- 1.内存模型(1.7 和1.8),每个模型做什么?
- 2.堆内存组成(新生代和老年代)怎么?
- 3.Java中类的加载过程?
- 1.Spring 的重要注解
2.Spring MVC 框架有什么用?- 3.Mybatis 中#{}和{}是字符串替换。
4. MyBatis 的优点?
5.MyBatis 框架的缺点?
6. SQL 语言分类
7.事务的四个特性:- 8.聊聊脏读,幻读,不可重复读
- 9.spring创建Bean的几种方式
1.通过配置文件
2.通过注解
3.通过接口
11.聊聊面向对象的特征的理解AOP- 内存模型(1.7 和1.8),每个模型做什么
- 堆内存组成(新生代和老年代)怎么
- Java中类的加载过程?
类加载器有哪些?- 双亲委派模型如何打破
- 内存溢出和内存泄漏
- GC怎么判断对象是否可回收
- GC常用算法
- GC在堆内存的工作过程
- GC的回收器(CMS和G1)?
- Java中4种引用及区别?
- final、finally与finalize的区别?
哪些可以作为GC ROOTS?- 面向对象的认知?
- 面向对象的特征以及理解?
- this和super?
- 抽象类和接口(1.7和1.8)的区别?
- 各种关键字:static final instanceof?
- 装箱和拆箱?
- 排序算法(冒泡、快排)
- 查找算法(二分)
- 数组元素去重算法
- ArrayList底层,初始容量,扩容
- 1.HashMap底层结构1.7和1.8
2.HashMap的头插法和尾插法- 3.HashMap的put源码过程
- 4.ConCurrentHashMap底层1.7和1.8 安全(JUC)
- 线程的创建方式(4种)
线程的生命周期(状态)
sleep和wait
线程调度方法:join、notify- 1.线程池的五大状态
2.线程池的七大参数:核心线程,阻塞队列,最大线程,拒接策略
3.线程池的工作原理- 4.线程池的线程
- 1.锁的相关分类:乐观|悲观、公平|非公平、可重入|不可重入、共享|排他?
2.对象的锁升级过程(无锁、偏向锁、轻量级锁、重量级锁)
3.synchronized的三种用法和区别?
4.synchronized的实现原理- 2.Mybatis的缓存策略的理解
4.Mybatis的动态SQL和作用- 5.SpringMVC的拦截器和过滤器的区别?
1.内存模型(1.7 和1.8),每个模型做什么?
类的元数据信息转移到Metaspace的原因是PermGen很难调整。PermGen中类的元数据信息在每次FullGC的时候可能会被收集,但成绩很难令人满意。而且应该为PermGen分配多大的空间很难确定,因为PermSize的大小依赖于很多因素,比如JVM加载的class的总数,常量池的大小,方法的大小等。
此外,在HotSpot中的每个垃圾收集器需要专门的代码来处理存储在PermGen中的类的元数据信息。从PermGen分离类的元数据信息到Metaspace,由于Metaspace的分配具有和Java Heap相同的地址空间,因此Metaspace和Java Heap可以无缝的管理,而且简化了FullGC的过程,以至将来可以并行的对元数据信息进行垃圾收集,而没有GC暂停。
JDK1.7内存模型

对于这五个区域我大概做一个大概介绍,详细情况可以查阅其他资料或者文章
程序计数器:线程私有,可以看做当前程序执行的行号指令器。
Java虚拟机栈:线程私有,生命周期与线程相同,虚拟机栈描述的是Java方法执行的内存模型,每个方法在执行时会形成一个栈帧,用于存储局部变量表、操作数栈、动态链接、方法出口等信息,一个方法从调用到执行完毕,就是一个栈帧从进栈到出栈的过程,下图是虚拟机栈的结构模型,图片来源和详细解释:https://www.cnblogs.com/aflyun/p/10575740.html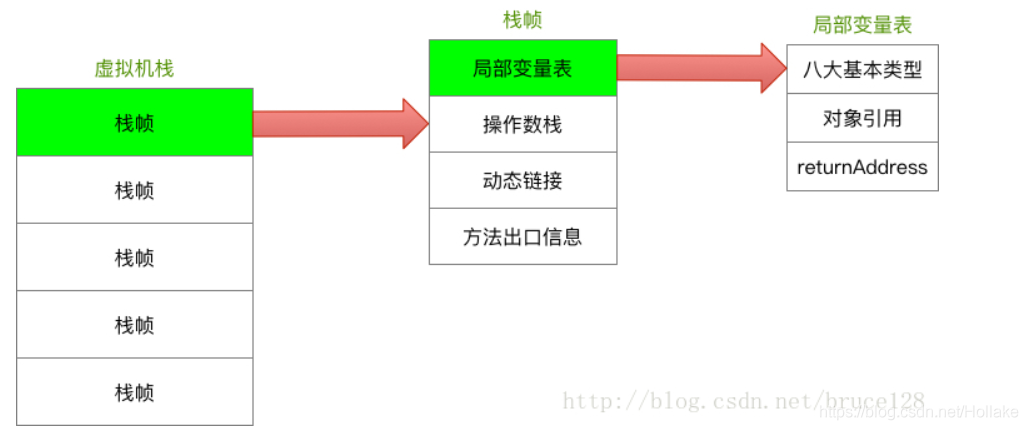
