图的结构
对于图来说,主要有邻接矩阵和邻接表两种表示方法,在这里定义邻接表结构
//图public class Graph{//图中所有节点的集合public HashMap<Integer,Node> nodes;//图中所有边的集合public HashSet<Edge> edges;public Graph() {this.nodes = new HashMap<>();this.edges = new HashSet<>();}}//节点public Node {//节点的值public int value ;//节点的入度public int in;//节点的出度public int out;//节点的所有指向节点(出度对应节点)public ArrayList<Node> nexts;//节点的所有出边public ArrayList<Edge> edges;public Node(int value) {this.value = value;this.in = 0 ;this.out = 0 ;this.nexts = new ArrayList<>();this.edges = new ArrayList<>();}}//边public Edge {//边的权值public int weight;//边的from节点public Node from;//边的to节点public Node to;public Edge(int weight,Node from,Node to) {this.weight = weight;this.from = from;this.to = to;}}
图的宽度优先遍历BFS
图的宽度优先遍历就是从一个节点开始,逐步遍历这个节点的所有邻接节点,然后再去遍历这些邻接节点的邻接节点
//从node节点开始进行宽度优先遍历public void bfs(Node node) {if (node == null) {return ;}Queue<Node> queue = new LinkedList<>();//确保不会重复遍历Set<Node> set = new HashSet<>();queue.offer(node);set.add(node);while (!queue.isEmpty()) {Node current = queue.poll();System.out.println(current.val);//加入这个节点的邻接节点for (Node node1 : current.nexts) {if (!set.contains(node1)) {queue.offer(node1);set.add(node1);}}}}
图的深度优先遍历
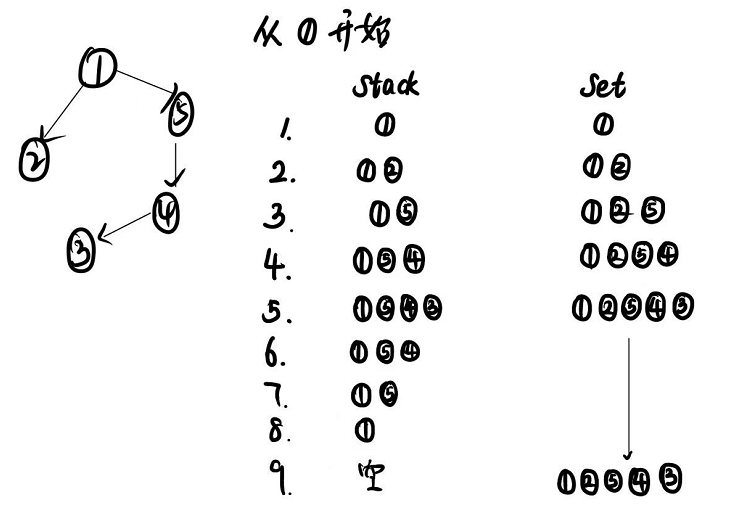
public void dfs(Node node) {//用来进行dfs的栈Stack<Node> stack = new Stack<>();Set<Node> set = new HashSet<>();stack.push(node);set.add(node);System.out.println(node.value);while (!stack.isEmpty()) {//得到当前stack的栈顶元素Node current = stack.pop();for (Node next : current.nexts) {if (!set.contains(next)) {//有了邻接节点之后就要从这个邻接节点开始遍历了//但是还需要将当前的current节点入栈,防止next无法继续遍历了//就回来继续从current遍历stack.push(current);stack.push(next);set.add(next);System.out.println(next.value);//有邻接节点了,就不用继续遍历current了,直接breakbreak;}}}}
拓扑排序
与拓扑排序相关的问题是:假设有许多任务,一些任务有着前置任务,只有完成了前置任务才能完成当前任务,如何得到最终处理任务的顺序?
