数组
Java 数组是固定长度的相同类型的元素的列表,数组下标从 0 开始,通过下标随机访问数组元素。数组初始化后不能改变大小,初始化数组(分配内存空间,初始化默认值)的方式如下:
// 静态初始化int[] array0 = {1, 2, 3};int[] array1 = new int[]{1, 2, 3, 4, 5};// 动态初始化int[] array2 = new int[10];array2[0] = 1;array2[1] = 2;array2[2] = 3;// 数组遍历for (int i = 0; i < array2.length; ++i) {System.out.print(array2[i]);}// 增强 for- each 循环for (int i : array2) {System.out.print(i);}
java.util.Arrays 类提供了数组排序、查找、拷贝等方法,还提供了数组转为集合的方法。数组五种拷贝方式:
int[] x = {1, 2, 3, 4, 5};int[] y = new int[5];// for 循环// y = x.clone();// System.arraycopy(x, 0, y, 0, 5);// y = Arrays.copyOf(x, 5);// y = Arrays.copyOfRange(x, 0, 5);// 以上方法一维数组对基本类型是深拷贝,对引用类型是浅拷贝
数组拷贝最快的方式应该就是 System.arraycopy() 方法了,它由 JVM 专门实现基于内存的拷贝:
@HotSpotIntrinsicCandidatepublic static native void arraycopy(Object src, int srcPos, Object dest, int destPos, int length);
Collection
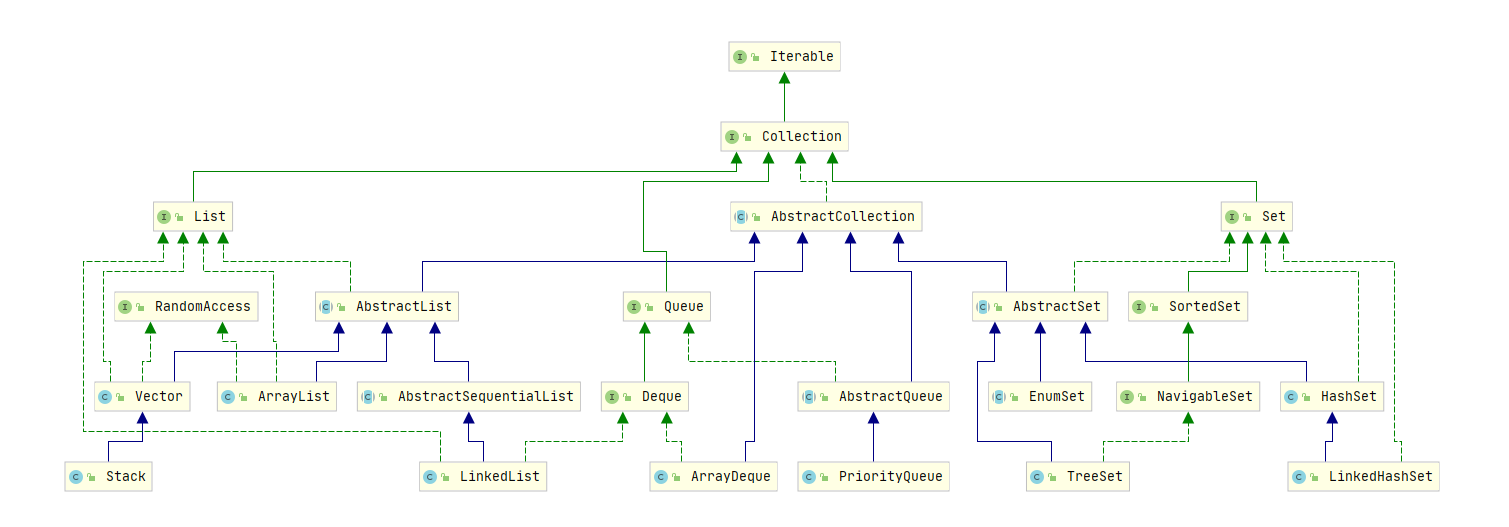
Collection 接口提供的方法如下:
- 获取元素个数
size()、转为数组toArray(T[] a) - 末尾添加
add(E e)、删除第一个匹配元素remove(Object o)、清空clear() - 是否没有元素
isEmpty()、是否包含contains(Object o)、是否包含全部containsAll(Collection<?> c) 并集
addAll(Collection<? extends E> c)、交集retainAll(Collection<?> c)、差集removeAll(Collection<?> c)List JDK1.2
List 是有序、可重复元素(通常可以为 null)的列表。List 提供了以下基本方法:
获取
get(int index)、修改set(int index, E element)- 查找第一个匹配的下标
indexOf(Object o)、查找最后一个匹配的下标lastIndexOf(Object o) - 截取
subList(int fromIndex, int toIndex) - 排序
sort(Comparator<? super E> c、迭代器遍历listIterator(int index) - 创建不可变列表
of(E e1)JDK 9、复制不能为 null 的元素的不可变列表copyOf(Collection<? extends E> coll)JDK 10ArrayList
基于数组的可动态扩容的列表,可以通过索引随机访问元素。
ArrayList 的size()、isEmpty()、get(int index)、set(int index, E element)、iterator()方法以固定时间运行;通过 add 方法插入 n 个元素以 O(n) 固定时间运行;其它大部分操作以线性时间运行。 details ArrayList 源码浅析(JDK 15)ArrayList 底层结构 ```java // ArrayList 基于数组 elementData 实现,通过 size 来记录元素个数 transient Object[] elementData; private int size;
// 还可以看到存储的对象都是 Object 类型,它使用的是泛型约束
**数组初始化方法源码如下:**```java// 构造器public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}public ArrayList(int initialCapacity) {if (initialCapacity > 0) {this.elementData = new Object[initialCapacity];} else if (initialCapacity == 0) {this.elementData = EMPTY_ELEMENTDATA;} else {throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);}}public ArrayList(Collection<? extends E> c) {Object[] a = c.toArray();if ((size = a.length) != 0) {if (c.getClass() == ArrayList.class) {elementData = a;} else {elementData = Arrays.copyOf(a, size, Object[].class);}} else {elementData = EMPTY_ELEMENTDATA;}}
以上方法中可看到,初始化数组时,如果给定的容量不为 0,则直接分配指定大小的容量创建数组 elementData;如果为 0,则初始化为默认的空数组。
数组新增元素源码如下:
// 添加元素public boolean add(E e) {modCount++;add(e, elementData, size);return true;}private void add(E e, Object[] elementData, int s) {if (s == elementData.length)elementData = grow();elementData[s] = e;size = s + 1;}public void add(int index, E element) {rangeCheckForAdd(index);modCount++;final int s;Object[] elementData;if ((s = size) == (elementData = this.elementData).length)elementData = grow();System.arraycopy(elementData, index,elementData, index + 1,s - index);elementData[index] = element;size = s + 1;}public boolean addAll(Collection<? extends E> c) {Object[] a = c.toArray();modCount++;int numNew = a.length;if (numNew == 0)return false;Object[] elementData;final int s;if (numNew > (elementData = this.elementData).length - (s = size))elementData = grow(s + numNew);System.arraycopy(a, 0, elementData, s, numNew);size = s + numNew;return true;}public boolean addAll(int index, Collection<? extends E> c) {rangeCheckForAdd(index);Object[] a = c.toArray();modCount++;int numNew = a.length;if (numNew == 0)return false;Object[] elementData;final int s;if (numNew > (elementData = this.elementData).length - (s = size))elementData = grow(s + numNew);int numMoved = s - index;if (numMoved > 0)System.arraycopy(elementData, index,elementData, index + numNew,numMoved);System.arraycopy(a, 0, elementData, index, numNew);size = s + numNew;return true;}
新增元素时,如果新增的元素个数超过当前剩余容量,则调用 grow() 或者 grow(int) 方法先扩容;然后通过 System.arraycopy() 方法插入元素。我们看下 grow 方法的逻辑:
grow 自动扩容源码如下:
// 两个空数组,用于标识第一次应该分配多大容量private static final Object[] EMPTY_ELEMENTDATA = {}; // 初始化列表时给定的容量为 0private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}; // 初始化列表时没有指定容量private static final int DEFAULT_CAPACITY = 10; // 默认扩充容量// 具体扩容方法private Object[] grow() {return grow(size + 1);}// 参数为数组目标大小private Object[] grow(int minCapacity) {int oldCapacity = elementData.length;// 如果是一个指定为 0 容量的初始化列表或者列表中已有元素,则调用 ArraysSupport.newLength 方法扩充容量,然后底层调用 System.arraycopy() 方法复制已有的元素if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity >> 1 /* preferred growth */);return elementData = Arrays.copyOf(elementData, newCapacity);} else {// 如果是一个没有指定容量的初始化列表,则直接分配一个 Math.max(DEFAULT_CAPACITY, minCapacity) 大小的数组返回return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];}}
手动扩容源码如下:
// 手动扩容方法public void ensureCapacity(int minCapacity) {// 可以看到调用此方法符合条件才会扩容,需要满足要增加的容量要超过当前数组的大小并且不能超过 Integer.MAX_VALUE - 8,并且不能是无参构造刚初始化好的列表if (minCapacity > elementData.length&& !(elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA&& minCapacity <= DEFAULT_CAPACITY)) {modCount++;grow(minCapacity);}}// 调整容量到元素个数,减少空间使用public void trimToSize() {modCount++;if (size < elementData.length) {elementData = (size == 0)? EMPTY_ELEMENTDATA: Arrays.copyOf(elementData, size);}}
