- 1 认识SQL Server
- 2 数据库的操作
- 3 数据库表的操作
- 4 Transact-SQL语言基础
- 5 掌握T-SQL语句
- 6 认识函数
- 6.1 SQL Server函数简介
- 6.2 字符串函数
- 6.3 数学函数
- 6.3.1 ABS(x)函数
- 6.3.2 PI()函数
- 6.3.3 SQRT(x)函数
- 6.3.4 RAND()函数
- 6.3.5 ROUND(x,y)函数
- 6.3.6 SIGN(x)函数
- 6.3.7 CEILING(x)函数
- 6.3.8 FLOOR(x)函数
- 6.3.9 POWER(x,y)函数
- 6.3.10 SQUARE(x)函数
- 6.3.11 EXP(x)函数
- 6.3.12 LOG(x)函数
- 6.3.13 LOG10(x)函数
- 6.3.14 RADIANS(x)函数
- 6.3.15 DEGREES(x)函数
- 6.3.16 SIN(x)函数
- 6.3.17 ASIN(x)函数
- 6.3.18 COS(x)函数
- 6.3.19 ACOS(x)函数
- 6.3.20 TAN(x)函数
- 6.3.21 ATAN(x)函数
- 6.4 数据类型转换函数
- 6.5 文本和图像函数
- 6.6 日期和时间函数
- 6.7 系统函数
- 7 Transact-SQL查询
- 7.4 使用聚合函数统计汇总
- 7.5 嵌套查询
- 7.5.1 使用比较运算符=
- 7.5.2 使用IN关键字
- 7.5.3 使用ANY关键字
- 7.5.4 使用ALL关键字
- 7.5.5 使用EXISTS关键字
- 7.6 多表连接查询
- 7.7 外连接
- 7.8 使用排序函数
- 8 数据的更新
- 8.2 修改数据-UPDATE
- 8.3 删除数据-DELETE
- 9 规则、默认和完整性约束
- 10 创建和使用索引
- 11 事务和锁
- 12 游标
- 13 存储过程和自定义函数
- 14 视图操作
- 15 触发器
- 16 SQL Server 2012的安全机制
1 认识SQL Server
2 数据库的操作
2.1 数据库组成
2.1.1 数据文件
一个数据库能有一个主数据文件,扩展名是mdf,此数据文件的扩展名是ndf
2.1.2 日志文件
日志文件是由一系列的日志记录组成,记录存储数据的更新情况,扩展名是ldf。一个数据库至少有一个事务日志文件,也可以有多个事务日志文件
2.2 系统数据库
2.2.1 master数据库
master数据库是数据库中最重要的数据库,是数据库的核心,不能直接修改该数据库,否则数据库无法正常工作。包括所有的信息配置属性,服务器的本地数据库名称,用户信息等。数据库管理员应定期备份此数据库。
2.2.2 model数据库
2.2.3 msdb数据库
msbd数据库提供运行SQL Server功能信息,是服务数据库。
2.2.4 tempdb数据库
tempdb数据库是临时数据库,用来存放临时对象中间结果的。SQL Server关闭后,该数据库被清空,重启启动后,重新新建
2.3 创建数据库
2.3.1 使用对象资源管理器
- 路径:选中数据库—>右键选择新建数据库—>输入数据库名称—>点击确定按钮
- 截图:
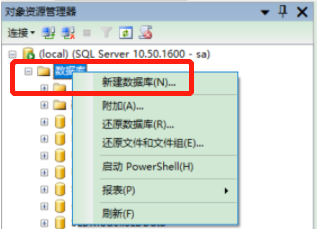
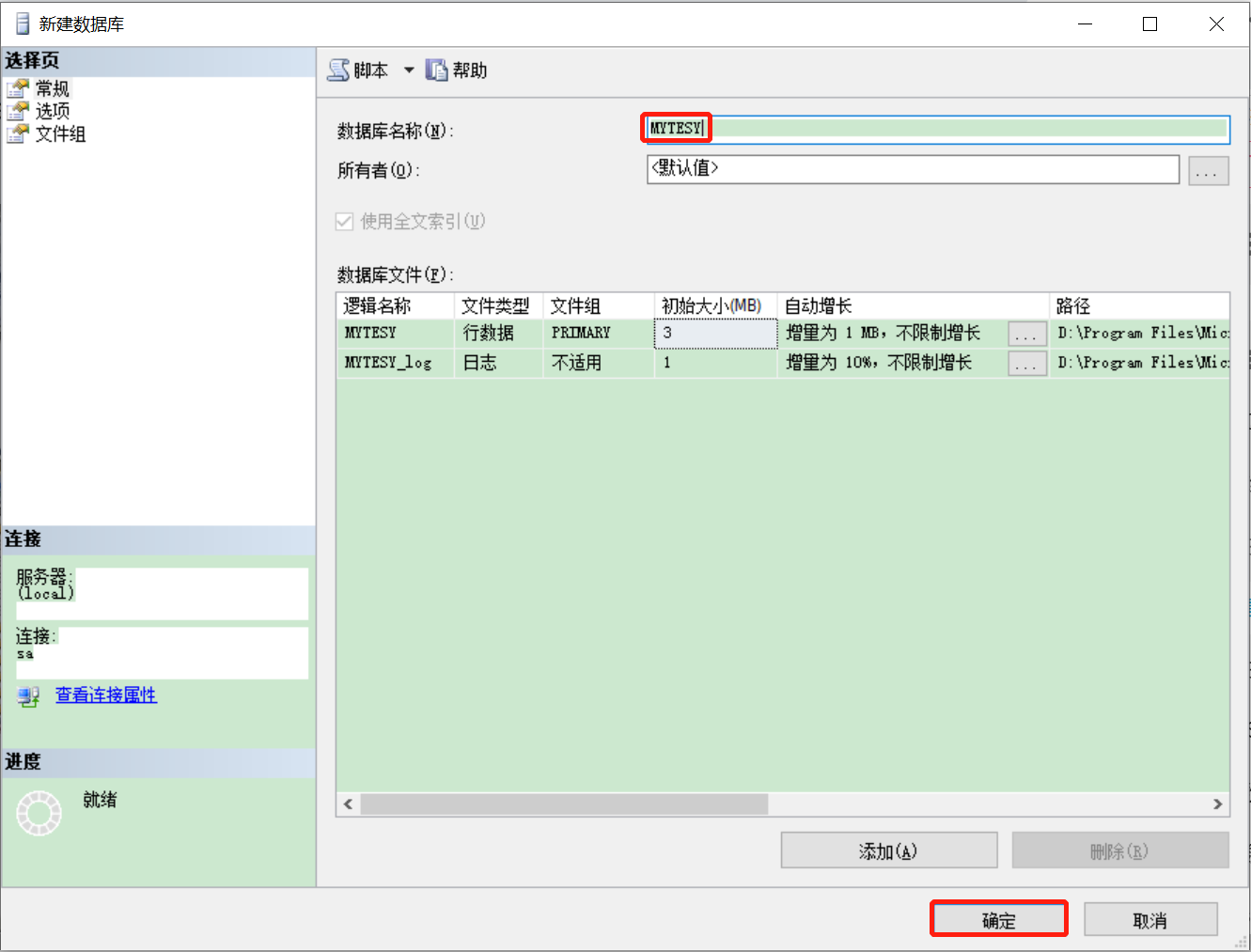
2.3.2 使用Transact-SQL
CREATE DATABASE [sample_db] ON PRIMARY —创建数据库
(
NAME = ‘samole_db’, —数据文件名
FILENAME = ‘D:\Program Files\Microsoft SQL Server\project\sample.mdf’, —数据文件路径
SIZE = 5120KB, —数据文件大小
MAXSIZE = 30MB, —数据文件最大值
FILEGROWTH = 5% —数据文件增幅
)
LOG ON
(
NAME =’sample_log’, —日志文件名
FILENAME = ‘D:\Program Files\Microsoft SQL Server\project\sample_log.ldf’, —日志文件路径
SIZE = 1024KB, —日志文件大小
MAXSIZE = 8192KB, —日志文件最大值
FILEGROWTH =10% —日志文件增幅
)
GO
2.4 管理数据库
2.4.1 修改数据库
ALTER DATABASE sample_db —修改数据库名
MODIFY FILE —修改文件
(
NAME = ‘samole_db’, —数据文件名
SIZE = 5130KB —修改数据文件大小
)
GO
2.4.2 查看数据库信息
- 查看数据库状态
USE sample_db
GO
SELECT DATABASEPROPERTYEX ( ‘sample_db’, ‘Statue’)
AS ‘sample_db数据库状态’;—NULL
- 查看存储过程空间
2.4.3 数据库更名
ALTER DATABASE sample_db<br />MODIFY NAME = sample;<br />GO--数据库 名称 'sample' 已设置。
2.4.4 删除数据库
3 数据库表的操作
3.1 数据库对象
3.1.1 描述
数据库对象是数据库的组成部分,数据表、视图、索引、存储过程以及触发器等都是数据库对象
3.1.2 图示
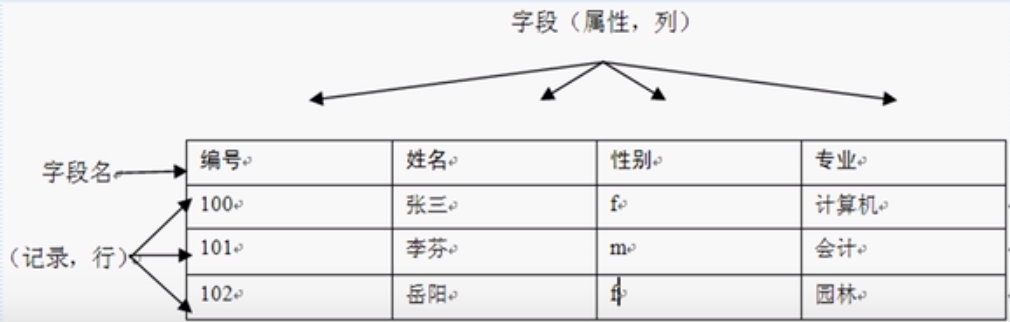
3.2 创建数据表
3.2.1 数据类型
3.2.1.1 精确数字
- bit
- tinyint
- smallint
- int
- bigint
- mumeric
- decimal
- smallmoner
-
3.2.1.2 近似数字
float
-
3.2.1.3 日期和时间
datetime
- smalldatetime
- date
- time
- datetimeoffset
-
3.2.1.4 字符串
char
- varchar
-
3.2.1.5 Unicode字符串
nchar
- nvarchar
-
3.2.1.6 二进制字符串
binary
- varbinary
-
3.2.1.7 其他数据类型
sql_variant
- timestamp
- uniqueidentifier
-
3.2.1.8 CLR数据类型
-
3.2.1.9 空间数据类型
geometry
-
3.2.2 使用对象资源管理器
路径:选中数据库下的表—>右键选择新建表(N)—>输入列名、选择数据类型、确定是否允许NULL值—>点击保存按钮—>输入表名称—>点击确定按钮
- 图示:
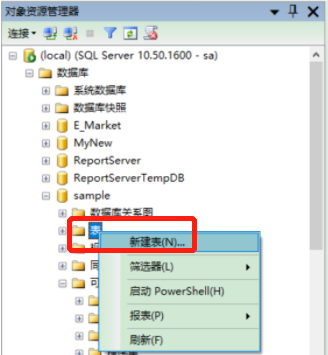
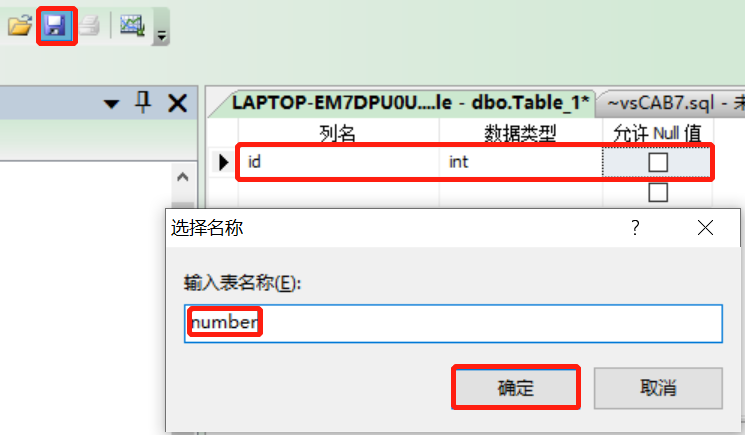
3.2.3 使用Transact-SQL
USE sample
CREATE TABLE authors
(
id INT PRIMARY KEY, —数据表主键
name VARCHAR(20) NOT NULL UNIQUE, —作者名称,不能为空
gender TINYINT NOT NULL DEFAULT(1) —作者性别,男(1),女(0)
);
3.3 管理数据表
3.3.1 增加表字段
3.3.1.1 管理器增加
- 路径:选中表—>右键选择设计—>输入列名、选择数据类型、确定是否允许NULL值—>点击保存按钮
- 图示:
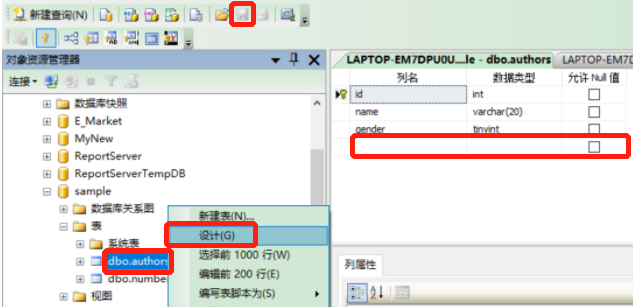
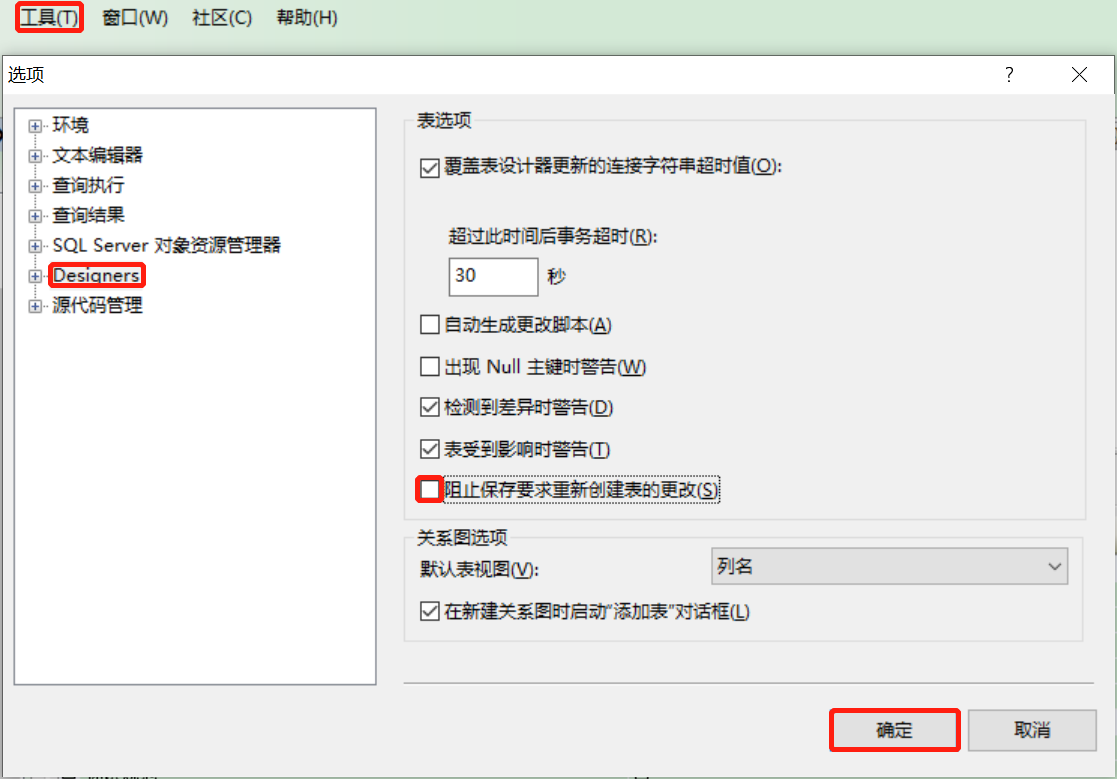
- 问题:不允许保存时,修改配置,工具—>选项—>设计—>不勾选阻止保存要求重新创建表的更改—确定
3.3.1.2 T-SQL增加
ALTER TABLE authors
ADD note VARCHAR(50) NULL
3.3.2 修改表字段
3.3.2.1 管理器修改
- 路径:选中表—>右键选择设计—>选择修改的列名、选择数据类型或否允许NULL值—>点击保存按钮
- 图示:
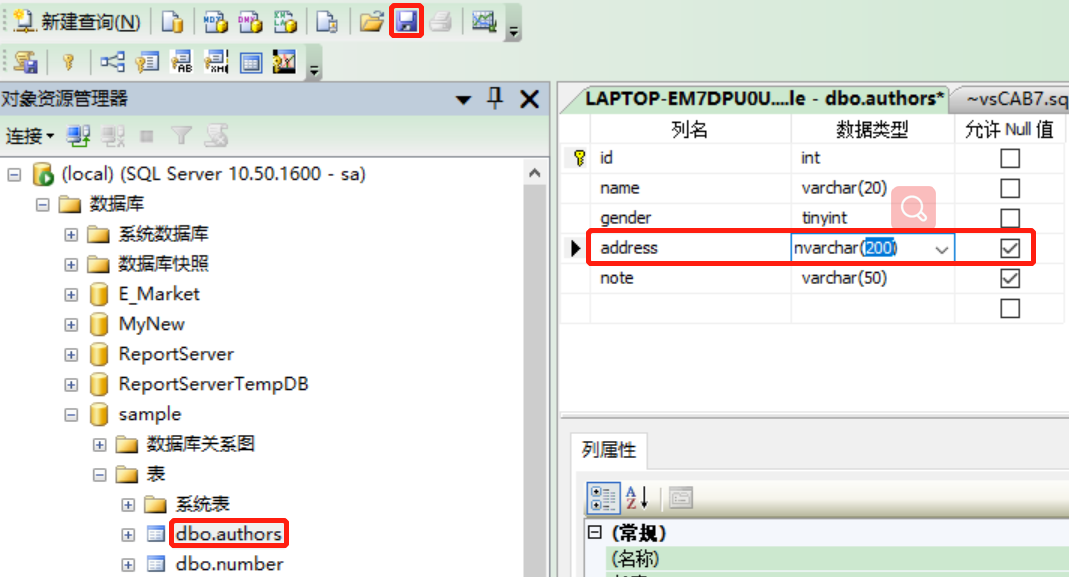
3.3.2.2 T-SQL修改
ALTER TABLE authors
ALTER COLUMN note VARCHAR(60)
GO
3.3.3 创建表约束
3.3.3.1 管理器创建
- 路径:选中表—>右键选择设计—>选中创建的列名—>右键选择设置主键、索引或键、CHECK约束等—>保存
- 图示:
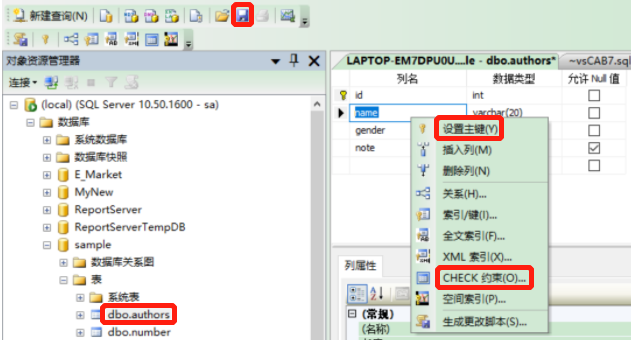
3.3.3.2 T-SQL创建
CREATE TABLE emp
(
id CHAR(18) CONSTRAINT PK_id PRIMARY KEY,
name VARCHAR(25) NOT NULL,
sex NVARCHAR(1) CONSTRAINT DF_sex DEFAULT (0),
deptid INT,
phone VARCHAR(15) CONSTRAINT UQ_phone UNIQUE
)
3.3.4 删除表字段
3.3.4.1 管理器删除
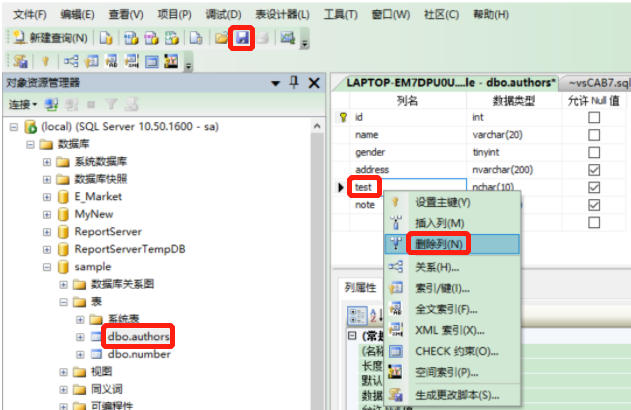
- 路径:选中表—>右键选择设计—>选中列—>右键选择删除列—点击保存按钮
图示:
3.3.4.2 T-SQL删除
ALTER TABLE authors
DROP COLUMN address3.3.5 编辑数据表
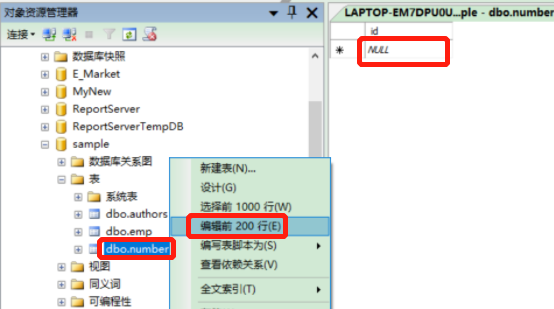
3.3.5.1 管理器编辑
路径:选中表—>右键选择编辑前200行—>打开表—>录入相关字段信息—点击保存按钮
- 图示:
3.3.5.2 T-SQL编辑
INSERT INTO number (id) VALUES (1),(2),(3);
3.3.6 查看数据表
3.3.6.1 管理器查看
- 路径:选中表—>右键选择编辑前200行—>打开表
-
3.3.6.2 T-SQL查看
3.3.6.3 查看SQL版本和服务器名称
SELECT @@VERSION AS ‘SQL Server版本’, @@SERVERNAME AS ‘服务器名称’
3.3.6 删除数据表
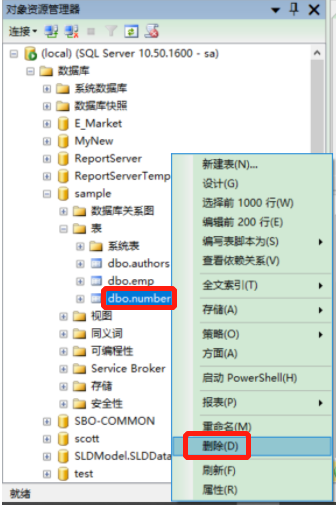
3.3.6.1 管理器删除
路径:选中表—>右键选择删除—>点击确定
- 图示:
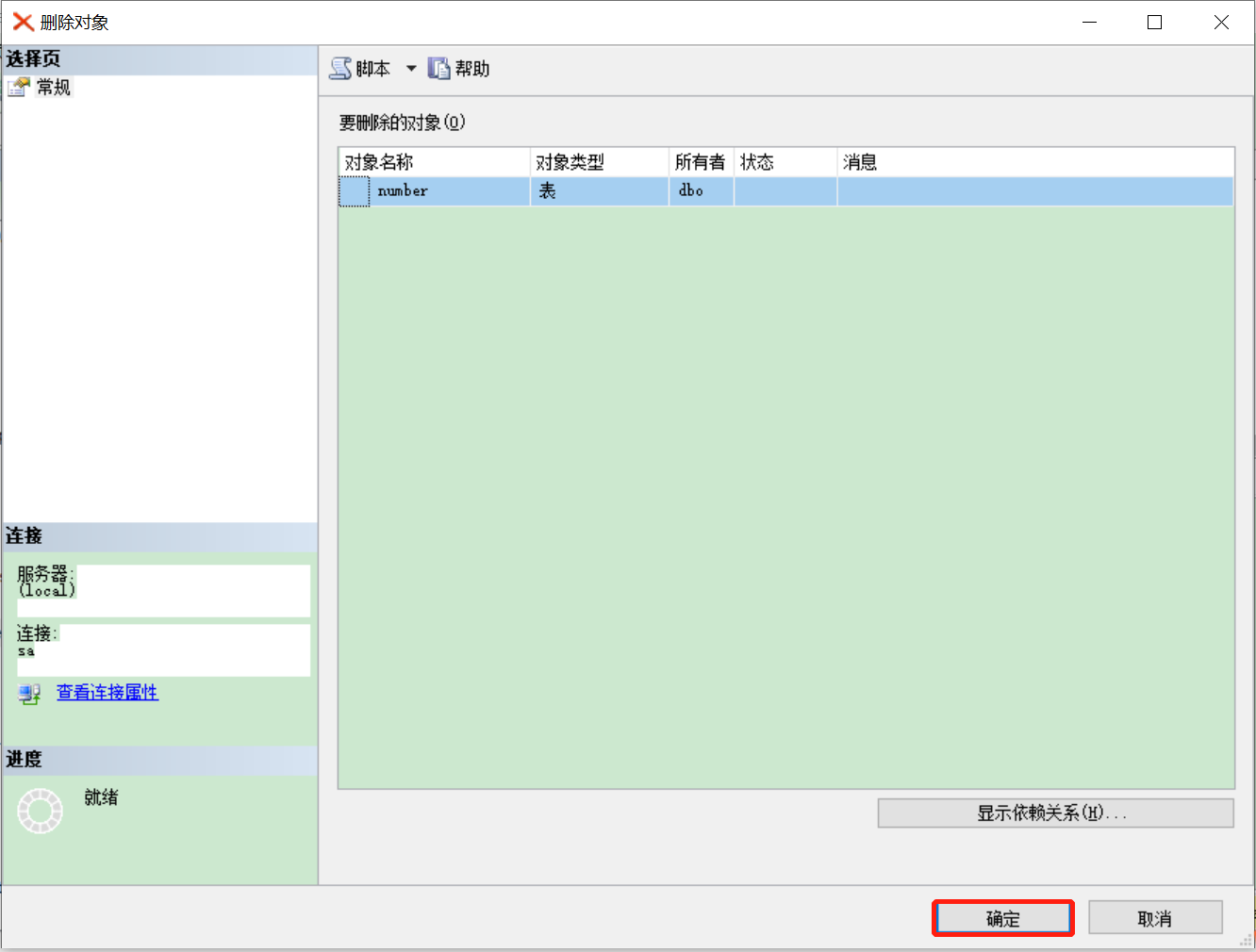
3.3.6.2 T-SQL删除
4 Transact-SQL语言基础
4.1 Transact-SQL概述
4.1.1 什么是T-SQL
4.1.1.1 描述
结构化查询语言(Structure Query Language,SQL)是对数据库进行查询和修改的语言。
Transact-SQL是SQL的一种实现形式,它包含了标准的SQL语言部分。
4.1.1.2 分类
根据完成的具体功能,Transact-SQL分为4大类。
- 数据操作语句:
SELECT , INSERT, DELETE, UPDATE
- 数据定义语句:
CREATE TABLE, DROP TABLE, ALTER TABLE,
CREATE VIEW, DROP VIEW,
CREATE INDEX, DROP INDEX,
CREATE PROCEDURE, ALTER PROCEDURE, DROP PROCEDURE,
CREATE TRIGGER, ALTER TRIGGER, DROP TRIGGER
数据控制语句:
GRANT, DENY, REVOKE
附加的语言元素:
BEGIN TRANSACTION/COMMIT, ROLLBACK,
SET TRANSACTION, DECLARE OPEN, FETCH, CLOSE, EXECUTE
4.1.2 T-SQL语法的约定
| 约定 | 用于 |
|---|---|
| 大写 | Transact-SQL 关键字。 |
| 斜体 | 用户提供的 Transact-SQL 语法的参数。 |
| 粗体 | 数据库名、表名、列名、索引名、存储过程、实用工具、数据类型名以及必须按所显示的原样键入的文本。 |
| 下划线 | 指示当语句中省略了包含带下划线的值的子句时应用的默认值。 |
| | | 分隔括号或大括号中的语法项。只能使用其中一项。 |
| [ ] | 可选语法项。不要键入方括号。 |
| { } | 必选语法项。不要键入大括号。 |
| [,…n] | 指示前面的项可以重复 n 次。各项之间以逗号分隔。 |
| […n] | 指示前面的项可以重复 n 次。每一项由空格分隔。 |
| ; | Transact-SQL 语句终止符。虽然在此版本的 SQL Server 中大部分语句不需要分号,但将来的版本需要分号。 |
| 语法块的名称。此约定用于对可在语句中的多个位置使用的过长语法段或语法单元进行分组和标记。可使用语法块的每个位置由括在尖括号内的标签指示:<标签>。 集是表达式的集合,例如 <分组集>;列表是集的集合,例如 <组合元素列表>。 |
4.2 如何给标识符起名
4.2.1 标识符分类
大多情况下标识符是必不可少的,但是是否有标识符可以选择。数据库共定义了两种标识符,规则标识符和界定标识符。
4.2.2 规则标识符
