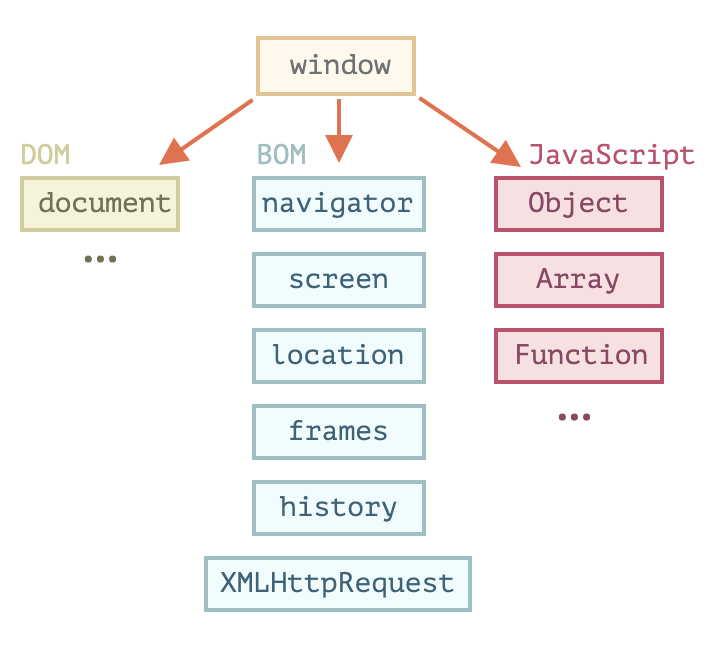
浏览器环境,规格
浏览器的构成部分:
- 文档对象模型DOM,也就是document对象,是页面的入口点
- 浏览器对象模型BOM,提供了诸如
navigator, location等对象 - JavaScript本身
DOM树
根据文档对象模型DOM,每个HTML标签都是一个对象,嵌套的标签是父级标签的子标签,所以我们有 children 这个属性可以访问。嵌套的文本也是一个对象。
document.body 表示通过JS访问body标签的对象
文本节点的特殊字符
- 换行符↵
- 空格␣
都是有效的字符,是DOM的一部分。是一个#text节点。但是有空格,换行有2个顶级忽略。
=>
hello
<a name="cyk19"></a>## 其他类型节点比如注释节点,也是一个节点类型```html<ol><li>An elk is a smart</li><!-- comment --><li>...and cunning animal!</li></ol>
一共有12种节点类型,常用的有4种
- document
- 元素节点,div, p..
- 文本节点
-
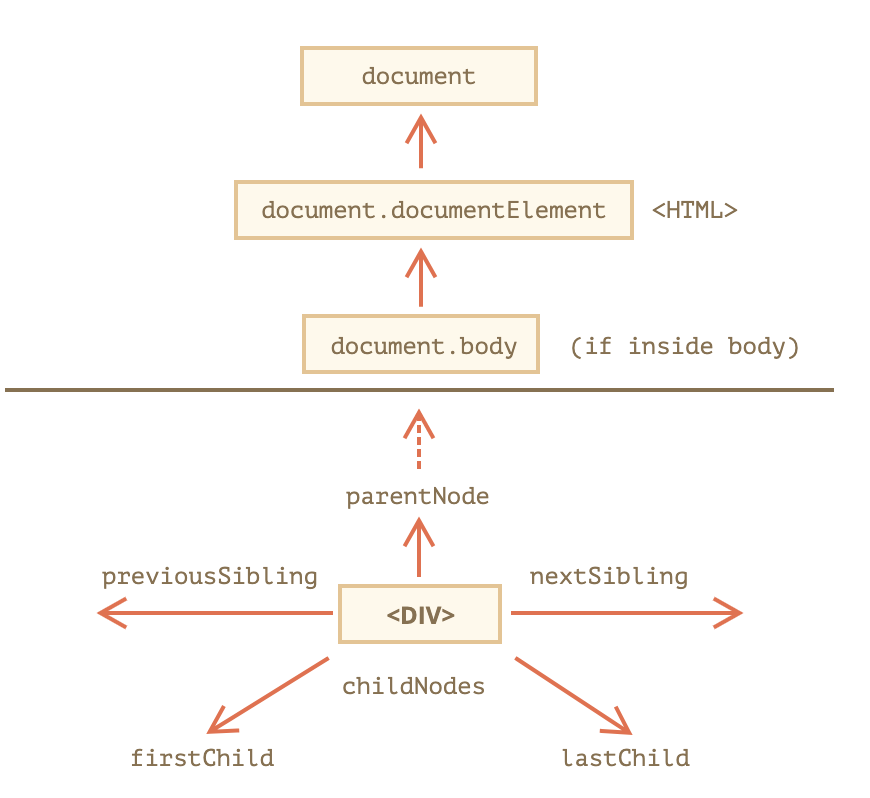
遍历DOM
最顶层documentElement和body
