在Python编程中,多线程编程是非常重要的知识点。在本篇中我们主要来讲讲如何实现多线程编程以及如何实现线程同步。
实现多线程编程主要有两种方式,一种是实例化Thread类来实现,另外一种是通过继承于Thread类来实现。
一、通过实例化Thread类来实现多线程
我们来看个实际的例子,代码如下:
from threading import Threadimport timedef func1():print("func1 started")time.sleep(2) # 模拟耗时操作print("func1 ended")def func2():print("func2 started")time.sleep(2) # 模拟耗时操作print("func2 ended")if __name__ == "__main__":t1 = Thread(target=func1)t2 = Thread(target=func2)start_time = time.time()t1.start()t2.start()print("last time: {}".format(time.time() - start_time))
这段代码非常简单,我们使用Thread类的实例来生成了两个线程,并分别执行对应的func1和func2方法。运行该代码后,生成的结果如下:
大家可以看到,运行结果中显示的last time只有0.000几秒,如果按照代码逻辑,这里每个线程都等待了2秒,那么在线程结束后打印这个时间应该是超过2秒才对,不可能会输出0.000这样的结果。那这是什么原因引起的呢?要回答这个问题,首先要搞清楚我们写的这段代码运行时有几个线程,每个线程之间又有什么关系。
- 这段代码运行时有几个线程?答案是有三个,我们在代码中创建的2个线程和程序的主线程。大家可以在print语句中打个断点运行就能看到确实有3个不同的线程在运行。

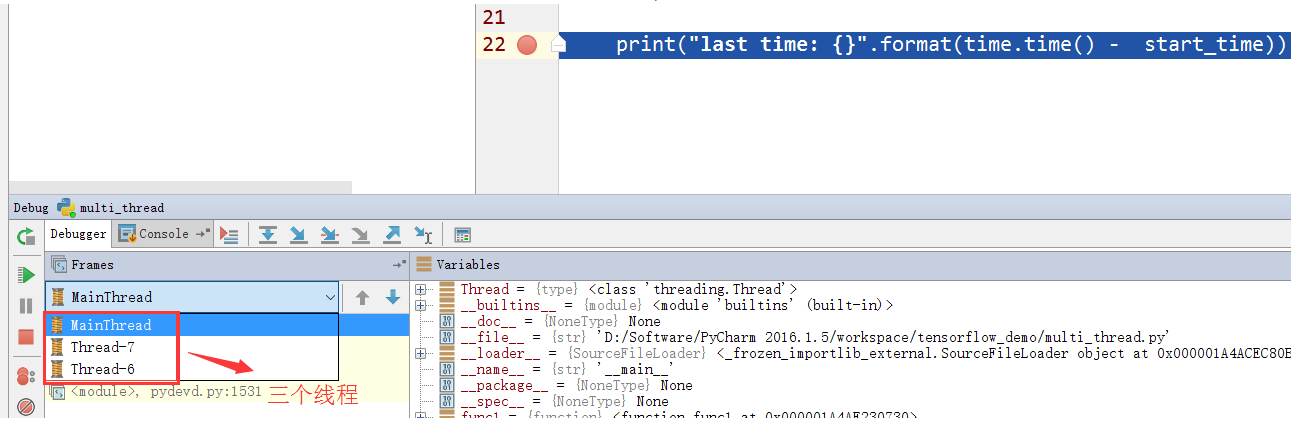
- 3个线程之间的运行关系是怎样的呢?在我们现在上面这段代码中,3个线程之间是完全独立的运行,没有任何关系,所以才会出现打印出0.000秒的结果。我们在运行时,最先启动的是主线程,然后我们在主线程中创建了2个不同的线程,之后,每个线程等待了2秒,但这里要注意,主线程并没有跟着它们一起等待,主线程创建完子线程后,即运行完t2.start()语句后,就立即执行了最后的print语句,随后主线程运行结束。两个子线程各自等待2秒后,分别结束,最终整个程序结束。注意,2个子线程之间运行也是独立的,所以我们可以看到运行结果有时是func1先结束,有时又是func2先结束,这个是随机的。
那么接下来大家可能会想问,如果我想要在所有子线程都结束后,再打印执行时间,应该怎么办?另外,如果我想主线程结束后,立即结束所有的子线程或者单独结束某个子线程,应该怎么办?
我们先来回答第一个问题,即“如果我想要在所有子线程都结束后,再打印执行时间,应该怎么办?”
