https://mp.weixin.qq.com/s/_PiXQ5e0jxjxWC2OMgYlzA
Jing 生信人 2021-03-08 07:40
人工智能是当代计算机应用的前沿,而人工智能与临床诊断的结合也是一个热点方向,因此,今天小编要和大家分享的是今年一月份发表在nature communications杂志(IF:12.121)上的一篇关于人工智能在败血症早期预测和诊断中的应用的文章。
医疗保健中使用非结构数据对败血症进行早期预测和诊断的人工智能
一、研究背景
医院中败血症是引起死亡的主要原因之一,而且败血症的治疗具有高度的时间敏感性,因此败血症的早期预测及诊断对降低死亡率至关重要。然而由于许多患者的迹象和症状与其他不那么严重的情况类似,导致败血症的早期预测及诊断具有很大的挑战。如今,现有的败血症诊断和早期预测方法多数情况下仅利用存储在电子病历(EMR)系统中的结构化数据来进行。然而,研究表明EMR系统中约80%的临床数据由非结构化数据组成。因此,今天小编要介绍一篇开发人工智能算法,使用结构化数据和非结构化临床记录来预测和诊断败血症的文章。
二、数据及方法
1.数据样本:研究使用MySQL从EMR系统中提取患者数据来建立预测算法。样本包括从2015年至2017年入院的5317名患者,其中有114602条临床记录。作者将样本分为训练和验证样本以及一个独立留出法的测试样本。训练和验证样本包括3722名患者(80162个临床记录条目),而独立的留出法样本包括1595名患者的34440个临床记录条目。研究使用每个病人会诊实例(临床记录)作为分析单位。
2.文本挖掘技术:除了预测模型中使用的结构化数据,作者还使用了非结构化自由格式文本的临床记录数据。在非结构化自由格式文本能够被分析和作为预测模型的一部分之前,作者首先利用LDA方法将非结构化自由格式文本编码成数值。LDA是一种无监督的技术,它根据在分析的文档中发现的单词出现的模式根据经验创建主题。因此,通过LDA作者从临床记录中生成主题,这些主题由一个向量表示。接着,作者使用以下五个步骤处理非结构化的自由格式文本。1)根据HIPAA指导方针和数据匿名化标准(健康保险携带和责任法案,HIPPA),删除临床记录中所有可能的标识符,包括:姓名、地理分区、邮政编码等所有元素。2)通过删除所有标点符号来识别文档中包含的文本;使用词性标注去掉定冠词和介词等。作者还删除了一长串在这些文本中常见但没有实际意义的与医学相关的词或短语。如report、progress等。在这两个步骤之后,创建了一个术语文档矩阵,其中行表示某个术语在文档中的出现情况,列表示文档。3)对处理后的文本应用一个文本过滤器,通过消除罕见词和加权多次出现的词来减少词的数量。4)使用LDA主题聚类算法来确定不同的主题。基于现有的文献,文本中可以开发的主题的数量是高度主观的,通常是观察的数量或数据集中主题的预期多样性的函数。