uuid
- uuid叫做通用唯一识别码,是按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片 ID 码和许多可能的数字。
- UUID 是由一组 32 位数的 16 进制数字所构成,是故 UUID 理论上的总数为1632=2128,约等于 3.4 x 10123。也就是说若每纳秒产生 1 百万个 UUID,要花 100 亿年才会将所有 UUID 用完。
- UUID 通常以连字号分隔的五组来显示,形式为 8-4-4-4-12,总共有 36 个字符(即 32 个英数字母和 4 个连字号)。例如: 123e4567-e89b-12d3-a456-426655440000 。
- uuid缺点:
- 太长
- 非纯数字,夹带了字母,存储到数据库里时不能存储于整形里,字符串索引的代价比较大
- 不安全。UUID 中会包含网卡的 MAC 地址。
JDK 从 1.5 开始在 java.util 包下提供了一个 UUID 类用来生成 UUID:
UUID uuid = UUID.randomUUID(); String uuidStr1 = uuid.toString(); String uuidStr2 = uuidStr1.replaceAll("-","");
雪花id
源码SnowflakeIdGenerator.java,hutools工具类也有雪花id的功能
雪花即
SnowFlake,Snowflake 是 Twitter 开源的分布式 ID 生成算法,有如下好处:- 比uuid短,纯数字,信息安全,生成的id总体趋势上是自增的
- SnowFlake 的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生 ID 碰撞(由数据中心 ID 和机器 ID 作区分),并且效率较高。
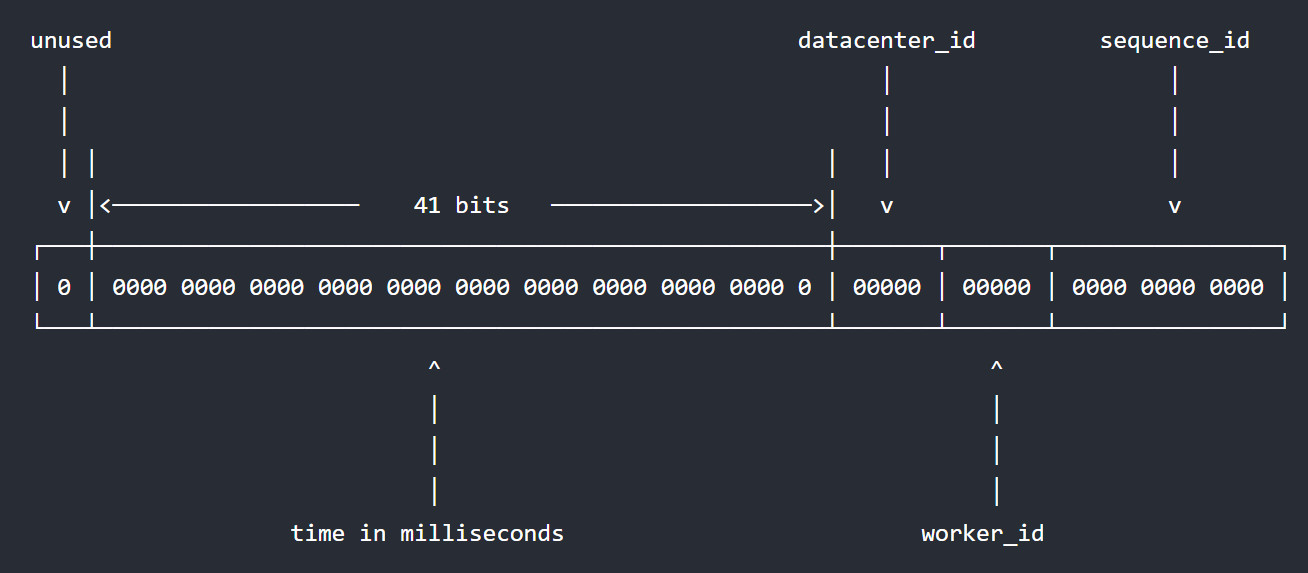
- 雪花id一共64bit,8位,刚好是long的大小,因此雪花id是long型
- 第一个bit是最高标识位,是long型的正负位,0是正,1是负
- 41位bit的是毫秒级时间戳,存储的是
**当前时间戳-id生成器开始使用时的时间**- id生成器开始使用的时间由我们程序指定,我们可以使用1969年(
(1L << 41) / (1000L * 60 * 60 * 24 * 365) ≈ 69)
- id生成器开始使用的时间由我们程序指定,我们可以使用1969年(
- 数据机器位(10bit):由 5 位的 data-center-id 和 5 位的 worker-id组成。数据中心是地点,worker-id是一个地点的一个电脑的标识,即最多支持
32*32=1024台主机的分布式系统 - 顺序号(12bit):毫秒内的计数,12 位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生 4096 个 ID 序号
-
时间回拨问题
时间回拨问题就是如果当前时间设置为过去,可能会生成重复id,解决方案有如下几种:
sonyflake 算法是索尼公司基于 snowflake 改进的一个分布式唯一 ID 生成算法。基本思路和 snowflake 一致,不过位分配上略有不同。
- 序列号只用8位,意味着单位时间内生成的数量比雪花id少很多,所以sonyflake并发量比雪花id小
1 Bit 正负 | 39 Bit 时间 | 8 Bit 序列id | 16 Bit 机器id

若有收获,就点个赞吧
0 人点赞
