前言
location 指令是 nginx 中最关键的指令之一,location 指令的功能是用来匹配不同的 URI 请求,进而对请求做不同的处理和响应,这其中较难理解的是多个 location 的匹配顺序,本文会作为重点来解释和说明。
开始之前先明确一些约定,我们输入的网址叫做请求 URI,nginx 用请求 URI 与 location 中配置的 URI 做匹配。
nginx文件结构
首先我们先简单了解 nginx 的文件结构,nginx 的 HTTP 配置主要包括三个区块,结构如下:
Global: nginx 运行相关Events: 与用户的网络连接相关httphttp Global: 代理,缓存,日志,以及第三方模块的配置serverserver Global: 虚拟主机相关location: 地址定向,数据缓存,应答控制,以及第三方模块的配置
从上面展示的 nginx 结构中可以看出 location 属于请求级别配置,这也是我们最常用的配置。
配置 location 块
location 语法
Location 块通过指定模式来与客户端请求的URI相匹配。
Location基本语法:
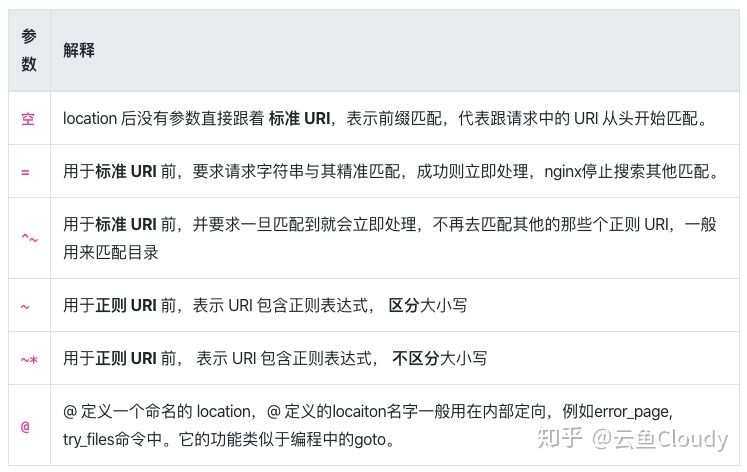
- 匹配 URI 类型,有四种参数可选,当然也可以不带参数。
- 命名location,用@来标识,类似于定义goto语句块。
location [ = | ~ | ~* | ^~ ] /URI { … }location @/name/ { … }
location匹配命令解释
location匹配顺序
nginx有两层指令来匹配请求 URI 。第一个层次是 server 指令,它通过域名、ip 和端口来做第一层级匹配,当找到匹配的 server 后就进入此 server 的 location 匹配。
location 的匹配并不完全按照其在配置文件中出现的顺序来匹配,请求URI 会按如下规则进行匹配:
- 先精准匹配
=,精准匹配成功则会立即停止其他类型匹配; - 没有精准匹配成功时,进行前缀匹配。先查找带有
^~的前缀匹配,带有^~的前缀匹配成功则立即停止其他类型匹配,普通前缀匹配(不带参数^~)成功则会暂存,继续查找正则匹配; =和^~均未匹配成功前提下,查找正则匹配~和~*。当同时有多个正则匹配时,按其在配置文件中出现的先后顺序优先匹配,命中则立即停止其他类型匹配;- 所有正则匹配均未成功时,返回步骤 2 中暂存的普通前缀匹配(不带参数
^~)结果
以上规则简单总结就是优先级从高到低依次为(序号越小优先级越高):
1. location = # 精准匹配2. location ^~ # 带参前缀匹配3. location ~ # 正则匹配(区分大小写)4. location ~* # 正则匹配(不区分大小写)5. location /a # 普通前缀匹配,优先级低于带参数前缀匹配。6. location / # 任何没有匹配成功的,都会匹配这里处理
上述匹配规则可以用以下伪代码表示,加深理解:
function match(uri):rv = NULLif uri in exact_match:return exact_match[uri]if uri in prefix_match:if prefix_match[uri] is '^~':return prefix_match[uri]else:rv = prefix_match[uri] // 注意这里没有 return,且这里是最长匹配if uri in regex_match:return regex_match[uri] // 按文件中顺序,找到即返回return rv
案例分析
案例 1
server {server_name website.com;location /doc {return 701; # 用这样的方式,可以方便的知道请求到了哪里}location ~* ^/document$ {return 702;}}
curl -I website.com:8080/document 返回 返回 HTTP/1.1 702
说明:按照上述的规则,显然第二个正则匹配会有更高的优先级
案例 2
server {server_name website.com;location /document {return 701;}location ~* ^/document$ {return 702;}}
curl -I website.com:8080/document 返回 HTTP/1.1 702
说明:第二个匹配了正则表达式,优先级高于第一个普通前缀匹配
案例 3
server {server_name website.com;location ^~ /doc {return 701;}location ~* ^/document$ {return 702;}}
curl [http://website.com/document](http://website.com/document) 返回 HTTP/1.1 701
说明:第一个前缀匹配 ^~ 命中以后不会再搜寻正则匹配,所以会第一个命中。
案例 4
server {server_name website.com;location /docu {return 701;}location /doc {return 702;}}
curl -I website.com:8080/document 会返回 HTTP/1.1 701
server {server_name website.com;location /doc {return 702;}location /docu {return 701;}}
curl -I website.com:8080/document 依然返回 HTTP/1.1 701
说明:前缀匹配下,返回最长匹配的 location,与 location 所在位置顺序无关
案例 5
server {listen 8080;server_name website.com;location ~ ^/doc[a-z]+ {return 701;}location ~ ^/docu[a-z]+ {return 702;}}
curl -I website.com:8080/document 返回 HTTP/1.1 701
把顺序换一下
server {listen 8080;server_name website.com;location ~ ^/docu[a-z]+ {return 702;}location ~ ^/doc[a-z]+ {return 701;}}
