集合简介
- 集合不能存储基本类型,只能存储引用数据类型(如不能存储int,可以存储Integer。String不是基本数据类型和基本类) 如果传入基本类型,会被自动装箱为基本类进行存储
- 集合就是“由若干个确定的元素所构成的整体”。集合可以方便处理一组相似的数据。
(集合显然不仅仅是 存储基本类,还可以存储其他引用数据类型,类类型…所以我们看作集合中存储了一个个实例对象,创建对象时可以从集合中获取,如
集合都使用了泛型,虽然不写明类型也能识别,但是最好写上
Map<String, Student> map = new HashMap<>();map.put("Xiao Ming", s); // 将"Xiao Ming"和Student实例映射并关联Student target = map.get("Xiao Ming");//Map返回一个实例
在Java中,如果一个Java对象可以在内部持有若干其他Java对象,并对外提供访问接口,我们把这种Java对象称为集合。很显然,Java的数组可以看作是一种集合
如一个String数组持有了多个String对象,数组对外可以取出对象或者放入对象
数组有如下限制:
- 数组初始化后大小不可变;(定长)
- 数组只能按索引顺序存取。
- 数组获取元素个数不方便,length只能获取空间总长度
- 数组可以通过下标获取元素,但是通过元素值获取下标索引不方便
因此,我们需要各种不同类型的集合类来处理不同的数据,集合主要功能有如下几点:
- 存储不确定数量的数据(可以动态改变集合长度)
- 存储具有映射关系的数据
- 存储不同类型的数据
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合:
**List**:一种有序列表的集合,例如,按索引排列的Student的List;**Set**:一种保证没有重复元素的集合,例如,所有无重复名称的Student的Set;**Map**:一种通过键值查找的映射表集合,例如,根据Student的name查找对应Student的Map。遗留集合类
Hashtable:一种线程安全的Map实现;Vector:一种线程安全的List实现;Stack:基于Vector实现的LIFO的栈。
还有一小部分接口是遗留接口,也不应该继续使用:
Enumeration<E>:已被Iterator<E>取代。迭代器Iterator
Java访问集合都通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
- 只有数组和实现了
**Iterable**接口的类才可以直接用**for each**循环来遍历,如List,Set - 实现类迭代器的集合类会以内部类的方式实现迭代器遍历,而迭代方法即
itertor() - 迭代遍历:在取元素之前先判断集合中有没有元素,如果有,就把这个元素取出来,再继续判断,如果还有就再继续取出来。一直到把集合中的所有元素全部取出。这种取出方式就称为迭代。因此Iterator 对象也被称为「迭代器」。
- Iterator本身也是一个对象,但它是由List的实例调用iterator()方法的时候创建的。Iterator对象知道如何遍历一个List,并且不同的List类型,返回的Iterator对象实现也是不同的,所以总是具有最高的访问效率(适用于所有类型的List)
- Iterator 接口中的常用方法:
E next();// 返回迭代的下一个元素。boolean hasNext();// 如果仍有元素可以迭代,则返回 trueCollection<String> coll = new ArrayList<String>();// 添加元素到集合coll.add("A");coll.add("B");coll.add("C");// 获取 coll 的迭代器Iterator<String> it = coll.iterator();while(it.hasNext()){ // 判断是否有迭代元素String s = it.next(); // 获取迭代出的元素System.out.println(s);}}
类图
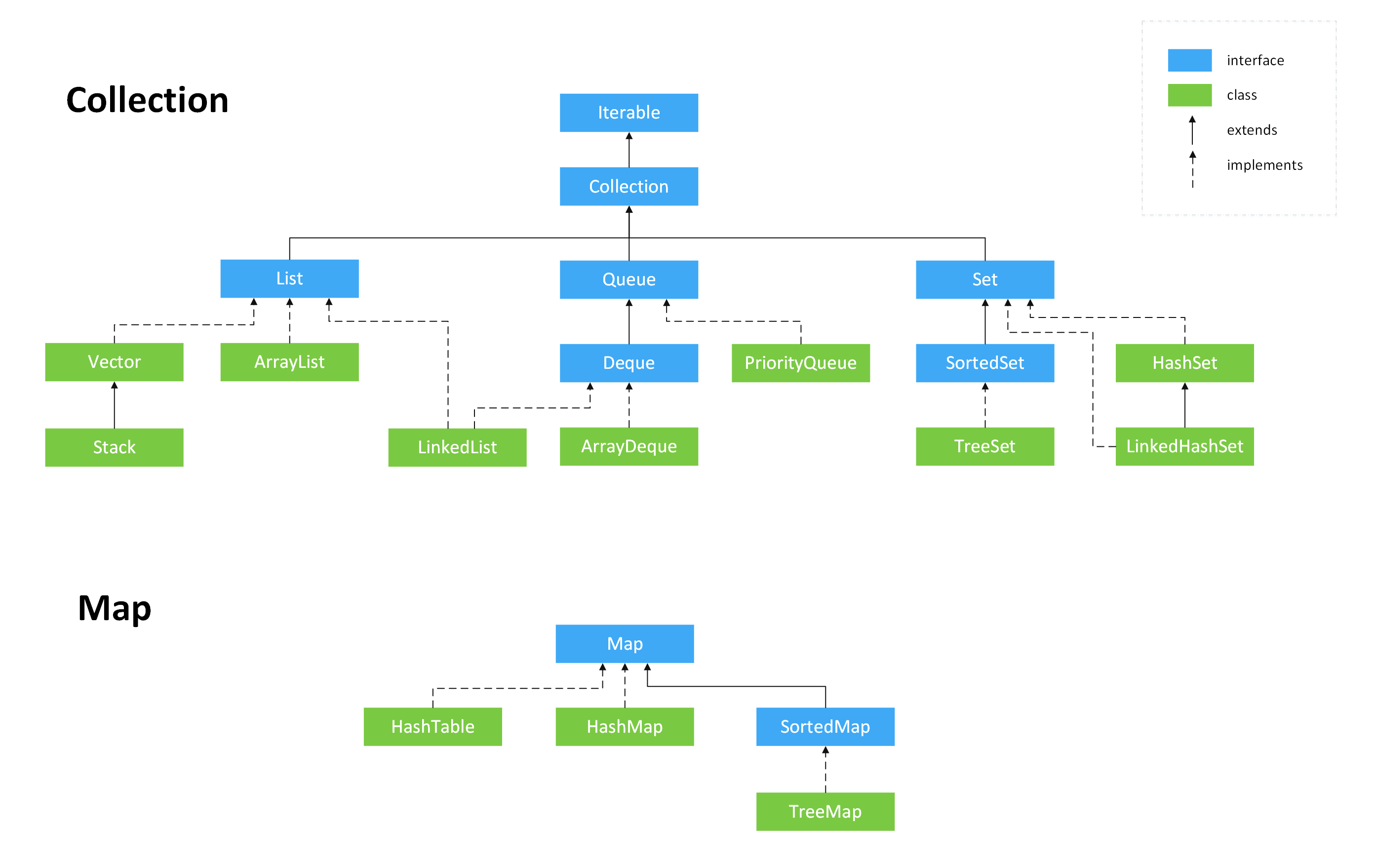
Collection 接口
java.util.Collection单列集合:元素是孤立存在的,向集合中存储元素采用一个个元素的方式存储。增:
**public boolean add(E e);**// 把给定的对象添加到当前集合中add(int,E)在索引为索引为int的元素前插入元素,这就意味着int可以=size()
- 清空:public void clear(); // 清空集合中所有的元素
