本的值在250范围之内,样本的数量为3个。
http_response_duration_ms _bucket{le="ini"}=10 表示样本的值在无穷范围,样本的数量为10个。
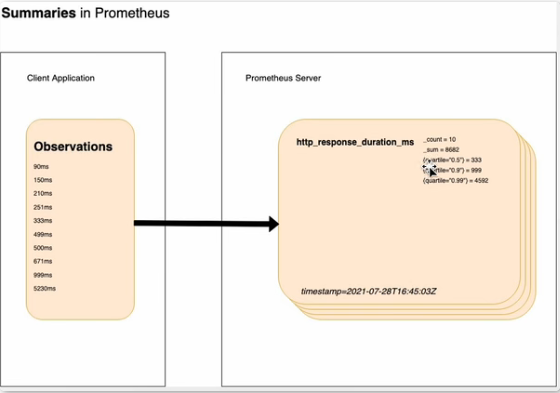
PromQL 介绍 - 复杂指标类型
Summary
server端直接算好分位数,不能聚合
5.2.1.3 Prometheus 告警处理
Prometheus 告警处理 - 架构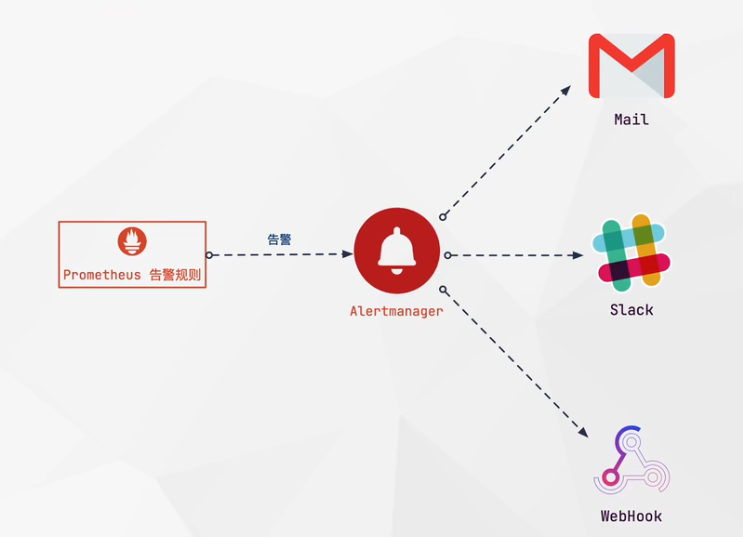
Prometheus 是按功能划分的平台。Prometheus 指标的收集和存储,Prometheus 的告警系统是分开来的。Prometheus 的告警系统是 Alertmanager 负责的。Alertmanager 作为独立的组件,负责接收并处理来自Prometheus 平台的消息。Alertmanager 将处理完的数据进行去重并分组;然后路由到不同的接收器。
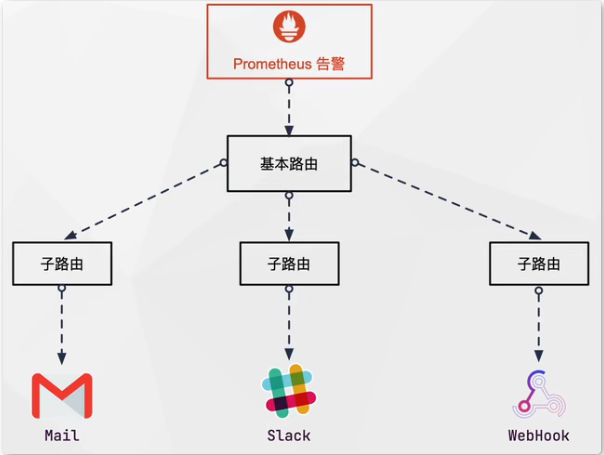
# alertmanager.yml
cat > /etc/prometheus/alertmanager.yml <<-'EOF'
global:
smtp_smarthost: "localhost: 25"
smtp_from: 'alertmanage@example.com'
smtp_require_tls: false
templates:
- "/etc/alertmanager/template/*.tmpl'
route:
receiver: "email"
group_wait: 30s
group_interval: 5m
repeat _interval: 4h
routes:
- receiver: 'slack"
group_wait: 10s
matchers:
- service=~"mysql|cassandra"
- receiver: 'webhook '
group_by: [product,environment]
matchers:
- team="frontend”
receivers:
- name : 'email'
email_configs:
- to: 'alerts@example.com"
- name : 'slack'
slack_configs:
- channel: 'xxx"
- name: 'webhook"
webhook _configs:
- url: 'xxx'
EOF
cat > /etc/prometheus/prometheus.yml <<-'EOF'
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
#- "node_down.yml"
# - "first_rules.yml"
# - "second_rules.yml"
- "/etc/prometheus/rules/*_rules.yml"
- "/etc/prometheus/rules/*_alerts.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
# prometheus抓取的监控的信息
- job_name: 'prometheus'
static_configs:
- targets: ["localhost:9090"]
#采集node exporter监控数据
- job_name : "node"
static_configs:
- targets: ["localhost:9100"]
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
EOF
# 重启容器prometheus
$ docker restart prometheus
$ tar -zxvf alertmanager-0.24.0.linux-amd64.tar.gz
$ cd alertmanager-0.24.0.linux-amd64/
$ ./alertmanager --config.file=./alertmanager.yml
$ export VERSION=0.23.0
$ wget https://github.com/prometheus/alertmanager/releases/download/v$VERSION/alertmanager-$VERSION.linux-amd64.tar.gz
$ tar zxvf alertmanager-$VERSION.linux-amd64.tar.gz
$ cd alertmanager-$VERSION.linux-amd64
$ ./alertmanager --config.file alertmanager.yml
浏览器访问 10.0.0.51:9093
$ mkdir -pv /etc/prometheus/rules/
# 重启容器prometheus
$ docker restart prometheus
#/etc/prometheus/rules/node_alerts.yml
cat > /etc/prometheus/rules/node_alerts.yml <<-'EOF'
groups:
- name: node_alerts
rules:
- alert: HostOutOfMemory
expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100 > 10
for: 2m
labels:
severity: warning
annotations:
summary: Host out of memory (instance {{ $labels.instance }})
description: "Node memory is filling up (> 10% left)\n VALUE ={{ $value }}\n LABELS = {{ $labels }}"
EOF
- 节点的内存可用率不断变化,每隔一段时间由scrape_interval定义的时间被Prometheus抓取一次,默认是15秒。
- 根据每个evaluation_interval 的指标来评估告警规则,默认是15秒。
- 当告警表达式为true时,会创建一个告警并转换到Pending状态,执行for语句。
- 在下一个评估周期中,如果告警表达式仍然为true,则检查for的持续时间。如果超过了持续时间,则告警将转换为 Firing,生成通知并将其推送到Alertmanager。
- 如果告警表达式不再为true,则 Prometheu:会将告警规则的状态从 Pending更改为Inactive
5.2.1.4 Prometheus Operator 安装使用与高级配置
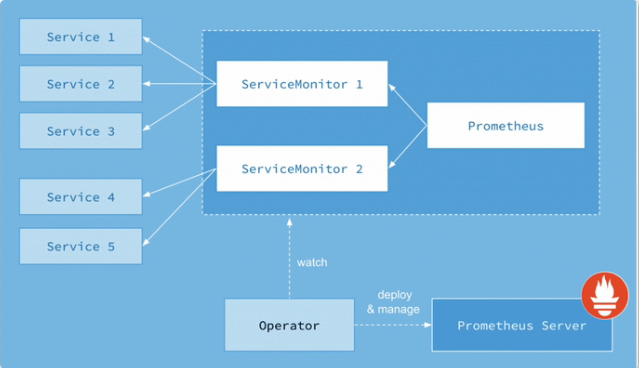
- Prometheus:声明Prometheus deployment期望的状态。Prometheus Server : Operator根据自定义资源
- Prometheus类型中定义的内容而部署的PrometheusServer集群。
- Alertmanager:声明了Alertmanager Deployment。ServiceMonitor :声明式指定应如何监控KubernetesService,自动生成相关Prometheus 抓取配置。
- Operator:根据自定义资源(CRD )来部署和管理
- Prometheus Server,同时监控这些自定义资源事件的变化来做相应的处理,是整个系统的控制中心。
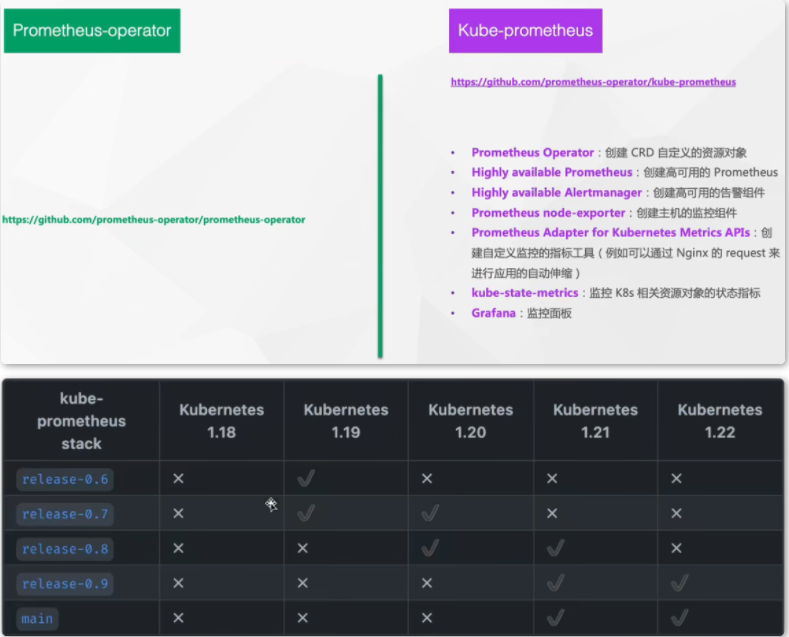
$ git clone https://github.com/prometheus-operator/kube-prometheus.git
$ cd kube-prometheus/manifests
$ mkdir -p serviceMonitor prometheus adapter node-exporter kube-state-metrics grafana alertmanager operator blackbox rules
