1. 处理器 内存和指令
本章目标:
- 了解intel 8086处理器的通用寄存器和段地址加偏移地址的内存访问方式。
- 了解分段机制对程序重定位的好处。
- 理解intel 8086处理器内存分段的本质,充分认识到这种分段机制的灵活性。
处理器是一台电子计算机的核心,它会在振荡器脉冲的激励下,从内存中获取指令,并发起一系列由该指令所定义的操作。 当这些操作结束后,它接着在取下一条指令。 通常情况下,这个过程是连续不断、循环往复的。
内存储器
8位处理器包含8位的寄存器和算术逻辑部件,16位处理器包含16位的寄存器和算术逻辑部件,64位处理器包含64位的寄存器和算术逻辑部件.尽管内存的最小组成单位是字节,但是经过精心的设计和安排,它能够按字节、字、双字、和四字进行访问。 换句话说,仅通过单次访问就能处理8位、16位、32位或者64位的二进制数。 注意,是单次访问,而不是一个一个地取出每个字节,然后加以组合。
指令和指令集
处理器的设计者用某些数来指示处理器所进行的操作,这称为指令,或者叫机器指令。只有处理器才认识他们。
处理器内部又寄存器和负责运算的部件,控制器“分析”一个个指令,然后确定在哪个时间点让哪些部件进行工作。
比如,指令F4H表示让处理器停机,当处理器取到并执行这条指令后,就停止工作,指令是集中存放在内存里的,一条接着一条,处理器的工作是自动按顺序取出并加以执行。
8086的通用寄存器
8086处理器内部有8个16位的通用寄存器,分别被命名位AX,BX,CX,DX,SI,DI,BP,SP。“通用”的意思是,他们之中的大部分都可以根据需要用于多种目的。
如下图所示,因为这8个寄存器都是16位的,所以通常用于进行16位的操作。比如,可以在这8个寄存器之间互相传送数据,他们之间也可以进行算术逻辑运算;也可以在他们和内存单元之间进行16位的数据传送或者算术逻辑运算。
同事,如下图所示,这8个寄存器的前4个,即AX、BX、CX和DX,又各自拆分为两个8位的寄存器来使用,总共可以提供8个8位的寄存器AH、AL、BH、BL、CH、CL、DH和DL。这样依赖,当需要在寄存器和寄存器之间,或者寄存器和内存单元之间进行8位的数据传送或者算术逻辑运算时,使用它们就很方便。
内存分段机制
8086的内存分段机制
2. 汇编语言和汇编软件
3. 虚拟机安装和使用
实模式:
- 从多个角度展现8086处理器分段内存访问的特点,彻底理解分段的本质。
- 学习过程调用、栈、中断和外围设备访问的技术。
- 了解操作系统加载用户程序并实施重定位的一般原理。
- 学会用bochs虚拟机调试程序。
4. 编写主引导扇区代码
在屏幕上显示文字
显卡和显存
为了显示文字,通常需要两种硬件,一是显示器,二是显卡。显卡的职责是为显示器提供内容,并控制显示器的显示模式和状态,显示器的职责是将那些内容以视觉可见的方式呈现在屏幕上。
显卡控制显示器的最小单位是像素,一个像素对应着屏幕上的一个点。屏幕上通常又数十万乃至更多的像素,通过控制每个像素的阴暗和颜色,就能形成大量的像素形成的文字和图像。
如何来控制这些像素呢?
显卡都有自己的存储器,因为它位于显卡上,故称为显示存储器,简称现存,要显示的内容都预先写入显存。 和其他半导体存储器一样,显存并没有什么特殊的地方,也是一个按字节访问的存储器件。
图。。 显存内容和显示器内容之间的对应关系
显卡的工作是周期性地从显存中提取这些比特,并把他们按顺序显示在屏幕上。如果是比特“0”。则像素保持原来的状态不变。
xor指令的目的操作数可以是通用寄存器和内存单元,源操作数可以是通用寄存器、内存单元和立即数(不允许两个操作数同时为内存单元)。而且,异或操作是在两个操作数相应的比特之间单独进行的。
使程序进入无限循环状态infi: jmp near infi
jmp 是转移指令,用于使处理器脱离当前的执行序列,转移到指定的地方执行,
near表示目标位置依然在当前代码段内。
上面这条指令唯一特殊的地方在于它不是转移到别处,而是转移到自己。也就是说,它将会不断的重复执行自己。
处理器取指令、执行指令是依赖于段寄存器CS和指令指针寄存器IP的,8086处理器取指令时,把CS的内容左移4位,加上IP的内容,形成20位的物理地址,取得指令,然后执行,同时把IP的内容加上当前指令的长度,以指向下一条指令的偏移地址。
5. 相同功能,不同代码
学习目标:
- 用一种不同的分段方法,从另一个不同的角度理解处理器的分段内存访问机制。
- 在计算机中,指令的执行并非总是按照它们的自然排列顺序来进行的,其执行流程也因为各种原因发生变化。 本章将学习两种非顺序的流程控制方法,即循环和条件转移。
- 认识几种新指令,包括movsb, movsw,inc, dec, cld, std, div, neg, cbw, cwd, sub, idiv, jcxz, cmp 等。
- 认识INTEL8086标志寄存器FLAGS的各个标志位,了解条件转移指令。
- 认识计算机中的负数。
- 学习用bochs调试程序的更多技巧,包括查看FLAGS寄存器各标志位的状态。
段之间的批量数据传送
movsb movsw
这两个指令通常用于把数据从内存中的一个地方批量地传送(复制)到另一个地方,处理器把它们看成是数据串。但是movsb的传送是以字节为单位的,而movsw的传送是以字为单位的。
movsb和movsw指令执行时, 原始数据串的段地址由DS指定, 偏移地址由SI指定,简写为DS:SI;要传送到目的地址由ES:DI指定; 传送的字节数(movsb)或者字数(movsw)由CX指定。 除此之外,还要指定是正向传送还是反向传送,正向传送是指传送操作的方向是从内存区域的低地址端到高地址端; 反向传送正好相反。
正向传送时,每传送一个字节(movsb)或者一个字(movsw),SI和DI加1或者加2; 反向传送时,每传送一个字节(movsb)或者一个字(movsw)时,SI和DI减去1或者减去2. 不管是正向传送还是反向传送,也不管每次传送的是字节还是字,每传送一次,CX的内容自动减一。
在8086处理器里,有一个特殊的寄存器,叫做标志寄存器FLAGS。作为一个例子,它的第6位是ZF(zero flag),即零标志。 当处理器执行一条算术或者逻辑运算指令后,算术逻辑部件送出的结果除了送到指令中指定位置(目的操作数指定的位置)外,还送到一个或非门。
使用循环分解数位
在8086处理器上,如果要用寄存器来提供偏移地址,只能用BX,SI、DI,BP,不能使用其他寄存器。所以,以下指令都是非法的:
mov [ax],dlmov [dx],bx
原因很简单,寄存器BX最初的功能之一就是用来提供数据访问的基地址,所以又叫基地址寄存器(Base Address Register)。之所以不能用SP、IP、AX、CX、DX,这是一种硬性规定,说不上有什么特别的理由。而且在设计8086处理器时,每个寄存器都有自己的特殊用途,比如AX是累加器(Accumulator),与它有关的指令还会做指令长度上的优化(较短);CX是计数器(counter);DX是数据(Data)寄存器,除了作为通用寄存器使用外,还专门用于和外设之间进行数据传送操作,我们已经在movsb和movsw指令的用法中领略过了。
数位的显示
将保存有各个位数的数据区首地址传送到基址寄存器BX。
一共5个数字要显示,它们在当前数据段内的起始偏移地址就是number的汇编地址,且已传送到寄存器BX中。为了依次得到这5个数字,程序中使用的指令是mov al, [bx+si]
寄存器BX中的内容是基地址,保持不变,当寄存器SI的内容从0逐次增加到4,或者反过来,从4递减到0时,就可以通过BX+SI来连续访问这5个数字。在这里,SI的作用相当于索引,因此它被称为索引寄存器,或者叫变址寄存器。另一个常用的变址寄存器时DI。
注意,INTEL8086处理器只允许以下几种基址寄存器和变址寄存器的组合
[bx+si][bx+di][bp+si][bp+di]
这些组合可以用于任何带有内存操作数的指令中。其他任何组合,比如[bx+ax]、[cx+dx]、[ax+cx]等等,都是非法的。
其他标志位和条件转移指令
在处理器内进行的很多算术逻辑运算,都会影响到标志寄存器的某些位。比如我们已经学过的加法指令add、逻辑运算指令xor等。
- 奇偶标志位PF
当运算结果出来后,如果最低8位中,有偶数个为1的比特,则PF=1;否则PF。例如:
mov ax,1000100100101110B ;ax <- 0x892exor ax,3 ;结果为0x892d(1000100100101101B)
顺序执行以上两条指令后,因为结果是1000100100101101B,低8位是00101110B,有偶数个1,所以PF=1.
