MLflow跟踪组件是一个API和UI,用于在运行机器学习代码时记录参数、代码版本、指标和输出文件,并在以后可视化结果。MLflow跟踪允许您使用Python、REST、R API和Java API。
概念
MLflow跟踪是围绕运行的概念组织的,运行是一些数据科学代码的执行。每次运行记录如下信息:
Code Version
运行时使用的Git提交散列(如果是从MLflow项目运行的话)。
Start & End Time
运行的开始和结束时间
Source
启动运行的文件名称,或者从MLflow项目运行时运行的项目名称和入口点。
Parameters
键值输入参数的选择。键和值都是字符串。
Metrics
键值度量,其中值为数字。在整个运行过程中,可以更新每个指标(例如,跟踪您的模型的损失函数是如何收敛的),MLflow记录并允许您可视化指标的完整历史。
Artifacts
输出文件的任何格式。例如,您可以将图像(例如,png)、模型(例如,一个pickle的scikit-learn模型)和数据文件(例如,一个Parquet文件)记录为工件。
- 您可以在任何运行代码的地方使用MLflow Python、R、Java和REST api记录运行情况。例如,您可以在一个独立的程序中、远程云机上或交互式笔记本中记录它们。如果记录在MLflow项目中的运行,MLflow会记住项目URI和源版本。
- 您可以选择将运行组织为实验,这些实验将特定任务的运行组合在一起。您可以使用mlflow实验CLI、使用mlflow.create_experiment()或使用相应的REST参数创建实验。MLflow API和UI允许您创建和搜索实验。
一旦记录了运行,就可以使用跟踪UI或MLflow API查询它们。
记录运行的地方
MLflow运行可以记录到本地文件、SQLAlchemy兼容数据库或远程跟踪服务器上。默认情况下,MLflow Python API记录本地运行到mlruns目录中的文件,无论您在哪里运行程序。然后可以运行mlflow ui来查看记录的运行情况。
要记录远程运行的日志,将MLFLOW_TRACKING_URI环境变量设置为跟踪服务器的URI或调用mlflow.set_tracking_uri()。
有不同种类的远程跟踪uri:本地文件路径(指定为file:/my/ Local /dir),数据直接存储在本地。
- 数据库编码为
+ :// : @ : / 。MLflow支持“mysql”、“mssql”、“sqlite”和“postgresql”方言。有关详细信息,请参阅SQLAlchemy数据库uri。 - HTTP服务器(指定为https://my-server:5000),它是托管MLflow跟踪服务器的服务器。
Databricks工作区(指定为Databricks或Databricks://
, Databricks CLI配置文件。请参阅从外部Databricks [AWS] [Azure]访问MLflow跟踪服务器,或快速入门,以方便在Databricks Community Edition上使用托管的MLflow。 记录数据到运行
您可以使用MLflow Python、R、Java或REST API将数据记录到运行。本节展示了Python API。
日志记录功能
mlflow.set_tracking_uri()连接到一个跟踪URI。您还可以设置MLFLOW_TRACKING_URI环境变量,让MLflow从中查找URI。在这两种情况下,URI可以是远程服务器的HTTP/HTTPS URI、数据库连接字符串或将数据记录到目录的本地路径。URI默认为mlruns。
- get_tracking_uri()返回当前的跟踪URI。
- mlflow.create_experiment()创建一个新的实验并返回它的ID。通过将实验ID传递给mlflow.start_run,可以在实验下启动运行。
- mlflow.set_experiment()设置一个实验为活动的。如果实验不存在,创建一个新的实验。如果您没有在mlflow.start_run()中指定一个实验,新的运行将在这个实验下启动。
- mlflow.start_run()返回当前活动的运行(如果存在的话),或者启动一个新的运行并返回一个mlflow。ActiveRun对象可用作当前运行的上下文管理器。您不需要显式地调用start_run:在没有活动运行的情况下调用一个日志记录函数会自动启动一个新的日志记录函数。
- mlflow.end_run()以可选的运行状态结束当前活动的运行(如果有的话)。
mlflow.active_run()返回一个mlflow.entities.Run。对象对应于当前活动的运行(如果有)。注意:您不能通过mlflow.active_run返回的运行访问当前活动的运行属性(参数、指标等)。为了访问这些属性,请使用mlflow.tracking.MlflowClient如下:
client = mlflow.tracking.MlflowClient()data = client.get_run(mlflow.active_run().info.run_id).data
mlflow.log_param()记录当前活动运行中的单个key-value参数。键和值都是字符串。使用mlflow.log_params()一次记录多个参数。
- mlflow.log_metric()记录单个key-value度量。该值必须总是一个数字。MLflow记住每个度量值的历史。使用mlflow.log_metrics()一次记录多个指标。
- set_tag()在当前活动的运行中设置单个key-value标记。键和值都是字符串。使用mlflow.set_tags()一次设置多个标签。
- mlflow.log_artifact()将本地文件或目录作为工件记录,可以选择使用artifact_path将其放置在运行的工件URI中。可以将运行工件组织到目录中,这样您就可以以这种方式将工件放置在目录中。
- mlflow.log_artifacts()将给定目录中的所有文件作为工件记录,同样采用可选的artifact_path。
get_artifact_uri()返回当前运行的工件应该记录到的URI。
在一个程序中启动多次运行
有时,您希望在同一个程序中启动多个MLflow运行:例如,可能正在本地执行超参数搜索,或者您的实验运行得非常快。这很容易做到,因为mlflow.start_run()返回的ActiveRun对象是一个Python上下文管理器。你可以将每次运行的“scope”限定为一个代码块,如下所示:
with mlflow.start_run():mlflow.log_param("x", 1)mlflow.log_metric("y", 2)...
运行在整个with语句中保持打开状态,并在语句退出时自动关闭,即使语句因异常退出。
使用指标进行性能跟踪
您可以在跟踪API中使用日志方法记录MLflow指标。日志方法支持两种不同的方法来区分x轴上的度量值:时间戳和步骤。
timestamp是一个可选的长值,表示记录度量值的时间。timestamp默认为当前时间。step是一个可选的整数,表示训练进度的任何度量(训练迭代的次数、纪元的数量,等等)。step默认为0,并具有以下要求和属性:必须是有效的64位整数值。
- 可以是负的。
- 在连续的写调用中可能会打乱顺序。例如,(1,3,2)是一个有效的序列。
- 在连续的写调用中指定的值序列中可能有“空白”。例如,(1,5,75,-20)是一个有效的序列。
如果您同时指定了时间戳和步骤,那么指标将分别针对这两个轴进行记录。
范例
Python
with mlflow.start_run():for epoch in range(0, 3):mlflow.log_metric(key="quality", value=2*epoch, step=epoch)
Java and Scala
MlflowClient client = new MlflowClient();RunInfo run = client.createRun();for (int epoch = 0; epoch < 3; epoch ++) {client.logMetric(run.getRunId(), "quality", 2 * epoch, System.currentTimeMillis(), epoch);}
可视化指标
以下是快速入门教程的一个示例图,带有步骤x轴和两个时间戳轴:
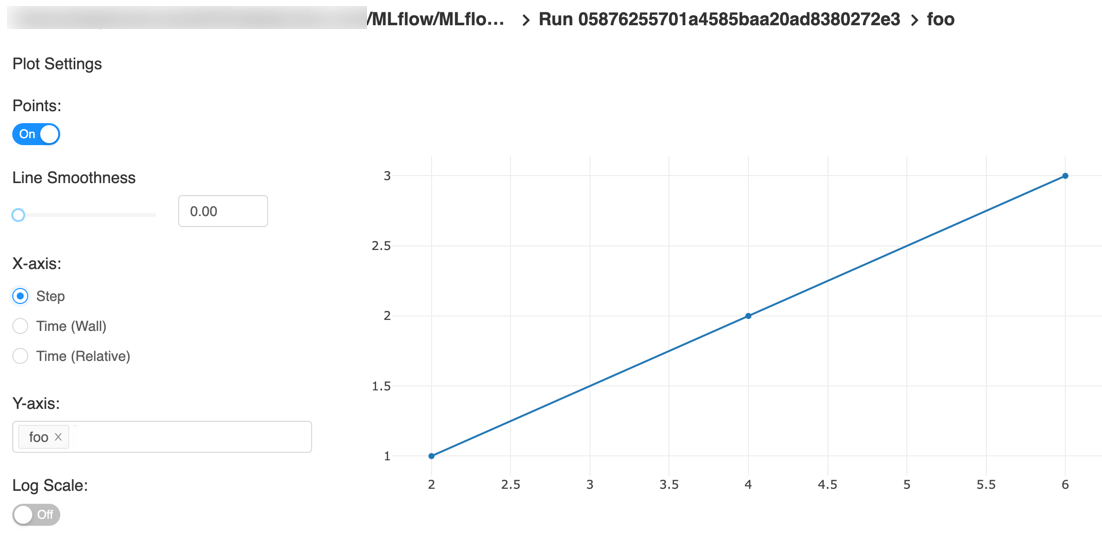
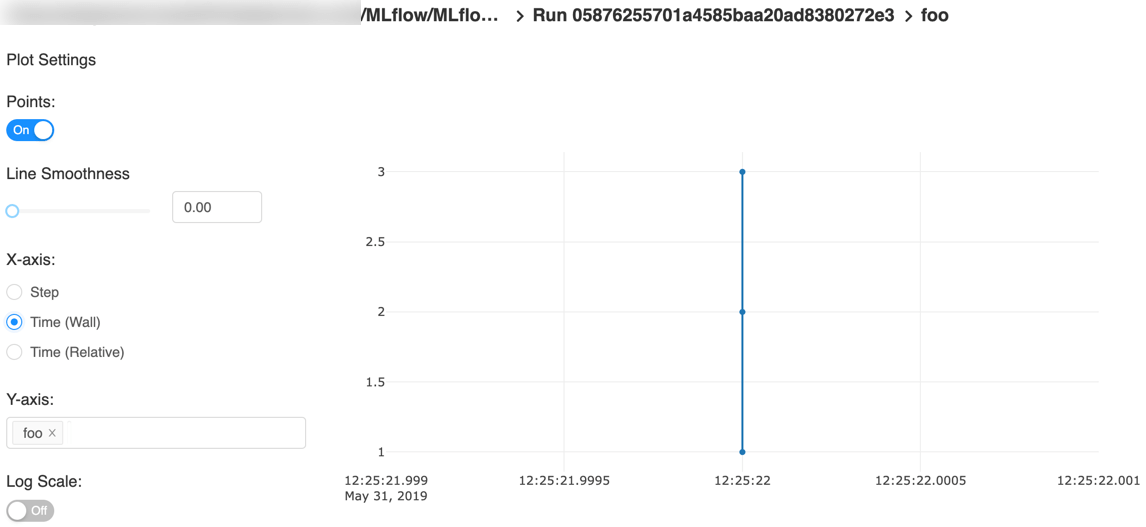
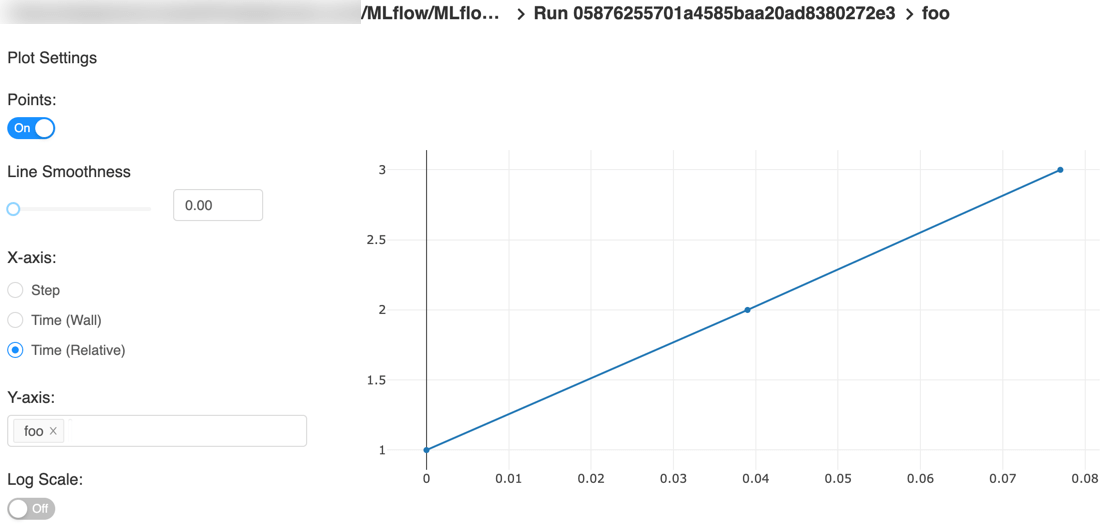
x轴相对时间——对于每次运行,相对于第一个度量记录的时间的图表
自动记录
自动日志记录允许您记录度量、参数和模型,而不需要显式的日志语句。
使用自动记录有两种方法:
- 在您的训练代码之前调用mlflow.autolog()。这将在您导入所安装的每个受支持的库时启用自动记录功能。
- 对代码中使用的每个库使用特定于库的autolog调用。请看下面的例子。
Scikit-learn(实验)
在您的训练代码之前,调用mlflow.sklearn.autolog()来启用对sklearn指标、参数和模型的自动日志记录。请在这里查看示例用法。
对评估者(如线性回归)和元评估者(如流水线)的自记录创建单个运行和日志:
| Metrics | Parameters | Tags | Artifacts |
|---|---|---|---|
Training score obtained by estimator.score |