- 删:
**public boolean remove(E e); **// 把给定的对象在当前集合中删除 **public boolean contains(E e);**// 判断当前集合中是否包含给定的对象,返回布尔值**public int indexOf(E e);**//判断是否包含给定对象,存在返回索引,不存在返回-1**public boolean isEmpty();**// 判断当前集合是否为空**public int size();**// 返回集合中元素的个数**public Object[] toArray(); **// 把集合中的元素,存储到数组中addAll(Collection<E> )将2个集合的数据合并 如a.addAll(b)即将b集合元素追加到a集合中
Collections工具类
- 创建空集合;
- 创建单元素集合;
- 创建不可变集合;
- 排序/洗牌等操作
- 详见链接
T Collections.min/max(List list)list大小不能为0,不能存在null元素List接口
List集合特点是元素有序,可重复 有序即元素的存入顺序和取出顺序一致
- List允许null值
- List索引从0开始
- List有2个实现类:ArrayList和LinkedList
List接口增加了些根据索引进行操作的方法
通过Array和Linked的构造方法创建,事后通过add()方法初始化
通过静态方法
**List.of()**或者静态方法**Arrays.asList()**创建时并初始化- List.of()在java11以上的版本才有此方法。该方法不能接受null。通过给定参数列表或者数组参数返回的是一个不可变的ArrayList对象
- Arrays.asList()通过给定参数列表或者数组参数返回不可变的ArrayList对象
- 反正二者用法都一样,就是of不能接受null值
List a= Arrays.asList(1,2,3);List<String> list = new ArrayList<>();//后面泛型类型可以不写,连后面<>都可以不写ArrayList<String> list = new ArrayList<>();Collection<String> list=new ArrayList<>();...
ArrayList
底层结构是数组,线程不安全。
自动扩容:也跟数组一样;增加元素时,如果ArrayList数组满了,就创建一个更大的新数组,然后把旧数组的所有元素复制到新数组,紧接着用新数组取代旧数组
LinkedList
LinkedList不仅仅是List的实现类,还实现了Queue类。所以LinkedList可以使用来自Queue的方法
- 注意,如果是
LinkedList list=new LinkedList(); 那么list可以调用来自List和Queue的方法 - 如果是
List/Collection list=new LinkedList() 那么list要想使用Queue方法必须下转型。因为子类Linked引用调用父类/父接口方法可以,但是父类引用(List)不能调用调用同级别类(Queue)和父类(Collection)的方法。- 解决方法是下转型。
((LinkedList<String>) list).peek() **注意.优先级大于强转()**
- 解决方法是下转型。
- 注意,如果是
- 底层结构是链表,线程不安全
链表结构如下:在LinkedList中,它的内部每个元素都指向下一个元素,首尾元素有一个连接节点,中间元素有两个连接节点
┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐HEAD ──>│ A │ ●─┼──>│ B │ ●─┼──>│ C │ ●─┼──>│ D │ │└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
ArrayList与LinkedList比较
通常情况下,我们总是优先使用
**ArrayList**。- ArrayList适合查找,LinkedList适合增删。(其实LinkedList仅仅是在头尾增加删除快,指定位置增加快不了多少,所以基本不会用到
LinkedList)- 为了避免扩容影响性能。最好在创建时就给定一个合适的大小
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素(查询) | 速度很快 | 需要从头开始查找元素(慢) |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素(更慢) | 不需要移动元素(更快) |