再如:
mov ah,00100110B ;ah<-0x26mov al,10000001B ;al<-0x81add ah,al ;ah<-0xa7
以上,因为最后ah的内容是0xa7(10100111B),包含奇数个1,故PF=0;
- 进位标志cf
- 溢出标志of
- 现有指令对标志位的影响
- 条件转移指令
6. 更快的计算
伟大的数学家高斯在9岁那年,用很短的时间完成了从1到100的累加。那原本是老师给学生们出的难题,希望他们能够老老实实的呆在教室里。
高斯的方法很简单,他发现这是50个101的求和: 100+1、99+2、。。。50+51,于是很快的算出结果是101*50=5050.从1加到100,高斯发现了其中的规律,当然很快就能算出结果。但是计算机很蠢,他不懂什么规律,只能从1老老实实加到100. 不过,他的强项就是速度,而且不怕麻烦。
本章主要学习一种重要的数据结构,栈,了解处理器为访问栈提供了怎样的支持。
总结INTEL8086处理器的寻址方式。
学习心得处理器指令, or and push pop。
栈 学过数据结构的都知道,不说了,,,
和代码段、数据段和附加段一样,栈也被定义成一个内存段,叫栈段,由段寄存器SS指向。
定义栈需要两个连续的步骤,即初始化段寄存器SS和栈指针SP的内容。
pop dx指令的功能是将逻辑地址:SS:SP处的一个字弹出到寄存器DX中,然后将SP的内容加上操作数的字长。
和push指令一样,pop指令的操作数可以是16位的寄存器或者内存单元。例如
pop axpop word [label_a]
pop指令执行时,处理器将栈段寄存器SS的内容左移4位,再加上栈指针寄存器SP的内容,形成20位的物理地址访问内存,取得所需的数据。然后,将SP的内容加操作数的字长,以指向下一个栈位置。
几点说明:
一、push指令的操作数可以是16位寄存器或者16位内存单元,push指令执行后,压入栈中的仅仅是该寄存器或者内存单元里的数值,与该寄存器活内存单元不再相干。 如果不理解这一点,就容易错误地以为压入了某个寄存器的值,比如AX之后,将来还要再弹回AX才行,这是不对的。 所以,下面的指令时合法而且正确的:
push cspop ds
这两条指令的意思是,将代码段寄存器的内容压栈,并弹出到数据段寄存器DS。如此一来,代码段和数据段将属于同一个内存段。 实际上,这两条指令的执行结果,和以下指令的执行结果相同:
mov ax,cxmov ds,ax
二、 栈在本质上也只是普通的内存区域,之所以要用push和pop指令来访问,是因为你把它看成栈而已。实际上,如果你把它看成是普通的数据段而忘掉它是一个栈,那么它将不再神秘。
引入栈和push、pop指令只是为了方便程序开发。临时保存一个数值到栈中,使用push指令是最简洁最省事的,但如果你不怕麻烦,也可以不使用它。所以,下面的代码可以用来取代push ax指令:
sub sp,2 mov bx,sp mov [ss:bx], ax
同样,pop ax指令的执行结果和下面的代码相同:mov bx,sp mov ax,[ss:bx] add sp,2
你可能还有另一种想法,即,我连栈段都不用,SP也省了,我自己把临时数据都保存在数据段中。 如果是这样的话,你必须在数据段中开辟一些空间,并亲自维护一个指针来跟踪这些数据的存入和取出。 当程序变得越来越复杂时,这些维护工作同样让你焦头烂额。
因此,显而易见的是,push和pop指令更方便,毕竟与栈访问有关的一切都是由处理器自动维护的。而且,总有一天你会发现,有些工作不使用栈来进行的话,是非常困难的。
三、 注意保持栈平衡。如果在做某件事的时候要使用栈,那么,栈指针寄存器SP在做这件事之前的值,应当和这件事做完后的值相同。就是说,push指令和pop指令的数量应当是相同的。栈时反复使用的内存区域,如果使用不当,将会出现问题,下面就是一个例子
repeat:push ax...... ;其他非栈操作的指令pop bxpop axloop repeat
入栈了一个ax 出栈时缺多弹出一个bx 栈不匹配
8086处理器的寻址方式
寄存器寻址
指令执行时,操作的数位于寄存器中,可以从寄存器里取得。
比如:mov ax,cx add bx,0xf000 inc dx
以上,第一条指令的两个操作数都是寄存器,是典型的寄存器寻址。
第二条指令的目的操作数是寄存器,因此,该操作数也是寄存器寻址;
第三条指令就更不用说了。
立即寻址
立即寻址又叫立即数寻址。也就是说,指令的操作数是一个立即数。 比如:add bx,0xf000 mov dx,label_a
以上,第一条指令的目的操作数采用了寄存器寻址方式,用于提供被加数;
第二个操作数(源操作数)用于给出加数0xf000。这是一个直接给出的数值,是立即在指令中给出的,最终参与加法运算的就是它,不需要通过其他方式寻找,故称为立即数。这也是一种寻址方式,称为立即寻址。
