一、Flume概述
Flume是一个分布式、高可用、高可靠的海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时提供了对数据进行简单处理并写到各种数据接收方的能力。
二、Flume架构
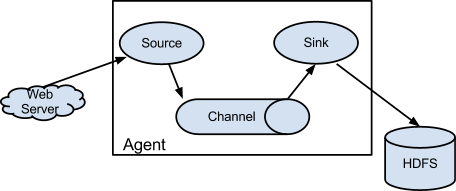
过程简要说明:
(1)外部数据源(Web Server)将Flume可识别的Event发送到Source;
(2)Source收到Event事件后存储到一个或多个Channel中;
(3)Channel保留Event直到Sink将其处理完毕;
(4)Sink从Channel中取出数据,并将其传输到外部存储,比如HDFS上。
2.1 Event
事件是Flume内部数据传输的最基本单元,将传输的数据进行封装。事件本身是由一个载有数据的字节数组和可选的 headers 头部信息构成,如下图所示。Flume以事件的形式将数据从源头传输到最终的目的地。
2.2 Agent
Flume Agent 是一个JVM进程,通过三个组件(Source、Channel、Sink)将事件流从一个外部数据源收集并发送给下一个目的地。
2.2.1 Source
从数据发生器接收数据,并将数据以Flume 的 Event 格式传递给一个或多个通道(Channel)
支持的source有:
- Avro Source
-
2.2.2 Channel
一种短暂的存储容器,位于Source和Sink之间,起着桥梁的作用。Channel将从Source处接收Event格式的数据并缓存起来,当Sink成功的将Event发送到吓一跳的Channel或最终目的地后,Event从Channel中移除。
Channel是一个完整的事务,这一点保证了数据在收发的时候的一致性。可以把Channel看成是一个FIFO队列,当数据的获取速率超过流出速率时,可以将Event保暂时的缓存到队列中,再从队列中一个一个取出来。
有以下几种Channel: Memory Channel 事件存储在可配置容量的内存队列中,队列容量即为可存储最大事件数,适用于高吞吐量的场景,在agent出现错误的时候可能会丢失部分数据。
- File Channel 给予文件系统的持久化存储机制。
- Spillable Memory Channel 内存和文件混合Channel,当内存队列满了之后,新的事件会存储在文件系统,目前处于实验阶段,不建议在生产中使用。
- JDBC Channel 事件存储在持久化的数据库中,目前只支持Derby。
- Kafka Channel 事件存储在Kafka集群中。
- Pseudo Transaction Channel 伪事务Channel,仅用于测试,不能在生产中使用。
- Custom Channel 自定义Channel。
2.2.3 Sink
获取Channel中暂时保存的数据并进行处理。Sink从Channel中移除事件,并将其发送到下一个Agent(简称下一跳)或者最终的目的地,比如HDFS。
2.3 可靠性
事件在每个Agent的Channel中暂时的存储,然后事件被发送到下一个Agent或者最终目的地。只有当事件存储在下一个Channel或最终存储后才会从当前的Channel中删除。
Flume使用事务的办法来保证Event的可靠传递。Source和Sink分别被封装在事务中,事务由保存Event的存储或者Channel提供。这就保证了Event在数据流的点对点传输中是可靠的。在多跳的数据流中,上一跳的Sink和下一跳的Source均运行事务来保证数据被安全地存储到下一跳的Channel中。
三、Flume的使用
下载地址:Flume官方下载地址
3.1 入门使用示例
3.1.1 安装Netcat
使用 Flume 监听某个端口,使用Netcat向这个端口发送数据,Flume将接收到的数据打印到控制台。
Netcat是一款 TCP/UDP测试工具,可以通过如下命令安装。
Linux 安装
yum install -y nc
MacOS安装
brew install netcat
3.1.2 使用组件
- NetCat TCP Source
必须属性
| 属性名 | 默认值 | 说明 |
|---|---|---|
| channels | - | |
| type | - | netcat |
| bind | - | 绑定的主机名或者IP地址 |
| port | - | 绑定的端口 |
- Memory Channel
必须属性
| 属性名 | 默认值 | 说明 |
|---|---|---|
| type | - | memory |
- Logger Sink
必须属性
| 属性名 | 默认值 | 说明 |
|---|---|---|
| channel | - | |
| type | - | logger |
3.1.3 添加配置文件
在 apache-flume-1.9.0/conf 目录下添加配置文件 example.conf
# example.conf: 单点flume配置# 定义agent名称为a1# 设置3个组建的名称a1.sources = r1a1.sinks = k1a1.channels = c1# 配置source类型为NetCat,监听地址为本机,端口为4444a1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 4444# 配置channel类型为内存,内存队列最大容量为1000,# 一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transacitonCapacity = 100# 配置sink类型为Loggera1.sinks.k1.type = logger# 将source和sink绑定到channel上a1.sources.r1.channels = c1 # 注意这里的channels必须写出复数形式a1.sinks.k1.channel = c1 # 注意这里channel不能写出复数形式
3.1.4 运行组件
