索引
索引常见模型
索引常见的模型:
- 哈希表
- 有序数组
- 搜索树哈希表
哈希表这种结构适用于只有等值查询的场景,比如 Memcached 及其他一些 NoSQL 引擎。- 哈希表是一种以 键-值(key-value)存储的数据结构.
- 用哈希函数吧数据的key换算成一个确定的位置,然后把value放在数组的位置
- 因为通过哈希函数换算出的数组位置会导致出现同一个值的情况,解决办法是拉出一个链表链表处理哈希结果一致的问题
- 图中,User2 和 User4 根据身份证号算出来的值都是 N,但没关系,后面还跟了一个链表。 假设,这时候你要查 ID_card_n2 对应的名字是什么,处理步骤就是:首先,将 ID_card_n2 通过哈希函数算出 N;然后,按顺序遍历,找到 User2。 需要注意的是,图中四个 ID_card_n 的值并不是递增的,这样做的好处是增加新的 User 时速度会很快,只需要往后追加。但缺点是,因为不是有序的,所以哈希索引做区间查询的速度是很慢的。 你可以设想下,如果你现在要找身份证号在[ID_card_X, ID_card_Y]这个区间的所有用户,就必须全部扫描一遍了。
- 有序数组
有序数组在等值查询和范围查询场景中的性能就都非常优秀,但是有序数组索引只适用于静态存储引擎,一些不会再进行变更的数据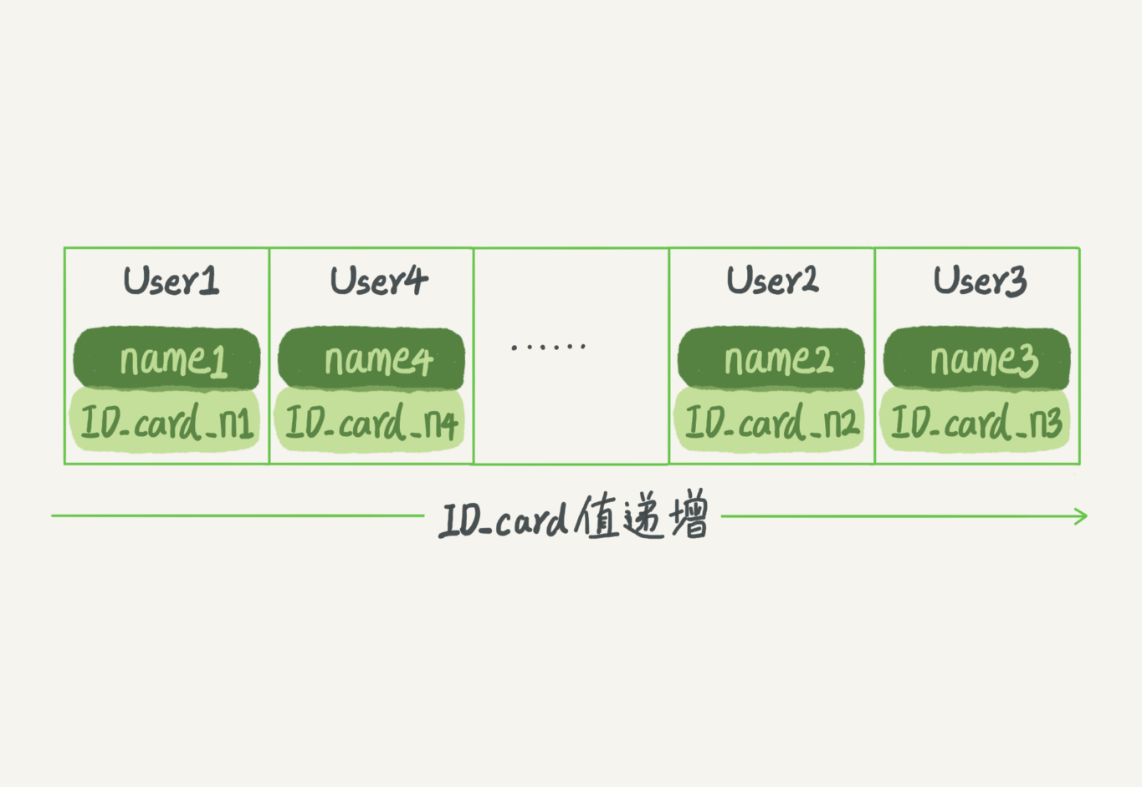
- 这里我们假设身份证号没有重复,这个数组就是按照身份证号递增的顺序保存的。这时候如果你要查 ID_card_n2 对应的名字,用二分法就可以快速得到,这个时间复杂度是 O(log(N))。 同时很显然,这个索引结构支持范围查询。你要查身份证号在[ID_card_X, ID_card_Y]区间的 User,可以先用二分法找到 ID_card_X(如果不存在 ID_card_X,就找到大于 ID_card_X 的第一个 User),然后向右遍历,直到查到第一个大于 ID_card_Y 的身份证号,退出循环。如果仅仅看查询效率,有序数组就是最好的数据结构了。但是,在需要更新数据的时候就麻烦了,你往中间插入一个记录就必须得挪动后面所有的记录,成本太高。 所以,有序数组索引只适用于静态存储引擎,比如你要保存的是 2017 年某个城市的所有人口信息,这类不会再修改的数据。搜索树
二叉搜索树
特点: 父节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的
- 数据库存储大多不适用二叉树,因为树高过高,会适用N叉树二叉搜
每一张表其实就是多个B+树,树结点的key值就是某一行的主键,value是该行的其他数据。新建索引就是新增一个B+树,查询不走索引就是遍历主B+树。- InnoDB中的索引模型:B+Tree
- 索引类型:主键索引、非主键索引