在第二条指令中,目的操作数也采用的是寄存器寻址方式。
内存寻址
7. 硬盘和显卡的访问与控制
本章目标:
- 模拟操作系统加载应用程序的过程,演示段的重定位方法,最终使你彻底理解8086处理器的分段内存管理机制。
- 学习x86处理器过程调用的程序执行机制。
- 以读硬盘扇区和控制屏幕光标为实例,了解x86处理器访问外围硬件设备的方法。
- 总结JMP和CALL指令的全部格式。
- 认识更多的x86处理器指令,如in、out、shl、rol、ror、jmp、call、ret等。
分段、段的汇编地址和段内汇编地址
处理器的工作模式是将内存分成逻辑上的段,指令的获取和数据的访问一律按“段地址:偏移地址”的方式进行。相对应的,一个规范的程序,应当包括代码段、数据段、附加段和栈段。 这样依赖,段的划分和段与段之间的界限在程序加载到内存之前就已经准备好了。
NASM编译器使用汇编指令“SECTION”或者“SEGMENT”来定义段。 它的一般格式是SECTION 段名称
或者SEGMENT 段名称
第一个段的名字是header ,表明它是整个程序的开头部分; 第二个段的名字是code,表明这是代码段; 第三个段的名字是data,表明这是数据段。
Intel处理器要求段在内存中的其实物理地址起码是16字节对其的。 这句话的意思是,必须是16的整数倍,或者说改物理地址必须能被16整除。
响应的,汇编语言中源程序中定义的各个段,也有对其方面的要求。具体做法是,在段定义中使用 align=子句,用于指定某个section的汇编地址对齐方式。
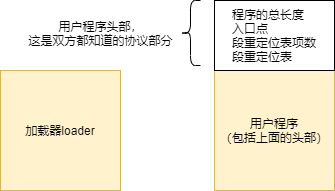
头部需要在源程序以一个段的形式出现。SECTION header vstart=0
而且,因为它是“头部”,所以,该段当然必须是第一个被定义的段,而且总是位于整个源程序的开头。
用户程序头部起码要包含以下信息:
- 用户程序的尺寸,即以字节为单位的大小。这对加载器来说是很重要的,加载器需要根据这一信息来决定读取多少个逻辑扇区
- 应用程序的入口点,包括段地址和偏移地址。加载器并不清楚用户程序的分段情况,更不知道第一条要执行的指令在用户程序中的位置。 因此,必须在头部给出第一条指令的段地址和偏移地址,这就是所谓的应用程序入口点。
- 段重定位表。 用户程序可能包含不止一个段,比较打的程序可能会包含多个代码段和多个数据段。这些段如何使用,是用户程序自己的事,但前提是程序加载到内存后,每个段的地址必须重新确定一下。
段的重定位是加载器的工作,它需要知道每个段在用户程序内的位置,即他们分别位于用户程序内的多少字节处。 为此, 需要在用户程序头部建立一张段重定位表。
用户程序可以定义的段在数量上是不确定的,因此,段重定位表的大小,或者说表项数是不确定的。 为此,代码清单8-2第14行,声明并初始化了段重定位表的数目数。 因此段重定位表位于两个标号header_end 和code_1_segment之间,而且每个表项占用4字节,故实际的表项数位(header_end - code_1_segment) / 4
这个值实在程序编译阶段计算的,先用两个标号所代表的汇编地址相减,再除以每个表项的长度4.
紧接着表项数的,是实际的段重定位表, 每个表项用伪指令dd声明并初始化为1个双字。
加载程序(器)的工作流程
- 初始化和决定加载位置
从大的方面来说,加载器是要加载一个用户程序,并使之开始执行,需要决定两件事。
第一,看看内存中的什么地方是空闲的,即从哪个物理内存地址开始加载用户程序;
第二,用户程序位于硬盘上的什么位置,它的其实逻辑扇区号是多少。如果你连他在哪里都不知道,怎么找得到他呢!
- 准备加载用户程序
- 外围设备及其接口
- i/o端口和端口访问
- 通过硬盘控制器端口读扇区数据
- 过程调用
- 加载用户程序
- 用户程序重定位
- 将控制权交给用户程序
-
用户程序的工作流程
初始化段寄存器和栈切换
- 调用字符串显示例程
- 过程的嵌套
- 屏幕光标控制
- 取当前光标位置
- 处理回车和换行字符
- 显示可打印字符
- 滚动屏幕内容
- 重置光标
- 切换到另一个代码段中执行
- 访问另一个数据段
8. 中断和动态时钟显示
外部硬件中断
- 非屏蔽中断
- 可屏蔽中断
- 实模式下的中断向量表
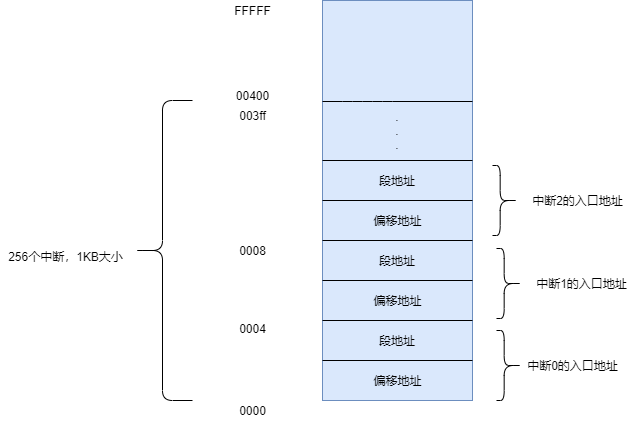
所谓中断处理,归根结底就是处理器要执行一段与该中断有关的程序(指令)。处理器可以识别256个中断,那么理论上就需要256段程序。 这些程序的位置并不重要,重要的是,在实模式下,处理器要求将它们的入口点集中存放在内存中的物理地址0x000000开始,到0x003ff结束,共1KB的空间内,这就是所谓的中断向量表(Interrupt Vector Table,IVT).
