Hive介绍
- 专用定义
- 英文名称为Data Warehouse,可简写为DW
- 是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合
- 它是单个数据存储,出于分析性报告和决策支持目的而创建
- 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制
- 通俗解释
- 面向分析的存储系统(面向数据分析的存储系统)
- 一个面向主题的(Subject Oriented)、集成的(Integrate)、不可修改的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于数据分析、辅助管理决策
- 面向主题:指数据仓库中的数据是按照一定的主题域进行组织
- 集成:指对原有分散的数据库数据经过系统加工, 整理得到的消除源数据中的不一致性
- 不可修改:指一旦某个数据进入数据仓库以后只需要定期的加载、刷新,不会更改
- 反映历史变化:指通过这些信息,对企业的发展历程和未来趋势做出定量分析预测
- 数据仓库和数据库对比分析
- 主要联系
- 两者均是用来存储数据的,即均为数据的存储载体
- 数据仓库也是数据库,是数据库的一种衍生、延深应用
- 数库仓库和数据库之间存在数据交互,即你中有我、我中有你
- 数据库中的在线数据推送到离线的数据仓库用于分析处理
- 数据仓库中分析处理的结果数据也通常推送到关系数据库中,便于前台应用的可视化展现应用
- 数据仓库的出现,并不是要取代数据库,且当下大部分数据仓库还是用关系数据库管理系统来管理的,即数据库、数据仓库相辅相成、各有千秋
- 主要区别
- 数据库是面向事务的设计,数据仓库是面向主题设计的
- 数据库一般存储在线交易数据,实时性强存储空间有限,数据仓库存储的一般是历史数据,实时性弱但存储空间庞大
- 数据库设计是尽量避免冗余,数据仓库在设计是有意引入冗余
- 数据库是为捕获数据而设计,即实时性强吞吐量弱,数据仓库是为分析数据而设计,即吞吐量强实时性弱
- 主要联系
Hive的产生
- 定义
- Hive是建立在 Hadoop 上的数据仓库基础架构和解决方案
- 架构:支持拿来即用,亦支持灵活的参数和计算引擎的变更
- 作用
- 拿出了数据仓库构建的完整解决方案
- 意义
- 基于Hadoop平台解决了企业数据仓库构建的核心技术问题,证明了Hadoop平台的强大
- 进一步降低了Hadoop使用的准入门槛
Hive在Hadoop生态圈的地位

Hive的使用与Mysql的sql类似
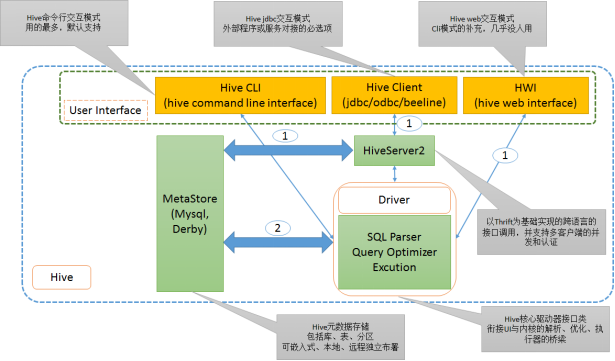
Hive架构设计

特别说明:hive2.2以后版本变化较大,去掉了HWI模块,HiveCLI模式也直接采用了beeline链接
Hive运行流程
Hive基础应用
Hive数据模型

数据类型
数值型
| 类型 | 说明 |
|---|---|
| TINYINT | 1-byte signed integer from -128 to 127 |
| SMALLINT | 2-byte signed integer from -32,768 to 32,767 |
| INT INTEGER |
4-byte signed integer from -2,147,483,648 to 2,147,483,647 |
| BIGINT | 8-byte signed integer from -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 |
| FLOAT | 4-byte single precision floating point number |
| DOUBLE | 8-byte double precision floating point number PRECISION |
| DECIMAL | Decimal datatype was introduced in Hive0.11.0 (HIVE-2693) and revised in Hive 0.13.0 (HIVE-3976) |
2.2 日期类型
| 类型 | 说明 |
|---|---|
| TIMESTAMP | UNIX时间戳和可选的纳秒精度 |
| DATE | 描述特定的年/月/日,格式为YYYY-MM-DD |
2.3 字符串
| 类型 | 说明 |
|---|---|
| string | 最常用的字符串格式,等同于java String |
| varchar | 变长字符串,hive用的较多,最长为65535 |
| char | 定长字符串,比varchar更多一些,一般不要超过255个字符 |
2.4 布尔类型
| 类型 | 说明 |
|---|---|
| boolean | 等同于java的boolean用的很少 |
2.5 字节数组
| 类型 | 说明 |
|---|---|
| binary | 字节数组类型,可以存储任意类型的数据用的很少 |
2.6 复杂(集合)数据类型
| 数据类型 | 描述 | 字面语法示例 |
|---|---|---|
| STRUCT | 和C语言中的struct或者”对象”类似,都可以通过”点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, lastdt STRING},那么第1个元素可以通过字段名.first来引用 | struct( ‘John’, ‘Doe’) |
| MAP | MAP是一组键-值对元组集合,使用数组表示法(例如[‘key’])可以访问元素。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取值’Doe’ | map(‘first’, ‘John’, ‘last’, ‘Doe’) |