本地方法栈:线程私有,作用于Java虚拟机栈类似,只不过Java虚拟机栈执行Java方法,而本地方法栈运行本地的Native方法。
堆:Java虚拟机管理的最大的一块内存区域,Java堆是线程共享的,用于存放对象实例。也就是说对象的出生和回收都是在这个区域进行的。堆分为初生代(Young Gen)和老年代(Tenured Gen),比例默认为1:2,而初生代又分为Eden和From和To三个区域,比例默认为8:1:1
方法区:线程共享,用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,这里要说一下方法区和永久代到底是什么关系,永久代是HotSpot虚拟机对于方法区的实现,方法区的实现是不受虚拟机规范约束的,这里只是HotSpot虚拟机团队是这样实现的。
运行时常量池:在JDK1.7中,是运行时常量池是方法区的一部分,用于存放编译期生成的各种字符变量和符号引用。其实除了运行时常量池,还有字符串常量池,class常量池,具体的介绍和区别请看这篇文章:Java中的常量池(字符串常量池、class常量池和运行时常量池)
以上就是JDK1.7的虚拟机内存模型。
JDK1.8内存模型
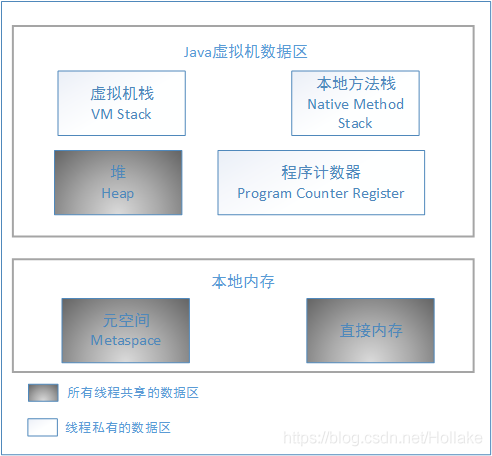
JDK1.8与1.7最大的区别是1.8将永久代取消,取而代之的是元空间,既然方法区是由永久代实现的,取消了永久代,那么方法区由谁来实现呢,在1.8中方法区是由元空间来实现,所以原来属于方法区的运行时常量池就属于元空间了。元空间属于本地内存,所以元空间的大小仅受本地内存限制,但是可以通过-XX:MaxMetaspaceSize进行增长上限的最大值设置,默认值为4G,元空间的初始空间大小可以通过-XX:MetaspaceSize进行设置,默认值为20.8M,还有一些其他参数可以进行设置,元空间大小会自动进行调整,详细请看这篇文章:jdk8 Metaspace 调优
这里要说明一下,要区分字符串常量池和运行时常量池,这里引用这篇文章JDK1.8关于运行时常量池, 字符串常量池的要点所提到的:
- 在JDK1.7之前**运行时常量池逻辑包含字符串常量池存放在方法区,** 此时hotspot虚拟机对方法区的实现为永久代
- 在JDK1.7字符串常量池被从方法区拿到了堆中, 这里没有提到运行时常量池,也就是说字符串常量池被单独拿到堆,运行时常量池剩下的东西还在方法区, 也就是hotspot中的永久代
- 在JDK1.8 hotspot移除了永久代用元空间(Metaspace)取而代之, 这时候字符串常量池还在堆, 运行时常量池还在方法区, 只不过方法区的实现从永久代变成了元空间(Metaspace)
从jdk开始,就开始了永久代的转移工作,将譬如符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap。但是永久在还存在于JDK7中,直到JDK8,永久代才完全消失,转而使用元空间。而元空间是直接存在内存中,不在java虚拟机中的,因此元空间依赖于内存大小。当然你也可以自定义元空间大小。
为什么叫元空间,是因为这里面存储的是类的元数据信息
元数据(Meta Date),关于数据的数据或者叫做用来描述数据的数据或者叫做信息的信息。 这些定义都很是抽象,我们可以把元数据简单的理解成,最小的数据单位。元数据可以为数据说明其元素或属性(名称、大小、数据类型、等),或其结构(长度、字段、数据列),或其相关数据(位于何处、如何联系、拥有者)
为什么这么做呢?
