一、动态SQL
相比固定的sql语句,动态sql结构不固定,可以根据需求更改
作用:
根据条件拼接不同结构的sql语句,提高sql代码的重用性
可以满足某些特定要求,如条件查询、判断查询
Mapper.XML配置:include 标签,将sql语句部分内容提取出来,通过include标签放入需要位置(不建议使用,会增加代码维护难度)
if 标签,如果满足test的条件,则拼接语句,test使用OGNL语法(参数对象属性:属性名 支持常见运算符:!=、==)
foreach 标签,传入的是数组、集合时使用(批量删除)
collection:指定参数池的变量名
index:设置索引变量
open:设置整个循环前添加的内容,如左括号
close:设置整个循环后添加的内容,如右括号
separator:设置循环间隔符,如逗号
item:设置循环的临时对象
trim 标签,可以在语句两端(最前面和最后面)添加或去除内容,至少要有一个属性不为空
perfix:最前面添加
suffix:最后面添加
prefixOverrides:最前面去除
suffixOverrides:最后面去除
_set 标签,替代sql语句中的set关键字,根据传入的参数属性值不为空,进行更新对应属性动态更新,只更新参数不为空的数据,忽略最后面的逗号
where 标签,用于替代where关键字,会自动去除多余的 and ,如果没有需要拼接的条件,where关键字也不会出现在sql语句中
二、动态SQL注解实现
在接口方法中使用注解,通过提供一个Java类的方法,动态拼接处sql语句并返回给方法调用
// 接口方法@SelectProvider(type = UserMapperProvider.class,method = "findByCondition")List<User> findByCondition(User user);// 拼接sql语句的Java类// 非集合类型参数直接传入,集合类型需要搭配@Param进行参数池绑定public String findByCondition(User user){StringBuilder sb = new StringBuilder();sb.append("SELECT `user`.id,`user`.username,`user`.birthday,`user`.sex,`user`.address\n" +" FROM `user`\n"+" where 1=1\n");if (user.getUsername()!=null){sb.append("and username like concat ('%',#{username},'%')");}if (user.getSex()!=null){sb.append("and sex = #{sex}");}if (user.getBirthday()!=null){sb.append("and birthday = #{birthday}");}if (user.getAddress()!=null){sb.append("and address = #{address}");}return sb.toString();}
注意:
1.动态SQL语句的提供类,提供的就是拼接好的SQL语句
2.如果参数不是标量类型或者单个实体对象,那么必须使用Map包装起来
批量删除时,接口方法参数需要使用注解 @Param(自定义变量名) ,在拼接sql语句的Java类中使用@Param(自定义变量名)从参数池中获取绑定到的数据
// 接口方法
@DeleteProvider(type = UserMapperProvider.class,method = "deleteBatch")
int deleteBatch(@Param("ids") List<Integer> ids);
// 拼接sql语句的Java类
public String deleteBatch(@Param("ids")List<Integer> ids){
StringBuilder sb = new StringBuilder();
sb.append("delete from user where id in ");
sb.append("(");
for (int i = 0; i < ids.size(); i++) {
sb.append("#{ids["+i+"]},"); // 从参数池的ids中获取对应索引位置的值,索引需要使用Java遍历获取
}
sb.deleteCharAt(sb.length()-1);
sb.append(")");
return sb.toString();
}
三、高级查询(多表连接查询)
表与表的关系
一对一:在两张表中,都只能从对方表找出一条数据对应
一对多:在两张表中,主表表的一条数据能从从表中找出多条数据对应,而从表的每条数据只能在主表找出一条数据对应
多对一:在两张表中,主表的每条数据只能在从表中找出一条数据对应,而从表的每条数据能在主表中找出多条数据对应
多对多:在两张表中,每张表都能在对方表中找出多条数据对应
实体类配置
账户实体类,需要添加用户实体类作为其中一个属性
association标签使用
根据实体类的定义,如果是属性集合就配置
在userMapper中,配置User的映射字段名
使用一条sql语句查询:
accountMapper中,使用连表查询查询两张表(一条sql查询),返回结果集 resultMap

