tensorflow 系统架构
TensorFlow 的系统结构以 C API 为界,将整个系统分为前端 和后端两个子系统1。
1. 前端系统:提供编程模型,负责构造计算图;
2. 后端系统:提供运行时环境,负责执行计算图。
TensorFlow 的系统设计遵循良好的分层架构,后端系统的设计和实现可以进一步分解 为 4 层。
1. 运行时:分别提供本地模式和分布式模式,并共享大部分设计和实现;
2. 计算层:由各个 OP 的 Kernel 实现组成;在运行时,Kernel 实现执行 OP 的具 体数学运算;
3. 通信层:基于 gRPC 实现组件间的数据交换,并能够在支持 IB 网络的节点间实 现 RDMA 通信; 4. 设备层:计算设备是 OP 执行的主要载体,TensorFlow 支持多种异构的计算设备 类型。

Client
程序员写的普通代码,就是 client。
当我们写完一段代码,此时,TensorFlow 并未执行任何的图计算,直至与后台计算引擎建立 Session,并以 Session 为桥梁,建立 Client 与 Master 之间的通道,并将 Protobuf 格式的 GraphDef 序列 化后传递给 Master,启动计算图的执行过程。
Master
在分布式的运行时环境中,Client 执行 Session.run 时,传递整个计算图给后端的 Master。此时,计算图是完整的,常称为 Full Graph。随后,Master 根据 Session.run 传 递给它的 fetches, feeds 参数列表,反向遍历 Full Graph,并按照依赖关系,对其实施剪 枝,最终计算得到最小的依赖子图,常称为 Client Graph。 接着,Master 负责将 Client Graph 按照任务的名称分裂 (SplitByTask) 为多个 Graph Partition;其中,每个 Worker 对应一个 Graph Partition。随后,Master 将 Graph Partition 分别注册到相应的 Worker 上,以便在不同的 Worker 上并发执行这些 Graph Partition。最 后,Master 将通知所有 Work 启动相应 Graph Partition 的执行过程。 其中,Work 之间可能存在数据依赖关系,Master 并不参与两者之间的数据交换,它们 两两之间互相通信,独立地完成交换数据,直至完成所有计算。
Worker
对于每一个任务,TensorFlow 都将启动一个 Worker 实例。Worker 主要负责如下 3 个 方面的职责:
1. 处理来自 Master 的请求;
2. 对注册的 Graph Partition 按照本地计算设备集实施二次分裂 (SplitByDevice), 并通知各个计算设备并发执行各个 Graph Partition;
3. 按照拓扑排序算法在某个计算设备上执行本地子图,并调度 OP 的 Kernel 实现;
4. 协同任务之间的数据通信。
Kernel
Kernel 是 OP 在某种硬件设备的特定实现,它负责执行 OP 的具体运算。
其中,大多数 Kernel 基于 Eigen::Tensor 实现。Eigen::Tensor 是一个使用 C++ 模板 技术,为多核 CPU/GPU 生成高效的并发代码。但是,TensorFlow 也可以灵活地直接使用 cuDNN, cuNCCL, cuBLAS 实现更高效的 Kernel。
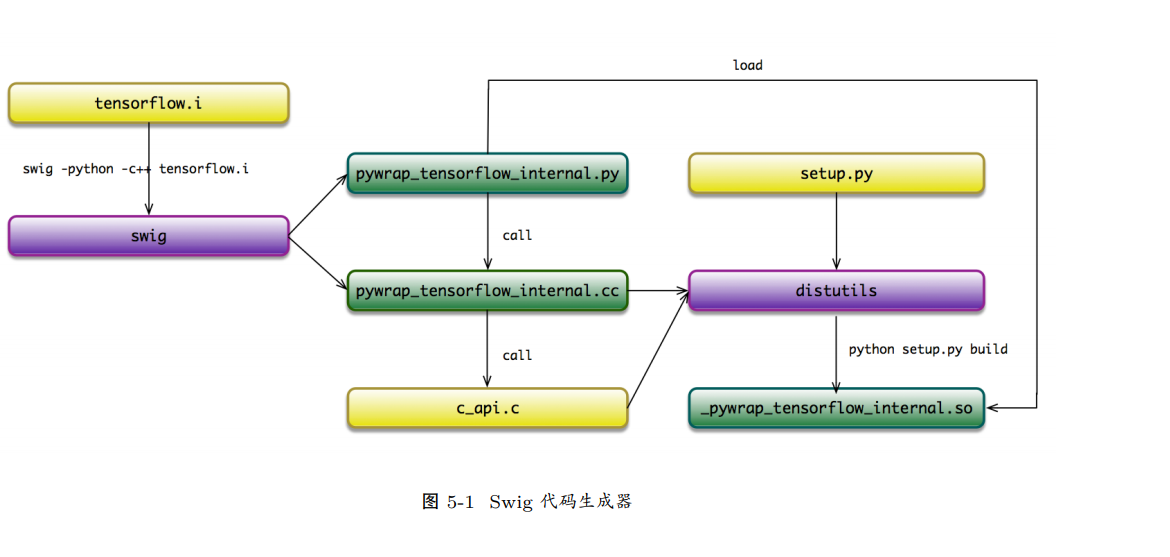
Swig:幕后英雄
