- 组件介绍
- 基础概念
- Kubernetes 基础
- Kubernetes 控制器
- Kubernetes 配置管理
- Kubernetes 安全
- Kubernetes 网络
- Kubernetes 调度器
- Kubernetes 存储
- Helm 包管理
- Kubernetes 监控
- Kubernetes 日志
- Kubernetes 多租户
- Kubernetes 运维 Yaml实例
- 实践技巧
- 高可用的k8s集群构建
- kubeadm-V1.20
- 一、前置知识点
- 二、部署 Nginx+keepalived 高可用负载均衡器
- 三、部署Etcd集群
- 四、安装Docker/kubeadm/kubelet【所有节点】
- 五、部署Kubernetes Master
- 六、加入Kubernetes Node
- 七、部署网络组件
- 八、部署 Dashboard
- 二进制
- 一、前置知识点
- 二、部署Etcd集群
- 三、安装Docker
- 四、部署Master Node
- 五、部署Worker Node
- 六、部署Dashboard和CoreDNS
- 七、扩容多Master(高可用架构)
组件介绍
1.发展经历
MESOS APACHE 分布式资源管理框架 2019-5 Twitter 》 Kubernetes
Docker Swarm 2019-07 阿里云宣布 Docker Swarm 剔除
Kubernetes Google 10年容器化基础架构 borg GO 语言 Borg
特点:
轻量级:消耗资源小
开源
弹性伸缩
负载均衡:IPVS
适合人群:软件工程师 测试工程师 运维工程师 软件架构师 项目经理
2.知识图谱
更详细图谱 F:-—-—\1、Kubernetes - 组件介绍\2、资料: 查看 kubernetes 结构.xmind
Kubernetes 结构 .xmind
介绍说明: 前世今生 KUbernetes 框架 KUbernetes关键字含义
基础概念: 什么是 Pod 控制器类型 K8S 网络通讯模式
Kubernetes: 构建 K8S 集群
资源清单:资源 掌握资源清单的语法 编写 Pod 掌握 Pod 的生命周期*
Pod 控制器:掌握各种控制器的特点以及使用定义方式
服务发现:掌握 SVC 原理及其构建方式
存储:掌握多种存储类型的特点 并且能够在不同环境中选择合适的存储方案(有自己的简介)
调度器:掌握调度器原理 能够根据要求把Pod 定义到想要的节点运行
安全:集群的认证 鉴权 访问控制 原理及其流程
HELM:Linux yum 掌握 HELM 原理 HELM 模板自定义 HELM 部署一些常用插件
运维:修改Kubeadm 达到证书可用期限为 10年 能够构建高可用的 Kubernetes 集群
服务分类
有状态服务:DBMS
无状态服务:LVS APACHE

3.组件说明
Master组件
kube-apiserver
Kubernetes API,集群的统一入口,各组件协调者,以RESTful
API提供接口服务,所有对象资源的增删改查和监听操作都交给
APIServer处理后再提交给Etcd存储。
kube-controller-manager
处理集群中常规后台任务,一个资源对应一个控制器,而
ControllerManager就是负责管理这些控制器的。
kube-scheduler
根据调度算法为新创建的Pod选择一个Node节点,可以任意部署,
可以部署在同一个节点上,也可以部署在不同的节点上。
etcd
分布式键值存储系统。用于保存集群状态数据,比如Pod、Service
等对象信息。
Node组件
kubelet
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周
期,比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态
等工作。kubelet将每个Pod转换成一组容器。
kube-proxy
在Node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。
docker或rocket
容器引擎,运行容器。
基础概念
有了Docker, 为什么还需要Kubernetes?
为提高业务并发和高可用,会使用多台服务器,因此会面向这些问题:
• 多容器跨主机提供服务
• 多容器分布节点部署
• 多容器怎么升级
• 怎么高效管理这些容器
容器编排系统:
• Kubernetes
• Swarm
• Mesos Marathon
kubernetes是什么?
• Kubernetes是Google在2014年开源的一个容器集群管理系统,Kubernetes简称K8s。
• Kubernetes用于容器化应用程序的部署,扩展和管理,目标是让部署容器化应用简单高效。
官方网站:http://www.kubernetes.io
官方文档:https://kubernetes.io/zh/docs/home/
k8s集训营:https://www.qikqiak.com/k8strain/
Kubernetes 基础
资源清单
Pod 原理
Pod 生命周期
Pod 使用进阶
Kubernetes 控制器
ReplicaSet
Deployment
StatefulSet
DaemonSet
Job
HPA
Kubernetes 配置管理
ConfigMap
Secret
ServiceAccount
Kubernetes 安全
RBAC
Security Context
准入控制器
Kubernetes 网络
网络插件
网络策略
Service 服务
Ingress
Kubernetes 调度器
调度器介绍
Pod 调度
Kubernetes 存储
Local 本地存储
Ceph 存储
存储原理
Helm 包管理
Helm
Charts
模板开发
Chart Hooks
Kubernetes 监控
Prometheus
Grafana
Kubernetes 日志
ELK
Kubernetes 多租户
Kubernetes 运维 Yaml实例
pod模板
前端应用
apiVersion: apps/v1kind: Deploymentmetadata:name: scm-web-testnamespace: testspec:replicas: 1selector:matchLabels:app: scm-web-testtemplate:metadata:labels:app: scm-web-testspec:tolerations: # 由于我这里的边缘节点只有master一个节点,所有需要加上容忍- operator: "Exists"nodeSelector: # 固定在边缘节点#kubeadm: appkubernetes.io/os: linuxcontainers:- name: scm-web-testimage: "192.168.16.18/scm-test/batar-scm-web:1.77"---apiVersion: v1kind: Servicemetadata:name: scm-web-testnamespace: testspec:ports:- port: 80 # service端口protocol: TCP # 协议targetPort: 80 # 容器端口nodePort: 31004selector: # 标签选择器app: scm-web-test # 指定关联Pod的标签type: NodePort # 服务类型---apiVersion: networking.k8s.io/v1kind: Ingressmetadata:name: scm-web-testnamespace: testspec:rules:- host: scm-web-test.app.batarhttp:paths:- path: /pathType: Prefixbackend:service:name: scm-web-testport:number: 80
Java应用
apiVersion: apps/v1kind: Deploymentmetadata:name: scm-testnamespace: testspec:replicas: 2selector:matchLabels:app: scm-testtemplate:metadata:labels:app: scm-testspec:tolerations: # 由于我这里的边缘节点只有master一个节点,所有需要加上容忍- operator: "Exists"nodeSelector: # 固定在边缘节点#kubeadm: appkubernetes.io/os: linuxcontainers:- name: scm-testimage: "192.168.16.18/scm-test/batar-scm:1.45"env:- name: PARAMSvalue: "--server.port=8080 --spring.profiles.active=test"---apiVersion: v1kind: Servicemetadata:name: scm-testnamespace: testspec:ports:- port: 8080 # service端口protocol: TCP # 协议targetPort: 8080 # 容器端口nodePort: 31003selector: # 标签选择器app: scm-test # 指定关联Pod的标签type: NodePort # 服务类型---apiVersion: networking.k8s.io/v1kind: Ingressmetadata:name: scm-testnamespace: testspec:rules:- host: scm-test.app.batarhttp:paths:- path: /pathType: Prefixbackend:service:name: scm-testport:number: 8080
ingress-nginx
mandatory.yaml
apiVersion: v1
kind: Namespace
metadata:
name: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: nginx-configuration
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: tcp-services
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
kind: ConfigMap
apiVersion: v1
metadata:
name: udp-services
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: nginx-ingress-clusterrole
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
verbs:
- list
- watch
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- apiGroups:
- ""
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- events
verbs:
- create
- patch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses/status
verbs:
- update
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: Role
metadata:
name: nginx-ingress-role
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
rules:
- apiGroups:
- ""
resources:
- configmaps
- pods
- secrets
- namespaces
verbs:
- get
- apiGroups:
- ""
resources:
- configmaps
resourceNames:
# Defaults to "<election-id>-<ingress-class>"
# Here: "<ingress-controller-leader>-<nginx>"
# This has to be adapted if you change either parameter
# when launching the nginx-ingress-controller.
- "ingress-controller-leader-nginx"
verbs:
- get
- update
- apiGroups:
- ""
resources:
- configmaps
verbs:
- create
- apiGroups:
- ""
resources:
- endpoints
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: nginx-ingress-role-nisa-binding
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: nginx-ingress-role
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: nginx-ingress-clusterrole-nisa-binding
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: nginx-ingress-clusterrole
subjects:
- kind: ServiceAccount
name: nginx-ingress-serviceaccount
namespace: ingress-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
template:
metadata:
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/part-of: ingress-nginx
annotations:
prometheus.io/port: "10254"
prometheus.io/scrape: "true"
spec:
# wait up to five minutes for the drain of connections
terminationGracePeriodSeconds: 300
serviceAccountName: nginx-ingress-serviceaccount
tolerations: # 由于我这里的边缘节点只有master一个节点,所有需要加上容忍
- operator: "Exists"
nodeSelector: # 固定在边缘节点
#disktype: ssd
kubernetes.io/os: linux
#kubernetes.io/hostname: k8s-master
hostNetwork: true # 将pod使用主机网命名空间
containers:
- name: nginx-ingress-controller
image: quay.io/kubernetes-ingress-controller/nginx-ingress-controller:0.26.1
#command: [ "/bin/bash", "-ce", "tail -f /dev/null" ]
args:
- /nginx-ingress-controller
- --configmap=$(POD_NAMESPACE)/nginx-configuration
- --tcp-services-configmap=$(POD_NAMESPACE)/tcp-services
- --udp-services-configmap=$(POD_NAMESPACE)/udp-services
- --publish-service=$(POD_NAMESPACE)/ingress-nginx
- --annotations-prefix=nginx.ingress.kubernetes.io
securityContext:
allowPrivilegeEscalation: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
# www-data -> 33
runAsUser: 33
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
ports:
- name: http
containerPort: 80
- name: https
containerPort: 443
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 10254
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 10
lifecycle:
preStop:
exec:
command:
- /wait-shutdown
---
mysql
mysql-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: common-resource
name: mysql-config
data:
mysqld.cnf: |-
[mysqld]
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
datadir = /var/lib/mysql
#log-error = /var/log/mysql/error.log
# By default we only accept connections from localhost
#bind-address = 127.0.0.1
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
max_connections=5000
mysql-pv.yaml
---
apiVersion: v1
kind: PersistentVolume
metadata:
namespace: common-resource
name: mysql-pv
spec:
capacity:
storage: 100G
accessModes:
- ReadWriteMany
storageClassName: managed-nfs-storage
hostPath:
path: "/home/data/k8s/test/hostpath/mysql"
#nfs:
# server: 192.168.33.157 # NFS服务器地址
# path: /nfsdata/data/mysql # NFS目录
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
namespace: common-resource
name: mysql-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: managed-nfs-storage
resources:
requests:
storage: 100G
mysql-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: common-resource
name: mysql
spec:
serviceName: mysql
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
nodeSelector: # 固定在边缘节点
local1: 16-25
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
ports:
- containerPort: 3306
volumeMounts:
- name: mysql-data
mountPath: "/var/lib/mysql"
- name: config-volume
mountPath: "/etc/mysql/mysql.conf.d/"
- name: date-mysql
mountPath: /etc/localtime
volumes:
- name: mysql-data
persistentVolumeClaim:
claimName: mysql-pvc
- name: config-volume
configMap:
name: mysql-config
- name: date-mysql
hostPath:
path: /etc/localtim
mysql-svc.yaml
--- #以下是创建svc的yaml文件
apiVersion: v1
kind: Service
metadata:
namespace: common-resource
name: mysql
spec:
type: NodePort
clusterIP: 10.105.254.185
ports:
- port: 3306
targetPort: 3306
nodePort: 30002
selector:
app: mysql
selector:
app: mysql
redis
redis-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
namespace: common-resource
name: redis-conf
data:
redis.conf: |
bind 0.0.0.0
port 6379
#requirepass 111111
appendonly yes
cluster-config-file nodes-6379.conf
pidfile /redis/log/redis-6379.pid
cluster-config-file /redis/conf/redis.conf
dir /redis/data/
logfile /redis/log/redis-6379.log
cluster-node-timeout 5000
protected-mode no
redis-pv.ymal
---
apiVersion: v1
kind: PersistentVolume
metadata:
namespace: common-resource
name: redis-pv
spec:
capacity:
storage: 1G
accessModes:
- ReadWriteMany
storageClassName: nfsredis
hostPath:
path: "/home/data/k8s/test/hostpath/redis"
#nfs:
# server: 192.168.16.24 # NFS服务器地址
# path: "/home/nfsdata/data/redis" # NFS目录
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
namespace: common-resource
name: redis-pvc
spec:
volumeName: redis-pv
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1G
storageClassName: nfsredis
redis-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
namespace: common-resource
name: redis
spec:
replicas: 1
serviceName: redis
selector:
matchLabels:
name: redis
template:
metadata:
labels:
name: redis
spec:
# nodeName: gggd xxx-xxx-xxx-xxx 指定调度节点
initContainers:
- name: init-redis
image: busybox
command: ['sh', '-c', 'mkdir -p /redis/log/;mkdir -p /redis/conf/;mkdir -p /redis/data/']
volumeMounts:
- name: redis-pvc
mountPath: /redis/
nodeSelector: # 固定在边缘节点
local1: 16-25
containers:
- name: redis
image: redis:5.0.6
imagePullPolicy: IfNotPresent
command:
- sh
- -c
- "exec redis-server /redis/conf/redis.conf"
ports:
- containerPort: 6379
name: redis
protocol: TCP
volumeMounts:
- name: redis-config
mountPath: /redis/conf/
- name: redis-pvc
mountPath: /redis/
- name: date-redis
mountPath: /etc/localtime
#command: ["sleep", "60000"]
volumes:
- name: redis-config
configMap:
name: redis-conf
- name: redis-pvc
persistentVolumeClaim:
claimName: redis-pvc
- name: date-redis
hostPath:
path: /etc/localtime
redis-svc.yaml
kind: Service
apiVersion: v1
metadata:
namespace: common-resource
labels:
name: redis
name: redis
spec:
type: NodePort
clusterIP: 10.104.65.245
ports:
- name: redis
port: 6379
targetPort: 6379
nodePort: 30003
selector:
name: redis
faastdfs
tracker-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: tracker-deploy # 部署的容器名称
namespace: common-resource
spec: # 该 Deployment 的规格说明
replicas: 1 # 副本数
selector:
matchLabels:
app: tracker-deploy
template:
metadata:
labels:
app: tracker-deploy
spec:
nodeSelector: # 固定在边缘节点
local1: 16-25
hostNetwork: true # 使用主机网络
containers:
- name: tracker
image: delron/fastdfs:latest
imagePullPolicy: Always #获取镜像的策略 Always表示下载镜像 IfNotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
ports:
- containerPort: 22122
name: tracker
- containerPort: 8080
name: http
#protocol: TCP #端口协议,支持TCP和UDP,默认TCP
volumeMounts:
# - name: date-tracker
# mountPath: /etc/localtime
#command: ["sleep", "60000"]
- name: tracker-var
mountPath: /var/fdfs
command: ["/usr/bin/start1.sh","tracker"]
volumes:
- name: tracker-var
hostPath:
path: /home/data/k8s/test/hostpath/fastdfs/tracker/ # 在宿主机上存储的地址
storage-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: storage-deploy
namespace: common-resource
spec:
replicas: 1
selector:
matchLabels:
app: storage-deploy
template:
metadata:
labels:
app: storage-deploy
spec:
nodeSelector: # 固定在边缘节点
local1: 16-25
hostNetwork: true # 使用主机网络
containers:
- name: storage-deploy
image: delron/fastdfs:latest # 表示引用镜像的地址
imagePullPolicy: Always #获取镜像的策略 Always表示下载镜像 IfNotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
ports:
- containerPort: 23000
name: storage
- containerPort: 8888
name: nginx
#protocol: TCP #端口协议,支持TCP和UDP,默认TCP
volumeMounts:
- name: storage-volume
mountPath: /var/fdfs
- name: nginx-volume
mountPath: /usr/local/nginx/conf/conf.d
#- name: date-storage
# mountPath: /etc/localtime
#command: ["sleep", "60000"]
env:
- name: TRACKER_SERVER
value: 192.168.16.25:22122
#value: 10.96.0.110:22122
command: ["/usr/bin/start1.sh","storage"]
volumes:
- name: storage-volume
hostPath:
path: /home/data/k8s/test/hostpath/fastdfs/storage # 在宿主机上存储的地址,可自行配置
- name: nginx-volume
hostPath:
path: /home/data/k8s/test/hostpath/fastdfs/nginx # 在宿主机上存储的地址,可自行配置
fastdfs-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: tracker
namespace: common-resource
labels:
app: tracker
spec:
selector:
app: tracker-deploy # 这里选择器一定要选择容器的标签
type: NodePort # 此处可以是ClusterIP,但ClusterIP只能在集群内部调用,外网访问不了
#clusterIP: 10.96.0.110
ports:
- port: 22122
targetPort: 22122
nodePort: 30007
name: tracker
- port: 8080
targetPort: 8080
nodePort: 30008
name: http
---
apiVersion: v1
kind: Service
metadata:
name: storage
namespace: common-resource
labels:
app: storage
spec:
selector:
app: storage-deploy
type: NodePort
ports:
- port: 23000
targetPort: 23000
nodePort: 30010
name: storage
- port: 8888
targetPort: 8888
nodePort: 30009
name: nginx
premetheus
alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: ops
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'baojingtongzhi@163.com'
smtp_auth_username: 'baojingtongzhi@163.com'
smtp_auth_password: 'NCKBJTSASSXMRQBM'
receivers:
- name: default-receiver
email_configs:
- to: "zhenliang369@163.com"
route:
group_interval: 1m
group_wait: 10s
receiver: default-receiver
repeat_interval: 1m
alertmanager-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: ops
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
version: v0.14.0
template:
metadata:
labels:
k8s-app: alertmanager
version: v0.14.0
spec:
containers:
- name: prometheus-alertmanager
image: "prom/alertmanager:v0.14.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/alertmanager.yml
- --storage.path=/data
- --web.external-url=/
ports:
- containerPort: 9093
readinessProbe:
httpGet:
path: /#/status
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: "/data"
subPath: ""
resources:
limits:
cpu: 10m
memory: 50Mi
requests:
cpu: 10m
memory: 50Mi
- name: prometheus-alertmanager-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9093/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: config-volume
configMap:
name: alertmanager-config
- name: storage-volume
persistentVolumeClaim:
claimName: alertmanager
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager
namespace: ops
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: ops
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Alertmanager"
spec:
type: "NodePort"
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9093
nodePort: 30093
selector:
k8s-app: alertmanager
grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: ops
spec:
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
nodeSelector: # 固定在边缘节点
local: 16-25
containers:
- name: grafana
image: grafana/grafana:7.5.2
ports:
- containerPort: 3000
protocol: TCP
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- name: grafana-data
mountPath: /var/lib/grafana
subPath: grafana
securityContext:
fsGroup: 472
runAsUser: 472
volumes:
- name: grafana-data
persistentVolumeClaim:
claimName: grafana
---
apiVersion: v1
kind: PersistentVolume
metadata:
namespace: ops
name: grafana-pv
spec:
capacity:
storage: 5G
accessModes:
- ReadWriteMany
storageClassName: grafana
hostPath:
path: "/home/data/k8s/test/hostpath/grafana"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: ops
spec:
storageClassName: grafana
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5G
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: ops
spec:
type: NodePort
ports:
- port : 80
targetPort: 3000
nodePort: 30012
selector:
app: grafana
---
apiVersion: batch/v1
kind: Job
metadata:
name: grafana-chown
namespace: ops
spec:
template:
spec:
restartPolicy: Never
containers:
- name: grafana-chown
command: ["chown", "-R", "472:472", "/var/lib/grafana"]
image: busybox
imagePullPolicy: IfNotPresent
volumeMounts:
- name: storage
subPath: grafana
mountPath: /var/lib/grafana
volumes:
- name: storage
persistentVolumeClaim:
claimName: grafana
kube-state-metrics.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: ops
labels:
k8s-app: kube-state-metrics
spec:
selector:
matchLabels:
k8s-app: kube-state-metrics
version: v1.3.0
replicas: 1
template:
metadata:
labels:
k8s-app: kube-state-metrics
version: v1.3.0
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: lizhenliang/kube-state-metrics:v1.8.0
ports:
- name: http-metrics
containerPort: 8080
- name: telemetry
containerPort: 8081
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
- name: addon-resizer
image: lizhenliang/addon-resizer:1.8.6
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 30Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --container=kube-state-metrics
- --cpu=100m
- --extra-cpu=1m
- --memory=100Mi
- --extra-memory=2Mi
- --threshold=5
- --deployment=kube-state-metrics
volumes:
- name: config-volume
configMap:
name: kube-state-metrics-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-state-metrics-config
namespace: ops
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
---
apiVersion: v1
kind: Service
metadata:
name: kube-state-metrics
namespace: ops
annotations:
prometheus.io/scrape: 'true'
spec:
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
protocol: TCP
- name: telemetry
port: 8081
targetPort: telemetry
protocol: TCP
selector:
k8s-app: kube-state-metrics
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: ops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
- apiGroups: ["networking.k8s.io", "extensions"]
resources:
- ingresses
verbs: ["list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources:
- storageclasses
verbs: ["list", "watch"]
- apiGroups: ["certificates.k8s.io"]
resources:
- certificatesigningrequests
verbs: ["list", "watch"]
- apiGroups: ["policy"]
resources:
- poddisruptionbudgets
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: kube-state-metrics-resizer
namespace: ops
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get"]
- apiGroups: ["extensions","apps"]
resources:
- deployments
resourceNames: ["kube-state-metrics"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: ops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kube-state-metrics
namespace: ops
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics-resizer
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: ops
node-exporter.yml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: ops
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
k8s-app: node-exporter
version: v0.15.2
template:
metadata:
labels:
k8s-app: node-exporter
version: v0.15.2
spec:
containers:
- name: prometheus-node-exporter
image: "prom/node-exporter:v0.15.2"
imagePullPolicy: "IfNotPresent"
args:
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
ports:
- name: metrics
containerPort: 9100
hostPort: 9100
volumeMounts:
- name: proc
mountPath: /host/proc
readOnly: true
- name: sys
mountPath: /host/sys
readOnly: true
resources:
limits:
cpu: 10m
memory: 50Mi
requests:
cpu: 10m
memory: 50Mi
hostNetwork: true
hostPID: true
hostIPC: true
volumes:
- name: proc
hostPath:
path: /proc
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
- name: dev
hostPath:
path: /dev
---
apiVersion: v1
kind: Service
metadata:
name: node-exporter
namespace: ops
annotations:
prometheus.io/scrape: "true"
spec:
clusterIP: None
ports:
- name: metrics
port: 9100
protocol: TCP
targetPort: 9100
selector:
k8s-app: node-exporter
prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: ops
data:
prometheus.yml: |
rule_files:
- /etc/config/rules/*.rules
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-kubelet
kubernetes_sd_configs:
- role: node # 发现集群中的节点
relabel_configs:
# 将标签(.*)作为新标签名,原有值不变
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
# 将标签(.*)作为新标签名,原有值不变
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
# 实际访问指标接口 https://NodeIP:10250/metrics/cadvisor,这里替换默认指标URL路径
- target_label: __metrics_path__
replacement: /metrics/cadvisor
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints # 从Service列表中的Endpoint发现Pod为目标
relabel_configs:
# Service没配置注解prometheus.io/scrape的不采集
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
# 重命名采集目标协议
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
# 重命名采集目标指标URL路径
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
# 重命名采集目标地址
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
# 将K8s标签(.*)作为新标签名,原有值不变
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
# 生成命名空间标签
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
# 生成Service名称标签
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod # 发现所有Pod为目标
# 重命名采集目标协议
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
# 重命名采集目标指标URL路径
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
# 重命名采集目标地址
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
# 将K8s标签(.*)作为新标签名,原有值不变
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
# 生成命名空间标签
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
# 生成Service名称标签
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:80"]
prometheus-deployment.yam
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: ops
labels:
k8s-app: prometheus
spec:
replicas: 1
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
spec:
serviceAccountName: prometheus
initContainers:
- name: "init-chown-data"
image: "busybox:latest"
imagePullPolicy: "IfNotPresent"
command: ["chown", "-R", "65534:65534", "/data"]
volumeMounts:
- name: prometheus-data
mountPath: /data
subPath: ""
nodeSelector: # 固定在边缘节点
local: 16-25
containers:
- name: prometheus-server-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9090/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
- name: prometheus-server
image: "prom/prometheus:v2.20.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
resources:
limits:
cpu: 500m
memory: 1500Mi
requests:
cpu: 200m
memory: 1000Mi
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: prometheus-data
mountPath: /data
subPath: ""
- name: prometheus-rules
mountPath: /etc/config/rules
volumes:
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-rules
configMap:
name: prometheus-rules
- name: prometheus-data
persistentVolumeClaim:
claimName: prometheus
---
apiVersion: v1
kind: PersistentVolume
metadata:
namespace: ops
name: prometheus-pv
spec:
capacity:
storage: 10G
accessModes:
- ReadWriteMany
storageClassName: prometheus
hostPath:
path: "/home/data/k8s/test/hostpath/prometheus"
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus
namespace: ops
spec:
storageClassName: prometheus
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10G
---
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: ops
spec:
type: NodePort
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
nodePort: 30011
selector:
k8s-app: prometheus
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: ops
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- nonResourceURLs:
- "/metrics"
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: ops
prometheus-rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: ops
data:
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: error
annotations:
summary: "Instance {{ $labels.instance }} 停止工作"
description: "{{ $labels.instance }} job {{ $labels.job }} 已经停止5分钟以上."
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: |
100 - (node_filesystem_free{fstype=~"ext4|xfs"} /
node_filesystem_size{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} 分区使用率过高"
description: "{{ $labels.instance }}: {{ $labels.mountpoint }} 分区使用大于80% (当前值: {{ $value }})"
- alert: NodeMemoryUsage
expr: |
100 - (node_memory_MemFree+node_memory_Cached+node_memory_Buffers) /
node_memory_MemTotal * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} 内存使用率过高"
description: "{{ $labels.instance }}内存使用大于80% (当前值: {{ $value }})"
- alert: NodeCPUUsage
expr: |
100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 60
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} CPU使用率过高"
description: "{{ $labels.instance }}CPU使用大于60% (当前值: {{ $value }})"
- alert: KubeNodeNotReady
expr: |
kube_node_status_condition{condition="Ready",status="true"} == 0
for: 1m
labels:
severity: error
annotations:
message: '{{ $labels.node }} 已经有10多分钟没有准备好了.'
pod.rules: |
groups:
- name: pod.rules
rules:
- alert: PodCPUUsage
expr: |
sum(rate(container_cpu_usage_seconds_total{image!=""}[1m]) * 100) by (pod_name, namespace) > 80
for: 5m
labels:
severity: warning
annotations:
summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod_name }} CPU使用大于80% (当前值: {{ $value }})"
- alert: PodMemoryUsage
expr: |
sum(container_memory_rss{image!=""}) by(pod_name, namespace) /
sum(container_spec_memory_limit_bytes{image!=""}) by(pod_name, namespace) * 100 != +inf > 80
for: 5m
labels:
severity: warning
annotations:
summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod_name }} 内存使用大于80% (当前值: {{ $value }})"
- alert: PodNetworkReceive
expr: |
sum(rate(container_network_receive_bytes_total{image!="",name=~"^k8s_.*"}[5m]) /1000) by (pod_name,namespace) > 30000
for: 5m
labels:
severity: warning
annotations:
summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod_name }} 入口流量大于30MB/s (当前值: {{ $value }}K/s)"
- alert: PodNetworkTransmit
expr: |
sum(rate(container_network_transmit_bytes_total{image!="",name=~"^k8s_.*"}[5m]) /1000) by (pod_name,namespace) > 30000
for: 5m
labels:
severity: warning
annotations:
summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod_name }} 出口流量大于30MB/s (当前值: {{ $value }}/K/s)"
- alert: PodRestart
expr: |
sum(changes(kube_pod_container_status_restarts_total[1m])) by (pod,namespace) > 0
for: 1m
labels:
severity: warning
annotations:
summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod重启 (当前值: {{ $value }})"
- alert: PodFailed
expr: |
sum(kube_pod_status_phase{phase="Failed"}) by (pod,namespace) > 0
for: 5s
labels:
severity: error
annotations:
summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态Failed (当前值: {{ $value }})"
- alert: PodPending
expr: |
sum(kube_pod_status_phase{phase="Pending"}) by (pod,namespace) > 0
for: 1m
labels:
severity: error
annotations:
summary: "命名空间: {{ $labels.namespace }} | Pod名称: {{ $labels.pod }} Pod状态Pending (当前值: {{ $value }})"
elk
elasticsearch.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: ops
labels:
k8s-app: elasticsearch
spec:
serviceName: elasticsearch
selector:
matchLabels:
k8s-app: elasticsearch
template:
metadata:
labels:
k8s-app: elasticsearch
spec:
containers:
- image: elasticsearch:7.12.0
name: elasticsearch
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 0.5
memory: 500Mi
env:
- name: "discovery.type"
value: "single-node"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx2g"
ports:
- containerPort: 9200
name: db
protocol: TCP
volumeMounts:
- name: elasticsearch-data
mountPath: /usr/share/elasticsearch/data
- name: date-es
mountPath: /etc/localtime
volumes:
- name: elasticsearch-data
hostPath:
path: /home/data/k8s/test/hostpath/elk
- name: date-es
hostPath:
path: /etc/localtime
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: ops
spec:
clusterIP: None
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch
# volumeClaimTemplates:
# - metadata:
# name: elasticsearch-data
# spec:
# storageClassName: "managed-nfs-storage"
# accessModes: [ "ReadWriteOnce" ]
# resources:
# requests:
# storage: 20Gi
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: ops
spec:
clusterIP: None
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch
# volumeClaimTemplates:
# - metadata:
# name: elasticsearch-data
# spec:
# storageClassName: "managed-nfs-storage"
# accessModes: [ "ReadWriteOnce" ]
# resources:
# requests:
# storage: 20Gi
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: ops
spec:
clusterIP: None
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch
filebeat-kubernetes.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: ops
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.config:
inputs:
# Mounted `filebeat-inputs` configmap:
path: ${path.config}/inputs.d/*.yml
# Reload inputs configs as they change:
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
# Reload module configs as they change:
reload.enabled: false
output.elasticsearch:
hosts: ['elasticsearch.ops:9200']
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-inputs
namespace: ops
labels:
k8s-app: filebeat
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: ops
labels:
k8s-app: filebeat
spec:
selector:
matchLabels:
k8s-app: filebeat
template:
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
tolerations: # 由于我这里的边缘节点只有master一个节点,所有需要加上容忍
- operator: "Exists"
nodeSelector: # 固定在边缘节点
kubernetes.io/os: linux
containers:
- name: filebeat
image: elastic/filebeat:7.9.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: inputs
mountPath: /usr/share/filebeat/inputs.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: date-config
mountPath: /etc/localtime
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: inputs
configMap:
defaultMode: 0600
name: filebeat-inputs
- name: date-config
hostPath:
path: /etc/localtime
# data folder stores a registry of read status for all files, so we don't send everything again on a Filebeat pod restart
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: ops
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: ops
labels:
k8s-app: filebeat
k8s-logs.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: k8s-logs-filebeat-config
namespace: ops
data:
filebeat.yml: |
filebeat.inputs:
- type: log
paths:
- /var/log/messages
fields:
app: k8s
type: module
fields_under_root: true
setup.ilm.enabled: false
setup.template.name: "k8s-module"
setup.template.pattern: "k8s-module-*"
output.elasticsearch:
hosts: ['elasticsearch-0.elasticsearch.kube-system:9200']
index: "k8s-module-%{+yyyy.MM.dd}"
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: k8s-logs
namespace: ops
spec:
selector:
matchLabels:
project: k8s
app: filebeat
template:
metadata:
labels:
project: k8s
app: filebeat
spec:
tolerations: # 由于我这里的边缘节点只有master一个节点,所有需要加上容忍
- operator: "Exists"
nodeSelector: # 固定在边缘节点
kubernetes.io/os: linux
containers:
- name: filebeat
image: elastic/filebeat:7.9.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: k8s-logs
mountPath: /var/log/messages
- name: date-filebeat
mountPath: /etc/localtime
volumes:
- name: k8s-logs
hostPath:
path: /var/log/messages
- name: filebeat-config
configMap:
name: k8s-logs-filebeat-config
- name: date-filebeat
hostPath:
path: /etc/localtime
kibana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: ops
labels:
k8s-app: kibana
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kibana
template:
metadata:
labels:
k8s-app: kibana
spec:
containers:
- name: kibana
image: kibana:7.12.0
volumeMounts:
- name: date-config
mountPath: /etc/localtime
resources:
limits:
cpu: 2
memory: 2Gi
requests:
cpu: 0.5
memory: 500Mi
env:
- name: ELASTICSEARCH_HOSTS
value: http://elasticsearch.ops:9200
- name: I18N_LOCALE
value: zh-CN
ports:
- containerPort: 5601
name: ui
protocol: TCP
volumes:
- name: date-config
hostPath:
path: /etc/localtime
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: ops
spec:
type: NodePort
ports:
- port: 5601
protocol: TCP
targetPort: ui
nodePort: 30019
selector:
k8s-app: kibana
zookeeper
zookeeper-pv.yaml
kind: PersistentVolume
apiVersion: v1
metadata:
name: zookeeper-pv
spec:
accessModes:
- ReadWriteOnce #访问模式定义为只能以读写的方式挂载到单个节点
capacity:
storage: 1Gi
persistentVolumeReclaimPolicy: Retain
storageClassName: zookeeper-nfs
nfs:
path: /nfsdata/data/zookeeper/
server: 192.168.33.157
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: zookeeper-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: zookeeper-nfs #这里指定关联的PV名称
zookeeper-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: zookeeper
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
containers:
- name: zookeeper
image: zookeeper
ports:
- containerPort: 2181
volumeMounts:
- name: zookeeper-persistent-storage
mountPath: /data
- name: zookeeper-persistent-storage
mountPath: /conf
- name: zookeeper-persistent-storage
mountPath: /logs
volumes:
- name: zookeeper-persistent-storage
persistentVolumeClaim:
claimName: zookeeper-pvc #指定pvc的名称
zookeeper-svc.yaml
--- #以下是创建svc的yaml文件
apiVersion: v1
kind: Service
metadata:
name: zookeeper
spec:
type: NodePort
ports:
- port: 2181
targetPort: 2181
nodePort: 32181
selector:
app: zookeeper
selector:
app: zookeeper
activemq
activemq-pv.yaml
kind: PersistentVolume
apiVersion: v1
metadata:
name: activemq-pv
spec:
accessModes:
- ReadWriteOnce #访问模式定义为只能以读写的方式挂载到单个节点
capacity:
storage: 1Gi
persistentVolumeReclaimPolicy: Retain
storageClassName: activemq-nfs
nfs:
path: /nfsdata/data/activemq
server: 192.168.33.157
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: activemq-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: activemq-nfs #这里指定关联的PV名称
activemq-deplo.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: activemq
spec:
replicas: 1
selector:
matchLabels:
app: activemq
template:
metadata:
labels:
app: activemq
spec:
containers:
- name: activemq
image: webcenter/activemq
ports:
- containerPort: 61616
- containerPort: 8161
volumeMounts:
- name: activemq-persistent-storage
mountPath: /data
volumes:
- name: activemq-persistent-storage
persistentVolumeClaim:
claimName: activemq-pvc #指定pvc的名称
activemq-svc.yaml
--- #以下是创建svc的yaml文件
apiVersion: v1
kind: Service
metadata:
name: activemq
spec:
type: NodePort
ports:
- name: activemq-gl
port: 61616
targetPort: 61616
nodePort: 31616
- name: activemq-web
port: 8161
targetPort: 8161
nodePort: 31161
selector:
app: activemq
xxl-job-admin
k8s 部署xxl-job-admin 流程
需要提前部署好sql
跑sql脚本tables_xxl_job.sql,创建库和表
需要的镜像提前下载 xuxueli/xxl-job-admin:2.2.0
部署xxl-job-admin
kubectl apply -f xxx.yaml
最后登陆
Nodeport:端口(service暴露的端口)
用户名/密码:
admin/123456
tables_xxl_job.sql
# XXL-JOB v2.2.0
# Copyright (c) 2015-present, xuxueli.
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_cron` varchar(128) NOT NULL COMMENT '任务执行CRON',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` varchar(512) DEFAULT NULL COMMENT '执行器地址列表,多地址逗号分隔',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL);
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_cron`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '0 0 0 * * ? *', '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;
xxl-jod-admin-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
#namespace: ops
name: xxl-job-admin
spec:
replicas: 1
selector:
matchLabels:
app: xxl-job-admin
template:
metadata:
labels:
app: xxl-job-admin
spec:
containers:
- name: xxl-job-admin
image: xuxueli/xxl-job-admin:2.2.0
imagePullPolicy: Always
ports:
- containerPort: 8080
env:
- name: PARAMS # 定义变量,接收sql的用户和密码
value: "--spring.datasource.url=jdbc:mysql://mysql:3306/xxl_job?Unicode=true&characterEncoding=UTF-8&useSSL=false --spring.datasource.username=root --spring.datasource.password=123456 --spring.mail.username=fdd39969@163.com --spring.mail.password=Flyaway123"
---
apiVersion: v1
kind: Service
metadata:
#namespace: ops
name: xxl-job-admin
labels:
app: xxl-job-admin
spec:
ports:
type: NodePort
ports:
- port: 8080
targetPort: 8080
nodePort: 30080
#protocol: TCP
#name: http
selector:
app: xxl-job-admin
seata
seata-server.yaml
apiVersion: v1
kind: Service
metadata:
name: seata-server
namespace: common-resource
labels:
k8s-app: seata-server
spec:
type: NodePort
clusterIP: 10.98.240.90
ports:
- port: 8091
nodePort: 30018
protocol: TCP
name: http
selector:
k8s-app: seata-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: seata-server
namespace: common-resource
labels:
k8s-app: seata-server
spec:
replicas: 1
selector:
matchLabels:
k8s-app: seata-server
template:
metadata:
labels:
k8s-app: seata-server
spec:
nodeSelector: # 固定在边缘节点
local1: 16-25
containers:
- name: seata-server
image: docker.io/seataio/seata-server:latest
imagePullPolicy: IfNotPresent
#volumeMounts:
#- name: date-redis
# mountPath: /etc/localtime
env:
- name: SEATA_PORT
value: "8091"
- name: STORE_MODE
value: file
ports:
- name: http
containerPort: 8091
protocol: TCP
#volumes:
#- name: date-redis
# hostPath:
# path: /etc/localtime
dubbo-admin