严格准守相关规则的标识符叫规则标识符,凡是有规则的都不必使用界定
4.2.3 界定标识符
4.2.4 标识符规则
标识符首字母必须是以下两种情况
- 首字母必须是规定的字符
-
4.2.5 对象命名规则
4.2.6 事例的命名规则
4.3 常量
4.3.1 数字常量
定义:数字常量是规则公式最简单的组成部分。包括数字、前导减号(可选)和小数点(可选)
- 事例:5.0、6、-5。下面是一些无效的数字常量的示例:1-、1A、3、4。
说明:
定义:用双引号(“”)括起来的0个或者多个字符组成的序列
- 存储:每个字符串尾自动加一个 ‘\0’ 作为字符串结束标志
4.3.3 日期和时间常量
| 常数 | 值 | 描述 | | —- | —- | —- | | vbSunday | 1 | 星期日 | | vbMonday | 2 | 星期一 | | vbTuesday | 3 | 星期二 | | vbWednesday | 4 | 星期三 | | vbThursday | 5 | 星期四 | | vbFriday | 6 | 星期五 | | vbSaturday | 7 | 星期六 | | vbUseSystemDayOfWeek | 0 | 由系统设置定义每周的第一天是星期几。 | | vbFirstJan1 | 1 | 使用包含 1 月 1 日的星期(默认)。 | | vbFirstFourDays | 2 | 使用第一个至少包含新的年中四天的星期。 | | vbFirstFullWeek | 3 | 使用某年的第一个整周。 |
4.3.4 符号常量
- 定义:符号常量是在C语言中,可以用一个标识符来表示一个常量,这个标识符称之为符号常量
特点:编译后写在代码区,不可寻址,不可更改,属于指令的一部分
4.4 变量
4.4.1 全局变量
全局变量既可以是某对象函数创建,也可以是在本程序任何地方创建。全局变量是可以被本程序所有对象或函数引用
4.4.2 局部变量
局部变量又可称之为内部变量。由某对象或某个函数所创建的变量通常都是局部变量,只能被内部引用,而无法被其它对象或函数引用
4.4.3 批和脚本
批处理(batch),也称为bai批处理脚本。du顾名思义,批zhi处理就是对dao某对象进行批量的处理zhuan。批处理文shu件的扩展名为bat
批处理包含两类:dos批处理和ps批处理。ps批处理是基于强大的图片编辑软件photoshop的,用来批量处理图片的脚本;而dos批处理则是基于dos命令的,用来自动地批量地执行dos命令以实现特定操作的脚本
批处理属于脚本。脚本的含义比较大,批处理只是其中的一种语言,脚本的语言很多4.5 运算符和表达式
4.5.1 算术运算符
定义:用来处理四则运算的符号,这是最简单,也最常用的符号,尤其是数字的处理,几乎都会使用到算术运算符号
事例:+(加号) 加法运算 (3+3)
–(减号) 减法运算 (3–1) 负 (–1)
(星号) 乘法运算 (33)
/(正斜线) 除法运算 (3/3)
%(百分号) 求余运算10%3=1 (10/3=3·······1)
^(乘方) 乘幂运算 (3^2)
! (阶乘) 连续乘法 (3!=321=6)
|X| x为任何数 (绝对值) 求正 (|1|)4.5.2 比较运算符
定义:比较运算符是指可以使用下列运算符比较两个值。当用运算符比较两个值时,结果是一个逻辑值,不是 TRUE(成立) 就是 FALSE(不成立)的运算符号
事例:=(等号) 等于 (A1=B1)
(大于号) 大于 (A1>B1)
<(小于号) 小于 (A1
<=(小于等于号) 小于或等于 (A1<=B1)
<>(不等号) 不相等 (A1<>B1)
===(全等)
!==(不全等)4.5.3 逻辑运算符
定义:逻辑运算符通常用于
布尔型(逻辑)值。这种情况下,它们返回一个布尔值。然而,&&和||运算符会返回一个指定操作数的值,因此,这些运算符也用于非布尔值。这时,它们也就会返回一个非布尔型值- 事例:
| 运算符 | 语法 | 说明 |
| :—- | :—- | :—- |
| 逻辑与,AND(
&&) |_expr1_ && _expr2_| 若expr**1**可转换为true,则返回expr**2**;否则,返回expr**1**。 | | 逻辑或,OR(||) |_expr1_ || _expr2_| 若expr**1**可转换为true,则返回expr**1**;否则,返回expr**2**。 | | 逻辑非,NOT(!) |!_expr_| 若expr可转换为true,则返回false;否则,返回true。 |
4.5.4 连接运算符
- 定义:把两个字符串合并成一个字符串
- 事例:string c = “ABCD” + “EFGH”,最后字符串变量c里面储存的是字符串“ABCDEFGH”
4.5.5 按位运算符
按bai位运算符是把两du个操作数分别转换成二进制数,如zhi果两个二dao进制数长度不一样,在短zhuan的左shu边补0,补到一样的长度,然后对两个二进制数按对应的位进行运算4.5.5.1 二进制位运算
a = 1010 0101;
b = 0111 0011;4.5.5.2 取反运算
b = 0111 0011;
~b = 1000 1100;//结果
注:1变为0,0变为1.4.5.5.3 按位与&运算
a = 1010 0101;
b = 0111 0011;
a&b = 0010 0001;
注:只有两个运算对象相应位置都为1时,结果才为1,
(只两个运算对象相应位置都为真时,才为真)4.5.5.4 按位或 | 运算
a = 1010 0101;
b = 0111 0011;
a|b= 1111 0111;//结果
注:运算对象相应位置有1,结果就是1;
(只两个运算对象相应位置有一个为真时,就为真)4.5.5.5 按位异或^运算
a = 1010 0101;
b = 0111 0011;
a^b= 1101 0110;//结果
注:运算对象相应位置相同位0,不同为1。4.5.5.6 左移:<<
int a = 4;
a = a<<2;
System.out.println(“a=”+a);
运算结果 16;
左移是运算对象乘以2的n次方;4.5.5.7 右移:>>
int a = 8;
a = a>>2;
System.out.println(“a=”+a);
运算结果 2;
对象为正时,右移是除以2的n次方;4.5.6 运算符的优先级
4.5.7 什么是表达式
表达式指运算符与圆括号把变量、常量、函数等运算连接成一个有意义的式子
4.5.8 T-SQL 表达式的分类
4.6 T-SQL利器-通配符
4.6.1 %
- 描述:匹配任意长度的字符,甚至包括零字符
-
4.6.2 _
描述:匹配任意单个字符
-
4.6.3 [字符集合]
描述:匹配字符集合中的任意一个字符
-
4.6.4 [^]或[!]