配置映射字段resultMap 标签中,使用 autoMapping 属性可自动映射能够映射的属性,但是主表id必须配置

分开两次查询:
collection标签使用(配合list):
property:实体类里面的属性名的集合
resultMap:指定已经设置好的映射(mapper命名空间.resultMap的id)
javaType:实体类里面的类型
ofType:集合元素的类型
select:指定查询的操作,操作结果一定要与property指定的属性名相匹配
column:传入的select的id字段名
**
纯注解配置
映射接口,使用数据库操作注解 @Select 和注解 @Results ,其中包含子注解 @Result
@Results 注解对应配置文件的 resultMap 标签, @Result 对应 result 标签
@Result 标签可以配置One注解和Many注解,@One 注解对应配置文件的 association 标签, @Many 对应 collection 标签
四、延迟加载
在一些多表连接的查询中,只用到主表数据,不需要使用关联表数据的时候不查询关联表(需要再加载,不需要不加载,适合分开查询使用)
配置:
主配置文件中配置
lazyLoadingEnabled 设置为true时为延迟加载(默认为true)aggressiveLazyLoading 设置为false时取消积极加载(默认为true)
积极加载的映射就是当前对象关联属性也会立即加载
延迟加载和积极加载要同时配置
五、逆向工程
1、pom引入maven的逆向工程插件配置
插件中需要另外引入数据库依赖,该依赖与项目使用的依赖不通用
2、在资源路径下放入逆向工程配置文件,编写配置文件
1)设置MySQL依赖和数据库连接4要素


2)配置项目结构dao的包名、entity的包名、映射配置文件的包名


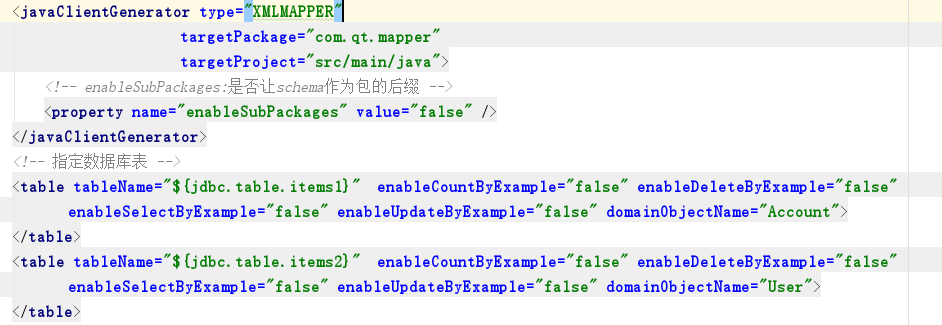
3)配置需要逆向生成代码的表和逆向规则
tableName:需要在数据库连接文件中设置需要生成的表
六、缓存机制
缓存
第一个方法查询数据时,先查询缓存中是否存在有数据,如果有则直接返回结果,如果没有则对数据库进行查询,查询到对应数据后将数据返回给方法调用者的同时,将数据存入缓存中(存储方式为键值对)。
第二个方法查询相同数据时,直接查找缓存中的数据,并不会再次对数据库进行查询操作,提升了程序的性能
一级缓存(无需设置)
1、依赖sqlSession,是sqlSession中的一个集合对象,key为自动生成包含了方法和参数值,value是该执行sql的返回数据
2、mybatis自动管理一级缓存,第一次查询数据库后,会自动将数据放入一级缓存中
3、当前sqlSession销毁前一直有效,不能跨sqlSession读取缓存
4、如果增删改操作,会导致一级缓存失效(更改了数据库数据,为保持数据一致性,需要重新获取数据)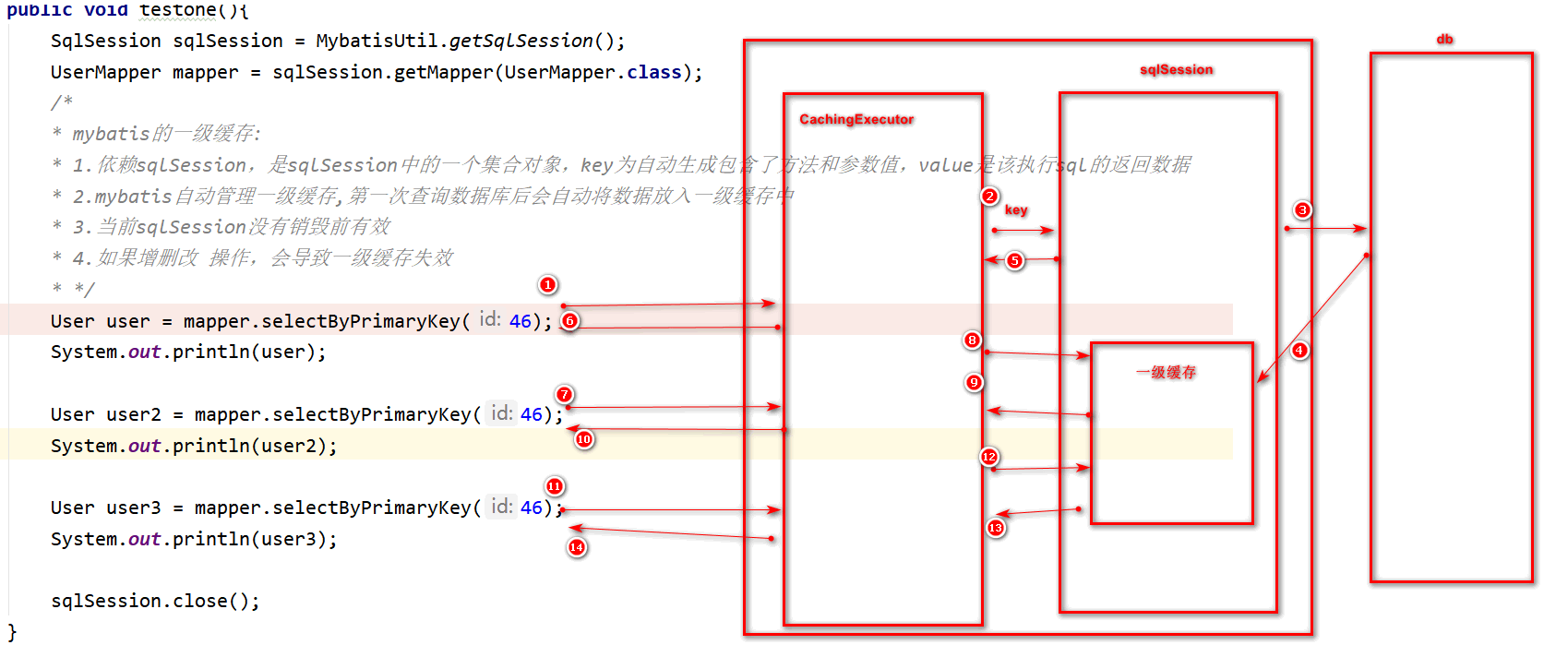
二级缓存(手动设置)
1、全局设置开启支持二级缓存(默认开启)
2、将需要放入二级缓存管理对象的实体类需要实现序列化接口
3、在需要使用二级缓存的mapper映射文件中添加 cache 标签设置二级缓存配置
默认会自动创建一个二级缓存对象,设置默认值
总结:
1、二级缓存是mapper对象中的一个缓存对象属性,需要配置开启
2、查询数据时,缓存执行器CachingExecutor会从二级缓存查找数据,如果没有则会进入一级缓存查找,如果没有则执行sql语句进行数据查询,然后返回所查找的数据
3、一级缓存中的数据会在关闭sqlSession的时候,自动放入二级缓存中,放入二级缓存的前对象会序列化,所以实体类接口要实现序列化接口
4、缓存命中率(做数据统计):从缓存中查到的次数/总共查询次数

