Apache Kafka 是一款开源的消息引擎系统, 也是一个分布式流处理平台(Distributed Streaming Platform)
- 处理实时数据提供一个统一、高吞吐、低延迟的平台。
- 它使用的是纯二进制的字节序列, 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
- 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- Scale out:支持在线水平扩展。
高性能缘由
- 并行处理
- 批处理
- 顺序 IO
- 数据压缩
- 零拷贝
- Page Cache
Kafka功能
削峰填谷、异步通信、业务解耦、混沌磐涅
KafKa传输模型
Kfaka有两种传输模型,分别是基于一对一、多对多的思想。
- 一对一:一般也称之为消息队列模型,系统 A 发送的消息只能被系统 B 接收,其他任何系统都不能读取 A 发送的消息。
- 多对多:一般称之为发布订阅模型。与上面不同的是,它有一个主题(Topic)的概念,该模型也有发送方和接收方,只不过提法不同。发送方也称为发布者(Publisher)接收方称为订阅者(Subscriber)。和点对点模型不同的是,这个模型可能存在多个发布者向相同的主题发送消息,而订阅者也可能存在多个,它们都能接收到相同主题的消息。
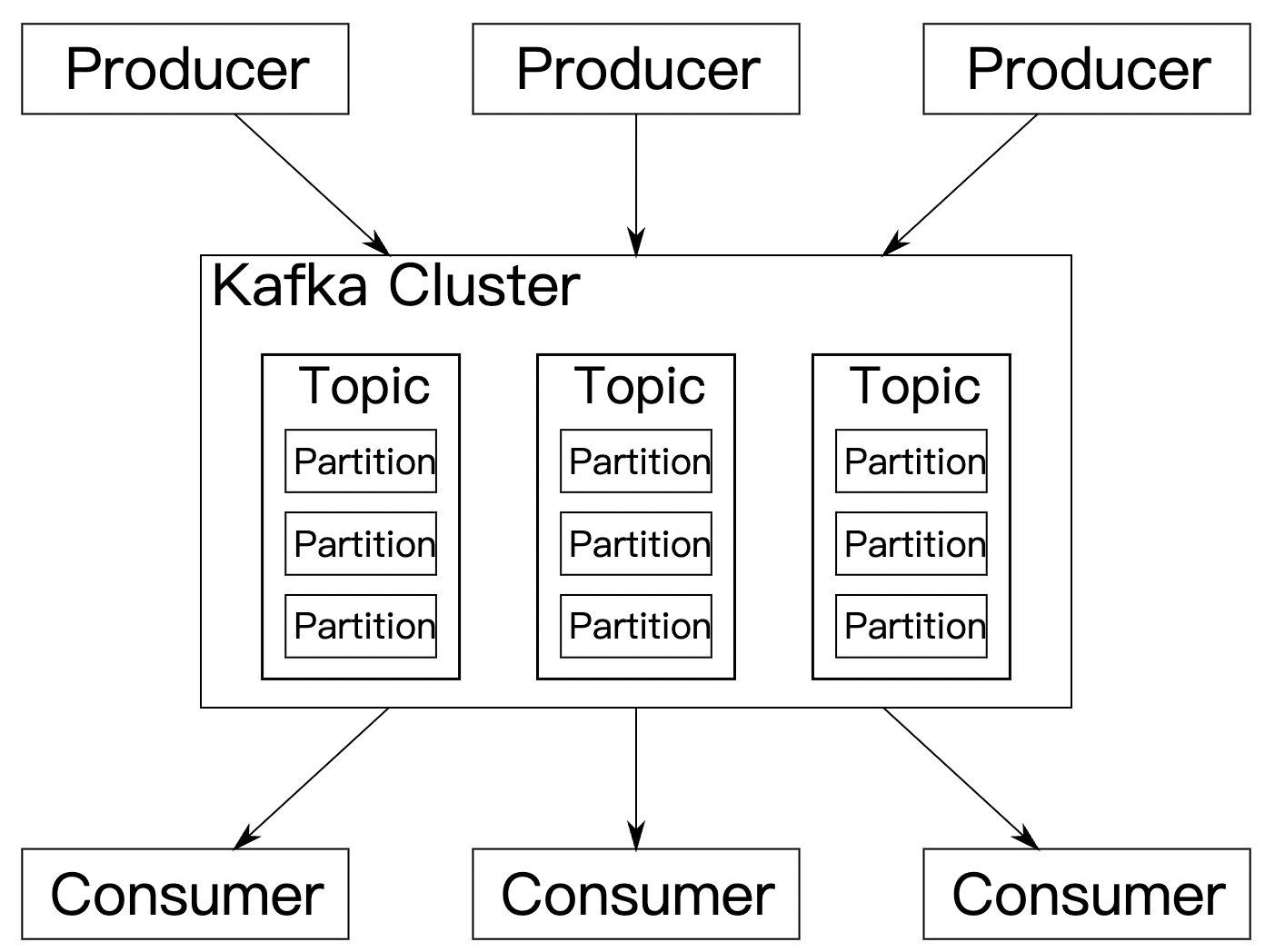
Kafka术语
客户端
- 生产者(Producer): 向主题发布消息的客户端应用程序,生产者程序通常持续不断地向一个或多个主题发送消息。
- 消费者(Consumer): 订阅这些主题消息的客户端应用程序。和生产者类似,消费者也能够同时订阅多个主题的消息。
- 消费者组(Consumer Group):多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
- 消费者实例(Consumer Instance): 运行消费者应用的进程,也可以是一个线程。
message
- 主题(Topic):在 Kafka 中,发布订阅的对象是主题(Topic),你可以为每个业务、每个应用甚至是每类数据都创建专属的主题。
- 分区(Partitioning):将每个主题划分成多个分区(Partition),每个分区是一组有序的消息日志。生产者生产的每条消息只会被发送到一个分区中
- 消息(Record):Kafka 是消息引擎,这里的消息就是指 Kafka 处理的主要对象。
服务端
- Broker: Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成,Broker 负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个 Broker进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。
- Replication: 把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replica)副本的数量是可以配置的,这些副本保存着相同的数据,但却有不同的角色和作用。
- Kafka 定义了两类副本:
- 领导者副本(Leader Replica):对外提供服务,这里的对外指的是与客户端程序进行交互;
- 追随者副本(Follower Replica):被动地追随领导者副本,不能与外界进行交互。
