推荐参考资料
- java虚拟机规范
- java语言规范
- 垃圾回收算法手册, 自动内存管理的艺术
- Virtural Manchines. Versatile Platforms for Systems and Processes
- Java 性能优化权威指南
- http://hllvm.group.iteye.com
- https://wiki.openjdk.java.net/groups/hotspot
- openjdk.java.net/groups/hotspot
自动内存管理
java内存区域与内存溢出异常
运行时的数据区域
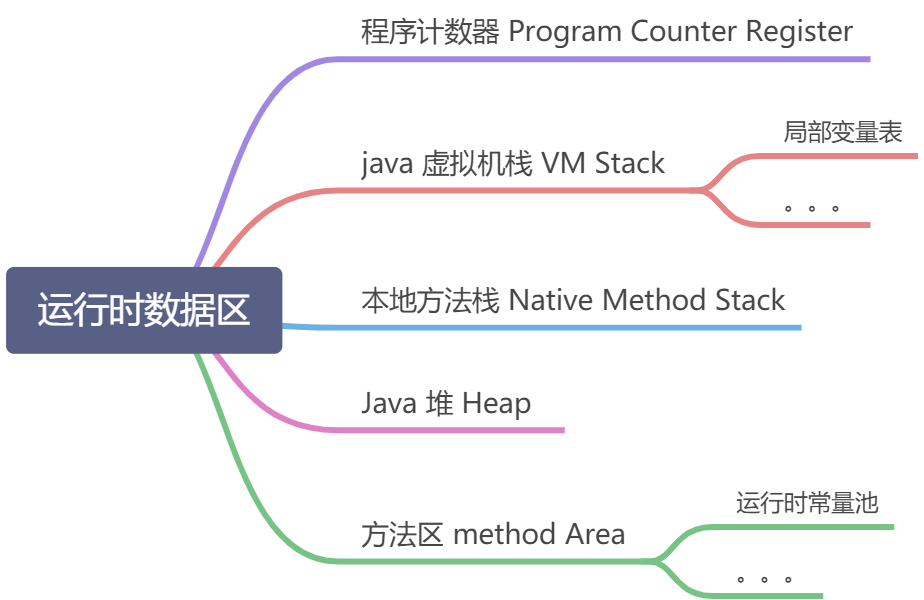
程序计算器
每条线程拥有一个独立的程序计数器,互不影响,线程私有内存
- 如果线程在执行java方法,计数器记录的是正在执行的虚拟机字节码指令地址
- 如果线程执行的是本地方法,计数器值为空
- 这个区域没有溢出 说法
java虚拟机栈
- 也是线程私有的,生命周期与线程相同
- 执行方法时,栈帧会被创建用于 存储 局部变量表,操作数栈, 动态连接, 方法出口等信息, 每个方法的执行周期,对应一个栈帧在 stack的入栈到出栈过程
- 局部变量表存放基本类型 对象引用 和returnAddress类型
- 局部变量槽 slot
- StackOverFlowError 线程请求的栈深度大于虚拟机允许的深度
- OutOfMemoryError 当栈可以动态扩展,但无法申请到足够内存时
java 本地方法栈
- 与虚拟机栈一样,只是用于执行本地方法
java 堆
- 是被所有线程共享的一块区域
- 虚拟机启动时创建
- 唯一目的是用于存放对象实例,java规范上有些 所有对象实例及数组都应当分配在堆上,但实际不是这么绝对
- java 堆 是垃圾收集器管理的内存区域, 也叫GC 堆
- 物理上可以不连续
- 可以设置为扩展,或固定大小(-Xmx -Xms) , 当堆也无法扩展时,也会抛OutOfMemoryError
方法区
- 也是所有线程共享的一块区域
- 用于存储已经被加载的 类信息, 常量, 静态变量 即时编译器编译后的代码缓存等数据
- 方法区也可以选择固定大小或可扩展,无法满足内存分配需求时将抛出 OutOfMemoryError
- 废弃了永久代概念,改用本地内存 中实现的元空间 来实现 方法区
- 运行时常量池是方法区的一部分,Class文件中有个常量池表用于存放编译产生的 字面量与符号引用,类加载后会放到运行时常量池,他是动态的
常量池时方法区的一部分,因此受到方法区内存限制,无法申请到内存时会抛OutOfMemoryError
直接内存
不是虚拟机运行时数据区的一部分,但也可能有OutOfMemoryError
- 本机直接内存的分配不会受到java堆大小的限制,可能会被忽略,即使堆方法区的内存都在设置内,也可能超出物理内存出现 OutOfMemoryError
HotSpot 虚拟机对象探秘
对象的创建
- new 指令
- 检查指令参数是否是常量池中的一个类符号引用
- 检查是否被加载,解析和初始化
- 没有,就执行类加载过程
- 虚拟机为新生对象分配内存
- 内存大小在类加载完成后可以确定