ArraysSupport.newLength 具体扩容大小源码
// 扩容参数为:当前数组大小、需要大小、当前的一半(右移一位相当于整除)public static int newLength(int oldLength, int minGrowth, int prefGrowth) {// assert oldLength >= 0// assert minGrowth > 0int newLength = Math.max(minGrowth, prefGrowth) + oldLength;if (newLength - MAX_ARRAY_LENGTH <= 0) {return newLength;}return hugeLength(oldLength, minGrowth);}private static int hugeLength(int oldLength, int minGrowth) {int minLength = oldLength + minGrowth;if (minLength < 0) { // overflowthrow new OutOfMemoryError("Required array length too large");}if (minLength <= MAX_ARRAY_LENGTH) {return MAX_ARRAY_LENGTH;}return Integer.MAX_VALUE;}
通过 grow 方法可以知道了,如果是一个没有指定容量的初始化列表,根据新元素个数和 10 的最大值返回一个新的数组;
如果是一个指定为 0 容量的初始化列表或者列表中已有元素,则进行扩充,如果新增的元素个数超过了当前数组大小的一半,则尝试直接扩充为目标大小;否则尝试扩充为当前数组大小的 1.5 倍。如果超出 Integer.MAX_VALUE - 8,则再次尝试分配,如果新增元素的个数在内存范围内,小于 Integer.MAX_VALUE - 8 则直接扩充为 Integer.MAX_VALUE - 8,否则扩充为 Integer.MAX_VALUE。Integer.MAX_VALUE - 8 是因为有些虚拟机要在数组中保留标题字。
总结:
- 初始化时直接根据元素个数大小分配数组
- 新增元素,不够用时才扩容,扩容根据初始化方式有所不同:
- 如果是没初始化容量的空列表,扩充为 10 ,目标大小超过 10 则扩充为目标大小
- 否则扩充为当前数组大小的 1.5 倍,目标大小超过 1.5 倍则扩充为目标大小
Vector
和 ArrayList 几乎一样,只不过 Vector 是同步的,保证线程安全。Stack
继承自 Vector,提供先进先出(FIFO)的简单的栈。官方推荐使用含有更完整的堆栈操作的 Deque 的实现类。LinkedList
基于双向链表实现的列表。它只保存了第一个和最后一个 Node 节点,根据索引访问其它元素都需要遍历。
LinkedList 实现了 List 和 Deque 接口,所以它是有序的,但是支持双向访问,可以作为队列、栈、双向队列使用。 details LinkedList 源码浅析(JDK 15)底层数据结构 ```java transient int size = 0; // 元素个数 transient Nodefirst; // 头节点 transient Node last; // 尾节点
// Node 节点是个内部类,有两个指针指向上一个和下一个 Node
private static class Node
Node(Node<E> prev, E element, Node<E> next) {this.item = element;this.next = next;this.prev = prev;}
}
所有的操作最终都是基于 Node 的增删操作,如下:```java// 在头部添加节点private void linkFirst(E e) {final Node<E> f = first;final Node<E> newNode = new Node<>(null, e, f);first = newNode;if (f == null)last = newNode;elsef.prev = newNode;size++;modCount++;}// 在尾部添加节点void linkLast(E e) {final Node<E> l = last;final Node<E> newNode = new Node<>(l, e, null);last = newNode;if (l == null)first = newNode;elsel.next = newNode;size++;modCount++;}// 在中间插入节点void linkBefore(E e, Node<E> succ) {// assert succ != null;final Node<E> pred = succ.prev;final Node<E> newNode = new Node<>(pred, e, succ);succ.prev = newNode;if (pred == null)first = newNode;elsepred.next = newNode;size++;modCount++;}// 删除第一个节点private E unlinkFirst(Node<E> f) {// assert f == first && f != null;final E element = f.item;final Node<E> next = f.next;f.item = null;f.next = null; // help GCfirst = next;if (next == null)last = null;elsenext.prev = null;size--;modCount++;return element;}// 删除最后一个节点private E unlinkLast(Node<E> l) {// assert l == last && l != null;final E element = l.item;final Node<E> prev = l.prev;l.item = null;l.prev = null; // help GClast = prev;if (prev == null)first = null;elseprev.next = null;size--;modCount++;return element;}// 删除中间节点E unlink(Node<E> x) {// assert x != null;final E element = x.item;final Node<E> next = x.next;final Node<E> prev = x.prev;if (prev == null) {first = next;} else {prev.next = next;x.prev = null;}if (next == null) {last = prev;} else {next.prev = prev;x.next = null;}x.item = null;size--;modCount++;return element;}
查找节点源码如下:
Node<E> node(int index) {// assert isElementIndex(index);// 如果下标小于一半,则从头部开始查找,否则从尾部开始查找if (index < (size >> 1)) {Node<E> x = first;for (int i = 0; i < index; i++)x = x.next;return x;} else {Node<E> x = last;for (int i = size - 1; i > index; i--)x = x.prev;return x;}}
Set JDK1.2
Set 是包含不可重复元素(通常可以为 null)的集合。Set 提供了以下基本方法:
- 创建不可变集合
of(E e1)JDK 9、复制不能为 null 的元素的不可变集合copyOf(Collection<? extends E> coll)JDK 10HashSet
内部使用 HashMap 实现的集合。
它为基本操作 add、remove、contains 和 size 提供了恒定的时间性能,但是对该集合迭代使用的时间和内部元素个数及 HashMap 桶的个数之和有关。 details HashSet 源码浅析(JDK 15)底层数据结构
构造器 ```java // HashMap 实例默认初始容量为 16,加载因子为 0.75private transient HashMap<E,Object> map;private static final Object PRESENT = new Object();
public HashSet() { map = new HashMap<>(); }
// 以指定集合创建时,HashMap 保证初始容量可以容纳指定集合中的元素 public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); } public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); }
// LinkedHashSet 使用 HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }
<a name="jVtn9"></a>### LinkedHashSet内部使用 LinkedHashMap 实现的有序集合。<br />此类的迭代时间不受容量影响;由于添加同样的元素不会改变它原有的顺序,常用于通过构造器 `LinkedHashSet(Collection<? extends E> c)` 将含重复元素的集合去重并保持原来的顺序,相比 TreeSet 更轻量。<a name="g1uK7"></a>### TreeSet基于 TreeMap 的有序集合。保证 log(n) 的时间复杂度。<a name="ijWpv"></a>### EnumSetJDK 5JDK 5 新增的专门用于枚举类型的枚举集合。可以通过集合操作处理枚举值。它提供的方法如下:- 返回该枚举类所有枚举值的集合 `allOf(Class<E> elementType)`- 返回该枚举类的空集合 `noneOf(Class<E> elementType)`- 返回该枚举类部分枚举值的集合 `EnumSet<E> copyOf(EnumSet<E> s)`、`copyOf(Collection<E> c)`、`EnumSet<E> of(E e)`、`range(E from, E to)`- 补集 `complementOf(EnumSet<E> s)`它内部使用位向量实现,非常紧凑和高效,具有极好的时空性能,几乎所有操作都在固定时间内运行。---<a name="u3mAa"></a>## QueueJDK 5JDK 5 新增的 Queue 是基于优先级堆实现的无限优先级队列,该队列中的元素会根据优先级进行排序。队列中通常不能存储 null 值(LinkedList 除外),队列的每种操作都有两种形式:- 一种是操作失败会抛出异常- `add(E e)`- `remove()`- `element()`- 一种是操作失败会返回特殊值 null 或者 false- `offer(E e)`- `poll()`- `peek()`<a name="RGTgi"></a>### PriorityQueuePriorityQueue 是基于二进制堆实现的优先级队列,可通过构造器传入元素优先级比较器 Comparator,不指定则默认元素的自然比较排序,即元素需要实现 Comparable,是可比较的。details PriorityQueue 源码浅析(JDK 15)**底层数据结构**```java// 表示基于平衡二叉树的最小堆的优先级队列,queue[n] 的两个孩子是 queue[2 * n + 1] 和 queue[2 *(n + 1)]transient Object[] queue;int size;// 通过比较器实现对于堆中的每个节点小于等于它的孩子节点,比较器为 null 则使用元素的自然排序@SuppressWarnings("serial") // Conditionally serializableprivate final Comparator<? super E> comparator;transient int modCount;