如图9-3所示,每个中断在中断向量表中占2个字,分别是中断处理程序的偏移地址和段地址。 中断0的入口点位于物理地址0x000000处,也就是逻辑地址0x0000:0x0000;中断1的入口点位于物理地址0x00004处,即逻辑地址0x0000:0x0004;其他中断依次类推,总之是按顺序的,
当中断发生时,如果从外部硬件到处理器之间的道路都是畅通的, 那么,吹起在执行完当前的指令后,会立即着手为硬件服务。它首先会影响中断,告诉8259芯片准备着手处理该中断。接着,它还会要求8259芯片把中断号送过来。
在8259芯片哪里,每个引脚都赋予了一个中断号。而且,这些中断号是可以改变的,可以对8259编程来灵活设置,但不能单独运行,只能以芯片为单位进行。比如,可以指定朱片的中断号从0x08开始,那么它每个引脚IR0~IR7所对应的中断号分别是0x08~0x0e。
中断信号来自哪个引脚,8259芯片是最清楚的,所以它会把对应的中断号告诉处理器,处理器拿着这个中断号,要顺序做以下几件事。
- 保护断点的现场。首先要将标志寄存器FLAGS压栈,然后清楚它的IF位和TF位。TF是陷阱标志,接着,再将当前的代码段寄存器CS和指令指针寄存器IP压栈。
- 执行中断处理程序。由于处理器已经拿到了中断号,它将该号码乘以4(毕竟每个中断再中断向量表中占4字节),就得到了该中断入口点在中断向量表中的偏移地址。接着,从表中依次取出中断程序的偏移地址和段地址,并分别传送到IP和CS,自然地,处理器就开始执行中断处理程序了。
实模式下的中断向量表
注意, 由于IF标志被清楚,在中断处理过程中,处理器将不再响应硬件中断。如果希望更高优先级的中断嵌套,可以在编写中断向量处理程序时,适时用sti指令开放终端。
- 返回到断电接着执行。所有中断处理程序的最后一条指令必须是中断返回指令iret。这将导致处理器依次从栈中弹出(恢复)IP、CS和FLAGS的原始内容,于是转到主程序接着执行。
顺便提醒一句,由于中断处理过程过程返回时,已经恢复了FLAGS的原始内容,所以IF标志位也自动恢复。也就是说,可以接受新的中断。
和可屏蔽中断不同,NMI发生时,处理器不会从外部获得中断号,它自动生成中断号吗,其他处理过程和可屏蔽终端相同。
中断随时可能发生,中断向量表的建立和初始化工作是由BIOS在计算机启动时负责完成的。BIOS为每个中断号填写入口地址,因为它不知道多数中断处理程序的位置,所以,一律将它们指向一个相同的入口地址,在哪里,只有一条指令:iret。也就是说,当这些中断发生时,只做一件事,那就是立即返回。当计算机启动后,操作系统和用户程序再根据自己的需要,来修改某些中断的入口地址,使他指向自己的代码。
实时时钟、cmos ram和bcd编码
初始化8259、rtc和中断向量表
- 使处理器进入低功耗状态
- 实时时钟中断的处理过程
内部中断
和硬件中断不同,内部中断发生在处理器内部,是由执行的指令引起的。比如,当处理器检测到div或者idiv指令的除数为零时,或者出发的结果溢出时,将产生中断0 (0号中断),这就是除法错中断。
再比如,当处理器遇到非法指令时,将产生中断6。非法指令时只指令的操作码没有定义,或者指令超过了规定的长度。操作码没有定义通常意味着那不是一条指令,而是普通的数。
内部中断不受标志寄存器IF位的影响,也不需要中断识别总线周期,他们的中断类型时固定的,可以立即转入相应的处理过程。
软中断
软中断是由int指令引起的中断处理。这类中断也不需要中断识别总线周期,中断号再指令中给出。int指令的格式如下:int3 int imm8 into
int3是断点中断指令,机器指令码为CC。这条指令在调试程序的时候很有用,当程序运行不正常时,多数时候希望在某个地方设置一个检查点,也成为断电,来查看寄存器、内存单元或者标志寄存器的内容,这条指令就是为这个目的而设的。
指令都是连续存放的,因此,所谓的断点,就是某条指令的起始地址。int3时单字节指令,这是有意设计的。当需要设置断点时,可以将断点处那条指令的第1字节改成0xcc,原字节予以保存。当处理器执行到int3时,即发生3号中断,专区执行相应的中断处理程序。中断处理程序的执行也要用到各个寄存器,它会破坏它们的内容,但push指令不会。我们可以再改程序内先压栈所有相关寄存器和内存单元,然后分别取出予以显示,它们就是中断前的现场内容。 最后,再恢复那条指令的第1字节,并修改位于栈中的返回地址,执行iret指令。
注意,int3和int 3不是一回事。前者是机器码CC,后者是CD 03,这就是通常所说的int n,其操作码为0xCD,第2字节的操作数给出了中断号。举几个例子:int 0x00 ;引发0号中断 int 0x15 ;引发0x15号中断int 0x16 ;引发0x16号中断
into 是溢出中断指令,机器码为0xCE,也是单字节指令。当处理器执行这条指令时,如果标志寄存器的OF位为1,那么,将产生4号中断。否则,这条指令什么也不做。
保护模式
- 学习处理器32位保护模式的工作原理,包括分段、分页、特权级、保护、中断和异常中断等。
- 学习32位保护模式下的汇编语言程序设计。
- 通过多个实例了解操作系统如何再保护模式下加载应用程序,并提供各种管理服务。
- 学会用bochs虚拟机调试32位保护模式下的程序。
9. 32位的x86处理器架构
9.1 ia-32架构的基本执行环境
9.1.1 寄存器的扩展
9.1.2 基本的工作模式
9.1.3 线性地址
9.2 现代处理器的结构和特点
9.2.1 流水线
9.2.2 高速缓存
9.2.3 乱序执行
9.2.4 寄存器重命名