启动 Netcat,监听4444端口
nc -lk localhost 4444
根据配置文件启动 Flume,并将日志打印到控制台,日志级别为INFO
flume-ng agent -n a1 -c $FLUME_HOME/conf -f $FLUME_HOME/conf/example-conf.properties -Dflume.root.logger=INFO,console
3.2 数据持久化
使用组件:File Channel
| 属性名 | 默认值 | ** |
|---|---|---|
| type | - | file |
| checkpointDir | ~/.flume/file-channel/checkpoint | 检查点文件存放路径 |
| dataDirs | ~/.flume/file-channel/data | 日志存储路径,多个路径使用逗号分隔。使用不同的磁盘上的多个路径能提高file channel的性能 |
四、日志文件监控
4.1 案例说明
企业中应用程序部署后会将日志写入文件中,可以使用Flume从各个日志文件中将日志收集到日志中心以便于查找和分析。
4.1.1 使用 Exec Source
- Exec Source 通过指定命令监控文件的变化,加红加粗属性为必须设置的。
| 属性名 | 默认值 | 说明 |
| —- | —- | —- |
| channels | - |
| | type | - | exec | | command | - | 要执行的命令 | | restart | false | 如果执行命令挂了是否要重启 | | batchSize | 20 | 同时往Channel发送的最大行数 | | batchTimeout | 3000 | 批量发送的事件 | | selector.type | replicating | channel选择器replicating或者multiplexing | | selector. | | 通道选择器匹配属性 | | interceptors | - | 拦截器 | | interceptors. | | |
添加配置文件 exec-log.conf
# example.conf: 单点flume配置# 定义agent名称为a1# 设置3个组建的名称a1.sources = r1a1.sinks = k1a1.channels = c1# 配置source类型为NetCat,监听地址为本机,端口为4444a1.sources.r1.type = execa1.sources.r1.command = tail -F app.log# 配置channel类型为内存,内存队列最大容量为1000,# 一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transacitonCapacity = 100# 配置sink类型为Loggera1.sinks.k1.type = logger# 将source和sink绑定到channel上a1.sources.r1.channels = c1 # 注意这里的channels必须写出复数形式a1.sinks.k1.channel = c1 # 注意这里channel不能写出复数形式
通过指定 ( tail ) 命令来监控日志变化这一方案存在的问题:
- 一、只能监控一个日志文件;
-
4.1.2 解决重复消费的问题
Taildir Source | 属性名 | 默认值 | 说明 | | —- | —- | —- | | channels | - | | | type | - | TAILDIR. | | filegroups | - | 可以定义多个组,每个组里包含一序列被监控的文件 | | filegroups.**
| - | 被监控的文件的绝对路径,文件名支持正则表达式 | | positionFile | ~/.flume/taildir_position.json | 记录监控文件的绝对路径和上次读取位置**的json文件 |
新增 dir-log.conf
# example.conf: 单点flume配置# 定义agent名称为a1# 设置3个组建的名称a1.sources = r1a1.sinks = k1a1.channels = c1# 配置source类型为TAILDIR,监听命令为tail,日志文件为app.loga1.sources.r1.type = TAILDIRa1.sources.r1.filegroups = f1 f2a1.sources.r1.positionFile = /Volumes/Lighting/dev/log-app/position.jsona1.sources.r1.filegroups.f1 = /Volumes/Lighting/dev/log-app/app1.loga1.sources.r1.filegroups.f2 = /Volumes/Lighting/dev/log-app/logs/.*log# 配置channel类型为内存,内存队列最大容量为1000,# 一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transacitonCapacity = 100# 配置sink类型为Loggera1.sinks.k1.type = logger# 将source和sink绑定到channel上a1.sources.r1.channels = c1a1.sinks.k1.channel = c1
4.2 多个agent模型