- 采用“指针碰撞” Bump the The Pointer 方式分配内存, 简单高效,内存管理有带压缩功能时会用这种
- 如果内存不连续 不规整,采用 “空闲列表” 这种分配方式,
- 线程安全问题, 一种可采用 CAS 和失败重试保证操作原子性,另一种是使用 TLAB 本地线程分配缓冲,只有在缓冲用完了才需要同步锁定
- 虚拟机将分配好的内存空间不包括对象头都初始化为0
- 设置对象,就是把 对象属于哪个类,如何找到类的元数据, 对象哈希码,对象GC分带年龄信息等存到对象头
- 执行构造函数
对象的内存布局
- 可分为 对象头 实例数据 对其填充 header Instance Data, Padding
- 对象头
- 运行时数据 动态定义的数据结构 “Mark world”
- 哈希码
- GC分带年龄
- 锁状态标识
- 线程持有锁
- 偏向线程ID
- 偏向时间戳
- 类型指针 执行类型元数据的指针, 通过它判断是哪个类的对象
- 如果是数组,需要记录长度的数据
- 运行时数据 动态定义的数据结构 “Mark world”
实例数据
- 无论是父类还是子类的所有字段
- 存储顺序收分配策略 -XX:FieldsAllocationStyle 参数影响
- 默认相同宽度的字段会分配到一起存放
对齐填充
- 对象代销必须是8字节整数倍,不够的化需要填充
对象的访问定位
- java程序通过栈上的reference数据来操作堆上的具体对象
- 主流访问方式
- 句柄,java堆中会开辟一块内存作为句柄池,reference存储句柄地址,句柄中包含对象实例的地址信息(方法区 与堆中)
- 直接指针, reference直接存储的就是对象地址,或到对象类型数据的指针(指向方法区的对象类型数据)
OutOfMemoryError 异常
除程序计数器外,其它运行区域都有可能出现OutOfMemoryError
Java 堆溢出
对象实例容量超过堆的大小,只要不停的new 对象就会出现
- 会提示 java heap space
- 分析
- 区分是内存泄漏 Memory Leak 还是内存溢出 Memory Overflow
- 如果是内存泄漏,可以通过工具查看泄漏对象到GC Roots 的引用链,
- 如果不是内存泄漏,就必须检查 堆参数 并进行调整
虚拟机栈和本地方法栈溢出
- Hotspot 不区分虚拟机栈和本地方法栈
- 线程请求的栈深度大于虚拟机运行的深度,抛 StackOverFlowError
- 栈如果允许动态口哦组,当扩展的栈容量无法申请到足够内存时,抛OutOfMemoryError
- HotSpot 是不支持扩展的
- 触发栈溢出
- -Xss减少栈内存
- 定义大量的本地变量,增大方法帧中本地变量表的长度
- 不断创建线程
- 栈深度一般到 1000-2000是没有问题的,
-
方法区和运行时常量池溢出
java 6 之前 String是存储于常量池,,后面被移到堆中
- 可以用CGLib 生成很多动态类
元空间替代了永久区后 就很难利用上面两种方法产生方法区溢出了
本机直接内存溢出
大小可以通过-XX:MaxDirectMemorySize 指定,默认于java堆最大值一致
- Unsafe::allocateMemory
垃圾收集器与内存分配策略
对象已死?