$ mv *Rule.yaml rules
$ mv *serviceMonitor* serviceMonitor
$ mv alertmanager-* alertmanager
$ mv blackboxExporter-* blackbox/
$ mv grafana-* grafana/
$ mv kubeStateMetrics-* kube-state-metrics
$ mv nodeExporter-* node-exporter
$ mv prometheus-* prometheus/
$ mv prometheusAdapter-* adapter
$ mv prometheusOperator-* operator
$ kubectl apply --server-side -f setup
$ kubectl apply -f operator
$ kubectl apply -f adapter/ -f alertmanager/ -f blackbox/ -f grafana/ -fkube-state-metrics/ -f node-exporter/ -f prometheus/ -f rules/ -f serviceMonitor/
$ kubectl get all -n monitoring
Prometheus Operator - 配置解析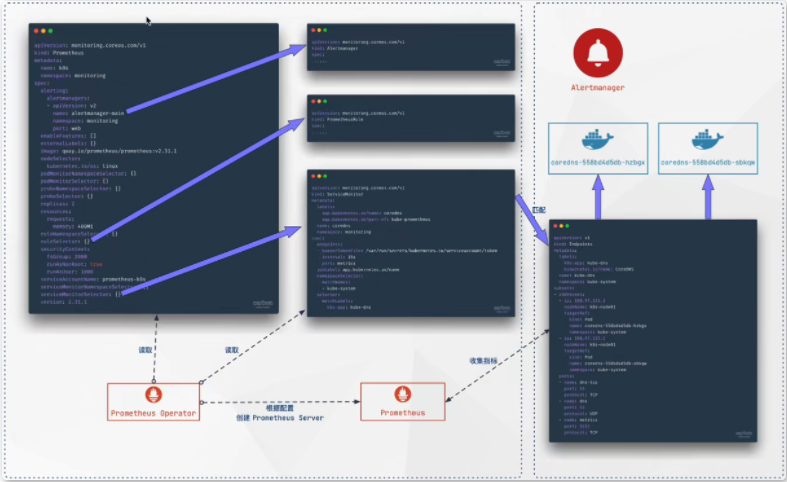
5.2.2 KubeSphere 监控与告警系统
- 监控系统介绍
- 集群状态监控
- 应用资源监控
5.2.2.1 KubeSphere 监控功能与使用
监控系统介绍
- 基于Prometheus生态
- 多租户隔离
- 多维度监控
- 全面丰富的指标
- 灵活多样的展现方式
集群状态监控
- 物理资源监控
- 集群资源
- 节点资源
- Kubernetes核心组件监控
- API Server
- Etcd
- Scheduler
- KubeSphere核心组件监控
5.2.2.2 应用资源监控
管理员视角
- 集群层级
- 项目与应用资源统计
- 用量排行
- 普通用户视角
- 企业空间层级
- 项目层级
- 工作负载层级
- 容器组层级
- 容器层级
5.2.2.3 集群状态监控
Reference:
集群状态监控
- 点击左上角的平台管理,然后选择集群管理。
- 如果您已启用了多集群功能并已导入了成员集群,您可以选择一个特定集群以查看其应用程序资源。如果尚未启用该功能,请直接进行下一步。
- 在左侧导航栏选择监控告警下的集群状态以查看集群状态概览,包括集群节点状态、组件状态、集群资源用量、etcd 监控和服务组件监控。
应用资源监控
- 点击左上角的平台管理,然后选择集群管理。
- 如果您已启用了多集群功能并已导入了成员集群,您可以选择一个集群以查看其应用程序资源。如果尚未启用该功能,请直接进行下一步。
- 在左侧导航栏选择监控告警下的应用资源以查看应用资源概览,包括集群中所有资源使用情况的汇总信息。
- 集群资源用量和应用资源用量提供最近 7 天的监控数据,并支持自定义时间范围查询。
- 点击特定资源以查看特定时间段内的使用详情和趋势,例如集群资源用量下的 CPU。在详情页面,您可以按项目查看特定的监控数据,以及自定义时间范围查看资源的确切使用情况。
5.2.2.4 KubeSphere 基于租户的告警与通知
告警功能介绍
- 兼容Prometheus规则(KubeSphere3.1开始)
- 多租户支持
- 内置平台告警策略
- 规则配置方式
集群告警
- 内置告警策略
- 物理资源(cpu/内存/存储)
- 核心组件(k8s/etcd等)
- 规则模板配置策略
- 节点(cpu/内存/磁盘/网络/容器组利用率)
- 自定义规则配置策略
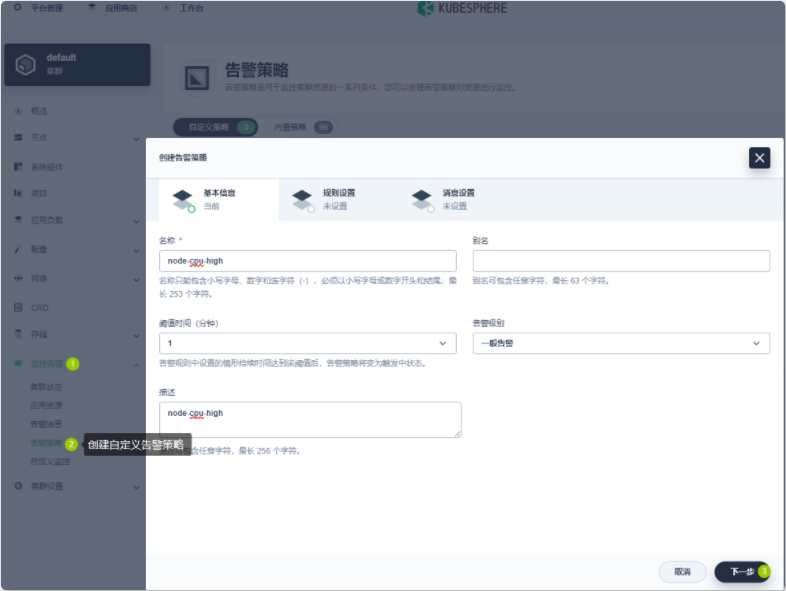
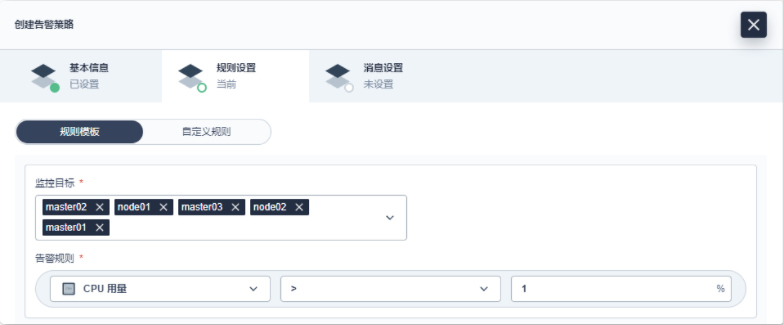
- 设置通信配置
- 应用告警
规则模板配置策略(cpu/内存/网络/副本不可用)。
- 部署
- 有状态副本集
- 守护进程集
自定义规则配置策略
5.2.2.5 KubeSphere 自定义监控面板
https://github.com/kubesphere/monitoring-dashboard/tree/master/config/crd/bases
$ kubectl api-resources | grep dashboard
clusterdashboards monitoring.kubesphere.io/v1alpha2 false ClusterDashboard
dashboards monitoring.kubesphere.io/v1alpha2 true Dashboard
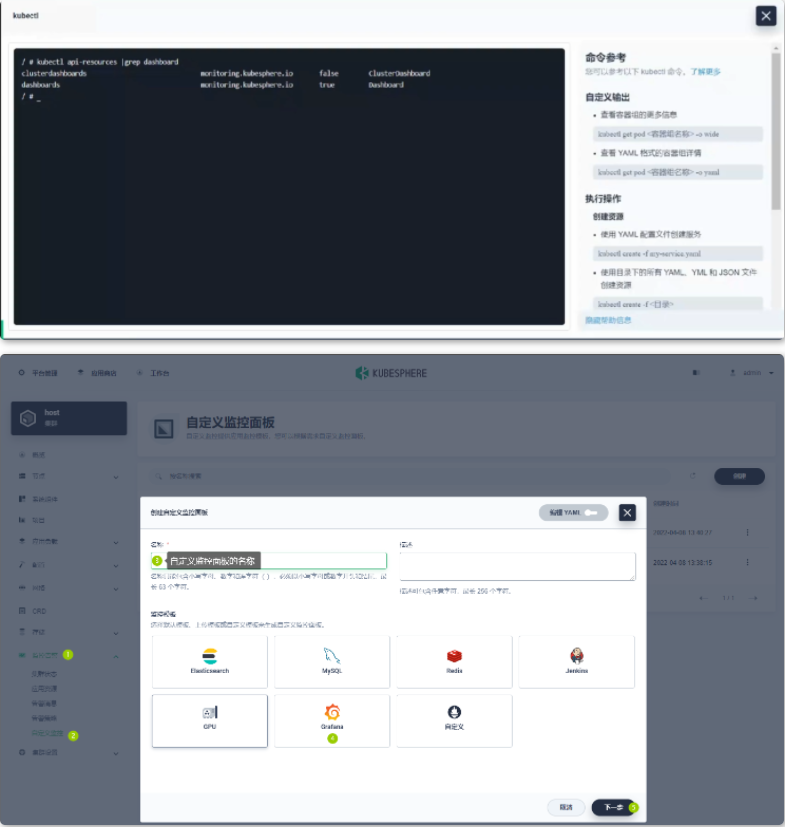
5.2.2.6 导入 Grafana 监控模板
KubeSphere 导入 Grafana 监控模板 - 转换过程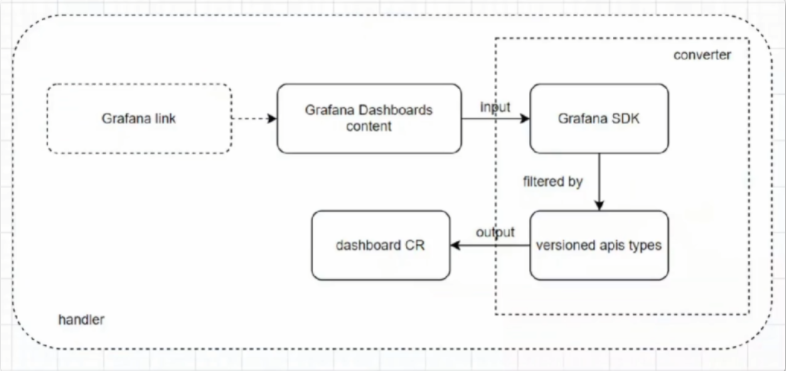
https://github.com/kubesphere/monitoring-dashboard#converter-tool
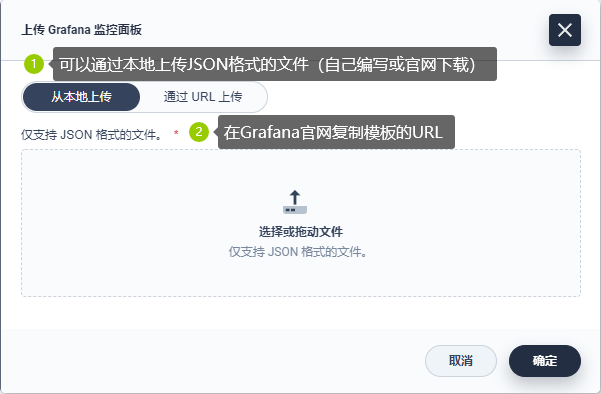
5.2.2.7 使用自定义监控面板 GPU
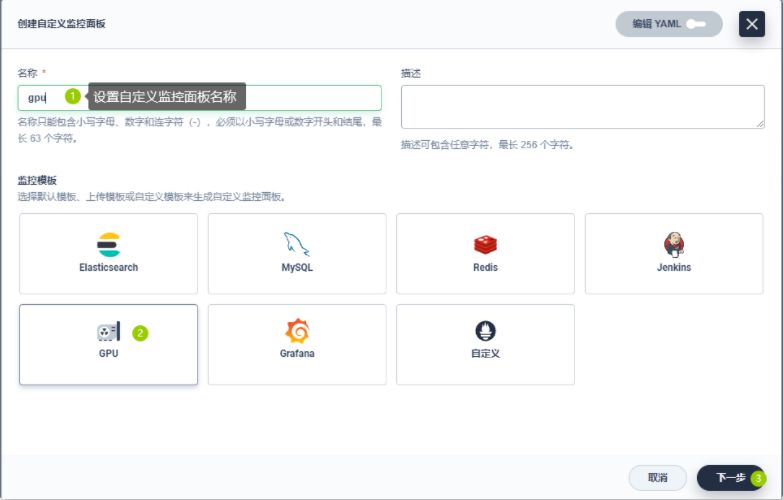
5.3 审计与事件
KubeSphere 审计日志提供了与安全相关的、按时间顺序排列的记录集,记录每个用户、管理员或系统其他组件对系统产生影响的一系列活动。对 KubeSphere 的每个请求都会生成一个事件,随后该事件会写入 Webhook 并根据特定规则进行处理。根据不同规则,该事件会被忽略、存储或生成告警。
Reference:
5.3.1 审计日志 Auditing Log
KubeSphere 支持租户隔离的审计日志查询。本教程演示了如何使用查询功能,包括界面、搜索参数和详情页面。
5.3.2 集群与应用的事件 Events
Reference:KubeSphere 事件系统
验证您可以使用右下角工具箱中的资源事件查询功能。
5.4 计量计费
5.4.1 计量计费功能介绍
KubeSphere 计量功能帮助您在不同层级追踪集群或企业空间中的资源消费。具有不同角色的租户只能看到其有权访问的数据。此外,您还可以为不同的资源设置价格以查看计费信息。
- 所有租户都可以访问资源消费统计模块,但每个租户可见的信息可能有所不同,可见信息具体取决于租户在所处层级上具有的角色。请注意,计量功能并非 KubeSphere 的可插拔组件,即只要您有一个 KubeSphere 集群,就可以使用该功能。
对于新创建的集群,您需要等待大约一小时才能看到计量信息。 - 如需查看计费信息,您需要预先启用计费。
5.4.2 在 KubeSphere 中开启计量计费
Reference:启用计费 (kubesphere.com.cn)
本教程介绍如何启用 KubeSphere 的计费功能,以查看集群中不同资源的消费情况。计费功能默认不启用,因此您需要在 ConfigMap 中手动添加价格信息。
请按照以下步骤启用 KubeSphere 的计费功能。
- 执行以下命令编辑 ConfigMap
kubesphere-config:kubectl edit cm kubesphere-config -n kubesphere-system
- 在该 ConfigMap 的
