SQL入门
在线练习网站: http://xuesql.cn/
1.认识数据库
关系型数据库: 类似于Excel, 存表
非关系型数据库: 存对象
mySQL关键字不区分大小写, SQL语句以分号结尾.
可以使用SQLyog可视化操作的历史记录中的语句辅助学习.
2.基本操作
CRUD 增删改查
create database xxxx; --创建数据库create database [if not exists] xxx --可加判断条件drop database xxxx; --删除数据库drop database [if exists] xxxx;show databases; --查看所有数据库use xxxx; --切换 使用数据库show tables; --查看数据库中所有表describe xxxx; --查看表中的数据desc xxxx;用`xxx`包住的字段名区别SQL的保留字
3.数据类型
数值
tinyint 1个字节
smallint 2个字节
mediumint 3个字节
int 4个字节
bigint 8个字节
float 4个字节
double 8个字节
decimal 字符串形式的浮点数 精度高 适用于金融计算
字符串
char 字符 0~255
varchar 可变字符串 0~65535 保存常用的变量 类似String
tinytext 微型文本 0~2^8-1
text 文本串 0~2^16-1 用于保存大文本
时间日期
data YYYY-MM-DD 日期格式
time HH:mm:ss 时间格式
datatime YYYY-MM-DD HH:mm:ss
timestamp 时间戳 格林尼治起始时到现在的毫秒数
year 年份
null
- 表示未知
4.字段属性
unsigned
无符号整数
声明了该列不能为负数
zerofill
- 不足的位数用0填充
自增
自动在上一条的基础上加1
通常用来设计唯一的主键 如index.
可以自定义设计主键的起始值和步长
非空not null
- 设置为not null, 如果不给赋值, 则报错
null
- 如果不填写值, 默认为null
默认default
- 设置默认值
5.创建表
CREATE TABLE IF NOT EXISTS `student` (`id` INT(4) NOT NULL AUTO_INCREMENT COMMENT '学号', --AUTO_INCREMENT自增`name` VARCHAR(30) NOT NULL DEFAULT '匿名' COMMENT '姓名',`pwd` VARCHAR(20) NOT NULL DEFAULT '123456' COMMENT '密码',`sex` VARCHAR(2) NOT NULL DEFAULT '男' COMMENT '性别',`birthday` DATETIME DEFAULT NULL COMMENT '出生日期',`address` VARCHAR(100) DEFAULT NULL COMMENT '住址',`email` VARCHAR(50) DEFAULT NULL COMMENT '邮箱',PRIMARY KEY (`id`) --设置主键)ENGINE=INNODB CHARSET=utf8
格式
CREATE TABLE [IF NOT EXISTS] `表名` (`字段名1` 列类型(长度) [属性] [属性] [索引] [注释],`字段名2` 列类型(长度) [属性] [属性] [索引] [注释],`字段名3` 列类型(长度) [属性] [属性] [索引] [注释])[表类型] [字符集类型] [注释]
6.关于数据库引擎
INNODB 默认使用 安全性高 事务处理 多表多用户操作
MYISAM 远古使用 节约空间 速度较快
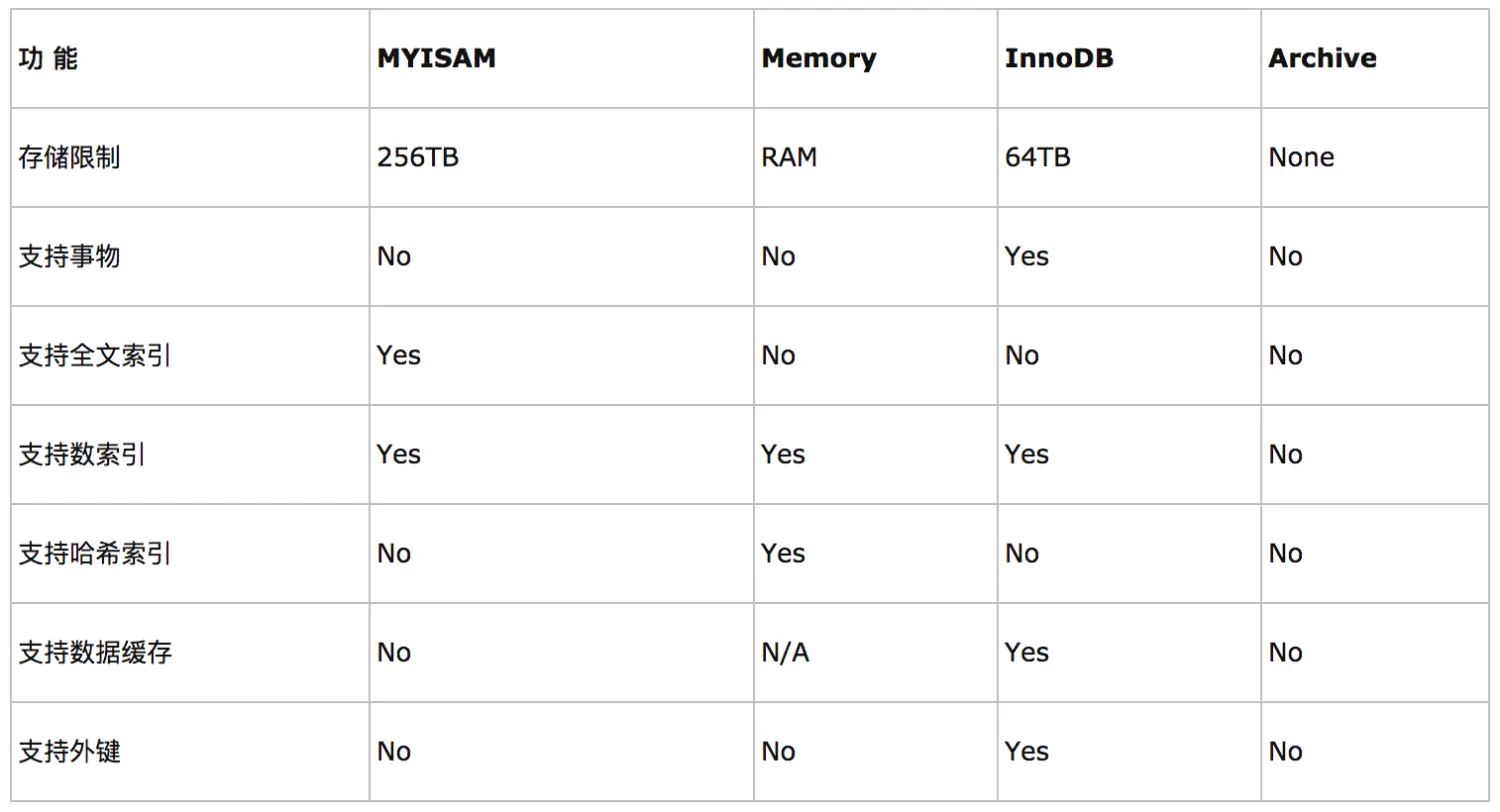