- Kafka 定义了两类副本:
- 重平衡(Rebalance): 消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
- 消费者位移(Consumer Offset): 表征消费者消费进度,每个消费者都有自己的消费者位移。

消息系统必要性
- 解耦:消息系统在处理过程中插入了一个隐含的,基于数据接口, 两边的处理过程都要实现这一接口.这允许独立拓展或修改两边的处理过程. 只要确保他们遵循同样的接口约束. 而基于消息发布订阅的机制, 可以联动多个业务下流子系统,能够不侵入的情况下的情况下分布编排和开发,来保证数据一致性
- 冗余:有些情况下,处理数据的过程中会失败.除非数据被持久化,否则将造成丢失.消息队列吧数据进行持久化直到已经完全被处理, 通过这一方式可规避数据丢失,许多消息队列所采用的”插入-获取-删除”的范式,把一个消息从队列中删除之前,需要处理系统明确指出该消息已经被完全处理完毕, 从而确保你的数据被安全的保存直到使用完毕
- 拓展:消息解耦了处理过程, 所以增大消息入队和处理的频率是简单的,只需要在对应的端加速处理即可. 无需修改代码,修改参数,扩展非常简单
- 灵活 & 峰值处理能力: 在访问量剧增的情况下, 应用仍然需要继续发挥作用,但这样的突发流量并不常见; 如果对此特定时间为标准投入资源,无疑是巨大的浪费. 使用消息队列能使关键组件顶住突发的压力,而不是因为突发的超负荷的请求完全崩溃
- 可恢复性:系统的一部分组件失效时,不会影响到整个系统. 消息队列降低了进程间的耦合度, 即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在恢复后被处理
- 顺序:在大多使用厂家下,数据处理的顺序都很重要. 大部分消息队列本来就是排序的,并且能保证数据按照特定的顺序来处理. kafka保证一个Partition内的消息有序性
- 缓冲:在任何重要的系统中,都会有需要不同的处理时间因素, 消息队列通过一个缓冲层来帮助业务最高效的执行-写入队列的处理尽可能的快速. 缓冲有助于控制和优化数据流和系统的速度
- 异步:很多时候并不需要立即处理消息,而消息队列提供了异步处理机制, 允许将消息放入到队列,但不立即处理它. 只需要到一定的时间点处理即可
kafka发行版本与版本号
Apache Kafka
Apache Kafka 是最“正宗”的 Kafka,也应该最熟悉的发行版。
自 Kafka 开源伊始,它便在 Apache 基金会孵化并最终毕业成为顶级项目,它也被称为社区版 Kafka。咱们专栏就是以这个版本的 Kafka作为模板来学习的。更重要的是,它是后面其他所有发行版的基础。也就是说,后面提到的发行版要么是原封不动地继承了 Apache Kafka,要么是在此之上扩展了新功能,总之 Apache Kafka 是我们学习和使用 Kafka 的基础
- 优: 对 Apache Kafka 而言,它现在依然是开发人数最多、版本迭代速度最快的 Kafka。在 2018 年度 Apache 基金会邮件列表开发者数量最多的 Top 5 排行榜中,Kafka 社区邮件组排名第二位。如果你使用 ApacheKafka 碰到任何问题并提交问题到社区,社区都会比较及时地响应你。这对于我们 Kafka 普通使用者来说无疑是非常友好的。
- 劣: Apache Kafka 的劣势在于它仅仅提供最最基础的组件,特别是对于前面提到的 Kafka Connect 而言,社区版 Kafka只提供一种连接器,即读写磁盘文件的连接器,而没有与其他外部系统交互的连接器,在实际使用过程中需要自行编写代码实现,这是它的一个劣势。