堆数组的扩容源码如下:
private void grow(int minCapacity) {int oldCapacity = queue.length;// Double size if small; else grow by 50%// 如果当前大小小于 64 则每次增加 2,否则增加一半int newCapacity = ArraysSupport.newLength(oldCapacity,minCapacity - oldCapacity, /* minimum growth */oldCapacity < 64 ? oldCapacity + 2 : oldCapacity >> 1/* preferred growth */);queue = Arrays.copyOf(queue, newCapacity);}
对于堆调整的源码如下:
// 由于Floyd (1964) 产生的 O(size) 算法,在整个树中建立堆不变式:private void heapify() {final Object[] es = queue;int n = size, i = (n >>> 1) - 1;final Comparator<? super E> cmp;if ((cmp = comparator) == null)for (; i >= 0; i--)siftDownComparable(i, (E) es[i], es, n);elsefor (; i >= 0; i--)siftDownUsingComparator(i, (E) es[i], es, n, cmp);}private static <T> void siftUpComparable(int k, T x, Object[] es) {Comparable<? super T> key = (Comparable<? super T>) x;while (k > 0) {int parent = (k - 1) >>> 1;Object e = es[parent];if (key.compareTo((T) e) >= 0)break;es[k] = e;k = parent;}es[k] = key;}private static <T> void siftUpUsingComparator(int k, T x, Object[] es, Comparator<? super T> cmp) {while (k > 0) {int parent = (k - 1) >>> 1;Object e = es[parent];if (cmp.compare(x, (T) e) >= 0)break;es[k] = e;k = parent;}es[k] = x;}private static <T> void siftDownComparable(int k, T x, Object[] es, int n) {// assert n > 0;Comparable<? super T> key = (Comparable<? super T>)x;int half = n >>> 1; // loop while a non-leafwhile (k < half) {int child = (k << 1) + 1; // assume left child is leastObject c = es[child];int right = child + 1;if (right < n &&((Comparable<? super T>) c).compareTo((T) es[right]) > 0)c = es[child = right];if (key.compareTo((T) c) <= 0)break;es[k] = c;k = child;}es[k] = key;}private static <T> void siftDownUsingComparator(int k, T x, Object[] es, int n, Comparator<? super T> cmp) {// assert n > 0;int half = n >>> 1;while (k < half) {int child = (k << 1) + 1;Object c = es[child];int right = child + 1;if (right < n && cmp.compare((T) c, (T) es[right]) > 0)c = es[child = right];if (cmp.compare(x, (T) c) <= 0)break;es[k] = c;k = child;}es[k] = x;}
DequeJDK 6
Deque 接口是继承了 Queue 接口的双端队列,支持从队列两端进行操作。
ArrayDeque
ArrayDeque 是基于可调整大小的圆形数组的无界双端队列。官方说,当用作堆栈时,此类比 Stack 类快;当用作队列时,此类比 LinkedList 类快。