<html>=document.documentElement<body>=document.body-
子节点childNodes, firstChild, lastChild
子节点,指的是直系子元素
-
childNodes
可迭代
因为是一个集合,一个类数组的可迭代对象,所以我们可以迭代它
for (let node of document.body.childNodes) {console.log(node)}
可转换为真正的数组
转换后可以使用数组方法
Array.from(document.body.childNodes).filter
兄弟节点,父节点,快捷第一个最后一个
nextSibling下一个previousSibling上一个parentNode父节点-
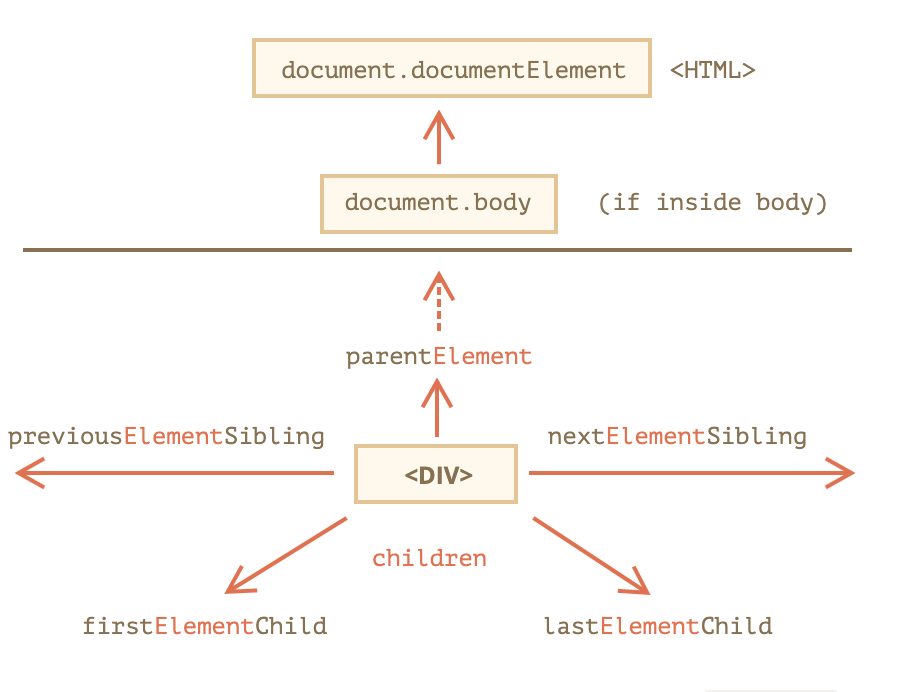
纯元素导航(真正想要的)
上面所说的所有dom导航api,获取的节点都包含了文本,注释等等。而通常我们希望获取真真的元素节点(标签节点)
从图上看到,在之前的api增加element字眼就可以了。 所有子元素
children- 父元素
parentElement- 一个特例
document.documentElement.parentElement = null,而document.documentElement.parentNode = document(整个文档),因为parentElement不认为整个文档是一个元素节点!
