2.5.1 表结构优化原则
- 适度冗余,让Query尽量减少Join
在对Query优化是,最直接最有效的优化方式就是减少Join。根据需求,在一些查询频繁更新不频繁的数据表中,可允许适当的冗余,减少Join的表。
- 大字段垂直拆分
如果有些表中含有大字段,比如存放一些较长的详情信息,产品介绍,文章内容的字段(text/blog),可以拆分出来,还有一些使用频率不是很高的字段,也可以拆分出来,独立放在一个表中。
- 大表的水平拆分
如果一个大表中的一小部分记录使用的频率很高,而其他的大多数字段使用频率不是很高的情况下,可以考虑将使用频率高的字段,单独放在一个表中。比如,论坛中的文章,需要将一些精品帖子置顶,那么可以将置顶的文章单独存储在一个新的表中。
- 统计表-准实时优化
在做一些需要实时统计的需求时,其实不需要一定实时展示准确的数据。一般统计的计算都会涉及到大量的数据,需要大量的计算资源,访问的频率非常高,需要很大的开销。所以可以通过定时任务,隔一段时间统计一次,将统计好的数据存放在专门的统计表中。
2.5.2 表数据形式选择
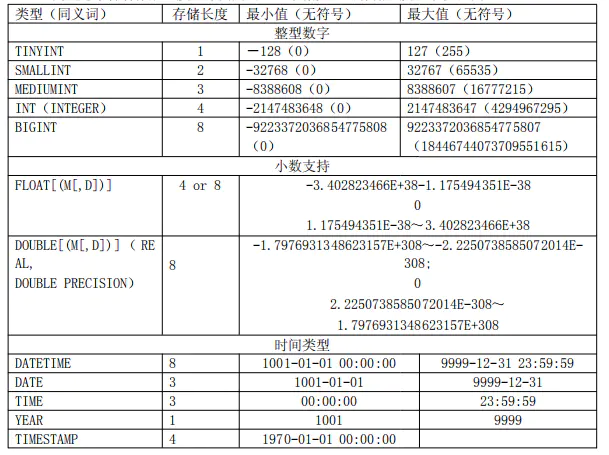
2.5.2.1 数值类型的选择
- int(M) M表示总位数
- 默认存在符号位,unsigned 属性修改
- 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改;**M与int类型的长度无任何关系**
例:int(5) 插入一个数’123’,补填后为’00123’ - 在满足要求的情况下,越小越好。
- 1表示bool值真,0表示bool值假。MySQL没有布尔类型,通过整型0和1表示。常用tinyint(1)表示布尔型。
- 浮点型既支持符号位 unsigned 属性,也支持显示宽度 zerofill 属性。
- 不同于整型,前后均会补填0
- 不同于整型,前后均会补填0
定义浮点型时,需指定总位数和小数位数。
- float(M, D) double(M, D)
- M表示总位数,D表示小数位数。
- M和D的大小会决定浮点数的范围。不同于整型的固定范围。
- M既表示总位数(不包括小数点和正负号),也表示显示宽度(所有显示符号均包括)。
- 支持科学计数法表示。
- 浮点数表示近似值。
2.5.2.2时间字段的选择
根据上面的图可以看出,时间的选择可以使用DateTime和Timestamp两种,DateTime比TImestramp多出一倍的占用空间,但是Timestramp的最早只能存储1970年之后的时间,DataTime可以存储从1001年之后的时间。所以在实际的使用场景中做具体的考虑(一般推荐适用**Timestamp**)2.5.2.3 文本字段的选择
MySQL中的文本字段长度如下:
char和varchar的区别
- char
char表示定长字符串,长度是固定的;
如果插入数据的长度小于char的固定长度时,则用空格填充;
因为长度固定,所以存取速度要比varchar快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
对于char来说,最多能存放的字符个数为255,和编码无关
- varchar
varchar表示可变长字符串,长度是可变的;
插入的数据是多长,就按照多长来存储;
varchar在存取方面与char相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
对于varchar来说,最多能存放的字符个数为65532
- 四种动态存储类型
需要注意的是,TinyText,Text,MediumText,LongText四个类型都是动态存储长度类型。
实际能存储的长度要比规定长度要小。
另外二进制文件多媒体数据**,流水队列数据和超大文本数据不应该存储到数据库中**
- 二进制多媒体文件
空间资源消耗严重
消耗数据库主机的cpu资源
- 流水队列数据
流水队列数据有太多次的增删改,数据库(支持事务的存储引擎)会产生大量的日志文件
- 超大文本数据
由上图可知:VARCHAR最长存放255字节,TEXT最长存放64KB,LONGTEXT最长存放4GB
性能:VARCHAR>TEXT>LONGTEXT

若有收获,就点个赞吧
0 人点赞