描述:匹配不在括号中的任何字符
-
4.7 T-SQL语言中的注释
4.7.1 单行注释—···
描述:单行注释以两个减号“—”开始,作用范围是从注释符号开始到一行的结束
事例:—CREATE TABLE temp
—(id INT PRIMARY KEY, hobby VARCHAR(100) NULL)
4.7.2 多行注释/···/
描述:多行注释作用于某一代码块,该种注释使用斜杠星型(/*/),使用这种注释时,编译器将忽略从(/)开始后面的所有内容,知道遇到(*/)为止
事例:/*CREATE TABLE temp
(id INT PRIMARY KEY, hobby VARCHAR(100) NULL)*/
5 掌握T-SQL语句
5.1 数据定义语句(DDL)
5.1.1 CREATE的应用
—创建一个数据表emp1
USE sample
CREATE TABLE emp1
(
id INT PRIMARY KEY,
name VARCHAR(25) NOT NULL,
deptId CHAR(2) NOT NULL,
salary SMALLMONEY NULL
);5.1.2 DROP的功能
5.1.3 ALTER的功能
—修改数据库名称
ALTER DATABASE sample
MODIFY NAME = company;5.2 数据操作语句(DML)
5.2.1 数据的插入-INSERT
创建一个表teacher
USE sample
CREATE TABLE teacher
(
id INT CONSTRAINT PK_teacher_id PRIMARY KEY NOT NULL,
name VARCHAR(20) NOT NULL,
birthday DATE,
sex VARCHAR(4),
cellphone VARCHAR(18)
);
- 向表中插入一条数据
INSERT INTO teacher VALUES(1,’张三’,’1987-02-14’,’男’,’010-0018611’);
- 向表中插入多条数据
INSERT INTO teacher VALUES
(2,’李四’,’1988-11-21’,’女’,’010-0018624’),
(3,’王五’,’1986-12-05’,’男’,’010-0018678’),
(4,’赵六’,’1980-6-5’,’女’,’010-0018699’);
5.2.2 数据的更改-UPATE
- 修改其中一条记录
UPDATE teacher
SET birthday = ‘1987-03-20’, cellphone = ‘010-0018600’
WHERE id = 1;
- 修改多条记录为一个值
SELECT FROM teacher;
UPDATE teacher SET cellphone = ‘010-01008611’;
SELECT FROM teacher;
5.2.3 数据的删除-DELETE
- 删除表中一行记录
DELETE FROM teacher WHERE id = 1;
- 删除表中所有记录
5.2.4 数据的查询-SELECT
—创建表stu_info
CREATE TABLE stu_info
(
s_id INT CONSTRAINT FK_s_id PRIMARY KEY,
s_name VARCHAR(20),
s_score INT,
s_sex CHAR(2),
s_age VARCHAR(90)
);
—给表stu_info赋值
INSERT INTO stu_info VALUES
(1,’许三’,98,’男’,18),
(2,’张靓’,70,’女’,19),
(3,’王宝’,25,’男’,18),
(4,’马华’,10,’男’,20),
(5,’李岩’,65,’女’,18),
(6,’刘杰’,88,’男’,19);
- 查询数据表stu_info的所有信息
SELECT * FROM stu-info;
- 查询学生表中的姓名和成绩
SELECT s_name, s_score FROM stu_info;
- 查询所有学生成绩减少5分后姓名和成绩
SELECT s_name, s_score, s_score-5 AS new_score FROM stu_info;
- 查询前3名学生的所有信息—分组查询
SELECT TOP 3 * FROM stu_info ORDER BY s_score DESC;
- 查询性别不为男的所有学生信息—非查询
SELECT FROM stu_info WHERE NOT s_sex = ‘男’;
等价于
SELECT FROM stu_info WHERE s_sex <> ‘男’;
等价于
SELECT * FROM stu_info WHERE s_sex = ‘女’;
- 查询成绩大于80分的男同学信息—合并条件
SELECT * FROM stu_info WHERE s_sex = ‘男’ AND s_score > 80;
- 查询姓马的同学的所有信息—模糊查询
SELECT * FROM stu_info WHERE s_name LIKE ‘马%’;
- 查询成绩在50到90之间的学生信息—区间查询
SELECT * FROM stu_info WHERE s_score BETWEEN 50 AND 90;
5.3 数据控制语句(DCL)
5.3.1 授予权限-GRANT
GRANT UPDATE, DELETE ON stu_info TO guest WITH GRANT OPTION;
5.3.2 取消权限-DENY
DENY UPDATE ON stu_info TO guest CASCADE;
5.3.3 收回权限-REVOKE
DEVOKE DELETE ON stu_info FROM guest;
5.4 其他基本语句
5.4.1 数据声明-DECLARE
DECLARE @username VARCHAR(20)
DECLARE @pwd VARCHAR(20)
5.4.2 数据赋值-SET
SET @username= ‘newadmin’
SET @pwd = ‘newpwd’
5.4.3 数据输出-PRINT
PRINT ‘用户名:’+@username+’ 密码:’+@pwd;
—用户名:newadmin 密码:newpwd
-
5.5 流程控制语句
5.5.1 BEGIN···END语句
DECLARE @count INT;
SELECT @count = 0;
WHILE @count < 10
BEGIN
PRINT ‘count = ‘+CONVERT(VARCHAR(8), @count)
SELECT @count = @count +1
END
PRINT ‘loop over count = ‘+ CONVERT(VARCHAR(8), @count);
/ count = 0
count = 1
count = 2
count = 3
count = 4
count = 5
count = 6
count = 7
count = 8
count = 9
loop over count = 10 /5.5.2 IF···ELSE语句
DECLARE @age INT;
SET @age = 40
IF @age < 30
PRINT ‘This is a young man!’
ELSE
PRINT ‘This is a old man!’