metering下添加保留期限和价格信息。以下为示例配置:$ kubectl get cm kubesphere-config -n kubesphere-system -oyaml ... alerting: prometheusEndpoint: http://prometheus-operated.kubesphere-monitoring-system.svc:9090 thanosRulerEndpoint: http://thanos-ruler-operated.kubesphere-monitoring-system.svc:10902 thanosRuleResourceLabels: thanosruler=thanos-ruler,role=thanos-alerting-rules ... metering: retentionDay: 7d billing: priceInfo: currencyUnit: "USD" cpuPerCorePerHour: 1.5 memPerGigabytesPerHour: 5 ingressNetworkTrafficPerMegabytesPerHour: 1 egressNetworkTrafficPerMegabytesPerHour: 1 pvcPerGigabytesPerHour: 2.1 kind: ConfigMap ...
相关参数描述如下:
| 参数 | 描述 |
|---|---|
retentionDay |
retentionDay决定用户的资源消费统计页面显示的日期范围。该参数的值必须与 Prometheus 中 retention的值相同. |
currencyUnit |
资源消费统计页面显示的货币单位。目前可用的单位有 CNY(人民币)和 USD(美元)。若指定其他货币,控制台将默认以美元为单位显示消费情况。 |
cpuCorePerHour |
每核/小时的 CPU 单价。 |
memPerGigabytesPerHour |
每 GB/小时的内存单价。 |
ingressNetworkTrafficPerMegabytesPerHour |
每 MB/小时的入站流量单价。 |
egressNetworkTrafficPerMegabytesPerHour |
每 MB/小时的出站流量单价。 |
pvcPerGigabytesPerHour |
每 GB/小时的 PVC 单价。请注意,无论实际使用的存储是多少,KubeSphere 都会根据 PVC 请求的存储容量来计算存储卷的总消费情况。 |
- 执行以下命令重启
ks-apiserver。kubectl rollout restart deploy ks-apiserver -n kubesphere-system
- 在资源消费统计页面,您可以看到资源的消费信息。
5.4.3 在 KubeSphere 中查看资源消费
Reference:查看资源消费 (kubesphere.com.cn)
集群资源消费情况包含集群(也包括节点)的资源使用情况,如 CPU、内存、存储等。
- 使用
admin用户登录 KubeSphere Web 控制台,点击右下角的 ,然后选择资源消费统计。
,然后选择资源消费统计。 - 在集群资源消费情况一栏,点击查看消费。
- 如果您已经启用多集群管理,则可以在控制面板左侧看到包含 Host 集群和全部 Member 集群的集群列表。如果您未启用该功能,那么列表中只会显示一个
default集群。
在右侧,有三个模块以不同的方式显示资源消费情况。
| 模块 | 描述 | | —- | —- | | 资源消费统计 | 显示自集群创建以来不同资源的消费概览。如果您在 ConfigMapkubesphere-config
中已经配置资源的价格
,则可以看到计费信息。 | | 消费历史 | 显示截止到昨天的资源消费总况,您也可以自定义时间范围和时间间隔,以查看特定周期内的数据。 | | 当前消费 | 显示过去一小时所选目标对象的资源消费情况。 |
6 KubeVirt 虚拟机负载管理
6.1 虚拟化技术介绍
Cloud Computing ; Virtualization ; LibVirt
(1)Cloud Computing
在云计算发展过程中,有两类虚拟化平台技术:
- OpenStack(laaS):关注虚拟机的计算,网络和存储资源管理
- Kubernetes(PaaS):关注容器的自动化部署,编排调度以及发布管理
(2)Virtualization
Hypervisor(or virtual machine monitor,VMM,Virtualizer)is a kind of emulator,classified two types of hypervisor:[ 是一种虚拟模拟软件,主要以下两种架构 ]
- Typer-1,native or bare-metal hypervisors:
Hypervisor 直接运行在物理硬件之上
- Microsoft Hyper-V
- VMware ESXi
- KVM
Typer-2 or hosted hypervisors:
Hypervisor 运行在另一个操作系统中
- QEMU
- VitrualBox
- VMware Player
- VMware WorkStation
(3)Libvirt
libvirt is an open-source API , daemon and mangement tool for managing platform virtualization . It can he used to manage KVM , XEN , VMware EXSi , QEMU and other virtualization technologies.
LibVirt 是一个虚拟化管理平台的软件集合,包括API的接口,守护进程以及一些管理工具;LibVirt 可以管理很多不一样的 Virtualization 虚拟化技术,包括KVM , XEN , VMware EXSi , QEMU
- Reference
https://en.wikipedia.org/wiki/Hypervisor/ https://en.wikipedia.org/wiki/Libvirt https://chowdera.com/2021/05/20210512132739845e.html
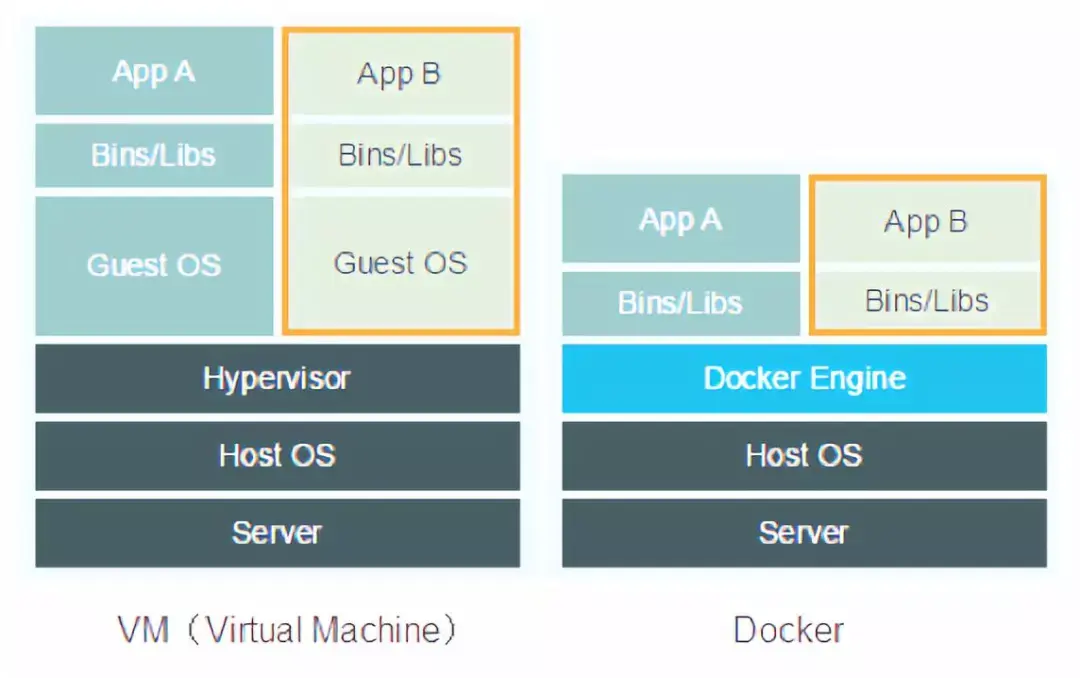
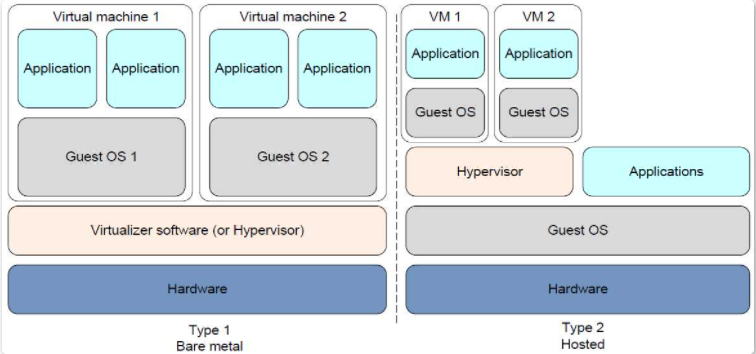
- 注意:两者现如今也在扩展自己的生态:
- OpenStack 扩展管理和运行容器;Kubernetes 扩展管理和运行虚拟机。
- 其中 KubeVirt 就是让Kubernetes 可以管理和运行虚拟机。
1. Virtualization includes CPU,Memory and I/O devices virtualization,Intel VT-x/AMD-X(CPU),Intel EPT/AMD-NPT(MMU)
2. I/O virtualization includes Full virtualization(全虚拟化) , para-virtualization(半虚拟化) and pass-through(硬件辅助虚拟化).
3. virtio , VT-d/AMD-Vi(IOMMU),VFIO,SR-IOV
# KVM 在产生时只实现了CPU和内存的虚拟化,像其他的网络设备,例如磁盘,网卡等设备则使用Qemu技术进行虚拟化
4. Qemu-KVM
6.2 KubeVirt 介绍
官方站点:https://kubevirt.io//quickstart_minikube/
GitHub 项目站点:https://github.com/kubevirt/kubevirt
- Reference
# https://cloud.tencent.com/developer/article/1452532
# https://jishuin.proginn.com/p/763bfbd38601
# http://www.yidianzixun.com/article/0XVT2k6J
6.2.1 KubeVirt 是什么
KubeVirt ;KubeVirt Components;VM starting flow
(1)KubeVirt
KubeVirt is a virtual machine mangement add-on for kubernetes . The aim is to provide a common ground for virtualization solutions on top of Kubernetes.