另外 Apache Kafka 没有提供任何监控框架或工具。显然在线上环境不加监控肯定是不可行的,你必然需要借助第三方的监控框架实现对 Kafka 的监控。好消息是目前有一些开源的监控框架可以帮助用于监控 Kafka(比如 Kafka manager)。
总而言之,如果仅仅需要一个消息引擎系统亦或是简单的流处理应用场景,同时需要对系统有较大把控度,那么推荐你使用 Apache Kafka。
Confluent Kafka
它主要从事商业化 Kafka 工具开发,并在此基础上发布了 Confluent Kafka。Confluent Kafka 提供了一些 Apache Kafka 没有的高级特性,
比如跨数据中心备份、Schema 注册中心以及集群监控工具等。
- 优: Confluent Kafka 目前分为免费版和企业版两种。前者和 Apache Kafka 非常相像,除了常规的组件之外,免费版还包含 Schema 注册中心和 REST proxy 两大功能。前者是帮助你集中管理 Kafka 消息格式以实现数据前向 / 后向兼容;后者用开放 HTTP 接口的方式允许你通过网络访问 Kafka 的各种功能,这两个都是 Apache Kafka 所没有的。除此之外,免费版包含了更多的连接器,它们都是 Confluent 公司开发并认证过的,可以免费使用它们。至于企业版,它提供的功能就更多了。最有用的当属跨数据中心备份和集群监控两大功能了。多个数据中心之间数据的同步以及对集群的监控历来是 Kafka 的痛点,Confluent Kafka 企业版提供了强大的解决方案帮助你“干掉”它们
- 劣: Confluent 公司暂时没有发展国内业务的计划,相关的资料以及技术支持都很欠缺,很多国内 Confluent Kafka 使用者甚至无法找到对应的中文文档,因此目前 Confluent Kafka 在国内的普及率是比较低的。
如果需要用到 Kafka 的一些高级特性,那么推荐使用 Confluent Kafka。
Cloudera/Hortonworks Kafka
Cloudera 提供的 CDH 和 Hortonworks 提供的 HDP 是非常著名的大数据平台,里面集成了目前主流的大数据框架,能够帮助用户实现从分布式存储、集群调度、流处理到机器学习、实时数据库等全方位的数据处理。
很多创业公司在搭建数据平台时首选就是这两个产品。不管是 CDH 还是 HDP 里面都集成了 Apache Kafka,因此把这两款产品中的 Kafka 称为 CDH Kafka 和 HDP Kafka。
- 优: 大数据平台天然集成了 Apache Kafka,通过便捷化的界面操作将 Kafka 的安装、运维、管理、监控全部统一在控制台中。所有的操作都可以在前端 UI 界面上完成,而不必去执行复杂的 Kafka 命令。
- 劣: 这样做的结果是直接降低了你对 Kafka 集群的掌控程度。另一个弊端在于它的滞后性。由于它有自己的发布周期,因此是否能及时地包含最新版本的 Kafka 就成为了一个问题。比如 CDH 6.1.0 版本发布时 Apache Kafka 已经演进到了 2.1.0 版本,但 CDH 中的 Kafka 依然是 2.0.0版本,显然那些在 Kafka 2.1.0 中修复的 Bug 只能等到 CDH 下次版本更新时才有可能被真正修复。
| kafka版本 | 优势 | 不足 |
|---|---|---|