curl -I website.com:8080/document 返回 HTTP/1.1 702
说明:可见正则匹配是使用文件中的顺序,先匹配成功的返回。
案例 6
最后我们对一个官方文档中提到例子做一些补充,来看一个相对较完整的例子,假设我们有如下几个请求等待匹配:
//index.html/documents/document.html/documents/abc/images/a.gif/documents/a.jpg
以下是 location 配置及其匹配情况
location = / {# 只精准匹配 / 的查询.[ configuration A ]}# 匹配成功: /location / {# 匹配任何请求,因为所有请求都是以”/“开始# 但是更长字符匹配或者正则表达式匹配会优先匹配[ configuration B ]}#匹配成功:/index.htmllocation /documents {# 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索/# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条/[ configuration C ]}# 匹配成功:/documents/document.html# 匹配成功:/documents/abclocation ~ /documents/ABC {# 区分大小写的正则匹配# 匹配任何以 /documents/ 开头的地址,匹配符合以后,还要继续往下搜索/# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条/[ configuration CC ]}location ^~ /images/ {# 匹配任何以 /images/ 开头的地址,匹配符合以后,立即停止往下搜索正则,采用这一条。/[ configuration D ]}# 成功匹配:/images/a.giflocation ~* \.(gif|jpg|jpeg)$ {# 匹配所有以 .gif、.jpg 或 .jpeg 结尾的请求,不区分大小写# 然而,所有请求 /images/ 下的图片会被 [ config D ] 处理,因为 ^~ 到达不了这一条正则/[ configuration E ]}# 成功匹配:/documents/a.jpglocation /images/ {# 字符匹配到 /images/,继续往下,会发现 ^~ 存在/[ configuration F ]}location /images/abc {# 最长字符匹配到 /images/abc,继续往下,会发现 ^~ 存在/# F与G的放置顺序是没有关系的/[ configuration G ]}location ~ /images/abc/ {# 只有去掉 [ config D ] 才有效:先最长匹配 [ config G ] 开头的地址,继续往下搜索,匹配到这一条正则,采用/[ configuration H ]}
其他location配置相关
匹配问号后的参数
请求 URI 中问号后面的参数是不能在 location 中匹配到的,这些参数存储在 $query_string 变量中,可以用 if 来判断。
例如,对于参数中带有单引号 ’ 进行匹配然后重定向到错误页面。
/plus/list.php?tid=19&mid=1124‘if ( $query_string ~* “.*[;’<>].*” ){return 404;}
location URI结尾带不带 /
关于 URI 尾部的 / 有三点也需要说明一下。第一点与 location 配置有关,其他两点无关。
- location 中的字符有没有
/都没有影响。也就是说/user/和/user是一样的。 - 如果 URI 结构是
[https://domain.com/](https://domain.com/)的形式,尾部有没有/都不会造成重定向。因为浏览器在发起请求的时候,默认加上了/。虽然很多浏览器在地址栏里也不会显示/。这一点,可以访问baidu验证一下。 - 如果 URI 的结构是
[https://domain.com/some-dir/](https://domain.com/some-dir/)。尾部如果缺少/将导致重定向。因为根据约定,URL 尾部的/表示目录,没有/表示文件。所以访问/some-dir/时,服务器会自动去该目录下找对应的默认文件。如果访问/some-dir的话,服务器会先去找some-dir文件,找不到的话会将some-dir当成目录,重定向到/some-dir/,去该目录下找默认文件。可以去测试一下你的网站是不是这样的。命名 location
带有@的 location 是用来定义一个命名的 location,这种 location 不参与请求匹配,一般用在内部定向。用法如下:
上例中,当尝试访问 URI 找不到对应的文件就重定向到我们自定义的命名 location(此处为 custom)。location / {try_files $uri $uri/ @custom}location @custom {# ...do something}
值得注意的是,命名 location 中不能再嵌套其它的命名 location。location 实际使用建议
所以实际使用中,个人觉得至少有三个匹配规则定义,如下:
直接匹配网站根,通过域名访问网站首页比较频繁,使用这个会加速处理,官网如是说。
这里是直接转发给后端应用服务器了,也可以是一个静态首页。第一个必选规则:
第二个必选规则是处理静态文件请求,这是 nginx 作为 http 服务器的强项,有两种配置模式,目录匹配或后缀匹配,任选其一或搭配使用:location = / {proxy_pass http://tomcat:8080/index}
第三个规则就是通用规则,用来转发动态请求到后端应用服务器,非静态文件请求就默认是动态请求,自己根据实际把握,毕竟目前的一些框架的流行,带.php,.jsp后缀的情况很少了:location ^~ /static/ {root /webroot/static/;}location ~* \.(gif|jpg|jpeg|png|css|js|ico)$ {root /webroot/res/;}
location / {proxy_pass http://tomcat:8080/}

若有收获,就点个赞吧
0 人点赞