—This is a old man!5.5.3 CASE语句
USE sample
SELECT s_id, s_name,
CASE s_name
WHEN ‘马华’ THEN ‘班长’
WHEN ‘许三’ THEN ‘学习委员’
WHEN ‘刘杰’ THEN ‘体育委员’
ELSE ‘无’
END AS ‘职位’
FROM stu_info;
/ s_id s_name 职位
1 许三 学习委员
2 张靓 无
3 王宝 无
4 马华 班长
5 李岩 无
6 刘杰 体育委员 /5.5.4 WHILE语句
DECLARE @num INT
SET @num = 10
WHILE @num > -1
BEGIN
IF @num >5
BEGIN
PRINT ‘@num 等于’ +CONVERT(VARCHAR(4), @num)+ ‘大于5循环继续执行’;
SET @num = @num -1
CONTINUE
END
ELSE
BEGIN
PRINT ‘@num 等于’+ CONVERT(VARCHAR(4), @num);
BREAK
END
END
PRINT ‘循环终止之后@mun等于’ + CONVERT(VARCHAR(4), @num);
/ @num 等于10大于5循环继续执行
@num 等于9大于5循环继续执行
@num 等于8大于5循环继续执行
@num 等于7大于5循环继续执行
@num 等于6大于5循环继续执行
@num 等于5
循环终止之后@mun等于5 /5.5.5 GOTO语句
USE sample
BEGIN
SELECT s_name FROM stu_info;
GOTO jump
SELECT s_score FROM stu_info;
jump:
PRINT ‘第二条SELECT语句没有执行’;
END
/ s_name
许三
张靓
王宝
马华
李岩
刘杰 /5.5.6 WAITFOR语句
DECLARE @name VARCHAR(20)
SET @name = ‘admin’
BEGIN
WAITFOR DELAY ‘00:00:05’
PRINT @name
END;—admin5.5.7 RETURN语句
事例:
CREATE PROCEDURE findjobs @nm sysname = NULL
AS
IF @nm IS NULL
BEGIN
PRINT ‘You must give a user name’
RETURN
END
ELSE
BEGIN
SELECT o.name, o.id, o.uid
FROM sysobjects o INNER JOIN master..syslogins l
ON o.uid = l.sid
WHERE l.name = @nm
END;
说明:
一个批处理中只要存在一处语法错误,整个批处理都无法通过编译
- 批处理中可以包含多个存储过程,但除第一个过程外,其他存储过程前面都必须使用EXECTUE关键字
- 某些特殊的SQL指令不能和别的SQL语句共存在一个批处理中,如CREATE TABLE和CREATE VIEW语句
- 所有的批处理使用GO作为结束的标志,当编译器读到GO的时候就把GO前面的所有语句当做一个批处理,然后打包成一个数据包发给服务器
- GO本身不是T-SQL的组成部分,只是一个用于表示批处理结束的前端指令
- CREATE DEFAULT、CREATE FUNCTION、CREATE PROCEDURE、CREATE RULE、CREATE SCHEMA、CREATE TRIGGER和CREATE VIEW语句不能再批处理中与其他语句组合使用
- 批处理必须以CREATE语句开始,所有跟在此批处理后的其他语句将被解释为第一个CREATE语句定义的一部分
- 不能再删除一个对象之后,在同一批处理中再次引用这个对象
- 如果EXECUTE语句是批处理中的第一句,则不需要EXECUTE关键字;如果是第一句,则需要EXECUTE关键字
- 不能再定义一个CHECK约束之后,在同一个批处理中使用
- 不能再修改表的一个字段之后,立即在同一个批处理中引用这个字段
- 使用SET语句设置的某些选项值不能引用于同一个批处理中的查询
-
6 认识函数
6.1 SQL Server函数简介
函数表示对输入参数值返回一个具有特定关系的值,SQL Server提供了大量丰富的函数,在进行数据库管理以及数据的查询和操作是将精彩地使用到各种函数
6.2 字符串函数
6.2.1 ASCII()函数
描述:根据字符求代码值
事例:SELECT ASCII(‘s’), ASCII(‘sql’), ASCII(1);—115,115,49
6.2.2 CHAR()函数
描述:根据代码值求字符
事例:SELECT CHAR(115), CHAR(49);—s,1
6.2.3 LEFT()函数
描述:左截取字符
事例:SELECT LEFT(‘football’, 4);—foot
6.2.4 RIGHT()函数
描述:右截取字符
事例:SELECT RIGHT(‘football’, 4);—ball
6.2.5 LTRIM()函数
描述:去除字符串左边空格
事例:SELECT ‘(‘+’ book ‘+’)’, ‘(‘+ LTRIM(‘ book ‘)+’)’;—( book ), (book )
6.2.6 RTRIM()函数
描述:去除字符串左边空格
事例:SELECT ‘(‘+’ book ‘+’)’, ‘(‘+ RIGHT(‘ book ‘)+’)’;—( book ), ( book)
6.2.7 STR()函数
描述:数值型转换成字符型
事例:SELECT STR(3141.59, 6, 1), STR(123.45, 2, 2);—3141.6,**
6.2.8 REVERSE(s)函数
描述:字符串反转(逆序)函数
事例:SELECT REVERSE (‘abc’);—cba
6.2.9 LEN(ser)函数
描述:计算字符串长度
事例:SELECT LEN(‘not’), LEN(‘日期’), LEN(12345);—3,2,5
6.2.10 CHARINDEX函数
描述:匹配字符串开始位置
事例:SELECT CHARINDEX(‘a’, ‘banana’), CHARINDEX(‘a’, ‘banana’, 4), CHARINDEX(‘na’, ‘banana’, 4);—2,4,5
6.2.11 SUBSTRING()函数
描述:从中提取字符
事例:SELECT SUBSTRING(‘elephant’,4,2);—ph
6.2.12 LOWER()函数
描述:大写转换成小写
事例:SELECT LOWER (‘BEAUTIFUL’), LOWER(‘Well’);—beautiful,well
6.2.13 UPPER()函数
描述:小写转换成大写
事例:SELECT UPPER(‘black’), UPPER(‘BLacK’);—BLACK,BLACK
6.2.14 REPLACE(s,s1,s2)函数
描述:将字符串进行替换
事例:SELECT REPLACE(‘xxx.sqlserver2008.com’, ‘x’, ‘w’);—www.sqlsorvor2008.com
6.3 数学函数
6.3.1 ABS(x)函数
描述:返回绝对值
事例:SELECT ABS(2), ABS(-3.3), ABS(-33);—2, 3.3, 33
6.3.2 PI()函数
描述:返回圆周率
事例:SELECT PI();—3.14159265358979
6.3.3 SQRT(x)函数
描述:返回平方根
事例:SELECT SQRT(9), SQRT(40);—3, 6.32455532033676
6.3.4 RAND()函数
描述:获取随机数
事例:SELECT RAND(), RAND(), RAND();—返回三个小余1的任意值
6.3.5 ROUND(x,y)函数
描述:四舍五入
事例:SELECT ROUND(1.38, 1), ROUND(1.38, 0);—1.40, 1.00
SELECT ROUND(232.38, -1), ROUND(232.38, -2);—230.00, 200.00
6.3.6 SIGN(x)函数
描述:符号函数
事例:SELECT SIGN(-21), SIGN(0), SIGN(21);— -1, 0, 1
6.3.7 CEILING(x)函数
描述:获取不小于参数的最小整数值
事例:SELECT CEILING(-3.35), CEILING(3.35);— -3, 4
6.3.8 FLOOR(x)函数
描述:获取不大于参数的最大整数值
事例:SELECT FLOOR(-3.35), FLOOR(3.35);— -4, 3
6.3.9 POWER(x,y)函数
描述:幂运算平方或是根
事例:SELECT POWER(2, 2), POWER(2.00, -2);—4, 0.25
6.3.10 SQUARE(x)函数
描述:幂运算平方
-
6.3.11 EXP(x)函数
描述:以1为底的参数方
事例:SELECT EXP(3), EXP(-3), EXP(0);—20.0855369231877, 0.0497870683678639, 1
6.3.12 LOG(x)函数
描述:以1为基数的对数运算
事例:SELECT LOG(3);—1.09861228866811
6.3.13 LOG10(x)函数
描述:以10为基数的对数运算
事例:SELECT LOG10(3);—0.4771271254719662
6.3.14 RADIANS(x)函数
描述:以度数值返回弧度值
事例:SELECT RADIANS(800), RADIANS(360), RADIANS(60);—13, 6, 1
6.3.15 DEGREES(x)函数
描述:返回以弧度指定的角的相应角度
事例:SELECT DEGREES(13), DEGREES(6), DEGREES(1);—744, 343, 57
6.3.16 SIN(x)函数
描述:正弦函数
事例:DECLARE @angle float
SET @angle = 45.175643
SELECT ‘The SIN of the angle is: ‘ + CONVERT(varchar,SIN(@angle))
—The SIN of the angle is: 0.9296076.3.17 ASIN(x)函数
描述:返回以弧度表示的角,其正弦为指定 float 表达式。也称为反正弦
事例:DECLARE @angle float
SET @angle = -1.00
SELECT ‘The ASIN of the angle is: ‘ + CONVERT(varchar, ASIN(@angle))
—The ASIN of the angle is: -1.57086.3.18 COS(x)函数
描述:返回指定表达式中以弧度表示的指定角的三角余弦
事例:DECLARE @angle float
SET @angle = 14.78
SELECT ‘The COS of the angle is: ‘ + CONVERT(varchar,COS(@angle))
—The COS of the angle is: -0.5994656.3.19 ACOS(x)函数
描述:返回其余弦是所指定的 float 表达式的角(弧度);也称为反余弦
事例:SET NOCOUNT OFF;
DECLARE @cos float;
SET @cos = -1.0;
SELECT ‘The ACOS of the number is: ‘ + CONVERT(varchar, ACOS(@cos));
—The ACOS of the number is: 3.141596.3.20 TAN(x)函数
描述:返回输入表达式的正切值
事例:SELECT TAN(PI()/2);—1.63312393531954E+16
6.3.21 ATAN(x)函数
描述:返回以弧度表示的角,其正切为指定的 float 表达式。它也称为反正切函数
- 事例:SELECT ‘The ATAN of -45.01 is: ‘ + CONVERT(varchar, ATAN(-45.01));
—The ATAN of -45.01 is: -1.54858
6.4 数据类型转换函数
6.4.1 描述
在同时处理不同数据类型的值时,SQL Server一般会自动尽心隐式类型转换。这对于数据类型相近的数值是有效的,比如int和float,但是对于其他数据类型,例如整型和字符型数据,隐式转换就无法实现了,此时必须使用显示转换。
6.4.2 分类
为了实现这种转换,T-SQL提供了两个显示转换的函数,分别是CAST函数和CONVERT函数。
6.4.2.1 CAST函数
SELECT CAST(‘201130’ AS DATE), —2020-11-30
CAST(100 AS CHAR(3)); —100
6.4.2.2 CONVERT函数
SELECT CONVERT(TIME, ‘2020-10-01 12:11:10’);—12:11:10.0000000
6.5 文本和图像函数
6.5.1 TEXTPTR函数
- 创建一个数据表t1并赋值
CREATE TABLE t1 (c1 INT NOT NULL, c2 TEXT)
INSERT INTO t1 VALUES (‘1’, ‘This is text.’)