类的元数据, 字符串池, 类的静态变量将会从永久代移除, 放入Javaheap或者native memory. 其中建议JVM的实现中将类的元数据放入 native memory, 将字符串池和类的静态变量放入Java堆中. 这样可以加载多少类的元数据就不在由MaxPermSize控制, 而由系统的实际可用空间来控制.
为什么这么做呢? 减少OOM只是表因, 更深层的原因还是要合并HotSpot和JRockit的代码, JRockit从来没有一个叫永久代的东西, 但是运行良好, 也不需要开发运维人员设置这么一个永久代的大小.
5、方法区:
方法区也是所有线程共享。主要用于存储类的信息、常量池、方法数据、方法代码等。方法区逻辑上属于堆的一部分,但是为了与堆进行区分,通常又叫“非堆”。 关于方法区内存溢出的问题会在下文中详细探讨。
二、PermGen(永久代)
绝大部分 Java 程序员应该都见过 “java.lang.OutOfMemoryError: PermGen space “这个异常。这里的 “PermGen space”其实指的就是方法区。不过方法区和“PermGen space”又有着本质的区别。前者是 JVM 的规范,而后者则是 JVM 规范的一种实现,并且只有 HotSpot 才有 “PermGen space”,而对于其他类型的虚拟机,如 JRockit(Oracle)、J9(IBM) 并没有“PermGen space”。由于方法区主要存储类的相关信息,所以对于动态生成类的情况比较容易出现永久代的内存溢出。最典型的场景就是,在 jsp 页面比较多的情况,容易出现永久代内存溢出。我们现在通过动态生成类来模拟 “PermGen space”的内存溢出:
本例中使用的 JDK 版本是 1.7,指定的 PermGen 区的大小为 8M。通过每次生成不同URLClassLoader对象来加载Test类,从而生成不同的类对象,这样就能看到我们熟悉的 “java.lang.OutOfMemoryError: PermGen space “ 异常了。这里之所以采用 JDK 1.7,是因为在 JDK 1.8 中, HotSpot 已经没有 “PermGen space”这个区间了,取而代之是一个叫做 Metaspace(元空间) 的东西。下面我们就来看看 Metaspace 与 PermGen space 的区别。
三、Metaspace(元空间)
其实,移除永久代的工作从JDK1.7就开始了。JDK1.7中,存储在永久代的部分数据就已经转移到了Java Heap或者是 Native Heap。但永久代仍存在于JDK1.7中,并没完全移除,譬如符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap。 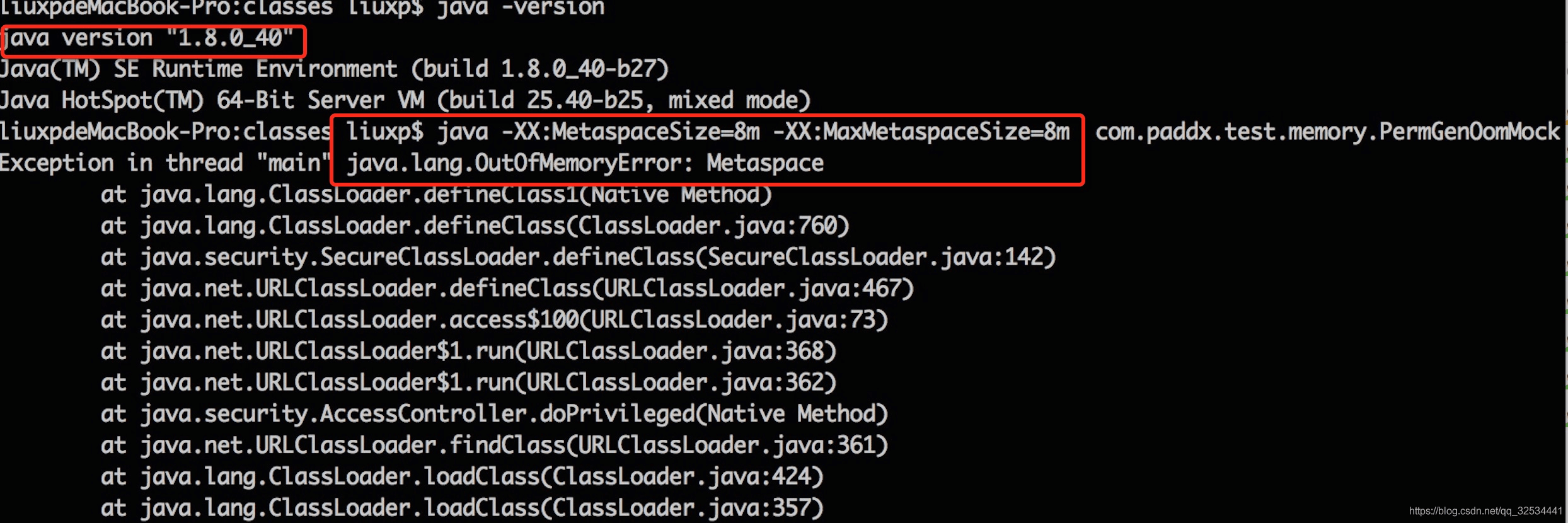 从输出结果,我们可以看出,这次不再出现永久代溢出,而是出现了元空间的溢出。
从输出结果,我们可以看出,这次不再出现永久代溢出,而是出现了元空间的溢出。
四、总结
通过上面分析,大家应该大致了解了 JVM 的内存划分,也清楚了 JDK 8 中永久代向元空间的转换。不过大家应该都有一个疑问,就是为什么要做这个转换?所以,最后给大家总结以下几点原因:
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
4、Oracle 可能会将HotSpot 与 JRockit 合二为一。
2.堆内存组成(新生代和老年代)怎么?