拓扑排序的思路是:先从入度为0的节点开始执行, 执行了之后更新其他节点的入度,然后重复执行这个过程。 
public void topological(Graph graph) {//存储所有节点的入度Map<Node,Integer> map = new HashMap<Node,Integer>();//存储0入度节点Queue<Node> zeroInQueue = new LinkedList<>();for (Integer integer : graph.nodes.keySet()) {map.put(graph.nodes.get(integer),graph.nodes.get(integer).in);if (graph.nodes.get(integer).in == 0) {zeroInQueue.offer(graph.nodes.get(integer));}}//不断访问入度为0的节点并更新其他节点入度while (!zeroInQueue.isEmpty()) {Node node = zeroInQueue.poll();System.out.println(node.value);for (Node next : node.nexts) {map.put(next,map.get(next)-1);if (map.get(next) == 0) {zeroInQueue.offer(next);}}}}
最小生成树算法
最小生成树就是在整个图联通的基础上,能到达最小边权重和的图结构,最小生成树的算法使用到了贪心思想。
克鲁斯卡尔算法
以边作为贪心算法核心,每次观察当前最小边两侧的节点集合是否是同一个集合,如果是一个节点集合说明产生了环路,这条边不能用,就去找下一条最小边。
克鲁斯卡尔算法的重点在于定义集合结构用来表示节点集。
class MeSets {//一开始应该给每个点都分配一个集合,这个集合中只有一个点public HashMap<Node,Set<Node>> setMap;public MySets(List<Node> nodes) {//初始化节点集合for (Node node : nodes) {setMap.put(node,new HashSet<>());//把自己加入到自己的集合中setMap.get(node).add(node);}}//判断两个节点所属的集合是否是一个集合public boolean isSameSet(Node from,Node to) {Set<Node> fromSet = setMap.get(from);Set<Node> toSet = setMap.get(to);return fromSet == toSet;}//合并两个节点集合public void union(Node from,Node to) {Set<Node> fromSet = setMap.get(from);Set<Node> toSet = setMap.get(to);//把toSet中的所有节点加入到fromSet,并更新setMapfor (Node node : toSet) {fromSet.add(node);setMap.put(node,fromSet);}}}
public static Set<Edge> kruskal(Graph graph) {//结果集合Set<Edge> result = new HashSet<>();//初始化集合结构MySets mySets = new MySets(new ArrayList<>(graph.nodes.values()));//建立边的小顶堆来存储最小的边PriorityQueue<Edge> queue = new PriorityQueue<>(new Comparator<Edge>(){@Overridepublic int compare(Edge o1,Edge o2) {return o1.weight - o2.weight;}});//把图中所有的节点加入到queuefor (Edge edge : graph.edges) {queue.offer(edge);}while (!queue.isEmpty()) {//得到当前最小的边Edge edge = queue.poll();//如果这条边的to和from不是一个集合就合并if (!mySets.isSameSet(edge.from,edge.to)) {result.add(edge);mySets.union(edge.from,edge.to);}}return result;}
普里姆算法Prim
普里姆算法是以节点为贪心核心的最小生成树算法:定义一个节点集合,从某个节点开始,找到距离这个节点最近的非集合内节点,将节点加入集合,重复过程。 
//返回List<Set<Edge>> 是为了应对可能出现的不同森林状况,即图内可能有多个连通图
public List<Set<Edge>> prim(Graph graph) {
//Set结合,来避免节点重复计算
Set<Node> set = new HashSet<>();
//结果集
List<Set<Edge>> result = new ArrayList<>();
//这一层循环是森林层面的
for (Node node : graph.nodes.values()) {
Set<Edge> edgeSet = new HashSet<>();
//如果这个节点还没有被遍历过,就进入(一个新的森林)
if (!set.contains(node)) {
set.add(node);
//小顶堆,存储当前最小的边
PriorityQueue<Edge> queue = new PriorityQueue<>(new Comparator<Edge>(){
@Override
public int compare(Edge o1,Edge o2) {
return o1.weight - o2.weight;
}
});
//把当前节点所有的邻接边加入队列
for (Edge edge : node.edges) {
queue.offer(edge);
}
while (!queue.isEmpty()) {
//当前最小的边
Edge edge = queue.poll();
Node to = edge.to;
//如果通向新的节点
if (!set.contains(to)) {
edgeSet.add(edge);
set.add(to);
//加入新节点的邻接边
for (Edge edge : to.edges) {
queue.offer(edge);
}
}
}
}
list.add(edgeSet);
}
return list;
}
单源最短路径问题
单源最短路径问题 :求某个节点到达图中其他所有节点的最短距离。
迪杰斯特拉算法
迪杰斯特拉算法用到了动态规划算法,每次找到一个新的点的时候,就更新整个**distanceMap**的距离 ,看看利用这个点作为中转,到达其他点的距离能否进一步缩小,当图中所有的节点都被遍历过之后,整个图的单源最短路径就求出来了。 
//计算node到其他节点的最短距离
public Map<Node,Integer> dijkstra(Node node) {
//记录节点node到其他节点距离
Map<Node,Integer> distanceMap = new HashMap<>();
//自己到自己的距离是0
distanceMap.put(node,0);
//已经被遍历过的节点
HashSet<Node> selectedNodes = new HashSet<>();
//找到不在selectedNodes中并且距离当前节点最近的节点
Node minNode = getMinDistanceNodeAndNotSelected(distanceMap,selectedNodes);
while (minNode != null) {
//当前的距离
int currentDistance = distanceMap.get(minNode);
//通过距离来更新整个图的distance
Set<Edge> edges = minNode.edges;
for (Edge edge : edges) {
Node to = edge.to;
//找到了一个新的节点(之前不连通,距离为+oo)
if (!distanceMap.containsKey(to)) {
distanceMap.put(to,currentDistance+edge.weight);
}
//如果通过这个点计算,有的点有了更短的距离,就更新
distanceMap.put(to,Math.min(currentDistance+edge.weight,distanceMap.get(to)));
}
selectedNodes.add(minNode);
//继续寻找下一个节点
minNode = getMinDistanceNodeAndNotSelected(distanceMap,selectedNodes);
}
return distanceMap;
}
//找到不在selectedSet中并且距离当前节点最近的节点
public Node getMinDistanceNodeAndNotSelected(Map<Node,Integer> distanceMap,Set selectedSet) {
Node ans = null;
int min = Integer.MAX_VALUE;
Set<Node> keySet = distanceMap.keySet();
for (Node node : keySet) {
if (!selectedSet.contains(node) && distanceMap.get(node) < min) {
min = distanceMap.get(node);
ans = node;
}
}
return node;
}

若有收获,就点个赞吧
0 人点赞
