今日任务:
1、事务本质
一组命令的集合,一个事务中的所有命令都会被序列化,在事务的执行过程中,会按照顺序执行
一次性、顺序性、排他性、执行一系列的命令
redis事务没有隔离级别的概念
所有的命令在事务中,并没有直接被执行,只有发起执行命令的时候才会在执行redis单条命令是保证原子性,但是事务不保证原子性(原子性:要么同时成功,要么同时失败)
2、持久化方案,原理,有什么问题
redis支持两种方式的持续化:RDB快照和AOF
RDB快照缺点:
无法保证数据完整性,会丢失最后一次快照后的所有数据。
bgsave执行每次执行都会阻塞Redis服务进程创建子线程,频繁执行影响系统吞吐率。
3、两种持久化机制对比
优点:
1.RDB是一个单一的紧凑文件,它保存了某个时间点的数据集,非常适合数据集的备份,比如你可以在每个小时保存一下过去24小时内的数据,同时每天保存过去30天的数据,这样即使出了问题你也可以根据需求恢复到不同版本数据集。
2.RDB是一个紧凑的单一文件,方便传送,适用于灾难恢复。
3.RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做IO操作,所有RDB持久化方式可以最大化redis的性能。
4.与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些。
缺点:
1.Redis意外宕机,可能会丢失几分钟的数据(取决于配置的save时间点)。RDB方式需要保存整个数据集,是一个毕竟繁重的工作,通常需要设置五分钟或者更久做一次完整的保存。
2.RDB需要经常fork子进程来保存数据集到硬盘上,当数据比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求,如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续更久。
4、高可用-主从复制的原理
首先主从复制需要分为两个角色:master(主)和slave(从),注意:redis里面只支持一个主,不像mysql、nginx主从复制可以多主从。
1.redis多复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作多时候自动将数据同步到从数据库,而从数据库一般是只读到,并接收主数据同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