KubeVirt extends Kubernetes by adding additional virtualization resource types (especially the VM and VMI type) through Kubernetes’s Clustom Resource Definitions API
KubeVirt 是以Redhat公司开源的以容器方式运行的虚拟机项目,是基于Kubernetes运行。利用 K8S CRD为增加虚拟机运行和管理相关的资源类型
VirtualMachine(VM)、VirtualMachineInstance(VMI), 使用容器的image registry去创建虚拟机并提供VM生命周期管理。 CRD的方式是的kubevirt对虚拟机的管理不局限于pod管理接口,但是也无法使用 Pod 的RS DS Deployment等管理能力,也意味着 kubevirt如果想要利用pod管理能力,要自主去实现,目前kubevirt实现了类似RS的功能。kubevirt目前支持的runtime是docker和runv。kubevirt可以自定义额外的操作,来调整常规容器中不可用的行为。其目的是为了让 Kubernetes 能够像运行容器一样,类似的运行虚拟机。
Master 节点组件为 Controller,API;Worker 节点组件为 Agent;Worker 节点启动一个 Pod,在Pod上可以运行虚拟机。Pod里面可以运行虚拟机和容器。
VirtualMachine(VM):是用户所定义的虚拟机,为集群内的VMI提供生命周期管理功能,确保虚拟机实例的状态,并且它与VMI 1:1
VirtualMachineInstance(VMI):是用户所定义的虚拟机实例,虚拟机管理的最小资源,一个VMI对象即标识一台正在运行的VM
# 通过定义着两种资源类型,可以让Kubernetes 运行和管理虚拟机
6.2.2 为什么要使用 KubeVirt
KubeVirt 技术提供了一个统一的开发平台,开发人员可以在该平台上构建,修改和部署驻留在公共共享环境中的应用程序容器和虚拟机中的应用程序。
好处是广泛而重大的。依赖现有基于虚拟机的工作负载团队有权快速将应用程序容器化。通过将虚拟化工作负载直接放置在开发工作流中,团队可以随时间分解它们,同时仍然可以按需使用剩余的虚拟化组件。
6.2.3 KubeVirt 能做什么
- 利用 KubeVirt 和 Kubernetes 来管理虚拟机
- 一个平台上将现有的虚拟化与容器化打通并管理
- 支持虚拟机应用与容器化应用实现内部交互访问
6.2.4 KubeVirt 架构
从kubevirt架构看如何创建虚拟机,Kubevirt架构如图所示,由4部分组件组成。从架构图看出kubevirt创建虚拟机的核心就是创建了一个特殊的pod virt-launcher ,其中的子进程包括libvirt和qemu。
做过Openstack nova 项目的朋友应该比较习惯于一台宿主机中运行一个libvirtd后台进程,kubevirt中采用每个pod中一个libvirt进程是去中心化的模式,来避免因为 libvirtd服务异常导致所有的虚拟机无法管理。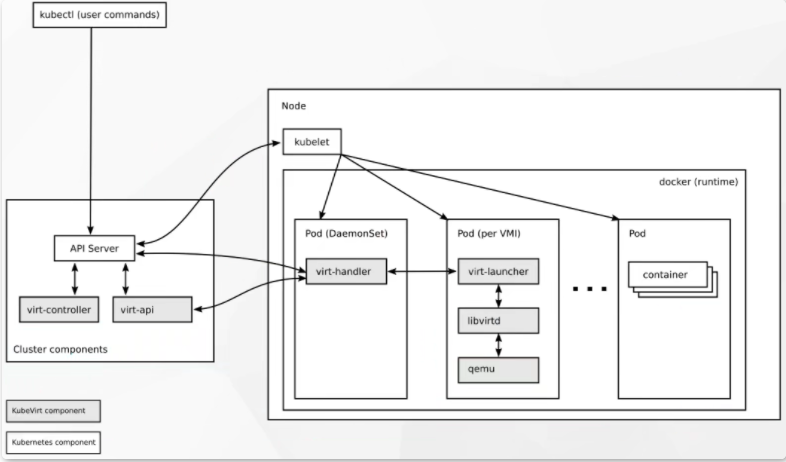
KubeVirt 组件介绍
与OpenStack 类似, kubevirt 每个组件负责不同的功能,不同点是资源调度策略由k8s 去管理,其中主要组件如下: virt-api,virt-controller,virt-handler,virt-launcher。
- virt-api
- kubevirt API服务,kubevirt是以CRD的方式工作的,virt-api提供了自定义的api请求处理,如
vncconsolestart vmstop vm等。 - 是 Kubernetes 所有虚拟化操作的入口
- kubevirt API服务,kubevirt是以CRD的方式工作的,virt-api提供了自定义的api请求处理,如
- virt-controller
- 与k8s api-server通讯监控
VMI资源创建删除等状态 - 根据
VMI定义创建virt-launcherpod,该pod中将会运行虚拟机 - 监控pod状态,并随之更新
VMI状态 - 监控标记为”kubevirt.io/schedulable” node heartbeat
- 与k8s api-server通讯监控
- virt-handler
- 运行在kubelet的node上定期更新heartbeat,并标记”kubevirt.io/schedulable”
- 监听在k8s apiserver当发现
VMI被标记得nodeName与自身node匹配时,负责虚拟机的生命周期管理
- virt-launcher
- 以pod形式运行(提供了虚拟机的运行环境)
- 根据
VMI定义生成虚拟机模板,通过libvirt API创建虚拟机 - 每个虚拟机会对应对立的libvirtd(会调用QEMU )
- 与libvirt通讯提供虚拟机生命周期管理
| 名称 | 功能 |
| —- | —- |
| virt_api | 类似 nova-api 组件,此组件提供 HTTP RESTful 入口,虚拟化相关流程的入口,
作为 KubeVirt 的主要入口,它负责默认和验证所提供的VMI CRD | | virt_controller | 此组件是一个 Kubernetes 控制器,用于管理 Kubernetes 集群中 VM 的生命周期,virt-controller具有所有集群范围的虚拟化功能 | | virt_handler | 每个 Kubernetes 节点上都会运行的守护程序。它负责根据 Kuebrnetes 监视 VMI 的状态,并确保相应的引导或者停止了相应的 libvirt 域。为了执行这些操作,virt-handler 与每个 virt-launcher 都有一个通信通道,用于管理 virt-launcher 容器内 qemu 进程的声明周期 | | virt_launcher | 每个运行的 VMI 都有一个,该组件直接在VMI 的 pod 中管理 qemu 进程的生命周期 |
6.2.5 KubeVirt 创建虚拟机流程
- Client 发送创建 VMI 命令达到Kubernetes API server.
- Kubernetes API 创建 VMI
- virt-controller 监听到 VMI 创建时,根据VMI spec生成pod spec文件,创建 pods
- Kubernetes 调度创建 pods
- virt-controller 监听到 pods 创建后,根据pods的调度node,更新 VMI 的nodeName
- virt-handler 监听到 VMI nodeName 与自身节点匹配后,与 pod 内的 virt-launcher 通信,virt-laucher创建虚拟机,并负责虚拟机生命周期管理
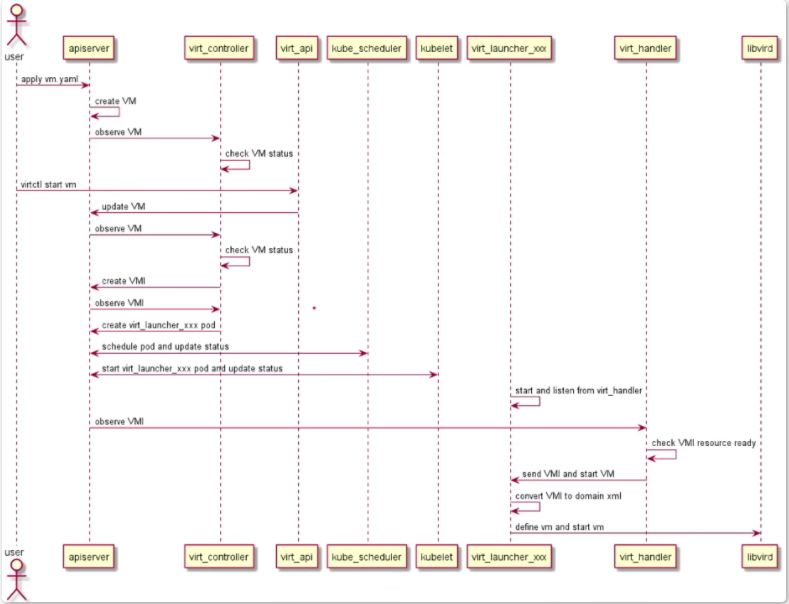
6.3 KubeVirt 核心概念概述
6.3.1 虚拟机
| 资源对象名称 | 功能 |
|---|---|
| VirtualMachines(VM) | 为集群内的 VirtualMachineInstance(VMI) 提供管理服务,例如开机、关机、重启虚拟机,确保虚拟机实例的启动状态。 |
| VirtualMachineInstance(VMI) | 类似于 Kubernetes Pod,是 Kubernetes KubeVirt 管理虚拟机的最小资源。 一个 VirtualMachineInstance(VMI) 对象即表示一台正在运行的虚拟机实例,包含一个虚拟机所需要的各种配置。 |
| VirtualMachineInstanceReplicaSet | 是虚拟机的副本控制,类似于 Kubernetes 的 ReplicaSet ,可以启动指定数量的 VirtualMachineInstance(VMI) ,并且确保指定数量的 VirtualMachineInstance(VMI) 的运行,可以配置 HPA |
| VirtualMachineInstanceMigrations | 提供虚拟机迁移的能力 |
- Kubernestes 虚拟机模板

6.3.2 虚拟机镜像
Containerized-Data-Importrer(CDI) is a persistent storage management add-on for kubernetes . It’s perimary goal is to provide a declaration way to build Virtual Machine Disk on PVCs for Kubevirt VMS。
KubeVirt 有一个子项目叫 CDI,CDI 是 Kubernetes 持久化存储管理插件,其主要的目标是提供一种生命式的方法去构建虚拟机的磁盘,基于PVC去构建。CDI 还定义了一种资源叫 —dataVolume,用于定义和管理虚拟机镜像
6.3.3 磁盘和卷
在 spec.columes 下可以指定多种类型的卷:
- cloudInitNoCloud:Cloud-init 相关的配置,用于修改或者初始化虚拟机中的配置信息
- containerDisk:指定一个包含 qcow2 或 raw 格式的 Docker 镜像,重启 VM 数据会丢失
- dataVolume:动态创建一个 PVC,并用指定的磁盘映像填充该PVC,重启 VM 数据不会丢失
- emptyDisk:从宿主机上分配固定容量的空间,映射到 VM 中的一块磁盘,emptyDisk 的生命周期于 VM 等同,重启 VM 数据会丢失
- ephemeral:在虚机启动时创建一个临时卷,虚机关闭后自动销毁,临时卷在不需要磁盘持久性的任何情况下都很有用。
- hostDisk:在宿主机上创建一个 img 镜像文件,挂给虚拟机使用。重启 VM 数据不会丢失。