Parameters obtained by estimator.get_params |
- Class name |
Fully qualified class name
| Fitted estimator |
参数搜索估计器(例如GridSearchCV)的自动记录创建一个父运行和嵌套的子运行
- Parent run- Child run 1- Child run 2- ...
载有下列数据:
| Run type | Metrics | Parameters | Tags | Artifacts |
|---|---|---|---|---|
| Parent | Training score | - Parameter search estimator’s parameters |
Best parameter combination
|
- Class nameFully qualified class name
|
- Fitted parameter search estimatorFitted best estimator
Search results csv file
| | Child | CV test score for each parameter combination | Each parameter combination |
- Class nameFully qualified class name
| – |
这个特性是实验性的——记录数据的API和格式可能会发生变化=
TensorFlow and Keras (实验)
在您的训练代码之前,调用mlflow.tensorflow.autolog()或mlflow.keras.autolog()来启用度量和参数的自动日志记录。参见Keras和TensorFlow的用法示例。
注意tf.keras的自动记录由mlflow.tensorflow.autolog()处理,而不是mlflow.keras.autolog()。是否使用TensorFlow1.x或2.x,与tf.estimator和earlystop相关的相应指标会自动记录。作为示例,尝试运行MLflow TensorFlow示例。
automologging捕获如下信息:
| Framework/module | Metrics | Parameters | Tags | Artifacts |
|---|---|---|---|---|
keras |
Training loss; validation loss; user-specified metrics. Metrics from the EarlyStopping callbacks. For example, stopped_epoch, restored_epoch, restore_best_weight, etc. |
fit() or fit_generator() parameters; optimizer name; learning rate; epsilon.Parameters associated with EarlyStopping. For example, min_delta, patience, baseline, restore_best_weights, etc |
– | Model summary on training start; MLflow Model (Keras model) on training end |
tf.keras |
Training loss; validation loss; user-specified metrics | fit() or fit_generator() parameters; optimizer name; learning rate; epsilon |
– | Model summary on training start; MLflow Model (Keras model); TensorBoard logs on training end |
tf.keras.callbacks.EarlyStopping |
Metrics from the EarlyStopping callbacks. For example, stopped_epoch, restored_epoch, restore_best_weight, etc |
fit() or fit_generator() parameters from EarlyStopping. For example, min_delta, patience, baseline, restore_best_weights, etc |
– | – |
tf.estimator |
TensorBoard metrics. For example, average_loss, loss etc. |