| 内存占用 | 少 | 较大 |
遍历List
方法一:for循环
- 跟数组一样,List也可以用
**for**循环根据索引配合**get(int)**方法遍历 int为参数类型,参数为索引- 只有数组结构的List才可以这样访问,如ArrayList
```java
List
list = List.of(“apple”, “pear”, “banana”); for (int i=0; i<list.size(); i++) {
}String s = list.get(i); System.out.println(s);
- 只有数组结构的List才可以这样访问,如ArrayList
```java
List
或者使用foreach简化 for (String s : list) { System.out.println(s); }
**方法二:使用迭代器**
```java
List<String> list = List.of("apple", "pear", "banana");
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
------------------------------------------------------------------
while(it.hasNext()){ // 判断是否有迭代元素
String s = it.next(); // 获取迭代出的元素
System.out.println(s);
}
- 循环首先创建迭代器对象并确定迭代器类型(该类型为获取到的数据的类型,不是要处理的对象的类型)
- 然后令迭代器对象初始化,iterator()返回一个迭代器对象
**hasNext()**判断对象是否为空,为空返回false然后退出循环,不为空则指针(索引)后移一位- next()为获取下一位元素,即获取元素值(不清楚0索引元素哪去了。。。
只要实现了import java.util.List; public class Main { public static void main(String[] args) { List<String> list = List.of("apple", "pear", "banana"); for (String s : list) { System.out.println(s); } } }**Iterable**接口的集合类都可以直接用**for each**循环来遍历,Java编译器本身并不知道如何遍历集合对象,但它会自动把**for each**循环变成**Iterator**的调用,原因就在于**Iterable**接口定义了一个**Iterator<E> iterator()**方法,强迫集合类必须返回一个**Iterator**实例。List转Array(Array是数组)
首先有一个List对象list
方法一:Object[] array = list.toArray();toArray方法会返回一个Object数组
此种方法会丢失类型信息,实际应用较少
方法二:给toArray(T[])传入一个类型相同的Array(用于指定转换后数组的类型),List内部自动把元素复制到传入的Array中
toArray(T[] a)方法使用了泛型参数,可以返回指定类型数组,但是这个泛型在确定的时候必须是list中元素类型的父类或本身(比如String元素放不进int型数组)至于那个参数数组,其实就是为了传递参数类型罢import java.util.List; public class Main { public static void main(String[] args) { List<Integer> list = List.of(12, 34, 56); Integer[] array = list.toArray(new Integer[3]); for (Integer n : array) { System.out.println(n); } } }
如果传入的数组不够大,那么**List**内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比**List**元素还要多,那么填充完元素后,剩下的数组元素一律填充**null**。
方法三:我们一般传入一个刚刚好大小的数组**toArray(new <T>[list.size()]);**函数式简化写**toArray(Integer[]::new);**