JVM堆内存
jvm堆内存主要分为新生代和老年代,当垃圾收集器触发GC的时候会对堆内存长时间没用的对象分代进行回收,新生代和老年代内存占比为1:2。
文章目录
JVM堆内存
新生代
1.Eden区
2.s0,s1
老年代
Xmx和Xms
新生代
新生代主要分为Eden区,s1,s0三个区域,分别内存占比8:1:1。1.Eden区
当新创建一个对象,这个对象首先会到Eden区,如果Eden区放满了,会产生一次young GC 这次GC会把Eden区没有用到的对象回收掉,并把可用对象复制到Survival 区,并记录这些对象一次GC年龄。2.s0,s1
当Eden区内存满了后,GC收集器会触发复制算法,将Eden区的存活对象复制到s0或者s1,s0和s1始终保持有一个空的区域,当s1或s0其中一个满了,也会触发一次GC并把可用对象赋值到另一个空区域,当GC到一定次数后依然存活的对象会进入老年代。老年代
当经过多次GC的对象年龄达到一个阈值而没有被回收或者比较大的对象,会直接进入老年代,当老年代内存满了,会触发full GC这个时候会清理整个堆内存未被使用的对象,GC时老年代采用的是标记整理算法。
在这里插入图片描述Xmx和Xms
Xms 用来指定初始堆内存,默认占系统内存1/64,java应用启动后jvm会向操作系统申请内存,在申请的内存到达Xms之前,所有申请的内存不用了会还给操作系统,当申请的内存达到Xms,那么Xms之前的内存只会清空不会还给操作系统,而申请超过初始内存小于最大内存这些内存也会归还给操作系统,如果程序启动默认就会申请很多内存,建议把Xmx和Xms设置成一样。
Xmx 用来指定最大堆大小,默认占系统内存1/4,当申请的内存超过最大堆内存就会造成堆OutOfMemoryError,导致程序直接挂掉。————————————————版权声明:本文为CSDN博主「风飞-沙」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/qq_39217120/article/details/112313187
3.Java中类的加载过程?
当Java程序需要使用某个类时,如果该类还未被加载到内存中,JVM会通过加载、连接(验证、准备和解析)、初始化三个步骤来对该类进行初始化。
类的加载是指把类的.class文件中的数据读入到内存中,通常是创建一个字节数组读入.class文件,然后产生与所加载类对应的Class对象。加载完成后,Class对象还不完整,所以此时的类还不可用。当类被加载后就进入连接阶段,这一阶段包括验证、准备(为静态变量分配内存并设置默认的初始值)和解析(将符号引用替换为直接引用)三个步骤。最后JVM对类进行初始化,包括:
1)如果类存在直接的父类并且这个类还没有被初始化,那么就先初始化父类;
2)如果类中存在初始化语句,就依次执行这些初始化语句。
1.Spring 的重要注解
@Controller - 用于 Spring MVC 项目中的控制器类。
@Service - 用于服务类。
@RequestMapping - 用于在控制器处理程序方法中配置 URI 映射。
@ResponseBody - 用于发送 Object 作为响应,通常用于发送 XML 或 JSON 数据作为响应。
@PathVariable - 用于将动态值从 URI 映射到处理程序方法参数。
@Autowired - 用于在 spring bean 中自动装配依赖项
@Qualifier - 使用 @Autowired 注解,以避免在存在多个 bean 类型实例时出现混淆。
@Scope - 用于配置 spring bean 的范围。
@Configuration,@ComponentScan 和 @Bean - 用于基于 java 的配置。
@Aspect,@Before,@After,@Around,
@Pointcut - 用于切面编程(AOP)。
2.Spring MVC 框架有什么用?