| Apache Kafka,也称社区版 Kafka | 优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度 | 缺陷在于仅提供基础核心组件,缺失一些高级的特性。 |
| Confluent Kafka,Confluent 公司提供的 Kafka | 优势在于集成了很多高级特性且由 Kafka 原班人马打造,质量上有保证 | 缺陷在于相关文档资料不全,普及率较低,没有太多可供参考的范例。 |
| CDH/HDP Kafka,大数据云公司提供的 Kafka,内嵌 Apache Kafka | - 优势在于操作简单,节省运维成本 | 缺陷在于把控度低,演进速度较慢 |
kafka 版本号
Kafka 版本命名

其中前半部分为 Scala语言版本,后才为kafka版本,如上图所示
他们均符合x.y.z 命名规范
Kafka 版本演进
Kafka 目前总共演进了 7 个大版本,分别是 0.7.x、0.8.x、0.9.x、0.10.x、0.11.x、1.x 、 2.x,3.x 其中的小版本和 Patch 版本很
多。
本文书写 时最新版本为 3.10(2022-03-29)
0.7.x版本
很老的Kafka版本,它只有基本的消息队列功能,连消息副本机制都没有,不建议使用。
0.8.x版本
两个重要特性,
一个是Kafka 0.8.0增加了副本机制,
另一个是Kafka 0.8.2.0引入了新版本Producer API。
新旧版本Producer API如下:
1//旧版本Producer2kafka.javaapi.producer.Producer<K,V>34//新版本Producer5org.apache.kafka.clients.producer.KafkaProducer<K,V>
与旧版本相比,新版本ProducerAPI有点不同,一是连接Kafka方式上,旧版本的生产者及消费者API连接的是Zookeeper,而新版本则连接的是Broker;二是新版Producer采用异步方式发送消息,比之前同步发送消息的性能有所提升。但此时的新版ProducerAPI尚不稳定,不建议生产使用。
0.9.x版本
Kafka 0.9 是一个重大的版本迭代,增加了非常多的新特性,主要体现在三个方面:
- 安全方面:在0.9.0之前,Kafka安全方面的考虑几乎为0。Kafka 0.9.0 在安全认证、授权管理、数据加密等方面都得到了支持,包括支持Kerberos等。
- 新版本Consumer API:Kafka 0.9.0 重写并提供了新版消费端API,使用方式也是从连接Zookeeper切到了连接Broker,但是此时新版ConsumerAPI也不太稳定、存在不少Bug,生产使用可能会比较痛苦;而0.9.0版本的Producer API已经比较稳定了,生产使用问题不大。
- Kafka Connect:Kafka 0.9.0 引入了新的组件 Kafka Connect ,用于实现Kafka与其他外部系统之间的数据抽取。
0.10.x版本
Kafka 0.10 是一个重要的大版本,因为Kafka 0.10.0.0 引入了 Kafka Streams,使得Kafka不再仅是一个消息引擎,而是往一个分布式流处理平台方向发展。0.10 大版本包含两个小版本:0.10.1 和0.10.2,它们的主要功能变更都是在 Kafka Streams 组件上。