7.数据库操作
修改,删除表,字段
表操作
修改表的名字
ALTER TABLE 原表名 RENAME AS 新表名;ALTER TABLE student RENAME AS student2;
删除表
DROP TABLE [IF EXISTS] 表名;DROP TABLE [IF EXISTS] student;
所有的删除操作要加上判断,避免报错
字段操作
添加字段
ALTER TABLE 表名 ADD 字段名 列属性;ALTER TABLE student2 ADD age INT(10);
修改字段名
ALTER TABLE 表名 MODIFY 字段名 字段属性; --修改字段属性规范ALTER TABLE student2 MODIFY age VARCHAR(10);ALTER TABLE 表名 CHANGE 原字段名 新字段名; --字段重命名ALTER TABLE student2 CHANGE age age2;ALTER TABLE 表名 CHANGE 原字段名 新字段名 [列属性]; --还可以修改列属性ALTER TABLE student2 CHANGE age age2 varchar(10);
删除字段
ALTER TABLE 表名 DROP 字段名;ALTER TABLE student2 DROP age2;
8.数据管理
逻辑运算符 比较运算符
| 符号 | 描述 | 语法 |
|---|---|---|
| AND | 类似 && 与 | a&&b 或者 a AND b |
| OR | 类似 || 或 | a||b 或者 a OR b |
| BETWEEN … AND … | 类似 [a,b] | BETWEEN a AND b |
| LIKE | SQL匹配 | a LIKE b |
| IN | 在…里 | a IN (b,c,d,e) |
添加外键约束
ALTER TABLE `表名` ADD CONSTRAINT `外键名` FOREIGN KEY(`内表的键名`) REFERENCES `外表名`(`外表的键名`);ALTER TABLE `student` ADD CONSTRAINT `FK_gradeid` FOREIGN KEY(`gradeid`) REFERENCES `grade`(`gradeid`);
数据操纵语言DML
数据操纵语言DML主要有三种形式:
- 插入:INSERT
- 更新:UPDATE
- 删除:DELETE
添加数据
| name | age | id |
|---|---|---|
INSERT INTO `表名` (`字段1`,`字段2`, `字段3`) VALUES ('值1', 值2, 值3);INSERT INTO `student` (`name`,`age`, `id`) VALUES ('william', 19, 20193818);--可插入多个,只需要满足一一对应.INSERT INTO `student` (`name`,`age`, `id`) VALUES ('william', 19, 20193818),('lea',19,20190001);--字段可以省略,只需值与字段顺序一一对应INSERT INTO `student` VALUES ('william', 19, 20193818);INSERT INTO `student` VALUES ('william', 19, 20193818),('lea',19,20190001);
修改数据
UPDATE `表名` SET `要改的字段1`=`值1`, `要改的字段2`=`值2` [条件]; --不加条件则会修改全部!!!UPDATE `student` SET `name`=`Kevin` WHERE `id`=20193818;UPDATE `student` SET `name`=`Kevin`,`age`=3 WHERE `id`=20193818; --修改多个数据