Spring Web MVC 框架提供 模型-视图-控制器 架构和随时可用的组件,用于开发灵活且松散耦合的 Web 应用程序。 MVC 模式有助于分离应用程序的不同方面,如输入逻辑,业务逻辑和 UI 逻辑,同时在所有这些元素之间提供松散耦合。
3.Mybatis 中#{}和{}是字符串替换。
Mybatis 在处理#{}时,会将 sql 中的#{}替换为?号
Mybatis 在处理{}替换成变量的值。
使用#{}可以有效的防止 SQL 注入,提高系统安全性。
4. MyBatis 的优点?
1、基于 SQL 语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,
SQL 写在XML里,解除sql与程序代码的耦合,便于统一管理;提供 XML 标签,支持编写动态SQL语句,并可重用。
2、与JDBC相比,减少了 50%以上的代码量,消除了 JDBC 大量冗余的代码,不需要手动开关连接;
3、很好的与各种数据库兼容。
4、能够与 Spring 很好的集成;
5、提供映射标签,支持对象与数据库的 ORM 字段关系映射;提供对象关系映射标签,支
持对象关系组件维护。
5.MyBatis 框架的缺点?
1、SQL 语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写 SQL 语句
的功底有一定要求。
2、SQL 语句依赖于数据库,导致数据库移植性差,不能随意更换数据库。
6. SQL 语言分类
数据查询语言DQL
数据操纵语言 DML
数据定义语言DDL
7.事务的四个特性:
事务是访问数据库的一个操作序列,数据库应用系统通过事务集来完成对数据库的存取。事务的正确执行使得数据库从一种状态转换成另一种状态。
原子性(Atomicity):
原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成
功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。
一致性(Consistency):
事务开始前和结束后,数据库的完整性约束没有被破坏。
隔离性(Isolation):
隔离性是当多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。
持久性(Durability):
持久性是指一个事务一旦被提交了,对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作
8.聊聊脏读,幻读,不可重复读
1.脏读
是指一个事务读取了另一个事务还未提交的数据。
2.不可重复读:
事务前后读取到的数据不一致
3.幻读:
发生在两个完全相同的查询执行时,第二次查询所返回的结果跟第一次查询不相同。
9.spring创建Bean的几种方式
1.通过配置文件
2.通过注解
3.通过接口
10.restful接口规范在Restful风格中,用户请求的url使用同一个url,而用请求方式:get(查询),post(添加),delete(删除),put(修改)进行区分
11.聊聊面向对象的特征的理解AOP
面向对象的特征:继承,封装,多态
封装可以隐藏代码实现的细节,使得代码模块化;
继承可以扩展已存在的代码模块;
它们的目的都是代码重用;
而多态实现了另一个目的:接口重用。
内存模型(1.7 和1.8),每个模型做什么
JDK1.8与JDK1.7最大的区别是:JDK1.8将永久代取消,取而代之的是元空间,在JDK1.8中方法区是由元空间来实现,所以原来属于方法区的运行时常量池就属于元空间了。元空间属于本地内存,所以元空间的大小仅受本地内存限制,但是可以通过-XX:MaxMetaspaceSize进行增长上限的最大值设置,默认值为4G,元空间的初始空间大小可以通过-XX:Me
堆内存组成(新生代和老年代)怎么
堆内存用于存放由new创建的对象和数组,其中新声带存放新生的对象或者年龄不大的对象,老年代则存放老年对象。新生代分为den区、s0区、s1区,s0和s1也被称为from和to区域,他们是两块大小相等并且可以互相角色的空间。绝大多数情况下,对象首先分配在eden区,在新生代回收后,如果对象还存活,则进入s0或s1区,之后每经过一次新生代回收,如果对象存活则它的年龄就加1,对象达到一定的年龄后,则进入老年代。
Java中类的加载过程?
类加载的过程主要分为三个部分:
- 加载
- 链接
- 初始化
链接又可以细分为三个小部分:
- 验证
- 准备
-
类加载器有哪些?java类加载器有四种,具体包括:
1、引导类加载器用来加载Java的核心库,引导类加载器用原生代码来实现。
2、扩展类加载器用来加载Java的扩展库,该类加载器在此目录里面查找并加载Java类。
3、系统类加载器根据Java应用的类路径来加载Java类。
4、除了系统提供的类加载器以外,开发人员可以通过继承的方式实现自己的类加载器,以满足一些特殊的需求双亲委派模型如何打破
当类加载器收到加载任务,总是先将任务委派给内部的父类加载器,(内部包含父类加载器),直到将请求传递到最顶层的启动类加载器,如果成功加载,返回通知结果,如果失败则由下层加载。
如果想自定义类加载器,就需要继承ClassLoader,并重写findClass,如果想不遵循双亲委派的类加载顺序,还需要重写loadClass。内存溢出和内存泄漏
内存溢出(Out Of Memory) :就是申请内存时,JVM没有足够的内存空间。
- 内存泄露 (Memory Leak):就是申请了内存,但是没有释放,导致内存空间浪费。
GC怎么判断对象是否可回收
1 引用计数器:每一个对象有一个引用属性,新增一个引用时加一,引用释放时减一,计数为0的时候可以回收。
2 可达性分析:从GcRoot开始向下搜索,搜索所走过的路径被称为引用链,当一个对象到GcRoot没有任何引用链相连时,则证明此对象是不可用的,那么虚拟机就可以判定回收。GC常用算法
引用计数法、标记-清除法、复制算法、标记-清除算法GC在堆内存的工作过程
先一次性分配一块较大的空间,然后每次new时都在该空间上进行分配和释放,减少了系统的调用的次数,节省了一定的系统消耗,这和内存池机制有相似;第二点就是有了这块内存空间后,如何进行分配和回收就和GC 机制有相关了。GC的回收器(CMS和G1)?