9.2.5 分支目标预测
9.3 32位模式的指令系统
9.3.1 32位处理器的寻址方式
9.3.2 操作数大小的指令前缀
Intel处理器的指令系统比较复杂,这种复杂性来源于两个方面,一是指令的数量较多,二是寻址方式也很多。可以想象,为了组成这些众多的指令,必须有一套同样复杂的指令格式。
如下图所示,每一条处理器指令都可以拥有前缀,比如重复前缀(REP/REPE/REPNE)、段超越前缀(如:ES:)、总线封锁前缀(LOCK)等。 前缀是可选的,每个前缀的长度是1字节,每条指令可以有1~4个前缀,或者不适用前缀。
前缀(如果有的话)的后面是操作码部分,指示执行什么样的操作,比如传送、加法、减法、乘法、除法、位移等。根据指令的不同,操作码的长度是1~3字节。 同时,操作码还可以用来指示操作的字长,即数据宽度是字节还是字。
操作码之后是操作数类型和寻址方式部分。 这部分是可选的,简单的指令不包含这一部分,稍微复杂一点的指令,这一部分只有1字节:最复杂的指令,可能有2字节。 这部分给出了指令的寻址方式,以及寄存器的类型(用的是哪个寄存器)。
指令的最后是立即数和偏移量。如果指令中使用了立即数,那么立即数就在这一部分给出: 如果指令使用了带偏移量的寻址方式,如:mov cx,[0x2000] mov ecx,[eax+ebx*8+0x02]
那么。偏移量0x2000和0x02也在这部分出现。取决于具体的指令,立即数可以是1、2或者4字节,偏移量部分与此相同。
上述的指令编码格式发源于16位处理器时代,并在32位处理器出现之后做了修改,主要是扩展了数据的宽度,其他都保持不变。毕竟,兼容性是首要考虑的因素。但是,这也带来了一些问题。考虑以下指令:mov dx, [bx+si+0x02]
在16位指令编码格式中,这种内存单元到寄存器的传送指令使用了操作码0x8B。如下图所示,在操作吗0x8B之后是1字节的寻址方式和操作数类型部分。 位7和位6的值是01,表示使用了基地址变址的寻址方式,而且带有8位偏移量; 位5~位3的值是010,指示目的操作数位寄存器DX;位2~位0的值是000,表示寻址方式为“BX+SI+8位偏移量”。在改字节之后,是1字节的偏移量0x02。因此,这条指令编译后的机器代码是8B 50 02
32位处理器使用相同的编码格式,但是,寻址方式和寄存器的定义却是另起炉灶,完全不同于16位指令。如下图二所示,在32位处理器上,位7和位6的值是01,表示使用了基址寻址方式,而且带有8位偏移量;位5~位3的值是010,表示目的操作数为寄存器EDX;位2~位0的值是000,表示寻址方式位EAX+8位偏移量。在该字节之后,是1字节的偏移量0x02。因此,同样的机器指令码,却对应着不同的32位指令:mov edx, [eax+0x02]
这就是说,相同的机器指令,在16位模式下和32位模式下的解释和执行效果是不同的。但是,别忘了,32位处理器可以执行16位的程序,包括实模式和16位保护模式。为此,在16位模式下,处理器把所有指令都看成16位的。举个例子,机器指令码0x40在16位模式下的含义是inc ax
当处理器在16位模式下运行时,也可以用32位的寄存器,执行32位的运算。为此,必须使用前缀0x66来改变这种默认状态,因为同一个指令码,在16位模式下和32位模式下具有不用的解释。因此,当处理器在16位模式下运行时,机器指令码 66 40 对应的指令不再是 inc ax ,而是 inc eax
相反地,如果处理器运行在32位模式下,那么,处理器认为指令的操作数都是32位的,如果你加了前缀,这个前缀就用来指示指令是16位的。因此,指令前缀0x66具有反转当前默认操作数大小的作用。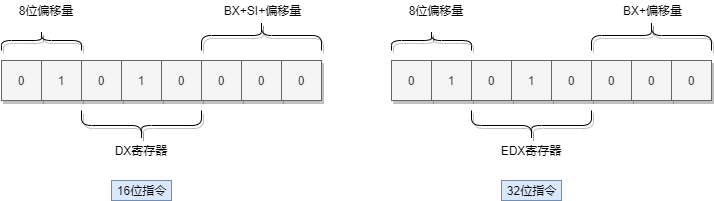
在编写程序的时候,就应当考虑到指令的运行环境。 为了指明程序的默认运行环境,编译器提供了伪指令bits,用于指明其后的指令应该被编译成16位的,还是32位的。 比如
bits 16mov cx,dx ;89 D1mov eax,ebx ;66 89 D8bits 32mov cx, dx ; 66 89 D1mov eax,ebx ; 89 D8
注意,bits 16或者bits 32可以放在方括号中,也可以没有方括号。以下两种方式都是允许的:
[bits 32]mov ecx, edxbits 16mov ax, bx
最后,16位模式是默认的编译模式。如果没有指定指令的编译模式,则默认是“bits 16”的。
有关寻址方式和指令前缀的话题比较复杂。
9.3.3 一般指令的扩展
由于32位的处理器都拥有32位的寄存器和算术逻辑部件,而且同内存芯片之间的数据通路至少是32位的,因此,所有以寄存器或内存单元为操作数的指令都被扩充,以适应32位的算术逻辑操作。而且,这些扩展的操作即使是在16位模式下(实模式和16位保护模式)也是可用的。比如加法指令ADD,在32位处理器上,除了允许8位或者16位的操作数外,32位的操作数现在也是可用的:add al,bl add ax,bx add eax, ebx add dword [ecx],0x0000005f
除了双操作数指令,单操作数指令也同样允许32位操作数。比如inc al inc dword [0x2000] dec dword [eax*2]
和16位时代一样,在32位处理器上,逻辑移动指令的源操作数如果是寄存器的话,则依然必须使用CL。同时,32位处理器在实际执行时,要先将源操作数(在CL寄存器内)同0x1F做逻辑与。也就是说,仅保留源操作数的低5位,因此,实际移动的次数最大位32.
