1.Redis是什么?
2.Redis的作用
3.Nosql数据库的介绍
3.1Nosql与sql数据库的区别
3.2行式数据库与列式数据库的优缺点
4.Redis数据库的安装过程
5.Redis的数据类型介绍以及使用
5.1Redis(key键)(用<>的就是参数)
- key * 查看当前库的所有的键
- exists
查看key是否存在 - type
查看当前键的类型 - del
删除指定键的数据 - expire
给指定的key设置过期的时间 - ttl
查看key还有多长时间过期 - select
选择数据库 - dbsize 查看当前数据库中的key的个数
- flushdb 清空当前库
-
5.2Redis字符串(strings)(value值)
5.2.1常用的命令
set
添加键值对 - mset
添加多个键值对 - get
获取对应的键值 - mget
一次获取多个key的值 - append
将value的值添加到 的末尾 - strlen
获取value值的长度 - setnx
只有当key的值不存在的时候设置key的值 - incr
(原子操作) 将key的值加一,只能对数字进行操作 - decr
(原子操作) 将key中储存的数字值减一 - getrange
<起始位置> <结束位置> 获得值的范围类似于java中的substring() - setex
<过期的时间> 设置键值的同时设置了过期的时间 -
5.2.2数据结构
特点:二进制安全的,最大值为512M
- 可以包含任何数据,如简单的字符串,图片
源码结构:
struct SDS {// 数组容量T capacity; //分配的字符的长度// 数组长度T len; //实际存储的字符的长度// 特殊标识位byte flags;// 数组内容byte[] buf;}1.数组的长度采用泛型,长度比较短的时候可以采用byte,short进行存储
存储结构示意图
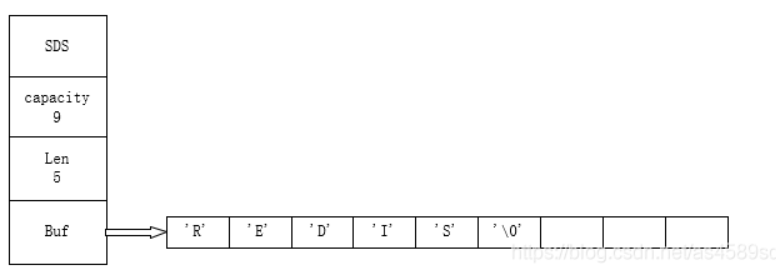
- capacity的分配策略
- 计数器
- incr和decr的命令是将key中存储的数字的值,加1和减1用来计算。如:点赞数,评论数,分享数
- 分布式锁(不理解)
- setnx的作用,是当key不存在时,设置值并返回1,当key已经存在,不设置值并返回0,而这个操作也是原子性的,所以可以用来做分布式锁。返回1表示获得到了锁,返回0表示没有获得到锁;然后使用del删除key来释放锁。可以同时给key设置一个过期时间,这样当del删除失败时,也可以保证锁能够释放。
- 缓存(最常用的)
- set可以存储值,可将数据对象进行序列化操作时候进行缓存
- 用户签到记录
- 特点:有序,不唯一
5.3.2 常用命令
| lpush/rpush| 从左边/右边插入一个或多个值 | | —- | —- | | lpop/rpop | 从左边/右边吐出一个值。值在键在,值光键亡。 | | rpoplpush | 从右边吐出一个值,插到列表的左边 | | lrange (0 ,-1) | 按照索引下标获得元素(从左到右) | | lindex | 按照索引的下表获取元素 | | llen | 获取key的值的长度 | | linsert before/after | 在 的后面/前面插入 插入值 | | lrem | 从左边删除n个value | | lset | 将列表key下标为index的值替换成value |
5.3.3数据结构
- 大体上看来是一个链表
- 实际上是数组加链表
- 在元素列表元素比较少 的时候会用ziplist称为为压缩列表,分配一块连续的内存
- 数据量比较多的时候会改成quiteList
- 这样既满足了插入删除的性能,又不会浪费空间

5.4Redis集合(set)
5.4.1简介
- Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
5.4.2常用的命令
| sadd| 将一个或者多个key添加到set里面 | | —- | —- | | smembers | 取出该集合的所有值 | | sismember | 判断是不是有这个key,如果有返回1,否则返回0 | | scard | 返回这个集合中的数量 | | srem | 删除集合中的某个元素或者多个元素 | | spop | 随机从该集合中吐出一个值 | | sinter | 返回两个集合的交集 | | sunion | 返回两个集合的并集 | | sdiff | 返回两个集合的差集 - |
5.4.3数据结构(有待整理)
-
5.5Redis有序集合(zset)
5.5.1简介
zset和set基本是一样的主要是zset增加了一个评分(score),可以根据这个评分进行排序,评分是可以一样的
- 特点:
- 可以根据评分,和postion去获取一个范围的值
5.5.2 常用的命令
| zadd| 将一个或者多个member及score的值添加到有序集key中 | | —- | —- | | zrange (下标问题) | 返回下标在 之间的元素 | | zrange | 可以带分数一起去返回 | | zrangebyscore key min max [withscores] [limit offset count] | 返回有序key,分数在min<==>max的分数按递增排序 | | zrevrangebyscore key max min [withscores] [limit offset count] | 同上,从大到小 | | zincrby | 为分数添加增量 | | zrem | 删除该集合下,指定值的元素 | | zcount | 统计该集合,分数区间的元素个数 | | zrank | 返回该值在集合中排名 从0 开始 |
- 可以根据评分,和postion去获取一个范围的值
5.5.3数据结构