如Integer[] array = list.toArray(Integer[]::new);
List中的equals()
- List中判断元素是否相同使用的是equals而不是==,所以contains和indexOf对于参数与元素同值不同对象的结果也还是相等,如new 2个
但是这equals只覆写(覆写就是重写)了基本包装类。对于其他类型,如类类型没有定义到。所以比如indexOf判断的是类类型参数就会不相等,就返回-1
- 如何针对List的equals进行重写见https://www.liaoxuefeng.com/wiki/1252599548343744/1265116446975264
如果不在List中查找元素,就不必覆写equals()方法。基本类型也不用覆写
- Vector增加一倍,ArrayList增加 0.5倍。二者初始容量都是10
- LinkedList无需考虑扩容问题
Vector 和 ArrayList 内存总开销更小,但需要是连续内存空间;LinkedList 内存总开销更大,但可以利用零碎的内存空间,无需连续内存空间
Set接口
Set接口用法与List差不多的使用方法,只不过Set不支持重复元素,(不支持重复的本质是因为HashMap不支持重复的键)
- 支持null值,但是只能有一个null值
- 而且元素无序(但是SortedSet实现了有序排序)
- Set因为不是数组实现的,所以不能通过索引访问
- Set有两个实现类
**HashSet**和**LinkedHashSet**- HashSet底层基于 HashMap 实现,采用 HashMap 来保存元素。
- LinkedHashSet 是 HashSet 的子类,并且其底层是通过 LinkedHashMap 来实现的。可以保证key的有序还有唯一
- 存入到 LinkedHashSet 中的的值最终会作为 key 值(value 值为 null),存入到 LinkedHashMap 中,而 Map 的 key 要求唯一,因此 LinkedHashSet 中的值也就是唯一的。
- TreeSet除了实现Set接口外,还实现了SortedSet接口,该要接口要求它的实现类必须有自动排序的功能
Map接口
- Map是双列集合,元素是成对存在的。每个元素由键(key)与值(value)两部分组成,通过键可以找对所对应的值。显然这个双列集合解决了数组无法存储映射关系的痛点
- 适合高效通过key快速查找value(元素)。
- 一个键值对即一个项(Entry) Entry 将键值对的对应关系封装成了对象,即键值对对象
- Map 不能包含重复的键,值可以重复;并且每个键只能对应一个值
- Map有两个重要的实现类:
**HashMap**和**LinkedHashMap**(LinkedHashMap既继承了HashMap同时还实现了Map接口) - Map只存储关系映射,不存储键值对的顺序,所以多次遍历时结果顺序是随机的
- Map只能通过键查找值,不能通过值查找键
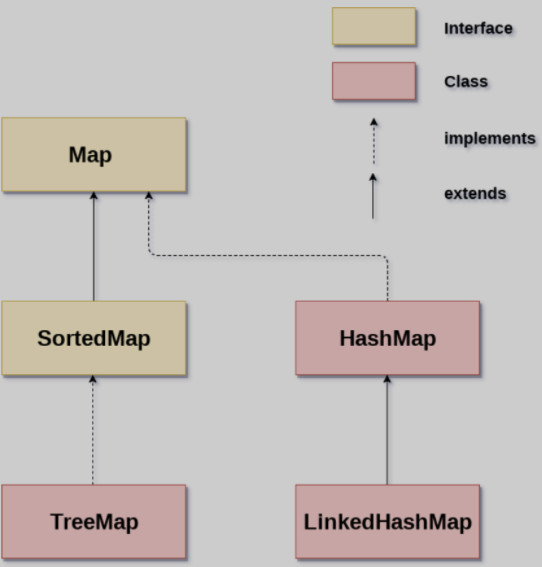
Map通用方法
- 增:
**put(K key, V value);**// 把指定的键与指定的值添加到 Map 集合中。 - 改:对一个键重复put,新值会覆盖旧值,然后返回被覆盖的值
- 删:
remove(Object key);// 删除指定键对应的值,返回被删除元素的值。 - 查:
get(Object key);// 根据指定的键,在 Map 集合中获取对应的值。 boolean containsKey(Object key);// 判断集合中是否包含指定的键。Set<K> keySet();// 获取 Map 集合中所有的键,存储到 Set 集合中。(因为Map键不重复,所以用Set存储)Set<Map.Entry<K,V>> entrySet();// 获取 Map 中所有的 Entry 对象的集合。getKey();// 获取某个 Entry 对象中的键getValue();// 获取某个 Entry 对象中的值。
size():获取Map长度Student s = new Student("Xiao Ming", 99); Map<String, Student> map = new HashMap<>();HashMap
hashmap允许null作为键/值。Hashtable和ConcurrentHashMap不允许null作为键/值。
- HashMap 有两个重要的参数:容量(Capacity)和负载因子(LoadFactor)。
