Hystrix
雪崩
这里我们解决了服务之间的调用问题,但是有的时候系统出现问题(几乎不会了,系统上线之前应该都解决了,但是万一有没查到的bug呢)和服务调用多个服务的时候某个服务出现延时呢,这样可能因为某个服务的延迟,导致所有的请求都处于延迟状态,如果延迟到达了系统最大值,这样可能就会使系统资源耗尽,最终导致这个分布式系统都不可用,这就是雪崩现象。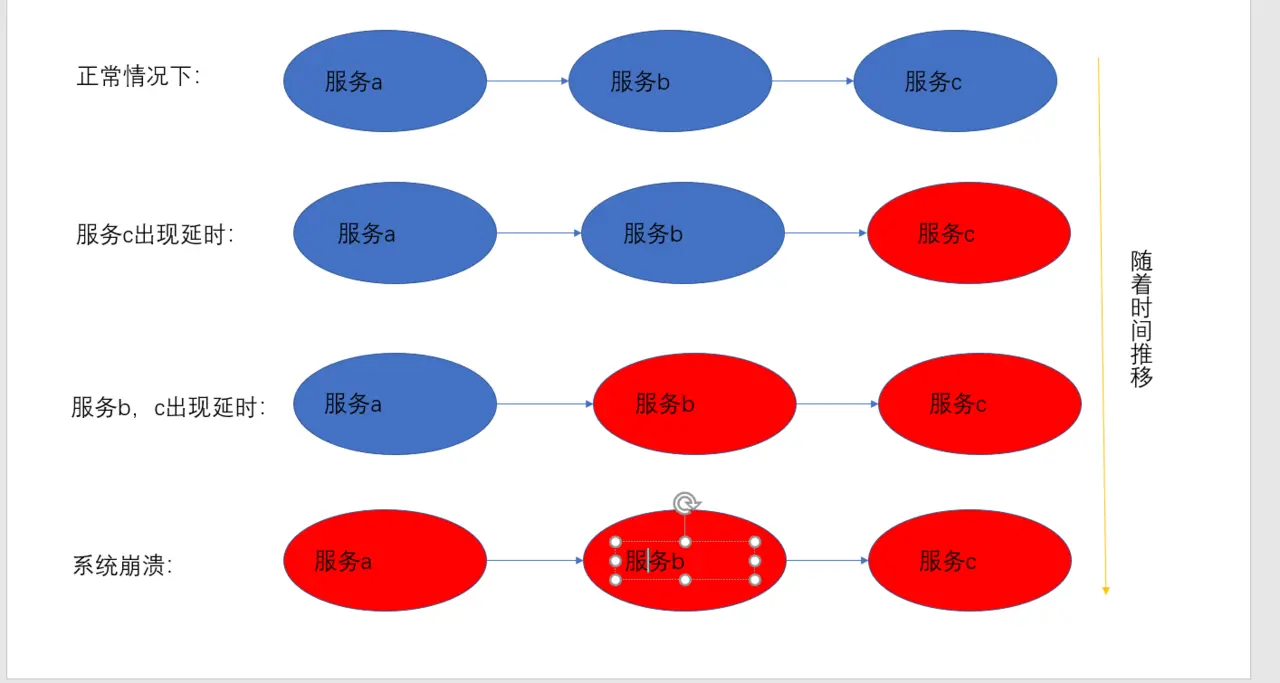 xuebeng.png
xuebeng.png
服务熔断
为了解决这个问题,我们可以通过hystrix实现在某个服务延迟的情况下,给系统返回一个可以接受的值,服务熔断,也得保证系统的可用性。我们只需要添加@HystrixCommand(commandProperties={@HystrixProperty(name = “execution.isolation.thread.timeoutInMilliseconds”,value=”3000”)},fallbackMethod = “requestError”)参数指定超时时间以及调用的方法并编写即可。不太懂可以看下下面的图,从官网摘出来的: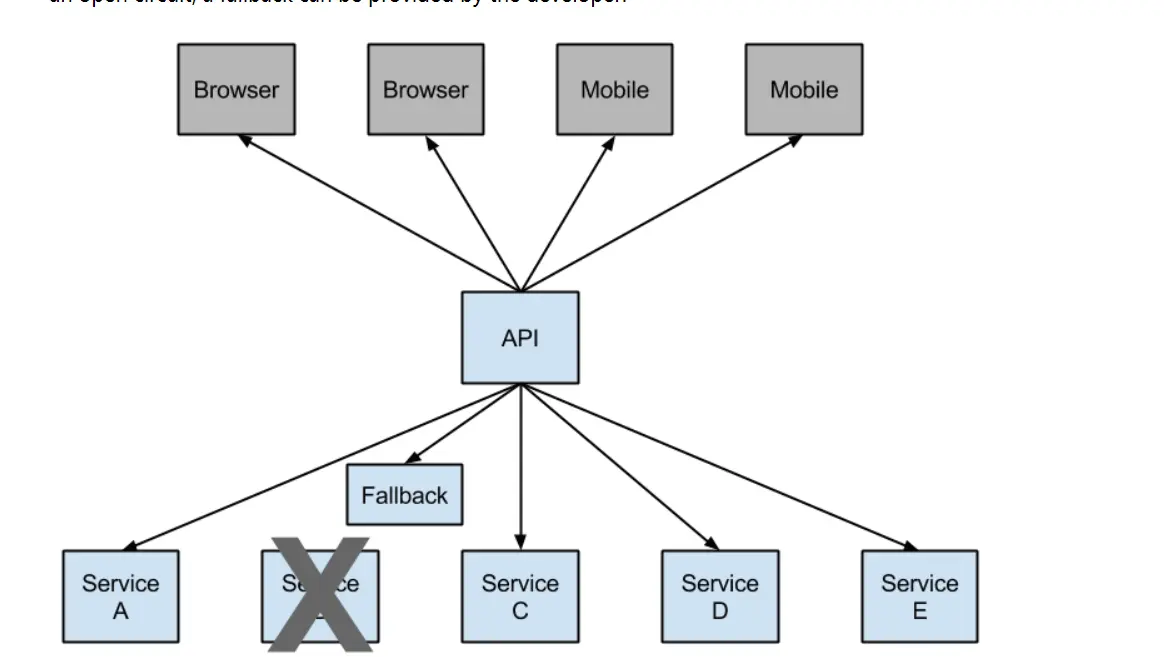 rongduanjiaoji.png
rongduanjiaoji.png
pom
1 <!-- hystrix -->2 <dependency>3 <groupId>org.springframework.cloud</groupId>4 <artifactId>spring-cloud-starter-netflix-hystrix</artifactId>5 </dependency>复制代码
代码