steps, max_steps |
– | MLflow Model (TF saved model) on call to tf.estimator.export_saved_model |
| TensorFlow Core | All tf.summary.scalar calls |
– | – | – |
如果在autolog()捕获数据时不存在活动运行,MLflow将自动创建一个运行来记录信息。此外,一旦训练结束,MLflow将通过调用tf.estimator.train()、tf.keras.fit()、tf.keras.fit_generator()、keras.fit()或keras.fit_generator()自动结束运行,或者tf.estimator模型通过tf.estimator.export_saved_model()导出。
如果在autolog()捕获数据时已经存在一个运行,那么MLflow将记录到该运行,但不会在训练后自动结束该运行。
- 在使用keras.Model.fit_generator()时,用户未显式传递的参数(使用默认值的参数)目前不会自动记录日志。
- 这个特性是实验性的——记录数据的API和格式可能会发生变化。
Spark(实验)
使用附加的mlflow-spark JAR初始化SparkSession(例如SparkSession.builder.config(“spark. JAR . spark. JAR “)。然后调用mlflow.spark.autolog()来在读取时自动记录Spark数据源信息,而不需要显式的日志语句。注意,目前还不支持Spark ML (MLlib)模型的自动记录。
automologging捕获如下信息:
| Framework | Metrics | Parameters | Tags | Artifacts |
|---|---|---|---|---|
| Spark | – | – | Single tag containing source path, version, format. The tag contains one line per datasource | – |
- 这个特性是实验性的——记录数据的API和格式可能会发生变化。
- 此外,Spark数据源自动记录是异步发生的——因此,在启动短暂的MLflow运行时,可能会看到导致数据源信息未被记录的竞争条件(尽管不太可能)。
Ptorch(实验)
在您的Pytorch Lightning训练代码之前,调用mlflow.pytorch.autolog()来启用度量、参数和模型的自动日志记录。请在这里查看示例用法。注意,目前,Pytorch automologging只支持使用Pytorch Lightning训练的模型。
自动记录在调用pytorch_lightning.trainer.Trainer时被触发。适合并捕捉以下信息:
| Framework/module | Metrics | Parameters | Tags | Artifacts |
|---|---|---|---|---|
pytorch_lightning.trainer.Trainer |
Training loss; validation loss; average_test_accuracy; user-defined-metrics. | fit() parameters; optimizer name; learning rate; epsilon. |
– | Model summary on training start, MLflow Model (Pytorch model) on training end; |
pytorch_lightning.callbacks.earlystopping |
Training loss; validation loss; average_test_accuracy; user-defined-metrics. Metrics from the EarlyStopping callbacks. For example, stopped_epoch, restored_epoch, restore_best_weight, etc. |
fit() parameters; optimizer name; learning rate; epsilon Parameters from the EarlyStopping callbacks. For example, min_delta, patience, baseline,restore_best_weights, etc |
