秒杀系统功能需求和非功能需求
功能需求:
- 电商大环境营销模式形成, 秒杀活动在 2011 年后流行起来
- 电商用户爆发式增长,竞争激励,各大电商纷纷低价促销抢夺用户
- 在大型促销活动中,老系统面临并发性能、可用性、公平性等问题的挑战。
只有了解了秒杀系统诞生的业务背景已经需要解决的问题,我们才好进行准确的需求分析。
用户端需求:
用户购买流程图:
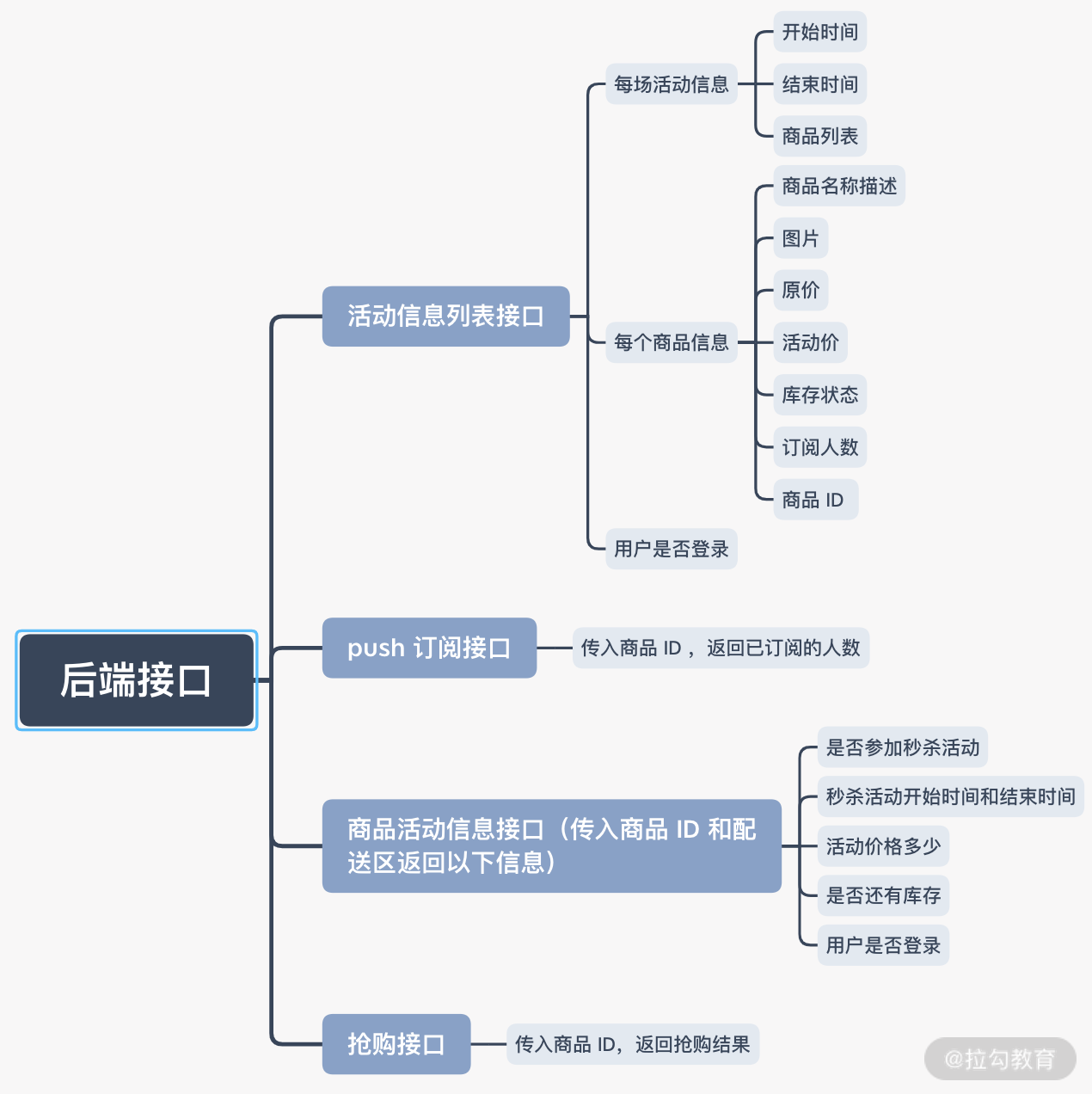
对应的后台接口:
管理后台需求:
- 活动专题管理,要是用于管理所有秒杀活动专题,包括专题列表页和专题编辑页;
- 活动场次管理功能,用于录入秒杀活动场次信息,并关联到专题上,包括场次列表页和场次编辑页;
- 商品管理功能,用于管理参与秒杀活动的商品信息,包括商品列表页和商品编辑页。
在需求分析时,为了考虑全面,我们可以站在不同的角色立场来分析,比如:用户、产品、前后端开发、测试、运营等。
非功能需求:
- 高可用。
衡量指标:
- MTBF(平均可用时长)。系统正常、稳定运行的平均时长,比如三天内系统出现了3次故障,每次持续1小时,那么平均可用时长是23小时;
- MTTR(Mean Time To Repair,平均修复时长),系统从失效后到恢复正常所耗费的平均时间,比如前面提到的每次故障持续1小时;
- SLA(Service-Level Agreement,服务等级协议),用于评估服务可用性等级,计算公式是MTBF/(MTBF+MTTR),一般我们所说的可用性高于 99.99%,是指 SLA 高于 99.99%。
- 高性能
影响性能的因素:
- 用户网络环境
- 请求/返回数据大小
- 业务系统CPU、内存、磁盘等性能
- 下游资源性能
- 算法是否高效
- 请求链路长短
- 高并发。