2.通过redis到复制功能可以很好的实现数据库到读写分离,提高服务器到负载能力。主数据库主要进行写操作,而从数据库负责读操作。
5、主从存在问题
1.一旦主节点宕机,从节点晋升为主机点,同时需要修改应用方点主节点地址,还需要命令所有从节点复制新的主节点,整个过程需要人工干预。
2.主节点点写能力受到单位的限制
3.主节点的存储能力受到单位的限制
4.原生复制的弊端在早期的版本中也会比较突出,比如:redis复制中断后,从节点会发起psync。此时如果同步不成功,则会进行全量同步,主库执行全量备份的同时,可能也会造成毫秒或秒级的卡顿。
《哨兵可以解决以上问题》
6、哨兵模式原理
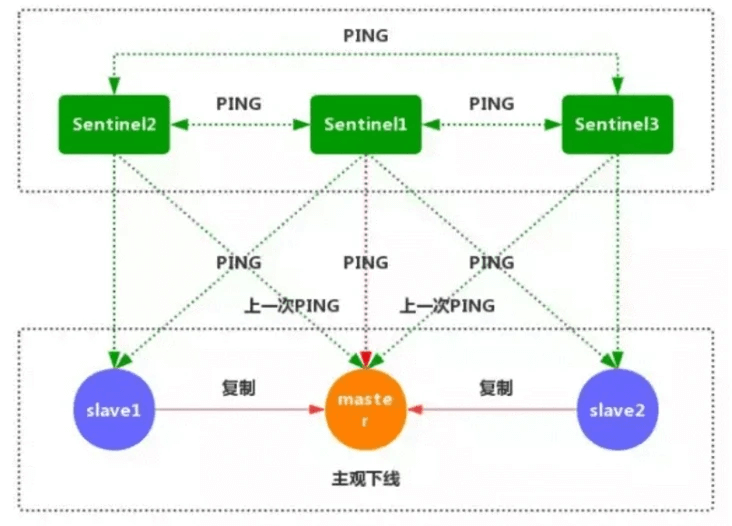
1.每个Sentinel节点都需要定期执行以下任务:每个Sentinel以每秒一次 的频率,向它所知的主服务器,从服务器以及其他的Sentinel实例发送一个ping命令。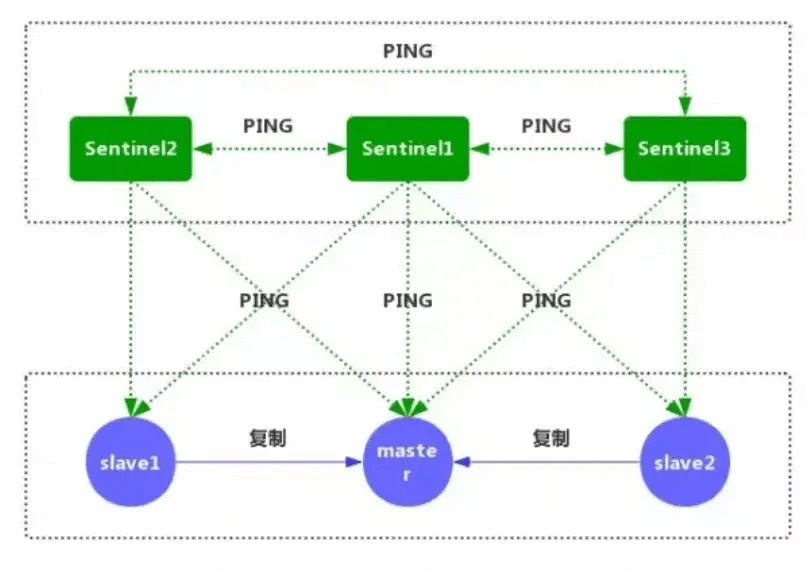
2.如果一个实例距离最后一次有效回复ping命令的时间超过down-after-milliseconds所指定的值,那么这个实例会被Sentinel标记为主观下线。
3.如果一个主服务器被标记为主观下线,那么监视这个服务器的所有Sentinel节点,要以每秒一次的频率确认主服务器的确进入了主观下线状态。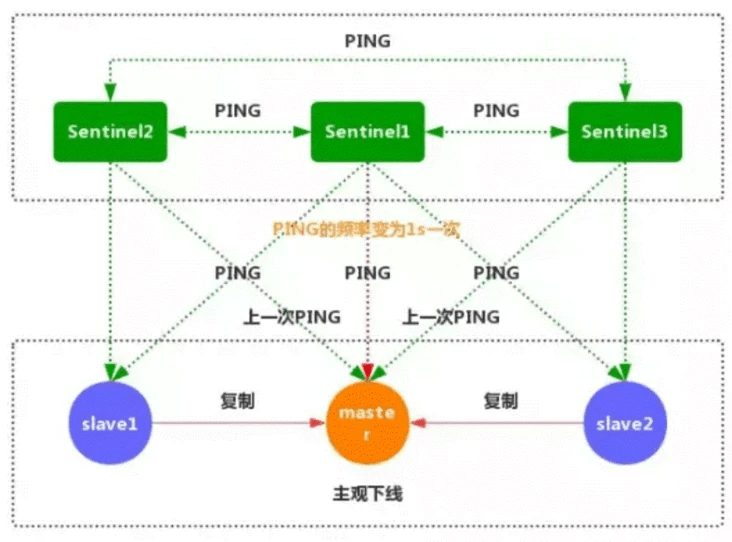
4.如果一个主服务器被标记为主观下线,并且有足够数量的Sentinel(至少要达到配置文件指定的数量)在指定的时间范围内同意这一判断,那么这个主服务器被标记为客观下线。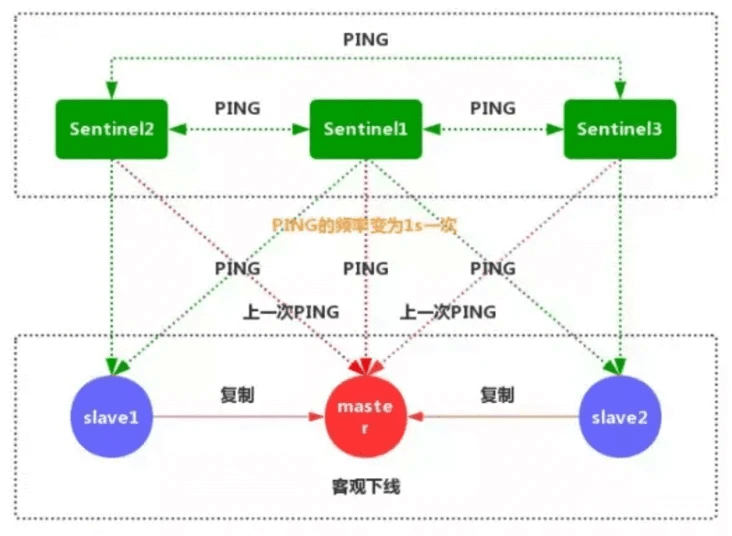
5.一般情况下,每个Sentinel会以每10秒一次的频率向已知的所有的主服务器和从服务器发送INFO命令,当一个主服务器被标记为客观下线时,Sentinel向线下主服务器的所有主服务器发送INFO命令的频率,会从10秒一次改为每秒一次。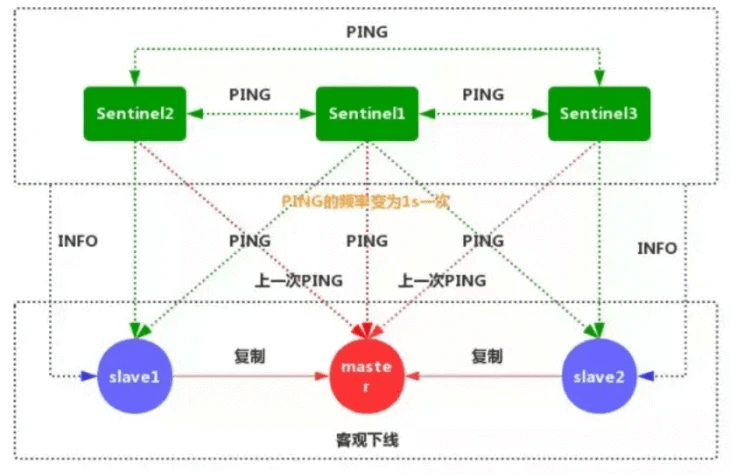
6.Sentinel和其他Sentinel协商客观下线的主节点的状态,如果处于SDOWN状态,则投票自动选出新的主节点,将剩余从节点指向新的主节点进行数据复制。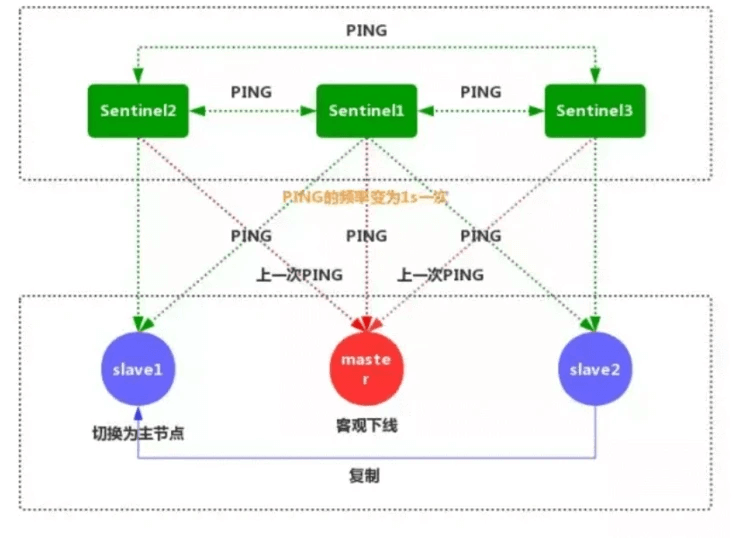