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。这是因为CMS收集器工作时,GC工作线程与用户线程可以并发执行,以此来达到降低收集停顿时间的目的。
G1重新定义了堆空间,打破了原有的分代模型,将堆划分为一个个区域。这么做的目的是在进行收集时不必在全堆范围内进行,这是它最显著的特点。区域划分的好处就是带来了停顿时间可预测的收集模型:用户可以指定收集操作在多长时间内完成。即G1提供了接近实时的收集特性。Java中4种引用及区别?
java对象的引用包括
强引用,软引用,弱引用,虚引用
Java中提供这四种引用类型主要有两个目的:
第一是可以让程序员通过代码的方式决定某些对象的生命周期;
第二是有利于JVM进行垃圾回收。
强引用
是指创建一个对象并把这个对象赋给一个引用变量
软引用(SoftReference)
如果一个对象具有软引用,内存空间足够,垃圾回收器就不会回收它;
如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
弱引用(WeakReference)
弱引用也是用来描述非必需对象的,当JVM进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象
虚引用(PhantomReference)
虚引用和前面的软引用、弱引用不同,它并不影响对象的生命周期。如果一个对象与虚引用关联,则跟没有引用与之关联一样,在任何时候都可能被垃圾回收器回收。
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。
虚引用与软引用和弱引用的一个区别在于:
虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,
如果发现它还有虚引,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队
列中
final、finally与finalize的区别?
final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
finally 是异常处理语句结构的一部分,表示总是执行。
finalize 是 Object 类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,
可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。
哪些可以作为GC ROOTS?
作为 GC Roots 对象的包括如下几种:
- 虚拟机栈(栈桢中的本地变量表)中的引用的对象。
- 方法区中的类静态属性引用的对象。
- 方法区中的常量引用的对象。
- 本地方法栈中JNI的引用的对象
面向对象的认知?
1,从面向过程到面向对象是角色的转变:从执行者转向指挥者。
2、将一系列功能封装到类中,可以提高代码的复用性。
3、面向对象的三大特征:封装、继承、多态。
4、类的构成:
java中最基本的单位是类,类由成员变量和成员方法构成。面向对象的特征以及理解?
三个基本特征是:封装、继承、多态。
封装,也就是把客观事物封装成抽象的类,并且类可以把自己的数据和方法只让可信的类或者对象操作,对不可信的进行信息隐藏。
继承
面向对象编程 (OOP) 语言的一个主要功能就是“继承”。继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展。
多态性(polymorphisn)是允许你将父对象设置成为和一个或更多的他的子对象相等的技术,赋值之后,父对象就可以根据当前赋值给它的子对象的特性以不同的方式运作。this和super?
this代表当前对象本身,可以理解为:指向对象本身的一个指针。
this用法:
this(param):调用本类的构造方法;
this.成员变量:调用当前对象的成员变量;
this.成员方法(param):调用本类的成员方法
super代表当前对象的父类,可以理解为:指向自己父类对象的一个指针。
super用法:
super(param):调用父类的构造方法;
super.成员变量:调用父类的成员变量;
抽象类和接口(1.7和1.8)的区别?
JDK1.7
接口的方法默认是 public,所有方法在接口中不能有实现,而抽象类可以有非抽象的方法。
接口中除了 static、final 变量,不能有其他变量,而抽象类中则不一定。
一个类可以实现多个接口,但只能实现一个抽象类。接口自己本身可以通过 extends 关键字扩展多个接口。
接口方法默认修饰符是 public,抽象方法可以有 public、protected 和 default 这些修饰符(抽象方法就是为了被重写所以不能使用 private 关键字修饰!)
- JDK1.8改动
在 jdk 7 或更早版本中,接口里面只能有常量变量和抽象方法。这些接口方法必须由选择实现接口的类实现。
jdk8 的时候接口可以有默认方法和静态方法功能。
Jdk 9 在接口中引入了私有方法和私有静态方法
各种关键字:static final instanceof?
static关键字
可以将类中的成员标识为静态的,既可以用来标识成员属性,也可以用来标识成员方法。
final关键字
它可以加在类或类中方法前。但不能使用final标识成员属性,使用final标识的类,不能被继承
在类中使用final标识的成员方法,在子类中不能被覆盖
Instanceof关键字
使用这个关键字可以确定一个对象是类的实例、类的子类,还是实现了某个特定接口,并进行相应的操作
装箱和拆箱?