| ARRAY | 数组是一组具有相同类型的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第1个元素可以通过数组名[0]进行引用 | ARRAY( ‘John’, ‘Doe’) |
3. hive数据文件格式和压缩格式
Ø 文件格式
文件格式按面向的存储形式不同,分为面向行和面向列两大类文件格式。
| 面向行/列类型 | 类型名称 | 是否可切割计算 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 面向行 | 文本文件格式(.txt) | 可以 | 查看、编辑简单 | 无压缩占空间大、传输压力大、数据解析开销大 | 学习练习使用 |
| 面向行 | SequenceFile序列文件格式(.seq) | 可以 | 自支持、二进制kv存储、支持行和块压缩 | 本地查看不方便:小文件合并成kv结构后不易查看内部数据 | 生产环境使用、map输出的默认文件格式 |
| 面向列 | rcfile文件格式(.rc) | 可以 | 数据加载快、查询快、空间利用率高、高负载能力 | 每一项都不是最高 | 学习、生产均可 |
| 面向列 | orcfile文件格式(.orc) | 可以 | 兼具rcfile优点、进一步提高了读取、存储效率、新数据类型的支持 | 每一项都不是最高 | 学习、生产均可 |
Ø 压缩格式
压缩格式按其可切分独立性,分成可切分和不可切分两种。
| 可切分性 | 类型名称 | 是否原生支持 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 可切分 | lzo(.lzo) | 否 | 压缩/解压速度快 合理的压缩率 |
压缩率比gzip低 不原生、需要native安装 |
单个文件越大,lzo优点越越明显。压缩完成后>=200M为宜 |
| 可切分 | bzip2(.bz2) | 是 | 高压缩率超过gzip 原生支持、不需要native安装、用linux bzip可解压操作 |
压缩/解压速率慢 | 处理速度要求不高、要求高压缩率(冷数据处理经常使用) |
| 不可切分 | gzip(.gz) | 是 | 压缩/解压速度快 原生/native都支持使用方便 |
不可切分、对CPU要求较高 | 压缩完成后<=130M的文件适宜 |
| 不可切分 | snappy(.snappy) | 否 | 高速压缩/解压速度 合理的压缩率 |
压缩率比gzip低 不原生、需要native安装 |
适合作为map->reduce或是job数据流的中间数据传输格式 |
4. 数据操作分类
| 操作分类 | 具体操作 | sql备注 |
|---|---|---|
| DDL | •建表 •删除表 •修改表结构 •创建/删除视图 •创建数据库 •显示命令 |
Create/Drop/Alter Database Create/Drop/Truncate Table Alter Table/Partition/Column Create/Drop/Alter View Create/Drop Index Create/Drop Function Show functions; Describe function; |
| DML | •数据插入(insert,load) | load data…into table insert overwrite table |
| DQL | •数据查询(select) |
建表模板
CREATE [external] TABLE [IF NOT EXISTS] table_name[(col_name data_type [comment col_comment], ...)][comment table_comment][partitioned by (col_name data_type [comment col_comment], ...)][clustered by (col_name, col_name, ...)[sorted by (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][row format row_format][stored as file_format][location hdfs_path]
- 关键词解释
- external: 创建内部表还是外部表,此为内外表的唯一区分关键字。
- comment col_comment: 给字段添加注释
- comment table_comment: 给表本身添加注释
- partitioned by: 按哪些字段分区,可以是一个,也可以是多个
- clustered by col_name… into num_buckets BUCKETS:按哪几个字段做hash后分桶存储
- row format:用于设定行、列、集合的分隔符等设置
- stored as : 用于指定存储的文件类型,如text,rcfile等
- location : 设定该表存储的hdfs目录,如果不手动设定,则采用hive默认的存储路径
实例
创建学生表student,包括id,name,classid,classname及分区和注释信息。
CREATE TABLE student(id string comment '学号',username string comment '姓名',classid int comment '班级id',classname string comment '班级名称')comment '学生信息主表'partitioned by (come_date string comment '按入学年份分区')ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\001'LINES TERMINATED BY '\n'STORED AS textfile;
加载数据脚本
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