ArrayDeque 大部分方法以固定时间执行,除了批量操作及 remove(Object)、removeFirstOccurrence(Object o)、removeLastOccurrence(Object o)、contains(Object o)、iterator.remove() 以线性时间运行。
ArrayDeque 源码浅析(JDK 15)底层数据结构
// 虚拟机擅长优化简单的数组循环,其中索引在有效切片上递增或递减。// 因为在圆形数组中,元素通常存储在两个不相交的切片中,所以我们通过为元素上的所有遍历编写不寻常的嵌套循环来帮助虚拟机.// 仅具有一个热的内部循环主体而不是两个或三个,可以简化人工维护,并鼓励VM循环内联到调用者中。// 存储双端队列元素的数组,其中每个不含元素的位置都为 null,数组至少有一个 null(在尾部)transient Object[] elements;// 头部索引,0 <= head < elements.length,双端队列为空时 head = tailtransient int head;// 尾部索引,作为下一个元素插入到尾部的索引,elements[tail] 始终为 nulltransient int tail;private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
容量扩充源码如下:
private void grow(int needed) {// overflow-conscious codefinal int oldCapacity = elements.length;int newCapacity;// Double capacity if small; else grow by 50%int jump = (oldCapacity < 64) ? (oldCapacity + 2) : (oldCapacity >> 1);if (jump < needed|| (newCapacity = (oldCapacity + jump)) - MAX_ARRAY_SIZE > 0)newCapacity = newCapacity(needed, jump);final Object[] es = elements = Arrays.copyOf(elements, newCapacity);// Exceptionally, here tail == head needs to be disambiguatedif (tail < head || (tail == head && es[head] != null)) {// wrap around; slide first leg forward to end of arrayint newSpace = newCapacity - oldCapacity;System.arraycopy(es, head,es, head + newSpace,oldCapacity - head);for (int i = head, to = (head += newSpace); i < to; i++)es[i] = null;}}/** Capacity calculation for edge conditions, especially overflow. */private int newCapacity(int needed, int jump) {final int oldCapacity = elements.length, minCapacity;if ((minCapacity = oldCapacity + needed) - MAX_ARRAY_SIZE > 0) {if (minCapacity < 0)throw new IllegalStateException("Sorry, deque too big");return Integer.MAX_VALUE;}if (needed > jump)return minCapacity;return (oldCapacity + jump - MAX_ARRAY_SIZE < 0)? oldCapacity + jump: MAX_ARRAY_SIZE;}
双端队列操作源码如下:
/*** Circularly increments i, mod modulus.* Precondition and postcondition: 0 <= i < modulus.*/static final int inc(int i, int modulus) {if (++i >= modulus) i = 0;return i;}/*** Circularly decrements i, mod modulus.* Precondition and postcondition: 0 <= i < modulus.*/static final int dec(int i, int modulus) {if (--i < 0) i = modulus - 1;return i;}/*** Circularly adds the given distance to index i, mod modulus.* Precondition: 0 <= i < modulus, 0 <= distance <= modulus.* @return index 0 <= i < modulus*/static final int inc(int i, int distance, int modulus) {if ((i += distance) - modulus >= 0) i -= modulus;return i;}/*** Subtracts j from i, mod modulus.* Index i must be logically ahead of index j.* Precondition: 0 <= i < modulus, 0 <= j < modulus.* @return the "circular distance" from j to i; corner case i == j* is disambiguated to "empty", returning 0.*/static final int sub(int i, int j, int modulus) {if ((i -= j) < 0) i += modulus;return i;}