引用计数算法
-
可达性分析算法
GCRoots 根对象 根据引用关系向下搜索,走过的路径为 引用链(Reference Chain),没有引用链接相连,就是对象不可达,判定为回收对象
可以作为GCRoots的对象
强引用
- 软引用 SoftReference
- 将要发送溢出时,进行二次回收
- 弱引用 WeakReference
- 只能生存到下次发生垃圾回收之前
虚引用 PhantomReference
判断 不可达 是做一次标记,相当于死缓
- 然后看时候有必要执行finalize (没有自定义的finalize 或已经执行过 就不会执行)
- 执行finalize时会把对象放到F-Queue中,
- 如果在finalize中重新引用可以逃脱死亡
-
回收方法区
废弃的常量
- 不再使用的类型
- 该类的所有实例都已被回收
- 加载该类的类加载器已经被回收
- 该类对应的java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法
垃圾收集算法
分代收集理论 (Generational Collection)
- 假说
- 弱分代假说 Weak Generational Hypothiesis 绝大数对象都是朝生夕灭
- 强分代假说 Strong … 熬过多次垃圾回收过程的对象就越难以消亡
- 跨代引用假说 InterGenerational Reference Hypothiesis 跨代引用相对于同代引用只占少数
标记清除算法 Mark-Sweep
缺点
分为两个区域
- 存活的对象 复制到 另一个空区域
- 清空当前区域,下次对调两个区域的角色
- Apple式回收
- Eden 两个Suvivor空间 默认 8:1:1 大小
- 安全设计,Suvivor不足以存放存活下的对象时,会依赖其它区域进行分配担保
- 缺点
- 存活率较高时不适用
- 50% 空间浪费
标记- 整理算法
- 区别在于整理,是对存活的对象进行一个整理,使其连续
- 适用于存活率很高的情况(老年代)
- 很容易触发“STOP THE Word”
- 标记-清楚和标记-整理可以混合使用,在碎片到一定程度时进行整理
- 整理会带来吞吐量的正相关,延迟负相关,
HotSpot的算法细节实现
根节点枚举
- 这个步骤和内存碎片整理一样 会引发“Stop the world”
- 因为这个期间引用关系不能发生变化,这是必须停顿所有用户线程的一个原因
-
安全点
必须执行到安全点才能暂停线程
- 抢先式中断 ,先全部中断,发现没有在安全点上,恢复执行,让它到安全点再中断
主动式中断, 轮询一个标志位,发现中断标志,就在最近的安全点中断挂起
安全区域
在一段代码片段中,引用关系不会发生变化,所以在这个区域中任意地方进行垃圾回收都是安全的
- 首先标记进入安全区域,当线程离开安全区域时,检查是否完成了根节点枚举,
-
记忆集与卡表
Remembered Set 用来避免把整个老年代加进GC Root 扫描范围
- Remembered Set 是记录从非收集区域指向收集区域的指针集合的抽象数据结构
- 精度
- 字长精度
- 对象精度
- 卡精度 使用卡表的方式实现记忆集
写屏障
- 卡表变脏,有其它区域中的对象引用了本区域的对象
- 写前屏障,写后屏障,相当于AOP 给写增强了前置与后置操作
- 卡表的状态维护就是使用写屏障
- 伪共享问题 ,使用同一个缓存行造成的问题
卡表会使用同一个缓存行,可以通过卡表标记开解决, —XX:UseCondCardMark 用来开启,也是有性能损耗的
并发的可达性分析
对象消失的两种情况
- 赋值器插入了一条或多条从黑色对象到白色的象的新引用
- 赋值器删除了全部从灰色对象到该白色对象的直接或间接引用
- 增量更新
- 先记录下来这个新插入的引用,在并发扫描结束后以黑色对象为根重新扫描
原始快照
单线程
- 新生代采用复制算法 暂停所有线程
- 老年代用标记整理算法 暂停所有线程
ParNew 收集器
- 较Serial 收集器 就是 多线程,其它没有太多创新
- 虽然是多线程 ,但GC 线程 和用户线程还是不能同时进行
ParNew在单核心处理器不会有 serial 收集器更好的效果
Parallel Scanvenge 收集器
