lambda表达式
- lambda表达式是Java8引入的极为重要的新特性。
引入lambda表达式的原因
由于Java面向对象的特性,在引入lambda表达式之前,将一个方法作为参数传递并不容易,因为需要构造包含这个方法的类的实例。
public class MyClass {public static void main(String[] args) {Integer[] a = {1, 5, 3, 2, 4};Arrays.sort(a, new Comparator<Integer>() {@Overridepublic int compare(Integer o1, Integer o2) {return o1 < o2 ? 1 : -1;}});System.out.println(Arrays.toString(a)); //out: [5, 4, 3, 2, 1]}}
lambda表达式就是用于高效地传递方法的
lambda表达式基本语法
lambda表达式实际上就是一个代码块,用于代替之前完整的方法传递,格式如下
(参数1, 参数2...) -> 表达式\代码块
- 当代码块中只有一条语句,那么可以省略代码块的大括号,这样就变为了表达式
- 如果表达式是一条return语句,那么return必须省略
对于上面的例子,传入的
compare(Integer o1, Integer o2)方法可以写为下述形式(Integer o1, Integer o2) -> o1 < o2 ? 1 : -1
即使lambda表达式不需要参数,仍然要提供空括号,就像无参数的方法一样
如果编译器可以推导出lambda表达式参数的类型,则可以不指定参数的类型
public class MyClass {public static void main(String[] args) {Integer[] a = {1, 5, 3, 2, 4};Arrays.sort(a, (o1, o2) -> o1 < o2 ? 1 : -1); //lambda没有指定参数类型System.out.println(Arrays.toString(a)); //out: [5, 4, 3, 2, 1]}}
无法指定lambda表达式的返回值类型,返回值类型是由上下文推导得出的。
- 函数式接口和lambda表达式
对于只有一个抽象方法的接口(如Comparator、Runnable等),称为函数式接口。
- 当需要函数式接口的对象时,就可以提供一个lambda表达式,不仅限于传参
- 可以说lambda表达式可以代替函数式接口的实现和实例化 ```java Runnable runnable = () -> System.out.println(“run()函数”); //lambda表达式用于实现并实例化接口 Thread thread1 = new Thread(runnable);
Thread thread2 = new Thread(()-> System.out.println(“run()函数”)); //lambda表达式用于传参
- 当一个接口是函数式接口时(仅包含一个抽象方法),就可以用`@FunctionalInterface`注解来标记自己定义了函数式接口,并用`@FunctionalInterface`标记,那么如果又无意增加了一个抽象方法,则编译器就会产生一个错误信息。<a name="XoEuK"></a>### 方法引用- **方法引用定义**- 方法引用是形如`System.out::println`的表达式,即**使用**`**::**`**运算符分隔方法名与对象或类名**。- **方法引用等价于lambdm表达式**如`**System.out::println**`**就等价于**`**x -> System.out.println(x)**`- **只有当lambdm表达式的代码块中只调用一个方法而不做其他操作时,才能把lambda表达式写为方法引用**如`s -> s.length() == 0`就不能写为方法引用的形式,因为该表达式除了调用`length()`方法外,还有一个比较操作- **方法引用的三种情况**根据`::`运算符前是类名还是对象名,以及`::`运算符后是动态方法还是静态方法,方法引用可以分为以下三种情况1. `**object::instanceMethod**`这种情况下,lambda表达式的参数将作为**动态方法**的**显式参数**传入2. `**Class::instanceMethod**`这种情况下,lambda表达式的第一个参数将作为**动态方法**的**隐式参数**,其他参数则作为实例方法的显式参数。<br />如`String::compareToIgnoreCase`等同于`(x, y) -> x.compareToIgnore(y)`- 注意,**当方法只有一个参数时,不能采用该方式**,因为单个参数默认为方法的参数。因此单个参数必须使用lambda表达式的形式```javastream.filter(str -> str.startsWith("Q")); //通过编译stream.filter(String::startsWith("Q")); //报错
**Class::staticMethod**
这种情况和第一种情况类似,lambda表达式的所有参数都传入了静态方法
- 方法引用中是可以使用
**this**或者**super**的,它们指代的是分别是创建这个lambda表达式的方法的类和这个类的父类 ```java class SuperClass { void sayHello() {
} }System.out.println("superClass: Hello!");
public class MyClass extends SuperClass { public static void main(String[] args) { new MyClass().greet(); } void greet() { new Thread(this::sayHello).start(); //this指代MyClass实例 new Thread(super::sayHello).start(); //super指代SuperClass实例 }
@Overridevoid sayHello() {System.out.println("MyClass: Hello!");}
}
- 上述代码输出```javaMyClass: Hello!superClass: Hello!
