UTF-8编码中的汉字,由3~4个字节表示,大部分为3个字节。基本汉字的编码范围为4E00-9FA5,如4E00转换为二进制为01001110 00000000,从后往前套模板发现最少需要三个字节
Unicode定义了Unicode码点和字符之间的映射关系。一个Unicode码点就是一个非负整数,每个Unicode码点唯一对应一个字符。目前Unicode码点的范围从 0 到0x10FFFF。由于整数范围足够大,Unicode可以表示任何可见或不可见的字符。
单兴聪 12-30 20:54:36
一个中文在unicode中占用2个字节。1个字节由8位二进制组成
编码:将字符转换为字节的过程
解码:将字节转换为字符的过程
字符对应于码点。每个字符对应的unicoe码点都是一致的
范围为0-0x10FFFF
然后unicode和utf-8有一个对应关系表
如下: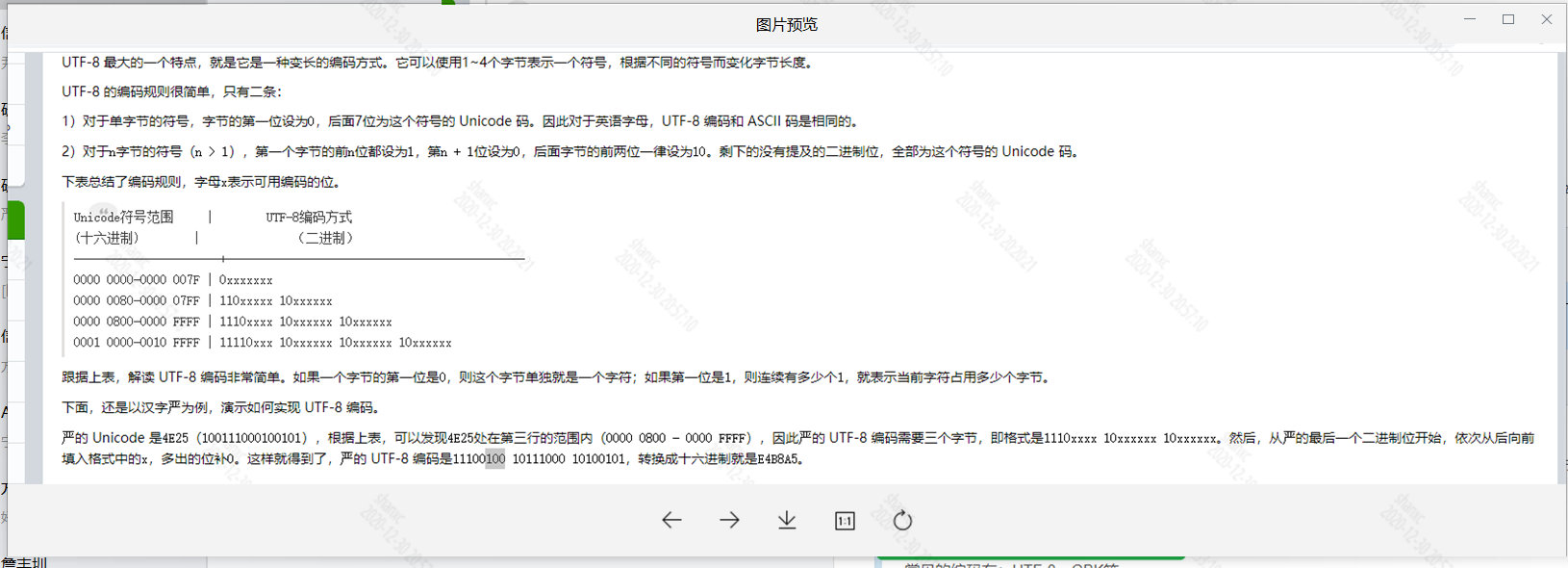
实际上传输还是以转换为utf-8编码格式对应的二进制流进行传输的
此链接介绍了unicode和utf-8的区别与联系

若有收获,就点个赞吧
0 人点赞
