kubeadm是官方社区推出的一个用于快速部署kubernetes集群的工具。
这个工具能通过两条指令完成一个kubernetes集群的部署:
# 创建一个 Master 节点kubeadm init# 将一个 Node 节点加入到当前集群中kubeadm join <Master节点的IP和端口 >
一、总体步骤
使用kubeadm方式搭建K8s集群主要分为以下几步
- 准备三台虚拟机,同时安装操作系统CentOS 7.x
- 对三个安装之后的操作系统进行初始化操作
- 在三个节点安装 docker, kubelet, kubeadm, kubectl
- 在master节点执行kubeadm init命令初始化
- 在node节点上执行 kubeadm join命令,把node节点添加到当前集群
- 配置CNI网络插件,用于节点之间的连通
- 通过拉取一个nginx进行测试,能否进行外网测试
二、 准备环境
k8s环境
| 角色 | IP |
|---|---|
| master | 10.4.104.169 |
| node1 | 10.4.104.170 |
| node2 | 10.4.104.171 |
| 用户名 | root |
| 密码 | 123qweASD |
然后开始在每台机器上执行下面的命令
# 关闭防火墙systemctl stop firewalldsystemctl disable firewalld# 关闭selinux# 永久关闭sed -i 's/enforcing/disabled/' /etc/selinux/config# 临时关闭setenforce 0# 关闭swap# 临时swapoff -a# 永久关闭sed -ri 's/.*swap.*/#&/' /etc/fstab# 根据规划设置主机名【master节点上操作】hostnamectl set-hostname k8smaster# 根据规划设置主机名【node1节点操作】hostnamectl set-hostname k8snode1# 根据规划设置主机名【node2节点操作】hostnamectl set-hostname k8snode2# 在master添加hostscat >> /etc/hosts << EOF10.4.104.169 k8smaster10.4.104.170 k8snode110.4.104.171 k8snode2EOF# 在master添加hostscat >> /etc/hosts << EOF10.4.107.207 k8smaster10.4.107.208 k8snode110.4.107.209 k8snode2EOF# 将桥接的IPv4流量传递到iptables的链cat > /etc/sysctl.d/k8s.conf << EOFnet.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1EOF# 生效sysctl --system# 时间同步yum install ntpdate -yntpdate time.windows.com
三、 安装Docker/kubeadm/kubelet
所有节点安装Docker/kubeadm/kubelet ,Kubernetes默认CRI(容器运行时)为Docker,因此先安装Docker
3.1 安装Docker
配置Docker的阿里yum源
cat >/etc/yum.repos.d/docker.repo<<EOF[docker-ce-edge]name=Docker CE Edge - \$basearchbaseurl=https://mirrors.aliyun.com/docker-ce/linux/centos/7/\$basearch/edgeenabled=1gpgcheck=1gpgkey=https://mirrors.aliyun.com/docker-ce/linux/centos/gpgEOF
yum方式安装docker
ce—社区版
ee—企业版
# yum安装yum -y install docker-ce# 查看docker版本docker --version# 启动dockersystemctl enable dockersystemctl start docker
配置docker的镜像源
cat >> /etc/docker/daemon.json << EOF{"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]}EOF
重启docker
systemctl restart docker
3.2 添加kubernetes软件源
还需要配置一下yum的k8s软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF[kubernetes]name=Kubernetesbaseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64enabled=1gpgcheck=0repo_gpgcheck=0gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpgEOF
3.3 安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
# 安装kubelet、kubeadm、kubectl,同时指定版本yum install -y kubelet-1.18.0 kubeadm-1.18.0 kubectl-1.18.0# 设置开机启动systemctl enable kubelet
四、 部署Kubernetes Master【master节点】
在 10.4.104.169 执行,也就是master节点 ```shell kubeadm init \ —apiserver-advertise-address=10.4.104.169 \ —image-repository registry.aliyuncs.com/google_containers \ —kubernetes-version v1.18.0 \ —service-cidr=10.96.0.0/12 \ —pod-network-cidr=10.244.0.0/16
kubeadm init \ —apiserver-advertise-address=10.4.107.207 \ —image-repository registry.aliyuncs.com/google_containers \ —kubernetes-version v1.18.0 \ —service-cidr=10.96.0.0/12 \ —pod-network-cidr=10.244.0.0/16
由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址,【执行上述命令会比较慢,因为后台其实已经在拉取镜像了】,我们 docker images 命令即可查看已经拉取的镜像<br />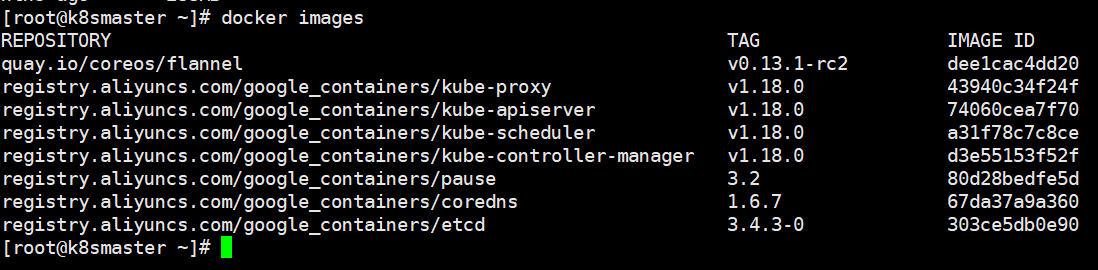<br />当我们出现下面的情况时,表示kubernetes的镜像已经安装成功<br />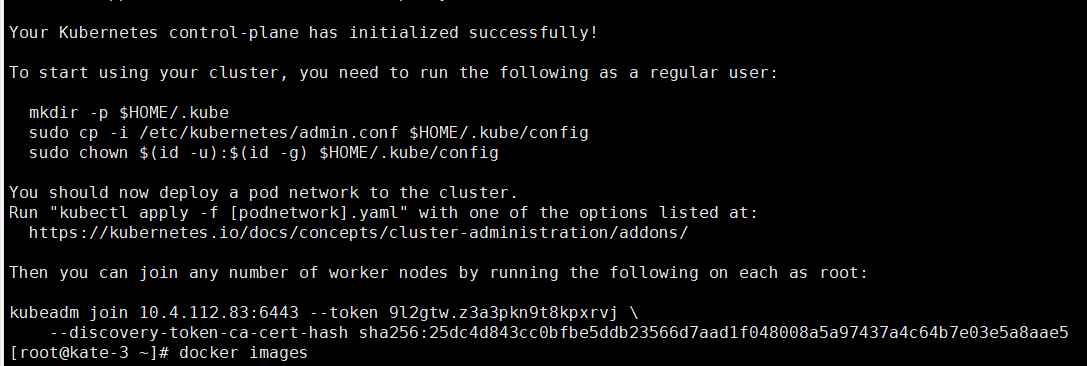<br />使用kubectl工具 【master节点操作】
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
执行完成后,我们使用下面命令,查看我们正在运行的节点
kubectl get nodes
<br />能够看到,目前有一个master节点已经运行了,但是还处于未准备状态<br />下面我们还需要在Node节点执行其它的命令,将node1和node2加入到我们的master节点上<a name="dNqSR"></a>## 五、 加入Kubernetes Node【Slave节点】下面我们需要到 node1 和 node2服务器,执行下面的代码向集群添加新节点<br />执行在kubeadm init输出的kubeadm join命令:> 注意,以下的命令是在master初始化完成后,每个人的都不一样!!!需要复制自己生成的```shellkubeadm join 10.4.104.169:6443--token 8j6ui9.gyr4i156u30y80xf \--discovery-token-ca-cert-hashsha256:eda1380256a62d8733f4bddf926f148e57cf9d1a3a58fb45dd6e80768af5a500
默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,操作如下:
kubeadm token create --print-join-command
当我们把两个节点都加入进来后,我们就可以去Master节点 执行下面命令查看情况
kubectl get node
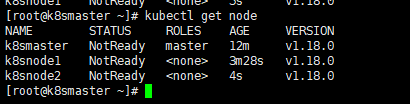
六、 部署CNI网络插件
上面的状态还是NotReady,下面我们需要网络插件,来进行联网访问
# 下载网络插件配置wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果连不上网:
那就到所在地址复制yml文件传到虚拟机中
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
文件如下:
kube-flannel.yml
默认镜像地址无法访问,sed命令修改为docker hub镜像仓库。(这一步没用过)
