1.视图
简介
- 对某个查询结果, 通过视图(英文名VIEW)的方式来复用这些查询语句
CREATE VIEW 视图名 AS 查询语句
- 视图也可以被称为虚拟表,因为我们可以对视图进行一些类似表的增删改查操作,只不过我们对视图的相关操作都会被映射到那个又臭又长的查询语句对应的底层的表上。那一串又臭又长的查询语句的查询列表可以被当作视图的虚拟列,比方说male_student_view这个视图对应的查询语句中的查询列表是number、name、major、subject、score,它们就可以被当作male_student_view视图的虚拟列。
创建和使用视图
- 我们平时怎么从真实表中查询信息,就可以怎么从视图中查询信息,比如这么写:
mysql> SELECT s1.number, s1.name, s1.major, s2.subject, s2.score FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number AND s1.sex = '男';+----------+-----------+--------------------------+-----------------------------+-------+| number | name | major | subject | score |+----------+-----------+--------------------------+-----------------------------+-------+| 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 || 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 || 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 || 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 |+----------+-----------+--------------------------+-----------------------------+-------+4 rows in set (0.00 sec)#新建视图mysql> CREATE VIEW male_student_view AS SELECT s1.number, s1.name, s1.major, s2.subject, s2.score FROM student_info AS s1 INNER JOIN student_score AS s2 WHERE s1.number = s2.number AND s1.sex = '男';Query OK, 0 rows affected (0.02 sec)##使用视图mysql> SELECT * FROM male_student_view;+----------+-----------+--------------------------+-----------------------------+-------+| number | name | major | subject | score |+----------+-----------+--------------------------+-----------------------------+-------+| 20180101 | 杜子腾 | 计算机科学与工程 | 母猪的产后护理 | 78 || 20180101 | 杜子腾 | 计算机科学与工程 | 论萨达姆的战争准备 | 88 || 20180103 | 范统 | 软件工程 | 母猪的产后护理 | 59 || 20180103 | 范统 | 软件工程 | 论萨达姆的战争准备 | 61 |+----------+-----------+--------------------------+-----------------------------+-------+4 rows in set (0.00 sec)
- 视图其实就相当于是某个查询语句的别名, 是一张虚拟表, 所以新创建的视图的名称不能和当前数据库中的其他视图或者表的名称冲突!- 创建视图的时候并不会把原来的查询语句的结果集维护在硬盘或者内存里!在对视图进行查询时,MySQL服务器将会帮助我们把对视图的查询语句转换为对底层表的查询语句然后再执行,比如说上边这个查询语句其实可以被转换成下边这个查询语句去执行- 在书写查询语句时,视图还可以和真实表一起使用
利用视图来创建新视图
- 把一个新建的视图, 完全当做表来引用做 FROM源 即可
创建视图时指定自定义列名
- 视图的虚拟列其实是这个视图对应的查询语句的查询列表,我们也可以在创建视图的时候为它的虚拟列自定义列名,这些自定义列名写到视图名后边,用逗号,分隔- 有了自定义列名之后,我们之后对视图的查询语句都要基于这些自定义列名. 如果仍旧使用与视图对应的查询语句的查询列表中的列名就会报错
mysql> SELECT number, name, major FROM student_info_view;ERROR 1054 (42S22): Unknown column 'number' in 'field list'