- 在使用方法引用时,如果引用的方法有多个同名的重载方法,则编译器会根据参数类型和数量自动确定具体的方法。[
](https://blog.csdn.net/ThinkWon/article/details/102243189)
构造器引用
构造器引用和方法引用类似,语句格式如下
类名::new
- 例如
int[]::new就等价于lambda表达式x -> new int[x]
当有多个构造器时,编译器会根据参数类型和数量自动确定具体的构造器。
- 构造器引用在Stream类的各种方法中大量使用。
使用lambda表达式
- 现在已经知道如何生成以及传递lambda表达式,现在就需要了解如何编写方法来接收lambda表达式以及什么时候需要接收lambda表达式
- 何时选择接收lambda表达式
使用lambda表达式的核心需求是延迟执行。有很多时候我们会希望延迟执行代码,如
- 在一个线程中运行代码
- 多次运行代码
- 在算法的适当位置执行代码(如排序算法中的比较操作)
- 发生某种情况时执行代码
- 接收lambda表达式
要使方法接收lambda表达式,需要选择(偶尔可能需要自己创建)一个函数式接口作为参数
Java提供的常用函数式接口如下 | 函数式接口 | 参数类型 | 返回类型 | 抽象方法 | 描述 | | —- | —- | —- | —- | —- | | Runnable | T | void | run | 作为无参数或返回值的动作运行 | | Supplier
| 无 | T | get | 提供一个T类型的值 | | Consumer | T | void | accept | 处理一个T类型的值 | | BiConsumer | int | R | apply | 有一个int类型参数,返回R类型 | | BiFunction | T | boolean | test | 有一个T类型参数,返回布尔值 | | BiPredicate 例如现在想要重复一个不需要参数和返回值的动作n次,那么我们就可以定义如下
repeat()方法,并使用函数式接口Runnablepublic class MyClass {public static void main(String[] args) {MyClass myClass = new MyClass();myClass.repeat(3, () -> System.out.println("Hello!"));}void repeat(int n, Runnable action) {for (int i = 0; i < n; i++)action.run();}}
在平常使用时,最好使用上表中的函数式接口。
Optional类型
- Optional定义
- Optional
是一种包装器,要么包装了类型T的对象(称为存在值),要么没有包装任何对象(称为不存在值) - T的引用,要么引用了某个对象,要么就是null,不够安全
- Optional
Optional
- Stream类的部分终端操作,返回的就是Optional
类型
- Optional的安全性
Optional安全性体现在下面两点
- Optional在值不存在的情况下会产生一个可替代物(如产生默认值),而只有在值存在的情况下才会直接产生这个值
- Optional只有在值存在的情况下,才会将它传递给指定方法
###Optional类API(java.util包)
动态方法
**T optional.orElse(T other)**
返回optional的值,当optional不存在值时,返回other
**T optional.orElseGet(Supplier<? extends T> other)**
返回optional的值,当optional不存在值时,调用other
**<X extends Throwable> T orElseThrow(Supplier<? extends X> exceptionSupplier)**
返回optional的值,当optional不存在值时,抛出调用exceptionSupplier的结果
**void optional.ifPresent(Consumer<? super T> action)**
如果optional存在值,就将它的值传递给action
**void optional.ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)**
如果optional存在值,就将它的值传递给action,否则调用emptyAction
Stream
Stream概述
- Stream的定义与特性
- Java 8添加了一个新的称为流Stream的类型,位于java.util.stream包。
Stream与java.io包里的**InputStream**和**OutputStream**是完全不同的概念。
- Stream是对容器对象功能的增强,它专注于对容器对象进行便利、高效的聚合操作。
- 所有Stream操作都能以lambda表达式为参数,极大的提高编程效率和程序可读性
使用Stream的好处
- 在处理集合时,我们常会迭代遍历其中的元素,并在每个元素上执行某个元素。
- 使用流,我们可以直接说明想要完成什么任务,进行什么操作,而不需要指定实现操作,指定操作应该以什么顺序或在哪个线程中执行。
- 例如,我们想要计算某个属性的平均值,那么就可以指定数据源和属性,然后流库就可以执行计算并优化计算的过程,如使用多线程来计算总和与个数,并将结果合并。