可以将多个 Flume agent 程序连接在一起,其中一个 agent 的 sink 将数据发送给另一个agent的source。
Avro文件格式是使用Flume通过网络发送数据的标准方法。
从多个Web服务器收集日志,发送到一个或多个几种处理的agent,之后再发送到日志存储中心。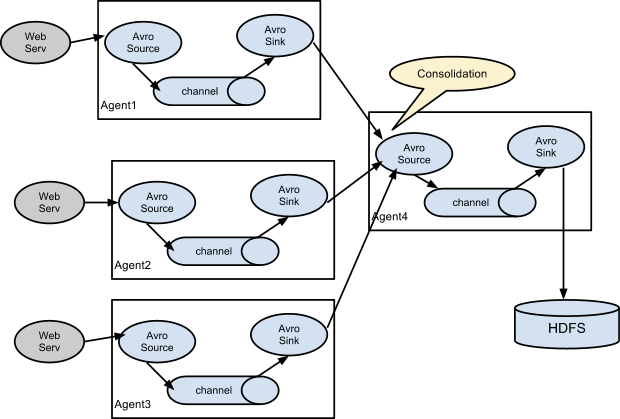
同样,还可以将一个Source中的日志发送到不同的目的地: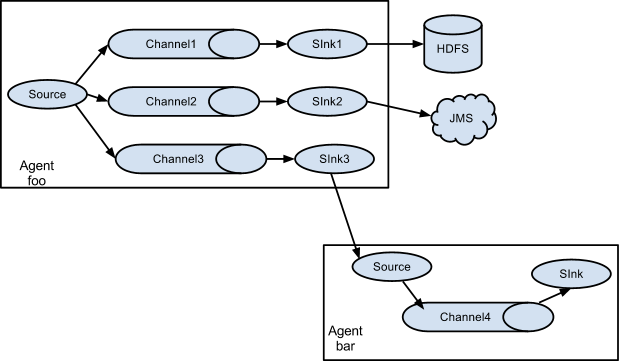
4.2.1 综合案例
设置两个agent:
- 第一个agent从Netcat接收数据,增加一个channel和sink,将这个sink发送到第二个agent
- 第二个agent监控某个日志文件,同时监控从sink发送来的事件,最终输出到控制台
使用Avro Sink,必须设置以下属性
| 属性名 | 默认值 | 说明 |
|---|---|---|
| channel | - | |
| type | - | avro |
| hostname | - | 绑定的主机名或者ip地址 |
| port | - | 监听端口 |
使用 Avro Source,必须设置以下属性
| 属性名 | 默认值 | 说明 |
|---|---|---|
| channels | - | |
| type | - | avro |
| bind | - | 绑定的主机名或者ip地址 |
| port | - | 监听端口 |
添加agent1配置文件: agent1-conf.properties
# 设置3个组建的名称a1.sources = r1a1.sinks = k1 k2a1.channels = c1 c2# 配置source类型为NetCat,监听地址为本机,端口为4444a1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 4444# 配置sink1类型为Loggera1.sinks.k1.type = logger# 配置sink2类型为avroa1.sinks.k2.type = avroa1.sinks.k2.hostname = 192.168.1.3a1.sinks.k2.port = 5555# 配置channel类型为内存,内存队列最大容量为1000,# 一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100# channel1a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transacitonCapacity = 100# channel2a1.channels.c2.type = memorya1.channels.c2.capacity = 1000a1.channels.c2.transacitonCapacity = 100# 将source和sink绑定到channel上a1.sources.r1.channels = c1 c2a1.sinks.k1.channel = c1a1.sinks.k2.channel = c2
添加agent2配置文件 agent2-conf.properties
# example.conf: 单点flume配置# 定义agent名称为a1# 设置3个组建的名称a1.sources = r1 r2a1.sinks = k1a1.channels = c1# 配置source1类型为TAILDIR,监听命令为tail,日志文件为app1.log,logs/*.loga1.sources.r1.type = TAILDIRa1.sources.r1.filegroups = f1 f2a1.sources.r1.positionFile = /Volumes/Lighting/dev/log-app/position.jsona1.sources.r1.filegroups.f1 = /Volumes/Lighting/dev/log-app/app1.loga1.sources.r1.filegroups.f2 = /Volumes/Lighting/dev/log-app/logs/.*log# 配置source2类型为avroa1.sources.r2.type = avroa1.sources.r2.bind = 192.168.1.3a1.sources.r2.port = 5555# 配置channel类型为内存,内存队列最大容量为1000,# 一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transacitonCapacity = 100# 配置sink类型为Loggera1.sinks.k1.type = logger# 将source和sink绑定到channel上a1.sources.r1.channels = c1a1.sources.r2.channels = c1a1.sinks.k1.channel = c1
4.3 拦截器
拦截器可以修改或者丢弃事件,Flume支持链式调用拦截器,拦截器定义在sources中
4.3.1 Host Interceptor
这个拦截器将运行的agent的hostname或者IP地址写入到事件的headers中
| 属性名 | 默认值 | 说明 |
|---|---|---|
| type | - | host |
| preserveExisting | false | 如果headers已经存在host,是否要保留 |