- 一个特例
- 前一个兄弟元素
previousElementSibling - 后一个兄弟元素
nextElementSibling - 第一个和最后一个元素
firstElemenetChildlastElementChild
特定导航
方便起见,某些类型的DOM元素提供了特定的属性,方便我们访问相关元素,比如Table
table.rows获取所有tr元素的集合table.caption/tHead/tFoot获取元素<caption> <thead> <tfoot>table.tBodies获取<tbody>的集合,没错,可以有多个thead tbody tfoot里也有大量的rows,也就是行,我们也可以获取。tbody.rows<tr>标签也有对应的属性tr.cells获取单元格集合tr.sectionRowIndex当前tr在thead tbody 或 tfoot的索引位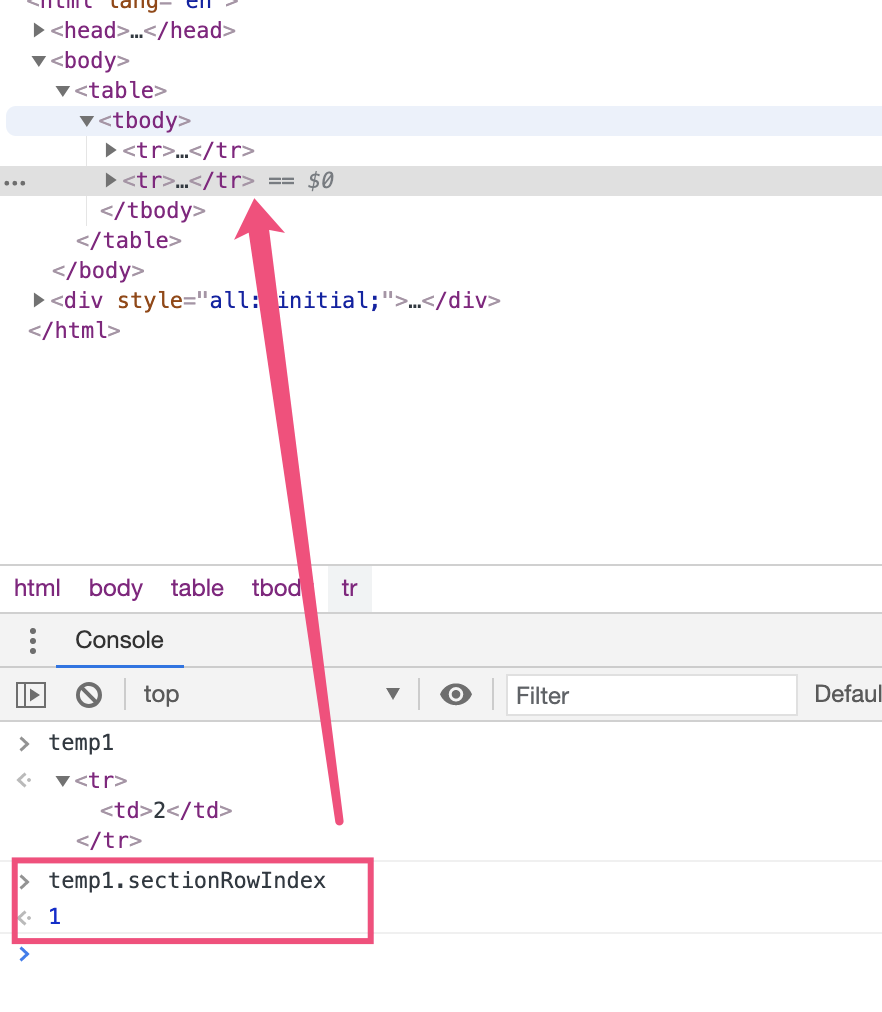
tr.rowIndex在整个表格中的tr的编号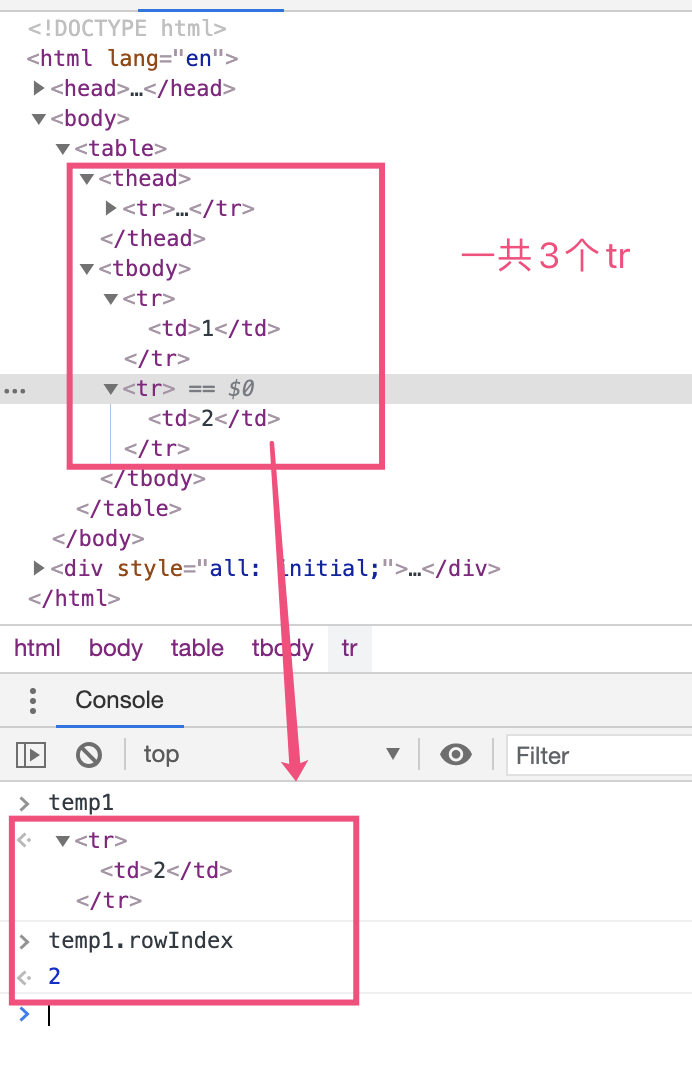
总结
dom的导航(访问dom节点)有2组
一组访问所有节点(文本,注释,标签):
- childNodes
- parentNode
- firstChild, lastChild
- previousSibling, nextSibling
- 一组访问元素节点(只有标签)
// index.js document.getElementById(‘a’) a // 直接id也可以访问到,但是不安全,如果有全局同名变量,变量优先。
<a name="pbRvF"></a>## querySelectorAll 和 querySelector`querySelectorAll(css pattern)` 十分强大,返回符合参数要求的所有元素的集合, `querySelector` 只查找第一个匹配到的。强大的原因在于接收的参数是一个css查询器,灵活```javascript<ul><li>The</li><li>test</li></ul><ul><li>has</li><li>passed</li></ul><script>let elements = document.querySelectorAll('ul > li:last-child');for (let elem of elements) {alert(elem.innerHTML); // "test", "passed"}</script>
matches
检查elem是否与给定css选择器匹配,返回boolean
elem.matches('a[href$="zip"]')
closest
elem.closest(css) 方法会查找与css选择器匹配的最近的祖先,elem自己也会被搜索。
<h1>Contents</h1><div class="contents"><ul class="book"><li class="chapter">Chapter 1</li><li class="chapter">Chapter 1</li></ul></div><script>let chapter = document.querySelector('.chapter'); // LIalert(chapter.closest('.book')); // ULalert(chapter.closest('.contents')); // DIValert(chapter.closest('h1')); // null(因为 h1 不是祖先)</script>
