1.数据放置
1.1 Data Block
一个大文件被切分成多个 64MB 单位的小文件,在本地文件系统以单独的文件存储。不足 64MB 的记一个文件 
1.2 机架感知
1.2.1 拓扑距离
两个节点到达最近的共同祖先的距离总和 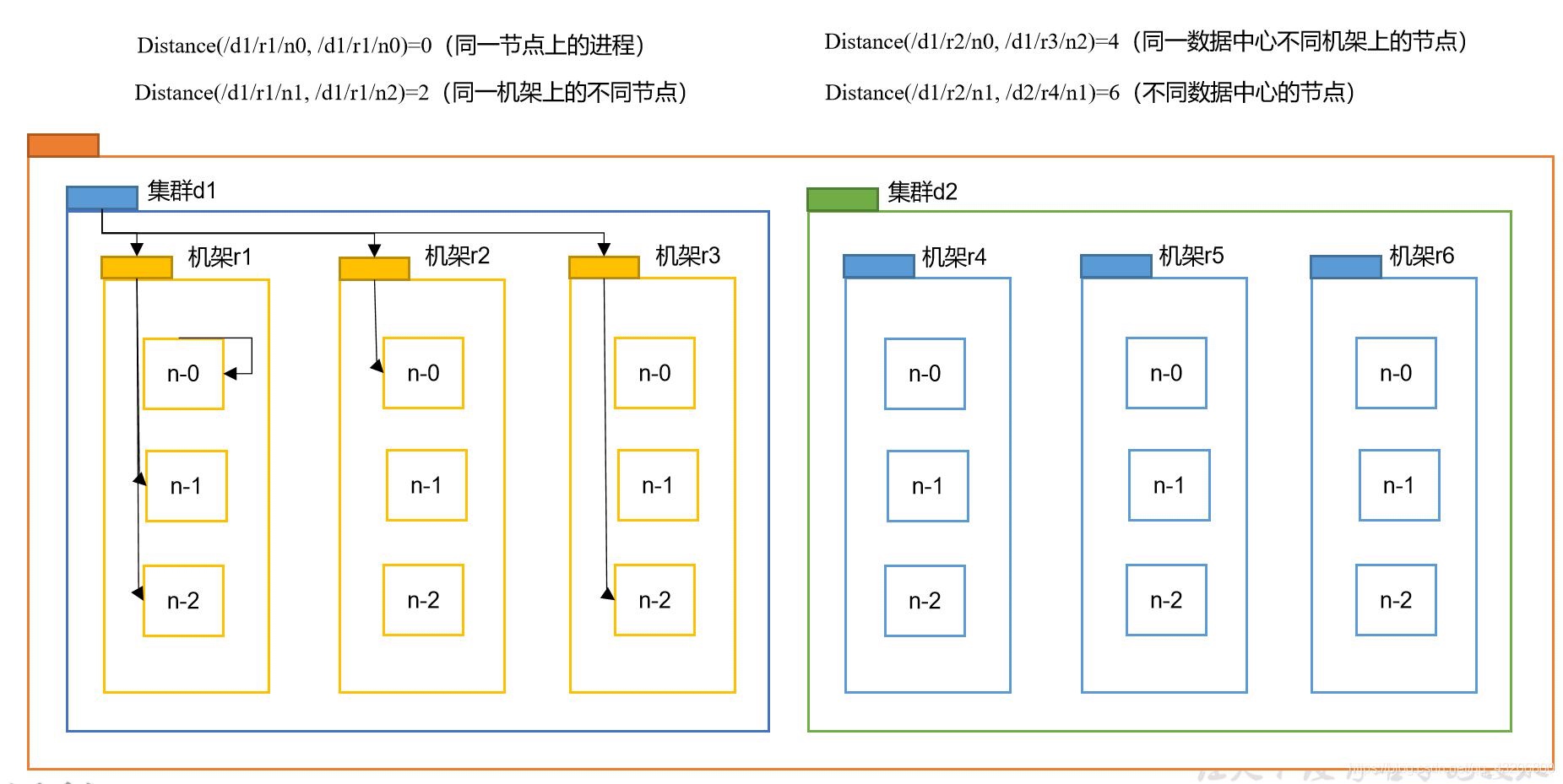
如何求解树的最近公共父节点
class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {if(root == null || root == p || root == q) return root;TreeNode left = lowestCommonAncestor(root.left, p, q);TreeNode right = lowestCommonAncestor(root.right, p, q);if(left == null) return right;if(right == null) return left;return root;}}
1.2.2 副本放置策略
- 副本 1 放置在 client 所在的节点,若 client 在集群外,随机选一个
- 副本 2 在另一个 rack 随机的一个节点
- 副本 3 在 副本 2 所在 rack 的随机一个节点
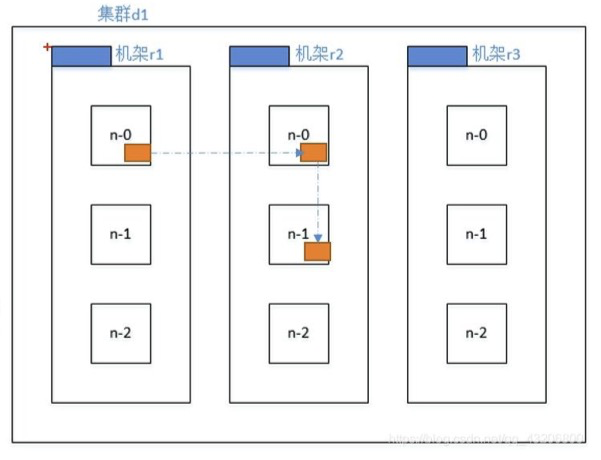
HDFS副本放置策略,为何副本3放到和副本2相同的rack里,而不是重新选择一个rack
减少文件传输的时间。副本 1 和 副本2 放不同的 rack 是为防止 rack 挂掉导致数据不可读。但跨 rack 存储会导致读写书速度变慢, 同时两个 rack 同时挂掉的几率很低。
2.HA
高可用:解决单点故障
不支持在 Docs 外粘贴 block
2.1主备一致实现
即如何保证主和备 NameNode 的状态同步
- Active NameNode 启动后提供服务, 并把Editlog写到本地和 QJM 中
- Standby NameNode 周期性的从 QJM 中拉取 Editlog,保持与 active 的状态同步
DataNode同时两个NameNode 发送 BlockReport
2.2 脑裂的解决
产生了两个 active 的 NameNode,导致集群行为不一致了
通过 fencing, 即保留竞争之后胜利的唯一结果