查看和删除视图
- 查看当前库视图:- 同 查看库中表 操作: SHOW TABLES;- 查看视图的定义
SHOW CREATE VIEW 视图名;
mysql> SHOW CREATE VIEW student_info_view\G*************************** 1. row ***************************View: student_info_viewCreate View: CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `student_info_view` AS select `student_info`.`number` AS `no`,`student_info`.`name` AS `n`,`student_info`.`major` AS `m` from `student_info`character_set_client: utf8collation_connection: utf8_general_ci1 row in set (0.00 sec)
视图的更新
- 我们前边唠叨的都是对视图的查询操作,其实有些视图是可更新的,也就是在视图上执行INSERT、DELETE、UPDATE语句。对视图执行INSERT、DELETE、UPDATE语句的本质上是对该视图对应的底层表中的数据进行增、删、改操作。比方说视图student_info_view的底层表是student_info,所以如果我们对student_info_view执行INSERT、DELETE、UPDATE语句就相当于对student_info表进行INSERT、DELETE、UPDATE语句- 并不是可以在所有的视图上执行更新语句的,在生成视图的时候使用了下边这些语句的都不能进行更新1. 聚集函数(比如SUM(), MIN(), MAX(), COUNT()等等)1. DISTINCT1. GROUP BY1. HAVING1. UNION 或者 UNION ALL1. 某些子查询1. 某些连接查询1. 等等等等
删除视图
DROP VIEW 视图名;
2.自定义变量
SET自定义变量
mysql> SET @a = 1;Query OK, 0 rows affected (0.00 sec)
使用自定义变量
mysql> SELECT @a;+------+| @a |+------+| 1 |+------+1 row in set (0.00 sec)
- 变量也可以再次赋值存储不同类型的值
mysql> SET @a = '哈哈哈';Query OK, 0 rows affected (0.01 sec)
- 可以把一个变量赋值给另一个变量
mysql> SET @b = @a;Query OK, 0 rows affected (0.00 sec)
- 将某个查询的结果赋值给一个变量,前提是这个查询的结果只有一个值
mysql> SET @a = (SELECT m1 FROM t1 LIMIT 1);Query OK, 0 rows affected (0.00 sec)
- 另一种形式的语句来将查询的结果赋值给一个变量
mysql> SELECT n1 FROM t1 LIMIT 1 INTO @b;Query OK, 1 row affected (0.00 sec)
- INTO: 查询结果中有多个列的值的话,INTO 可分别赋值到不同的变量中
mysql> SELECT m1, n1 FROM t1 LIMIT 1 INTO @a, @b;Query OK, 1 row affected (0.00 sec)
3.语句结束分隔符: delimiter
- 在MySQL客户端的交互界面处,当我们完成键盘输入并按下回车键时,MySQL客户端会检测我们输入的内容中是否包含;、\g或者\G这三个符号之一,如果有的话,会把我们输入的内容发送到服务器。这样一来,如果我们想一次性给服务器发送多条的话,就需要把这些语句写到一行中,比如这样:
mysql> SELECT * FROM t1 LIMIT 1;SELECT * FROM t2 LIMIT 1;SELECT * FROM t3 LIMIT 1;+------+------+| m1 | n1 |+------+------+| 1 | a |+------+------+1 row in set (0.00 sec)+------+------+| m2 | n2 |+------+------+| 2 | b |+------+------+1 row in set (0.00 sec)+------+------+| m3 | n3 |+------+------+| 3 | c |+------+------+1 row in set (0.00 sec)mysql>
- delimiter命令来自定义MySQL的检测语句输入结束的符号,也就是所谓的语句结束分隔符