– | Model summary on training start; MLflow Model (Pytorch model) on training end; Best Pytorch model checkpoint, if training stops due to early stopping callback. |
如果在autolog()捕获数据时不存在活动运行,MLflow将自动创建一个运行来记录信息,并在调用pytorch_lightn.com .trainer. trainer. fit()完成后结束运行。
如果在autolog()捕获数据时已经存在一个运行,那么MLflow将记录到该运行,但不会在训练后自动结束该运行。
- 当使用pytorch_lightn.com .trainer. trainer. fit()时,用户没有显式传递的参数(使用默认值的参数)目前不会自动记录
- 对于多优化器场景(如使用自动编码器),只记录第一个优化器的参数
- 这个特性是实验性的——记录数据的API和格式可能会发生变化
其它机器学习模型的自动记录,请参考MLflow Tracking的Automatic Logging部分**
组模式实验运行
MLflow允许您在实验中对运行进行分组,这对于比较用于处理特定任务的运行非常有用。您可以使用命令行界面(mlflow experiments)或mlflow.create_experiment() Python API创建实验。您可以使用CLI为单个运行传递实验名称(例如,mlflow run…—experimental-name [name])或环境变量MLFLOW_EXPERIMENT_NAME。或者,您可以使用实验ID,通过——experimental-ID CLI标志或MLFLOW_EXPERIMENT_ID环境变量。
# Set the experiment via environment variablesexport MLFLOW_EXPERIMENT_NAME=fraud-detectionmlflow experiments create --experiment-name fraud-detection
# Launch a run. The experiment is inferred from the MLFLOW_EXPERIMENT_NAME environment# variable, or from the --experiment-name parameter passed to the MLflow CLI (the latter# taking precedence)with mlflow.start_run():mlflow.log_param("a", 1)mlflow.log_metric("b", 2)
管理实验并使用跟踪服务API运行
MLflow提供了一个更详细的跟踪服务API来管理实验并直接运行,它可以通过MLflow中的客户端SDK获得。跟踪模块。这使得查询关于过去运行的数据、记录关于它们的附加信息、创建实验、向运行添加标签等等成为可能。
例子:
client = MlflowClient()experiments = client.list_experiments() # returns a list of mlflow.entities.Experimentrun = client.create_run(experiments[0].experiment_id) # returns mlflow.entities.Runclient.log_param(run.info.run_id, "hello", "world")client.set_terminated(run.info.run_id)
为运行添加标记
mlflow.tracking.MlflowClient.set_tag()函数允许您为运行添加自定义标记。一个标记一次只能有一个唯一的值映射到它。例如:
client.set_tag(run.info.run_id, "tag_key", "tag_value")
不要为标记使用前缀mlflow。这个前缀保留给MLflow使用。
Tracking UI
Tracking UI允许您可视化、搜索和比较运行,以及下载运行工件或元数据,以便在其他工具中进行分析。如果将运行记录到本地mlruns目录,则在上面的目录中运行mlflow ui,它将加载相应的运行。或者,MLflow跟踪服务器提供相同的UI并支持远程存储运行工件。在这种情况下,您可以在浏览器中使用URL http://MLflow跟踪服务器:5000的ip地址,从任何机器(包括任何可以连接到您的跟踪服务器的远程机器)查看UI。
UI包含以下关键特性:
- 基于实验的运行列表和比较
- 根据参数或度量值搜索运行
- 可视化运行指标
-
编程的方式查询运行
您可以以编程方式访问跟踪UI中的所有函数。这使得做一些常见的任务很容易:
查询和比较运行使用您选择的任何数据分析工具,例如,pandas。