关注点是达到一个可控制的吞吐量,这里的吞吐量是用户代码允许时间占比
- -XX:MaxGCPauseTime -XX:GCTimeRatio 这个事吞吐量的倒数
-XX:UseAdaptiveSizePolicy 交给虚拟机自己动态调节
Serial Old收集器
Serial 收集器老年代回收版本
- 使用标记整理方法
- 客户端模式下的HotSpot虚拟机使用
Parallel Old收集器
- Parallel Scanvenge老年代版本
- 标记整理算法
- Parallel Scanvenge + Parallel Old 搭配
CMS 收集器
- 以获取最短回收停顿时间为目标的收集器
- 标记清除算法
- 浮动垃圾,无法当次收集中处理的
- 必须预留一部分空间供并发收集时程序运行使用
碎片问题,可以设置若干fullGC后下次进入fullgc 进行整理
Garbage First 收集器
在jdk9 后取代 Parallel Scanvenge + Parallel Old 搭配成为默认收集器,CMS 为不推荐使用
- Mixed GC 模式
- 开创基于 Region 的堆内存布局
- 不再坚持固定的分代区域划分
- 划分成Region,根据需要扮演 Eden Survivor 或老年代
- 根据不同角色采用不同策略去收集
- Humongous区域 专门用于存储大对象,可以通过-XX:G1HeapRegionSize 设定
- 当作老年代对待
- 优先处理回收价值最大的Region
- G1 要解决的问题
- 类似跨代引用,这里要解决跨Region引用,每个region都要使用到双向卡表结构,需要占用更多的内存来维持收集器工作,
- 保证用户线程和收集线程互不干扰,既要不改变对象引用关系下运行,通过原始快照STAB来实现
- 内存回收速度赶不上内存分配速度,G1会被迫冻结用户线程,导致Full GC (STW)
- 建立可靠的停顿预测模型
- 通过 -XX:MaxGCPauseMillis 指定期望停顿时间
- “衰减均值” 来计算收益
- G1 收集器的运作过程(不考虑用户线程)
- 初始标记 Initial Marking
- 标记下GC Roots能直接关联到的对象
- 修改TAMS 指针值, 使下阶段用户 线程并发时可以分配新对象
- 停顿比较小,借用minor GC时候同步完成
- 并发标记
- GC Root 开始进行可达性分析,找到要回收的对象
- 耗时长,但可与用户线程并行
- 重新处理 STAB记录下的在并发时有引用变动的对象
- 最终标记
- 对用户线程做的另一个短暂的暂停,用于处理并发阶段仍遗留下来的最后那些少量的SATB记录
- 筛选回收
- 更新Region的统计数据,对回收价值和成本进行排序,根据用户指定的停顿时间制定回收计划
- 可选择任意多个Region构成回收集,存活的复制到空的Region,清理掉旧Region
- 必须暂停用户线程,由多条收集器线程并发完成
- 初始标记 Initial Marking
- 全功能收集器
- 并非纯粹的追求低延迟,而是在延时可控范围内追求吞吐量
- 期望值必须符合实际
- 几十到一百甚至到两百毫秒都很正常
- 如果设置太小,会导致每次回收的内存很少,赶不上分配器的分配速度,导致垃圾慢慢堆积,最终导致Full GC
- G1 开始, 收集器都被设计成能够应付应用内的分配速率
G1 与CMS对比
衡量垃圾收集器的指标
- 内存占用 FootPrint
- 吞吐量 Throughput
- 延迟 Latency
一些问题
- 像CMS 算法会产生碎片,不可避免会发生 STW
- G1 整理阶段也是有暂停的
- 内存变大后,反而会使回收时间边长
Shenandoah 收集器
- 之前官方不支持,openjdk支持,
- 目标是在任何堆大小下都可以把垃圾收集停顿时间控制在 10毫秒内
- 与G1 很多方面高度一致
- 与G1 的三个区别
- g1的回收阶段是并行的,但不能和用户线程并发
- Shenandoah 默认不使用分代,
- Shenandoah 摈弃了 G1中耗费大量资源维护的记忆集,改用连接矩阵
- 九个工作阶段
- 初始标记
- 与g1一样标记与GC roots 直接关联的对象,仍然会 STW, 但停顿时间与堆大小无关,只与GC Roots 的数量相关