- 返回t1表中c2列的文本指针值
SELECT TEXTPTR(c2) FROM t1 WHERE c1 = 1;—0xFFFFD107000000007200000001000000
6.5.2 TEXTVALID函数
- 描述:检查文本字段是否有效
事例:SELECT ‘This is text.’ = TEXTVALID(‘t1.c2’, TEXTPTR(c2)) FROM t1;—1
6.6 日期和时间函数
6.6.1 GETDATE()函数
描述:获取系统当前时间的函数
事例:SELECT GETDATE();—2020-12-15 11:41:45.953
6.6.2 GETUTCDATE()函数
描述:获取当前世界标准时间的函数
事例:SELECT GETUTCDATE();—2020-12-15 03:41:07.950
6.6.3 DAY(d)函数
描述:获取天数的函数
事例:SELECT DAY (‘2020-12-15 01:01:01’);—15
6.6.4 MONTH(d)函数
描述:获取月数的函数
事例:SELECT MONTH (‘2020-12-15 01:01:01’);—12
6.6.5 YEAR(d)函数
描述:获取年份的函数
事例:SELECT YEAR (‘2020-12-15 01:01:01’);—2020
6.6.6 DATENAME(dp, d)函数
描述:返回日期中指定部分字符串值的函数
事例:SELECT DATENAME (YEAR, ‘2020-12-15 11:04:36’) —2020
,DATENAME (WEEKDAY, ‘2020-12-15 11:04:36’) —星期二
,DATENAME (DAYOFYEAR, ‘2020-12-15 11:04:36’); —3506.6.7 DATEPART(dp, d)函数
描述:获取日其中指定部分的整数值的函数
事例:SELECT DATEPART(YEAR, ‘2020-12-15 12:10:30.123’) —2020
,DATEPART(MONTH, '2020-12-15 12:10:30.123') --12<br /> ,DATEPART(DAY, '2020-12-15 12:10:30.123') --15<br /> ,DATEPART(DAYOFYEAR, '2020-12-15 12:10:30.123') --350<br /> ,DATEPART(WEEKDAY, '2020-12-15 12:10:30.123') --3<br />,DATEPART(HOUR, '2020-12-15 12:10:30.123') --12<br />,DATEPART(MINUTE, '2020-12-15 12:10:30.123') --10<br />,DATEPART(SECOND, '2020-12-15 12:10:30.123'); --30
说明:DATEPART 可用于选择列表 WHERE、HAVING、GROUP BY 和 ORDER BY 子句中。
6.6.8 DATEADD(dp, num, d)函数
描述:计算加固定值的日期和时间函数
事例:SELECT DATEADD (YEAR, 1, ‘2020-12-15 11:04:36’) —2021-12-15 11:04:36.000
,DATEADD (MONTH, 2, '2020-12-15 11:04:36') --2021-02-15 11:04:36.000<br /> ,DATEADD (HOUR, 3, '2020-12-15 11:04:36'); --2020-12-15 14:04:36.000<br />
6.7 系统函数
6.7.1 COL_LENGTH(‘表名’,’字段名’)
描述:返回表中指定字段的长度值
事例:SELECT COL_LENGTH(‘stu_info’,’s_name’);—20
6.7.2 COL_NAME(OBJECT_ID(‘数据库名.表名’),列数)
描述:返回表中指定字段的名称
事例:SELECT COL_NAME(OBJECT_ID(‘sample.dbo.stu_info’),2);—s_name
6.7.3 DATALENGTH(字段名)
描述:返回指定字段的实际长度
事例:SELECT DATALENGTH(s_name) FROM stu_info WHERE s_name=’许三’;—4
6.7.4 DB_ID(‘数据库名’)
描述:返回数据库的编号
事例:SELECT DB_ID(‘sample’),DB_ID(‘SBO-COMMON’);—16, 9
6.7.5 DB_NAME()
描述:返回数据库的名称
事例:SELECT DB_NAME(),DB_NAME(DB_ID(‘SBO-COMMON’));—sample, SBO-COMMON
6.7.6 HOST_ID()
描述:返回计算机的ID号
-
6.7.7 HOST_NAME()
描述:返回计算机的名称
事例:SELECT HOST_NAME();—LAPTOP-EM7DPU0U
6.7.8 BOJECT_ID(‘数据库名.表名’)
描述:返回数据库对象编号
事例:SELECT OBJECT_ID(‘sample.dbo.stu_info’);—357576312
6.7.9 SUSER_SID(‘用户名’)
描述:返回指定登录名的安全标识号
事例:SELECT SUSER_SID(‘EM7DPU0U\Administrator’);—NULL
6.7.10 USER_NAME()
描述:返回数据库的用户名
-
7 Transact-SQL查询
7.1 查询工具的使用
7.1.1 编辑查询
SELECT * FROM sample.dbo.stu_info;
7.1.2 查询结果的显示方法
以网格显示结果:默认显示方法
- 以文本格式显示结果
- 将结果保存到文件

7.2 使用SELECT进行查询
—创建表fruits
USE sample
CREATE TABLE fruits
(
f_id CHAR(10) CONSTRAINT PK_fruits_f_id PRIMARY KEY —水果id
,s_id INT NOT NULL —供应商id
,f_name VARCHAR(255) NOT NULL —水果名称
,f_price DECIMAL(8,2) NOT NULL —水果价格
);
—给表fruits赋值
INSERT INTO fruits (f_id,s_id,f_name,f_price) VALUES
(‘A1’,101,’apple’,5.2)
,(‘B1’,101,’blackberry’,10.2)
,(‘O1’,102,’orange’,11.2)
,(‘M1’,105,’melon’,8.2)
,(‘M2’,106,’mango’,15.6);
7.2.1 使用星号和列名
- 查询表中所有字段:SELECT * FROM fruits;
按列名查询表字段:SELECT f_id, f_name, f_price FROM fruits;
7.2.2 使用DISTINCT取消重复
SELECT DISTINCT s_id FROM fruits;—101、102、105、106
7.2.3 使用TOP返回前n行
SELECT TOP 3 s_id FROM fruits;—101、101、105
SELECT TOP 30 * FROM fruits;—查询前30%的全部数据7.2.4 修改列标题
SELECT f_id AS 编号, f_price AS 价格 FROM fruits;
7.2.5 在查询结果集中使用字符串
7.2.6 查询的列为表达式
7.4 使用聚合函数统计汇总
7.4.1 SUM()函数
描述:求列总计
- 事例:101供应商的水果总价
SELECT SUM(f_price) AS sum_price
FROM fruits
WHERE s_id = 101;—15.4
7.4.2 AVG()函数
- 描述:求列平均值
- 事例:所有供应商的水果均价
SELECT AVG(f_price) AS avg_price
FROM fruits
GROUP BY s_id;
7.4.3 MAX()函数
- 描述:求列最大值
事例:SELECT MAX(f_price) AS max_price FROM fruits;—15.6
SELECT MAX(f_name) AS max_name FROM fruits;—orange
7.4.4 MIN()函数
描述:求列最小值
事例:SELECT MIN(f_name) AS min_name FROM fruits;—apple
7.4.5 COUNT()函数
描述:统计总数
事例:SELECT COUNT(DISTINCT s_id) AS 供应商总数 FROM fruits;—4
SELECT COUNT(*) AS 总行数 FROM fruits;—5
7.5 嵌套查询
—新建表suppliers
CREATE TABLE suppliers
(
s_id INT CONSTRAINT PK_suppliers_s_id PRIMARY KEY NOT NULL
,s_name VARCHAR(50) NOT NULL
,s_city VARCHAR(25) NOT NULL
);—给表suppliers赋值
INSERT INTO suppliers (s_id, s_name, s_city) VALUES
(101, ‘北京绿色水果有限责任公司’, ‘beijing’)
,(102, ‘天津绿色水果有限责任公司’, ‘tianjin’)
,(103, ‘上海绿色水果有限责任公司’, ‘shanghai’)
,(104, ‘重庆绿色水果有限责任公司’, ‘chongqing’)
,(105, ‘深圳绿色水果有限责任公司’, ‘shenzhen’)
,(106, ‘西安绿色水果有限责任公司’, ‘xian’);7.5.1 使用比较运算符=
描述:返回一个多维表达式 (MDX) 的值是否等于另一个 MDX 表达式的值
- 事例:查询城市是tianjin的供应商编号和水果名称
SELECT s_id, f_name FROM fruits WHERE s_id =
(SELECT s_id FROM suppliers WHERE s_city = ‘tianjin’);—102, orange
延伸:有效的比较运算符还有 = 、 <> 、 != 、>、>= 、 !> 、< 、<= 、!<
7.5.2 使用IN关键字
描述:确定指定的值是否与子查询或列表中的值相匹配
- 事例:查询水果编号是A1的供应商名称
SELECT s_name FROM suppliers WHERE s_id IN
(SELECT s_id FROM fruits WHERE f_id = ‘A1’);—北京绿色水果有限责任公司
—创建表tbl1和tbl2
CREATE TABLE tbl1 (num1 INT NOT NULL);