设置非严格模式
set hive.exec.dynamic.partition.mode=nonstric;
Hive系统函数

Hive自定义函数
UDF
- IO要求
- in:out=1:1,只能输入一条记录当中的数据,同时返回一条处理结果
- 属于最常见的自定义函数,像cos,sin,substring,instr等均是如此要求
- 实现步骤(Java创建自定义UDF类)
- 自定义一个java类
- 继承UDF类
- 约定俗成的重写evaluate方法
- 打包类所在项目成一个all-in-one的jar包并上传到hive所在机器
- 在hive中执行add jar操作,将jar加载到classpath中。
- 在hive中创建模板函数,使得后边可以使用该函数名称调用实际的udf函数
- hive sql中像调用系统函数一样使用udf函数
代码实现
- 功能要求:实现当输入字符串超过2个字符的时候,多余的字符以”…”来表示
- 如“12”则返回“12”,如“123”返回“12…”
- 自定义类、继承UDF、约定俗成的“重写”evaluate方法已在代码中体现
import org.apache.hadoop.hive.ql.exec.UDF;/** 功能:实现当输入字符串超过2个字符的时候,多余的字符以"..."来表示。* 输入/输出:* 如“12”则返回“12”,如“123”返回“12..."*/public class ValueMaskUDF extends UDF{public String evaluate(String input,int maxSaveStringLength,String replaceSign) {if(input.length()<=maxSaveStringLength){return input;}return input.substring(0,maxSaveStringLength)+replaceSign;}public static void main(String[] args) {System.out.println(new ValueMaskUDF().evaluate("河北省",2,"..."));
布署步骤
maven管理
<project xmlns="http://maven.apache.org/POM/4.0.0"; xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance";xsi:schemaLocation="http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd";><modelVersion>4.0.0</modelVersion><groupId>com.tianliangedu.course</groupId><artifactId>TlHadoopCore</artifactId><version>0.0.1-SNAPSHOT</version><!-- 设置编码为 UTF-8 --><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.encoding>UTF-8</maven.compiler.encoding></properties><!-- 首先配置仓库的服务器位置,首选阿里云,也可以配置镜像 --><repositories><repository><id>nexus-aliyun</id><name>Nexus aliyun</name><url>http://maven.aliyun.com/nexus/content/groups/public</url></repository></repositories><dependencies><!-- 引入hadoop-cli-2.7.4依赖 --><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.7.4</version><scope>provided</scope></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-cli</artifactId><version>1.2.1</version><scope>provided</scope></dependency></dependencies><build><finalName>TlHadoopCore</finalName><plugins><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>assembly</goal></goals></execution></executions></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.7</source><target>1.7</target><encoding>UTF-8</encoding></configuration></plugin></plugins></build></project>
上传jar包至hive操作环境中
- 加载jar包、声明函数、使用函数
UDAF
- 自定义udaf函数self_count,实现系统udaf count的功能
- in:out=n:1,即输入N条数据,返回一条处理结果,即列转行
- 最常见的系统聚合函数,如count,sum,avg,max等
- 实现步骤
- 自定义一个java类
- 继承UDAF类
- 内部定义一个静态类,实现UDAFEvaluator接口
- 实现方法init,iterate,terminatePartial,merge,terminate共5个方法

- 在hive中执行add jar操作,将jar加载到classpath中