7.当没有足够的Sentinel同意主服务器下线时,主服务器的客观下线就会被移除。当主服务器重新向Sentinel的PING命令返回有效回复时,主服务器的主观下线就会被移除。
7、经典主从集群解决了什么问题,还存在什么问题
解决了主服务器宕机,集群无法进行写操作,实现了蛀虫集群可以实现自动切换,可用性更高。防治数据更大限度的丢失。减少了误判问题
存在的问题:当大量请求进行读写操作时,效率较低。而因为每个服务器存储顺序一样就会存在存储能力较低的问题
8、高可扩-分片集群的原理
数据切片和实例的对应分布关系
○ Redis Cluster 方案:无中心化
■ 采用哈希槽(Hash Slot)来处理数据和实例之间的映射关系
■ 一个切片集群共有 16384 个哈希槽,只给Master分配
■ 具体的映射过程
1 根据键值对的 key,按照CRC16 算法计算一个 16 bit 的值;
2 再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽
○ 哈希槽映射到具体的 Redis 实例上
■ 用 cluster create 命令创建集群,Redis 会自动把这些槽平均分布在集群实例上
■ 也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,再使用 cluster addslots 命令,指定每个实例上的哈希槽个数 注意:需要把 16384 个槽都分配完,否则 Redis 集群无法正常工作
● 客户端如何定位数据
○ Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散
○ 客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端
○ 客户端会把哈希槽信息缓存在本地。当请求键值对时,会先计算键所对应的哈希槽
○ 但集群中,实例和哈希槽的对应关系并不是一成不变的
■ 实例新增或删除
■ 负载均衡
○ 实例之间可以通过相互传递消息,获得最新的哈希槽分配信息,但客户端是无法主动感知这些变化
9、异常测试*
异常关闭主节点,查看集群节点变化和日志
○ 结论:对应的从节点升级为主节点
● 恢复主节点,查看集群节点变化
○ 结论:会添加到最新的主机点上,成为从节点
● 异常关闭从节点,查看集群状态
○ 结论:不影响集群使用,但是可能会存在单点故障问题
● 同时关闭节点的主和从,本案例中的7001(主) —— 7006(从),get取值,观察
○ 结论:导致整个Redis集群不可用