| useIP | true | true:为IP地址,false:为hostname |
| hostHeader | host | header中key的名称 |
在 agent1-conf.properties 中新增配置
a1.sources.r1.interceptors = r1a1.sources.r1.interceptors.r1.type = host
启动 agent1 ,这时从 agent1 中发送的事件的 headers 中都会带上 agent1 的IP地址。
4.3.2 Timestamp Interceptor
这个拦截器会将当前时间写入到事件的 headers 中
| 属性名 | 默认值 | 说明 |
|---|---|---|
| type | - | timestamp |
| headerName | timestamp | header中key的名称 |
| preserveExisting | false | 如果headers中已经存在timestamp,是否需要保留【true:保留原始的,false:写入当前的】 |
在 agent1-conf.properties 中新增配置
a1.sources.r1.interceptors = i1 i2a1.sources.r1.interceptors.i1 = hosta1.sources.r1.interceptors.i2 = timestamp

4.3.3 Static Interceptor
允许用户对所有的事件添加固定的header
| 属性名 | 默认值 | 说明 |
|---|---|---|
| type | - | static |
| preserveExisting | true | 如果header中已存在相关配置,是否需要保留【true:保留原始的,false:写入当前的】 |
| key | key | header 中 key 名称 |
| value | value | header 中 value 值 |
在 agent1-conf.properties 中新增配置
a1.sources.r1.interceptors = i1 i2 i3a1.sources.r1.interceptors.i1.type = hosta1.sources.r1.interceptors.i2.type = timestampa1.sources.r1.interceptors.i3.type = statica1.sources.r1.interceptors.i3.key = datacentera1.sources.r1.interceptors.i3.value = NEW_YOURK

4.3.4 UUID Interceptor
a1.source.r1.interceptors.i4.type = org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder

4.3.5 Search and Replace Interceptor
适用于脱敏操作
# 根据正则进行查找,然后替换a1.sources.r1.interceptors.i5.type = search_replacea1.sources.r1.interceptors.i5.searchPattern = \\d{6}a1.sources.r1.interceptors.i5.replaceString = ******

4.4 自定义拦截器
4.4.1 实现拦截器
/*** 自定义拦截器** @author sebuntin* @since 2021-05-16*/public class MyInterceptor implements Interceptor {private static final Logger LOGGER = LoggerFactory.getLogger(MyInterceptor.class);private String name;@Overridepublic void initialize() {this.name = "sebuntin";}/*** 对事件进行拦截,并进行处理** @param event {@link Event} 事件* @return {@link Event} 处理后返回的事件*/@Overridepublic Event intercept(Event event) {// 对事件进行处理,事件包含消息体和头部if (event.getHeaders().get("host").equals("192.168.1.3")) {event.setHeaders(new HashMap<String, String>() {{put("name", "sebuntin");}});LOGGER.info("event comes from 192.168.1.3");return event;}return null;}/*** 对所有事件进行拦截** @param list 事件列表* @return 处理后的事件列表*/@Overridepublic List<Event> intercept(List<Event> list) {return list.stream().map(this::intercept).filter(Objects::nonNull).collect(Collectors.toList());}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {// 启用MyInterceptor@Overridepublic Interceptor build() {return new MyInterceptor();}// 初始化配置@Overridepublic void configure(Context context) {}}}