- 在hive中创建模板函数,使得后边可以使用该函数名称调用实际的udf函数
- hive sql中像调用系统函数一样使用udaf函数
代码实现
- 实现与hive原生的count相似的计数功能
```java
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.log4j.Logger;
/**
- 自行实现sql的count操作
*/
//主类继承UDAF
public class DIYCountUDAF extends UDAF {
//日志对象初始化,使访类有输出日志的能力 public static Logger logger=Logger.getLogger(DIYCountUDAF.class);
- 自行实现sql的count操作
*/
//主类继承UDAF
public class DIYCountUDAF extends UDAF {
//静态类实现UDAFEvaluator public static class Evaluator implements UDAFEvaluator {
//设置成员变量,存储每个统计范围内的总记录数 private int totalRecords;
//初始化函数,map和reduce均会执行该函数,起到初始化所需要的变量的作用 public Evaluator() {init();
}
//初始化,初始值为0,并日志记录下相应输出 public void init() {totalRecords = 0;logger.info("init totalRecords="+totalRecords);
}
//map阶段,返回值为boolean类型,当为true则程序继续执行,当为false则程序退出
public boolean iterate(String input) {//当input输入不为空的时候,即为有值存在,即为存在1行,故做+1操作if (input != null) {totalRecords += 1;}//输出当前组处理到第多少条数据了logger.info("iterate totalRecords="+totalRecords);return true;
}
/*** 类似于combiner,在map范围内做部分聚合,将结果传给merge函数中的形参mapOutput* 如果需要聚合,则对iterator返回的结果处理,否则直接返回iterator的结果即可*/
public int terminatePartial() {
logger.info("terminatePartial totalRecords="+totalRecords);return totalRecords;
}
// reduce 阶段,用于逐个迭代处理map当中每个不同key对应的 terminatePartial的结果 public boolean merge(int mapOutput) {
totalRecords +=mapOutput;logger.info("merge totalRecords="+totalRecords);return true;
}
//处理merge计算完成后的结果,此时的count在merge完成时候,结果已经得出,无需再进一次对整体结果做处理,故直接返回即可 public int terminate() {logger.info("terminate totalRecords="+totalRecords);return totalRecords;
}
}
}
```- 实现与hive原生的count相似的计数功能
```java
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.log4j.Logger;
/**
布署步骤
- 加载jar包、声明函数、使用函数
- 测试运行
- 案例
- 自定义udaf函数,实现多条学生成绩的合并
- 数据输入
- 数据输出
- 代码 ```sql import java.util.HashMap; import java.util.Map; import java.util.Set; import org.apache.hadoop.hive.ql.exec.UDAF; import org.apache.hadoop.hive.ql.exec.UDAFEvaluator; import org.apache.log4j.Logger; /**
实现多条数据合并成一条数据 */ // 主类继承UDAF public class StudentScoreAggUDAF extends UDAF { // 日志对象初始化 public static Logger logger = Logger.getLogger(StudentScoreAggUDAF.class); // 静态类实现UDAFEvaluator public static class Evaluator implements UDAFEvaluator {
// 设置成员变量,存储每个统计范围内的总记录数private Map<String, String> courseScoreMap;//初始化函数,map和reduce均会执行该函数,起到初始化所需要的变量的作用public Evaluator() {init();}// 初始化函数间传递的中间变量public void init() {courseScoreMap = new HashMap<String, String>();}//map阶段,返回值为boolean类型,当为true则程序继续执行,当为false则程序退出public boolean iterate(String course, String score) {if (course == null || score == null) {return true;}courseScoreMap.put(course, score);return