dubbo-admin-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dubbo-admin
namespace: common-resource
labels:
app: dubbo-admin
spec:
replicas: 1
selector:
matchLabels:
app: dubbo-admin
template:
metadata:
labels:
app: dubbo-admin
spec:
containers:
- name: dubbo-admin
image: chenchuxin/dubbo-admin
imagePullPolicy: Always
# volumeMounts:
# - name: date-dubbo
# mountPath: /etc/localtime
env:
- name: dubbo.registry.address
value: zookeeper://10.107.211.169:2181
- name: dubbo.admin.root.password
value: root
- name: dubbo.admin.guest.password
value: guest
#command: [ "/bin/bash", "-ce", "java -Dadmin.registry.address=zookeeper://10.102.73.149:2181 -Dadmin.config-center=zookeeper://10.102.73.149:2181 -Dadmin.metadata-report.address=zookeeper://10.102.73.149:2181 -XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap -Djava.security.egd=file:/dev/./urandom -jar /app.jar"]
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 60
periodSeconds: 20
dubbo-admin-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: dubbo-admin
namespace: common-resource
labels:
app: dubbo-admin
spec:
selector:
app: dubbo-admin
type: NodePort
clusterIP: 10.110.181.11
ports:
- name: dubbo-admin-80
port: 8080
targetPort: 8080
nodePort: 30013
实践技巧
升级集群
修改源码 证书可用时间
高可用的k8s集群构建
kubeadm-V1.20
一、前置知识点
1.1 生产环境可部署Kubernetes集群的两种方式
目前生产部署Kubernetes集群主要有两种方式:
• kubeadm
Kubeadm是一个K8s部署工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。
• 二进制包
从github下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
这里采用kubeadm搭建集群。
kubeadm工具功能:
• kubeadm init:初始化一个Master节点
• kubeadm join:将工作节点加入集群
• kubeadm upgrade:升级K8s版本
• kubeadm token:管理 kubeadm join 使用的令牌
• kubeadm reset:清空 kubeadm init 或者 kubeadm join 对主机所做的任何更改
• kubeadm version:打印 kubeadm 版本
• kubeadm alpha:预览可用的新功能
1.2 准备环境
服务器要求:
• 建议最小硬件配置:2核CPU、2G内存、30G硬盘
• 服务器最好可以访问外网,会有从网上拉取镜像需求,如果服务器不能上网,需要提前下载对应镜像并导入节点
软件环境:
| 软件 | 版本 |
|---|---|
| 操作系统 | Centos7.8_x64 (mini) |
| Docker | 19-ce |
| Kubernetes | 1.20 |
服务器整体规划:
| 角色 | IP | 其它单装组件 |
|---|---|---|
| k8s-master1 | 192.168.31.61 | docker,etcd,nginx,keepalived |
| k8s-master2 | 192.168.31.62 | docker,etcd,nginx,keepalived |
| k8s-node1 | 192.168.31.63 | docker,etcd |
| 负载均衡器对外IP | 192.168.31.88 (VIP) |
1.3 操作系统初始化配置
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
# 根据规划设置主机名
hostnamectl set-hostname <hostname>
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.31.61 k8s-master1
192.168.31.62 k8s-master2
192.168.31.63 k8s-node1
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 生效
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
二、部署 Nginx+keepalived 高可用负载均衡器
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。
针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:Etcd数据库的高可用性和Kubernetes Master组件的高可用性。 而kubeadm搭建的K8s集群,Etcd只起了一个,存在单点,所以我们这里会独立搭建一个Etcd集群。
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
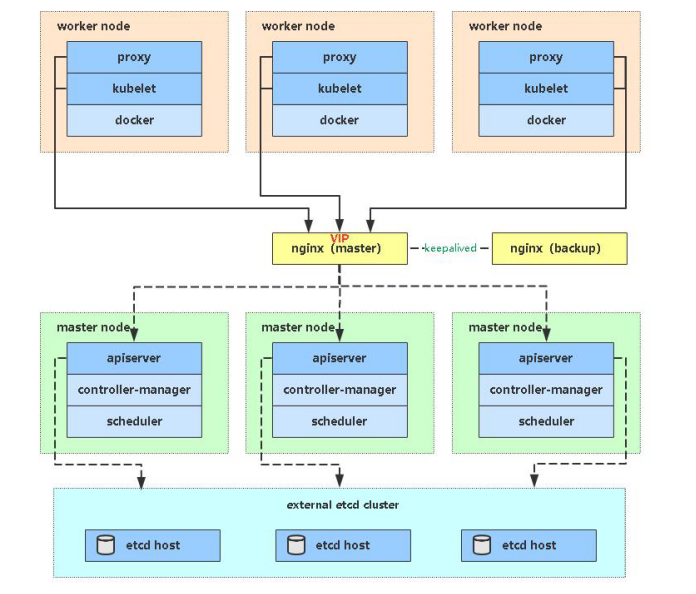
kube-apiserver高可用架构图
• Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
• Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(偏移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
注:为了节省机器,这里与K8s master节点机器复用。也可以独立于k8s集群之外部署,只要nginx与apiserver能通信就行。
2.1 安装软件包(主/备)
yum install epel-release -y
yum install nginx keepalived -y
2.2 Nginx配置文件(主/备一样)
cat > /etc/nginx/nginx.conf << "EOF"
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.31.61:6443; # Master1 APISERVER IP:PORT
server 192.168.31.62:6443; # Master2 APISERVER IP:PORT
}
server {
listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}
EOF
2.3 keepalived 配置文件(Nginx Master)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33 # 修改为实际网卡名
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.31.88/24
}
track_script {
check_nginx
}
}
EOF
• vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
• virtual_ipaddress:虚拟IP(VIP)
准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ss -antp |grep 16443 |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
2.4 keepalived 配置文件(Nginx Backup)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.31.88/24
}
track_script {
check_nginx
}
}
EOF
准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ss -antp |grep 16443 |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
注:keepalived根据脚本返回状态码(0为工作正常,非0不正常)判断是否故障转移。
2.5 启动并设置开机启动
systemctl daemon-reload
systemctl start nginx
systemctl start keepalived
systemctl enable nginx
systemctl enable keepalived
2.6 查看keepalived工作状态
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:04:f7:2c brd ff:ff:ff:ff:ff:ff
inet 192.168.31.80/24 brd 192.168.31.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.31.88/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe04:f72c/64 scope link
valid_lft forever preferred_lft forever
可以看到,在ens33网卡绑定了192.168.31.88 虚拟IP,说明工作正常。
2.7 Nginx+Keepalived高可用测试
关闭主节点Nginx,测试VIP是否漂移到备节点服务器。
在Nginx Master执行 pkill nginx
在Nginx Backup,ip addr命令查看已成功绑定VIP。
三、部署Etcd集群
如果你在学习中遇到问题或者文档有误可联系阿良~ 微信: xyz12366699
Etcd 是一个分布式键值存储系统,Kubernetes使用Etcd进行数据存储,kubeadm搭建默认情况下只启动一个Etcd Pod,存在单点故障,生产环境强烈不建议,所以我们这里使用3台服务器组建集群,可容忍1台机器故障,当然,你也可以使用5台组建集群,可容忍2台机器故障。
| 节点名称 | IP |
|---|---|
| etcd-1 | 192.168.31.61 |
| etcd-2 | 192.168.31.62 |
| etcd-3 | 192.168.31.63 |
注:为了节省机器,这里与K8s节点机器复用。也可以独立于k8s集群之外部署,只要apiserver能连接到就行。
3.1 准备cfssl证书生成工具
cfssl是一个开源的证书管理工具,使用json文件生成证书,相比openssl更方便使用。
找任意一台服务器操作,这里用Master节点
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
3.2 生成Etcd证书
1. 自签证书颁发机构(CA)
创建工作目录:
mkdir -p ~/etcd_tls
cd ~/etcd_tls
自签CA:
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json << EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
生成证书:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
2. 使用自签CA签发Etcd HTTPS证书
创建证书申请文件:
cat > server-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"192.168.31.61",
"192.168.31.62",
"192.168.31.63"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
EOF
注:上述文件hosts字段中IP为所有etcd节点的集群内部通信IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。
生成证书:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
会生成server.pem和server-key.pem文件。
3.3 从Github下载二进制文件
下载地址:https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
3.4 部署Etcd集群
以下在节点1上操作,为简化操作,待会将节点1生成的所有文件拷贝到节点2和节点3。
1. 创建工作目录并解压二进制包
mkdir /opt/etcd/{bin,cfg,ssl} -p
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
mv etcd-v3.4.9-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
2. 创建etcd配置文件
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.31.61:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.61:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.61:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.61:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.31.61:2380,etcd-2=https://192.168.31.62:2380,etcd-3=https://192.168.31.63:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
• ETCD_NAME:节点名称,集群中唯一
• ETCDDATADIR:数据目录
• ETCDLISTENPEER_URLS:集群通信监听地址
• ETCDLISTENCLIENT_URLS:客户端访问监听地址
• ETCDINITIALADVERTISEPEERURLS:集群通告地址
• ETCDADVERTISECLIENT_URLS:客户端通告地址
• ETCDINITIALCLUSTER:集群节点地址
• ETCDINITIALCLUSTER_TOKEN:集群Token
• ETCDINITIALCLUSTER_STATE:加入集群的当前状态,new是新集群,existing表示加入已有集群
3. systemd管理etcd
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
--logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
4. 拷贝刚才生成的证书
把刚才生成的证书拷贝到配置文件中的路径:
cp ~/etcd_tls/ca*pem ~/etcd_tls/server*pem /opt/etcd/ssl/
5. 启动并设置开机启动
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
6. 将上面节点1所有生成的文件拷贝到节点2和节点3
scp -r /opt/etcd/ root@192.168.31.62:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.31.62:/usr/lib/systemd/system/
scp -r /opt/etcd/ root@192.168.31.63:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.31.63:/usr/lib/systemd/system/
然后在节点2和节点3分别修改etcd.conf配置文件中的节点名称和当前服务器IP:
vi /opt/etcd/cfg/etcd.conf
#[Member]
ETCD_NAME="etcd-1" # 修改此处,节点2改为etcd-2,节点3改为etcd-3
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.31.71:2380" # 修改此处为当前服务器IP
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.71:2379" # 修改此处为当前服务器IP
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.71:2380" # 修改此处为当前服务器IP
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.71:2379" # 修改此处为当前服务器IP
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.31.71:2380,etcd-2=https://192.168.31.72:2380,etcd-3=https://192.168.31.73:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
7. 查看集群状态
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.31.61:2379,https://192.168.31.62:2379,https://192.168.31.63:2379" endpoint health --write-out=table
+----------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+----------------------------+--------+-------------+-------+
| https://192.168.31.61:2379 | true | 10.301506ms | |
| https://192.168.31.63:2379 | true | 12.87467ms | |
| https://192.168.31.62:2379 | true | 13.225954ms | |
+----------------------------+--------+-------------+-------+
如果输出上面信息,就说明集群部署成功。
如果有问题第一步先看日志:/var/log/message 或 journalctl -u etcd
四、安装Docker/kubeadm/kubelet【所有节点】
这里使用Docker作为容器引擎,也可以换成别的,例如containerd
4.1 安装Docker
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum -y install docker-ce
systemctl enable docker && systemctl start docker
配置镜像下载加速器:
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
systemctl restart docker
docker info
4.2 添加阿里云YUM软件源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
4.3 安装kubeadm,kubelet和kubectl
由于版本更新频繁,这里指定版本号部署:
yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0
systemctl enable kubelet
五、部署Kubernetes Master
5.1 初始化Master1
生成初始化配置文件:
cat > kubeadm-config.yaml << EOF
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 9037x2.tcaqnpaqkra9vsbw
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.31.61
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: k8s-master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs: # 包含所有Master/LB/VIP IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。
- k8s-master1
- k8s-master2
- 192.168.31.61
- 192.168.31.62
- 192.168.31.63
- 127.0.0.1
extraArgs:
authorization-mode: Node,RBAC
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 192.168.31.88:16443 # 负载均衡虚拟IP(VIP)和端口
controllerManager: {}
dns:
type: CoreDNS
etcd:
external: # 使用外部etcd
endpoints:
- https://192.168.31.61:2379 # etcd集群3个节点
- https://192.168.31.62:2379
- https://192.168.31.63:2379
caFile: /opt/etcd/ssl/ca.pem # 连接etcd所需证书
certFile: /opt/etcd/ssl/server.pem
keyFile: /opt/etcd/ssl/server-key.pem
imageRepository: registry.aliyuncs.com/google_containers # 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址
kind: ClusterConfiguration
kubernetesVersion: v1.20.0 # K8s版本,与上面安装的一致
networking:
dnsDomain: cluster.local
podSubnet: 10.244.0.0/16 # Pod网络,与下面部署的CNI网络组件yaml中保持一致
serviceSubnet: 10.96.0.0/12 # 集群内部虚拟网络,Pod统一访问入口
scheduler: {}
EOF
或者使用配置文件引导:
kubeadm init --config kubeadm-config.yaml
...