在16位处理器上,loop指令的循环次数在寄存器CX中。在32位处理器上,如果当前的运行模式为16位的(bits 16,8086实模式或者16位保护模式),那么,loop指令执行时,依然使用CX寄存器;否则,如果运行在32模式下(bits32),则使用的是ECX寄存器。
在16位处理器上,无符号数惩罚指令mul的格式为mul r/m8 ;AX <-- AL * r/m8 mul r/m16 ;DX:AX <-- AX*r/m16
这样,两个32位的数相乘,得到一个64位的结果。 这里有个例子“mov eax,0x10000 mov ebx,0x20000 mul ebx
有符号数乘法指令imul与此相同。
相应地,无符号数和有符号数除法也做了32位扩展:div r/m32 idiv r/m32
在这里,被除数是64位的,高32位在EDX寄存器;低32位在EAX寄存器。 除数是32位的,位于32位的寄存器,或者存放在有32位实际操作数的内存地址。 指令执行后,32位的商在EAX寄存器,32位的余数在EDX寄存器。
32位处理器的栈操作指令push和pop也有所扩展,允许压入双字操作数。特别是,它现在支持立即数压栈操作。立即数压栈操作的指令格式位push imm8 ;操作码位6A push imm16 ;操作码位68 push imm32 ;操作码位68
举个例子:比如push byte 0x55
在这里,关键字”byte”仅仅是给编译器用的,告诉它,压入的是字节(毕竟立即数0x55可以解释为字0x0055或者双字0x00000055),而不是用来在编译后的机器指令前添加指令前缀。
这条指令的16位形式(用bits 16编译)和32位形式(用bits 32编译)是一样的,机器代码都是 6A 55
但是,当它执行时, 就不同了。 注意,无论在什么时候,处理器都不会真的压入一字节,要么压入字,要么压入双字。因此,在16位模式下,默认的操作数字长是16,处理器在执行时,将改字节的符号位扩展到高8位,然后压入栈,压栈时使用SP寄存器,且先将SP的内容减去2。这就是说,实际压入栈中的数值时0x0055;在32位模式下,压入的内容是该字节操作数符号位扩展到高24位的结果,即0x00000055。压栈时使用ESP寄存器,且先将ESP的内容减去4.
如果压入的是字操作数,则必须用关键字”word”来修饰。如:push word 0xfffb
在16位模式下,默认的操作数字长是16,处理器在执行时,直接压入该字,压栈时使用SP寄存器,且先将SP的内容减去2;在32位模式下, 压入的内容是该操作数符号位扩展到高16位的结果,即0xFFFFFFFB,压栈时使用ESP寄存器,且先将ESP的内容减去4。
如果压入的是字操作数,则必须用关键字”word”来修饰。如:
push word 0xfffb
在16位模式下,默认的操作数字长是16,处理器在执行时,直接压入该字,压栈时使用SP寄存器,且先将SP的内容减去2;在32位模式下,压入的内容是该操作数符号位扩展到16位的结果,即0xFFFFFFFB,压栈时使用ESP寄存器,且先将ESP的内容减去4。
如果压入的是双字操作数,则必须用关键字“dword”来修饰。如:push dword 0xfb
则无论是在16位模式下,还是在32位模式下,压入的都是0x000000FB,而且栈指针寄存器(SP或者ESP)都先减去。
对于实际操作数位于通用寄存器,或者位于内存单元的情况,只能压入字或者双字,指令格式位:push r/m16 push r/m32
如果是寄存器,则可以使用16位或者32位的通用寄存器。比如push ax push edx
无论被压入的数位于寄存器,还是位于内存单元,在16位模式下,如果压入的是字操作数,那么先将SP的内容减去2;如果压入的是双字,应当先将SP的内容减去4。在32位模式下,如果压入的是子操作数,那么先将ESP的内容减去2;如果压入的是双字,应当先将ESP的内容减去4.
