3.3.0 远端存储
3.3.1 总体架构
面对更多历史数据的持久化,Prometheus 单纯依靠本地存储远不足以应对,为此引入了远端存储。为了适应不同的远端存储,Prometheus 并没有选择对接各种存储,而是定义了一套读写存储接口,并引入了 Adapter 适配器,将 Prometheus 的读写请求转化为第三方远端存储接口,从而完成数据读写。整体架构如图 3-7 所示。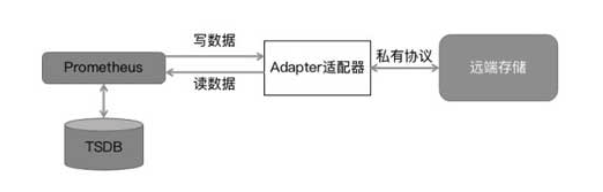
图 3-7
目前已经实现 Adapter 的远程存储主要包括 InfluxDB、OpenTSDB、CreateDB、TiKV、Cortex、M3DB 等。
3.3.2 远端接口规范
Prometheus 通过「HTTP POST 请求 + protobuf 编码」方式调用 Adapter 的读接口和写接口,未来应该会将采用效率更高的「gRPC(HTTP2)+ Protobuf 」方式。接口被定义在 remote.proto 文件中,内容如下:
在上面的 proto 文件中定义了请求参数和返回结果,其中,请求参数 Query 主要包括监控数据查询的开始时间、结束时间和匹配的标签,这里 repeated 表示可以添加多个标签的条件筛选;返回参数 QueryResult 主要包括时间序列 TimeSeries,时间序列主要包含这个序列的标签和样本数据,样本数据以「时间戳:样本值」格式传输。
每种存储的 Adapter 都通过实现读接口和写接口对接到 Prometheus,当然,Adapter 也可以只实现其中一个接口。若通过 Adapter 实现 OpenTSDB 的一个写接口,那么 Prometheus 会将数据写入 OpenTSDB 中,对监控数据的查询可以借助 OpenTSDB 原生的查询接口实现。
下面通过官方提供的一个 InfluxDB Adapter 说明 Prometheus 远端存储接口的实现(代码路径为 Prometheus/documentation/examples/remote_storage/remote_storage_Adapter)。
首先启动写请求监听:
接着,解析写请求的参数,并将其转化为指标格式:
然后,发送给 InfluxDB:
最后,通过 InfluxDB 的 HTTP 接口写入数据:
Prometheus 对远端存储的一次性写请求是通过上面的 Adapter 将请求(包括请求的参数格式和方式)转化成第三方存储的写请求。读接口与之类似,先启动读请求监听,在获取读请求的参数后转变为对 InfluxDB 的查询。虽然 InfluxDB 的查询接口基于 HTTP,但参数格式不同。下面是 InfluxDB 通过 HTTP 接口进行查询的实例,通过 HTTP 发送一条 SQL 来查询数据:
所以,Adapter 需要将 Prometheus 的读请求转化为 InfluxDB 格式的请求,通过 buildCommand 方法构建 InfluxDB 查询语句,关键代码如下:
上面的代码主要是将 Prometheus 基于标签的查询转换为 InfluxDB 能够识别的查询条件,从而完成 InfluxDB 的适配。
3.3.3 相关参数
Prometheus 是怎么知道 Adapter 地址的呢?Prometheus 在启动后会加载 Prometheus.yml 配置文件,在该配置文件中会配置 Adapter 的信息,主要包括 Adapter 的地址、超时时间、relabel 规则和请求队列配置。
下面是对远程 Adapter 写请求的配置:
如上所示主要配置了 Adapter 写请求相关的参数,主要是 Adapter 的地址和相关认证信息。除此之外,还有一个很重要的配置 queue_config(写请求队列配置),这也是 Adapter 读请求和写请求的最大差别。
下面是对读请求的配置:
下面将详细介绍写请求队列(queue)。Prometheus 对远程 Adapter 的读请求是同步的,但考虑到 Adapter 后端存储本身的性能问题,难以做到对写请求的同步,并且针对每个监控数据都执行写操作会非常消耗性能。如果能将多次写请求合并成一个请求,那么不仅可以大大减少网络传输流量,还能减少后端存储处理数据的压力。
如图 3-8 所示,在每个分片(shards)里都有一个保存样本的容器(Go 语言的切片),并且每个分片都单独启动一个协程来负责发送数据到 Adapter。在 Prometheus 初始启动后只有一个分片队列,然后每隔 10s 重新计算最优的分片个数。其中的算法是根据在上一个周期接收的数据预测本周期将接收的样本数,加上处于 pending 状态的样本数(还未发送到 Adapter 的样本),得出下一个周期需要发送的总样本数,然后除以每个分片每秒处理的样本数。当分片不足以支撑大量样本数据的转发时,会创建更多的分片来发送数据。在流量减少后,Prometheus 会相应地减少分片个数,不过会预留 30% 冗余,以防突发流量造成系统不稳定。至于监控样本应该由哪个分片负责发送,可以将样本标签 Hash 值和分片总个数求余来计算每个指标应该分配的分片。
图 3-8
在对接远端存储之前需要先对远端存储及 Adapter 进行压测,确保远端存储和 Adapter 都可以承受来自 Pormetheus 的数据写入。单个 Prometheus 每秒最多可以采集 1000 万个指标项,当前很多时序数据都无法承受如此大量的监控数据写入。如果发现在 Prometheus 中出现报错日志「Remote storage queue full,discarding sample.Multiple subsequent messages of this kind may be suppressed」,就代表 Adapter 或者远端存储无法满足数据写入,并且 Prometheus 开始丢弃部分监控数据了。
M3DB(https://github.com/m3db/m3)是一种不错的远端存储方式,不仅在时序数据存储方面有着良好的性能,而且与 Prometheus 紧密结合。感兴趣的读者可以对 M3DB 进行测试和使用。

若有收获,就点个赞吧
0 人点赞