true;}/*** 类似于combiner,在map范围内做部分聚合,将结果传给merge函数中的形参mapOutput* 如果需要聚合,则对iterator返回的结果处理,否则直接返回iterator的结果即可*/public Map<String, String> terminatePartial() {return courseScoreMap;}// reduce 阶段,用于逐个迭代处理map当中每个不同key对应的 terminatePartial的结果public boolean merge(Map<String, String> mapOutput) {this.courseScoreMap.putAll(mapOutput);return true;}// 处理merge计算完成后的结果,即对merge完成后的结果做最后的业务处理public String terminate() {return courseScoreMap.toString();}
} }
- 布署过程与之前相同- 测试脚本```sqlselectid,username,score_agg(course,score)fromstudent_scoregroup by id,username;
UDTF
- 解决一行输入多行输出,即1:n,即行转列应用
- 往往被lateral view explode+udf等替代实现,比直接用udtf会更简单、直接、更灵活一些
lateral view explode+udf替代udtf应用
案例需求
- 将一个array类型按列存储的学生成绩表,转变成按行来显示,学生名字超过2个字符的,后边用”…”来代替。
- 数据准备
通过lateral view explode实现行转列
select id,name,scorefrom test_arraylateral viewexplode(score_array) score_table as score;
加入udf处理业务需求
select id,mask(name,2,'...'),scorefrom test_arraylateral viewexplode(score_array) score_table as score;
Hive参数介绍

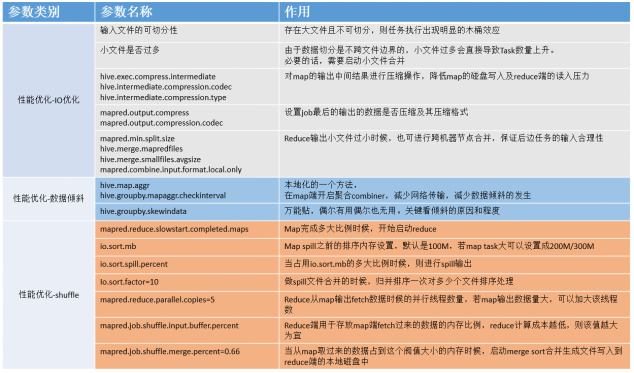
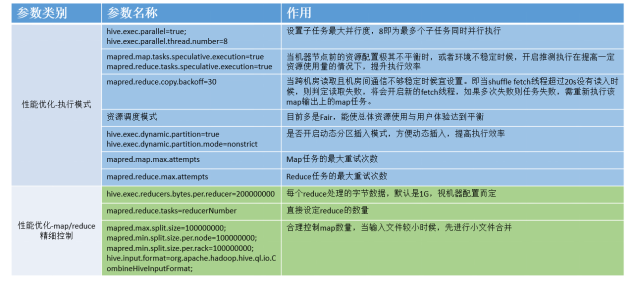
三个问题
- 关于MapJoin的问题剖析
- 概念
- 将本来应该是reduce进行关联查询的过程,改成由纯map进行查找
- 特点
- 减少了reduce的处理,全部放到了map端
- 减少了数据移动,提高了io效率
- 应用场景
- 大表join小表
- 大数据块join小数据块
- 代码实现
- hive默认开启了该功能
- 概念
- 关于数据倾斜的问题剖析
- 概念
- 在大数据处理环境下,数据处理过程出现明显的倾斜现象,导致任务整体迟迟不能完全结束
- 特点
- 在作业或是任务在分布式执行时,经常出现大部分Task任务很快结束,而很小一部分Task一直卡在99%的情况
- 典型的木桶效应,任务的执行完成时间,取决于最后一个Task的完成时间
- 应用场景
- 假倾斜场景
- 实际数据并没有倾斜,是由于人为代码原因导致的倾斜
- 比如
- 数据格式设置不对,导致没有发挥出分布式处理的优势
- 例如:设置成 gzip,snappy格式—不可切分的整体
- sql编写不合理-计算用户uv数
- 如select count(distinct uid) from user;
- 改成select count(1) from (select 1 from user group by uid) temp;
- 代码优化就可以了
- 数据格式设置不对,导致没有发挥出分布式处理的优势
- 真倾斜场景
- 数据或是任务本身真的存在客观的倾斜性
- 比如:VIP会员数据的倒卖倒买问题,导致极少数VIP帐号对应的数据量极多,而正常帐号较少
- 解决方法:只能分而治之,将倾斜的数据分类,将正常数据分类,然后进行分别计算
- 比如:硬件机器本身配置不均衡导致的计算能力倾斜问题
- 解决方法
- 第1种是硬性解决即让硬件更加均衡
- 第2种是通过NodeLabel方式
- 解决方法
- 比如:VIP会员数据的倒卖倒买问题,导致极少数VIP帐号对应的数据量极多,而正常帐号较少
- 数据或是任务本身真的存在客观的倾斜性
- 假倾斜场景
- 关于二次排序的问题剖析
- 概念
- 在map到reduce的处理过程当中,按照2个字段进行升序排列,而不是像默认的一次排序那样,只按照key一个字段排序
- 特点
- 2个字段排序,第1个字段若有比较结果则按第1个字段排序,若相等,则按第2个字段升序排列
- 应用场景
- 当单个字段不能够满足排序要求时,均可使用二次排序
- 代码实现
- Hadoopcore之mapreduce实现
- 重写Map和Reduce之前的输入输出的Key和Value
- HiveSQL实现
- Select * from table order by c1,c2 asc
- Hadoopcore之mapreduce实现
- 概念
- 概念
Hive阐述使用方式
四种使用方式
- 通过配置文件设置
- 此种主要是设置系统配置文件,多是全局性质的。在安装完hive后基本不需要再改动。主要是修改hive-site.xml或是hive-default.xml文件
- 通过在进入hive cli时指定配置参数
- 模板:hive —hiveconf param=value来设定session级参数
- 如:hive —hiveconf tez.queue.name=oncourse
- 在进入hive cli后,通过set来设定也是session级参数,此种最为常见
- 如之前提到的set tez.queue.name=oncourse;