删除数据
DELETE FROM `表名` [条件]; --不加条件则全部删除!!!!准备跑路!!DELETE FROM `student` WHERE id=1;--清空表TRUNCATE `表名`;TRUNCATE `student`;
相同: 两种删除都只删除数据, 不删除表的结构和索引约束
不同:
TRUNCATE会重新设置自增列, 计数器归零, 且不影响事务.
DELETE FROM不会影响自增
关于DELETE
- 在INNODB中, 数据库重启后, 自增列从1开始(存在内存中, 断电丢失)
- MYISAM中, 数据库重启后继续从上一个自增列开始(存在文件中, 不会丢失)
数据查询语言DQL
SELECT完整语法
SELECT[ALL|DISTINCT|DISTINCTROW|TOP]{*|talbe.*|[table.]field1[AS alias1][,[table.]field2[AS alias2][,…]]}FROM tableexpression[,…][IN externaldatabase][WHERE…][GROUP BY…][HAVING…][ORDER BY…] --后面几个可选句子的顺序不能改变[WITH OWNERACCESS OPTION]
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE
子句组成的查询块:
SELECT <字段名表>
FROM <表或视图名>
WHERE <查询条件>
基本查询
SELECT `字段名1`,`字段名2` FROM `表名`;SELECT `studentname`,`studentno` FROM `student`;
SELECT `字段名1` AS 显示名1,`字段名2` AS 显示名2 FROM `表名`; --给字段起别名SELECT `studentname` AS 学生名字,`studentno` AS 学号 FROM `student`;
字符串连接
SELECT CONCAT('字符串',`字段名`) AS 显示名 FROM `表名`;SELECT CONCAT('姓名:',`studentname`) AS 学生姓名 FROM `student`;
去重
SELECT DISTINCT `字段名` FROM `表名`; --DISTINCT关键字使得查询得的指定字段结果相同的只显示一个, 实现去重SELECT DISTINCT `studentno` FROM `student`;
表达式
SELECT VERSION(); --后可接函数SELECT 3*6 AS 计算; --可接表达式SELECT @@auto_increment_increment AS 步长 --可接变量
--例如将所有学生成绩+1SELECT `studentno` AS 学号, `studentresult`+1 AS 分数 FROM result;
模糊查询
IN 用于查询一个或多个精确的条件
LIKE 可以用于模糊查询, 常与%(代表任意个字符), _(代表一个字符)使用
--查询来自广西或重庆的学生名字SELECT `studentname` FROM `student` WHERE `address` IN (重庆, 广西);--查询姓覃的学生名字SELECT `studentname` FROM `student` WHERE `studentname` LIKE '覃%';--查询姓覃名由两个字组成的学生名字SELECT `studentname` FROM `student` WHERE `studentname` LIKE '覃__';
联表查询

LEFT JOIN会以左表为基准, 不管在右表中是否匹配, 只要查询的字段在左表中满足就会被查询出来.