- 容量(Capacity):是指 HashMap 中桶(也就是数组的单元)的数量,默认的初始值为 16。
- 负载因子(LoadFactor):也被称为装载因子,用于 Map 的扩容。
- HashMap 在 JDK 7 中会导致循环引用,从而造成死循环的问题。
因为在 JDK 7 中,多线程进行 HashMap 扩容时会导致链表的循环引用,这个时候使用 get() 获取元素时就会导致死循环,造成 CPU 100% 的情况。
HashMap结构
- JDK 1.8 之前 HashMap 底层由数组加链表实现,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法” 解决冲突)
- jdk8以后是数组+链表+红黑树
- JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间(注意:将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)
- 存放数据的规则:JDK 7 无冲突时,存放数组;冲突时,存放链表;JDK 8 在没有冲突的情况下直接存放数组,有冲突时,当链表长度小于 8 时,存放在单链表结构中,当链表长度大于 8 时,树化并存放至红黑树的数据结构中。
插入数据方式:JDK 7 使用的是头插法(先将原位置的数据移到后 1 位,再插入数据到该位置);JDK 8 使用的是尾插法(直接插入到链表尾部/红黑树)。
LinkedHashMap
HashMap 的子类,可以保证元素的存取顺序一致(存进去时候的顺序是多少,取出来的顺序就是多少,不会因为 key 的大小而改变)。
LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构,即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。
EnumMap
虽然叫做枚举表,但是也是可以接受任意引用类型作key类型的。
- 但是EnumMap对于Enum类型键具有更好的支持:它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
- 如果Map的key是enum类型,推荐使用EnumMap,既保证速度,也不浪费空间。
EnumMap不同于其他集合:它是在
**EnumMap()**构造方法内部就实例化了T类型(实例化了Key)。所以它需要传入一个class参数(见擦拭法第四种局限) TreeMap表既不是有序也不是无序。它输出是排序Key后的结果。排序的结果只是一个输出结果,不影响实际存储顺序
- key类型必须实现
Comparable接口。String和基本类型都已经实现了该接口- 如果key的class未实现,那需要指明一种排序或者比较的方法
- 如果是比较,TreeMap默认将结果为-1的往下排
- 如果key的class未实现,那需要指明一种排序或者比较的方法
- 详见链接
```java
public class Main {
public static void main(String[] args) {
} }Map<Person, Integer> map = new TreeMap<>(new Comparator<Person>() { public int compare(Person p1, Person p2) { return p1.name.compareTo(p2.name); } }); map.put(new Person("Tom"), 1); map.put(new Person("Bob"), 2); map.put(new Person("Lily"), 3); for (Person key : map.keySet()) { System.out.println(key); } // {Person: Bob}, {Person: Lily}, {Person: Tom} System.out.println(map.get(new Person("Bob"))); // 2
class Person { public String name; Person(String name) { this.name = name; } public String toString() { return “{Person: “ + name + “}”; } }
<a name="QkrwS"></a>
## 遍历Map
- **注意Map 由于没有实现或继承 Iterable 接口,所以不能直接使用迭代器或者 for each 循环进行遍历**,但是转成 Set 之后就可以使用了。