通过shell脚本调用hive -e做参数设置和脚本执行,生产环境采用最多详细步骤
- 创建一个shell文件,名为hive_shell.sh:touch hive_shell.sh
编辑文件,加入以下脚本:
#!/bin/shdb="job017"table_name="practice_set "hive -e "use $db;set tez.queue.name=oncourse;select count(1) from $table_name;"
执行脚本
sh hive_shell.sh
Hive参数实际应用
升级到Tez/Spark引擎后一般均采用集群平台参数值即可,应用开发层设置参数的场景很少,只有极个别情况情下的jvm的内存相关参数设置需要特别设置,待后续高资源需求量时再另行使用
Hive企业应用
数据仓库架构设计
数据仓库的主要工作就是ETL,即是英文 Extract-Transform-Load 的缩写,用来描述数据从来源端经过装载(load)、抽取(extract)、转换(transform)至目的端的过程。
数据仓库架构设计,即为公司针对自身业务场景实现的水平分层、垂直分主题的数据仓库构建过程的顶层设计
1.数据架构
- 架构原则:先水平分层,再垂直分主题域
- 数据架构分三层
- 源数据落地区(SDF:Source Data File)
- 数据仓库层(DW:Data WareHouse)
- 数据集市层(DM:Data Market)
- 数据仓库层进一步细分为三层
- 源数据层(DWB)
- 细节数据层(DWD)
- 汇总数据层(DWS)
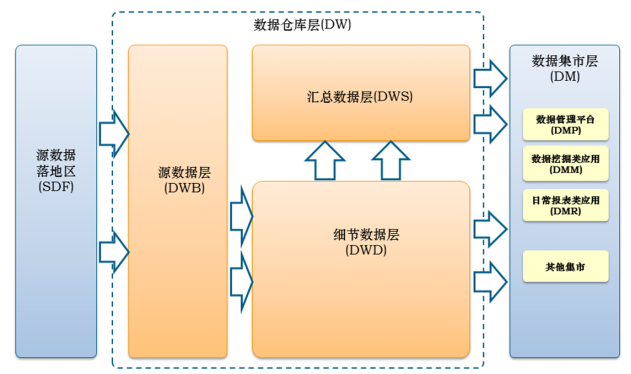
2.数据仓库分层介绍(水平)

3.按主题划分(垂直)

数据仓库建模
概念定义
- 数据模型是抽象描述现实世界的一种工具和方法,是通过抽象的实体及实体之间联系的形式,来表示现实世界中事务的相互关系的一种映射。
- 数据模型表现的抽象是实体和实体之间的关系,通过对实体和实体之间关系的定义和描述,来表达实际的业务中具体的业务关系。
- 数据仓库模型是数据模型中针对特定的数据仓库应用系统的一种特定的数据模型。
- 数据建模即数据模型的构建和应用过程。
- 数据仓库建模即数据仓库模型的构建和应用过程。
数据仓库建模的发展历史与意义
- 数据仓库建模的阶段发展
- 简单报表阶段
- 该阶段系统的主要目标是解决一些日常的工作中业务人员需要的报表,以及生成一些简单的能够帮助领导进行决策所需要的汇总数据;这个阶段的大部分表现形式为数据库和前端报表工具
- 特点:简单、单一
- 数据集市阶段
- 该阶段系统主要是根据某个业务部门的需要,进行一定的数据的采集,整理,按照业务人员的需要,进行多维报表的展现,能够提供对特定业务指导的数据,并且能够提供特定的领导决策数据
- 特点:多维度、业务场景化、按需定制性
- 数据仓库阶段
- 该阶段系统主要是按照一定的数据模型,对整个企业的数据进行采集,整理,并且能够按照各个业务部门的需要,提供跨部门的,完全一致的业务报表数据,能够通过数据仓库生成对对业务具有指导性的数据,同时,为领导决策提供全面的数据支持
- 特点:全面、灵活、数据模型支撑、体系化
- 简单报表阶段
- 数据建模的意义
- 进行全面的业务梳理,改进业务流程
- 建立全方位的数据视角,消灭信息孤岛和数据差异
- 解决业务的变动和数据仓库的灵活性
- 帮助数据仓库系统本身的建设
3.如何构建数据模型
- 数据模型的层次的一般划分

- 各层次说明
- 业务建模,生成业务模型,主要解决业务层面的分解和程序化。
- 领域建模,生成领域模型,主要是对业务模型进行抽象处理,生成领域概念模型。
- 逻辑建模,生成逻辑模型,主要是将领域模型的概念实体以及实体之间的关系进行数据库层次的逻辑化。
- 物理建模,生成物理模型,主要解决,逻辑模型针对不同关系型数据库的物理化以及性能等一些具体的技术问题
- 构建方法
- 数据模建构建与数据仓库架构设计有紧密关系,要优先吸收数据仓库架构设计即上一节内容。
- 数据仓库的建模方法有很多,每一种建模方法则代表哲学上的一个观点,代表了一种归纳,概括世界的一种方法。
- 目前的构建方法主要有三种:
- 范式建模法
- 维度建模法
- 实体建模法
- 具体构建方法详解
- 范式建模法
- 范式建模法其实是我们在构建数据模型常用的方法之一。
- 主要解决关系型数据库得数据存储,我们在关系型数据库中的建模方法,大部分采用的是三范式建模法。
- 数据库六大范式说明
- 第1范式-1NF:无重复的列、列不可再拆分。
- 第2范式-2NF:属性完全依赖于主键
- 第3范式-3NF:属性不依赖于其它非主属性,即属于依赖于主键不能出现传递依赖。
- 巴斯-科德范式(BCNF),第四范式(4NF),第五范式(5NF,又称完美范式)
- 特别说明
- 范式建模优点
- 从关系型数据库的角度出发,结合了业务系统的数据模型,能够比较方便的实现数据仓库的建模。
- 范式建模缺点
- 其建模方法限定在关系型数据库之上,在有些时候(需要冗余的时候)反而限制了整个数据仓库模型的灵活性,性能等,特别是考虑到数据仓库的底层数据向数据集市的数据进行汇总时,需要灵活调整才能达到要求。
- 使用建议:当不需要冗余设计提高易用性和计算效率时,可以采用这种模式。(常见的即为web项目开发中)
- 范式建模优点
- 维度建模法
- 即按照事实表,维度表来构建数据仓库,即最被人广泛知晓的名字就是星型模式(Star-schema)和雪花模式(Snowflake-schema)。
- 重要概念说明
- 事实表:发生在某个时间点上的一个事件,即具体的实体内容。比如以电商订单为例:下单是一个事实、付款是一个事实、退款是一个事实,所有事实的累计形成的表,均为事实表
- 维度表
- 维度表是从事实表中抽离出来的分析粒度。
- 维度表可以看作是用户来分析数据的窗口(视角),维度表中包含事实数据表中事实记录的特性,有些特性提供描述性信息,有些特性指定如何汇总事实数据表数据,以便为分析者提供有用的信息.