Map
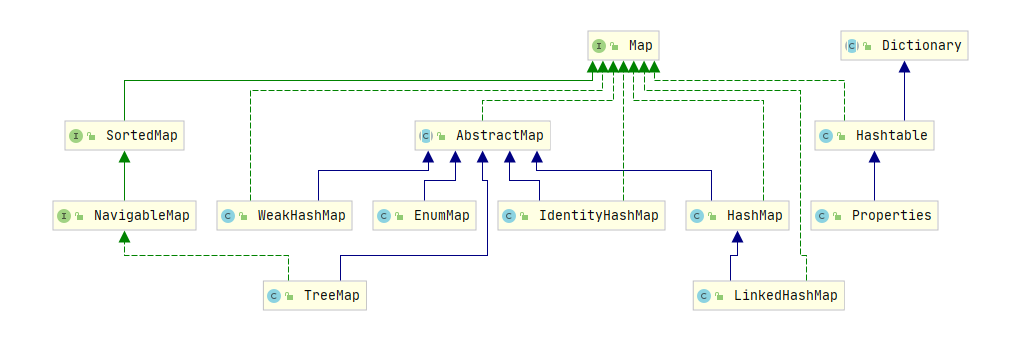
Map 是存储键值对的对象,键不能为 null,每个键最多映射一个值。Map 接口提供的方法如下:
- 获取键值对个数
size()、清空键值对clear()、 - 判断是否没有键值对
isEmpty()、是否包含键containsKey(Object o)、是否包含值containsValue(Object o) - 获取键对应的值
get(Object o)、获取键对应的值,没有返回提供的默认值getOrDefault(Object key, V defaultValue)JDK 8 - 添加键值对
put(K k, V v)、批量添加putAll(Map<? extends K, ? extends V> m)、键有值返回,没有添加putIfAbsent(K key, V value)JDK 8 - 删除键值对
remove(Object o)、删除对应的键值对remove(Object key, Object value)JDK 8 - 替换键的值
replace(K key, V value)、replace(K key, V oldValue, V newValue)、replaceAll(BiFunction<? super K, ? super V, ? extends V> function)JDK 8 - 遍历
forEach(BiConsumer<? super K, ? super V> action)JDK 8 - 指定键值关系
compute()、mergeJDK 8 - 构造不可变哈希表
of(K k1, V v1)JDK 9、ofEntries(Entry<? extends K, ? extends V>... entries)JDK 9、entry(K k, V v)JDK 9、copyOf(Map<? extends K, ? extends V> map)JDK 10
Map 提供了三种视图:
- 键的集合
keySet() - 值的集合
values() -
HashMap
基于哈希表实现。
它为基本的 get、put 操作提供恒定时间的性能,但是迭代性能和桶的数量及键值对的数量成比例,如果需要迭代,初始容量不要太高,负载因子不要太低。
HashMap 的实例有两个影响性能的参数:初始容量和负载因子。如果哈希表中的条目数量超过负载因子和当前容量的乘积,哈希表会重建。如果要存储很对键值对,指定初始容量将提高存储效率,而不是自动扩容。如果键的 hashcode() 相同肯定会降低性能,所以尽量提高键的可比性(Comparable)。 HashMap 源码浅析(JDK 15)底层数据结构 ```java // 键值对节点 static class NodeNode(int hash, K key, V value, Node
this.hash = hash;this.key = key;this.value = value;this.next = next;
}
public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + “=” + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;value = newValue;return oldValue;
}
public final boolean equals(Object o) {
if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;
} }
transient Node
transient Set
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 初始容量,必须为 2 的幂 static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量 static final float DEFAULT_LOAD_FACTOR = 0.75f; static final int TREEIFY_THRESHOLD = 8; // 桶的个数,桶会转为树,该值必须大于 2,并且至少应为 8 才能从树再变回桶 static final int UNTREEIFY_THRESHOLD = 6; // 取消树化的仓位阈值,小于 TREEIFY_THRESHOLD,最大为 6 static final int MIN_TREEIFY_CAPACITY = 64; // 可以树化的最小容量,应该至少为 4 * TREEIFY_THRESHOLD
<a name="F7C0K"></a>## LinkedHashMap基于哈希表和双向链表实现的有序的键值对集合。<br />默认根据插入顺序排序,但是也提供了构造器 `LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)` 可以指定排序模式(true 根据访问顺序,false 根据插入顺序),根据访问顺序可以实现最近最少访问的哈希表,非常适合构建 LRU 缓存。```javaimport java.util.LinkedHashMap;import java.util.Map;public class Main {/*** 使用 LinkedHashMap实现 LRU 缓存算法,LRU 缓存算法即删除最近最久未使用的数据* <p>* 实现思路为:* 1.每次访问一个数据则把这个数据移到队列尾部* 2.