历史api
以下返回的都是集合
- getElementsByClassName
- getElementsByName
- getElementsByTagName
实时集合与静态集合
getElementsBy*获取的是实时集合,而querySelector(All)获取的是静态集合。 ```javascriptFirst div
<a name="GewIX"></a># 节点属性type, tag和content<a name="xGOE5"></a>## DOM节点类此图一解一直困惑的为什么一个dom节点有那么多属性,而且像 `div` ,在TS里,可以是 `HTMLElement` , 也可以是 `HTMLDivElement` 。这些都跟DOM节点的内建类有关!<br />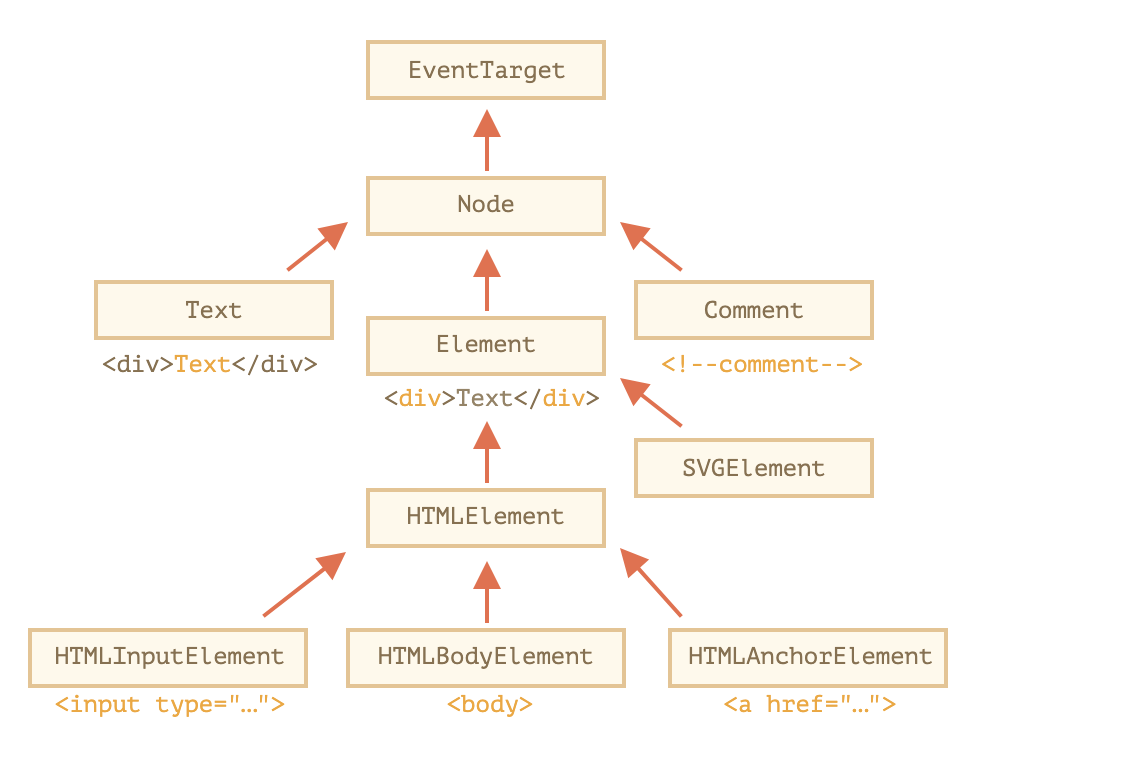<br />所有的DOM都继承自最上面的 `EventTarget` , `Element` 又被很多具体的标签类继承。- EventTarget,让所有dom节点都支持了事件对象event- Node,节点抽象类,如 `parentNode, nextSibling` 这类api,由此提供- Element,元素抽象类,提供了如 `nextElementSibling, children` 等dom导航api,也提供了 `getElementsBy*, querySelector` 这样的搜索方法。- HTMLElement,所有HTML元素的基本类,具体的HTML元素都继承自它,如 `HTMLInputElement`一层层的继承,让一个具体的标签DOM,获取很多属性和方法,按继承顺序叠加```javascript// 例如一个input标签HTMLInputElement -> HTMLElement -> Element -> Node -> EventTarget -> Object(万物皆对象)
我们可以通过 instanceof 检测
a instanceof xx.prototype a的原型链上存不存在 xx的原型对象
console.log(document.body.toString()) // [object HTMLBodyElement]document.body instanceof HTMLElement // truedocument.body instanceof Element // truedocument.body instanceof Node // truedocument.body instanceof EventTarget // true
nodeType判断节点类型
曾经用该方法,判断某个节点返回值类型是什么,这个方法已经过时了。
elem.nodeType // 1 元素 3 文本 9 document对象本身
标签nodeName和tagName
tagName 适用 Elemenet 类定义的nodeName 适用 Node 类定义的,因为Element继承自Node,所以对于元素来说,nodeName === tagName。 对于text, comment的话,有自己的nodeName。
<body><!-- comment --><script>// for commentalert( document.body.firstChild.tagName ); // undefined(不是一个元素)alert( document.body.firstChild.nodeName ); // #comment// for document,注意:document不是元素!!!alert( document.tagName ); // undefined(不是一个元素)alert( document.nodeName ); // #document</script></body>