装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型。
排序算法(冒泡、快排)
冒泡排序
冒泡排序(Bubble Sort)是一种简单直观的排序算法。# 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。# 走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。# 这个算法的名字由来是因为越小的元素会经由交换慢慢”浮”到数列的顶端。
快速排序
随机选择列表中的一个值作为中间值,将整个列表分割成两半。这个值称为base。# 建立两个空列表,分别是left 和right# 遍历整个列表,比base大的值都放right, 比base小的放left# 对left 和right分别做快速排序
查找算法(二分)
二分查找(Binary Search)
说明:元素必须是有序的,如果是无序的则要先进行排序操作。
基本思想:也称为是折半查找,属于有序查找算法。用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
数组元素去重算法
基本方法
思路:创建一个新数组,遍历原数组,若遍历元素在新数组不存在就添加到数组中,反正则忽略
先排序再去重
思路:先对数组排序,再定义一个新的数组,遍历排序后的数组,若排序后的数组元素不等于新数组的最后一个元素,则添加。
对象去重
思路:利用对象的属性。遍历数组,若该数组元素不是对象的属性,则添加。
filter,indexOf方法
思路:通过filter筛选出去重后的数组。若indexOf方法在该元素之后再查不到该元素的位置,表示该元素不存在,符合要求。
ES6 Set
思路:利用ES6中Set不包含重复元素的思想,为数组创建set对象,再将set对象转换为数组。
ArrayList底层,初始容量,扩容
构造一个容量大小为 10 的空的 list 数组,但这里构造函数了只是给 elementData 赋值了一个空的数组,实际上并未开始扩容,这时候的容量还是0,真正开始扩容其实是在第一次添加元素时才容量扩大至 10 的。
1.HashMap底层结构1.7和1.8
底层数据结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构(当链表长度大于8,转为红黑树)。
2.HashMap的头插法和尾插法
头插:
在头节点的后面进行插入操作,后一个插入进来的值,在前一个插入进来的值与头节点之间。
尾插法:
设法找到插入结点的上一个结点,总而言之,尾插法就是要使后面插入的结点在前一个插入结点和NULL值之间。
3.HashMap的put源码过程
1.判断当前是否初始化,进行初始化
2.判断当前位置有无节点,没有的话直接新new一个节点放入
3.当前位置有节点需要判断key是否相同,相同的话需要新值覆盖旧值
4.不相同的话判断当前节点是否是红黑树节点,是的话按照红黑树的插入方法插入
5.不是的话进行链表的遍历,查看是否有key相同的节点,有的话新值覆盖旧值,没有的话正常来说走到最后一个节点,使用尾插法插入即可
[
](https://blog.csdn.net/qq_43716944/article/details/112727248)
4.ConCurrentHashMap底层1.7和1.8 安全(JUC)
线程的创建方式(4种)
继承Thread类
实现Runnable接口
实现Callable接口
线程池
线程的生命周期(状态)
当线程被创建并启动以后,它既不是一启动就进入了执行状态,也不是一直处于执行状态。 在线程的生命周期中,它要经过新建(New)、就绪(Runnable)、运行(Running)、阻塞 (Blocked)和死亡(Dead)5 种状态。尤其是当线程启动以后,它不可能一直”霸占”着 CPU 独自 运行,所以 CPU 需要在多条线程之间切换,于是线程状态也会多次在运行、阻塞之间切换
[
](https://blog.csdn.net/qq_43599835/article/details/90721919)
sleep和wait
sleep() 方法是线程类(Thread)的静态方法,让调用线程进入睡眠状态,让出执行机会给其他线程,等到休眠时间结束后,线程进入就绪状态和其他线程一起竞争cpu的执行时间。
wait()是Object类的方法,当一个线程执行到wait方法时,它就进入到一个和该对象相关的等待池,同时释放对象的机锁,使得其他线程能够访问,可以通过notify,notifyAll方法来唤醒等待的线程
线程调度方法:join、notify
join方法的作用是父线程等待子线程执行完成后再执行,换句话说就是将异步执行的线程合并为同步的线程。
调用notify()方法后,将从对象的等待池中移走一个任意的线程并放到锁标志等待池中,只有锁标志等待池中线程能够获取锁标志;如果锁标志等待池中没有线程,则notify()不起作用。
1.线程池的五大状态
1.RUNNING
状态说明:线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。
状态切换:线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0!