CREATE TABLE tbl2 (num2 INT NOT NULL);
—给表tbl1和tbl2赋值
INSERT INTO tbl1 VALUES(1),(5),(13),(27);
INSERT INTO tbl2 VALUES(6),(14),(11),(20);
7.5.3 使用ANY关键字
- 描述:以一个或多个结果集的形式将其返回给用户,SOME 和 ANY 是等效的
- 事例:查询tbl1表的num1大于任何一个tbl2中num2的值
SELECT num1 FROM tbl1 WHERE num1 > ANY (SELECT num2 FROM tbl2);—13,27
延伸
描述:比较标量值和单列集中的值
- 事例:查询tbl1表的num1大于所有的tbl2中num2的值
SELECT num1 FROM tbl1 WHERE num1 > ALL (SELECT num2 FROM tbl2);—27
延伸
描述:指定一个子查询,测试行是否存在
- 事例:查询是否存在供应商编号为106的供应商名称,若存在现实水果表的全部信息
SELECT * FROM fruits
WHERE EXISTS
(SELECT s_name FROM suppliers WHERE s_id = 106);
7.6 多表连接查询
7.6.1 相等链接
- 语法:INNER JOIN···ON···=
- 事例:查询供应商编号,供应商名称,水果名称和水果价格信息
SELECT S.s_id, s_name, f_name, f_price
FROM fruits F
INNER JOIN suppliers S
ON F.s_id = S.s_id;
7.6.2 不等连接
- 语法:INNER JOIN···ON···<>/>=/<=
- 事例:查询供应商编号,供应商名称,水果名称和水果价格信息
SELECT S.s_id, s_name, f_name, f_price
FROM fruits F
INNER JOIN suppliers S
ON F.s_id <> S.s_id;
7.6.3 带选择条件的连接
- 语法:INNER JOIN···ON···=···AND
- 事例:查询编号为101的供应商提供的水果编号、名称以及城市
SELECT F.f_id, F.f_name, S.s_city
FROM fruits F
INNER JOIN suppliers S
ON F.s_id = S.s_id AND F.s_id = 101;
7.6.4 自连接
- 语法:FROM table AS T1, table AS T2
- 事例:查询水果编号是A1的水果编号、水果名称及价格
SELECT F1.f_id, F1.f_name, F1.f_price
FROM fruits F1, fruits F2
WHERE F1.s_id = F2.s_id AND F1.f_id = ‘A1’;
7.7 外连接
7.7.1 左外连接
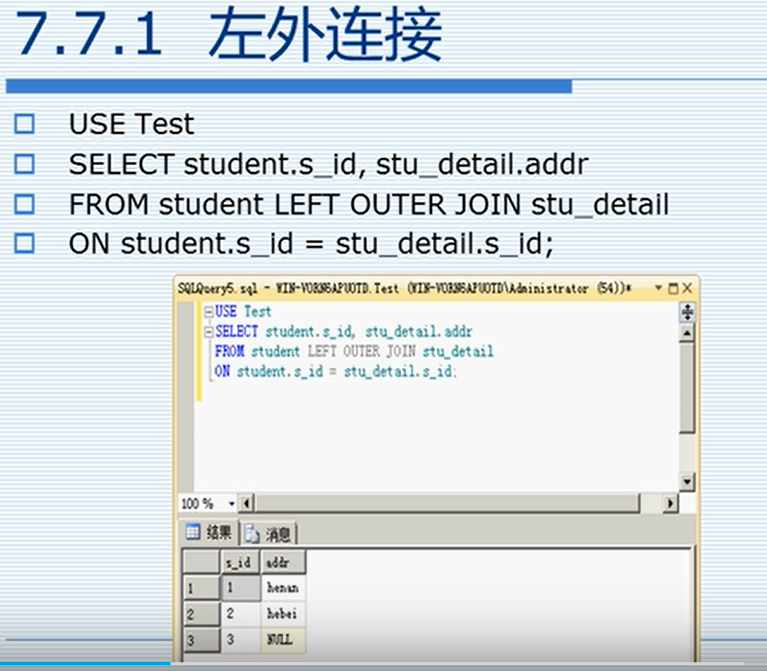
7.7.2 右外连接
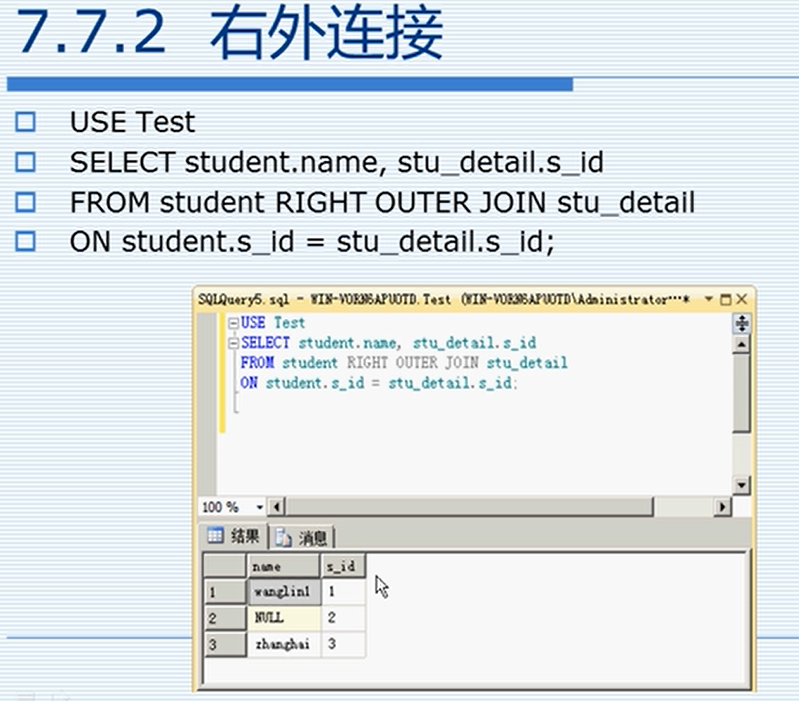
7.7.3 全外连接
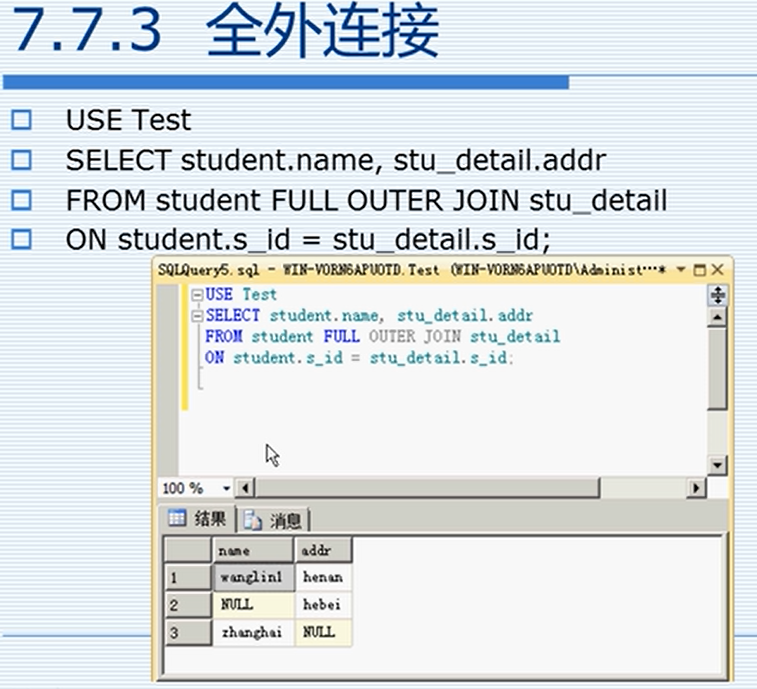
7.8 使用排序函数
7.8.1 ROW_NUMBER()函数
- 描述:按行分组排序
- 事例:按水果表的每一行分组显示
SELECT ROW_NUMBER() OVER (ORDER BY s_id ASC) AS ROWID FROM fruits;—1,2,3,4,5
7.8.2 RANK()函数
- 描述:按指定字段名分组(跳过)排序
- 事例:根据s_id不同,对水果明细跳跃式进行排序
SELECT RANK() (ORDER BY s_id ASC) AS RANKID FROM fruits;—1,1,3,4,5
7.8.3 DENSE_RANK()函数
- 描述:按指定字段名分组(不跳)排序
- 事例:按供应商编号,对水果明细不间断进行排序
SELECT DENSE_RANK() OVER (ORDER BY s_id ASC) AS RANKID FROM fruits;—1,1,2,3,4
7.8.4 NTILE()函数
- 描述:按指定数分组
- 事例:返回指定2组的水果明细
SELECT NTILE(2) OVER (ORDER BY s_id ASC) AS RANKID FROM fruits;—1,1,2,2,2
8 数据的更新
8.1 插入数据-INSERT
—新建数据表person
CREATE TABLE person
(
id INT NOT NULL CONSTRAINT PK_person_id PRIMARY KEY
,name VARCHAR(20) NOT NULL DEFAULT ‘’
,age INT NOT NULL DEFAULT 0
,info VARCHAR(50) NULL
);
—新建数据表person_old
CREATE TABLE person_old
(
id INT NOT NULL CONSTRAINT PK_person_old_id PRIMARY KEY
,name VARCHAR(20) NOT NULL DEFAULT ‘’
,age INT NOT NULL DEFAULT 0
,info VARCHAR(50) NULL
);
—给表person_old赋值并查询
INSERT INTO person_old VALUES
(8, ‘Harry’, 20, ‘student’)
,(9, ‘Backham’, 31, ‘ ‘);
SELECT * FROM person_old;
8.1.1 插入单行数据
- 语法:INSERT INTO···VALUES···
- 事例:
- 为person表插入一行数据
INSERT INTO person (id,name,age,info) VALUES (1,’Green’,21,’Lavyer’);
b. 不指定字段名插入数据并查询
INSERT INTO person VALUES (2,’Mary’,24,’musician’);
SELECT * FROM person;
8.1.2 插入多行数据
- 分别插入多行记录并查询表
INSERT INTO person (id,name, info) VALUES (3,’villain’, ‘sportsman’);
INSERT INTO person (id,name ) VALUES (4,’laura’);
SELECT * FROM person;
- 同时插入多行记录并查询表
INSERT INTO person (id,name,age,info) VALUES
(5,’Evans’,27,’secretary’),
(6,’Dale’,22,’cook’),
(7,’Edison’,28,’singer’);
SELECT * FROM person;
- 将一个表中的数据插入另一个表中并查询表
- 语法:INNER INTO···SELECT···
- 事例:
INSERT INTO person (id,name,age,info)
SELECT id,name,age,info FROM person_old;
SELECT * FROM person;
8.2 修改数据-UPDATE
8.2.1 修改单行数据
- 修改单行单个字段数据并查询
UPDATE person SET info = ‘driver’ WHERE id = 9;
SELECT * FROM person;
- 修改单行多个字段数据并查询
UPDATE person
SET info = ‘dancer’ ,age = 23
WHERE id = 4;
SELECT * FROM person;
8.2.2 修改多行数据
- 修改多行字段值并查询表
SELECT FROM person WHERE age BETWEEN 19 AND 22;
UPDATE person SET info = ‘student’ WHERE age BETWEEN 19 AND 22;
SELECT FROM person WHERE age BETWEEN 19 AND 22;
- 修改所有字段值并查询表
SELECT FROM person;
UPDATE person SET info = ‘vip’;
SELECT FROM person;
8.3 删除数据-DELETE
8.3.1 删除部分数据
SELECT FROM person;
DELETE FROM person WHERE age = 20;
SELECT FROM person;
8.3.2 删除所有数据
SELECT FROM person_old;
DELETE FROM person_old;
SELECT FROM person_old;
9 规则、默认和完整性约束
9.1 规则和默认概述
规则是对存储的数据表的列或用户定义数据类型中的值的约束,规则与其作用的表或用户定义数据类型是相互独立的,也就是说,对表或用户定义数据类型的任何操作与对其设置的规则不存在影响。
9.2 规则的基本操作
9.2.1 创建规则-CREATE RULE
USE sample;
GO
CREATE RULE rule_age
AS
@age > 0 AND @age < 50; —命令已成功完成。
9.2.2 把自定义规则绑定到列-EXEC sp_bindrule
EXEC sp_bindrule ‘rule_age’,’person.age’;—已将规则绑定到表的列。
9.2.3 验证规则作用
INSERT INTO person VALUES (10,’Jone’,50,’musician’);
SELECT * FROM person;
—列的插入或更新与先前的 CREATE RULE 语句所指定的规则发生冲突。该语句已终止。
9.2.4 取消规则绑定-EXEC sp_unbindrule
EXEC sp_unbindrule ‘person.age’;—已解除了表列与规则之间的绑定。
9.2.5 删除规则-DROP RULE
DROP RULE rule_age;—命令已成功完成。
说明:先解除规则才能删除规则,并且要确保删除的规则不被使用才可删除
9.3 默认的基本操作
9.3.1 创建默认-CREATE DEFAULT
CREATE DEFAULT default_info AS ‘student’;—(设置默认信息为学生)命令已成功完成。
9.3.2 把自定义默认绑定到列-EXEC sp_bindefault
EXEC sp_bindefault ‘default_info’, ‘person.info’;—已将规则绑定到表的列。
9.3.3 验证默认作用
INSERT INTO person (id,name,age) VALUES (12,’Worker’,22);
SELECT * FROM person;—info字段没有会默认为student.