- 星型建模法
- 定义:维度表全部直接关联到事实表中,其形状类似星星,故称之

- 举例说明(销售类数据仓库构建)
- 如在地域维度表中,存在国家A省B的城市C,及国家A省B的城市D两条记录,那么国家A和省B的信息分别存储了两次,即存在冗余。
- 定义:维度表全部直接关联到事实表中,其形状类似星星,故称之
- 雪花建模法
- 定义
- 维度表并非全部关联到事实表中,存在一个或多个表没有直接关联到事实表中时,其形状类似雪花,故称之。
- 举例如上:
- 将地域维表又分解为国家,省份,城市等维表。
- 优点是通过最大限度地减少数据存储量以及联合较小的维表来改善查询性能。雪花型结构去除了数据冗余。
- 如下图所示:

- 定义
- 关于星形和雪花模型进行维度建模的对比说明
- 定义
- 星形模型:维度表全部直接关联到事实表中,其形状类似星星,故称之。
- 雪花模型:维度表并非全部关联到事实表中,存在一个或多个表没有直接关联到事实表中时,其形状类似雪花,故称之。
- 相同点
- 雪花模型属于星形模型的扩展,属于星形模型。
- 都是围绕事实表、维度表展开模型构建,只是层次设计不尽相同。
- 差异点
- 星型架构的设计由于没有像现实世界当中的抽象情况进行层级依赖,所以是一种非正规化的结构,多维数据集的每一个维度都直接与事实表相连接,不存在渐变维度,所以数据有一定的冗余设计。
- 雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的“层次”区域,这些被分解的表都连接到主维度表而不是事实表。
- 对比总结说明
- 数据规范性:雪花胜于星型。
- 性能:雪花的表关联较多,并行性和计算性能上会低于性能上往往低于星型。
- ETL开发:雪花关系多则关联多,代码量较复杂一些。而星型数据较集中,关联少,代码量会少一些。
- 实际使用,两者应用的均比较多,但星型略胜一筹。
- 定义
- 关于维度建模法的总结说明
- 广泛被使用的原因:在于针对各个维作了大量的预处理,如按照维进行预先的统计、分类、排序等,能够极大的提升数据仓库的处理能力。
- 维度建模优点
- 由于其可以有必要合理的冗余和其它范式建模的严格限制,相对于针对3NF 的建模方法,星型模式在性能上占据明显的优势。
- 维度建模非常直观,紧紧围绕着业务模型,可以直观的反映出业务模型中的业务问题。不需要经过特别的抽象处理,即可以完成维度建模。
- 维度建模缺点
- 由于在构建星型模式之前需要进行大量的数据预处理,会带来大量的数据处理工作。
- 业务发生变化后,往往需要更新维度的预处理。
- 存储和处理过程中,数据冗余量较大
- 依靠维度建模的话,其维度必然会且维护成本增大,不能保证数据来源的一致性和准确性,而且在数据仓库的底层,不是特别适用于维度建模的方法。
- 使用建议:在数据架构设计中的细节数据层、汇总数据层、数据集市层等需要提升计算性能的时候,均可以使用,也是建模过程中逻辑建模阶段最常用的方法之一。(常用于数据仓库模型设计)
- 实体建模法
- 实体建模法并不是数据仓库建模中常见的一个方法。
- 源于哲学的一个流派。从哲学的意义上说,客观世界应该是可以细分的,客观世界应该可以分成由一个个实体,以及实体与实体之间的关系组成。
- 范式建模法
数据分析
1.概念
- 数据分析是指用适当的统计分析(当下也包含机器学习等数据挖掘)的方法
- 对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
- 这一过程也是质量管理体系的支持过程。在实用中,数据分析可帮助人们作出判断,以便采取适当行动。
-
2.专业术语
2.1 OLTP
全称:on-line transaction processing。中文意思: 联机事务处理
- 其是数据库的主要应用,主要是执行基本日常的事务处理,如数据库记录的增删查改。比如在支付定或银行的一笔交易记录,就是一个典型的事务。
- 主要特点
- 实时性要求高,操作完后立刻要能看到结果。
- 数据量不是很大,生产库上的数据量一般不会太大,而且会及时做相应的数据处理与转移。
- 交易一般是确定的,比如银行存取款的金额肯定是确定的,所以OLTP是对确定性的数据进行存取
- 高并发,并且要求满足ACID原则。比如两人同时操作一个银行卡账户,比如大型的购物网站秒杀活动时上万的QPS请求。
- 总结
- 主要是指关系数据库中的增删查改,也是我们最常用操作,此为数据库的基础。
2.2 数据库事务ACID四大特性
- 原子性(Atomicity)
- 整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性(Consistency)
- 一个事务可以封装状态改变(除非它是一个只读的)。事务必须始终保持系统处于一致的状态,不管在任何给定的时间并发事务有多少。
- 隔离性(Isolation)
- 隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。
- 如果有两个事务,运行在相同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。
- 亦称为串行化
- 持久性(Durability)
- 在事务完成以后,该事务对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
2.3 OLAP
- 全称:On-Line Analytical Processing,中文意思为: 联机分析处理
- 其是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。典型的应用就是复杂的动态的报表系统。
- 主要特点
- 实时性要求不是很高,比如最常见的应用就是天级更新数据,然后出对应的数据报表。
- 数据量大,因为OLAP支持的是动态查询,所以用户也需要通过将很多数据的统计后才能得到想要知道的信息,例如时间序列分析等等,所以处理的数据量很大;
- OLAP系统的重点是通过数据提供决策支持,所以查询一般都是动态,自定义的。所以在OLAP中,维度的概念特别重要。一般会将用户所有关心的维度数据,存入对应数据平台。
- 总结
- 其是数据仓库的核心部件。
- 所谓数据仓库是对于大量已经由OLTP形成的数据的一种分析型的数据库,用于处理商业智能(BI)、决策支持等重要的决策信息。
- 数据仓库是在数据库应用到一定程序之后而对历史数据的加工与分析,读取较多,更新较少
- OLTP发展到一定阶段后产生的OLAP。
3.hive对数据分析的支持
Hive数据分析函数:分析函数、窗口函数、增强Group(用的极少,不做讲解)三类,及用于辅助表达的over从句
3.1 产生背景
常规SQL语句中,明细数据和聚合后的数据不能同时出现在一张表中,而此类需求又常见。
如:员工既要查询当前收入多少又要显示本年度收入多少;
员工既要查询当前收入多少,又要显示历史总收入多少;
购物者既要查询当前剩余多少,又要显示历史充值多少等等。
该类函数即为解决两者可以同时出现的问题。
3.2 函数分类
- 分析函数(不支持与window子句联用,即ROWS BETWEEN)
- NTILE:序列分析函数,用于数据分片排序,对数据分片并返回当前分片值。(即对数据集分块,如第1块,第2块等),不均匀的时候,依次增加前边分片序列的数量。
- ROW_NUMBER:序列分析函数,用于排序,按照顺序,不关心是否有相等情况,从1开始逐条给数据一个加1后的序列号。如1,2,3,4….