前端多语言编程环境与后端 C++ 实现系统的通道归功于 Swig 的包装器。
TensorFlow 使用 Bazel 的构建工具,在系统编译之前启动 Swig 的代码生成过程,通过 tensorflow.i 自动生成了两个适配 (Wrapper) 文件:
1. pywrap_tensorflow_internal.py: 负责对接上层 Python 调用;
2. pywrap_tensorflow_internal.cc: 负责对接下层 C API 调用。
pywrap_tensorflow_internal.py 模块首次被导入时,自动地加载 _pywrap_tensorflow_internal.so 的动态链接库;其中,_pywrap_tensorflow_internal.so 包 含了整个 TensorFlow 运行时的所有符号。在 pywrap_tensorflow_internal.cc 的实现中,静 态注册了一个函数符号表,实现了 Python 函数名到 C 函数名的二元关系。在运行时,按 照 Python 的函数名称,匹配找到对应的 C 函数实现,最终实现 Python 到 c_api.c 具体 实现的调用关系。
共享图实例
一个 Session 只能运行一个图实例。如果一个 Session 要运行 其他的图实例,必须先关掉 Session,然后再将新的图实例注册到此 Session 中,最后启动 新的计算图的执行过程。 但反过来,一个计算图可以运行在多个 Session 实例上。如果在 Graph 实例上维持 Session 的引用计数器,在 Session 创建时,在该图实例上增加 1;在 Session 销毁时 (不 是关闭 Session),在该图实例上减少 1;当计数器为 0 时,则自动删除图实例。在新的接口实现中,实现了该引用计数器的技术。
消除序列化
在图的构造器,前端 Python 在构造每个 OP 时,直接通过 C API 将其追加至后端 C ++ 的图实例中,从而避免了图实例在前后端的序列化和反序列化的开销。
Operation
OP 用于表达某种抽象的数学计算,它表示计算图中的节点。Operation 是前端 Python 系统中最重要的一个领域对象,也是 TensorFlow 运行时最小的计算单位。
Operation 的元数据由 OpDef 与 NodeDef 持有,它们以 ProtoBuf 的格式存在,它描述 了 Operation 最本质的东西。其中,OpDef 描述了 OP 的静态属性信息,例如 OP 的名称, 输入/输出参数列表,属性集定义等信息。而 NodeDef 描述了 OP 的动态属性值信息,例如 属性值等信息。
Tensor
在图构造期,Tensor 在图中并未承载数据,它仅表示 Operation 输出的一个符号句柄。 事实上,需要通过 Session.run 计算才能得到 Tensor 所持有的真实数据。
Graph
Graph 是 TensorFlow 最重要的领域对象,TensorFlow 的运行时就是完成 Graph 的构造、 传递、剪枝、优化、分裂、执行。因此,熟悉 Graph 的领域模型,对于理解整个 TensorFlow 运行时大有裨益。
为了快速索引图中的节点信息,在当前图的作用域内为每个 Operation 分配唯一的 id, 并在图中存储 _nodes_by_id 的数据字典。同时,为了可以根据节点的名字快速索引节点信 息,在图中也存储了 _nodes_by_name 的数据字典。