- zset采用了两种数据结构
- 1.hash:关联value和权重score,保障value元素的唯一性,可以通过value找到对应的score
- 2.跳跃表,跳跃表的目的在于给score排序,根据score的范围获取元素的列表
- 跳跃表
简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
实例
对比有序链表和跳跃表,从链表中查询出51
(1) 有序链表
要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
(2) 跳跃表
从第2层开始,1节点比51节点小,向后比较。
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
从此可以看出跳跃表比有序链表效率要高
5.6Redis哈希(hashes)
5.6.1简介
- 是一个键值对集合
- 是一个string类型的field和value的映射表,hash特别适合用于存储对象。
5.6.2常用的命令
| hset| 给key中的field赋值 | | —- | —- | | hget | 从 取值 | | hmset … | 批量设置hash的值 | | hexists | 查看哈希表 key 中,给定域 field 是否存在 | | hkeys | 列出该hash集合的所有field | | hvals | 列出该hash集合的所有value | | hincrby | 为哈希表 key 中的域 field 的值加上增量 1 -1 | | hsetnx | 将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 . |
5.6.3数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用ziplist,否则使用hashtable
6.1Units单位
配置大小单位,开头定义了一些基本的度量单位,只支持bytes,不支持bit
-
6.2includes
-
6.3网络配置相关的
bind
- 设置谁可以访问redis
- 如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应
- protected-mode
- 本地访问保护
- Port
- 端口号
- tcp-backlog
- backlog是一个连接队列
- backlog=为完成三次握手+已完成三次握手的
- timeout
- 一个空闲的客户端在什么时间进行关闭,0代表永不关闭
tcp-keepalive
daemonize
- 是否为守护进程设为yes
- pidfile
- 存放pid文件的位置,每个实例会产生不同的pid
- loglevel
- 指定日志记录级别,Redis总共支持四个级别:debug、verbose、notice、warning,默认为notice
- 四个级别根据使用阶段来选择,生产环境选择notice 或者warning
- logfile
- 日志文件的名称
databases
-
6.6limits
maxclients
- 设置最多同事连接多少客户端
- 默认情况下为10000个客户端
- 如果达到了此限制,redis则会拒绝新的连接请求,并且向这些连接请求方发出“max number of clients reached”以作回应
- maxmemory
- 设置Redis可以用的内存
- 必须设置,一旦内存满了,redis试图移除内部的数据,移除规则可以通过maxmemory-policy来指定
- 如果redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,那么redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等
- 但是对于无内存申请的指令,仍然会正常响应,比如GET等。如果你的redis是主redis(说明你的redis有从redis),那么在设置内存使用上限时,需要在系统中留出一些内存空间给同步队列缓存,只有在你设置的是“不移除”的情况下,才不用考虑这个因素
- maxmemory-policy
- volatile-lru:使用LRU算法移除key,只对设置了过期时间的键;(最近最少使用)
- allkeys-lru:在所有集合key中,使用LRU算法移除key
- volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
- allkeys-random:在所有集合key中,移除随机的key
- volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
- noeviction:不进行移除。针对写操作,只是返回错误信息
- maxmemory-samples
<a name="Kw8cX"></a>### 6.2注意事项1. 禁用防火墙1. systemctl stop firewalld.service1. systemctl disable firewalled.service2. 开启权限访问1. redis.conf注释掉bind 127.0.0.11. protected-mode no<a name="UTMci"></a>### 6.3jedis的常规操作1. 创建动态工程```javapublic class redis {public static void main(String[] args) {Jedis jedis = new Jedis("hadoop102", 6379);String ping = jedis.ping();System.out.println("ping = " + ping);}}
任务

若有收获,就点个赞吧
0 人点赞