1、QJM的fencing
确保只有一个NN能写成功。高可用:QJM全称是Quorum Journal Manager, 由JournalNode(JN)组成,一般是奇数个结点组成。当存 活的节点数为偶数个时,无法提供正常服务。
- 基于Paxos:NameNode会同时向所有JournalNode并行写文件,只要有N/2+1个结点写成功则认为此次写操作成 功,遵循Paxos协议
- 防止双写:通过自增的 Epoch Number,要求严格有序。若 NN 发过来的 Epoch Number 比 JN 小,则拒绝接收
2、DataNode的fencing
确保只有一个NN能命令DN
- 每个 NN 改变状态的时候,向 DN 发送自己的状态和一个序列号(类似Epoch Numbers)
- DN 要求 NN 发送过来的序列号必须比本地的大,否则拒绝
3、客户端的fencing
确保只有一个NN能响应客户端请求
让访问Standby NN的客户端直接失败,并尝试连接新的 NN
2.3 透明切换
Failover时不应该导致正在连接的客户端失败,主要包括Client,Datanode与NameNode的链接
主备切换的实现:ZKFC
ZKFailoverController, 作为独立进程存在,负责控制NameNode的主备切换,ZKFC会监 测NameNode的健康状况,当发现Active NameNode出现异常时会通过Zookeeper集群进行一次主 备选举,完成Active和Standby状态的切换。
3. 故障恢复
3.1 DataNode 挂掉
- NameNode侦测DataNode 故障
- 数据块自动复制到剩余的节点以保证满足复制因子

3.2 NameNode 挂掉
通过快照恢复到之前的状态
- FsImage和EditLog
- FsImage是整个NameNode内存中元数据在某一时刻的快照(Snapshot)
- Editlog记录的是从这个快照开始到当前所有的元数据的改动
- Editlog 重放构建 FsImage
- Sencondary NameNode
- 构建 FsImage 对服务器压力很大
- 将构建 FsImage 的任务放到了 Sencondary NameNode
4.HDFS 读流程
5.HDFS 写流程
6.HDFS 元数据管理

若有收获,就点个赞吧
0 人点赞