10、如何实现redis动态的扩缩容
我们安装 7007 、 7008 两个Redis节点,然后将 7007 作为主节点,添加到集群中, 7008 作为从节点添加到集群中。
11、redis5种数据类型的应用场景*
String
应用场景:
String是最常用的一种数据类型,普通的key/value存储都可以归为此类,value其实不仅是String,
也可以是数字:比如想知道什么时候封锁一个IP地址(访问超过几次)。INCRBY命令让这些变得很容易,通过原子递增保持计数。
List
应用场景:
由于list它是一个按照插入顺序排序的列表,所以应用场景相对还较多的,例如:
- 消息队列:lpop和rpush(或者反过来,lpush和rpop)能实现队列的功能
- 朋友圈的点赞列表、评论列表、排行榜:lpush命令和lrange命令能实现最新列表的功能,每次通过lpush命令往列表里插入新的元素,然后通过lrange命令读取最新的元素列表。
Set
应用场景:
- 好友、关注、粉丝、感兴趣的人集合:
- sinter命令可以获得A和B两个用户的共同好友;
- sismember命令可以判断A是否是B的好友;
- scard命令可以获取好友数量;
- 关注时,smove命令可以将B从A的粉丝集合转移到A的好友集合
- 首页展示随机:美团首页有很多推荐商家,但是并不能全部展示,set类型适合存放所有需要展示的内容,而srandmember命令则可以从中随机获取几个。
- 存储某活动中中奖的用户ID ,因为有去重功能,可以保证同一个用户不会中奖两次。
Hash
应用场景:
- 购物车:hset [key] [field] [value] 命令, 可以实现以用户Id,商品Id为field,商品数量为value,恰好构成了购物车的3个要素。
- **存储对象:hash类型的(key, field, value)的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
**
Zset
应用场景:
zset 可以用做排行榜,但是和list不同的是zset它能够实现动态的排序,例如: 可以用来存储粉丝列表,value 值是粉丝的用户 ID,score 是关注时间,我们可以对粉丝列表按关注时间进行排序。
zset 还可以用来存储学生的成绩, value 值是学生的 ID, score 是他的考试成绩。 我们对成绩按分数进行排序就可以得到他的名次。
* 项目中如何使用的?

若有收获,就点个赞吧
0 人点赞