压入段寄存器的操作比较特殊。以下是压入段寄存器的push指令格式:push cs ;机器指令位0E push ds ;机器指令位1Epush es ;机器指令位06push fs ;机器指令位0F A0push gs ;机器指令位0F A8push ss ;机器指令位16
在16位模式下,先将SP的内容减去2,然后直接压入段寄存器的内容;在32位模式下,要先将段寄存器的内容用零扩展到32位,即高16位全为零。然后,将ESP的内容减去4,再压入扩展后的32位值。
10. 进入保护模式
本章学习目标
- 了解x85处理器的保护模式需要先定义全局描述符表GDT,认识段描述符的各个组成部分以及它们的含义和作用。
- 认识32位处理器的全局描述符表寄存器GDTR、段寄存器(由段选择器和描述符高速缓存器组成)、控制寄存器CR0和段选择子。
- 了解进入32位保护模式的方法和步骤。
- 学习保护模式下的一些程序调试技术,如查看全局描述符表GDT、段寄存器和控制寄存器等。
- 学习一条x86处理器的新指令lgdt。
10.1 全局描述符表
我们知道,为了让程序在内存中能自由浮动而又不影响它的正常执行,处理器将内存划分为逻辑上的段,并在指令中使用段内偏移地址。在保护模式下,对内存的访问仍然使用段地址和偏移地址,但是,在每个段能够访问之前,必须先进行登记。
当你访问的偏移地址超出段的界限时,处理器就会阻止这种访问,并产生一个叫做内部异常的中断。
和一个段有关的信息需要8个字节来描述,所以称为段描述符(Segment Descripor),每个段都需要一个描述符。为了存放这些描述符,需要在内存中开辟出一段空间。在这段空间里,所有的描述符都是挨在一起,集中存放的,这就构成一个描述符表。
最主要的是描述符表是全局描述符表(Global Descriptor Table,GDT),所谓全局,意味着该表是整个软硬件系统服务的。 在进入保护模式钱,必须要定义全局描述符表。
如下入所示,为了跟踪全局描述符表,处理器内部有一个48位的寄存器,称为全局描述符表寄存器(GDTR)。该寄存器分为两部分,分别是32位的线性地址和16位的边界。32位的处理器具有32根地址线,可以访问的地址范围是0x00000000到0xFFFFFFFF,共2^32字节的内存,即4GB内存。所以,GDTR的32位线性基地址部分保存的是全局描述符表在内存中的起始线性地址,16位边界部分保存的是全局描述符表的边界(界限),其在数值上等于表的大小(总字节数)减一。
换句话说,全局描述符表的界限值就是表内最后1字节的偏移量。第1自己的偏移量是0,最后1字节的偏移量是表达小减一。如果界限值为0,表示表的大小是1字节。
因为GDT的界限是16位的,所以,该表最大时2^16字节,也65535字节(64KB)。又因为一个描述符占8字节,故最多可以定义8192个描述符。实际上,不一定非得这么多,到底有多少,视需要而定,但是最多不能超多8192个。
理论上,全局描述符表可以位于内存中的任何地方。但是,如下图所示,由于在进入保护模式之后,处理器立即要按新的内存访问模式工作,所以,必须在进入保护模式之前定义GDT。但是,由于在实模式下只能访问1MB的内存,故GDT通常都定义在1MB以下的内存范围中。当然,允许在进入保护模式之后换个位置重新定义GDT。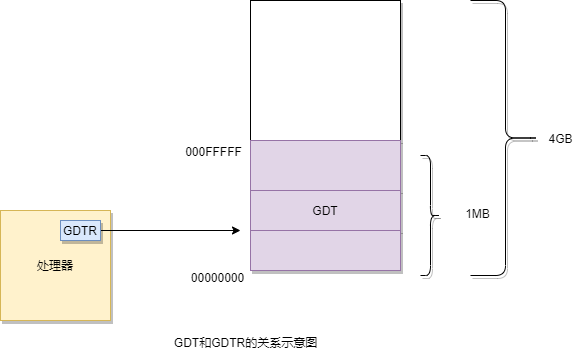
10.2 存储器的段描述符
10.3 安装存储器的段描述符并加载gdtr
10.4 关于第21条地址线a20的问题
10.5 保护模式下的内存访问
10.6 清空流水线并串行化处理器
10.7 保护模式下的栈
10.7.1 关于栈段描述符中的界限值
10.7.2 检验32位下的栈操作
10.8 程序的运行和调试
10.8.1 运行程序并观察结果
10.8.2 处理器刚加电是的段寄存器状态
10.8.3 设置pe位后的段寄存器状态
10.8.4 jmp指令执行后的段寄存器状态
10.8.5 查看全局描述符表gdt
10.8.6 查看控制寄存器的内容
11. 存储器的保护
12. 程序的动态加载和执行
13. 任务和特权级保护
14. 任务切换
15. 分页机制和动态页面分配
16. 中断和异常的处理与抢占式多任务

若有收获,就点个赞吧
0 人点赞