- persistentVolumeClaim:指定一个 PVC 创建一个块设备。重启 VM 数据不会丢失。
- configMap
- serviceAccount
- secret:可以把信息 configMap、serviceAccount、secret写入到iso磁盘中,挂给虚拟机
6.3.4 网络
KubeVirt 可能的网络拓扑结构: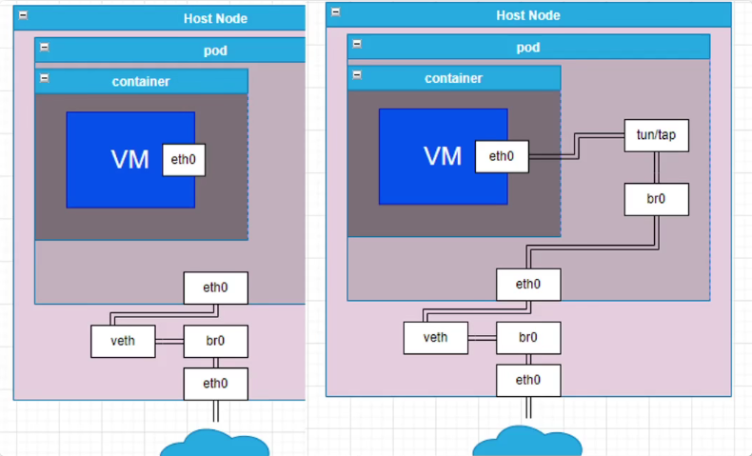
在 Pod 里面构建一个虚拟设备,然后虚拟机通过该虚拟设备连接到 Pod的网卡上。其实虚拟机的IP就是一个内网的IP,如果要连接外网或者连接Pod外面的服务,虚拟机必须通过这个Pod的网卡做一个NAT的转换。
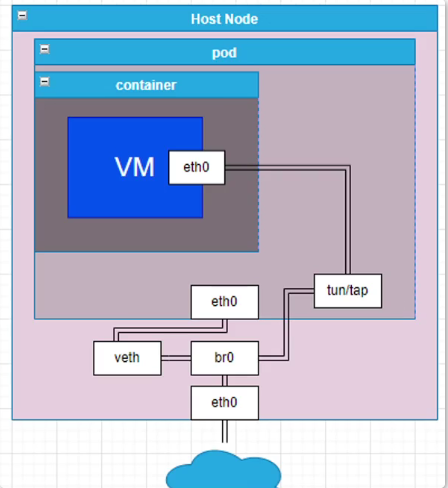
该连接方式是让虚拟机网络与容器的网络是在一个网络里,但是这个时候,这个Pod里面就需要有两张网卡。
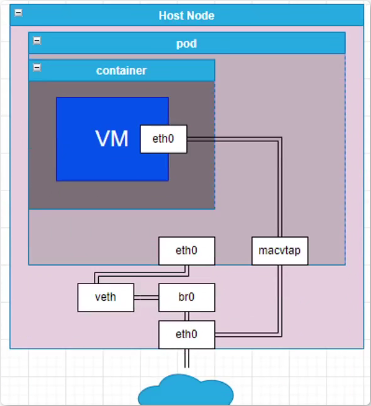
该连接方式是让虚拟机可以和宿主机Host IP在一个网段上,同时该Pod 也是需要有两张网卡。
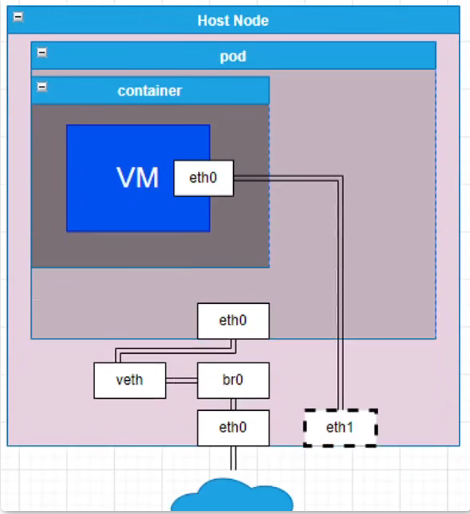
该连接方式是直接将宿主机中 eth1 直接透传到虚拟机中去。
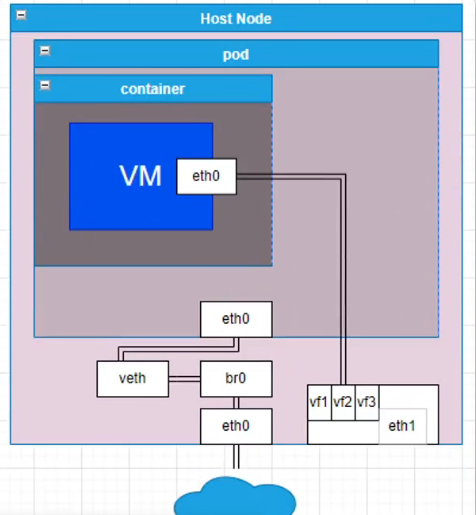
该连接方式是直接将宿主机中物理网卡eth1进行虚拟化,虚拟化出的网卡直接透传到虚拟机中去。
- 这个就是SRIOV的解决方案
Multus
- Mults CNI enables attaching multiple network interfaces to pods in Kubernetes
- CR - network-attachment-definition.k8s.cni.cncf.io
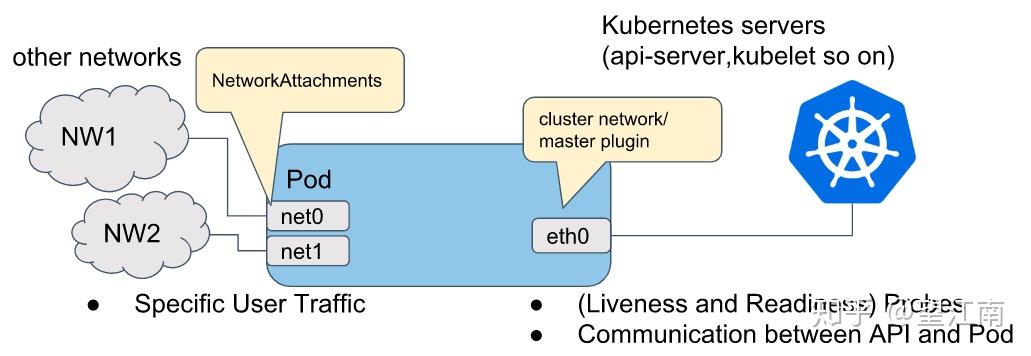
一般情况下,Pod 只有一张网卡,但是有些时候,我们是需要有多张网卡的支持。这个时候就需要 Multus CNI的插件。通过Multus 的插件,我们可以在 Pod 上加载或者生成多张网卡。
Connecting a virtual machine to a network consists of two parts将虚拟机连接到网络包括两部分:
- Frontend — spec.domain.devices.interfaces
- Backend — spec.networks
Each network should declare its type by defining one of the following fields 每个网络应该通过定义以下字段之一来声明其类型:
- pod — Default Kubernetes network
默认的Kubernetes网络- multus — Secondary network provided using Multus
使用multus提供的二次网络Binding method for spec.domain.devices.interfaces 用于spec.domain.devices.interfaces的绑定方法:
- bridge — Connect using a linux bridge
使用linux桥连接- sriov — Pass through a SR-IOV PCI device via vfio
通过vfio通过SR-IOV PCI设备- masquerade — Connect using Iptables rules to nat the traffic
使用Iptables规则连接来nat流量- macvtap — Connect using macvtap
使用macvtap连接Reference
https://github.com/kubevirt/kubevirt
https://github.com/kubevirt/containerized-data-importer/
https://github.com/k8snetworkplumbingwg/multus-cni
6.4 使用 KubeVirt 管理虚拟机负载
- KubeVirt 的部署
- 使用 KubeVirt 创建虚拟机
- 虚拟机的启动和停止
- 创建虚拟机快照与恢复快照
- 虚拟机的迁移
6.4.1 KubeVirt 的部署
KubeVirt 运行在 Kubernetes 之上,先准备 Kubernetes 环境。本实战使用 KubeKey 构建 Kubernetes 环境
export VERSION=v0.46.1
echo $VERSION
kubectl create -f https://github.com/kubevirt/kubevirt/releases/download/${VERSION}/kubevirt-operator.yaml
kubectl create configmap kubevirt-config -n kubevirt --from-literal debug.useEmulation=true --from-literal feature-gates=Macvtap,LiveMigration,Snapshot
kubectl create -f https://github.com/kubevirt/kubevirt/releases/download/${VERSION}/kubecirt-cr.yaml
# 下载virtual命令行工具
wget https://github.com/kubevirt/kubevirt/releases/download/${VERSION}/virtctl-${VERSION}-linux-amd64
cp -av virtctl-v0.46.1-linux-amd64 /usr/local/bin/virtctl
# 添加执行权限
chmod a+x /usr/local/bin/virtctl
# 查看 kubevirt 的Pod运行情况
$ kubectl get pod -n kubevirt -w
6.4.2 使用 KubeVirt 创建虚拟机
# 创建测试虚拟机
$ wget http://kubevirt.io/labs/manifests/vm.yaml
apiVersion: kubevirt.io/v1
kind: VirtualMachine # 资源类型:VirtualMachine
metadata:
name: testvm
spec:
running: false
template:
metadata:
labels:
kubevirt.io/size: small
kubevirt.io/domain: testvm
spec:
domain:
devices: # 设置硬盘
disks:
- name: containerdisk
disk:
bus: virtio
- name: cloudinitdisk
disk:
bus: virtio
interfaces:
- name: default
masquerade: {}
resources:
requests:
memory: 64M
networks:
- name: default
pod: {}
volumes:
- name: containerdisk # 启动盘
containerDisk:
image: quay.io/kubevirt/cirros-container-disk-demo # 虚拟机镜像
- name: cloudinitdisk # 数据盘
cloudInitNoCloud:
userDataBase64: SGkuXG4=
$ kubectl apply -f vm.yaml
# 查看虚拟机创建情况
$ kubectl get vm
NAME AGE STATUS READY
testvm 46s Stopped False
6.4.3 虚拟机的启动和停止
# 确保本机拥有 virtctl 软件工具
# 查看帮助
$ virtctl --help
## 虚拟机的启动
$ virtctl start testvm
$ kubectl get vm
NAME AGE STATUS READY
testvm 19m Starting True
## 虚拟机创建过程
# 首先启动虚拟机的时候,先创建VMI资源(虚拟机实例)
$ kubectl get vmi
NAME AGE PHASE IP NODENAME READY
testvm 2m52s Running 10.233.100.225 kubesphere-master True
# 然后根据VMI资源来创建相应的Pod
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
virt-launcher-testvm-kd67b 2/2 Running 0 5m25s
## 进入虚拟机控制台
$ virtual console testvm
Successfully connected to testvm console. The escape sequence is ^]
login as 'cirros' user. default password: 'gocubsgo'. use 'sudo' for root.
testvm login: cirros
Password: gocubsgo
$ ip addr
$ curl www.baidu.com
$ cat /etc/os-release
# Ctrl + ] 退出终端
## 进入虚拟机中的 Pod
$ kubectl exec -it virt-launcher-testvm-kd67b -- /bin/bash
bash-5.0# ps -ef
bash-5.0# virsh
Welcome to virsh, the virtualization interactive terminal.