mysql> delimiter $mysql> SELECT * FROM t1 LIMIT 1;-> SELECT * FROM t2 LIMIT 1;-> SELECT * FROM t3 LIMIT 1;-> $+------+------+| m1 | n1 |+------+------+| 1 | a |+------+------+1 row in set (0.00 sec)+------+------+| m2 | n2 |+------+------+| 2 | b |+------+------+1 row in set (0.00 sec)+------+------+| m3 | n3 |+------+------+| 3 | c |+------+------+1 row in set (0.00 sec)mysql>
- delimiter $命令意味着修改语句结束分隔符为$,也就是说之后MySQL客户端检测用户语句输入结束的符号为$。上边例子中我们虽然连续输入了3个以分号;结尾的查询语句并且按了回车键,但是输入的内容并没有被提交,直到敲下$符号并回车,MySQL客户端才会将我们输入的内容提交到服务器,此时我们输入的内容里已经包含了3个独立的查询语句了,所以返回了3个结果集。
避免使用反斜杠(\)字符作为语句结束分隔符,因为这是MySQL的转义字符。
4.存储函数
存储程序
- 存储程序可以封装一些语句,然后给用户提供一种简单的方式来调用这个存储程序,从而间接地执行这些语句- 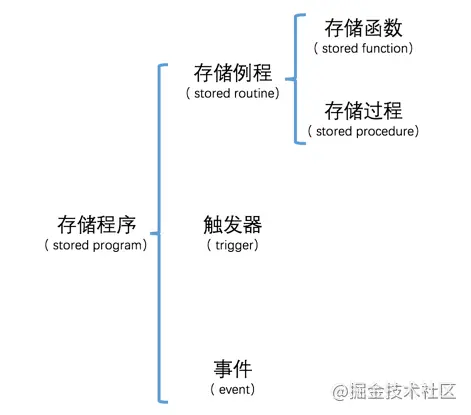- 其中存储例程需要我们去手动调用,而触发器和事件都是MySQL服务器在特定条件下自己调用的
存储函数
- 存储函数其实就是一种函数,只不过在这个函数里可以执行MySQL的语句而已
定义存储函数
- 定义一个存储函数需要指定函数名称、参数列表、返回值类型以及函数体内容。如果该函数不需要参数,那参数列表可以被省略,函数体内容可以包括一条或多条语句,每条语句都要以分号;结尾。上边语句中的制表符和换行仅仅是为了好看,如果你觉得烦,完全可以把存储函数的定义都写在一行里,用一个或多个空格把上述几个部分分隔开
CREATE FUNCTION 存储函数名([参数列表])RETURNS 返回值类型BEGIN函数体内容1;函数体内容2;...函数体内容n;END
mysql> delimiter $mysql> CREATE FUNCTION avg_score(s VARCHAR(100))-> RETURNS DOUBLE-> BEGIN-> RETURN (SELECT AVG(score) FROM student_score WHERE subject = s);-> END $Query OK, 0 rows affected (0.00 sec)mysql> delimiter ;
调用存储函数
- 同系统内置函数
mysql> SELECT avg_score('母猪的产后护理');+------------------------------------+| avg_score('母猪的产后护理') |+------------------------------------+| 73 |+------------------------------------+1 row in set (0.00 sec)
查看存储函数
- 查看存储函数
SHOW FUNCTION STATUS [LIKE 需要匹配的函数名]
- 查看具体函数的定义
SHOW CREATE FUNCTION 函数名
mysql> SHOW CREATE FUNCTION avg_score\G*************************** 1. row ***************************Function: avg_scoresql_mode: ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTIONCreate Function: CREATE DEFINER=`root`@`localhost` FUNCTION `avg_score`(s VARCHAR(100)) RETURNS doubleBEGINRETURN (SELECT AVG(score) FROM student_score WHERE subject = s);ENDcharacter_set_client: utf8collation_connection: utf8_general_ciDatabase Collation: utf8_general_ci1 row in set (0.01 sec)
- Create Function的那部分信息,该部分信息展示了这个存储函数的定义语句是什么样的
删除存储函数
DROP FUNCTION 函数名
mysql> DROP FUNCTION avg_score;Query OK, 0 rows affected (0.00 sec)
函数体
在存储函数的函数体中,DECLARE定义语句必须放到其他语句的前边。
在函数体中定义局部变量
- 使用SET语句来自定义变量的方式,可以不用声明就为变量赋值。而在存储函数的函数体中使用变量前必须先声明这个变量
DECLARE 变量名1, 变量名2, ... 数据类型 [DEFAULT 默认值];SET 变量名1 = 值1;SET 变量名1 = 值1;...SET 变量名n = 值n;
