一、基本概念
1、介绍
Elasticsearch 是一个分布式文档存储,与传统的关系型数据库不同,Elasticsearch 将复杂的数据已序列化的JSON格式存储,而不是存储为列数据行。当集群中有多个节点时,存储的文档分布在整个集群中,可以从任何节点立即访问。
当文档被存储时,它会被编入索引,并可在1秒钟内近实时的完全搜索( near real-time),Elasticsearch查询速度如此之快的原因是用了倒排索引的数据结构。倒排索引列出了每个在文档中出现的独立的单词,并标识了每个单词出现的位置
一个索引可以看作是文档的优化集合,每个文档是字段的集合,字段是包含数据的键值对。默认情况下,Elasticsearch将所有数据的每个字段编入索引,每个被编入索引的字段都有专用的,优化的数据结构。例如,文本字段被存储为倒排索引,数字和地理字段存储在BKD树中。使用好每个字段的数据结构和返回搜索结果的能力,是Elasticsearch如此快速的原因。
Elasticsearch同样拥有无模式的能力:也就是当文档中的每个不同字段,没有指定明确的处理方式时,依然可以被编入索引。当动态匹配开启时,Elasticsearch会自动的发现并将新字段加入索引。这个默认的行为使得编排索引和浏览数据变得容易——当编排索引开始时,Elasticsearch将检测布尔值,浮点值和整数值、日期和字符串,并将其映射到相应的Elasticsearch的数据类型。
不过,如果你最终比Elasticsearch更了解你的数据,则可以通过改变规则的方式来控制动态映射,以及定义一个明确的映射规则来完全控制字段的存储和编排索引。
2、索引
3、类型
4、文档
二、基本使用

1、查询基本信息:_cat
GET /_cat/nodes #查看所有节点GET /_cat/health #查看es的健康状况GET /_cat/master #查看主节点GET /_cat/indices #查看所有索引
2、新增和更新文档:POST/PUT
POST
带ID时
POST person/_doc/1{"name":"jie"}
请求格式:POST 索引名/_doc/ID,JSON格式的请求体
结果:
如果当前ID没有数据,则是新增,结果如下,result为created,且版本号为1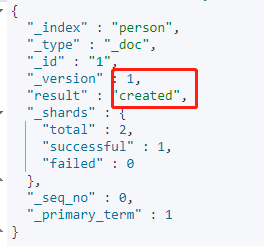
如果已经有数据了,则是更新,result为update,版本号加一
没带ID时:
POST person/_doc{"name":"jie"}

PUT
put必须带ID,且结果和POST一样,数据没存在则新增,已存在则更新。
如果没带ID,则会报错:
另一种更新方式
POST请求携带_update关键字,请求体增加key值doc,第一次会更新成功,第二次更新时,如果数据不变,则等于没有操作
POST person/_doc/1/_update{"doc":{"name":"jie"}}


3、查询数据:GET
GET person/_doc/1

4、删除数据
带ID
带ID的删除,是删除当前ID这个文档
DELETE person/_doc/1


不带ID
不带ID则表示删除整个索引
DELETE person


5、批量操作:bulk
示例1:
在某个索引下进行批量操作
POST person/_bulk{"delete":{"_id":"2"}}{"index":{"_id":"1"}}{"name":"jie1"}{"index":{"_id":"2"}}{"name":"jie2"}{"delete":{"_id":"2"}}
请求体格式:
新增/更新
新增或更新都需要两行,第一行表示索引和对应的ID值,例如:{"index":{"_id":"1"}}第二行表示文档的值,例如:{"name":"jie1"}如果文档没数据则是新增,否则是更新
删除:
只有一行,key值为delete,value值为要删除文档的id,例如{"delete":{"_id":"2"}}
每个操作之间的操作是互不影响的,比如示例1中的第一行,删除id为2的文档,由于此时文档是不存在的,则删除会失败,但其他的新增和删除操作还是会执行,结果如下:

示例2:
不带索引的批量操作
POST /_bulk{"index":{"_index":"dog","_id":"123"}}{"name":"来福"}{"delete":{"_index":"dog","_id":"123"}}
与示例1不同的是,没带索引时,可以对多个不同的索引进行操作,请求体格式如下
新增或更新,key值和示例一一致,value中就不止id了,还要加上要操作的索引,例如:{"index":{"_index":"dog","_id":"123"}}第二行还是要新增或更新的值,与示例一一致{"name":"来福"}删除与示例一的区别,也是value值中新增索引,例如:{"delete":{"_index":"dog","_id":"123"}}
结果: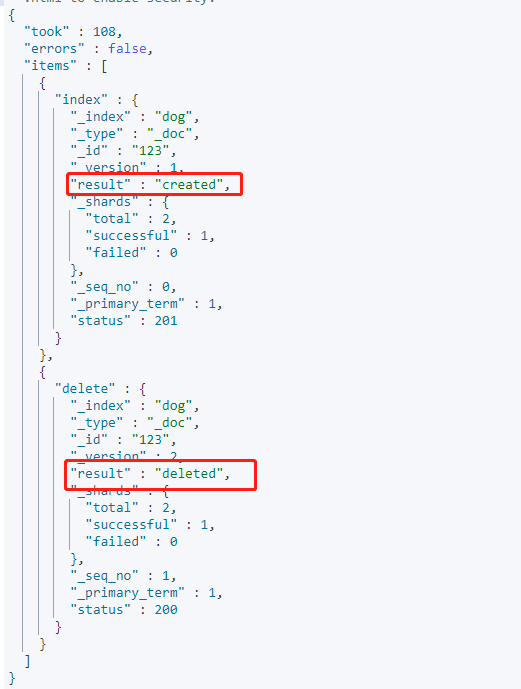

若有收获,就点个赞吧
0 人点赞