Type: 'help' for help with commands
'quit' to quit
virsh # list
Id Name State
--------------------------------
1 default_testvm running
bash-5.0# ip -d addr
bash-5.0# ip route
default via 169.254.1.1 dev eth0
10.0.2.0/24 dev k6t-eth0 proto kernel scope link src 10.0.2.1
169.254.1.1 dev eth0 scope link
## 虚拟机停止
$ virtctl stop testvm
VM testvm was scheduled to stop
$ kubectl get vm
NAME AGE STATUS READY
testvm 43m Stopped False
# VMI和Pod资源已经失效
$ kubectl get vmi
$ kubectl get pod
## 虚拟机的启动
$ virtctl start testvm
$ kubectl get vmi
$ kubectl get pod -o wide
## 小总结
virtctl start <虚拟机名称>
virtctl stop <虚拟机名称>
virtctl restart <虚拟机名称>
6.4.4 创建虚拟机快照与恢复快照
范例:创建虚拟机快照
cat > testvm-snap.yaml <<-'EOF'
apiVersion: snapshot.kubevirt.io/v1alpha1 # 资源类型
kind: VirtualMachineSnapshot
metadata:
name: snap-testvm # 虚拟机快照名
spec:
source:
apiGroup: kubevirt.io
kind: VirtualMachine # 资源类型
name: testvm # 虚拟机名称
EOF
# 创建虚拟机快照
$ kubectl create -f testvm-snap.yaml
# 查看虚拟机快照
$ kubectl get virtualmachinesnapshot.snapshot.kubevirt.io
NAME SOURCEKIND SOURCENAME PHASE READYTOUSE CREATIONTIME ERROR
snap-testvm VirtualMachine testvm Succeeded true 68s
范例:虚拟机恢复快照
cat > testvm-restore-snap.yaml <<-'EOF'
apiVersion: snapshot.kubevirt.io/v1alpha1
kind: VirtualMachineRestore # 资源类型
metadata:
name: restore-testvm
spec:
target:
apiGroup: kubevirt.io
kind: VirtualMachine
name: testvm
virtualMachineSnapshotName: snap-testvm
EOF
# 恢复虚拟机快照
$ kubectl create -f testvm-restore-snap.yaml
# 若提示以下报错:
# The request is invalid: spec.target.name: VirtualMachine "testvm" is running
# 解决方案:将虚拟机停止
$ virtctl stop testvm
# 查看虚拟机恢复快照
$ kubectl get virtualmachinerestore.snapshot.kubevirt.io
NAME TARGETKIND TARGETNAME COMPLETE RESTORETIME ERROR
restore-testvm VirtualMachine testvm true 9s
# 开启虚拟机
virtctl start testvm
6.4.5 虚拟机的迁移
# 进入虚拟机控制台
$ virtctl console testvm
Successfully connected to testvm console. The escape sequence is ^]
login as 'cirros' user. default password: 'gocubsgo'. use 'sudo' for root.
testvm login: cirros
Password:
$ touch xxx.txt
$ ls
xxx.txt
# Ctrl + ] 退出终端
# 查看Pod
$ kubectl get pod -o wide
# 虚拟机迁移(热迁移)
$ kubectl get pod -o wide -w
$ virtctl imgrate testvm
## 小总结
kubectl apply -f vm.yaml
virtctl start testvm
virtctl imgrate testvm
Reference:https://kubevirt.io/
6.5 KubeSphere 虚拟化管理平台介绍以及功能介绍
6.5.1 KSV 平台的背景以及平台简介
- KSV 平台的背景
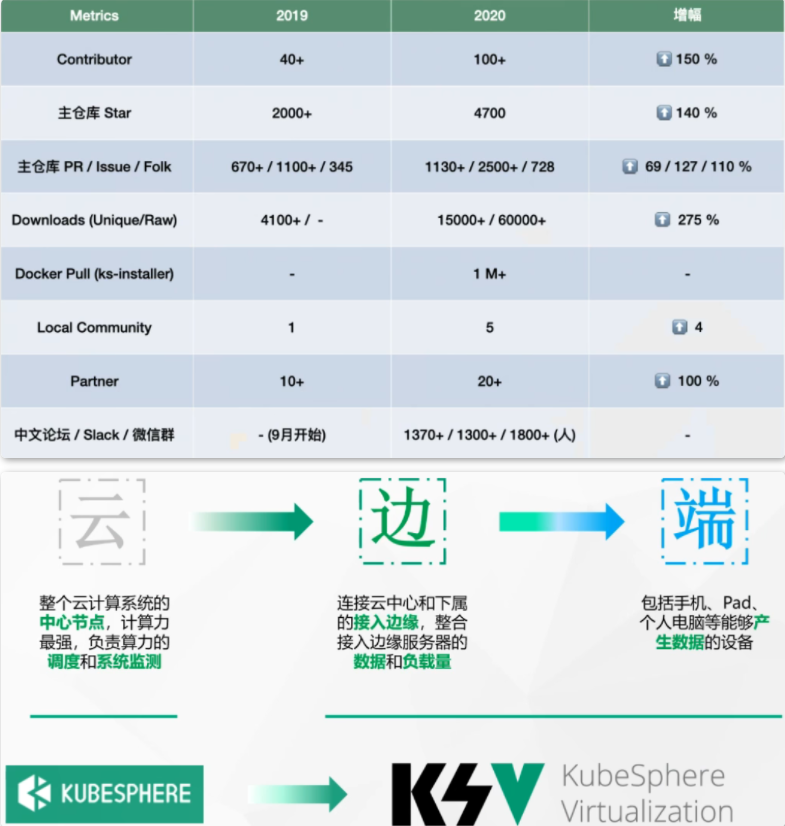
云:整个云计算系统的
中心节点,计算力最强,负责算力的调度和系统监测边:连接运中心和下属的
接入边缘,整合接入边缘服务器的数据和负载量端:包括手机、Pad、个人电脑等都
能产生数据的设备
KSV 平台介绍
KubeSphere Virtualization (简称 KSV)是一款容器虚拟化云平台管理软件,轻量级,松耦合是产品的初衷;简洁的界面和易懂的操作是产品的特点,用户无需拥有任何与容器相关的知识就可以非常轻松的部署和简单的操作功能。
KSV 特点:轻 简
- 简洁的UI界面
- 7个菜单项,操作功能基本不超过3个
- 内置 ubuntu 镜像:3.5G,不内置 ubuntu 镜像:3.0G
- 单节点资源:4C8G,单节点安装时间 20 分钟内
KSV 平台功能介绍 - 概览| 功能 | 功能说明 | | —- | —- | | 节点 | 提供集群节点的汇总列表以及每个节点资源使用情况,虚拟机状态、健康状态、网络状态等详情信息,支持节点数量扩展 | | IP 池 | IP 池用于将虚拟机分配到特定的网络中并为虚拟机提供IP地址 | | 虚拟机 | 提供虚拟机汇总列表和各虚拟机的管理 | | 镜像 | 提供镜像汇总列表和各镜像的详情 | | 磁盘 | 提供磁盘汇总列表和各磁盘的详情 | | 项目 | 提供项目汇总列表和各项目的详情,项目用于对资源进行分组管理 | | KSV 助手 | 查看节点和镜像的操作进度,以及添加可选功能 | |告警|提供告警消息汇总列表,告警策略汇总列表和告警策略的详情| |日志|记录和查询各个功能模块中的操作日志,包括对象级别,时间,详情等内容|
KSV 平台功能介绍 - 节点| 管理名称-子功能 | 功能说明 | | —- | —- | | 节点监控-节点信息 | 包括节点IP,操作系统,内核版本等 | | 节点监控-资源实时监控 | 包括CPU,内存的实时监控 | | 节点监控-网络状态 | 节点网络状态的实时监控 | | 节点监控-监控监控 | 节点监控状态监控 | | 节点监控-资源状态 | 创建,还原,删除快照 | | 节点监控-事件 | 查看虚拟机事件,支持导出 | | 节点监控-虚拟机列表 | 查看该节点下的虚拟机 | | 节点监控-添加节点 | 可以批量添加节点 |
名称解释:
事件:类似日志系统,可以查看节点的事件来源,类型等内容
KSV 平台功能介绍 - 网络| 管理名称-子功能 | 功能说明 | | —- | —- | | IPPOOL-IPAM | 通过IPPOOL的配置进行IPAM的管理 | | IPPOOL-VLAN支持 | 支持VLAN |
名称解释:
- IPAM:即 IP 地址管理
KSV 平台功能介绍 - 虚拟机| 管理功能-子功能 | 功能说明 | | —- | —- | | VM管理-创建VM | VM 基础配置,磁盘选择,IPPOOL 选取 | | VM管理-删除VM | 删除 VM,可选择是否销毁磁盘 | | VM管理-启动 & 关闭 | 启动 & 关闭VM | | VM管理-重启 | 重启 VM | | VM管理-快照 | 创建,还原,删除快照 | | VM管理-事件 | 查看虚拟机事件 | | VM管理-挂盘管理 | 挂载,卸载数据盘 | | VM控制台-VNC 接入 | VNC 登录虚拟机 | | VM控制台-Terminal 登录 | Terminal 登录虚拟机 |
名称解释:
- VNC:虚拟网络计算机,连接虚拟服务器的一种远程控制工具软件
- Terminal:连接到VM 虚拟机的终端连接工具,如SSH,RDP
KSV 平台功能介绍 - 镜像| 管理名称-子功能 | 功能说明 | | —- | —- | | 镜像导入-HTTP导入 | 支持HTTP方式导入 raw & qcow2 格式的镜像 | | 镜像导入-Block导入 | 支持项目间镜像互转 |
迭代功能:
- Docker 镜像导入:支持将镜像文件打包为 docker,然后由 docker 仓库拉取
- ISO 镜像:支持 ISO 格式的镜像导入
- 更多操作系统种类镜像支持:支持Win Server 系统,各版本的Linux 系统,国产操作系统等。
- 镜像导出:支持手动的方式,由底层存储导出镜像
KSV 平台功能介绍 - 磁盘| 管理名称-子功能 | 功能说明 | | —- | —- | | 磁盘管理-系统盘创建 & 删除 | 依托镜像进行系统盘的创建 | | 磁盘管理-数据盘创建 & 删除 | 创建指定大小的数据盘 | | 快照管理-制作快照 | 制作快照,用于 VM 的备份 | | 快照管理-快照恢复 | 使用快照恢复VM | | 磁盘扩容-磁盘扩容 | 支持磁盘动态扩容 |
名称解释:
- 动态扩容:在实际生产系统中,我们经常会遇到某个服务需要扩容的场景,也可能会遇到由于资源紧张或者工作负载降低而需要减少服务实例数的场景。此时可以利用命令行来完成这些任务。
KSV 平台功能介绍 - 项目| 管理名称-子功能 | 功能说明 | | —- | —- | | 项目管理-项目设置 | 包括对项目的添加,删除,修改等操作 | | 账号管理-账号设置 | 对账号的添加,修改,删除等操作 |
名称解释:
- 项目:可根据项目进行项目划分,也可根据业务 & 部门进行划分
- 账号:到不同的项目 & 业务中,设置为不同的角色取消,对项目中的 VM 等资源进行管理
KSV 平台功能介绍 - KSV 助手| 管理名称-子功能 | 功能说明 | | —- | —- | | 操作进度-镜像 | 实时查看镜像上传,共享的进度 | | 操作进度-节点 | 实时查看节点创建的进度以及日志 | | 可选功能-可选功能 | 可以自主安装 “告警” “日志” 两个功能 |
名称解释:
- 可选功能:KSV 默认安装包中未安装的功能,用户可以根据自身需求,按文档步骤进行自主安装。
KSV 平台功能介绍 - 告警| 管理功能-子功能 | 功能说明 | | —- | —- | | 告警消息-搜索 | 可根据告警状态和告警级别进行搜索 | | 告警消息-消息列表 | 查看告警消息 | | 告警策略-创建策略 | 创建告警策略 | | 告警策略-告警策略列表 | 查看告警策略 |
名称解释:
- 告警消息:某个节点或者虚拟机触发了某个告警策略而产生的信息
- 告警策略:规定某个节点或者虚拟机的指标达成了一定规范触发告警消息
- KSV 平台功能介绍 - 日志 | 管理名称 | 功能说明 | | —- | —- | | 日志列表 | 以项目,时间和信息展示日志内容 | | 详细日志 | 展示详细的日志内容 | | 导出 | 表格以 Execl 格式进行导出,日志详情以 txt 形式导出 |
6.5.2 KSV 平台功能介绍
6.5.2.1 KSV 平台单节点安装
(1)前提条件
- 服务器节点操作系统版本需要为 Ubuntu 18.04、Ubuntu 20.04、CentOS 7.9、CentOS 8.5 或银河麒麟 V10。其他操作系统尚未充分测试,可能存在未知问题。未来将支持更多操作系统。
检查操作系统版本:- 服务器节点的硬件配置必须满足以下条件:
检查 CPU 核心数(两行命令回显结果相乘为服务器节点 CPU 核心总数):- 服务器节点必须至少具有 1 个未格式化且未分区的磁盘,或 1 个未格式化的分区。该磁盘或分区的最低配置为 100 GB,推荐配置为 200 GB。
检查服务器节点磁盘分区:- 服务器节点需要支持虚拟化。如果服务器节点不支持虚拟化,KSV 将以模拟模式运行。该模式将占用更多资源,且可能影响性能。
检查服务器节点是否支持虚拟化(若无回显则不支持虚拟化):(2)安装 KSV
- 以
root用户登录服务器节点。- 执行以下命令下载安装包(安装包大小约 4.2 GB):
- 执行以下命令解压安装包:
- 执行以下命令进入安装包解压后生成的目录:
- 执行以下命令开始安装:
- 从安装成功回显中的
Console、Username和Password参数分别获取 KSV Web 控制台的地址、系统管理员用户名和系统管理员密码。- (可选)安装结束后,执行以下命令查看安装日志:
KSV单节点安装站点:
https://kubesphere.cloud/docs/ksv/installation/install-ksv-in-single-node-mode/
| 硬件 | 最低配置 | 推荐配置 |
|---|---|---|
| CPU | 4 核 | 8 核 |
| 内存 | 8 GB | 16 GB |
| 系统磁盘 | 100 GB | 100 GB |
$ cat /etc/issue
$ cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
检查内存大小:
检查可用磁盘大小:
$ lsblk -f
例如,以下回显表明 vdb 磁盘为满足条件的设备:
$ grep -E '(svm|vmx)' /proc/cpuinfo
$ curl -k -O https://virtualization.kubesphere.cloud/v1.2.0/kubesphere-virtualization-amd64-v1.2.0.tar.gz
$ tar -zxvf kubesphere-virtualization-amd64-v1.2.0.tar.gz
$ cd kubesphere-virtualization
$ ./install.sh -a --ratio <超卖比>
如果显示如下信息则安装成功:备注
KSV Web 控制台提供以下默认用户:
- 系统管理员:用户名
admin,密码P@88w0rd。default项目管理员:用户名project-default-admin,密码123456。default项目操作员:用户名project-default-operator,密码123456。
$ ksv logs
6.5.2.2 KSV 平台多节点安装
(1)前提条件
- 多节点模式需要至少 3 个服务器节点。
- 服务器节点操作系统版本需要为 Ubuntu 18.04、Ubuntu 20.04、CentOS 7.9、CentOS 8.5 或银河麒麟 V10。其他操作系统尚未充分测试,可能存在未知问题。未来将支持更多操作系统。
检查操作系统版本:- 每个服务器节点的硬件配置都必须满足以下条件:
检查 CPU 核心数(两行命令回显结果相乘为服务器节点 CPU 核心总数):- 多节点模式下必须确保至少 3 个服务器节点用作工作节点(控制平面节点同时也可以为工作节点)。每个工作节点都必须至少具有 1 个未格式化且未分区的磁盘,或 1 个未格式化的分区。该磁盘或分区的最低配置为 100 GB,推荐配置为 200 GB。
检查工作节点磁盘分区:- 所有服务器节点都需要支持虚拟化。如果存在不支持虚拟化的服务器节点,KSV 将以模拟模式运行。该模式将占用更多资源,且可能影响性能。
检查服务器节点是否支持虚拟化(若无回显则不支持虚拟化):- 所有服务器节点的时间必须同步。
(2)安装 KSV
- 以
root用户登录任意服务器节点。- 执行以下命令下载安装包(安装包大小约 4.2 GB):
- 执行以下命令解压安装包:
- 执行以下命令进入安装包解压后生成的目录:
- 执行以下命令编辑
config-sample.yaml文件并在hosts和roleGroups参数下配置节点信息:- 执行以下命令开始安装:
- 从安装成功回显中的
Console、Username和Password参数分别获取 KSV Web 控制台的地址、系统管理员用户名和系统管理员密码。- (可选)安装结束后,执行以下命令查看安装日志:
KVS 平台多节点安装:
https://kubesphere.cloud/docs/ksv/installation/install-ksv-in-multi-node-mode/
# 设置DNS域名解析地址
tee >> /etc/resolv.conf <<-'EOF'
# ADD DNS BEGIN
nameserver 8.8.8.8
nameserver 114.114.114.114
# ADD DNS END
EOF
# 机器设置主机名
hostnamectl set-hostname ksv-master | ksv-node01 | ksv-node02
# 所有机器设置命令提示符
echo 'export PS1="(KSV-master) [\u@\h \W]\$ "' >> .bashrc
echo 'export PS1="(KSV-node01) [\u@\h \W]\$ "' >> .bashrc
echo 'export PS1="(KSV-node02) [\u@\h \W]\$ "' >> .bashrc
| 硬件 | 最低配置 | 推荐配置 |
|---|---|---|
| CPU | 4 核 | 8 核 |
| 内存 | 8 GB | 16 GB |
| 系统磁盘 | 100 GB | 100 GB |
cat /etc/issue
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
检查内存大小:
检查可用磁盘大小:
lsblk -f
例如,以下回显表明 vdb 磁盘为满足条件的设备:
grep -E '(svm|vmx)' /proc/cpuinfo
curl -k -O https://virtualization.kubesphere.cloud/v1.2.0/kubesphere-virtualization-amd64-v1.2.0.tar.gz
tar -zxvf kubesphere-virtualization-amd64-v1.2.0.tar.gz
cd kubesphere-virtualization
vi config-sample.yaml
以下为示例配置:
相关参数描述如下:
| 参数 | 描述 |
|---|---|
| hosts | |
| name | 节点名称。 |
| address | 节点的 SSH 登录 IP 地址。 |
| internalAddress | 节点在子网内部的 IP 地址。 |
| port | 节点的 SSH 端口号。如果使用默认端口 22 可不设置此参数。 |
| user | 节点的 SSH 登录用户名。如果使用 root用户可不设置此参数。 |
| password | 节点的 SSH 登录密码。如果已经设置 privateKeyPath可不设置此参数。 |
| privateKeyPath | 节点的 SSH 登录密钥的路径。如果已经设置 password可不设置此参数。 |
| roleGroups | |
| etcd | 安装 etcd 数据库的节点,一般设置为集群控制平面节点。 |
| controlPlane | 集群控制平面节点。集群中可设置多个控制平面节点。 |
| worker | 集群工作节点。工作节点上可以创建虚拟机。多节点模式下集群中必须至少有 3 个工作节点,控制平面节点同时也可以是工作节点。 |
./install.sh -m --ratio <超卖比>
如果显示如下信息则安装成功:备注
KSV Web 控制台提供以下默认用户:
- 系统管理员:用户名
admin,密码P@88w0rd。default项目管理员:用户名project-default-admin,密码123456。default项目操作员:用户名project-default-operator,密码123456。
ksv logs
6.5.2.3 KSV 平台多节点演示
# 使用 admin 超级管理员登录KSV平台
http://10.0.0.101:30880
- 用户名: admin
- 密码: P@88w0rd
管理指南 - 用户
Reference:
https://kubesphere.cloud/docs/ksv/management/users/
https://kubesphere.cloud/docs/ksv/management/projects/
管理指南 - 登录 Web 控制台
Reference:
https://kubesphere.cloud/docs/ksv/management/web-console-introduction/
管理指南 - 概览
Reference:
https://kubesphere.cloud/docs/ksv/management/overview/
管理指南 - 节点
Reference:
https://kubesphere.cloud/docs/ksv/management/nodes/
管理指南 - IP池
Reference:
https://kubesphere.cloud/docs/ksv/management/ip-pools/
管理指南 - 虚拟机
Reference:
https://kubesphere.cloud/docs/ksv/management/vms/
管理指南 - 镜像
Reference:
https://kubesphere.cloud/docs/ksv/management/assets/
管理指南 - 磁盘
Reference:
https://kubesphere.cloud/docs/ksv/management/disks/
管理指南 - 项目
Reference:
https://kubesphere.cloud/docs/ksv/management/projects/
管理指南 - KSV助手
Reference:
https://kubesphere.cloud/docs/ksv/management/ksv-assistant/
管理指南 - 告警
Reference:
https://kubesphere.cloud/docs/ksv/management/alerts/
管理指南 - 日志
Reference:
https://kubesphere.cloud/docs/ksv/management/logs/
7 CKA 与 CKS 备考经验分享
7.1 如何高效备考 CKA
7.1.1 CKA / CKS 简介
CKA :Certified Kubernetes Administrator —> Kubernetes管理员认证 CKS :Certified Kubernetes Security Specialist —> Kubernetes安全专家认证
| CKA | CKS | |
|---|---|---|
| 考试时间 | 2 小时 | 2 小时 |
| 通过分数 | 66% | 67% |
| 证书有效期 | 3 年 | 2 年 |
| 考试费用 | $ 300 | $ 300 |
| 免费补考 | 1 次 | 1 次 |
| 认证条件 | 无 | 通过 CKA 认证 |
7.1.2 参考文档
- CKA
https://kubernetes.io/docs
https://github.com/kubernetes
https://kubernetes.io/blog
- CKS
https://kubernetes.io/docs
https://github.com/kubernetes
https://kubernetes.io/blog
Trivy:https://aquasecurity.github.io/trivy/
Sysdig:https://docs.sysdig.com/
Falco:https://falco.org/docs/
App Armor:https://gitlab.com/apparmor/apparmor-/wikis/Documnetation
7.1.3 考试环境
kubectl config use-context
7.1.4 学习途径推荐
视频课程
KubeSphere 官网,B 站,Udemy ……
GitHub
https://github.com/kelsayhightower/kubernetes-the-hard-way
https://github.com/kabary/kubernetes-cka/wiki
https://github.com/walidshaari/Kubernetes-Certigied-Administrator
https://github.com/walidshaari/Certified-Kubernetes-Security-Specialist官方资源
https://kubernetes.io
https://github.com/kubernetes联系实践
Katacode、killer.sh
公有云托管集群
minikube、kubeadm、kubekey ……
7.2 CKS 考纲与重点介绍
7.2.1 考试大纲
最新考纲地址:http://github.com/cncf/curriculum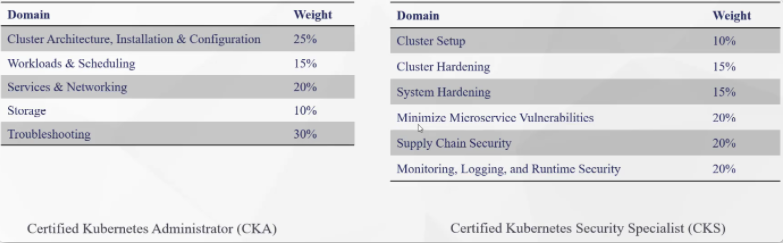
7.2.2 知识点梳理(CKA)
25% - 集群架构,安装和配置
- 管理基于角色的访问控制(RBAC)
https://kubernetes.io/docs/reference/access-authn-authz/rbac/
- 使用Kubeadm安装基本集群
- 设置基础架构以部署 Kubernetes 集群
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
- 管理高可用性的 Kubernetes 集群