要实现这个效果,我们可以在子线程中使用join方法。join方法的作用是让主线程等待子线程执行完成后,再执行主线程的代码,也就是说该子线程的代码会“阻塞”主线程的代码,主线程一定会在这个子线程的代码执行结束后再执行。我们来看看加了join方法后的效果:
from threading import Threadimport timedef func1():print("func1 started")time.sleep(2) # 模拟耗时操作print("func1 ended")def func2():print("func2 started")time.sleep(2) # 模拟耗时操作print("func2 ended")if __name__ == "__main__":t1 = Thread(target=func1)t2 = Thread(target=func2)start_time = time.time()t1.start()t2.start()t1.join() # 将thread1和主线程进行join,thread1将阻塞主线程直到thread1执行结束print("last time: {}".format(time.time() - start_time))


再次运行这段代码,可以看到我们打印出来的时间就是2秒了。这个2秒就是主线程等待thread1执行完毕后,再执行打印语句的效果。
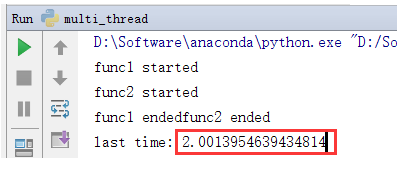
由于这里func1和func2都等待了2秒,所以我们会看到thread1和thread2几乎同时结束。为了能更明显地看到主线程只等待了thread1,没有等待thread2,我们可以把func2的休眠时间设置为4秒,然后再看看结果:
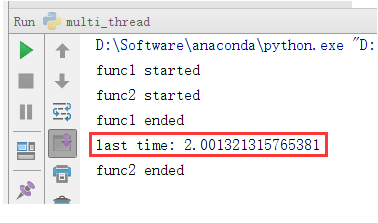
可以看到,确实只等待了thread1。如果我们把thread2也加上join,那么主线程同样也会等待thread2运行结束后再运行。
总结一下,join方法的作用就是让主线程等待子线程结束后再运行,用一句话形容就是“余生漫长,我永远在这里等你”。如果不设置join,则主线程和子线程之间就是“相濡以沫,不如相忘于江湖”,你管不了我,我也管不了你。
接下来,第二个问题,“如果我想主线程结束后,立即结束所有的子线程或者单独结束某个子线程,应该怎么办?”
要解决这个问题,必须用到setDaemon方法。Daemon在英文中是精灵,守护的意思,顾名思义这个方法的主要作用是让该子线程变成守护线程,给子线程设置为守护线程的时候,说明该线程不重要,当主线程结束的时候,会检查设置为守护线程的子线程是否结束,如果没有结束也会强制结束。我们在thread1中加上setDaemon方法看看实际效果,代码如下:
from threading import Threadimport timedef func1():print("func1 started")time.sleep(2) # 模拟耗时操作print("func1 ended")def func2():print("func2 started")time.sleep(2) # 模拟耗时操作print("func2 ended")if __name__ == "__main__":t1 = Thread(target=func1)t2 = Thread(target=func2)start_time = time.time()t1.setDaemon(True) # 将子线程设置为守护线程t2.setDaemon(True) # 将子线程设置为守护线程t1.start()t2.start()print("last time: {}".format(time.time() - start_time))
运行结果如下: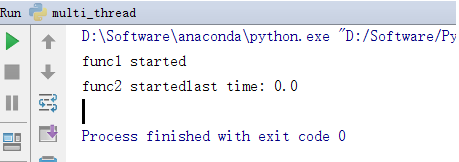
可见,主线程运行结束后,也把两个设置为守护线程的子线程结束掉了。如果我们只设置thread1为守护线程(即只在thread1中调用setDaemon方法),会发生什么情况呢?修改代码后,运行结果如下:
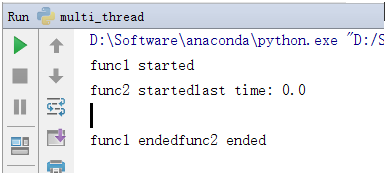
可以看到,两个子线程都运行完了。这里有点奇怪,按照之前的说法,不是将子线程设置为守护线程后,只要主线程运行结束,就会kill掉设置为守护线程的子线程吗?这里要注意一个特殊情况,当有多个子线程同时运行的情况,同时各个子线程运行时间不同(有快有慢),如果我们只在一个子线程上设置守护线程,那么只有在运行最慢的子线程上设置守护线程,主线程运行结束后才会kill掉这个守护进程。如果在其他运行时间较短的子线程上单独设置守护线程,其实是没有作用的,主线程运行结束后并不会kill掉这个运行时间较短的子线程,尽管这个子线程已经设置为了守护线程。比如我们来看看下面这个例子(注意代码中thread1的等待时间长于thread2):