tagName 和 nodeName 对于元素,返回值都是大写的标签
document.body.tagName // BODYdocument.body.nodeName // BODY
innerHTML, outerHTML
前者是元素里的所有
后者包括元素直接外层(closet parent),元素自身,元素里
nodeValue/data
innerHTML只对元素有效,这个对节点有效
<body>Hello<!-- Comment --><script>let text = document.body.firstChild;alert(text.data); // Hellolet comment = text.nextSibling;alert(comment.data); // Comment</script></body>
textContent
获取文本内容,节点内所有文本。
可以以安全方式写入文本,避免innerHTML
<div id="news"><h1>Headline!</h1><p>Martians attack people!</p></div><script>// Headline! Martians attack people!alert(news.textContent);</script>
hidden
跟 style = "dispaly: none" 做相同的事,更简洁。
特性和属性
dom属性
属性和JS对象是相似的,我们可以给dom对象随意增加自定义属性,方法。
document.body.sayTagName = function() {alert(this.tagName);};document.body.sayTagName();// 直接动Element.prototypeElement.prototype.sayHi = function() {alert(`Hello, I'm ${this.tagName}`);};document.documentElement.sayHi(); // Hello, I'm HTMLdocument.body.sayHi(); // Hello, I'm BODY
HTML特性
标准特性可转换为DOM属性
标签拥有的特性,浏览器解析HTML,会根据标签创建DOM对象,辨别标准的特性,是,则创建对应的dom属性。
<body id="test" something="non-standard"><script>// id是标准的特性,转换为dom的属性alert(document.body.id); // test// 非标准的特性没有获得对应的属性alert(document.body.something); // undefined</script></body>
不同标签,不同特性
每个标签有自己的特性,一个元素的特性对另一个元素来说可能就是不存在的。
<body id="body" type="..."><input id="input" type="text"><script>alert(input.type); // textalert(body.type); // undefined:DOM 属性没有被创建,因为它不是一个标准的特性</script></body>
如何访问非标特性
可以通过获取属性的api
- hasAttribute