<a name="sE5lI"></a>
### 通过根据 key 找值遍历
```java
public static void main(String[] args) {
// 创建 Map 集合对象
HashMap<Integer, String> map = new HashMap<Integer,String>();
// 添加元素到集合
map.put(1, "小五");
map.put(2, "小红");
map.put(3, "小张");
// 获取所有的键 获取键集
Set<Integer> keys = map.keySet();
// 遍历键集 得到 每一个键
for (Integer key : keys) {
// 获取对应值
String value = map.get(key);
System.out.println(key + ":" + value);
}
}
//foreach简化:
for(Integer key:map.keySet()){
String value = map.get(key);
System.out.println(key + " = " + value);
}
通过键值对Entry遍历
// 获取所有的 entry 对象
Set<Entry<Integer,String>> entrySet = map.entrySet();
// 遍历得到每一个 entry 对象
for (Entry<Integer, String> entry : entrySet) {
Integer key = entry.getKey();
String value = entry.getValue();
System.out.println(key + ":" + value);
}
哈希冲突
- Hashtable、HashMap 它们采用的处理方式叫『链地址法』。
这种方法的基本思想是将所有哈希地址为 i 的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第 i 个单元中,因而查找、插入和删除主要在同义词链(红黑树)中进行。链地址法适用于经常进行插入和删除的情况。
还有其它的一些处理方式。
Queue接口
- 队列也是有序集合(先进先出),但是不同于List等有序集合,队列只能对队首队尾进行操作
- 队尾只能插入
- 队首只能删除
- 大部分集合都是自动扩充长度的,但是有的Queue是存在最大长度的
- Queue最常用的实现类是LinkedList,其他Queue实现类都是有其他特殊功能的队列而非最原始基本的队列
- add,remove,element操作失败抛出异常,而offer操作失败返回false。poll和peek操作失败返回null
- 所以要避免把null插入到队列中,否则如果poll或者peek返回null就不知道是获取到空元素还是失败返回了null
插入元素失败一般是Queue是定长的,已经满了。 获取首元素失败一般是队列为空不存在元素
常见的有三种阻塞队列:
ArrayBlockingQueue ``LinkedBlockingQueuePriorityBlockingQueue阻塞队列的含义见多线程- 前者基于数据,后者基于链表
- ArrayBlockingQueue 使用时必须指定容量值,ArrayBlockingQueue 的最大容量值是使用时指定的,并且指定之后就不允许修改
- 不允许存入null
LinkedBlockingQueue可以不用指定容量;最大容量为Integer.Max_ValuePriorityQueue
存入与弹出时会根据排序规则决定存入/弹出哪个位置。用于实现总体上是先进先出的公平,又允许存在不遵守该规则的vip元素。
这是一个无界的阻塞队列,Delayed接口的实现类具有这种功能:其中的对象只能在其到期时才能从队列中取走,未到期无法取走。这种队列是有序的,即队头对象的延迟到期时间最长
- 不允许存储null
DelayQueue位于juc内,线程池定时线程就是基于DelayQueue,还可以利用DelayQueue实现个延时消息队列,并支持多消费者,多生产者
使用时必须存入的是
Delayed的实现类,即自定义 的根据时间排序的队列。Deque
Queue是单端队列,只能先进先出,即一端进行插,一端进行删除。而Deque 是双端队列,两端都能插入和删除元素。
stack栈来源于Vector接口。特性是先进后出。栈已经是一个遗留类了。在java中一般使用Deque来模拟栈
注意不要在Stack元素为空时进行pop或者peek