衡量指标:QPS(每秒查询率)
并不是指标越高越好,满足过高的指标可能会浪费很多不必要的资源。
系统架构总体设计
架构设计方法:推荐五视图方法。指从业务逻辑、开发环境、运行状态、物理部署、数据关系等方面绘制出相应的逻辑视图、开发视图、运行视图、物理视图、数据视图来设计架构。
- 逻辑视图:对应逻辑架构,主要关注功能需求,以及系统职责和行为的划分。
- 开发视图:对应开发架构,主要关注系统开发过程中的质量属性。它包括软件源码的组织方式、配置方式、编译打包方式以及与第三方包的依赖关系等。
- 运行视图:对应运行架构,主要关注软件运行过程中的质量属性,它包括进程、线程、协程、对象之间的并发、同步、通信的问题等。
- 物理视图:对应物理架构,主要关注安装和部署需求。它包括软件运行时的系统、网络、服务器等基础设施和相关配置,以及如何利用基础设施来实现应用程序的高可用、可伸缩等。
- 数据视图:对应数据架构,主要关注数据需求,它包括数据的格式、属性、关系等。
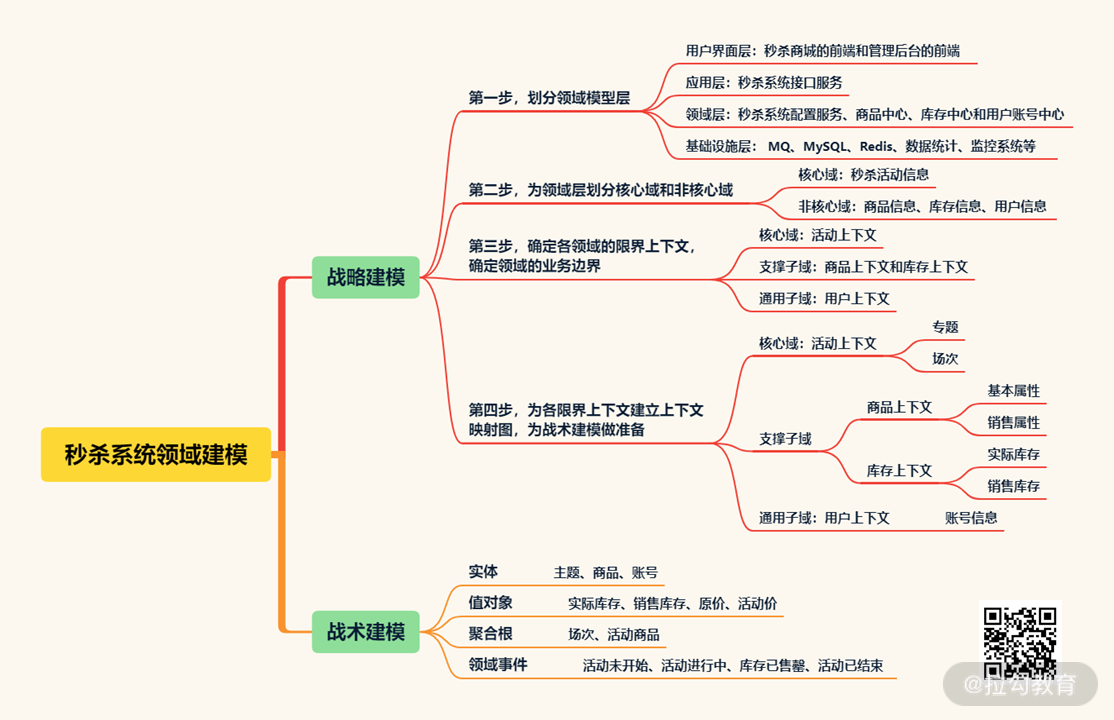
领域建模:DDD 原理及秒杀系统领域模型
高可用架构
高可用云架构
- IDC基础设施层:主要包括电源、网络、空调、消防等设备,甚至包括 IDC 机房所在的大楼的物理条件。
- 物理主机层:现在物理主机层通常采用存储和计算分离的方案来部署,这样的好处是能尽量避免因磁盘故障而导致计算能力下降,而且还能降低存储的整体成本。
- Iaas层:基础设施即服务的缩写,通过虚拟化技术在宿主机上虚拟出多个运行环境,应用部署在虚拟出来的运行环境里。目前比较常用的是主机虚拟化和容器虚拟化。