# 添加kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml##①首先下载v0.13.1-rc2-amd64 镜像##参考博客:https://www.cnblogs.com/pyxuexi/p/14288591.html##② 导入镜像命令,特别提示,3个机器都需要导入,不然抱错。如果没有操作,报错后,需要删除节点,重置,在导入镜像,重新加入才行。本地就是这样操作成功的!docker load < flanneld-v0.13.1-rc2-amd64.docker#####下载本地,替换将image: quay.io/coreos/flannel:v0.13.1-rc2 替换为 image: quay.io/coreos/flannel:v0.13.1-rc2-amd64# 查看状态 【kube-system是k8s中的最小单元】kubectl get pods -n kube-system
运行后的结果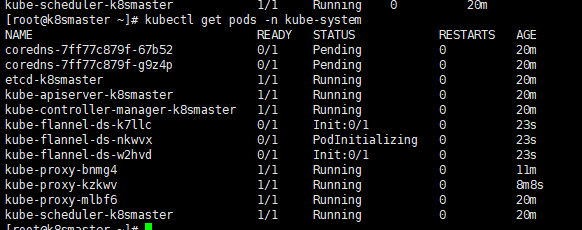
运行完成后,我们查看状态可以发现,已经变成了Ready状态了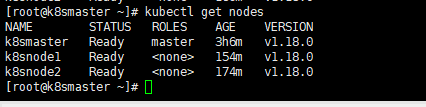
如果上述操作完成后,还存在某个节点处于NotReady状态,可以在Master将该节点删除(这步没用过)
# master节点将该节点删除##20210223 yan 查阅资料添加###kubectl drain k8snode1 --delete-local-data --force --ignore-daemonsetskubectl delete node k8snode1# 然后到k8snode1节点进行重置kubeadm reset# 重置完后在加入kubeadm join 192.168.177.130:6443--token 8j6ui9.gyr4i156u30y80xf--discovery-token-ca-cert-hash sha256:eda1380256a62d8733f4bddf926f148e57cf9d1a3a58fb45dd6e80768af5a500Copy to clipboardErrorCopied
七、 测试kubernetes集群
我们都知道K8S是容器化技术,它可以联网去下载镜像,用容器的方式进行启动
在Kubernetes集群中创建一个pod,验证是否正常运行:
# 下载nginx 【会联网拉取nginx镜像】kubectl create deployment nginx --image=nginx# 查看状态kubectl get pod
如果我们出现Running状态的时候,表示已经成功运行了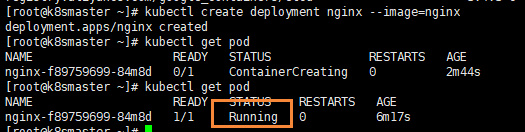
下面我们就需要将端口暴露出去,让其它外界能够访问
# 暴露端口kubectl expose deployment nginx --port=80 --type=NodePort# 查看一下对外的端口kubectl get pod,svc
能够看到,我们已经成功暴露了 80端口 到 30529上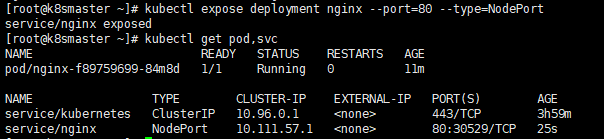
我们到我们的宿主机浏览器上,访问如下地址
http://10.4.104.169:30529/
发现我们的nginx已经成功启动了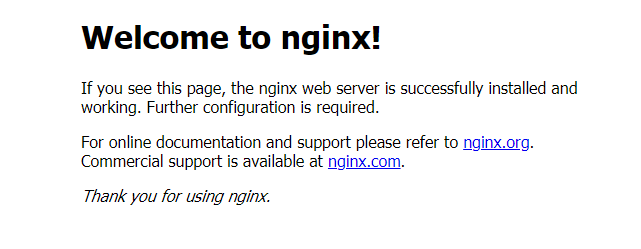
到这里为止,我们就搭建了一个单master的k8s集群
附录:
错误汇总(还没遇见错误)
错误一
在执行Kubernetes init方法的时候,出现这个问题
error execution phase preflight: [preflight] Some fatal errors occurred:[ERROR NumCPU]: the number of available CPUs 1 is less than the required 2
是因为VMware设置的核数为1,而K8S需要的最低核数应该是2,调整核数重启系统即可
错误二
我们在给node1节点使用 kubernetes join命令的时候,出现以下错误
error execution phase preflight: [preflight] Some fatal errors occurred:[ERROR Swap]: running with swap on is not supported. Please disable swap
错误原因是我们需要关闭swap
# 关闭swap# 临时swapoff -a# 临时sed -ri 's/.*swap.*/#&/' /etc/fstab
错误三
在给node1节点使用 kubernetes join命令的时候,出现以下错误
The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused
解决方法,首先需要到 master 节点,创建一个文件