- 确定运行的构件URI,以便在执行工作流时将其部分构件提供给新的运行。有关查询运行和构造多步骤工作流的示例,请参见MLflow多步骤工作流示例项目。
- 以MLflow模型的形式加载过去运行的工件。有关训练、导出和加载模型以及使用模型进行预测的示例,请参见MLflow TensorFlow示例。
- 运行自动参数搜索算法,您可以从不同的运行中查询度量,以提交新的度量。有关运行自动参数搜索算法的示例,请参见MLflow超参数调优示例项目。
MLflow跟踪服务器
您可以使用MLflow服务运行MLflow跟踪服务。服务的配置示例如下:mlflow server \--backend-store-uri /mnt/persistent-disk \--default-artifact-root s3://my-mlflow-bucket/ \--host 0.0.0.0
存储
MLflow跟踪服务有两个用于存储的组件:后端存储和工件存储。后端存储
后端存储是MLflow Tracking Server存储实验和运行元数据以及参数、度量和运行标记的地方。MLflow支持两种后端存储:文件存储和数据库支持的存储。为了使用模型注册功能,您必须使用数据库支持的存储来运行服务。
使用—back-end-store-uri配置后端存储的类型。你指定:
- 文件存储后端为./path_to_store或file:/path_to_store
- 作为SQLAlchemy database URI的支持存储。数据库URI通常采用
+ :// : @ : / 。MLflow支持mysql、mssql、sqlite、postgresql等数据库方言。驱动程序是可选的。如果没有指定驱动程序,SQLAlchemy将使用方言的默认驱动程序。例如,—back-end-store-uri sqlite:///mlflow.db将使用本地sqlite数据库。
mlflow server将对数据库支持的存储和过期的数据库模式失败。要防止这种情况发生,请使用mlflow db upgrade [db_uri]将数据库模式升级到最新受支持的版本。模式迁移可能会导致数据库停机,在较大的数据库上可能需要更长的时间,并且不能保证是事务性的。在运行mlflow db升级之前,您应该始终对数据库进行备份——请参阅数据库文档,了解备份的说明。
默认情况下—back-end-store-uri设置为本地 ./mlruns目录(与在本地运行mlflow run时相同),但在运行服务器时,请确保它指向一个持久的(也就是非短暂的)文件系统位置。
产品存储
产品存储是一个适合于大数据的位置(例如S3 bucket或共享的NFS文件系统),客户端记录产品输出(例如模型)的位置。artifact_location是记录在mlflow.entities.Experiment上的属性。为默认位置进行实验,以存储该实验中所有运行的工件。另外,artifact_uri是mlflow.entities.RunInfo上的一个属性。指示此运行的所有工件存储的位置。
MLflow除了支持本地文件路径外,还支持以下存储系统作为工件存储:Amazon S3、Azure Blob存储、谷歌云存储、SFTP服务器和NFS。
使用—default-artifact-root(默认为本地 ./mlruns目录)来配置默认位置到服务器的工件存储。这将被用作新创建的实验的工件位置,这些实验没有指定工件位置。一旦您创建了一个实验,—default-artifact-root就不再与该实验相关了。
为了允许服务器和客户端访问工件位置,您应该像往常一样配置您的云提供者凭据。例如S3,可以设置环境变量AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY,使用IAM角色,或者在~/.aws/credentials中配置默认配置文件。更多信息请参见设置AWS证书和区域开发。
如果在创建实验时没有指定—default-artifact-root或工件URI(例如,mlflow experiments create —artifact-location s3://
),工件根是文件存储中的路径。通常,这不是一个合适的位置,因为客户机和服务器可能引用不同的物理位置(即不同磁盘上的相同路径)。
FTP服务器
要在FTP服务器中存储工件,请指定格式为ftp://user@host/path/To/directory的URI。URI可以有选择地包含登录到服务器的密码,例如ftp://user:pass@host/path/to/director
SFTP服务器
要在SFTP服务器中存储工件,请指定一个形式为SFTP://user@host/path/ To /directory的URI。您应该将客户端配置为能够通过SSH无需密码登录SFTP服务器(例如,公钥,ssh_config中的身份文件等)。