- PaaS 层 :平台即服务的缩写,云产商将通用组件打包部署在已有的主机上,并提供访问组件的 SDK 或者 API,开发者修改应用的代码引入 SDK 或者调用 API 来访问云产商提供的通用组件。比如:在阿里云上购买数据库产品,修改应用程序代码访问购买的数据库产品。PaaS 的出现主要是为了解决 IaaS 上基础组件分发的问题。
- SaaS 层:软件即服务的缩写,不仅提供软件的后端,还提供软件的前端页面,达到开箱即用的效果。SaaS 系统可以通过同城双活、异地备份、多云部署等方案来降低单云单机房故障的风险
建议:起步阶段可以考虑在Iaas云厂商的两个机房分别购买 1 台云主机组成双活来部署业务服务。如果云产商有容器云,可以优先考虑使用容器。
发展阶段业务量大,流量大,需要注重系统可用性。为了防止单一可用区出现故障,核心业务服务和秒杀系统最好部署在多个可用区,每个可用区部署多个服务器实例,并由 SLB 组件做服务器的负载均衡。
另外,在秒杀系统内部做限流的时候,也可以选用云厂商提供的 MQ (Message Queue,消息队列) 组件限制并发流量,以便减少下游系统的压力,提升整体稳定性。
成熟阶段,此时业务核心功能基本稳定,用户量初具规模。如果发生事故,很容易影响公司营收,诸如秒杀这类涉及交易流程的系统,可以做特殊处理,比如:考虑多云架构、异地多活、异地备份等措施避免更极端的故障,比如地震、洪水破坏可用区。
故障转移和恢复
发生故障时,为了保证高可用性,首先要做的是故障转移,而不是排查和修复故障。
如何故障转移?主备切换。
步骤:
- 故障自动侦测(Auto-detect),采用健康检查、心跳等技术手段自动侦测故障节点;
- 自动转移(FailOver),当侦测到故障节点后,采用摘除流量、脱离集群等方式隔离故障节点,将流量转移到正常节点;
- 自动恢复(FailBack),当故障节点恢复正常后,自动将其加入集群中,确保集群资源与故障前一致。

若有收获,就点个赞吧
0 人点赞