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.31.88:16443 --token 9037x2.tcaqnpaqkra9vsbw \
--discovery-token-ca-cert-hash sha256:b1e726042cdd5df3ce62e60a2f86168cd2e64bff856e061e465df10cd36295b8 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.31.88:16443 --token 9037x2.tcaqnpaqkra9vsbw \
--discovery-token-ca-cert-hash sha256:b1e726042cdd5df3ce62e60a2f86168cd2e64bff856e061e465df10cd36295b8
初始化完成后,会有两个join的命令,带有 —control-plane 是用于加入组建多master集群的,不带的是加入节点的。
拷贝kubectl使用的连接k8s认证文件到默认路径:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane,master 6m42s v1.20.0
5.2 初始化Master2
将Master1节点生成的证书拷贝到Master2:
scp -r /etc/kubernetes/pki/ 192.168.31.62:/etc/kubernetes/
复制加入master join命令在master2执行:
kubeadm join 192.168.31.88:16443 --token 9037x2.tcaqnpaqkra9vsbw \
--discovery-token-ca-cert-hash sha256:b1e726042cdd5df3ce62e60a2f86168cd2e64bff856e061e465df10cd36295b8 \
--control-plane
拷贝kubectl使用的连接k8s认证文件到默认路径:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady control-plane,master 28m v1.20.0
k8s-master2 NotReady control-plane,master 2m12s v1.20.0
注:由于网络插件还没有部署,还没有准备就绪 NotReady
5.3 访问负载均衡器测试
找K8s集群中任意一个节点,使用curl查看K8s版本测试,使用VIP访问:
curl -k https://192.168.31.88:16443/version
{
"major": "1",
"minor": "20",
"gitVersion": "v1.20.0",
"gitCommit": "e87da0bd6e03ec3fea7933c4b5263d151aafd07c",
"gitTreeState": "clean",
"buildDate": "2021-02-18T16:03:00Z",
"goVersion": "go1.15.8",
"compiler": "gc",
"platform": "linux/amd64"
}
可以正确获取到K8s版本信息,说明负载均衡器搭建正常。该请求数据流程:curl -> vip(nginx) -> apiserver
通过查看Nginx日志也可以看到转发apiserver IP:
tail /var/log/nginx/k8s-access.log -f
192.168.31.71 192.168.31.71:6443 - [02/Apr/2021:19:17:57 +0800] 200 423
192.168.31.71 192.168.31.72:6443 - [02/Apr/2021:19:18:50 +0800] 200 423
六、加入Kubernetes Node
在192.168.31.63(Node)执行。
向集群添加新节点,执行在kubeadm init输出的kubeadm join命令:
kubeadm join 192.168.31.88:16443 --token 9037x2.tcaqnpaqkra9vsbw \
--discovery-token-ca-cert-hash sha256:e6a724bb7ef8bb363762fbaa088f6eb5975e0c654db038560199a7063735a697
后续其他节点也是这样加入。
注:默认token有效期为24小时,当过期之后,该token就不可用了。这时就需要重新创建token,可以直接使用命令快捷生成:kubeadm token create —print-join-command
七、部署网络组件
Calico是一个纯三层的数据中心网络方案,是目前Kubernetes主流的网络方案。
部署Calico:
kubectl apply -f calico.yaml
kubectl get pods -n kube-system
等Calico Pod都Running,节点也会准备就绪:
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready control-plane,master 50m v1.20.0
k8s-master2 Ready control-plane,master 24m v1.20.0
k8s-node1 Ready <none> 20m v1.20.0
八、部署 Dashboard
Dashboard是官方提供的一个UI,可用于基本管理K8s资源。
kubectl apply -f kubernetes-dashboard.yaml
# 查看部署
kubectl get pods -n kubernetes-dashboard
访问地址:https://NodeIP:30001
创建service account并绑定默认cluster-admin管理员集群角色:
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
使用输出的token登录Dashboard。
二进制
一、前置知识点
1.1 生产环境部署K8s集群的两种方式
• kubeadm
Kubeadm是一个K8s部署工具,提供kubeadm init和kubeadm join,用于快速部署Kubernetes集群。
• 二进制包
从github下载发行版的二进制包,手动部署每个组件,组成Kubernetes集群。
小结:Kubeadm降低部署门槛,但屏蔽了很多细节,遇到问题很难排查。如果想更容易可控,推荐使用二进制包部署Kubernetes集群,虽然手动部署麻烦点,期间可以学习很多工作原理,也利于后期维护。
1.2 准备环境
服务器要求:
• 建议最小硬件配置:2核CPU、2G内存、30G硬盘
• 服务器最好可以访问外网,会有从网上拉取镜像需求,如果服务器不能上网,需要提前下载对应镜像并导入节点
软件环境:
| 软件 | 版本 |
|---|---|
| 操作系统 | CentOS7.x_x64 (mini) |
| 容器引擎 | Docker CE 19 |
| Kubernetes | Kubernetes v1.20 |
服务器整体规划:
| 角色 | IP | 组件 |
|---|---|---|
| k8s-master1 | 192.168.31.71 | kube-apiserver,kube-controller-manager,kube-scheduler,kubelet,kube-proxy,docker,etcd, nginx,keepalived |
| k8s-master2 | 192.168.31.74 | kube-apiserver,kube-controller-manager,kube-scheduler,kubelet,kube-proxy,docker, nginx,keepalived |
| k8s-node1 | 192.168.31.72 | kubelet,kube-proxy,docker,etcd |
| k8s-node2 | 192.168.31.73 | kubelet,kube-proxy,docker,etcd |
| 负载均衡器IP | 192.168.31.88 (VIP) |
须知:考虑到有些朋友电脑配置较低,一次性开四台机器会跑不动,所以搭建这套K8s高可用集群分两部分实施,先部署一套单Master架构(3台),再扩容为多Master架构(4台或6台),顺便再熟悉下Master扩容流程。
单Master架构图:
单Master服务器规划:
| 角色 | IP | 组件 |
|---|---|---|
| k8s-master | 192.168.31.71 | kube-apiserver,kube-controller-manager,kube-scheduler,etcd |
| k8s-node1 | 192.168.31.72 | kubelet,kube-proxy,docker,etcd |
| k8s-node2 | 192.168.31.73 | kubelet,kube-proxy,docker,etcd |
1.3 操作系统初始化配置
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 关闭selinux
sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
setenforce 0 # 临时
# 关闭swap
swapoff -a # 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
# 根据规划设置主机名
hostnamectl set-hostname <hostname>
# 在master添加hosts
cat >> /etc/hosts << EOF
192.168.31.71 k8s-master1
192.168.31.72 k8s-node1
192.168.31.73 k8s-node2
EOF
# 将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 生效
# 时间同步
yum install ntpdate -y
ntpdate time.windows.com
二、部署Etcd集群
Etcd 是一个分布式键值存储系统,Kubernetes使用Etcd进行数据存储,所以先准备一个Etcd数据库,为解决Etcd单点故障,应采用集群方式部署,这里使用3台组建集群,可容忍1台机器故障,当然,你也可以使用5台组建集群,可容忍2台机器故障。
| 节点名称 | IP |
|---|---|
| etcd-1 | 192.168.31.71 |
| etcd-2 | 192.168.31.72 |
| etcd-3 | 192.168.31.73 |
注:为了节省机器,这里与K8s节点机器复用。也可以独立于k8s集群之外部署,只要apiserver能连接到就行。
2.1 准备cfssl证书生成工具
cfssl是一个开源的证书管理工具,使用json文件生成证书,相比openssl更方便使用。
找任意一台服务器操作,这里用Master节点。
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
2.2 生成Etcd证书
1. 自签证书颁发机构(CA)
创建工作目录:
mkdir -p ~/TLS/{etcd,k8s}
cd ~/TLS/etcd
自签CA:
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"www": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json << EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing"
}
]
}
EOF
生成证书:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
2. 使用自签CA签发Etcd HTTPS证书
创建证书申请文件:
cat > server-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"192.168.31.71",
"192.168.31.72",
"192.168.31.73"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing"
}
]
}
EOF
注:上述文件hosts字段中IP为所有etcd节点的集群内部通信IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。
生成证书:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
会生成server.pem和server-key.pem文件。
2.3 从Github下载二进制文件
下载地址:https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
2.4 部署Etcd集群
以下在节点1上操作,为简化操作,待会将节点1生成的所有文件拷贝到节点2和节点3.
1. 创建工作目录并解压二进制包
mkdir /opt/etcd/{bin,cfg,ssl} -p
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
mv etcd-v3.4.9-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
2. 创建etcd配置文件
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.31.71:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.71:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.71:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.71:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.31.71:2380,etcd-2=https://192.168.31.72:2380,etcd-3=https://192.168.31.73:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
• ETCD_NAME:节点名称,集群中唯一
• ETCD_DATA_DIR:数据目录
• ETCD_LISTEN_PEER_URLS:集群通信监听地址
• ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址
• ETCD_INITIAL_ADVERTISE_PEERURLS:集群通告地址
• ETCD_ADVERTISE_CLIENT_URLS:客户端通告地址
• ETCD_INITIAL_CLUSTER:集群节点地址
• ETCD_INITIALCLUSTER_TOKEN:集群Token
• ETCD_INITIALCLUSTER_STATE:加入集群的当前状态,new是新集群,existing表示加入已有集群
3. systemd管理etcd
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
--logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
4. 拷贝刚才生成的证书
把刚才生成的证书拷贝到配置文件中的路径:
cp ~/TLS/etcd/ca*pem ~/TLS/etcd/server*pem /opt/etcd/ssl/
5. 启动并设置开机启动
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
6. 将上面节点1所有生成的文件拷贝到节点2和节点3
scp -r /opt/etcd/ root@192.168.31.72:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.31.72:/usr/lib/systemd/system/
scp -r /opt/etcd/ root@192.168.31.73:/opt/
scp /usr/lib/systemd/system/etcd.service root@192.168.31.73:/usr/lib/systemd/system/
然后在节点2和节点3分别修改etcd.conf配置文件中的节点名称和当前服务器IP:
vi /opt/etcd/cfg/etcd.conf
#[Member]
ETCD_NAME="etcd-1" # 修改此处,节点2改为etcd-2,节点3改为etcd-3
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.31.71:2380" # 修改此处为当前服务器IP
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.71:2379" # 修改此处为当前服务器IP
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.71:2380" # 修改此处为当前服务器IP
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.71:2379" # 修改此处为当前服务器IP
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.31.71:2380,etcd-2=https://192.168.31.72:2380,etcd-3=https://192.168.31.73:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
7. 查看集群状态
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.31.71:2379,https://192.168.31.72:2379,https://192.168.31.73:2379" endpoint health --write-out=table
+----------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+----------------------------+--------+-------------+-------+
| https://192.168.31.71:2379 | true | 10.301506ms | |
| https://192.168.31.73:2379 | true | 12.87467ms | |
| https://192.168.31.72:2379 | true | 13.225954ms | |
+----------------------------+--------+-------------+-------+
如果输出上面信息,就说明集群部署成功。
如果有问题第一步先看日志:/var/log/message 或 journalctl -u etcd
三、安装Docker
这里使用Docker作为容器引擎,也可以换成别的,例如containerd
下载地址:https://download.docker.com/linux/static/stable/x86_64/docker-19.03.9.tgz
以下在所有节点操作。这里采用二进制安装,用yum安装也一样。
3.1 解压二进制包
tar zxvf docker-19.03.9.tgz
mv docker/* /usr/bin
3.2 systemd管理docker
cat > /usr/lib/systemd/system/docker.service << EOF
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF
3.3 创建配置文件
mkdir /etc/docker
cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
3.4 启动并设置开机启动
systemctl daemon-reload
systemctl start docker
systemctl enable docker
四、部署Master Node
4.1 生成kube-apiserver证书
1. 自签证书颁发机构(CA)
cd ~/TLS/k8s
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json << EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
生成证书:
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
2. 使用自签CA签发kube-apiserver HTTPS证书
创建证书申请文件:
cat > server-csr.json << EOF
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"192.168.31.71",
"192.168.31.72",
"192.168.31.73",
"192.168.31.74",
"192.168.31.88",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
注:上述文件hosts字段中IP为所有Master/LB/VIP IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。
生成证书:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
会生成server.pem和server-key.pem文件。
4.2 从Github下载二进制文件
下载地址: https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.20.md
注:打开链接你会发现里面有很多包,下载一个server包就够了,包含了Master和Worker Node二进制文件。
4.3 解压二进制包
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
tar zxvf kubernetes-server-linux-amd64.tar.gz
cd kubernetes/server/bin
cp kube-apiserver kube-scheduler kube-controller-manager /opt/kubernetes/bin
cp kubectl /usr/bin/
4.4 部署kube-apiserver
1. 创建配置文件
cat > /opt/kubernetes/cfg/kube-apiserver.conf << EOF
KUBE_APISERVER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--etcd-servers=https://192.168.31.71:2379,https://192.168.31.72:2379,https://192.168.31.73:2379 \\
--bind-address=192.168.31.71 \\
--secure-port=6443 \\
--advertise-address=192.168.31.71 \\
--allow-privileged=true \\
--service-cluster-ip-range=10.0.0.0/24 \\
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\
--authorization-mode=RBAC,Node \\
--enable-bootstrap-token-auth=true \\
--token-auth-file=/opt/kubernetes/cfg/token.csv \\
--service-node-port-range=30000-32767 \\
--kubelet-client-certificate=/opt/kubernetes/ssl/server.pem \\
--kubelet-client-key=/opt/kubernetes/ssl/server-key.pem \\
--tls-cert-file=/opt/kubernetes/ssl/server.pem \\
--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \\
--client-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--service-account-issuer=api \\