- 键索引的叶子节点存的是整行的数据(聚簇索引),非主键索引的叶子节点内容是主键的值(二级索引)
- 主键索引和普通索引的区别:主键索引只要搜索ID这个B+Tree即可拿到数据。普通索引先搜索索引拿到主键值,再到主键索引树搜索一次(回表)
- 一个数据页满了,按照B+Tree算法,新增加一个数据页,叫做页分裂,会导致性能下降。空间利用率降低大概50%。当相邻的两个数据页利用率很低的时候会做数据页合并,合并的过程是分裂过程的逆过程。
- 从性能和存储空间方面考量,自增主键往往是更合理的选择。基于主键索引和普通索引的查询有什么区别?
- 如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
- 如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
也就是说,基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询自增主键的插入数据模式下,每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。非自增主键的插入,如果是不按顺序插入,会涉及到逻辑其他记录的操作,如果当前页面满了会除非叶子节点的分裂影响性能和 效率,一般都是建议主键往往使用自增主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小有没有什么场景适合用业务字段直接做主键的呢? - 还是有的。比如,有些业务的场景需求是这样的:只有一个索引;该索引必须是唯一索引。你一定看出来了,这就是典型的 KV 场景。由于没有其他索引,所以也就不用考虑其他索引的叶子节点大小的问题。这时候我们就要优先考虑上一段提到的“尽量使用主键查询”原则,直接将这个索引设置为主键,可以避免每次查询需要搜索两棵树。
- 这里我们假设身份证号没有重复,这个数组就是按照身份证号递增的顺序保存的。这时候如果你要查 ID_card_n2 对应的名字,用二分法就可以快速得到,这个时间复杂度是 O(log(N))。 同时很显然,这个索引结构支持范围查询。你要查身份证号在[ID_card_X, ID_card_Y]区间的 User,可以先用二分法找到 ID_card_X(如果不存在 ID_card_X,就找到大于 ID_card_X 的第一个 User),然后向右遍历,直到查到第一个大于 ID_card_Y 的身份证号,退出循环。如果仅仅看查询效率,有序数组就是最好的数据结构了。但是,在需要更新数据的时候就麻烦了,你往中间插入一个记录就必须得挪动后面所有的记录,成本太高。 所以,有序数组索引只适用于静态存储引擎,比如你要保存的是 2017 年某个城市的所有人口信息,这类不会再修改的数据。搜索树

若有收获,就点个赞吧
0 人点赞