- getAttribute
- setAttribute
- removeAttribute
特性不区分大小写
会自动全部转为小写。<div id="1" ID="1" />
属性和特性的同步
当标准特性被修改,对应属性也会自动更新,反之亦然。除了部分特性,如input的value。 ```javascript let input = document.querySelector(‘input’);
// 特性 => 属性 input.setAttribute(‘id’, ‘id’); alert(input.id); // id(被更新了)
// 属性 => 特性 input.id = ‘newId’; alert(input.getAttribute(‘id’)); // newId(被更新了
看下input的value```javascript<input><script>let input = document.querySelector('input');// 特性 => 属性input.setAttribute('value', 'text');alert(input.value); // text// 这个操作无效,属性 => 特性input.value = 'newValue';alert(input.getAttribute('value')); // text(没有被更新!)</script>
因为用户的行为会导致value的更改(引起input的属性value的变化),而特性一直是原始值,不会随用户输入改变而改变。
DOM属性类型是多种多样的
如复选框
<input id="input" type="checkbox" checked>// input.checked true// input.getAttribute('checked') 空字符串
非标准的特性,dataset
// 因为特性可以是非标准的,我们可以用来做一些奇奇怪怪的事<div show-info="name"></div>// 通过querySelector获取// 这里参数是CSS查询器let d = document.querySelector('[show-info=name]')// 设置其值d.innerHTML = 'Jack'
// 利用特性来做css类的工作<style>/* 样式依赖于自定义特性 "order-state" */.order[order-state="new"] {color: green;}</style><div class="order" order-state="new">A new order.</div>
为了防止自定义特性和后续规范冲突,规定存入 data- 的特性中供自定义使用
<div id="d" data-about-whate="hello"></div>// 注意这里是使用驼峰来访问,如果你的data-自定义属性有多个连字符d.dataset.aboutWhat hello
总结:
document.createElement(tag)指定标签创建一个元素节点document.createTextNode(text)创建一个文本节点插入方法
插入节点
node.append(node or strings)指定node末尾node.prepend(node or string)指定node的开头node.before(node or string)指定node前面node.after(node or string)指定node之后node.replaceWith(node or string)将指定node替换为给定的节点