4.4.2 导出jar包并置于 $FLUME_HOME/lib 目录下

4.4.3 使用拦截器
# 添加自定义拦截器,type为自定义拦截器类型全名,并且需要加上 $Builder 以启用拦截器a1.sources.r2.interceptors = i1a1.sources.r2.interceptors.i1.type = com.sebuntin.flumedemo.interceptor.MyInterceptor$Builder
4.5 Channel选择器
channel选择器默认有两种:
- Replication Channel Selector 复制选择器,如果没有指定,其为默认选择器
- Multiplexing Channel Selector 多路Channel选择器
4.5.1 Replication Channel Selector
复制选择器,如果没有指定,其为默认的选择器
可选属性如下:
| 属性名 | 默认值 | 说明 |
|---|---|---|
| selector.type | replicating | replicating |
| selector.optional | - | optional |
使用案例:
a1.sources = r1a1.channels = c1 c2 c3a1.sources.r1.selector.type = replicatinga1.sources.r1.channels = c1 c2 c3a1.sources.r1.selector.optional = c3
上面👆的配置中,c3是一个可选的channel,写入c3失败的话会被忽略,c1和c2没有被标记可选,如果写入c1和c2失败会导致事务的失败。
4.5.1 Multiplexing Channel Selector
多路channel选择器,可选属性如下
| 属性名 | 默认值 | 说明 |
|---|---|---|
| selector.type | replicating | multiplexing |
| selector.header | flume.selector.header | 指定头部中的某个key |
| selector.default | - | |
| selector.mapping.* | - | 路由 |
使用案例:
a1.sources = r1a1.channels = c1 c2 c3 c4a1.sources.r1.selector.type = multiplexing# 指定头部中的key为statea1.sources.r1.selector.header = state# 当state=CZ时选择c1,当state=US时选择c2 c3a1.sources.r1.selector.mapping.CZ = c1a1.sources.r1.selector.mapping.US = c2 c3a1.sources.r1.selector.default = c4
这里通过事件的header值来判断将事件发送到哪个channel,可以配合拦截器一起使用。
4.6 Sink 处理器
可以将多个sink放入到一个组中,Sink处理器能够对一个组中所有的Sink进行负载均衡,在一个Sink出现临时错误时进行故障转移。
必须设置的属性:
| 属性名 | 默认值 | 说明 |
|---|---|---|
| sinks | - | 组中多个sink使用空格分隔 |
| processor.type | default | default, failover 或 load_balance |
举例:
a1.sinkgroups = g1a1.sinkgroups.g1.sinks = k1 k2a1.sinkgroups.g1.processor.type = failover
4.6.1 Default Sink Processor
默认的Sink处理器只支持单个Sink
4.6.2 Failover Sink Processor
故障转移处理器维护了一个带有优先级的sink列表,故障转移机制将失败的sink放入到一个冷却池中,如果sink成功发送了事件,将其放入到活跃池中,sink可以设置优先级,数字越高,优先级越高,如果一个sink发送事件失败,下一个有更高优先级的sink将被用来发送事件,比如,优先级100的比优先级为80的先被使用,如果没有设置优先级,按配置文件中配置的顺序决定。设置属性如下所示:
| 属性名 | 默认值 | 说明 |
|---|---|---|
| sinks | - | 组内多个sinks空格分隔 |
| processor.type | defalut | failover |
| processor.priority | - | 优先级 |
| processor.maxpenalty | 30000 | 失败sink的最大冷却时间 |
4.6.3 Load Balancing Sink Processor
负载均衡处理器,可以通过轮询或者随机的方式进行负载均衡,也可n以通过继承 AbstractSinkSelector 自定义负载均衡,设置属性如下:
| 属性名 | 默认值 | 说明 |
|---|---|---|
| processor.sinks | - | 组内多个sinks空格分隔 |
| processor.type | default | load_balance |
| processor.backoff | false | 是否将失败的sink加入黑名单 |
| processor.selector | round_robin | 轮询机制 round_robin ,random 或自定义 |
