转自:MySQL:简单insert 一秒原因排查
这个问题是来自一位朋友,我通过pstack最终确认问题,涉及到两个参数的设置,我将从源码进行解释,如果有误还请见谅。
一、问题展示
1、简单插入需要1秒

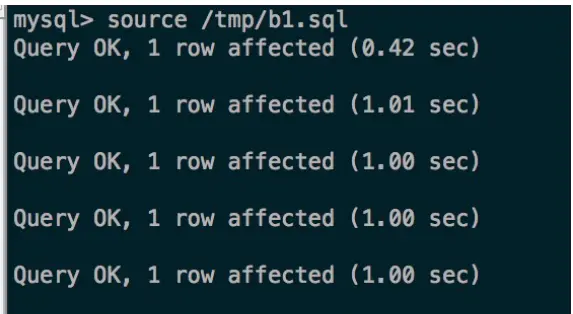
2、profile展示
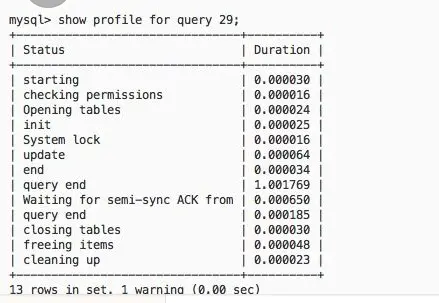
实际上这里的query end是一个非常有用的信息,基本确认是在order_commit函数上的等待。
二、问题初次分析
在我遇到的案例中有大事物造成的小事物commit慢的情况,且状态也是query end,但是这里问题显然不太一样,如果是大事物造成的会是偶尔出现commit慢的情况而这里是稳定出现等待1秒的情况。但是我还是要朋友采集了binlog的大事物信息使用我的一个工具如下:
小工具可以分析binlog 的一些信息比如:1、是否有长期未提交的事物2、是否有大事物3、每个表生成了多少日志4、生成速度。使用:./infobin mysql-bin.001793 20 2000000 10 -t >log1793.log第一个20 是分片数量第二个2000000 是大于2M左右的事物定义为大事物第三个10 是大于10秒未提交的事物定义为长期未提交的事物下载地址:http://pan.baidu.com/s/1jHIWUN0只能用于binlog 不能用于relaylog。最好将binlog拷贝其他机器执行,不要在生产服务器跑最好是5.6 5.7 row格式binlog
这个工具是我用C写的不依赖其他工具解析binlog获取有用信息的工具,也很多朋友在用。占时没有开源,其实也很简单就是分析binlog的event来获取有用信息。
得到的简化结果如下:
-------------Now begin--------------Check Mysql Version is:5.7.19-logCheck Mysql binlog format ver is:V4Warning:Check This binlog is not closed!Check This binlog total size:87546667(bytes)Note:load data infile not check!-------------Total now--------------Trx total[counts]:42771Event total[counts]:251792Max trx event size:9268(bytes) Pos:78378238[0X4ABF4FE]Avg binlog size(/sec):16745.729(bytes)[16.353(kb)]Avg binlog size(/min):1004743.688(bytes)[981.195(kb)]...--Large than 2000000(bytes) trx:(1)Trx_size:54586527(bytes)[53307.156(kb)] trx_begin_p:359790[0X57D6E] trx_end_p:54946317[0X3466A0D]Total large trx count size(kb):#53307.156(kb)....---(79)Current Table:froad_cbank_anhui.cb_sms_log::Insert:binlog size(824224(Bytes)) times(3135)Update:binlog size(2046042(Bytes)) times(3841)Delete:binlog size(0(Bytes)) times(0)Total:binlog size(2870266(Bytes)) times(6976)---(80)Current Table:test.2018products::Insert:binlog size(54586359(Bytes)) times(6647)Update:binlog size(0(Bytes)) times(0)Delete:binlog size(0(Bytes)) times(0)Total:binlog size(54586359(Bytes)) times(6647)---Total binlog dml event size:73212228(Bytes) times(65090)
实际上我们很容易看到binlog整个才80M左右确实包含一个大事物如下,大约占用了50M多
--Large than 2000000(bytes) trx:(1)Trx_size:54586527(bytes)[53307.156(kb)] trx_begin_p:359790[0X57D6E] trx_end_p:54946317[0X3466A0D]Total large trx count size(kb):#53307.156(kb)
但是大事物只会在提交的那一刻影响其他事物的提交且状态为query end参考我早期的一篇文章
http://blog.itpub.net/7728585/viewspace-2133674/
我们先排除大事物导致的的问题。那么到底是什么问题呢,有朋友说可能是半同步,但是不使用半同步的情况下也一样。且我觉得半同步的导致慢的状态应该不是query end 占时没有测试。
三、确认问题