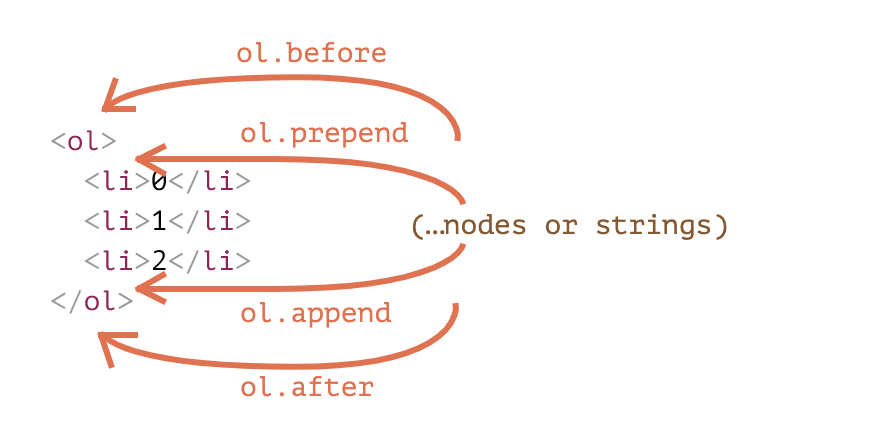
插入HTML,文本节点,元素节点
where是固定的几个参数: beforebegin afterbegin beforeend afterend
elem.insertAdjacentHTML(where, html)elem.insertAdjacentText(where, text)elem.insertAdjacentElement(where, text)节点移除
node.remove()插入方法都默认会将节点从原位置剪切到新位置,原位置不存在,相当于删除。
克隆节点cloneNode
elem.cloneNode(deep?:boolean)是否深克隆一个节点,包含所有特性和子元素。false则不克隆子元素DocumentFragement
一个特殊的DOM节点,节点列表的包装器。通常成片增加DOM,减少渲染性能消耗(重排)
古老的DOM操作方法
parentElement.appendChild(node) 将node插入到父元素的最后一个子元素的位置上
- parentElement.insertBefore(node, nextSibling) 在parentElement的nextSibling前插入node
- parentElement.replaceChild(node, oldChild) 将parentElement的后代中的oldChild替换为node
- parentElement.removeChild(node) 将parenElement的子元素node删除
样式和类
className和classList
为什么是elem.className,而不是elem.class?因此class是保留字,不能用作对象的属性,所以才引入了className。classList
相对className的整体更改,更为方便,是一个特殊的对象,提供了add/remove/toggle的方法
Style
使用驼峰来写
button.style.backgroundColor = 'red'
重置样式属性
document.body.style.display = ''
而不是delete document.body.style.display
cssText
完全重写style, body.style.cssText = ''
单位
需要写明 10px 而不是 10 body.style.margin = '20px'
获取计算样式getComputedStyle
因为 ele.style 属性访问,只能访问到 style 特性的值,如下:
<style>#box {color: blue;}</style><div id="box" style="background: red"></div>box.style.background //redbox.style.color // '' 空的,获取不到非直接style特性的值
因此我们有了这个方法getComputedStyle(elem, [pseudo]) ,返回一个对象,包含所有样式的对象。
- elem 指定元素
- pseudo 伪元素
通常需要完整的样式名称,如padding,到底需要哪个方向的,比如左,需要指明paddingLeft。
计算值和解析值
计算值:指的是style,css等样式层叠下来后,最终应用的那个值。
解析值:将计算值标准化后的值,比如1rem,解析为16px
<style>#box{font-size: 16px;}#box{font-size: 1rem;}</style>// html fontSize假定为12px<div id="box">box</div>// 计算值:1rem// 解析值:12px
