注意:查询、DM、事务(三大重点)
- 源数据(数据字典表)【oracle自带的】
- 不能进行DDL操作
- 也不能进行DM操作
- 对对象进行操作时可以
- 举例:大事务回滚(一般发生在非常特殊的场景下)
- oracle为了保护数据,会把之前做的动作全部重做一遍
- 伴随日志、锁等,导致性能影响
- 删字段(从表的角度)
- 把个块中寻找记录,并每条记录删除
- 把相关数据字典记录删除
- 数据规范
- 查询不用*,否则大数据集导致查询效率降低
- 进行运算时,先查询默认值是否为空,否则要使用nvl()等转换函数
- 日期的格式规范,全球化的日期,可能存在时区的问题
- 特殊
- 字符串使用between(界限问题)
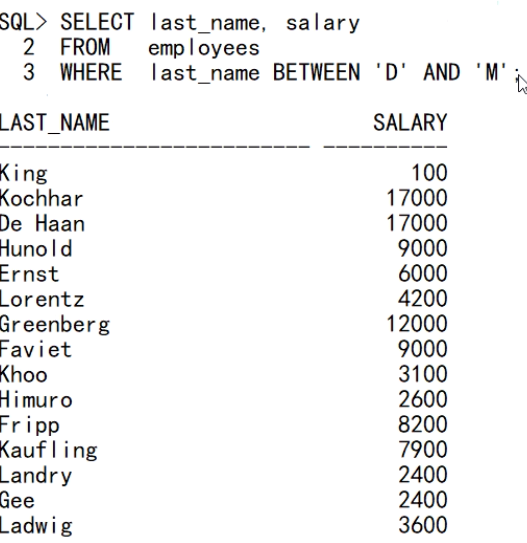
- 快速全索引扫描(oracle自动识别高级算法使用)

- 隐式类型转换带来的不走索引
- 索引关键字是不存空值的(需使用特殊值代替或者用转换函数做索引【不建议,消耗资源】)
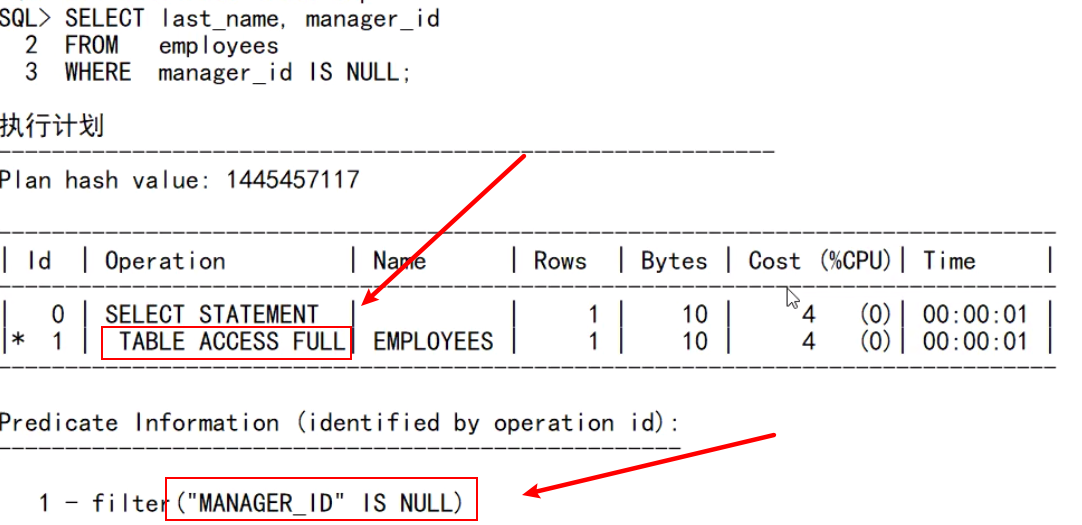
- oracle的索引优先级(数字>字符串)【隐式类型转换不一定是有利的,有时候我们自己进行转换】
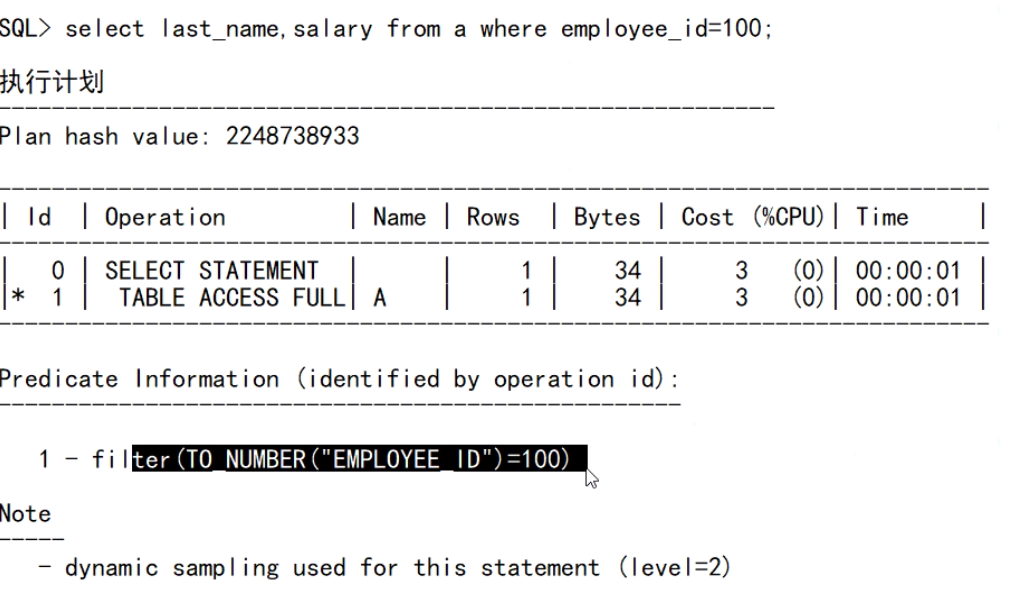
- avg()和sum()/count()的坑(具体看需求,是否要算全体还是拿奖金的部分人)

- RBU模式(手动定义处理逻辑)和CBU模式(自动选择高级算法)的区别【将索引字段的空值去掉就走索引,不去掉仍做全表扫描】

- 除了union all,其他都会有排序动作的(影响性能)
- sql查询质询顺序:
- from
- select(检查)
- where
- group by
- select(数据)
- having
- order by
- group by的常用函数(分组增强)
- rollup():小计、累计、总计



- grouping sets(用的很少,通常用语复杂报表)

- rollup():小计、累计、总计
- not in不能有null值,不然整个返回值都为空
- update相关子查询锁持续时间较长,要在空窗期使用
- 字符串使用between(界限问题)
- 结合数据特征,来优化sql查询,不能因为性能好,而去抛弃数据准确性(子查询返回单条记录一定可以,多条记录得看具体需求和数据情况【如:一个人仅在一个部门,且该部门只有一个管理者】)
- with会做数据快照(如果手动建立with语句就不会执行自动优化)


若有收获,就点个赞吧
0 人点赞