Stream和集合的差异
流和集合看起来很相似,都可以让我们转换和获取数据,但它们之间存在显著差异
- Stream不是一种数据结构,并不存储数据,操作时从数据源抓取数据。
- Stream的操作不会改变数据源,而是产生一个新的结果。
- Stream的操作是尽可能惰性的,这意味着直至需要最后的结果时,操作才会执行。
- Stream不支持索引访问
实例
ArrayList<String> wordList = new ArrayList<>();wordList.add("apple");wordList.add("pencil");Stream<String> stream = wordList.stream().filter(word -> word.length() > 3); //不推荐这样做,但是可以正常运行wordList.add("on");wordList.add("fuck");System.out.println(stream.count()); //out: 3
- 上述代码说明了Steam并不存储数据,并且是惰性的。
Stream操作流程

- 整个流操作流程就是一条流水线,对数据进行一系列的处理工作。
- 数据源
- 数据源可以是实现
Collection接口的类、数组、BufferedReader等
- 数据源可以是实现
- 生成Stream
- 不同的数据源使用相对应的方法可以生成Stream
- 中间操作
- Stream后面可以跟0个或多个中间操作,主要目的是对Stream中的元素进行映射、过滤、排序、类型转换等。
- 中间操作都会返回流对象本身,这样多个中间操作可以串联成一个管道
- 中间操作都是惰性的,即仅仅调用到这类方法,并没有真正开始流的遍历。
- 对一个Stream进行多次中间操作,每次都对Stream的每个元素进行转换,而且转换多次,这样时间复杂度就是N(转换次数)个for循环里把所有操作都做掉的总和吗?其实不是这样的,由于中间操作都是惰性的,因此多个中间操作只会在终端操作的时候融合起来,一次循环完成。可以理解为Stream里有个操作函数的集合,每次中间操作就是把转换函数放入这个集合中,在终端操作的时候遍历Stream对应的集合,然后对每个元素执行所有的函数。
- 终端操作
- 一个流操作流程只能有一个也必须有一个终端操作
- 当终端操作执行后,流就被使用“光”了,无法再被操作,所以这必定是流的最后一个操作。
- 终端操作的执行,才会真正开始流的遍历,并且会生成一个结果。
- 实例

- Stream出现前,进行这么一系列操作,需要使用迭代器或者for-each循环进行遍历,一步步地去完成这些操作;
使用Stream后,便可以直接声明式地下指令,流会完成这些操作,代码简洁,运行效率也高。
- Iterator和Stream的异同
- Stream就如同一个迭代器Iterator,单向、不可往复、数据只能遍历一次,遍历过一次后即用尽了
- 对于Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;
对于Stream,用户只要给出需要对其包含的元素执行什么操作,比如,“过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream就会隐式地在内部进行遍历,做出相应的数据转换。
- Stream和迭代器不同的是,Stream自动并行化操作而不需要额外的多线程代码,迭代器则只能串行化操作。当使用串行方式去遍历时,每个item读完后再读下一个item,而使用Stream去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。
- IntStream、LongStream和DoubleStream
- 对于基本数值型,有三种对应的Stream包装类型:
IntStream、LongStream和DoubleStream - 当然也可以用
Stream<Integer>、Stream<Long>和Stream<Double>,但是某些操作会很耗时,所以特别为这三种基本数值型提供了对应的Stream包装类型。
- 对于基本数值型,有三种对应的Stream包装类型:
从不同数据源生成Stream
- 从数组获得
**Stream<T> Arrays.stream(T[] array)**Stream<T> Stream.of(T... values)
- 从实现Collection接口的类实例获得
**Stream<E> collection.stream()**
- 从BufferedReader获得
Stream<String> reader.lines()
- 从文件中获得
Stream<String> Files.lines(Path path)Stream<String> Files.lines(Path path, Charset cs)
**stream()**和**parallelStream()**的区别
stream是顺序流,由主线程按顺序对流执行操作,
**parallelStream**是并行流,内部以多线程并行执行的方式对流进行操作,但使用时可能打乱流中元素的顺序。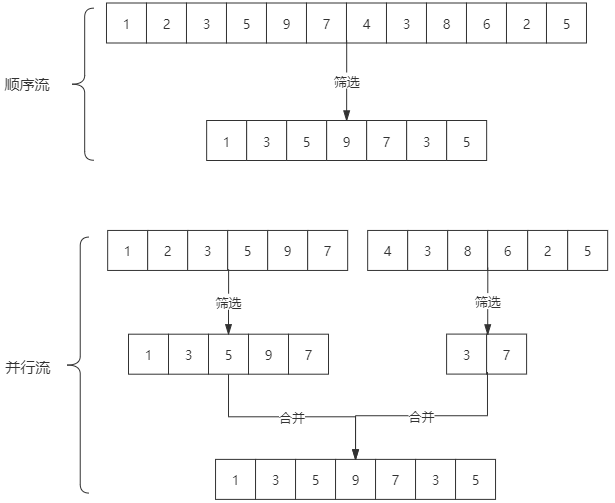
- 除了直接创建并行流,还可以通过
**parallel()**方法把顺序流转换成并行流
###Stream类API(java.util.stream包)
静态方法