- 函数体中的局部变量名不允许加@前缀,这一点和我们之前直接使用SET语句自定义变量的方式是截然不同的
mysql> delimiter $;mysql> CREATE FUNCTION var_demo()-> RETURNS INT-> BEGIN-> DECLARE c INT;-> SET c = 5;-> RETURN c;-> END $Query OK, 0 rows affected (0.00 sec)
- 如果我们不对声明的局部变量赋值的话,它的默认值就是NULL,当然我们也可以通过DEFAULT子句来显式的指定局部变量的默认值
mysql> delimiter $mysql> CREATE FUNCTION var_default_demo()-> RETURNS INT-> BEGIN-> DECLARE c INT DEFAULT 1;-> RETURN c;-> END $Query OK, 0 rows affected (0.00 sec)
- 可以将某个查询语句的结果赋值给局部变量
CREATE FUNCTION avg_score(s VARCHAR(100))RETURNS DOUBLEBEGINDECLARE a DOUBLE;SET a = (SELECT AVG(score) FROM student_score WHERE subject = s);return a;END
在函数体中使用自定义变量
- 可以在函数体中使用我们之前用过的自定义变量
mysql> delimiter $mysql>mysql> CREATE FUNCTION user_defined_var_demo()-> RETURNS INT-> BEGIN-> SET @abc = 10;-> return @abc;-> END $Query OK, 0 rows affected (0.00 sec)mysql> SELECT user_defined_var_demo();+-------------------------+| user_defined_var_demo() |+-------------------------+| 10 |+-------------------------+1 row in set (0.01 sec)
- 虽然现在存储函数执行完了,但是由于在该函数执行过程中为自定义变量abc赋值了,那么在该函数执行完之后我们仍然可以访问到该自定义变量的值
mysql> SELECT @abc;+------+| @abc |+------+| 10 |+------+1 row in set (0.00 sec)
存储函数的参数
- 定义存储函数的时候,可以指定多个参数,每个参数都要指定对应的数据类型
(参数名 数据类型, 参数名 数据类型)
- 数名不要和函数体语句中的其他变量名、列名冲突- 数参数不可以指定默认值,我们在调用函数的时候,必须显式的指定所有的参数,并且参数类型也一定要匹配,比方说我们在调用函数avg_score时,否则报错:
定义的 avg_score(...) 需要一个varchar 参数mysql> select avg_score();ERROR 1318 (42000): Incorrect number of arguments for FUNCTION xiaohaizi.avg_score; expected 1, got 0
函数体中的判断语句]
IF 表达式 THEN处理语句列表[ELSEIF 表达式 THEN处理语句列表; ]... # 这里可以有多个ELSEIF语句[ELSE处理语句列表; ]END IF;
- 处理语句列表中可以包含多条语句,每条语句以分号;结尾
函数体中的循环语句
- WHILE... DO...循环语句
WHILE 表达式 DO循环体;END WHILE;
#计算 1到n 的累和mysql> delimiter $mysql> CREATE FUNCTION sum_all(n INT UNSIGNED)-> RETURNS INT-> BEGIN-> DECLARE result INT DEFAULT 0;-> DECLARE i INT DEFAULT 1;-> WHILE i <= n DO-> SET result = result + i;-> SET i = i + 1;-> END WHILE;-> RETURN result;-> END $Query OK, 0 rows affected (0.00 sec)mysql> SELECT sum_all(3);+------------+| sum_all(3) |+------------+| 6 |+------------+1 row in set (0.00 sec)
- REPEAT循环语句- 类似 JAVA: do() while{}
REPEAT处理语句列表UNTIL 表达式 END REPEAT;
CREATE FUNCTION sum_all(n INT UNSIGNED)RETURNS INTBEGINDECLARE result INT DEFAULT 0;DECLARE i INT DEFAULT 1;REPEATSET result = result + i;SET i = i + 1;UNTIL i > n END REPEAT;RETURN result;END