RIGHT JOIN会以右表为基准, 不管在左表中是否匹配, 只要查询的字段在右表中满足就会被查询出来.
INNER JOIN
排序
SELECT `字段1`,`字段2`,xxxFROM `表名`ORDER BY `按xx字段` DESC --DESC降序 ASC升序SELECT `subjectno`,`subjectname`,`classhour`,`gradeid`FROM `subject`ORDER BY `classhour` DESC
分页
SELECT `字段1`,`字段2`,xxxFROM `表名`LIMIT 起始位置, 查询条数SELECT `subjectno`,`subjectname`FROM `subject`LIMIT 2,10 --显示下标从2开始的10条数据
子查询
SELECT `字段1`,`字段2`,xxxFROM `表名`WHERE `字段1`=(SELECT `字段1` FROM `其他表` [WHERE `xxx`= x])-- 查询里面套查询
分组和过滤
GROUP BY+ GROUP_CONCAT() : 表示分组之后,根据分组结果,使用 group_contact() 来放置每一组的每字段的值的集合
SELECT deparmant, GROUP_CONCAT(`name`) FROM employee GROUP BY deparmant
GROUP BY + HAVING 用来分组查询后指定一些条件来输出查询结果, 实现过滤
SELECT deparmant, GROUP_CONCAT(salary), SUM(salary) FROM employeeGROUP BY deparmantHAVING SUM(salary) > 9000;
9.MySQL函数
参考官方文档: https://dev.mysql.com/doc/refman/8.0/en/func-op-summary-ref.html
常用函数
与其他语言常用函数类似,ABS() CEIL() FLOOR() 等
聚合函数
COUNT() 用于计算行数
SELECT COUNT(列名); --忽略nullSELECT COUNT(*); --不忽略nullSELECT COUNT(1); --不忽略null
SUM() 求和
SELECT SUM(字段名) FROM 表名;
AVG() 求平均
SELECT AVG(字段名) FROM 表名;
10.事务
事务是恢复和并发控制的基本单位。
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability)。持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
手动处理事务的步骤
-- MySQL事务是自动提交的-- 实现手动处理事务,需关闭自动提交SET autocommit = 0;-- 事务开始START TRANSACTION-- 事务中语句INSERT xxxINSERT xx-- 事务成功,则提交COMMIT-- 事务失败,则回滚ROLLBACK-- 事务结束SET automommit = 1-----------------扩展----------------------- 事务中还可以设置保存点SAVEPOINT 保存点名-- 回滚到保存点ROLLBACK TO SAVEPOINT 保存点名-- 撤销保存点RELEASE SAVEPOINT 保存点名
11.索引
索引的分类
主键索引 (PRIMARY KEY)
- 只能有一个列为作为主键, 不能重复
唯一索引 (UNIQUE KEY)
- 唯一索引可以有多个
常规索引 (KEY/INDEX)
- 默认的索引
全文索引 (FullText Index)
- 特定数据库才有如MYISAM
索引的原则
- 索引不是越多越好
- 不要对经常变动的数据加索引
- 小数据量的表不需要加索引
- 索引一般加在常用来查询的字段上
12.用户管理
关于用户的管理就是在mysql数据库的user表中进行增删改查
-- 创建用户CREATE USER 用户名 IDENTIFIED BY '密码';-- 修改当前用户密码SET PASSWORD = PASSWORD('新密码');-- 修改制定用户密码SET PASSWORD FOR 指定用户名 = PASSWORD('新密码');-- 重命名RENAME USER 原用户名 TO 新用户名;-- 给用户授权GRANT 权限名 ON 库.表 TO 用户名;-- 查询权限SHOW GRANT FOR 用户名;-- 撤销权限REVOKE 权限名 ON 库.表 FROM 用户名;-- 删除用户DROP USER 用户名;
13.数据库备份
导出
方法1: 复制物理文件
复制data文件夹中的文件
方法2: 使用sqlyog等可视化软件导出
方法3: 在使用命令行导出
# mysqldump -h主机 -u用户 -p密码 库 [表1 表2 表3] >存储位置/文件名mysqldump -hlocalhost -uroot -p123456 school student >D:/student.sql
Bash中导入
先登录mysql
mysql -uroot -p123456source D:/student.sql
14.三大范式
第一范式 (1NF)
要求属性具有原子性,不可再分解;
每列描述的事情不可再分.