元素大小和滚动
盒模型
标准盒模型
现代浏览器默认模式,大小计算包含 content + padding + border
怪异盒模型|IE盒模型|替代盒模型
IE浏览器默认的模式,大小计算包含content + padding
盒模型转换
转为怪异盒模型,通过设置box-sizing: border-box
转为标准盒模型,通过设置box-sizing: content-box
总结
offsetParent
最近的具有定位样式,如relative, absolute, fixed的父元素。
offsetTop|Left
offsetWidth|Height
clientLeft|clientTop
元素的左上外角到左上内角的距离,实际上就是元素的border宽度。这个属性只跟元素自身有关
clientWidth|clientHeight
scrollWidth|Height
类似clientWidth|Height,但还包含了滚动出去的部分
scrollLeft|Top(读写属性)
元素滚动出去的那部分距离,是对滚动容器的属性访问,而不是容器内很长的内容元素。
<div id="wrap"><div id="content"></div></div><style>#wrap{width: 100px; height: 200px; owerflow: auto}#content{width: 100px; height: 1000px;}</style>// 获取滚动容器滚过了多少距离,wrap.scrollTop
window大小和滚动
clientWidth vs innerWidth
前者是文档(document.documentElement)的可用宽度
后者在有滚动条的情况下,会包含滚动条的宽度。
文档的宽度高度
测量文档的真实高度
Math.max(document.body.scrollHeight, document.documentElement.scrollHeight,document.body.offsetHeight, document.documentElement.offsetHeight,document.body.clientHeight, document.documentElement.clientHeight);
获取当前滚动
获取已经滚动过的距离。
document.documentElement.scrollLeft/Top
Safari 中需要使用 document.body
document.body.scrollTop // 0 试了下并不行document.documentElement.scrollTop // 420 这个OK
通用API
优先使用这个获取页面滚动距离
- window.pageXOffset/pageYOffset
滚动
scrollTo
直接滚动到指定位置scrollBy
相对于当前所在的位置滚动多少scrollIntoView
elem.scrollIntoView(top?: true)让元素滚动至视口处。参数为false,则滚动值视口底部。禁止滚动
冻结滚动:document.body.style.overflow = hidden
恢复滚动:document.body.style.overflow = ''
这些操作会让滚动条消失或恢复,导致内容空间会闪动,可以通过比对冻结滚动前后的cleintWidth来给适当的元素增加padding。

若有收获,就点个赞吧
0 人点赞