作为鲁棒性检查的一部分,作者尝试了五个不同的迭代,分别是25、50、75、100和150个主题。对结果的后续分析发现五次迭代中产生了相似的结果;因此为了简洁起见报道了100主题模型。在100主题模型的基础上将100个主题分别交给3位研究人员,将其分为7个类别。所有文本挖掘都使用SAS Enterprise Miner 14.2进行处理。5)开发主题的步骤只需要在模型开发和验证阶段进行。当使用文本挖掘算法评估新的临床记录时,将使用开发的100个主题作为基准,帮助计算新的临床记录与这100个主题之间的匹配度。高拟合度量代表了新的临床记录与基准主题之间的高度相似性。
3.机器学习算法:集成方法是一种机器学习算法,利用多个分类器对预测结果进行(加权)投票来确定预测结果。这些方法通常比任何单一分类器的性能都要好。研究中作者使用投票集成。投票结合了来自多个其他模型的预测。研究中使用两个基本分类器:基于随机梯度下降(SGD)的逻辑回归和随机森林算法。组合规则是概率的平均值,即计算两个基本模型的平均概率作为投票概率。SGD是一种优化算法,通过从先前的拟合估计迭代学习来寻求最小化预测中的错误。该方法从训练样本中迭代地抽取随机样本来估计模型的参数,该模型用于将患者分类为患有败血症或未患的。它从每次采样迭代中学习,以确定分类的准确性,并调整参数估计,直到预测结果的进一步改进最小。对于每次迭代,计算预测参数β,并使用以下方程更新模型: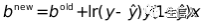 ,其中β是优化参数,lr是学习速率,
,其中β是优化参数,lr是学习速率,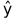 是由系数做出的预测,x是输入值。输入变量是结构化变量和在文本挖掘过程中提取的100个主题。用于投票的第二个分类器是随机森林分类器,败血症的情况是目标变量。两个分类器的概率被平均出来以得到投票集成模型中使用的最终概率。
是由系数做出的预测,x是输入值。输入变量是结构化变量和在文本挖掘过程中提取的100个主题。用于投票的第二个分类器是随机森林分类器,败血症的情况是目标变量。两个分类器的概率被平均出来以得到投票集成模型中使用的最终概率。
4.替换估计:为了便于比较,研究还使用了两种不同的备选估计器,即dagging和GBT。Dagging是一种集成方法,在现有的机器学习文献中广泛使用,特别是当数据是“有噪声”的时候。在dagging中,将训练数据样本划分为一组不相交的分层样本。然后,为这个过程选择使用SGD的基本分类器逻辑回归,并在每个脱节的样本中使用这个基本分类器训练数据。接下来,集成方法将基分类器训练的结果应用到验证数据样本中,计算所有子样本的平均值,预测结果基于所有子样本的投票。而GBT使用多个树的集合来创建更强大的分类和回归预测模型。关键思想是构建一系列树,其中每棵树都经过训练,以便尝试纠正系列中前一棵树的错误。作者添加固定数量的树,或者在损失达到可接受的水平或验证数据集上不再改进时停止训练。所有集成机器学习都是使用KNIME分析平台进行的。