第二范式(2NF)
记录的惟一性,要求记录有惟一标识,即实体的惟一性,即不存在部分依赖;
每张表只描述一件事.
第三范式(3NF)
是对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
每一列与主键直接相关, 不能间接相关.
规范与性能间的权衡
- 过于追求规范会导致性能下降, 使用体验下降
- 在商用中还可能导致成本提高
15.JDBC(Java数据库连接)
使用Java连接数据库的一般步骤:
import java.sql.*;public class JdbcTest {public static void main(String[] args) throws ClassNotFoundException, SQLException {// 1. 加载驱动Class.forName("com.mysql.cj.jdbc.Driver");// 2. 获得用户信息和url对象// url = "协议://主机地址:端口/数据库名?参数1&参数2&参数3";String url = "jdbc:mysql://localhost:3306/jdbcstudy?useUnicode=true&characterEncoding=utf8&uesSSL=true&serverTimezone=GMT";String username = "root";String password = "mysql824484";// 3. 连接数据库得到数据库对象connectionConnection connection = DriverManager.getConnection(url, username, password);// 4. 获得执行SQL的对象statementStatement statement = connection.createStatement();// 5. 将SQL语句的对象通过statement对象去执行,得到返回值集对象, 查看结果String sql = "SELECT * FROM users";ResultSet resultSet = statement.executeQuery(sql);// 返回值集对象中封装了所有查询到的数据, 通过getXxxx方法可以得到具体的值while (resultSet.next()) {System.out.println("id: " + resultSet.getObject("id"));System.out.println("Name: " + resultSet.getObject("NAME"));System.out.println("pwd: " + resultSet.getObject("PASSWORD"));System.out.println("birthday: " + resultSet.getObject("birthday"));System.out.println("---------------------------------------------------------------");}// 6. 释放连接 以对象生成的倒序逐一释放resultSet.close();statement.close();connection.close();}}
在实际操作中, 常把加载驱动, 用户信息和url以及释放连接写成封装成工具类方便直接调用
并编写增删改查的方法
执行SQL的对象statement存在漏洞, 通过SQL注入骗过数据库非法获得数据
所以引入了PreparedStatement
// 4,5. 获得执行SQL的对象prepareStatement,将SQL语句的对象通过prepareStatement对象去执行,得到返回值集对象, 查看结果// 使用?占位符String sql = "insert into users(id, `NAME`, `PASSWORD`, email, birthday) values (?,?,?,?,?)";// 与之前的直接通过statement执行SQL的方法不同, 这里先获得preparedStatement对象并将sql传入进行预编译PreparedStatement preparedStatement = connection.prepareStatement(sql);// 再设置占位符所代表的值preparedStatement.setInt(1,4);preparedStatement.setString(2,"william");preparedStatement.setString(3,"123456");preparedStatement.setString(4,"793553732@qq.com");preparedStatement.setDate(5, new Date(new java.util.Date().getTime()));// 然后直接执行int i = preparedStatement.executeUpdate();if (i > 0) {System.out.println("插入成功!");}

若有收获,就点个赞吧
0 人点赞
