6. Z 字形变换
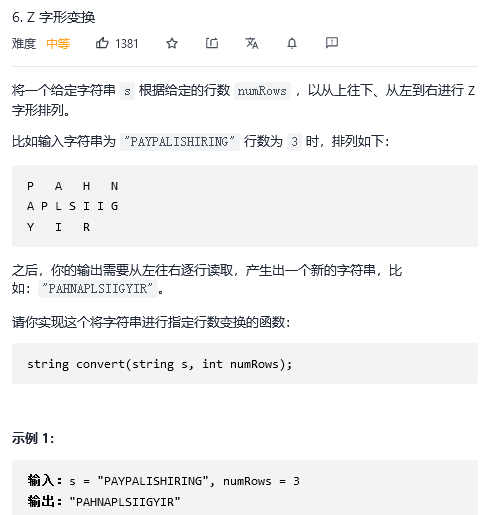
思路:对于上述例子,numRows=3, 设置3个字符串(编号为0-2)表示每一行的最终结果 然后从头开始遍历字符串s,可以看出以下结果: 字符串索引 设置的3个字符串编号 0 0 1 1 2 2 3 1 4 0 5 1 … … 可以看出随着字符传索引的增加,字符串编号先增大到3然后减少到1,然后再增到大3,反复循环,增大的转折点是row=0, 减少的转折点是row=2, 可以设置一个flag变量来控制下标是增大还是减少
class Solution {public:string convert(string s, int numRows) {if(numRows==1)return s;vector<string> rows(numRows);int flag=-1,i=0;for(char c:s){rows[i]+=c;if(i==0||i==numRows-1)//i转向增大还是减小flag=-flag;i+=flag;}string ans;for(string row:rows)ans+=row;return ans;}};//O(n)//O(n)
class Solution {
public String convert(String s, int numRows) {
if(numRows==1)
return s;
ArrayList<StringBuilder> rows=new ArrayList<>();
for(int i=0;i<numRows;i++)
rows.add(new StringBuilder());
int i=0,flag=-1;
for(int j=0;j<s.length();j++)
{
char c=s.charAt(j);
rows.get(i).append(c);
if(i==0||i==numRows-1)
flag=-flag;
i+=flag;
}
StringBuilder sb=new StringBuilder();
for(StringBuilder row:rows)
{
sb.append(row);
}
return sb.toString();
}
}
//O(n)
//O(n)
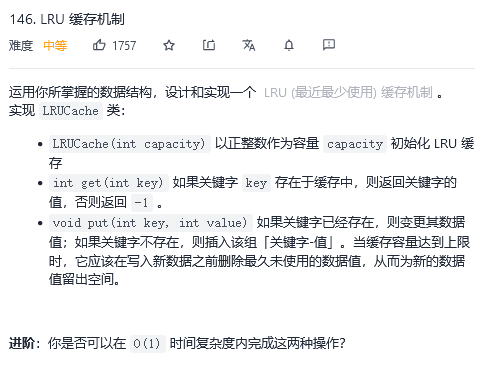
146. LRU 缓存机制
使用LinedHashMap这种数据结构可以很快实现LRU
class LRUCache {
int capacity;
LinkedHashMap<Integer,Integer> cache;
public LRUCache(int capacity) {
this.capacity=capacity;
cache=new LinkedHashMap<>();
}
public int get(int key) {
if(cache.containsKey(key))//key在缓存中
{
int oldVal=cache.get(key);//获取key对应的value
cache.remove(key);//删除旧的
cache.put(key,oldVal);//放到新的位置
return oldVal;//返回key对应的value
}
return -1;
}
public void put(int key, int value) {
if(cache.containsKey(key))
{
cache.remove(key);//从原来的位置删除
}
else if(cache.size()>=capacity)
{
cache.remove(cache.keySet().iterator().next());//删除第一个 即最老的
}
cache.put(key,value);//放到新的位置
}
}
//O(1)
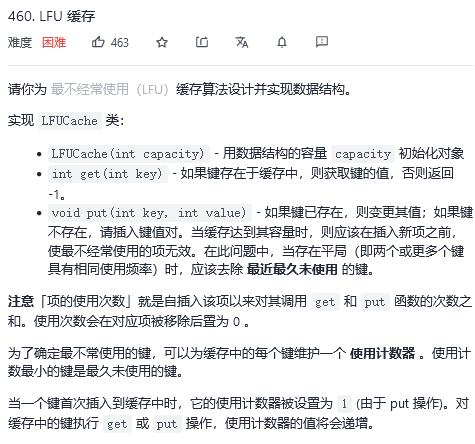
460. LFU 缓存
class LFUCache {
HashMap<Integer,Integer> key2val;//存放key-value
HashMap<Integer,Integer> key2freq;//存放key-freq
HashMap<Integer,LinkedHashSet<Integer>> freq2keys;//一个freq可能对应多个key
int capacity;
int minFreq;
public LFUCache(int capacity) {
key2val=new HashMap<>();
key2freq=new HashMap<>();
freq2keys=new HashMap<>();
this.capacity=capacity;
this.minFreq=0;
}
public int get(int key) {
//不含有key 返回-1
if(!key2val.containsKey(key))