5.其他模型诊断:作者也观察了PPV(精度)和灵敏度(召回)之间的权衡以及SERA算法的校准曲线。
6.在临床环境中建立SERA算法:作者提出了两种可能的模式,其中SERA算法可以在临床环境中操作。1)后台模型:SERA算法被设计为在后台运行。具体来说,它被配置为在关键事件期间使用最新的患者临床可用数据运行,例如在病房交接班期间。如果风险评分超过指定的临界值,EMR系统将向医生发出警报。如果有更多可用的计算资源,医院可以选择以固定的小时间隔运行它。对于一个拥有500个床位的大型医院,如果单独运行所有病例,那么SERA算法将花费约90秒的时间对所有500名患者进行评分。这种方法确保在医院内对患者进行持续、定期的败血症风险评估。2)Ad-hoc 模型:算法也可以设计成医生在EMR系统中更新临床记录后立即运行。在这种情况下,SERA算法将以一种特别的方式运行,因为只有在医生更新了患者的状态之后才会计算得分。从研究中可以看出,算法在败血症的早期预测方面优于医生,因此可以作为一个重要的早期预警指标,帮助医生进行诊断和患者护理。
三、研究的主要结果
1.数据及数据处理
这项研究调查了新加坡一家公立医院的病人,作者使用ICD-10代码构建败血症、严重败血症、败血症休克和是否有ICU住院的因变量。医院会将被诊断为有败血症的患者转到ICU病房;因此,至少有一种ICD-10编码并被收住ICU病房的患者被分配到败血症病例队列。所有其他不符合这些标准的患者被分配到非败血症对照组。训练和验证样本中有240例败血症患者,测试样本中有87例败血症患者。作者将败血症的发病时间定义为ICU病房的入院时间。由于数据是不平衡的,作者使用合成少数采样技术(SMOTE)来实现败血症病例和非败血症对照的1:1平衡数据。由于先前的文献认为,过采样将导致更精确的模型,而且早期研究已经使用了SMOTE算法,为其他临床情况开发了机器学习分类器。因此,作者也开发、测试和报告模型,而不进行任何过采样,以显示在败血症发病率相对较低的正常临床环境中操作该算法的可能性。
2.败血症早期风险评估算法(SERA)
首先图1概述了SERA算法的步骤。由于该算法利用临床记录和结构化数据来进行败血症风险评估,因此,该算法的分析单元是每个患者的会诊实例。作者采用这个分析单元,以确保算法可以在临床医生咨询、评估和诊断患者的典型临床环境中操作。SERA算法由两个相互关联的算法组成:诊断算法和早期预测算法。诊断算法在会诊时确定患者是否患有败血症,如果没有,早期预测算法将评估患者在接下来的4、6、12、24和48小时发生败血症的风险。对于诊断算法,作者将每次会诊的EMR系统临床记录与EMR系统中可用的最新结构化变量相结合,如表1所示。这些数据用于在会诊时对患者是否患有败血症进行分类。对于早期预测算法,其数据结构与诊断算法相似,不同之处在于,当患者确诊为败血症(即转入ICU)时,早期预测算法不会考虑任何来自样本的咨询情况。由于阳性败血症会诊具有与败血症病情密切相关的特征,因此,为了防止算法的预测能力出现偏颇,这是必要的。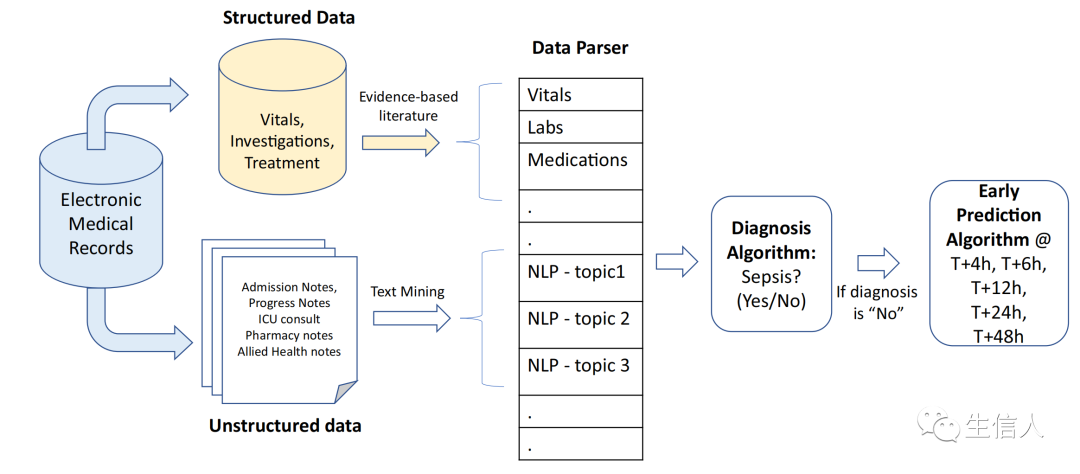