支持的登录格式为sftp://user:pass@host/。但是,出于安全原因,不建议这样做。
使用此存储时,必须在服务器和客户端同时安装pysftp。运行pip install pysftp安装所需的软件包。
NFS
要在NFS挂载中存储构件,请将URI指定为普通文件系统路径,例如/mnt/ NFS。此路径在服务器和客户端上必须是相同的-您可能需要使用符号链接或重新装入客户端来强制执行此属性。
HDFS
要在HDFS中存储工件,请指定hdfs: URI。可以包含host和port: hdfs://
也有两种方式认证到HDFS:
- 使用当前UNIX帐户授权
- 使用以下环境变量的Kerberos凭据:
大多数集群设置都是从HDFS本地驱动通过CLASSPATH环境变量访问的HDFS -site.xml中读取的。export MLFLOW_KERBEROS_TICKET_CACHE=/tmp/krb5cc_22222222export MLFLOW_KERBEROS_USER=user_name_to_use
使用的HDFS驱动程序为libhdfs。文件存储性能
如果已经安装了libYaml,MLflow将自动尝试使用它们。然而,如果你注意到使用文件存储后端时的任何性能问题,这可能意味着libyaml没有安装在你的系统上。在Linux或Mac上,您可以轻松地使用系统包管理器安装它: ```bashOn Ubuntu/Debian
apt-get install libyaml-cpp-dev libyaml-dev
On macOS using Homebrew
brew install yaml-cpp libyaml
安装完利比亚之后,你需要重新安装PyYAML:```bash# Reinstall PyYAMLpip --no-cache-dir install --force-reinstall -I pyyaml
删除行为
为了允许恢复MLflow运行,在删除运行时,不会自动从后端存储或工件存储中删除运行元数据和工件。mlflow gc CLI用于永久删除已删除运行的运行元数据和工件。
SQLAlchemy选项
您可以使用环境变量注入一些SQLAlchemy连接池选项。
| MLflow Environment Variable | SQLAlchemy QueuePool Option |
|---|---|
MLFLOW_SQLALCHEMYSTORE_POOL_SIZE |
pool_size |
MLFLOW_SQLALCHEMYSTORE_MAX_OVERFLOW |
max_overflow |
网络
—host选项在所有接口上公开服务。如果在生产环境中运行服务器,我们建议不要公开内置服务器(因为它是未经身份验证和加密的),而是将其放在反向代理(如NGINX或Apache httpd)后面,或者通过VPN连接。然后可以使用这些环境变量将身份验证头传递给MLflow。
此外,您应该确保—backend-store-uri(默认为./mlruns目录)指向持久(非临时)磁盘或数据库连接。
记录跟踪服务
要登录到跟踪服务器,将MLFLOW_TRACKING_URI环境变量设置为服务器的URI,以及它的方案和端口(例如,http://10.0.0.1:5000))或调用mlflow.set_tracking_uri()。
然后,mlflow.start_run()、mlflow.log_param()和mlflow.log_metric()调用向远程跟踪服务器发出API请求。
import mlflowremote_server_uri = "..." # set to your server URImlflow.set_tracking_uri(remote_server_uri)# Note: on Databricks, the experiment name passed to mlflow_set_experiment must be a# valid path in the workspacemlflow.set_experiment("/my-experiment")with mlflow.start_run():mlflow.log_param("a", 1)mlflow.log_metric("b", 2)
除了MLFLOW_TRACKING_URI环境变量外,以下环境变量允许向跟踪服务器传递HTTP身份验证:
- MLFLOW_TRACKING_USERNAME和MLFLOW_TRACKING_PASSWORD—HTTP基本身份验证使用的用户名和密码。要使用基本身份验证,必须设置两个环境变量。
- MLFLOW_TRACKING_TOKEN -与HTTP承载身份验证一起使用的token。如果设置了基本身份验证,则优先进行。