2.SHUTDOWN
状态说明:线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。
状态切换:调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN。
3.STOP
状态说明:线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。
状态切换:调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
4.TIDYING
状态说明:当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。
状态切换:当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。
当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING。
5.TERMINATED
状态说明:线程池彻底终止,就变成TERMINATED状态。
状态切换:线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED。
2.线程池的七大参数:核心线程,阻塞队列,最大线程,拒接策略
1、七大参数:
corePoolSize:线程池核心线程数量,核心线程不会被回收,即使没有任务执行,也会保持空闲状态。如果线程池中的线程少于此数目,则在执行任务时创建。
maximumPoolSize:池允许最大的线程数,当线程数量达到corePoolSize,且workQueue队列塞满任务了之后,继续创建线程。
keepAliveTime:超过corePoolSize之后的“临时线程”的存活时间。
unit:keepAliveTime的单位。
workQueue:当前线程数超过corePoolSize时,新的任务会处在等待状态,并存在workQueue中,BlockingQueue是一个先进先出的阻塞式队列实现,底层实现会涉及Java并发的AQS机制,有关于AQS的相关知识,我会单独写一篇,敬请期待。
threadFactory:创建线程的工厂类,通常我们会自顶一个threadFactory设置线程的名称,这样我们就可以知道线程是由哪个工厂类创建的,可以快速定位。
handler:线程池执行拒绝策略,当线数量达到maximumPoolSize大小,并且workQueue也已经塞满了任务的情况下,线程池会调用handler拒绝策略来处理请求
3.线程池的工作原理
提交任务
创建工作线程
启动工作线程
4.线程池的线程
1.锁的相关分类:乐观|悲观、公平|非公平、可重入|不可重入、共享|排他?
乐观锁 VS 悲观锁
对于同一个数据的并发操作,悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java中,synchronized关键字和Lock的实现类都是悲观锁。
而乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作
公平锁 VS 非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁。公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁,所以非公平锁有可能出现后申请锁的线程先获取锁的场景。非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
可重入锁 VS 非可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象或者class),不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。
独享锁 VS 共享锁
独享锁和共享锁同样是一种概念。
独享锁也叫排他锁,是指该锁一次只能被一个线程所持有。如果线程T对数据A加上排它锁后,则其他线程不能再对A加任何类型的锁。获得排它锁的线程即能读数据又能修改数据。JDK中的synchronized和JUC中Lock的实现类就是互斥锁。
共享锁是指该锁可被多个线程所持有。如果线程T对数据A加上共享锁后,则其他线程只能对A再加共享锁,不能加排它锁。获得共享锁的线程只能读数据,不能修改数据。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
[
](https://blog.csdn.net/dagedeshu/article/details/100912333)
2.对象的锁升级过程(无锁、偏向锁、轻量级锁、重量级锁)

3.synchronized的三种用法和区别?
用法
1.作用于实例方法,当前实例加锁,进入同步代码前要获得当前实例的锁;
2.作用于静态方法,当前类加锁,进去同步代码前要获得当前类对象的锁;
3.作用于代码块,这需要指定加锁的对象,对所给的指定对象加锁,进入同步代码前要获得指定对象的锁。
区别
修饰普通方法 一个对象中的加锁方法只允许一个线程访问。但要注意这种情况下锁的是访问该方法的实例对象, 如果多个线程不同对象访问该方法,则无法保证同步。
修饰静态方法 由于静态方法是类方法, 所以这种情况下锁的是包含这个方法的类,也就是类对象;这样如果多个线程不同对象访问该静态方法,也是可以保证同步的。
修饰代码块 其中普通代码块 如Synchronized(obj) 这里的obj 可以为类中的一个属性、也可以是当前的对象,它的同步效果和修饰普通方法一样;Synchronized方法 (obj.class)静态代码块它的同步效果和修饰静态方法类似。
4.synchronized的实现原理
2.Mybatis的缓存策略的理解
ybatis中,有两种缓存策略,也就是一级缓存和二级缓存;在说这两种缓存的区别前,先简单提一下mybatis的几个关键对象:SqlSession可以认为是一个数据库会话(连接),由SqlSessionFactory创建,而SqlSessionFactory又是由SqlSessionFactoryBuilder创建。
mybatis的一级缓存,缓存的数据,作用域范围是同一个SqlSession;
mybatis的二级缓存,缓存的数据,作用域范围是同一个SqlSessionFactory创建的所有SqlSession。
mybatis的缓存可以理解为一个map,map的key由namespace、statement-id、offset、limit、sql、env共同决定。
4.Mybatis的动态SQL和作用
5.SpringMVC的拦截器和过滤器的区别?
1.过滤器是servlet中的,任何框架都可以使用过滤器技术;
2.拦截器是Springmvc所独有的
3.过滤器设置/*可以拦截任何资源
4.拦截器只对控制器controller中的方法进行拦截

若有收获,就点个赞吧
0 人点赞