- LOOP循环语句- 在 <处理语句列表> 中使用 <RETURN;> 即 终止并返回函数
LOOP处理语句列表END LOOP;
CREATE FUNCTION sum_all(n INT UNSIGNED)RETURNS INTBEGINDECLARE result INT DEFAULT 0;DECLARE i INT DEFAULT 1;LOOPIF i > n THENRETURN result;END IF;SET result = result + i;SET i = i + 1;END LOOP;END
- 如果我们仅仅想结束循环,而不是使用RETURN语句直接将函数返回,那么可以使用LEAVE语句。不过使用LEAVE时,需要先在LOOP语句前边放置一个所谓的标记
CREATE FUNCTION sum_all(n INT UNSIGNED)RETURNS INTBEGINDECLARE result INT DEFAULT 0;DECLARE i INT DEFAULT 1;flag:LOOPIF i > n THENLEAVE flag;END IF;SET result = result + i;SET i = i + 1;END LOOP flag;RETURN result;END
- 在LOOP语句前加了一个flag:这样的东东,相当于为这个循环打了一个名叫flag的标记,然后在对应的END LOOP语句后边也把这个标记名flag给写上了。在存储函数的函数体中使用LEAVE flag语句来结束flag这个标记所代表的循环
实也可以在BEGIN … END、REPEAT和WHILE这些语句上打标记,标记主要是为了在这些语句发生嵌套时可以跳到指定的语句中使用的。
5.存储过程
- 存储函数和存储过程都属于存储例程,都是对某些语句的一个封装。存储函数侧重于执行这些语句并返回一个值,而存储过程更侧重于单纯的去执行这些语句
创建存储过程
- 与存储函数最直观的不同点就是,存储过程的定义不需要声明返回值类型。
CREATE PROCEDURE 存储过程名称([参数列表])BEGIN需要执行的语句END
mysql> delimiter $mysql> CREATE PROCEDURE t1_operation(-> m1_value INT,-> n1_value CHAR(1)-> )-> BEGIN-> SELECT * FROM t1;-> INSERT INTO t1(m1, n1) VALUES(m1_value, n1_value);-> SELECT * FROM t1;-> END $Query OK, 0 rows affected (0.00 sec)
- 建立了一个名叫t1_operation的存储过程,它接收两个参数,一个是INT类型的,一个是CHAR(1)类型的。这个存储过程做了3件事儿,一件是查询一下t1表中的数据,第二件是根据接收的参数来向t1表中插入一条语句,第三件是再次查询一下t1表中的数据
存储过程的调用: CALL
- 存储函数执行语句并返回一个值,所以常用在表达式中。存储过程偏向于执行某些语句,并不能用在表达式中,我们需要显式的使用CALL语句来调用一个存储过程
CALL 存储过程([参数列表]);
mysql> CALL t1_operation(4, 'd');+------+------+| m1 | n1 |+------+------+| 1 | a || 2 | b || 3 | c |+------+------+3 rows in set (0.00 sec)+------+------+| m1 | n1 |+------+------+| 1 | a || 2 | b || 3 | c || 4 | d |+------+------+4 rows in set (0.00 sec)Query OK, 0 rows affected (0.00 sec)
查看存储过程
- 前数据库中创建的存储过程
SHOW PROCEDURE STATUS [LIKE 需要匹配的存储过程名称]
- 查看某个存储过程具体是怎么定义
SHOW CREATE PROCEDURE 存储过程名称
删除存储过程
DROP PROCEDURE 存储过程名称
存储过程中的语句
- 存储函数中使用到的各种语句,包括变量的使用、判断、循环结构都可以被用在存储过程中
存储过程的参数前缀
- 储过程在定义参数的时候可以选择添加一些前缀- 不写明参数前缀的话,默认的前缀是IN
参数类型 [IN | OUT | INOUT] 参数名 数据类型
| 前缀 | 实际参数是否必须是变量 | 描述 |
|---|---|---|
| IN | 否 | 用于调用者向存储过程传递数据,如果IN参数在过程中被修改,调用者不可见。 |
| OUT | 是 | 用于把存储过程运行过程中产生的数据赋值给OUT参数,存储过程执行结束后,调用者可以访问到OUT参数。 |
| INOUT | 是 | 综合IN和OUT的特点,既可以用于调用者向存储过程传递数据,也可以用于存放存储过程中产生的数据以供调用者使用。 |
存储过程和存储函数的不同点