没有办法只能使用pstack进行分析,幸运的是这个问题确实简单如下的pstack栈帧: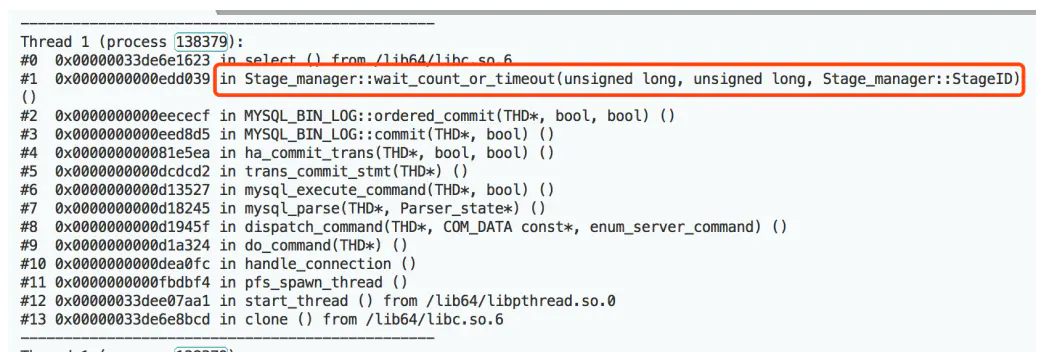
显然我的猜测没有问题确实是ordered_commit上出的问题,直接打开源码找到如下:
/* Shall introduce a delay. */stage_manager.wait_count_or_timeout(opt_binlog_group_commit_sync_no_delay_count,opt_binlog_group_commit_sync_delay,Stage_manager::SYNC_STAGE);
这段代码位于flush阶段之后 sync阶段之前,目的在于通过人为的设置delay来加大整个group commit组的事物数量,从而减少进行磁盘刷盘sync的次数。这块代码虽然以前看过但是没用过这两个参数也就直接跳过了。
四、stage_manager.wait_count_or_timeout函数分析和参数分析
这个函数还是非常简单如下逻辑 看注释即可:
void Stage_manager::wait_count_or_timeout(ulong count, ulong usec, StageID stage){ulong to_wait=DBUG_EVALUATE_IF("bgc_set_infinite_delay", LONG_MAX, usec);/*For testing purposes while waiting for inifinityto arrive, we keep checking the queue size at regular,small intervals. Otherwise, waiting 0.1 * infiniteis too long.*/ulong delta=DBUG_EVALUATE_IF("bgc_set_infinite_delay", 100000, //此处将等待时间分割 将使用max<ulong>(1, (to_wait * 0.1))); //binlog_group_commit_sync_delay*0.1 和 1之间的 大的那个值作为时间分割 (单位 1/1000000 秒)//binlog_group_commit_sync_delay是 (1000000)1秒则时间分割为0.1s(100000)while (to_wait > 0 && (count == 0 || static_cast<ulong>(m_queue[stage].get_size()) < count)) //进行主体循环退出条件为 1、binlog_group_commit_sync_delay设置的时间消耗完{ //2本组事物数量>binlog_group_commit_sync_no_delay_countmy_sleep(delta);//每次休眠delta时间如果是1秒则每次休眠0.1秒to_wait -= delta;//进行总时间-delta 时间}}
从源码我们分析一下参数binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count的含义:
- binlog_group_commit_sync_delay:通过人为的设置delay来加大整个group commit组的事物数量,从而减少进行磁盘刷盘sync的次数,但是受到binlog_group_commit_sync_no_delay_count的限制,单位1/1000000秒。最大值1000000也就是1秒
- binlog_group_commit_sync_no_delay_count:如果delay的时间内如果group commit中的事物数量达到了这个设置就直接跳出等待,而不需要等待binlog_group_commit_sync_delay的时间,单位group commit中事物的数量。
举个列子比如我binlog_group_commit_sync_delay设置为10,binlog_group_commit_sync_no_delay_count设置为10,整个group commit将在这里等待,达到2个条件中的1个将会退出等待:
- 等待达到了1/100000 秒
-
四、问题库设置
最后叫朋友查看了他们库的设置如下:
 居然binlog_group_commit_sync_delay设置为了最大值1000000也就是1秒,这也就解释了为什么简单的insert都会等待1秒了,且状态为query end。
居然binlog_group_commit_sync_delay设置为了最大值1000000也就是1秒,这也就解释了为什么简单的insert都会等待1秒了,且状态为query end。
五、总结
整个问题的排除最终还是依赖的pstack,这也再一次体现了它的重要性。栈帧是不会骗人的只有不懂的
- 要对query end代表的什么比较清楚
- 至此我知道了2种query end(或者显示commit为starting)状态下小事物提交慢的可能
1、某个大事物提交引起偶尔的提交慢
2、binlog_group_commit_sync_delay和binlog_group_commit_sync_no_delay_count 设置不正确引起提交慢

若有收获,就点个赞吧
0 人点赞