--service-account-signing-key-file=/opt/kubernetes/ssl/server-key.pem \\
--etcd-cafile=/opt/etcd/ssl/ca.pem \\
--etcd-certfile=/opt/etcd/ssl/server.pem \\
--etcd-keyfile=/opt/etcd/ssl/server-key.pem \\
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \\
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \\
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \\
--requestheader-allowed-names=kubernetes \\
--requestheader-extra-headers-prefix=X-Remote-Extra- \\
--requestheader-group-headers=X-Remote-Group \\
--requestheader-username-headers=X-Remote-User \\
--enable-aggregator-routing=true \\
--audit-log-maxage=30 \\
--audit-log-maxbackup=3 \\
--audit-log-maxsize=100 \\
--audit-log-path=/opt/kubernetes/logs/k8s-audit.log"
EOF
注:上面两个\ \ 第一个是转义符,第二个是换行符,使用转义符是为了使用EOF保留换行符。
• —logtostderr:启用日志
• —-v:日志等级
• —log-dir:日志目录
• —etcd-servers:etcd集群地址
• —bind-address:监听地址
• —secure-port:https安全端口
• —advertise-address:集群通告地址
• —allow-privileged:启用授权
• —service-cluster-ip-range:Service虚拟IP地址段
• —enable-admission-plugins:准入控制模块
• —authorization-mode:认证授权,启用RBAC授权和节点自管理
• —enable-bootstrap-token-auth:启用TLS bootstrap机制
• —token-auth-file:bootstrap token文件
• —service-node-port-range:Service nodeport类型默认分配端口范围
• —kubelet-client-xxx:apiserver访问kubelet客户端证书
• —tls-xxx-file:apiserver https证书
• 1.20版本必须加的参数:—service-account-issuer,—service-account-signing-key-file
• —etcd-xxxfile:连接Etcd集群证书
• —audit-log-xxx:审计日志
• 启动聚合层相关配置:—requestheader-client-ca-file,—proxy-client-cert-file,—proxy-client-key-file,—requestheader-allowed-names,—requestheader-extra-headers-prefix,—requestheader-group-headers,—requestheader-username-headers,—enable-aggregator-routing
2. 拷贝刚才生成的证书
把刚才生成的证书拷贝到配置文件中的路径:
cp ~/TLS/k8s/ca*pem ~/TLS/k8s/server*pem /opt/kubernetes/ssl/
3. 启用 TLS Bootstrapping 机制
TLS Bootstraping:Master apiserver启用TLS认证后,Node节点kubelet和kube-proxy要与kube-apiserver进行通信,必须使用CA签发的有效证书才可以,当Node节点很多时,这种客户端证书颁发需要大量工作,同样也会增加集群扩展复杂度。为了简化流程,Kubernetes引入了TLS bootstraping机制来自动颁发客户端证书,kubelet会以一个低权限用户自动向apiserver申请证书,kubelet的证书由apiserver动态签署。所以强烈建议在Node上使用这种方式,目前主要用于kubelet,kube-proxy还是由我们统一颁发一个证书。
TLS bootstraping 工作流程:
创建上述配置文件中token文件:
cat > /opt/kubernetes/cfg/token.csv << EOF
c47ffb939f5ca36231d9e3121a252940,kubelet-bootstrap,10001,"system:node-bootstrapper"
EOF
格式:token,用户名,UID,用户组
token也可自行生成替换:
head -c 16 /dev/urandom | od -An -t x | tr -d ' '
4. systemd管理apiserver
cat > /usr/lib/systemd/system/kube-apiserver.service << EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-apiserver.conf
ExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
5. 启动并设置开机启动
systemctl daemon-reload
systemctl start kube-apiserver
systemctl enable kube-apiserver
4.5 部署kube-controller-manager
1. 创建配置文件
cat > /opt/kubernetes/cfg/kube-controller-manager.conf << EOF
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--leader-elect=true \\
--kubeconfig=/opt/kubernetes/cfg/kube-controller-manager.kubeconfig \\
--bind-address=127.0.0.1 \\
--allocate-node-cidrs=true \\
--cluster-cidr=10.244.0.0/16 \\
--service-cluster-ip-range=10.0.0.0/24 \\
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--root-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--cluster-signing-duration=87600h0m0s"
EOF
• —kubeconfig:连接apiserver配置文件
• —leader-elect:当该组件启动多个时,自动选举(HA)
• —cluster-signing-cert-file/—cluster-signing-key-file:自动为kubelet颁发证书的CA,与apiserver保持一致
2. 生成kubeconfig文件
生成kube-controller-manager证书:
# 切换工作目录
cd ~/TLS/k8s
# 创建证书请求文件
cat > kube-controller-manager-csr.json << EOF
{
"CN": "system:kube-controller-manager",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager
生成kubeconfig文件(以下是shell命令,直接在终端执行):
KUBE_CONFIG="/opt/kubernetes/cfg/kube-controller-manager.kubeconfig"
KUBE_APISERVER="https://192.168.31.71:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-controller-manager \
--client-certificate=./kube-controller-manager.pem \
--client-key=./kube-controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-controller-manager \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
3. systemd管理controller-manager
cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-controller-manager.conf
ExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
4. 启动并设置开机启动
systemctl daemon-reload
systemctl start kube-controller-manager
systemctl enable kube-controller-manager
4.6 部署kube-scheduler
1. 创建配置文件
cat > /opt/kubernetes/cfg/kube-scheduler.conf << EOF
KUBE_SCHEDULER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--leader-elect \\
--kubeconfig=/opt/kubernetes/cfg/kube-scheduler.kubeconfig \\
--bind-address=127.0.0.1"
EOF
• —kubeconfig:连接apiserver配置文件
• —leader-elect:当该组件启动多个时,自动选举(HA)
2. 生成kubeconfig文件
生成kube-scheduler证书:
# 切换工作目录
cd ~/TLS/k8s
# 创建证书请求文件
cat > kube-scheduler-csr.json << EOF
{
"CN": "system:kube-scheduler",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler
生成kubeconfig文件(以下是shell命令,直接在终端执行):
KUBE_CONFIG="/opt/kubernetes/cfg/kube-scheduler.kubeconfig"
KUBE_APISERVER="https://192.168.31.71:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-scheduler \
--client-certificate=./kube-scheduler.pem \
--client-key=./kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-scheduler \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
3. systemd管理scheduler
cat > /usr/lib/systemd/system/kube-scheduler.service << EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler.conf
ExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
4. 启动并设置开机启动
systemctl daemon-reload
systemctl start kube-scheduler
systemctl enable kube-scheduler
5. 查看集群状态
生成kubectl连接集群的证书:
cat > admin-csr.json <<EOF
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin
生成kubeconfig文件:
mkdir /root/.kube
KUBE_CONFIG="/root/.kube/config"
KUBE_APISERVER="https://192.168.31.71:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials cluster-admin \
--client-certificate=./admin.pem \
--client-key=./admin-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=cluster-admin \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
通过kubectl工具查看当前集群组件状态:
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
6. 授权kubelet-bootstrap用户允许请求证书
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
五、部署Worker Node
下面还是在Master Node上操作,即同时作为Worker Node
5.1 创建工作目录并拷贝二进制文件
在所有worker node创建工作目录:
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
从master节点拷贝:
cd kubernetes/server/bin
cp kubelet kube-proxy /opt/kubernetes/bin # 本地拷贝
5.2 部署kubelet
1. 创建配置文件
cat > /opt/kubernetes/cfg/kubelet.conf << EOF
KUBELET_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--hostname-override=k8s-master1 \\
--network-plugin=cni \\
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\
--config=/opt/kubernetes/cfg/kubelet-config.yml \\
--cert-dir=/opt/kubernetes/ssl \\
--pod-infra-container-image=lizhenliang/pause-amd64:3.0"
EOF
• —hostname-override:显示名称,集群中唯一
• —network-plugin:启用CNI
• —kubeconfig:空路径,会自动生成,后面用于连接apiserver
• —bootstrap-kubeconfig:首次启动向apiserver申请证书
• —config:配置参数文件
• —cert-dir:kubelet证书生成目录
• —pod-infra-container-image:管理Pod网络容器的镜像
2. 配置参数文件
cat > /opt/kubernetes/cfg/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS:
- 10.0.0.2
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /opt/kubernetes/ssl/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF
3. 生成kubelet初次加入集群引导kubeconfig文件
KUBE_CONFIG="/opt/kubernetes/cfg/bootstrap.kubeconfig"
KUBE_APISERVER="https://192.168.31.71:6443" # apiserver IP:PORT
TOKEN="c47ffb939f5ca36231d9e3121a252940" # 与token.csv里保持一致
# 生成 kubelet bootstrap kubeconfig 配置文件
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials "kubelet-bootstrap" \
--token=${TOKEN} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user="kubelet-bootstrap" \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
4. systemd管理kubelet
cat > /usr/lib/systemd/system/kubelet.service << EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf
ExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
5. 启动并设置开机启动
systemctl daemon-reload
systemctl start kubelet
systemctl enable kubelet
5.3 批准kubelet证书申请并加入集群
# 查看kubelet证书请求
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-uCEGPOIiDdlLODKts8J658HrFq9CZ--K6M4G7bjhk8A 6m3s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
# 批准申请
kubectl certificate approve node-csr-uCEGPOIiDdlLODKts8J658HrFq9CZ--K6M4G7bjhk8A
# 查看节点
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady <none> 7s v1.18.3
注:由于网络插件还没有部署,节点会没有准备就绪 NotReady
5.4 部署kube-proxy
1. 创建配置文件
cat > /opt/kubernetes/cfg/kube-proxy.conf << EOF
KUBE_PROXY_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--config=/opt/kubernetes/cfg/kube-proxy-config.yml"
EOF
2. 配置参数文件
cat > /opt/kubernetes/cfg/kube-proxy-config.yml << EOF
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
metricsBindAddress: 0.0.0.0:10249
clientConnection:
kubeconfig: /opt/kubernetes/cfg/kube-proxy.kubeconfig
hostnameOverride: k8s-master1
clusterCIDR: 10.0.0.0/24
EOF
3. 生成kube-proxy.kubeconfig文件
# 切换工作目录
cd ~/TLS/k8s
# 创建证书请求文件
cat > kube-proxy-csr.json << EOF
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
生成kubeconfig文件:
KUBE_CONFIG="/opt/kubernetes/cfg/kube-proxy.kubeconfig"
KUBE_APISERVER="https://192.168.31.71:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-proxy \
--client-certificate=./kube-proxy.pem \
--client-key=./kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
4. systemd管理kube-proxy
cat > /usr/lib/systemd/system/kube-proxy.service << EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf
ExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
5. 启动并设置开机启动
systemctl daemon-reload
systemctl start kube-proxy
systemctl enable kube-proxy
5.5 部署网络组件
Calico是一个纯三层的数据中心网络方案,是目前Kubernetes主流的网络方案。
部署Calico:
kubectl apply -f calico.yaml
kubectl get pods -n kube-system
等Calico Pod都Running,节点也会准备就绪:
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready <none> 37m v1.20.4
5.6 授权apiserver访问kubelet
应用场景:例如kubectl logs
cat > apiserver-to-kubelet-rbac.yaml << EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
- pods/log
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
EOF
kubectl apply -f apiserver-to-kubelet-rbac.yaml
5.7 新增加Worker Node
1. 拷贝已部署好的Node相关文件到新节点
在Master节点将Worker Node涉及文件拷贝到新节点192.168.31.72/73
scp -r /opt/kubernetes root@192.168.31.72:/opt/
scp -r /usr/lib/systemd/system/{kubelet,kube-proxy}.service root@192.168.31.72:/usr/lib/systemd/system
scp /opt/kubernetes/ssl/ca.pem root@192.168.31.72:/opt/kubernetes/ssl
2. 删除kubelet证书和kubeconfig文件
rm -f /opt/kubernetes/cfg/kubelet.kubeconfig
rm -f /opt/kubernetes/ssl/kubelet*
注:这几个文件是证书申请审批后自动生成的,每个Node不同,必须删除
3. 修改主机名
vi /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8s-node1
vi /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8s-node1
4. 启动并设置开机启动
systemctl daemon-reload
systemctl start kubelet kube-proxy
systemctl enable kubelet kube-proxy
5. 在Master上批准新Node kubelet证书申请
# 查看证书请求
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-4zTjsaVSrhuyhIGqsefxzVoZDCNKei-aE2jyTP81Uro 89s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
# 授权请求
kubectl certificate approve node-csr-4zTjsaVSrhuyhIGqsefxzVoZDCNKei-aE2jyTP81Uro
6. 查看Node状态
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 47m v1.20.4
k8s-node1 Ready <none> 6m49s v1.20.4
Node2(192.168.31.73 )节点同上。记得修改主机名!