图1 SERA算法步骤
表1 预测算法中使用的结构变量列表
3.处理临床病历和机器学习
这一部分在使用非结构化的临床笔记作为预测因子之前,作者先将NLP应用于这些笔记,特别是LDA主题建模算法。在进展记录中找到主要主题提取出来,用数字加权,并与表1中的结构化变量数据相结合。作者通过将NLP LDA模型应用于临床笔记数据集,确定了100个常见的文本主题,依次分为以下七个类别:(1)临床状态;(2)沟通;(3)实验室测试;(4)非临床状态;(5)社会关系;(6)症状;(7)治疗。在诊断算法和早期预测算法中,利用100个主题的数值负荷和结构化数据作为预测因子。在诊断算法中,数据采用投票集成机器学习算法。为了比较也使用dagging和GBT作为两个替代分类器。当患者被诊断为未患败血症时,早期预测算法将使用投票集成机器学习方法预测患者在接下来的4、6、12、24和48小时内是否有患败血症的风险。早期预测算法的因变量分别是患者在接下来的4、6、12、24、48 小时是否会发生败血症。经过训练和验证的模型随后使用独立的测试样本进行测试。
接着作者展示了SERA算法对过采样和非过采样数据的测试结果。SMOTE模型给出了典型的机器学习预测模型的结果,其中败血症病例的发病率很高,与非败血症病例的发病率相当(表2)。非SMOTE模型显示了该模型在典型的败血症发病率较低的临床环境中的表现(表3)。分析发现,对于诊断算法,测试样本的AUC为0.94,敏感性为0.89,特异性为0.85,阳性预测值(PPV)为0.85。诊断算法的AUC高于以往研究。此外,在被医生诊断为败血症之前,算法可以预测患者是否有感染败血症的高风险。预测败血症发生前48小时的算法AUC为0.87。AUC在败血症发生前24小时提高到0.90,在败血症发生前12小时提高到0.94。此外,算法在12小时前的预测比先前的研究具有更高的AUC、灵敏度、特异性和PPV。24而小时提前期早期预测具有0.90的高AUC和至少0.80的敏感性、特异性和PPV值,这额外的早期预测时间对于改善临床结果至关重要。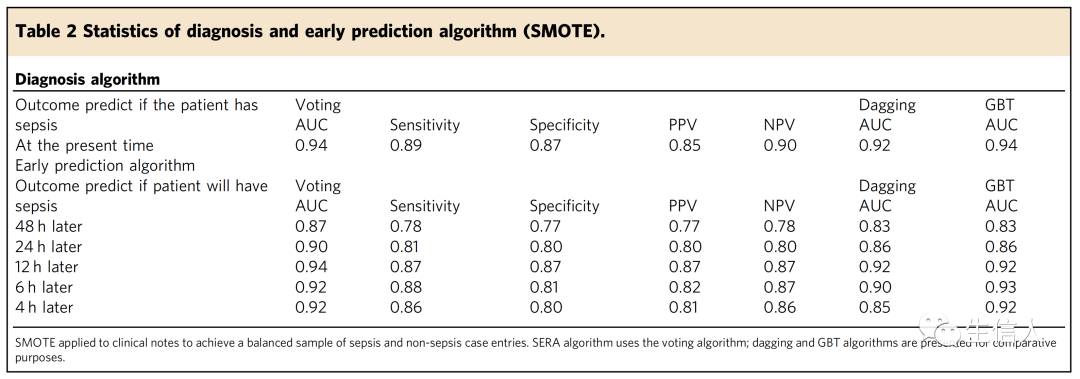
表2 诊断与早期预测算法(SMOTE)的统计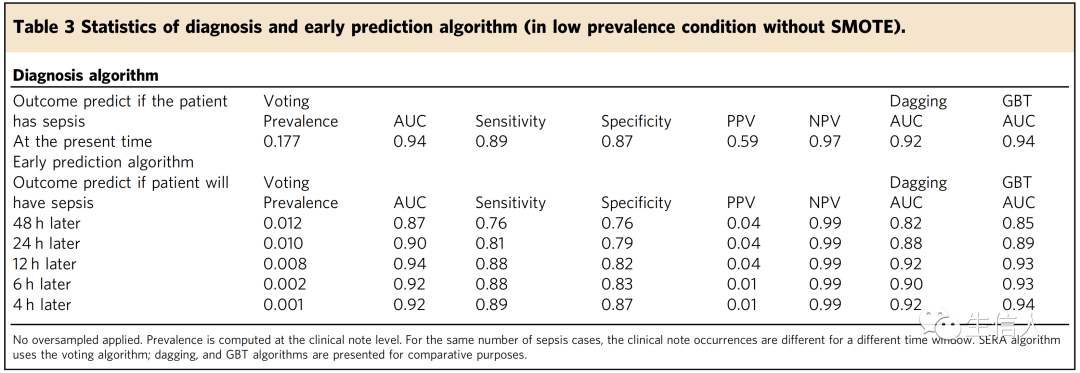
表3 诊断和早期预测算法的统计(在低患病率条件下,无SMOTE)
4.SERA算法与人为预测