- 存储函数在定义时需要显式用RETURNS语句标明返回的数据类型,而且在函数体中必须使用RETURN语句来显式指定返回的值,存储过程不需要。- 存储函数只支持IN参数,而存储过程支持IN参数、OUT参数、和INOUT参数。- 存储函数只能返回一个值,而存储过程可以通过设置多个OUT参数或者INOUT参数来返回多个结果。- 存储函数执行过程中产生的结果集并不会被显示到客户端,而存储过程执行过程中产生的结果集会被显示到客户端。- 存储函数直接在表达式中调用,而存储过程只能通过CALL语句来显式调用。
6.游标
举例
mysql> SELECT m1, n1 FROM t1;+------+------+| m1 | n1 |+------+------+| 1 | a || 2 | b || 3 | c || 4 | d |+------+------+4 rows in set (0.00 sec)
- 这个SELECT m1, n1 FROM t1查询语句对应的结果集有4条记录,游标其实就是用来标记结果集中我们正在访问的某一条记录。初始状态下它标记结果集中的第一条记录- 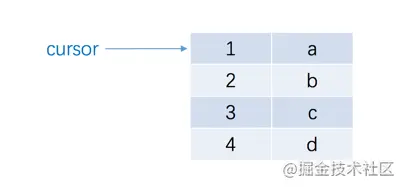
游标的使用
- 根据这个游标取出它对应记录的信息,随后再移动游标,让它执向下一条记录。游标既可以用在存储函数中,也可以用在存储过程中- 存储过程中游标的使用步骤1. 创建游标1. 打开游标1. 通过游标访问记录1. 关闭游标
创建游标
- 指定与游标关联的查询语句
DECLARE 游标名称 CURSOR FOR 查询语句;
#创建一个存储过程CREATE PROCEDURE cursor_demo()BEGINDECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;END
打开和关闭游标
- 在创建完游标之后,需要手动打开和关闭游标
OPEN 游标名称;CLOSE 游标名称;
- 打开游标意味着执行查询语句,创建一个该查询语句得到的结果集关联起来的游标,关闭游标意味着会释放该游标相关的资源,所以一旦我们使用完了游标,就要把它关闭掉。当然如果我们不显式的使用CLOSE语句关闭游标的话,在该存储过程的END语句执行完之后会自动关闭的。
CREATE PROCEDURE cursor_demo()BEGINDECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;OPEN t1_record_cursor;CLOSE t1_record_cursor;END
使用游标获取记录
FETCH 游标名 INTO 变量1, 变量2, ... 变量n
- 把指定游标对应记录的各列的值依次赋值给INTO后边的各个变量
CREATE PROCEDURE cursor_demo()BEGINDECLARE m_value INT;DECLARE n_value CHAR(1);DECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;OPEN t1_record_cursor;FETCH t1_record_cursor INTO m_value, n_value;SELECT m_value, n_value;CLOSE t1_record_cursor;END $mysql> CALL cursor_demo();+---------+---------+| m_value | n_value |+---------+---------+| 1 | a |+---------+---------+1 row in set (0.00 sec)Query OK, 0 rows affected (0.00 sec)
遍历结束时的执行策略
- 其实在FETCH语句获取不到记录的时候会触发一个事件,从而我们可以得知所有的记录都被获取过了,然后我们就可以去主动的停止循环。MySQL中响应这个事件的语句如下
DECLARE CONTINUE HANDLER FOR NOT FOUND 处理语句;
- 只要我们在存储过程中写了这个语句,那么在FETCH语句获取不到记录的时候,服务器就会执行我们填写的处理语句
CREATE PROCEDURE cursor_demo()BEGINDECLARE m_value INT;DECLARE n_value CHAR(1);DECLARE not_done INT DEFAULT 1;DECLARE t1_record_cursor CURSOR FOR SELECT m1, n1 FROM t1;DECLARE CONTINUE HANDLER FOR NOT FOUND SET not_done = 0;OPEN t1_record_cursor;flag: LOOPFETCH t1_record_cursor INTO m_value, n_value;IF not_done = 0 THENLEAVE flag;END IF;SELECT m_value, n_value, not_done;END LOOP flag;CLOSE t1_record_cursor;END
7.触发器
- 存储例程是需要我们手动调用的,而触发器和事件是MySQL服务器在特定情况下自动调用的
创建触发器
CREATE TRIGGER 触发器名{BEFORE|AFTER}{INSERT|DELETE|UPDATE}ON 表名FOR EACH ROWBEGIN触发器内容END