注解实现:
1、需要缓存的对象类型实现序列化接口
2、开启全局缓存支持,默认开启
3、在需要缓存的mapper上添加注解 @CacheNameSpace
blocking:设置是否使用锁进行阻塞,默认为true
通过装饰者模式,提供一个BlockingCache类来处理缓存
4、mapper的接口方法中对不需要缓存的接口添加 @Options(useCache=false)
第三方缓存
1、引用依赖jar包(同时需要slf4j的日志jar包)
2、添加配置文件(ehcache.xml)
添加缓存数据持久化的目录/地址
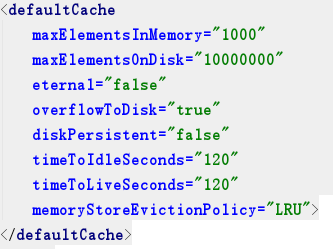
maxElementsInMemory :内存中最大缓存对象数maxElementsOnDisk :磁盘中最大缓存对象数,若是0表示无穷大eternal :Element是否永久有效,设置该属性后timeout会失效overflowToDisk :当内存中Element数量达到所设置的最大数时,第三方缓存会将数据写入磁盘中diskPersistent :是否缓存虚拟机重启期数据timeToIdleSeconds :设置Element在失效前的允许闲置时间。仅当element不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大
timeToLiveSeconds :设置Element在失效前允许存活时间。最大时间介于创建时间和失效时间之间。仅当element 不是永久有效时使用,默认是0,也就是element存活时间无穷大
memoryStoreEvictionPolicy : 当内存缓存达到最大,有新的element加入的时候, 移除缓存中element的策略。
默认是LRU(最近最少使用),可选的有LFU(最不常使用,从创建起计算)和FIFO(先进先出)
3、在mapper配置文件中开启ehcache缓存
cache标签的属性:
type:设置使用哪个缓存处理类
eviction:设置缓存的删除策略
size:设置缓存元素个数
flushInterval:刷新内存中的缓存数据的周期
readOnly:是否只读缓存

若有收获,就点个赞吧
0 人点赞