https://kubernetes.io/docs/tasks/administer-cluster/highly-available-control-plane/
- 使用 Kubeadm 在 Kubernetes 集群上执行版本升级
https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
etcd 备份和还原https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/
15% - 工作负载和调度
- 了解部署以及如何执行滚动更新和回滚
https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
https://kubernetes.io/docs/tasks/manage-daemon/rollback-daemon-set/
- 使用 ConfigMaps 和 Secrets 配置应用程序
https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/
https://kubernetes.io/docs/concepts/configuration/secret/
https://kubernetes.io/docs/tasks/inject-data-application/distribute-credentials-secure/
- 了解如何扩容应用程序
http://kubernetes.io/docs/tutorials/kubernetes-basics/scale/scale-intro/
- 了解如何创建健壮的,自修复的应用程序部署
http://kubernetes.io/docs/tutorials/kubernetes-basics/deploy-app/deploy-intro/
- 了解 Pod 资源限制
http://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- 了解清单管理和通用模板工具
http://kubernetes.io/docs/reference/kubectl/
20% - 服务和网络
- 了解集群节点上的主机网络配置
- 理解 Pods 之间的连通性
- 选择适当的容器网络插件
https://kubernetes.io/docs/concepts/cluster-administration/networking/
- 了解 ClusterIP、NodePort、LoadBalancer 服务类型和端点
https://kubernetes.io/docs/concepts/services-networking/service/
- 了解如何使用 Ingress controllers 和 Ingress
https://kubernetes.io/docs/concepts/services-networking/ingress/
https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/
- 了解如何配置和使用 CoreDNS
https://kubernetes.io/docs/tasks/administer-cluster/coredns/
10% - 存储
- 了解 storage classes,persistent volumes
- 了解 volumes mode,access modes 和卷回收策略
- 了解 persistent volumes clamis
https://kubernetes.io/docs/concepts/storage/storage-classes/
https://kubernetes.io/docs/concepts/storage/volumes/
https://kubernetes.io/docs/concepts/storage/persistent-volumes/
- 了解如何为应用配置持久化存储
https://kubernetes.io/docs/tasks/configure-pod-container/configure-volume-storage/
30% - 故障排除
- 查看集群和节点日志
- 管理容器标准输出和标准错误日志
https://kubernetes.io/docs/concepts/cluster-administration/logging/
- 了解如何监视应用程序
https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
https://kubernetes.io/docs/tasks/debug-application-cluster/resource-metrics-pipeline/
- 应用程序故障排除
https://kubernetes.io/docs/debug-application-cluster/
- 集群组件故障排除
- 网络故障排除
https://kubernetes.io/docs/tasks/administer-cluster/coredns/
https://kubernetes.io/docs/tasks/debug-application-cluster/debug-cluster/
https://kubernetes.io/docs/tasks/administer-cluster/dns-debugging-resolution/
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/troubleshooting-kubeadm/
7.2.3 知识点梳理(CKS)
10% - 集群安装
- 使用网络安全策略来限制集群级别的访问
- 保护节点元数据和端点
https://kubernetes.io/docs/concepts/services-netwoking/network-policies/
- 使用 CIS 基准检查 Kubernetes 组件(etcd、kubelet、kubedns、kubeapi)的安全配置
使用开源检测工具:kube-bench- 正确设置带有安全控制的 Ingress 对象
https://kubernetes.io/docs/concepts/services-netwoking/ingress/
- 最小化 GUI 元素的使用和访问
https://github.com/kubernetes/dashboard/blob/master/docs/user/access-control/README.md
- 在部署之前验证平台的二进制文件
https://github.com/kubernetes/kubernetes/releases
15% - 集群强化
- 限制访问 Kubernetes API
https://kubernetes.io/docs/tasks/administer-cluster/access-cluster-api/
https://kubernetes.io/docs/concepts/security/controlling-access/
https://kubernetes.io/docs/tasks/run-application/access-api-from-pod/
- 使用基于角色的访问控制来最小化暴露(RBAC)
https://kubernetes.io/docs/reference/access-authn-authz/rbac/
- 谨慎使用服务账号,例如禁用默认设置,减少新创建账户的权限
https://kubernetes.io/docs/reference/access-authn-authz/service-accounts-admin/
https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/
- Kubernetes 版本升级
https://kubernetes.io/docs/tasks/administer-cluster/cluster-upgrade/
15% - 系统强化
- 最小化主机操作系统的大小(减少攻击面)
- 最小化 IAM 角色
https://kubernetes.io/docs/reference/access-authn-authz/rbac/
- 最小化对网络的外部访问
- 适当使用内核强化工具,如
AppArmor,seccomphttps://kubernetes.io/docs/tutorials/clusters/apparmor/
https://kubernetes.io/docs/tutorials/clusters/seccomp/
https://kubernetes.io/docs/tutorials/clusters/apparmor/#securing-a-pod
https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-the-seccomp-profile-for-a-container20% - 微服务漏洞最小化
- 设置适当的 OS 级安全域,例如:PSP、OPA、security contexts
https://kubernetes.io/docs/concepts/policy/pod-security-policy/
https://kubernetes.io/blog/2019/08/06/opa-gatekeeper-policy-and-governance-for-kubernetes/
https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
- 管理 Kubernetes 密钥
https://kubernetes.io/docs/concepts/configuration/secret/
- 在多租户环境中使用沙箱容器运行时(例如
gvisor,kata容器)https://kubernetes.io/docs/concepts/containers/runtime-class/
- 使用 mTLS 实现 Pod 对 Pod 的加密
https://kubernetes.io/docs/tasks/tls/managing-tls-in-a-cluster/
20% - 供应链安全
- 最小化基础镜像
https://sysdig.com/blog/dockerfile-best-practices/
- 将允许的镜像仓库加入白名单,对镜像进行签名和验证
https://kubernetes.io/docs/reference/access-authn-authz/admission-containers/#imagepolicywebhook
- 工作负载静态分析(e.g. kubernetes resources , docker files)
https://kubernetes.io/blog/2018/07/18/11-ways-not-to-get-hacked/#7-statically-analyse-yaml
- 扫描镜像,找出已知的漏洞
https://github.com/aquasecurity/trivy#quick-start
20% - 监控、日志记录和运行时安全
- 在主机容器级别执行系统调用进程和文件活动的行为分析,以及检测恶意活动
- 检测物理基础架构,应用程序,网络,数据,用户和工作负载中的威胁
https://kubernetes.io/docs/tutorials/clusters/seccomp/
- 检测攻击的所有阶段,无论它发生在哪里,如何扩散
- 深入分析,调查和识别环境中的异常行为
- 使用审计日志来监视访问
https://kubernetes.io/docs/tasks/debug-application-cluster/audit/
- 确保容器在运行时不变
7.2.4 技巧方法总结
- 熟练使用的命令行工具。善用 -h / —help
- kubectl / systemctl / journalctl
- CKS:kube-bench / trivy / sysdig / strace / lsof
- 设置 kubectl 自动补全,尽量使用 kubectl,避免手敲 yaml
- 自动补全:source <(kubectl completion bash)
- dry run:kubectl —dry-run=client -o yaml
- 将重点内容文档整理至浏览器标签
# 安装bash-completion(如果已经安装忽略即可):
sudo apt install bash-completion
# 测试一下:
source /usr/share/bash-completion/bash_completion
source <(kubectl completion bash)
# 测试没问题后,对 /root/.bashrc 加2行代码 ,方便以后每次登录自动生效:
echo "source <(kubectl completion bash)" >> ~/.bashrc
echo "source <(helm completion bash)" >> ~/.bashrc

若有收获,就点个赞吧
0 人点赞