from threading import Threadimport timedef func1():print("func1 started")time.sleep(3)print("func1 ended")def func2():print("func2 started")time.sleep(2)print("func2 ended")if __name__ == "__main__":t1 = Thread(target=func1)t2 = Thread(target=func2)start_time = time.time()t2.setDaemon(True)t1.start()t2.start()print("last time: {}".format(time.time() - start_time))
行结果如下: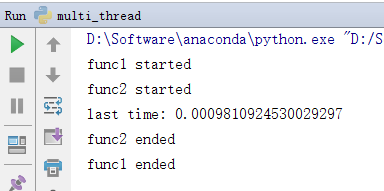
但如果我们在thread1上设置守护线程,thread2不设置(thread1运行时间较长),则主线程结束后会kill掉这个子线程。结果如下: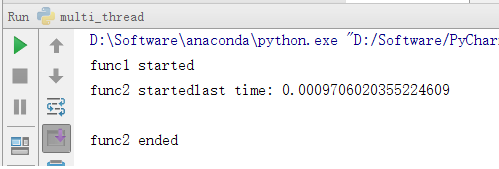
可见,运行较慢的thread1被kill掉了,并没有输入最后的end语句。
总结一下,setDaemon的作用就是“不能同月同日生,但求同月同日死”,不管子线程怎样运行,主线程结束,那么设置为守护进程的线程也会结束。
二、通过继承Thread类来创建多线程
接下来我们通过继承Thread类来创建多线程。我们来看一个实例,代码如下:
class Func1(Thread):def __init__(self, name):super().__init__(name=name) # 定义线程名称def run(self):print("func1 started")time.sleep(3)print("func1 ended")class Func2(Thread):def __init__(self, name):super().__init__(name=name) # 定义线程名称def run(self):print("func2 started")time.sleep(2)print("func2 ended")if __name__ == "__main__":t1 = Func1("t1")t2 = Func2("t2")start_time = time.time()t1.setDaemon(True)t1.start()t2.start()print("last time: {}".format(time.time() - start_time))
这两种方法创建的多线程从效果上没有任何区别,但一般来说继承类的方式创建更灵活,可以定义很多方法,但通过实例化的方式创建,写起来比较简单,方便写循环来批量创建多线程,在使用线程池的时候比较常用,大家可以根据情况自行决定用什么方法来创建。
接下来,创建了多线程之后,我们通常需要关心的另外一个问题是线程同步的问题,也就是确保线程的安全性。通常最简单的实现线程同步的方法是通过给操作全局变量的语句加锁来实现。一旦加锁之后,那么该语句将会被作为一个代码段整体执行,不会存在执行中间被中断的情况。我们用之前《深入理解GIL》中的例子来给大家看看怎么加锁,代码如下:
import threadingn = 0lock = threading.Lock()def add():global nglobal lockfor i in range(1000000):lock.acquire() # 获取锁n = n + 1lock.release() # 释放锁,必须释放,否则其他线程无法获得锁def sub():global nglobal lockfor i in range(1000000):lock.acquire()n = n - 1lock.release()if __name__ == "__main__":t1 = threading.Thread(target=add)t2 = threading.Thread(target=sub)t1.start()t2.start()t1.join()t2.join()print("n的值为:", n)
代码的关键是通过threading.Lock对象对要做操线程安全操作的语句加锁,这样来使得本来不是原子级的操作变成原子级的,这样就不会再出现之前说的同步问题。每次使用Lock时,必须先通过acquire方法获取锁,执行完后,要用release方法来释放锁。每个acquire语句在执行时,如果发现其他线程没有释放锁,那么会一直等待,所以锁操作完后,必须要释放,否则其他线程就会一直处于等待状态。
执行的这段代码,大家会发现n的值永远都是0,也就是我们预期的结果。但用了锁,也会引起一些问题,接下来,我们来讨论下在多线程状态下,使用锁可能会引起的一些问题。
- 使用锁会引起性能问题。这个是锁本身的机制引起的,所以锁的类型有很多,我们需要根据不同的应用场景来选择合适的锁。
2. 使用锁可能会引起死锁。
这两个问题是使用锁的时候最可能遇到的问题,我们将在专门的文章里面讲解这些问题。

若有收获,就点个赞吧
0 人点赞
