对数据先进行分组,然后再进行查询。
SELECT FROM GROUP BY *
分组理解
什么是分组,数据某个字段中相同类型的数据。然后根据查询条件查询相同类型数据中的指定数据。
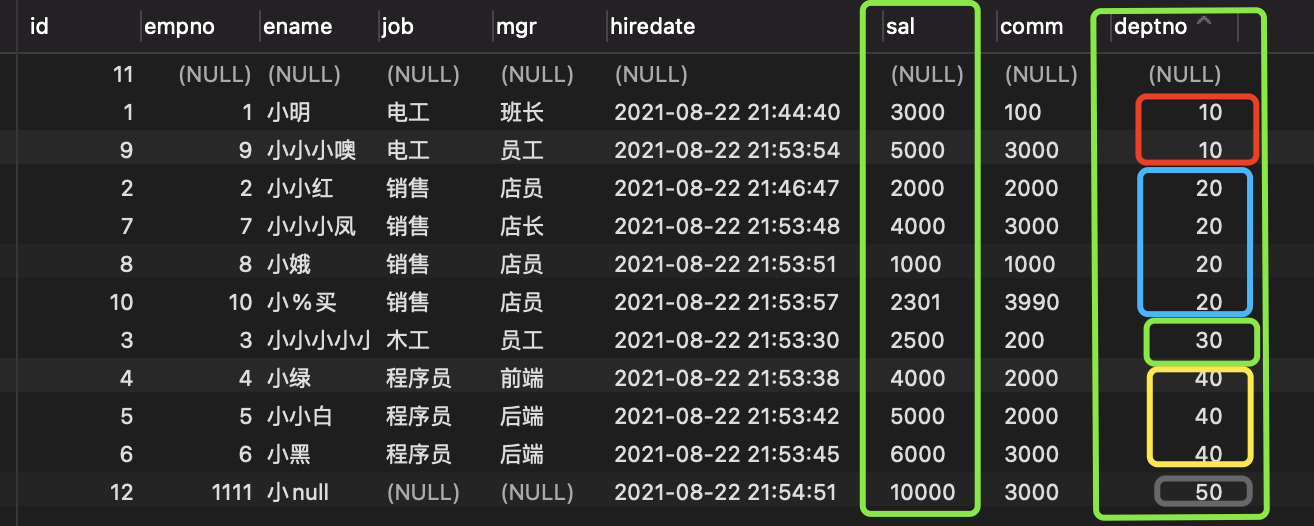
deptno是组的编号,根据组的编号查询每个组中sal最大值。
现有数据
查询语句
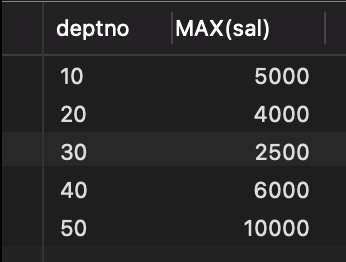
SELECTdeptno,MAX(sal)FROMempWHEREdeptno IS NOT NULL -- 上面图有null 所以要过滤nullGROUP BYdeptno;
查询结果
执行顺序
以下语句执行顺序,先从emp表中查找数据=>根据job分组=>对每一组进行SUM(sal);
SELECT job,sum(sal) FROM GROUP BY job;
错误语法
为什么会错误呢? ⚠️:因为在一条SELECT语句中,如果有GROUP BY , SELECT后面只能根 参加分组的字段,以及分组函数。其他的一律不能跟。
SELECT ename,job,sum(sal) FROM GROUP BY job;
多字段分组
SELECTdeptno, job, MAX(sal)FROMempGROUP BYdeptno, job;
分组后 条件处理
使用having关键字,可以对分组完后的数据进行下一步过滤处理,having不能单独使用,having不能代替where,having必须和group by 配合使用。
能使用where先过滤的优先使用where过滤。
-- 分组完后的数据 使用having 条件处理。效率较低SELECTdeptno ,MAX(sal)FROMempGROUP BYdeptnoHAVINGMAX(sal) > 5000;-- 先处理数据 后分组。效率相对较高。SELECTdeptno ,MAX(sal)FROMempWHEREsal > 5000GROUP BYdeptno;
WHERE 做不到的
当where做不到之后使用having过滤处理
SELECT ename,AVG(sal) FROM emp GROUP BY ename HAVING AVG(sal) > 2000;

若有收获,就点个赞吧
0 人点赞