# 创建文件夹mkdir /etc/systemd/system/kubelet.service.d# 创建文件vim /etc/systemd/system/kubelet.service.d/10-kubeadm.conf# 添加如下内容Environment="KUBELET_SYSTEM_PODS_ARGS=--pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true --fail-swap-on=false"# 重置kubeadm reset
然后删除刚刚创建的配置目录
rm -rf $HOME/.kube
然后 在master重新初始化
kubeadm init --apiserver-advertise-address=202.193.57.11 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.18.0 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
初始完成后,我们再到 node1节点,执行 kubeadm join命令,加入到master
kubeadm join 202.193.57.11:6443 --token c7a7ou.z00fzlb01d76r37s \--discovery-token-ca-cert-hash sha256:9c3f3cc3f726c6ff8bdff14e46b1a856e3b8a4cbbe30cab185f6c5ee453aeea5
添加完成后,我们使用下面命令,查看节点是否成功添加
kubectl get nodes
错误四
我们再执行查看节点的时候, kubectl get nodes 会出现问题
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
这是因为我们之前创建的配置文件还存在,也就是这些配置
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config
我们需要做的就是把配置文件删除,然后重新执行一下
rm -rf $HOME/.kube
然后再次创建一下即可
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config
这个问题主要是因为我们在执行 kubeadm reset 的时候,没有把 $HOME/.kube 给移除掉,再次创建时就会出现问题了
错误五
安装的时候,出现以下错误
Another app is currently holding the yum lock; waiting for it to exit...
是因为yum上锁占用,解决方法
yum -y install docker-ce
错误六
在使用下面命令,添加node节点到集群上的时候
kubeadm join 192.168.177.130:6443 --token jkcz0t.3c40t0bqqz5g8wsb --discovery-token-ca-cert-hash sha256:bc494eeab6b7bac64c0861da16084504626e5a95ba7ede7b9c2dc7571ca4c9e5
然后出现了这个错误
[root@k8smaster ~]# kubeadm join 192.168.177.130:6443 --token jkcz0t.3c40t0bqqz5g8wsb --discovery-token-ca-cert-hash sha256:bc494eeab6b7bac64c0861da16084504626e5a95ba7ede7b9c2dc7571ca4c9e5W1117 06:55:11.220907 11230 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.[preflight] Running pre-flight checks[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/error execution phase preflight: [preflight] Some fatal errors occurred:[ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`To see the stack trace of this error execute with --v=5 or higher
出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将包发往本机另一网卡,该网卡根据路由表继续发送数据包。这通常就是路由器所要实现的功能。也就是说 /proc/sys/net/ipv4/ip_forward 文件的值不支持转发
- 0:禁止
- 1:转发
所以我们需要将值修改成1即可
echo “1” > /proc/sys/net/ipv4/ip_forward
修改完成后,重新执行命令即可

若有收获,就点个赞吧
0 人点赞