Stack<Integer> stack = new Stack(); stack.push(10); //压栈 stack.push(20); stack.push(30); for (int i = 0; i < 3; i++) { //出栈,并删除这个元素 System.out.print(stack.pop() + " "); } //peek() 返回栈底的元素重写Object.equals()
集合中的
**indexOf(),contains()**传入的实例必须正确覆写**Object.equals**,否则查找不到- 因为二者本质上是调用equals来比较,即二者仅仅比较值
- 比如你即便
...=List.of("A");contains(new String("A"))虽然传入的是new,但是结果还是正确的。但是如果集合类型是自定义类,因为没有正确覆写equals。所以contains比较时会直接 ==。此时如果传入的是new …,那么结果肯定不存在
- 覆写equals()方法要求我们必须满足以下条件:
- 自反性(Reflexive):对于非null的x来说,x.equals(x)必须返回true;
- 对称性(Symmetric):对于非null的x和y来说,如果x.equals(y)为true,则y.equals(x)也必须为true;
- 传递性(Transitive):对于非null的x、y和z来说,如果x.equals(y)为true,y.equals(z)也为true,那么x.equals(z)也必须为true;
- 一致性(Consistent):对于非null的x和y来说,只要x和y状态不变,则x.equals(y)总是一致地返回true或者false;
- 对null的比较:即x.equals(null)永远返回false。
- equals不能使用泛型,因为它需要的是一个对象。
List和Map结合例子
import java.util.*;
public class Main{
public static void main(String[] args) {
Student[]array={new Student("Bob", 78),
new Student("Alice", 85),
new Student("Brush", 66),
new Student("Newton", 99)};
ArrayList<Student> list=new ArrayList<>(Arrays.asList(array));
Students holder = new Students(list);
System.out.println(holder.getScore("Bob") == 78 ? "测试成功!" : "测试失败!");
System.out.println(holder.getScore("Alice") == 85 ? "测试成功!" : "测试失败!");
System.out.println(holder.getScore("Tom") == -1 ? "测试成功!" : "测试失败!");
}
}
class Students { //这个跟Student类关系不大,主要是为了充当方法存储的类
List<Student> list;
Map<String, Integer> cache;
Students(ArrayList<Student> list) {
this.list = list;
cache = new HashMap<>();
}
/**
* 根据name查找score,找到返回score,未找到返回-1
*/
int getScore(String name) {
// 先在Map中查找:
Integer score = this.cache.get(name);
if (score == null) {
// TODO:
}
return score == null ? -1 : score.intValue();
}
Integer findInList(String name) {
for (Student ss : this.list) {
if (ss.name.equals(name)) {
return ss.score;
}
}
return null;
}
}
class Student {
String name;
int score;
Student(String name, int score) {
this.name = name;
this.score = score;
}
}

若有收获,就点个赞吧
0 人点赞