return -1;
increaseFreq(key);//对应key使用的次数+1
return key2val.get(key);//返回key对应的val
}
public void put(int key, int value) {
if(capacity<=0)//容量小于等于0直接返回
return;
if(key2val.containsKey(key))//key已经存在 直接更新
{
key2val.put(key,value);
increaseFreq(key);
return;
}
if(key2val.size()>=capacity)//容量达到最大
{
removeMinFreqKey();//移除最少使用的
}
//以下操作是新加的 不需要使用 increaseFreq
key2val.put(key,value);//放入key-value
key2freq.put(key,1);//放入key-freq 新加进来的 freq=1
freq2keys.putIfAbsent(1,new LinkedHashSet<>());//如果之前没有freq=1的就新建立一个
freq2keys.get(1).add(key);//freq为1对应的set中加入key
minFreq=1;//由于新加进去了一个key 所以此时的最少使用次数是1
}
public void removeMinFreqKey()
{
LinkedHashSet<Integer> keySet=freq2keys.get(minFreq);//获取最小的freq对应的set
int deleteKey=keySet.iterator().next();//set中可能有多个元素 当次数一样时 根据时间选择 第一个是最早加进来的
keySet.remove(deleteKey);//移除待删除的key
if(keySet.isEmpty())//删除完之后set为空
{
freq2keys.remove(minFreq);//删除这条freq-set映射
}
key2val.remove(deleteKey);//kv表更新
key2freq.remove(deleteKey);//kf表更新
}
public void increaseFreq(int key)
{
int freq=key2freq.get(key);//获得key对应的freq
key2freq.put(key,freq+1);//次数+1
freq2keys.get(freq).remove(key);//删除原来对应freq-set中的set中的key
freq2keys.putIfAbsent(freq+1,new LinkedHashSet<>());//fk表 如果freq+1对应的set不存在 则新建一个set
freq2keys.get(freq+1).add(key);//该set中加入key
if(freq2keys.get(freq).isEmpty())//如果原来的freq对应的set删除了key之后为空
{
freq2keys.remove(freq);
if(freq==minFreq)//增加的key使用的次数最少并且只有1个 更新minFreq
minFreq=freq+1;
}
}
}
380. O(1) 时间插入、删除和获取随机元素

题目要求插入、删除、查找的复杂度都是O(1), 对于数组而言,在末尾插入时间复杂度是O(1),获取一个元素自然是O(1),但是对于删除数组如何达到O(1)的复杂度呢? 假设现在我们要删除下标为index的元素,可以采用以下的思路:先将arr[index]和数组的最后一个元素交换,然后删除数组的最后一个元素即可(交换和删除数组的最后后1个元素的时间复杂度都是O(1))
class RandomizedSet {
Random random;
ArrayList<Integer> arr;//动态数组
HashMap<Integer,Integer> valToIndex;//map存放数组元素和下标的映射
public RandomizedSet() {
random=new Random();
arr=new ArrayList<>();
valToIndex=new HashMap<>();
}
public boolean insert(int val) {
if(valToIndex.containsKey(val))
return false;
arr.add(val);//数组添加元素
valToIndex.put(val,arr.size()-1);//map添加键值对
return true;
}
public boolean remove(int val) {
if(!valToIndex.containsKey(val))
return false;
int lastVal=arr.get(arr.size()-1);//获取数组的最后一个元素