接下来作者比较了在临床环境中,算法与其他预测评分系统的性能,并将算法的预测与诊断败血症或预测感染死亡率的标准临床实践相对照。临床实践通常采用标准化的评分系统,如SIRS、SOFA、qSOFA和MEWS来预测感染引起的败血症症或死亡率。meta分析发现,这四种评分系统在败血症发作前4 h的典型真阳性率(TPR) AUC为0.50 ~ 0.78,TPR为0.56 ~ 0.8,假阳性率(FPR)为0.16 ~ 0.50。作者根据报告的TPR和FPR评分绘制了早期预测算法的ROC曲线(图2a)。此外,作者也评估了医院医生诊断败血症的TPR和FPR。在图2a中,可以看到在败血症发作前4小时,算法在预测测试样本败血症方面优于医院医生。
此外,SERA算法的准确率超过了以往研究中报道的基于人的评分方法,如qSOFA、MEWS、SIRS和SOFA等。图2b给出了败血症前48、24、12、6、4 小时各时间点早期预测算法的ROC曲线。可以观察到ROC从48小时提高到12小时,并在12小时后保持在一个类似的水平。在所有时间段,算法的ROC值都超过了医院医生的预测。进一步作者将算法在48、24、12、6和4 小时的预测与文献报道的MEWS、qSOFA、SIRS和SOFA在4 小时标记时的预测精度进行对比。可以观察到,即使在败血症前4小时进行评估,SERA算法对所有四个阶段的预测通常都优于MEWS、qSOFA、SIRS和SOFA预测得分。为了检验早期预测算法的实用性,作者也在48、24、12、6和4 小时标记处计算早期预测算法的TPR和FPR(图3)。作者也观察到,在败血症发作48小时后,算法可以检测到所有最终患者中的0.78,而在败血症发作前12小时内,这个预测(TPR)至少提高到0.86。另一方面,医院医生在48小时后只能检测到大约0.53名最终败血症患者,而在6小时后这一比例仅略微增加到0.58。在4小时,医院医生观察到TPR明显增加到0.65。在所有时期,算法预测败血症的TPR高于医院医生0.21 ~ 0.32。这表明,与仅依靠医院医生评估相比,算法有潜力增加早期败血症检测。SERA算法的FPR从48小时的0.23变化到12小时的0.13(图3b)。然而,医院医生预测的FPR明显高于算法,从48小时到4小时,FPR在0.34 ~ 0.27之间变化。因此,使用SERA算法有可能减少误报。图3显示,医院医生的TPR和FPR仅在4小时时间点达到峰值,这意味着医生有一个更短的医疗干预的前置时间。相反,SERA算法可以在败血症发作前48小时达到相当早的预测率,这意味着医生可以更早地预警败血症的发作,从而有更多的时间进行更有效的干预。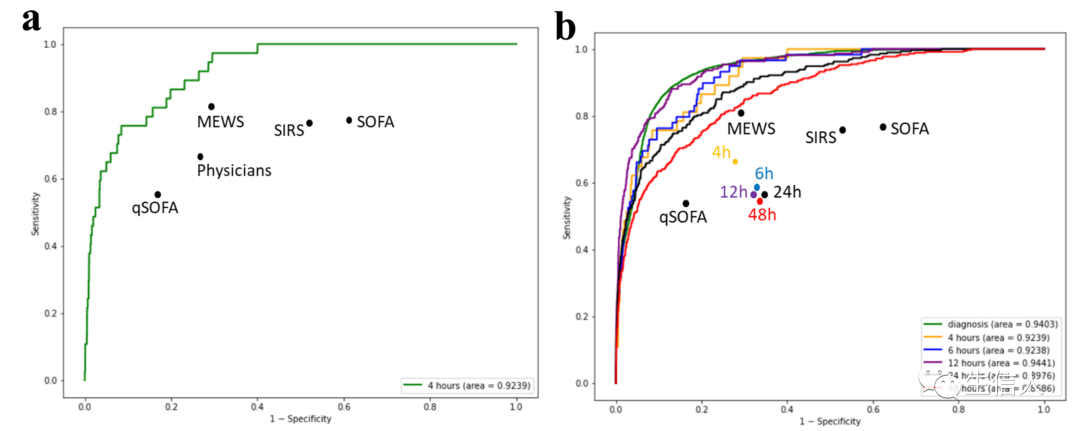
图2 早期预测的ROC曲线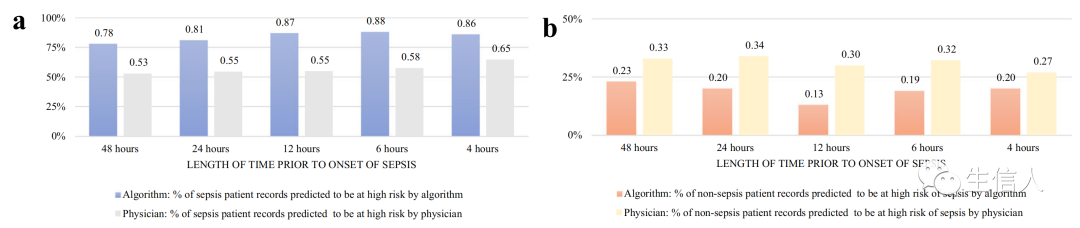
图3 比较SERA算法与医师的性能
5.非结构临床文本在早期败血症预测中的益处