- RANK:序列分析函数,用于排序,按照顺序,关心相等情况,如遇到相等情况,名次会留下空位。如1,2,2,4,4,6……
- DENSE_RANK:序列分析函数,用于排序,关心相等情况,如遇到相等情况,名次不会留下空位。如1,2,2,3,3,4……
- 窗口函数
- LAG:函数LAG(col,n,DEFAULT)用于统计窗口内往上第n行值。第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
- LEAD:与LAG作用相反,函数形式如LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值。第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
- FIRST_VALUE: 取分组内排序后,截止到当前行,第一个值
- LAST_VALUE:与FIRST_VALUE相反,取分组内排序后,截止到当前行,最后一个值
- over()从句:指定分析窗口函数的细化落围规则
- 与标准的聚合函数COUNT、SUM、MIN、MAX、AVG联用,如sum(…) over(…)
- 与区配的分析窗口联用,如ROW_NUMBER() over(…)
- 使用PARTITION BY语句,使用一个或者多个原始数据类型的列
- 使用PARTITION BY与ORDER BY语句,使用一个或者多个数据类型的分区或者排序列
- 使用窗口规范,窗口规范支持以下格式:
- ROWS BETWEEN:即为window子句或称窗口子句,属于物理截取,即物理窗口,从行数上控制截取数据的大小多少。
- RANGE BETWEEN: 即为window子句或称窗口子句,属于逻辑截取,即逻辑窗口,从列值上控制窗口的大小多少。
- PRECEDING:window子句之往前
- FOLLOWING:window子句之往后
- CURRENT ROW:window子句之当前行
- UNBOUNDED:window子句之起点,UNBOUNDED PRECEDING 表示从前面的起点,UNBOUNDED FOLLOWING:表示到后面的终点。
- 注意:order by子句后边如果没有跟着多大窗口,则默认为range between unbounded preceding and current row
3.4 数据分析的附加项
- 理解和表达能力良好,能够快速理解和响应需求。
- 思路清晰,快速迭代。
- PPT、Excel的熟练操作,主要是为数据分析报告做准备。
分类聚类算法有一定的了解和掌握,若能简单学会用R将会如虎添翼
在线数据备份
将生产系统中的数据库拷贝到hive中一份作灾备。
自行实现
- 在hive中创建要备份表的scheme,建立分区表,如按天来分区
- 将mysql生产库中的库表同步到hadoop客户端中,形成文件data.txt
- load local data.txt文件上传至hive表对应的hdfs目录中,加载到对应的天分区
- 周期性执行上边三步骤
- 使用sqoop实现在线数据备份
数据工程师岗位职责
- 数据仓库工程师
- 数据ETL清洗到位。
- 数据质量监控与运维
- 性能优化
- 数据分析工程师
- 数据ETL清洗
- 数据统计分析、数据挖掘算法应用
- 业务洞察、经营指导、辅助决策
- 数据开发工程师
- 是一个统称概念,只要是偏数据维度的工程师种类,均可称为数据开发工程师。
- 包括了数据仓库、数据分析、数据挖掘、数据相关的代码开发工作。
- 但一般会侧重一些开发工作,比如写java,scala代码场景更多。
- 数据挖掘工程师
- 统计分析
- 特征提取
- 模型训练
- 数据预测与评估
- ABTest与反馈迭代
- 模型上线与调优
阿里经典代码评测题
按照hive sql的语法完成下面任务:
输入表:
曝光数据表:
create table if not exists expo_detail_table(pvid string comment'唯一标识一次请求',user_id string comment'用户id',item_id string comment'商品id')lifecycle 29;
点击数据表:
create table if not exists click_detail_table(pvid string comment'唯一标识一次请求',user_id string comment'用户id',item_id string comment'商品id')lifecycle 29;
输出表有两个(排名按照从大到小,标号从1开始):
create table if not exists result1_table(user_id string,item_id string,expo_cnt bigint comment'曝光数量',click_cnt bigint comment'点击数量')lifecycle 29;create table if not exists result2_table(item_id string,uv_ctr double comment'uv曝光点击率',uv_ctr_rank bigint comment'uv曝光点击率排名',pv_ctr double comment'pv曝光点击率',pv_ctr_rank bigint comment'pv曝光点击率排名')lifecycle 29;

若有收获,就点个赞吧
0 人点赞