六、部署Dashboard和CoreDNS
6.1 部署Dashboard
kubectl apply -f kubernetes-dashboard.yaml
# 查看部署
kubectl get pods,svc -n kubernetes-dashboard
访问地址:https://NodeIP:30001
创建service account并绑定默认cluster-admin管理员集群角色:
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
使用输出的token登录Dashboard。
6.2 部署CoreDNS
CoreDNS用于集群内部Service名称解析。
kubectl apply -f coredns.yaml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5ffbfd976d-j6shb 1/1 Running 0 32s
DNS解析测试:
kubectl run -it --rm dns-test --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
解析没问题。
至此一个单Master集群就搭建完成了!这个环境就足以满足学习实验了,如果你的服务器配置较高,可继续扩容多Master集群!
七、扩容多Master(高可用架构)
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。
针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:Etcd数据库的高可用性和Kubernetes Master组件的高可用性。 而Etcd我们已经采用3个节点组建集群实现高可用,本节将对Master节点高可用进行说明和实施。
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
多Master架构图:
7.1 部署Master2 Node
现在需要再增加一台新服务器,作为Master2 Node,IP是192.168.31.74。
为了节省资源你也可以将之前部署好的Worker Node1复用为Master2 Node角色(即部署Master组件)
Master2 与已部署的Master1所有操作一致。所以我们只需将Master1所有K8s文件拷贝过来,再修改下服务器IP和主机名启动即可。
1. 安装Docker
scp /usr/bin/docker* root@192.168.31.74:/usr/bin
scp /usr/bin/runc root@192.168.31.74:/usr/bin
scp /usr/bin/containerd* root@192.168.31.74:/usr/bin
scp /usr/lib/systemd/system/docker.service root@192.168.31.74:/usr/lib/systemd/system
scp -r /etc/docker root@192.168.31.74:/etc
# 在Master2启动Docker
systemctl daemon-reload
systemctl start docker
systemctl enable docker
2. 创建etcd证书目录
在Master2创建etcd证书目录:
mkdir -p /opt/etcd/ssl
3. 拷贝文件(Master1操作)
拷贝Master1上所有K8s文件和etcd证书到Master2:
scp -r /opt/kubernetes root@192.168.31.74:/opt
scp -r /opt/etcd/ssl root@192.168.31.74:/opt/etcd
scp /usr/lib/systemd/system/kube* root@192.168.31.74:/usr/lib/systemd/system
scp /usr/bin/kubectl root@192.168.31.74:/usr/bin
scp -r ~/.kube root@192.168.31.74:~
4. 删除证书文件
删除kubelet证书和kubeconfig文件:
rm -f /opt/kubernetes/cfg/kubelet.kubeconfig
rm -f /opt/kubernetes/ssl/kubelet*
5. 修改配置文件IP和主机名
修改apiserver、kubelet和kube-proxy配置文件为本地IP:
vi /opt/kubernetes/cfg/kube-apiserver.conf
...
--bind-address=192.168.31.74 \
--advertise-address=192.168.31.74 \
...
vi /opt/kubernetes/cfg/kube-controller-manager.kubeconfig
server: https://192.168.31.74:6443
vi /opt/kubernetes/cfg/kube-scheduler.kubeconfig
server: https://192.168.31.74:6443
vi /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8s-master2
vi /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8s-master2
vi ~/.kube/config
...
server: https://192.168.31.74:6443
6. 启动设置开机启动
systemctl daemon-reload
systemctl start kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy
systemctl enable kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy
7. 查看集群状态
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
8. 批准kubelet证书申请
# 查看证书请求
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-JYNknakEa_YpHz797oKaN-ZTk43nD51Zc9CJkBLcASU 85m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
# 授权请求
kubectl certificate approve node-csr-JYNknakEa_YpHz797oKaN-ZTk43nD51Zc9CJkBLcASU
# 查看Node
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 34h v1.20.4
k8s-master2 Ready <none> 2m v1.20.4
k8s-node1 Ready <none> 33h v1.20.4
k8s-node2 Ready <none> 33h v1.20.4
7.2 部署Nginx+Keepalived高可用负载均衡器
kube-apiserver高可用架构图:
• Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
• Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(漂移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
注1:为了节省机器,这里与K8s Master节点机器复用。也可以独立于k8s集群之外部署,只要nginx与apiserver能通信就行。
注2:如果你是在公有云上,一般都不支持keepalived,那么你可以直接用它们的负载均衡器产品,直接负载均衡多台Master kube-apiserver,架构与上面一样。
在两台Master节点操作。
1. 安装软件包(主/备)
yum install epel-release -y
yum install nginx keepalived -y
2. Nginx配置文件(主/备一样)
cat > /etc/nginx/nginx.conf << "EOF"
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.31.71:6443; # Master1 APISERVER IP:PORT
server 192.168.31.74:6443; # Master2 APISERVER IP:PORT
}
server {
listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}
EOF
3. keepalived配置文件(Nginx Master)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33 # 修改为实际网卡名
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.31.88/24
}
track_script {
check_nginx
}
}
EOF
• vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
• virtual_ipaddress:虚拟IP(VIP)
准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ss -antp |grep 16443 |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
4. keepalived配置文件(Nginx Backup)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.31.88/24
}
track_script {
check_nginx
}
}
EOF
准备上述配置文件中检查nginx运行状态的脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ss -antp |grep 16443 |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
注:keepalived根据脚本返回状态码(0为工作正常,非0不正常)判断是否故障转移。
5. 启动并设置开机启动
systemctl daemon-reload
systemctl start nginx keepalived
systemctl enable nginx keepalived
6. 查看keepalived工作状态
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:04:f7:2c brd ff:ff:ff:ff:ff:ff
inet 192.168.31.80/24 brd 192.168.31.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.31.88/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe04:f72c/64 scope link
valid_lft forever preferred_lft forever
可以看到,在ens33网卡绑定了192.168.31.88 虚拟IP,说明工作正常。
7. Nginx+Keepalived高可用测试
关闭主节点Nginx,测试VIP是否漂移到备节点服务器。
在Nginx Master执行 pkill nginx;
在Nginx Backup,ip addr命令查看已成功绑定VIP。
8. 访问负载均衡器测试
找K8s集群中任意一个节点,使用curl查看K8s版本测试,使用VIP访问:
curl -k https://192.168.31.88:16443/version
{
"major": "1",
"minor": "20",
"gitVersion": "v1.20.4",
"gitCommit": "e87da0bd6e03ec3fea7933c4b5263d151aafd07c",
"gitTreeState": "clean",
"buildDate": "2021-02-18T16:03:00Z",
"goVersion": "go1.15.8",
"compiler": "gc",
"platform": "linux/amd64"
}
可以正确获取到K8s版本信息,说明负载均衡器搭建正常。该请求数据流程:curl -> vip(nginx) -> apiserver
通过查看Nginx日志也可以看到转发apiserver IP:
tail /var/log/nginx/k8s-access.log -f
192.168.31.71 192.168.31.71:6443 - [02/Apr/2021:19:17:57 +0800] 200 423
192.168.31.71 192.168.31.72:6443 - [02/Apr/2021:19:18:50 +0800] 200 423
7.3 修改所有Worker Node连接LB VIP
试想下,虽然我们增加了Master2 Node和负载均衡器,但是我们是从单Master架构扩容的,也就是说目前所有的Worker Node组件连接都还是Master1 Node,如果不改为连接VIP走负载均衡器,那么Master还是单点故障。
因此接下来就是要改所有Worker Node(kubectl get node命令查看到的节点)组件配置文件,由原来192.168.31.71修改为192.168.31.88(VIP)。
在所有Worker Node执行:
sed -i 's#192.168.31.71:6443#192.168.31.88:16443#' /opt/kubernetes/cfg/*
systemctl restart kubelet kube-proxy
检查节点状态:
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 32d v1.20.4
k8s-master2 Ready <none> 10m v1.20.4
k8s-node1 Ready <none> 31d v1.20.4
k8s-node2 Ready <none> 31d v1.20.4

若有收获,就点个赞吧
0 人点赞