- MLFLOW_TRACKING_INSECURE_TLS—如果字面设置为true, MLflow不会验证TLS连接,这意味着它不会验证证书或https://跟踪uri的主机名。不建议在生产环境中使用此标志。如果设置为true,则不能设置MLFLOW_TRACKING_SERVER_CERT_PATH。
- MLFLOW_TRACKING_SERVER_CERT_PATH—要使用的CA bundle的路径。设置请求的验证参数。request函数(参见requests主接口)。当您使用自签名的服务器证书时,您可以使用它在客户端验证它。如果设置了,MLFLOW_TRACKING_INSECURE_TLS不能设置(false)。
- MLFLOW_TRACKING_CLIENT_CERT_PATH—ssl客户端证书文件(.pem)路径。设置请求的cert参数。request函数(参见requests主接口)。这可以用于使用(自签名)客户端证书。
客户端直接将工件推入工件存储。它不通过跟踪服务器代理这些。
出于这个原因,客户端需要直接访问工件存储。
系统标签
您可以用任意标记对运行进行注释。以mlflow开始的标记键。预留给内部使用。以下标签由MLflow自动设置,在适当的时候:
| Key | Description |
|---|---|
mlflow.runName |
Human readable name that identifies this run. |
mlflow.note.content |
A descriptive note about this run. This reserved tag is not set automatically and can be overridden by the user to include additional information about the run. The content is displayed on the run’s page under the Notes section. |
mlflow.parentRunId |
The ID of the parent run, if this is a nested run. |
mlflow.user |
Identifier of the user who created the run. |
mlflow.source.type |
Source type. Possible values: "NOTEBOOK", "JOB", "PROJECT", "LOCAL", and "UNKNOWN" |
mlflow.source.name |
Source identifier (e.g., GitHub URL, local Python filename, name of notebook) |
mlflow.source.git.commit |
Commit hash of the executed code, if in a git repository. |
mlflow.source.git.branch |
Name of the branch of the executed code, if in a git repository. |
mlflow.source.git.repoURL |
URL that the executed code was cloned from. |
mlflow.project.env |
The runtime context used by the MLflow project. Possible values: "docker" and "conda". |
mlflow.project.entryPoint |
Name of the project entry point associated with the current run, if any. |
mlflow.docker.image.name |
Name of the Docker image used to execute this run. |
mlflow.docker.image.id |
ID of the Docker image used to execute this run. |
mlflow.log-model.history |
(Experimental) Model metadata collected by log-model calls. Includes the serialized form of the MLModel model files logged to a run, although the exact format and information captured is subject to change. |

若有收获,就点个赞吧
0 人点赞