缓存满了则删除队列首部的数据,即删除最久未使用的,* 3.删除后,后面的数据需要向前补位* <p>* 综合考虑使用 LinkedHashMap 来实现,原因为:* 1.使用链表结构,移动数据比较快需要 O(1) 时间;使用数组需要 O(n) 时间* 2.其提供带参数的构造函数,设置使用访问顺序遍历* 3.在访问顺序下,其 get 方法除了返回数据还会将访问的数据放到链表尾部,每次只需 remove 首部的数据*/public static class LRUCache<K, V> extends LinkedHashMap<K, V> {private static final long serialVersionUID = 1L;// 缓存最大容量private final int maxCapacity;public LRUCache(int maxCapacity) {super(maxCapacity, 0.75f, true);this.maxCapacity = maxCapacity;}@Overridepublic boolean removeEldestEntry(Map.Entry<K, V> eldest) {return size() > maxCapacity;}}public static void main(String[] args) {// 测试一下,设置缓存最大容量为4Map<Integer, String> map = new LRUCache<>(4);map.put(1, "h");map.put(2, "he");map.put(3, "hel");map.put(4, "hell");map.put(5, "hello");map.get(3);// 将依次输出2、4、5、3,因存储5个数据超出缓存最大容量,自动删除首部数据1;之后访问3,将3移到尾部for (Object key : map.keySet()) {System.out.println(key);}}}
TreeMap
EnumMap
WeakHashMap
基于哈希表实现的带有弱键的集合,当键被回收,则键值对会自动删除。
IdentityHashMap
基于哈希表实现的集合,比较键和值时使用 == 而不是 equals(),用于序列化和深拷贝。
Hashtable
与 HashMap 类似,但 Hashtable 不允许空值,并且是同步的,保证线程安全。
Properties
线程安全的属性表,每个键值对都是一个字符串。可以持久化。
fail - fast 机制
当创建迭代器之后,如果集合的结构改变(除了通过迭代器的 remove() 和 add() 方法之外),就会尽最大努力抛出 ConcurrentModificationException 异常。该机制仅用于检测错误,不能用于异常处理。
Collections 类
Collections 类提供了静态方法对集合进行操作,或者通过包装返回新集合。
以上集合除了 Vector、Hashtable、Properties 都是非线程安全的,如果需要并发处理,则需要 Collecitons 类提供的同步包装方法,使用如下包装方法返回的集合进行迭代器或 Stream 遍历时需要手动使用 synchronized 同步块包裹:
synchronizedList(List<T> list)synchronizedSet(Set<T> s)、synchronizedSortedSet(SortedSet<T> s)、synchronizedNavigableSet(NavigableSet<T> s)synchronizedMap(Map<K,V> m)、synchronizedSortedMap(SortedMap<K,V> m)、synchronizedNavigableMap(NavigableMap<K,V> m)
如果需要让集合只读,可以使用只读包装方法:
unmodifiableList(List<? extends T> list)等(同上 unmodifiable 开头)
还可以返回只读的空集合或者单例集合:
emptyList()EMPTY_LIST 等(同上 empty 开头)singletonList(T o)只能含有一个元素的不可变列表singleton(T o)只能含有一个元素的不可变集合singletonMap(K key, V value),只能含有一个键值对的不可变集合
Collections 类还提供了很多实用方法:
- 集合反转
reverse(List<?> list) - 随机打乱集合元素
shuffle(List<?> list) - 集合元素换位
swap(List<?> list, int i, int j) - 替换全部元素
fill(List<? super T> list, T obj) - 集合复制
copy(List<? super T> dest, List<? extends T> src) - 返回最值
min(Collection<? extends T> coll)、max(Collection<? extends T> coll)并发安全
使用 Collections 类提供的方法对不安全的集合进行包装需要手动进行同步,为了避免同步 JDK 5 增加了如下并发集合类:CopyOnWriteArrayList
替代 ArrayList 的并发安全的列表。CopyOnWriteArraySet
底层使用 CopyOnWriteArrayList 进行所有操作的并发安全的集合。ConcurrentHashMap
和 Hashtable 类似的并发安全的哈希表。ConcurrentSkipListMapJDK 6
基于 SkipLists 的变体实现的可按顺序排列的并发安全的哈希表。
注意:
SyncronizedMap 和 ConcurrentHashMap 等并发安全的集合,在进行查询并删除这种联合操作时也是线程不安全的,需要对整个集合使用 syncronized 块包裹。

若有收获,就点个赞吧
0 人点赞