int index=valToIndex.get(val);//获得待删除元素的下标
arr.set(index,lastVal);//将arr[index]的值换成lastVal
valToIndex.put(lastVal,index);//map更新键值对
arr.remove(arr.size()-1);//数组删除最后一个元素
valToIndex.remove(val);//map删除之前的键值对
return true;
}
public int getRandom() {
int x=random.nextInt(arr.size());//随机返回的下标
return arr.get(x);
}
}
//O(1)
//O(n)
710. 黑名单中的随机数

将区间分为两个部分,[0,sz-1]和[sz,n-1] sz是白名单中数字的大小 如果黑名单中的数字在[0,sz-]范围内,则将其映射到[sz,n-1]中不是黑名单数的位置
class Solution {
HashMap<Integer,Integer> map=new HashMap<>();
Random random=new Random();
int sz;
public Solution(int n, int[] blacklist) {
int sz=n-blacklist.length;//不在黑名单中的元素个数
this.sz=sz;
//[0,sz-1] 白名单数 [sz,N-1] 黑名单数
//如果blacklist中的数字在[0,sz-1]范围内 则建立一个到[sz,N-1]的映射 映射的数字不是黑名单中的数
for(int num:blacklist)
map.put(num,100);//随意赋值 表示这些num是黑名单中的数
int last=n-1;//最后一个元素的下标
for(int num:blacklist)
{
if(num>=sz)//数字在黑名单内
continue;
while(map.containsKey(last))//如果位置last是黑名单中的数 则继续寻找 直到找到一个不是黑名单的数字
last--;
map.put(num,last);//黑名单中的数映射到白名单中的数 第一次随意赋的值100会被更新
last--;//last位置使用过 减1
}
}
public int pick() {
int index=random.nextInt(sz);
if(map.containsKey(index))//映射到了黑名单中的数 则返回黑名单中的数对应的映射
return map.get(index);
return index;//没有映射到黑名单中的数 则直接返回数字
}
}
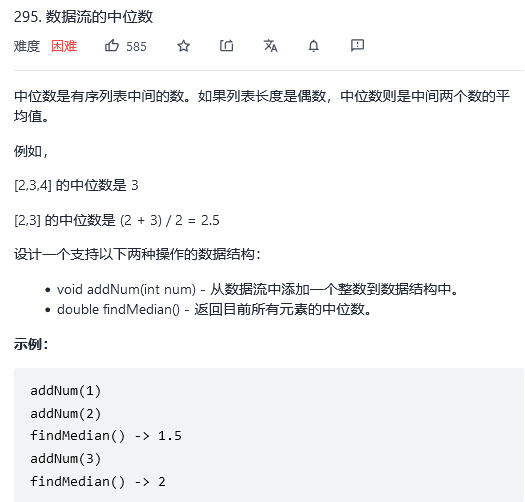
295. 数据流的中位数
采用两个优先级队列,小顶堆保存较大的一半元素,大顶堆保存较小的一半元素
class MedianFinder {
PriorityQueue<Integer> minHeap;
PriorityQueue<Integer> maxHeap;
public MedianFinder() {
minHeap=new PriorityQueue<>();
maxHeap=new PriorityQueue<>((a,b)->b-a);
}
public void addNum(int num) {
//假设小顶堆元素较多
if(minHeap.size()<=maxHeap.size())//需要给小顶堆添加元素
{
//1. 当需要给小顶堆添加元素并且maxHeap为空时 说明minHeap为空 此时直接将元素加入minHeap
//2. num>=maxHeap.peek() 说明num属于较大的一半 直接加入
if(maxHeap.isEmpty()||num>=maxHeap.peek())
{
minHeap.offer(num);
}
else//num不属于较大的一半 不能直接加入小顶堆 先加入大顶堆“过滤”一下
{
maxHeap.offer(num);
minHeap.offer(maxHeap.poll());
}
}
else if(minHeap.size()>maxHeap.size())
{
if(num<=minHeap.peek())
{
maxHeap.offer(num);
}
else
{
minHeap.offer(num);
maxHeap.offer(minHeap.poll());
}
}
}
public double findMedian() {
if(minHeap.size()>maxHeap.size())
return minHeap.peek();
return (minHeap.peek()+maxHeap.peek())/2.0;
}
}
// addNum函数的时间复杂度O(logn) findMedian函数的时间复杂度O(1)
// O(n)

若有收获,就点个赞吧
0 人点赞