为了更好地管理 Graph 中的节点,在每个 Operation 上打上特定的标签,实现了节点 的分类。相同类型的节点被划归在同一个 Collection 中,并使用唯一的 GraphKey 标识该 集合。
一般地,OP 注册到一个全局的、唯一的、隐式的、默认的图实例中。特殊地,TensorFlow 也可以显式地创建新的图实例 g,并调用 g.as_default() 使其成为当前线程中唯一默认的 图实例,并在该上下文管理器中所创建的 OP 都将自动注册到该图实例中。
在计算图的构造期间,不执行任何 OP 的计算。简单地说,图的构造过程就是根据 OP 构造器完成 Operation 实例的构造。而在 Operation 实例的构造之前,需要实现完成 OpDef 与 NodeDef 的构造过程。

Session
在 Session 的生命周期中,将根据计算图的计算需求,按需分配系统资源,包括变量, 队列,读取器等。
一个 Session 实例,只能运行一个图实例;但是,一个图实例,可以运行在多个 Session 实例中。如果尝试在同一个 Session 运行另外一个图实例,必须先关闭 Session(不必销毁), 再启动新图的计算过程。 虽然一个 Session 实例,只能运行一个图实例。但是,可以 Session 是一个线程安全 的类,可以并发地执行该图实例上的不同子图。例如,一个典型的机器学习训练模型中,可 以使用同一个 Session 实例,并发地运行输入子图,训练子图,及其 Checkpoint 子图。
Session
Session 继承 BaseSession,并增加了默认图与默认会话的上下文管理器的功能,保证 系统资源的安全释放。 一般地,使用 with 进入会话的上下文管理器,并自动切换默认图与默认会话的上下文; 退出 with 语句时,将自动关闭默认图与默认会话的上下文,并自动关闭会话。
InteractiveSession
与 Session 不同,InteractiveSession 在构造期间将其自身置为默认,并实现默认图与 默认会话的自动切换。与此相反,Session 必须借助于 with 语句才能完成该功能。在交互 式环境中,InteractiveSession 简化了用户管理默认图和默认会话的过程。 同理,InteractiveSession 在计算完成后需要显式地关闭,以便安全地释放其所占用的 系统资源。
Variable
Variable 是一个特殊的 OP,它拥有状态 (Stateful)。从实现技术探究,Variable 的 Kernel 实现直接持有一个 Tensor 实例,其生命周期与变量一致。相对于普通的 Tensor 实 例,其生命周期仅对本次迭代 (Step) 有效;而 Variable 对多个迭代都有效,甚至可以存储 到文件系统,或从文件系统中恢复。
在使用变量之前,必须对变量进行初始化。按照习惯用法,使用 tf.global_variables _initializer() 将所有全局变量的初始化器汇总,并对其进行初始化。

TensorFlow 的 Session 是线程安全的。也就是说,多个线程可以使用同一个 Session 实例,并发地执行同一个图实例的不同 OP;TensorFlow 执行引擎会根据输入与输出对图 实施剪枝,得到一个最小依赖的子图。 因此,通过多线程并使用同一个 Session 实例,并发地执行同一个图实例的不同 OP, 最终实现的效果是子图之间的并发执行。 对于典型的模型训练,可以充分发挥 Session 多线程的并发能力,提升训练的性能。例 如,输入子图运行在一个单独的线程中,用于准备样本数据;而训练子图则运行在另外一个 单独的线程中,并按照 batch_size 的大小一个批次取走训练样本,并启动迭代的训练过程。 本文将讲解上述并发模型中的基础设施,包括队列,多线程的协调器,及其控制 Enqueue OP 执行的 QueueRunner。