| processor.selector.maxTimeOut | 30000 | 黑名单有效时间(ms) |
4.7 将日志数据导入HDFS
数据导入到HDFS中需要使用HDFS Sink,需要配置属性如下:
| 属性名 | 默认值 | 说明 |
|---|---|---|
| channel | - | |
| type | - | hdfs |
| hdfs.path | - | HDFS文件路径 (例如hdfs://namenode/flume/webdata/) |
| hdfs.fileType | SequencdFile | 文件格式:SequenceFile、DataStream、CompressedStream (1) DataStream 不会压缩输出文件且不用设置codeC (2) CompressedStream 需要设置 hdfs.codeC |
| hdfs.codeC | 压缩格式:gzip、bzip2、lzo、lzop、snappy |
注:使用 HDFS Sink 需要用到 Hadoop 的多个包,可以在装有 Hadoop 的主机上运行 Flume,如果是单独的 Flume,可以通过多个Agent的形式将单独部署的Flume Agent 日志数据发送到装有 Hadoop 的 Flume Agent 上。
创建 hdfs.conf
# 定义agent名称为a1# 设置3个组件的名称a1.sources = r1a1.sinks = k1a1.channels = c1# 配置source类型为NetCat,监听地址为本机,端口号为4444a1.sources.r1.type = netcata1.sources.r1.bind = localhosta1.sources.r1.port = 4444# 配置sink类型为hdfsa1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = hdfs://node01:9000/user/flume/logsa1.sinks.k1.hdfs.fileType = DataStream# 配置 channel 类型为内存,最大容量为1000,# 一个事务中从source接收的Events数量或者发送给sink的Events数量最大为100a1.channels.c1.type = memorya1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# 将source和sink绑定到channel上a1.sources.r1.channels = c1a1.sinks.k1.channels = c1
启动 flume
flume-ng agent --conf conf/ --conf-file conf/hdfs.conf -Dfile.root.logger=debug,info,console --name hdfs
注:如果出现 com.google.common.base.Preconditions.checkArgument 查看 flume/lib 目录下的 guava.jar 版本是否与 hadoop/share/hadoop/common/lib 中的版本是否一致,不一致需要拷贝新版本重新运行。
五、Flume SDK
5.1 自定义Source
需要继承自 org.apache.flume.source.AbstractSource ,并实现 org.apache.flume.conf.Configurable、org.apache.flume.PollableSource 两个接口。
/*** 自定义source*/public class MySource extends AbstractSource implements Configurable, PollableSource {// 处理源数据(生产数据)@Overridepublic Status process() throws EventDeliveryException {Status status = null;try {for (int i = 0; i < 10; i++) {final Event event = new SimpleEvent();event.setBody(("data:" + i).getBytes(StandardCharsets.UTF_8));// 将数据存储到与Source关联的Channel中getChannelProcessor().processEvent(event);// 数据准备完成status = Status.READY;}// 休眠2秒Thread.sleep(2000);} catch (Exception e) {e.printStackTrace();status = Status.BACKOFF;}return status;}@Overridepublic long getBackOffSleepIncrement() {return 0;}@Overridepublic long getMaxBackOffSleepInterval() {return 0;}@Overridepublic void configure(Context context) {}}
5.2 自定义Sink
自定义Sink需要继承自 org.apache.flume.sink.AbstractSink 并实现 org.apache.flume.conf.Configurabl 接口。