**<T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b)**
拼接流a和b为一个流
中间操作
所有中间操作都是Stream实例的方法,返回都是一个新的Stream实例
**Stream<T> stream.map(Function<? super T, ? extends R> mapper)**
将mapper表示的方法应用到流的所有元素上
- 当需要按照某种方式来转换流中的值时,可以使用该方法,例如
stream.map(String::toLowerCase); //将stream中的字符串都转为小写
**Stream<T> stream.filter(Predicate<? super T> p)**
产生一个流,其中包含当前流中满足p的所有元素
- 当需要根据指定条件过滤流中元素时可以使用该方法
**Stream<T> stream.flatMap(Function<? super T, ? extends Stream<? extemds R>> mapper)**
将mapper表示的方法应用到当前流中所有元素所产生的结果连接到一起,注意这里mapper所产生的结果是流。
- 当使用的mapper返回流时可以使用该方法,否则当前流的所有元素都是流,不利于后续操作。
**Stream<T> limit(long maxSize)**
取当前流中前maxSize个元素
**Stream<T> skip(long n)**
丢掉当前流中前n个元素
**Stream<T> stream.takeWhile(Predicate<? super T> p)**
取当前流中满足p的元素,直到遇到第一个不满足p的元素则停止
**Stream<T> stream.dropWhile(Predicate<? super T> p)**
丢掉当前流中满足p的元素,直到遇到第一个不满足p的元素则停止
**Stream<T> stream.distinct()**
丢掉当前流中重复的元素
**Stream<T> stream.sorted()****Stream<T> stream.sorted(Comparator<? super T> comparator)**
对流中元素进行排序,第一个方法要求元素是实现了Comparable接口的类的实例
**Stream<T> stream.peek(Consumer<? super T> action)**
流中的元素不变,不过每获取流中的一个元素,就将其传给action并执行一次
###Stream类API——终端操作
**long stream.count()**
产生当前流中元素的数量
**Optional<T> stream.max(Comparator<? super T> comparator)****Optional<T> stream.min(Comparator<? super T> comparator)**
分别产生当前流的最大元素和最小元素,需要传入比较器。
- 如果当前流为空,则会产生一个空的Optional对象
**Optional<T> stream.findFirst()****Optional<T> stream.findAny()**
产生当前流的第一个和任意一个元素
- 如果当前流为空,则会产生一个空的Optional对象
第一个方法常与
filter()组合使用,如找到单词流中第一个以A开头的单词ArrayList<String> wordList = new ArrayList<>();wordList.add("Apple");wordList.add("American");wordList.add("fuck");Stream<String> stream = wordList.stream();System.out.println(stream.filter(str -> str.startsWith("A")).findFirst().orElse("null")); //out: Apple
如果不强调需要第一个匹配的结果,那么就可以使用第二个方法
第二个方法在并行处理流时很有效
**boolean stream.anyMatch(Predicate<? super T> p)****boolean stream.allMatch(Predicate<? super T> p)****boolean stream.noneMatch(Predicate<? super T> p)**
当前流中任意元素、所有元素、没有元素符合p时返回true
- 由于接收一个
Predicate,所以不需要filter()方法提前处理
**Iterator<T> stream.iterator()**
返回一个用于获取当前流中各个元素的迭代器
**void stream.forEach(Consumer<? super T> action)**
在当前流的每个元素上以任意顺序调用action
**void stream.forEachOrdered(Consumer<? super T> action)**
在当前流的每个元素上以流中的顺序调用action,但这样做可能丧失并行处理的部分甚至全部优势
**Object[] stream.toArray()****<A> A[] toArray(IntFunction<A[]> generator)**
返回流中的元素构成的数组
如果想让返回的数组具有正确的类型,可以传入一个数组构造器,如stream.toArray(String[]::new)

若有收获,就点个赞吧
0 人点赞