在这一部分,作者为了量化非结构化临床记录在SERA算法中增加的预测价值,首先仅使用结构化变量来诊断和预测败血症,然后比较算法的性能(图4)。可以观察到,虽然增加临床文本的使用确实提高了SERA诊断和早期预测算法的性能但改善甚微。此外,当考虑败血症前12到48小时的时间框架时,可以注意到使用临床文本进行早期预测有相当大的益处,可以观察到对于12 - 48小时早期预测的SERA算法,添加的临床文本将(1)AUC提高了0.10至0.15,(2)敏感性提高了0.07-0.13,(3)特异性提高了0.08-0.14。结果也表明,在接近败血症发作的时间段内,败血症的可测量症状表现为结构性变量,如血压值的下降。在这种情况下,增加临床文本的使用对SERA算法只提供了较小预测收益,因为结构变量捕获了大多数败血症症状。因此,医生的判断和患者预后的定性输入提供了额外的关键数据,可用于预测败血症。
图4 比较SERA算法与无临床文本模型的性能
6.SERA算法在低败血症流行环境中的应用
作者在一项从2009年到2014年对409家美国医院的回顾性队列研究中,发现败血症的患病率在所有住院患者的1.8%到12%之间,平均流行率为6%,并且随着时间的推移保持相对稳定。尽管在临床环境下败血症的自然患病率较低,但大多数研究使用过采样数据集开发败血症预测算法,其患病率显著高于50%。因此,在研究中,作者开发了既适用于过采样环境,也适用于流行率较低情况(如典型临床环境中所见)的模型。出于临床应用的目的,作者模拟了败血症患病率的变化如何影响PPV(表4)。例如,在12小时早期预测中,败血症患病率低于1.8%的医院的估计算法PPV为8.3%。如果败血症的患病率增加到12%,估计PPV增加到40.25%。模拟结果说明了在自然临床环境中应用SERA算法的能力,其中败血症的流行程度取决于临床专业类型和/或机构的位置。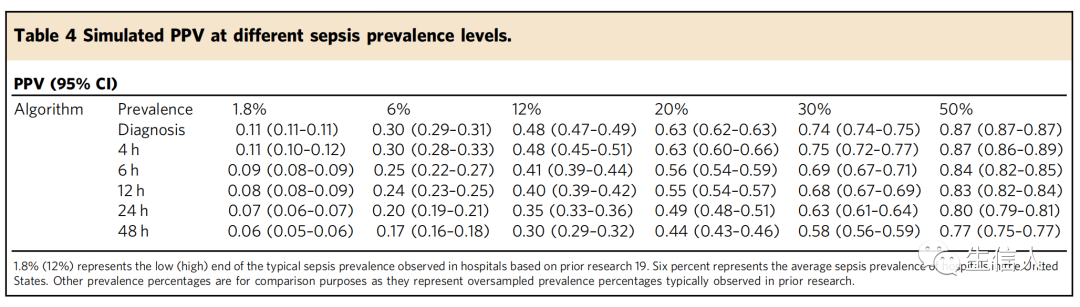
表4 模拟不同败血症流行水平下的PPV
到这里,文章的主要内容都介绍完了。可以看出文章针对败血症的早期预测及诊断这一问题,利用临床记录的结构化及非结构化数据结合机器学习方法开发出了败血症的预测及诊断模型,并从多个角度及情况对模型进行了评估。不论是败血症还是其他复杂疾病的研究,随着计算机与医疗的发展,这种人工智能与医疗的结合的分析可能都会变成一个非常重要的趋势。因此,无论是医生还是其他科研工作者,都可以学习这种利用临床数据资源结合人工智能方法开发实用算法或模型的研究角度。
欢迎关注生信人
转录组| 甲基化 | 重测序 | 单细胞 | m6A|多组学
cytoscape | limma | WGCNA |水熊虫传奇|linux
电泳 | PCR | 测序简史 | 核型 | NIPT | 基础实验
基因| 2019-nCoV | 富集分析 | 联合分析 |微环境
瘟疫追凶| 思路汇总| 学者 | 科研 | 撤稿| 读博|工作

若有收获,就点个赞吧
0 人点赞