值得一提的是,自 0.10.2.2 版本起,新版本 Consumer API 已经比较稳定了,而且 Producer API 的性能也得到了提升,因此对于使用 0.10.x 大版本的用户,建议使用或升级到 Kafka 0.10.2.2版本。
0.11.x版本
Kafka 0.11 是一个里程碑式的大版本,主要有两个大的变更,一是Kafka从这个版本开始支持 Exactly-Once 语义即精准一次语义,主要是实现了Producer端的消息幂等性,以及事务特性,这对于Kafka流式处理具有非常大的意义。
另一个重大变更是Kafka消息格式的重构,Kafka 0.11主要为了实现Producer幂等性与事务特性,重构了投递消息的数据结构。这一点非常值得关注,因为Kafka0.11之后的消息格式发生了变化,所以我们要特别注意Kafka不同版本间消息格式不兼容的问题。
1.x版本
Kafka 1.x 更多的是Kafka Streams方面的改进,以及Kafka Connect的改进与功能完善等。但仍有两个重要特性,一是Kafka 1.0.0实现了磁盘的故障转移,当Broker的某一块磁盘损坏时数据会自动转移到其他正常的磁盘上,Broker还会正常工作,这在之前版本中则会直接导致Broker宕机,因此Kafka的可用性与可靠性得到了提升;
二是Kafka 1.1.0开始支持副本跨路径迁移,分区副本可以在同一Broker不同磁盘目录间进行移动,这对于磁盘的负载均衡非常有意义。
2.x版本
Kafka 2.x 更多的也是Kafka Streams、Connect方面的性能提升与功能完善,以及安全方面的增强等。一个使用特性,Kafka2.1.0开始支持ZStandard的压缩方式,提升了消息的压缩比,显著减少了磁盘空间与网络io消耗。
3.x版本
- 不再支持 Java 8 和 Scala 2.12
- Kafka Raft 支持元数据主题的快照以及自我管理的仲裁中的其他改进
- 为默认启用的 Kafka 生产者提供更强的交付保证
- 弃用消息格式 v0 和 v1
- OffsetFetch 和 FindCoordinator 请求的优化
- 更灵活的 Mirror Maker 2 配置和 Mirror Maker 1 的弃用
- 能够在 Kafka Connect 中的一次调用中重新启动连接器的任务
- 现在默认启用连接器日志上下文和连接器客户端覆盖
- Kafka Streams 中时间戳同步的增强语义
- 改进了 Stream 的 TaskId 的公共 API
- Kafka 中的默认 serde 变为 null
Kafka版本建议
- 遵循一个基本原则,Kafka客户端版本和服务端版本应该保持一致,否则可能会遇到一些问题。
- 根据是否用到了Kafka的一些新特性来选择,假如要用到Kafka生产端的消息幂等性,那么建议选择Kafka 0.11 或之后的版本。
- 选择一个自己熟悉且稳定的版本,如果说没有比较熟悉的版本,建议选择一个较新且稳定、使用比较广泛的版本。
Kafka 部署
资源规划
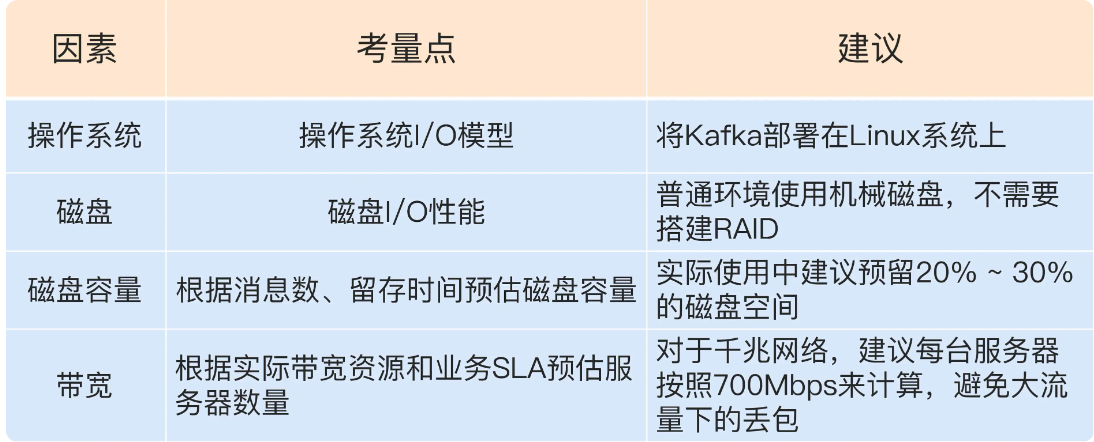
磁盘容量
磁盘容量需要考虑几个因素:新增消息数、消息留存时间、平均消息大小、备份数、是否启用压缩
$ 计算公式: 新增消息数 信息留存实践 平均消息大小 备份数 压缩率 * 110\% (索引及其他数据) $
假设有个业务每天需要向 Kafka 集群发送 1 亿条消息,每条消息保存两份以防止数据丢失,另外消息默认保存两周时间。现在假设消息的平均大小是 1KB,那么你能说出你的 Kafka 集群需要为这个业务预留多少磁盘空间吗?