- 并发标记
- 标记可达对象,与用户线程并发,时间长短取决与存活对象数量及对象图的结构复杂度
- 最终标记
- 处理剩余的STAB 扫描,统计出回收价值最高的region,组成回收集,会有小停顿
- 并发清理
- 清理一个存活对象都没找到的region
- 并发回收
- 把回收集里存活的对象复制到未使用的region
- 使用读屏障 可以使 用户线程与回收同时进行
- 初始引用更新
- 线程集合点,确保移动对象的任务已完成,有一个短暂的停顿
- 并发引用更新
- 把指向旧对象的应用修正到复制后的新地址
- 与用户线程并发
- 最终引用更新
- 修正GC Roots中的引用
- 并发清理
- 回收内存空间,供下次使用
- 初始标记
- Brooks Pointer
- 一个转发指针,会指向新的自己,相当于搬家后在原来的地方留下自己新的住址信息
- 这里有一个同步问题,
ZGC 收集器
- jdk 11, 官方研发
- 目标与Shenandoah一致
- 与PGC C4相似, Shenandoah则是G1继任者
- 特征
- 基于Region内存布局的
- 不设分代
- 使用了读屏障,染色指针,内存多重映射等技术来实现并发的标记-整理算法的
- 以低延迟为首要目标
- 内存布局
- 动态创建销毁与动态的区域大小
- 其中大型region容量不固定可以动态变化,为2MB整数倍
- 并发整理算法实现
- 染色指针技术
- 直接把标记信息记在引用对象的指针上,
- 会导致管理的内存减少到4TB
- 染色指针优势
- 使一个region存活对象移走后,立即就能释放重用,理论上只要还有一个空闲的region就能完成回收
- 减少内存屏障使用
- linux还有18位未使用,后面可以用来记录一些跟踪信息进行更多优化
- 过程
- 并发标记
- 与G1一样,做可达性分析
- 不一样的是在染色指针中改变 Mark0 Mark1标识位,而不是在对象中进行标记
- 并发预备重分配
- 根据特点条件统计出要清理哪些Region
- G1是收益优先增量回收,而ZGC是扫描所有Region,省去记忆集的维护
- 并发重分配
- 存活对象复制到新的region,维护一个转发表,记录旧对象到新对象的转向关系
- 用户线程如果此时访问对象,会被预置的内存屏障截获,根据转发表得到新的引用,这个就是“自愈能力”
- 并发重映射
- 修正旧对象的引用
- 会合并到下一个并发标记阶段一起
- 性能表现
- 吞吐量测试
- 停顿时间测试
- 并发标记
- 染色指针技术
- 选择合适的垃圾收集器
- Epsilon 收集器
- 收集器权衡
- 应用程序关注点
- 基础设施
- jdk发行商与版本
- 虚拟机及收集器日志
- 到jdk9 Hotspot所有功能的日志都归到 -Xlog上
- 例子
- 查看GC基本信息 -XX:+PrintGC jdk9后 -Xlog:gc:
- 查看GC详情 -XX:+PrintGCDetails jdk9 后 -Xlog:gc*
- 查看GC前后堆,方法区可用容量变化 -XX:PrintHeapAtGc jdk9后 -Xlog:gc+heap=debug
- 查看GC过程中用户线程并发时间及停顿时间, -XX:+Print-GCApplicationConcurrentTime 及-XX:+PrintGCApplicationStoppedTime jdk9后 -Xlog:safepoint:
- 查看收集器Ergonomics机制 -XX:+PrintAdaptive-SizePolicy -Xlog:gc+ergo*=trace
- 查看熬过收集后对象年龄分布 -XX+PrintTenuring-Distribution -Xlog:gc+age=trace
- 实战: 内存分配与回收策略 //TODO 码一下,运行一下
分类
- 商业授权工具
- 正式支持工具
- 实验性工具
- jps
- LVMID 与PID 是一致的
- jstat
- 主要有三类信息,类加载,垃圾收集, 运行期编译情况
- jinfo
- java 配置信息工具
- 运行期间可以修改配置
- jmap
- 内存映像工具
- jhat 堆转储快照分析工具
jstack 堆栈跟踪工具

若有收获,就点个赞吧
0 人点赞