1package com.lytw13.demo.controller; 2import com.lytw13.demo.model.BaseResult; 3import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand; 4import com.netflix.hystrix.contrib.javanica.annotation.HystrixProperty; 5import org.springframework.beans.factory.annotation.Autowired; 6import org.springframework.web.bind.annotation.*; 7import org.springframework.web.client.RestTemplate; 8 9@RestController 10@RequestMapping("/user") 11public class UserController { 12 @Autowired 13 RestTemplate restTemplate; 14 15 @HystrixCommand(commandProperties = {@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value="3000")}, 16 fallbackMethod = "requestError" 17 ) 18 @GetMapping("getUser") 19 public BaseResult getUser(Integer id) { 20 try { 21 Thread.sleep(5000); 22 } catch (InterruptedException e) { 23 e.printStackTrace(); 24 } 25 BaseResult baseResult = restTemplate.getForObject("http://USER/user/get/"+id, BaseResult.class); 26 return baseResult; 27 } 28 29 public BaseResult requestError(Integer id){ 30 return new BaseResult(400,"服务器访问人数过多,请稍候访问",null); 31 } 32} 复制代码注意:失败调用的方法方法参数和返回值必须和原方法相同。服务降级只作用在消费端。
测试: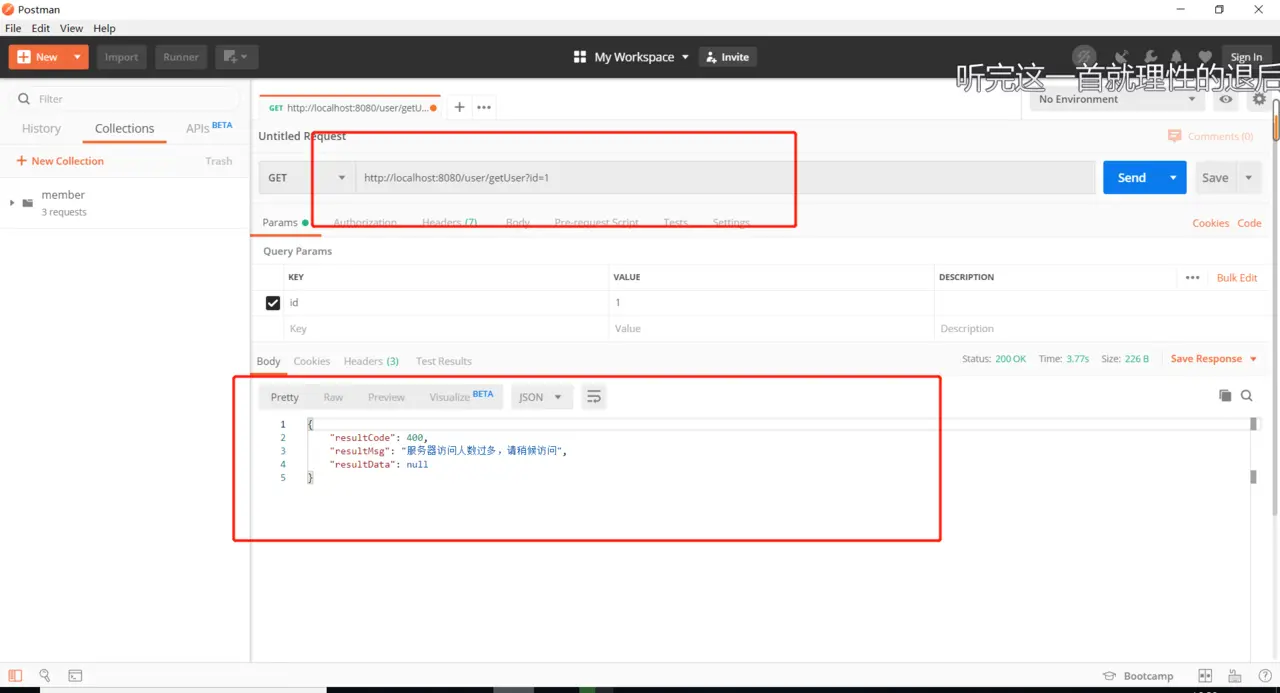 hystrix_chaoshi.png
hystrix_chaoshi.png
服务降级
理解: 系统资源不够时,系统会牺牲掉某些服务,等待资源恢复后,再重新启动那些牺牲的服务。
测试:
这里不太好演示,我们可以自己手动关闭系统某个服务,来演示系统资源不够,系统牺牲某些服务,然后调用,返回的结果是一个系统可以接受的值,但不是正确的结果;然后再启动那个服务,我们会发现,我们又能查找到对的数据了。服务降级与服务熔断区别
上面的例子属于服务熔断,服务熔断就是因为系统出现异常时,我们返回一个可以接受的值给系统,由上面可以看到,我最大等待时间是3000,实际让它等待了5000,这个时候系统就会抛出InterruptedException异常,系统会返回给系统一个可以接受的值。服务降级则是当系统资源不够,系统会牺牲掉某些服务,等待系统资源正常后,在重新启用那些关闭的服务。简单来说就是触发原因不太一样,服务熔断一般是某个服务故障引起,而服务降级一般是从整体负荷考虑。
服务降级一定会出现服务熔断,而服务熔断不一定会出现服务降级。Hystrix Board仪表盘
hystrixboard简单来说就是监控hystrix一款可视化仪表盘,可以通过图形化的界面直观的看到服务请求的时间、成功率等等,但是hystrixboard只能监控一个hystrix,为了实现多个,我们就需要Turbine了。
作者:lytw1315
链接:https://juejin.im/post/5df7342be51d4557f852c3f4
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