- 由大括号`{}`包裹并且内部用竖线`|`分隔的语句表示必须在给定的选项中选取一个值,比如`{BEFORE|AFTER}`表示必须在`BEFORE`、`AFTER`这两个之间选取一个。
{BEFORE|AFTER}
- 表示触发器内容执行的时机
| 名称 | 描述 |
|---|---|
| BEFORE | 表示在具体的语句执行之前就开始执行触发器的内容 |
| AFTER | 表示在具体的语句执行之后才开始执行触发器的内容 |
{INSERT|DELETE|UPDATE}
- 表示具体的语句,MySQL中目前只支持对INSERT、DELETE、UPDATE这三种类型的语句设置触发器
FOR EACH ROW BEGIN … END
- 表示对具体语句影响的每一条记录都执行我们自定义的触发器内容:- 对于INSERT语句来说,FOR EACH ROW影响的记录就是我们准备插入的那些新记录。- 对于DELETE语句和UPDATE语句来说,FOR EACH ROW影响的记录就是符合WHERE条件的那些记录(如果语句中没有WHERE条件,那就是代表全部的记录)。- 因为MySQL服务器会对某条语句影响的所有记录依次调用我们自定义的触发器内容,所以针对每一条受影响的记录,我们需要一种访问该记录中的内容的方式,MySQL提供了NEW和OLD两个单词来分别代表新记录和旧记录,它们在不同语句中的含义不同:- 对于INSERT语句设置的触发器来说,NEW代表准备插入的记录,OLD无效。- 对于DELETE语句设置的触发器来说,OLD代表删除前的记录,NEW无效。- 对于UPDATE语句设置的触发器来说,NEW代表修改后的记录,OLD代表修改前的记录。
定义触发器
mysql> delimiter $mysql> CREATE TRIGGER bi_t1-> BEFORE INSERT ON t1-> FOR EACH ROW-> BEGIN-> IF NEW.m1 < 1 THEN-> SET NEW.m1 = 1;-> ELSEIF NEW.m1 > 10 THEN-> SET NEW.m1 = 10;-> END IF;-> END $Query OK, 0 rows affected (0.02 sec)
- 我们对t1表定义了一个名叫bi_t1的触发器,它的意思就是在对t1表插入新记录之前,对准备插入的每一条记录都会执行BEGIN ... END之间的语句,NEW.列名表示当前待插入记录指定列的值。
查看和删除触发器
- 查看当前数据库中定义的所有触发器
SHOW TRIGGERS;
- 查看某个具体的触发器的定义:
SHOW CREATE TRIGGER 触发器名;
- 删除触发器:
DROP TRIGGER 触发器名;
触发器使用注意事项
- 触发器内容中不能有输出结果集的语句- 触发器内容中NEW代表记录的列的值可以被更改,OLD代表记录的列的值无法更改- 在BEFORE触发器中,我们可以使用SET NEW.列名 = 某个值的形式来更改待插入记录或者待更新记录的某个列的值,但是这种操作不能在AFTER触发器中使用,因为在执行AFTER触发器的内容时记录已经被插入完成或者更新完成了- 如果我们的BEFORE触发器内容执行过程中遇到了错误,那这个触发器对应的具体语句将无法执行;如果具体的操作语句执行过程中遇到了错误,那与它对应的AFTER触发器的内容将无法执行。
8.事件
- 定时器效果
创建事件
CREATE EVENT 事件名ON SCHEDULE{AT 某个确定的时间点|EVERY 期望的时间间隔 [STARTS datetime][END datetime]}DOBEGIN具体的语句END
定时事件
CREATE EVENT insert_t1_eventON SCHEDULEAT '2019-09-04 15:48:54'DOBEGININSERT INTO t1(m1, n1) VALUES(6, 'f');END
周期事件
CREATE EVENT insert_t1ON SCHEDULEEVERY 1 HOURDOBEGININSERT INTO t1(m1, n1) VALUES(6, 'f');END
- 也可指定该事件开始执行时间和截止时间
CREATE EVENT insert_t1ON SCHEDULEEVERY 1 HOUR STARTS '2019-09-04 15:48:54' ENDS '2019-09-16 15:48:54'DOBEGININSERT INTO t1(m1, n1) VALUES(6, 'f');END
查看和删除事件
- 查看当前数据库中定义的所有事件
SHOW EVENTS;
- 查看某个具体的事件的定义
SHOW CREATE EVENT 事件名;
- 删除事件
DROP EVENT 事件名;
执行事件
- 默认情况下,MySQL服务器并不会帮助我们执行事件,除非我们使用下边的语句手动开启该功能:
mysql> SET GLOBAL event_scheduler = ON;Query OK, 0 rows affected (0.00 sec)
event_scheduler其实是一个系统变量,它的值也可以在MySQL服务器启动的时候通过启动参数或者通过配置文件来设置event_scheduler的值。

若有收获,就点个赞吧
0 人点赞