每天 1 亿条 1KB 大小的消息,保存两份且留存两周的时间,那么总的空间大小就等于$ 10 ^ 8 * 1024 KB = 0.2 TB $
加上索引以及其他类型数据 在原有基础上增加 10%,那就是0.22TB
保留两周:$ 0.22TB * 14 = 3.08 TB $
压缩率为80%: $ 3.08 * 0.8 = 2.464 TB ≈ 2.5 TB $
保险起见建议预留3TB的存储空间
网络带宽
对于 Kafka 这种通过网络大量进行数据传输的框架而言,带宽特别容易成为瓶颈。事实上,在接触的真实案例当中,带宽资源不足导致 Kafka 出现性能问题的比例至少占 60% 以上。
当规划带宽时到不如说是部署kafka服务器数量
通常情况下只能假设 Kafka 会用到 70% 的带宽资源,因为总要为其他应用或进程留一些资源。根据实际使用经验,超过 70% 的阈值就有网络丢包的可能性了,故 70% 的设定是一个比较合理的值,也就是说单台 Kafka
服务器最多也就能使用大约 700Mb 的带宽资源。
稍等,这只是它能使用的最大带宽资源,你不能让 Kafka 服务器常规性使用这么多资源,故通常要再额外预留出 2/3 的资源,即单台服务器使用带宽 700Mb / 3 ≈ 240Mbps。需要提示的是,这里的 2/3
其实是相当保守的,你可以结合你自己机器的使用情况酌情减少此值。
好了,有了 240Mbps,我们就可以计算 1 小时内处理 1TB 数据所需的服务器数量了。根据这个目标,我们每秒需要处理 2336Mb 的数据,除以 240,约等于 10 台服务器。如果消息还需要额外复制两份,那么总的服务器台数还要乘以
3,即 30 台。
配置
config├── connect-console-sink.properties├── connect-console-source.properties├── connect-distributed.properties├── connect-file-sink.properties├── connect-file-source.properties├── connect-log4j.properties├── connect-mirror-maker.properties├── connect-standalone.properties├── consumer.properties├── kraft│ ├── README.md│ ├── broker.properties│ ├── controller.properties│ └── server.properties├── log4j.properties├── producer.properties├── server.properties├── tools-log4j.properties├── trogdor.conf└── zookeeper.properties
JVM 参数与垃圾回收算法
Kafka 服务器端代码是用 Scala 语言编写的,但终归还是会编译成 .Class 文件在 JVM 上运行,因此 JVM 参数设置对于 Kafka 集群的重要性不言而喻。
JVM 端设置,堆大小这个参数至关重要,无脑通用的建议:将 JVM 堆大小设置成 6GB
垃圾回收器的设置,也就是平时常说的 GC 设置。
手动设置使用 G1 收集器。在没有任何调优的情况下,G1 表现得要比 CMS 出色,主要体现在更少的 Full GC,需要调整的参数更少等,所以使用 G1 就好了。
- KAFKA_HEAP_OPTS:指定堆大小。
- KAFKA_JVM_PERFORMANCE_OPTS:指定 GC 参数。
export KAFKA_HEAP_OPTS=--Xms6g --Xmx6gexport KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=truekafka-server-start.sh ${KAFKA_HOME}/config/server.properties
操作系统参数
通常情况下,Kafka 并不需要设置太多的 系统参数.下面这几个在此较为重要:
- 文件描述符限制:比如ulimit -n 1000000
- 文件系统类型: 根据官网的测试报告,XFS 的性能要强于 ext4,所以生产环境最好还是使用 XFS甚至是ZFS。
- swap:建议将 swappniess 配置成一个接近 0 但不为 0 的值,比如 1。
- 提交时间:适当的增加提交间隔来降低物理磁盘的写操作
部署
# 安装jdksudo yum group install -y "development tools"sudo yum install -y java-1.8.0-openjdk.x86_64# 下载kafkawget -c https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.1.0/kafka_2.13-3.1.0.tgz# 解压缩tar -zxf kafka_2.13-3.1.0.tgz -C /usr/local# 配置环境变量# kafka env configexport KAFKA_HOME=/usr/local/kafka_2.13-3.1.0export KAFKA_BIN=${KAFKA_HOME}/binexport PATH=${KAFKA_BIN}:PATHsource /etc/profile# 初始化kafka-storage.sh format -c ${KAFKA_HOME}/config/kraft/server.properties -t `kafka-storage.sh random-uuid`# 启动服务kafka-server-start.sh ${KAFKA_HOME}/config/kraft/server.properties
验证
# 创建quickstart-events主题kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
Kafka监控工具
GitHub - didi/KnowStreaming: 一站式云原生实时流数据平台,通过0侵入、插件化构建企业级Kafka服务,极大降低操作、存储和管理实时流数据门槛
GitHub - jmxtrans/jmxtrans: jmxtrans
GitHub - yahoo/CMAK: CMAK is a tool for managing Apache Kafka clusters
GitHub - provectus/kafka-ui: Open-Source Web UI for Apache Kafka Management

若有收获,就点个赞吧
0 人点赞