/*** 自定义sink*/public class MySink extends AbstractSink implements Configurable {private static final Logger LOGGER = LoggerFactory.getLogger(MySink.class);// 消费数据@Overridepublic Status process() throws EventDeliveryException {Status status = null;// 获取与Sink绑定的Channelfinal Channel ch = getChannel();// 获取事务final Transaction transaction = ch.getTransaction();try {// 开启事务transaction.begin();// 从channel中接收数据final Event event = ch.take();// 将数据发送到外部服务if (event == null) {status = Status.BACKOFF;} else {LOGGER.info(new String(event.getBody()));status = Status.READY;}// 提交事务transaction.commit();} catch (Exception e) {LOGGER.error(e.getMessage());status = Status.BACKOFF;// 回滚事务transaction.rollback();} finally {// 关闭事务transaction.close();}return status;}@Overridepublic void configure(Context context) {}}
六、Flume监控—-Ganglia
Ganglia是UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia的核心包含gmond (监控守护进程)、gmetad (元数据守护进程) 以及一个Web前段。主要用来监控系统性能,如:cpu、mem、硬盘利用率、I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
6.1 Ganglia安装
6.1.1 中心节点的安装
- epel包的安装:yum install -y epel-release
- gmetad的安装: yum install -y ganglia-gmetad
- gmond的安装: yum install -y ganglia-gmond
- rrdtool的安装: yum install -y rrdtool
- httpd服务器的安装: yum install -y httpd
ganglia-web及php安装: yum install -y ganglia-web php
6.1.2 被检测节点的安装
epel包的安装: yum install -y epel-release
gmond的安装: yum install -y gmond
6.2 Ganglia配置
6.2.1 中心节点的配置
安装目录说明
ganglia 配置文件目录: /etc/ganglia
- rrd数据库存放目录: /var/lib/ganglia/rrds
- ganglia-web安装目录: /usr/share/ganglia
- ganglia-web配置目录: /etc/httpd/conf.d/ganglia.conf
相关配置文件修改
将ganglia-web的站点目录连接到httpd主站点目录
ln -s /usr/share/ganglia /var/www/html
修改httpd主站点目录下ganglia站点目录的访问权限
将ganglia站点目录访问权限改为 apache:apache,否则会报错
chown -R apache:apache /var/www/html/gangliachmod -R 755 /var/www/html/ganglia
修改rrd数据库存放目录访问权限
将rrd数据库存放目录访问权限改为 nobody:nobody ,否则会报错
chown -R nobody:nobody /var/lib/ganglia/rrds
修改ganglia-web的访问权限
修改/etc/httpd/conf.d/ganglia.conf
shell## Ganglia monitoring system php web fronted#Alias /ganglia /usr/share/ganglia<Location /ganglia>Require all granted# Require ip 10.1.2.3# Require host example.org</Location>
修改dwoo访问权限
chmod 777 /var/lib/ganglia/dwoo/compiledchmod 777 /var/lib/ganglia/dwoo/cache
配置 /etc/ganglia/gmetad.conf
data_source "my cluster" 192.168.85.132:8649setuid_username nobody
配置 /etc/ganglia/gmond.conf
cluster {name = "node01"...}udp_send_channel {# host 收集集群监控数据发送到gmetad元数据节点# 注释掉多播模式,以下出现这个都要注释掉# mcat_join = 239.2.11.71# 添加单播模式host = 192.168.1.3port = 8649}udp_recv_channel {bind = 192.168.1.3port = 8649}tcp_accept_channel {port = 8649}

若有收获,就点个赞吧
0 人点赞