在 TensorFlow 的执行引擎中,Queue 是一种控制异步计算的强大工具。特殊地,Queue 是一种特殊的 OP,与 Variable 类似,它是一类有状态的 OP。 与之类似,Variable 拥有关联的 Assign 等修改其状态的 OP,Queue 也有与之关联的 OP,例如 Enqueue,Dequeue,EnqueueMany,DequeueMany 等 OP,它们都能直接修改 Queue 的状态。
本地执行
在本地模式下,Client, Master, Worker 部署在同一台机器同 一进程内,并由 DirectSession 同时扮演这三个角色。DirectSession 运行在单独的进程内, 各服务实体之间是函数调用关系。

Master 收到计算图执行命令后,启动计算图的剪枝操作。它根据计算图的输入输出反 向遍历图,寻找一个最小依赖的子图,常称为 ClientGraph。 也就是说,每次执行 run_step 时,并不会执行整个计算图 (FullGraph),而是执行部分 的子图。剪枝体现了 TensorFlow 部分执行的设计理念。
然后,运行时按照当前设备集完成图的分裂,生成了很多子图,每个子图称为 PartitionGraph;然后触发各个 Worker 并发地执行每个 PartitionGraph;对于每一个 PartitionGraph,运行时将启动一个 Executor,按照其拓扑排序完成 PartitionGraph 的执 行。 也就是说,分裂和执行体现了 TensorFlow 并发执行的设计理念。
分布式模式
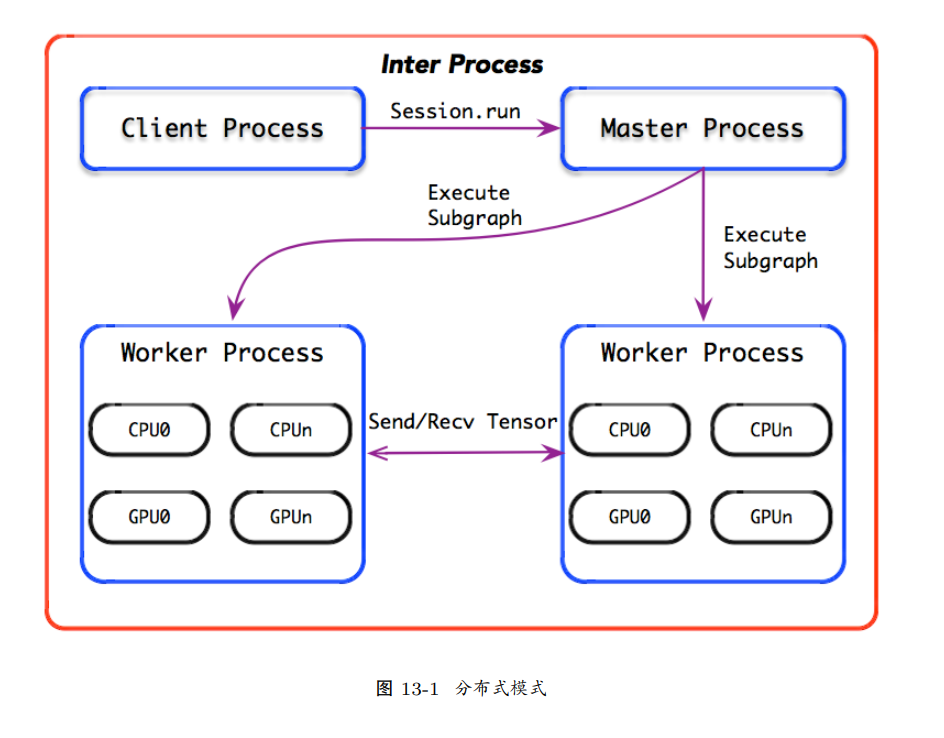
在 run_step 执行过程之中,涉及计算图的剪枝、分裂、执行 三个重要的图操作。其中,在分布式运行时,图分裂经历了两级分裂过程。
1. 一级分裂:由 MasterSession 完成,按照 SplitByWorker 或 SplitByTask 完成图 分裂过程;
2. 二级分裂:由 WorkerSession 完成,按照 SplitByDevice 完成图分裂过程。
在分布式模式中,图剪枝也体现了 TensorFlow 部分执行的设计理念;而图分裂和执行 也体现了 TensorFlow 并发执行的设计理念。其中,图剪枝仅发生在 Master 上,不发生在 Worker 上;而图分裂发生在 Master 和 Worker 上;图执行仅仅发生在 Worker 上,不发生 在 Master 上。


会话控制
如何反向传播
首先,根据正向子图的拓扑图,构造一个虚拟的反向子图。之所以称为虚拟的,是因为 真实的反向子图要比它复杂得多;更准确的说,虚拟的反向子图中的一个节点,对应于真实 的反向子图中的一个局部子图。
首先,根据该反向的虚拟子图执行 拓扑排序算法,得到该虚拟的反向子图的一个拓扑排序;然后,按照该拓扑排序,对每个正 向子图中的 OP 寻找其「梯度函数」;最后,调用该梯度函数,该梯度函数将构造该 OP 对 应的反向的局部子图。
一般地,梯度函数满足如下原型:
其中,梯度函数由 ops.RegisterGradient 完成注册,并放在保存梯度函数的仓库中。 以后,便可以根据正向 OP 的名字,索引对应的梯度函数了。

若有收获,就点个赞吧
0 人点赞