9.3.4 取消默认绑定-EXEC sp_unbindefault
EXEC sp_unbindefault ‘person.info’;—已解除了表列与其默认值之间的绑定。
9.3.5 删除默认-DROP DEFAULT
DROP DEFAULT default_info;—命令已成功完成。
说明:先解除默认绑定才能删除
9.4 完整性约束
9.4.1 主键约束-PRIMARY KEY
9.4.1.1 新建表时设置主键
CREATE TABLE employee
(
id INT NOT NULL
,name VARCHAR(25) NOT NULL
,sex NVARCHAR(1) NULL
,deptid CHAR(20) NOT NULL
,salary FLOAT NOT NULL
CONSTRAINT PK_employee_id PRIMARY KEY (id)
);
9.4.1.2 创建表后设置主键
ALTER TABLE tbl1
ADD CONSTRAINT PK_tbl1_num1 PRIMARY KEY (num1);
9.4.1.3 删除主键约束
ALTER TABLE employee
DROP CONSTRAINT PK_employee_id;
9.4.1.3 设置联合主键
ALTER TABLE employee
ADD CONSTRAINT PK_employee_iddeptid PRIMARY KEY (id, deptid);
9.4.2 外键约束-FOREIGN KEY
—创建一个数据表dept
CREATE TABLE dept
(
id INT CONSTRAINT PK_dept_id PRIMARY KEY
,name VARCHAR(20) NOT NULL
,location VARCHAR(50) NULL
);
9.4.2.1 创建表后设置外键
ALTER TABLE emp
ADD CONSTRAINT FK_emp_deptid FOREIGN KEY (deptid) REFERENCES dept (id);
9.4.2.2 新建表时设置外键
CREATE TABLE emp1
(
id INT NOT NULL
,name VARCHAR(20) NOT NULL
,deptid INT NULL
,salary FLOAT
,CONSTRAINT PK_emp1_id PRIMARY KEY (id)
,CONSTRAINT FK_emp1_deptid FOREIGN KEY (deptid) REFERENCES dept (id)
);
9.4.2.3 删除外键
ALTER TABLE emp1
DROP CONSTRAINT FK_emp1_deptid;
9.4.3 唯一性约束-UNIQUE
9.4.3.1 创建表时唯一性约束
USE test
CREATE TABLE dept2
(
id INT NOT NULL CONSTRAINT PK_dept2_id PRIMARY KEY
,name VARCHAR(20) NOT NULL CONSTRAINT UQ_dept2_name UNIQUE
,location VARCHAR(50)
);
9.4.3.2 创建表后唯一性约束
USE sample
ALTER TABLE emp
ADD CONSTRAINT UQ_emp_name UNIQUE (name);
9.4.4 CHECK约束
ALTER TABLE employee
ADD CONSTRAINT CK_employee_salary CHECK (salary > 1800 AND salary < 3000);
9.4.5 DEFAULT约束
ALTER TABLE employee
ADD CONSTRAINT DF_employee_sex DEFAULT ‘男’ FOR sex;
9.4.6 NOT NULL约束
10 创建和使用索引
10.1 索引的含义和特点
数据库中若有2万条记录,现在要执行这样一个查询:SELECT * FROM talbt where num = 10000。如果没有索引,必须遍历整个表,知道num等于10000的这一行被找到为止;如果在num列上创建索引,SQL Server不需要任何扫描,直接在索引里面找10000,就可以得知这一行的位置。可见,索引的建立可以加快数据库的查询速度。
10.2 索引的分类
不同数据库中提供不同的索引类型,SQL Server中的索引有两种:聚集索引和非聚集索引。其区别是在物理数据的存储方式上。
10.3 索引的涉及原则
- 索引并发越多越好,一个表中如有大量的所有,不仅占用磁盘空间将增大,而且会影响INSERT、DELETE、UPDATE等语句的性能,因为当表中的数据更改的同事,索引也会进行调整和更新。
- 避免对经常更新的表进行过多的索引,并且索引中的列尽可能少。而对经常用于查询的字段应该创建索引,但要避免添加不必要的字段。
- 数据量小的表最好不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
- 在条件表达式中经查用到的不同值较多的列上建立索引,在不同值少的列上不要建立索引。比如在学生表的“性别”字段上只有“男”与“女”两个不同值,因此就无必要建立索引。如果建立索引不但不会提高查询效率,反而会严重降低更新速度。
- 当维一性是某种数据本身的特征时,指定维一索引。使用维一索引能够确保定义的列的数据完整性。提高查询速度。
在频繁进行排序或分组(即进行GROUP BY或ORDER BY操作)的列上建立索引,如果带排序的列由多个,可以在这些列上建立组合索引。
10.4 创建索引
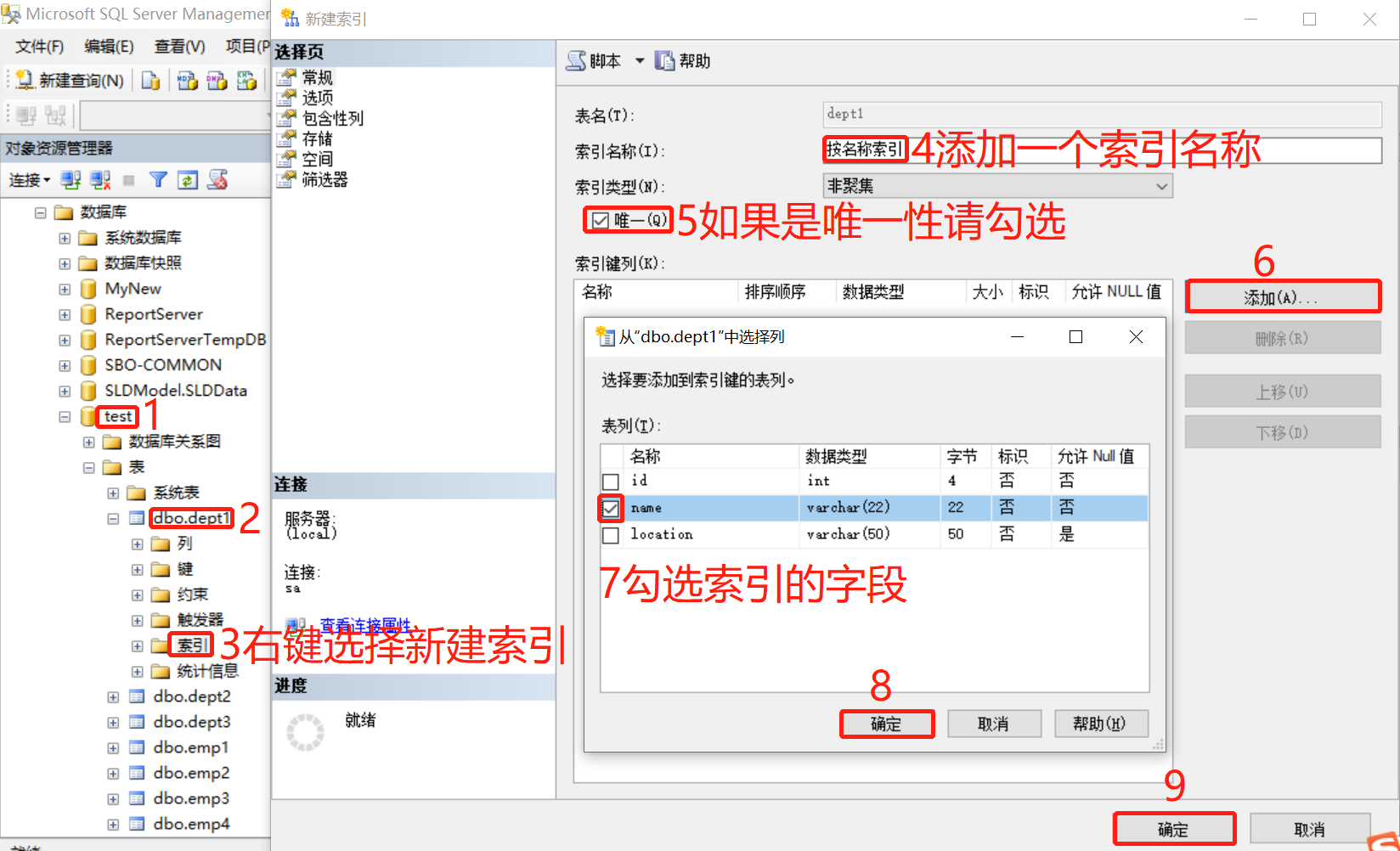
10.4.1 使用对象资源管理器创建索引
10.4.2 使用T-SQL语句创建索引
USE test
CREATE UNIQUE CLUSTERED INDEX Idx_name
ON emp1 (name DESC)
WITH
FILLFACTOR = 30;10.5 管理和维护索引
10.5.1 显示索引信息-EXEC sp_helpindex
USE test
EXEC sp_helpindex ‘emp1’;
—
10.5.2 重命名索引-EXEC sp_rename
USE test
EXEC sp_rename ‘emp1.idx_name’,’idx_name1’,’index’;
—注意: 更改对象名的任一部分都可能会破坏脚本和存储过程。(虽然提出注意,但是名称已经修改完毕)10.5.3 删除索引-DROP INDEX
USE test
GO
EXEC sp_helpindex ‘emp1’
DROP INDEX emp1.idx_name1
EXEC sp_helpindex ‘emp1’;11 事务和锁
11.1 事务管理
11.1.1 事务原理
11.1.2 事务管理的常用语句
语法:
- 建立一个事务:BEGIN TRANSACTION
- 提交事务:COMMIT TRANSACTION
- 事务失败时执行回滚操作:ROLLBACK TRANSACTION
- 保存事务:SAVE TRANSACTION
- 事例:
INSERT INTO stu_info VALUES
(7, ‘鹏飞’, 60, ‘男’, 18), (8, ‘王岚’, 90, ‘男’, 19), (9, ‘路飞’, 80, ‘男’, 18),
(10, ‘张霞’, 85, ‘女’, 18), (11, ‘魏波’, 70, ‘男’, 19), (12, ‘李婷’,74, ‘女’, 18)
DECLARE @studentCount INT
SELECT @studentCount = (SELECT COUNT(*) FROM stu_info)
IF @studentCount > 10
BEGIN
ROLLBACK TRANSACTION
PRINT ‘插入人数太多,插入失败!’
END
ELSE
BEGIN
COMMIT TRANSACTION
PRINT ‘插入成功!’
END;
11.1.3 事务的隔离级别
事务具有隔离性,不同事务中所使用的时间必须要喝其他事务进行隔离,在同一时间可以有很多个事务正在处理数据,但是每个数据在同一时刻只能有一个事务进行操作。如果将数据锁定,使用数据的事务就必须要排队等待,这样可以防止多个事务互相影响。但是如果有几个事务因为锁定了自己的数据,同时又在等待其他事务释放数据,则造成死锁。
11.2 锁
11.2.1 锁的内涵与作用
数据库中数据的并发操作经常发生,而对数据的并发操作会带来下面一些问题:脏读、幻读、非重复性读取、丢失更新。
11.2.2 锁的类型
11.2.3 减少死锁的策略
11.2.3.1 锁定行-ROWLOCK
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT * FROM person ROWLOCK WHERE id = 2;—2 Mary 24 musician
11.2.3.2 锁定数据库-TABLELOCK
SELECT * FROM person TABLELOCK WHERE info = ‘student’;—4 laura 23 dancer
11.2.3.3 建立两个事务并提交-BEGIN TRAN···COMMIT TRAN
BEGIN TRAN transaction1
UPDATE person SET info = ‘student’ WHERE id = 5;
WAITFOR DELAY ‘00:00:10’;
COMMIT TRAN;
BEGIN TRAN transaction2
SELECT * FROM person WHERE id = 5;
COMMIT TRAN;—-5 Evans 27 student
12 游标
12.1 认识游标
12.1.1 游标的概念
游标(Cursor)它使用户可逐行访问由SQL Server返回的结果集。使用游标(cursor)的一个主要的原因就是把集合操作转换成单个记录处理方式。用SQL语言从数据库中检索数据后,结果放在内存的一块区域中,且结果往往是一个含有多个记录的集合。游标机制允许用户在SQL server内逐行地访问这些记录,按照用户自己的意愿来显示和处理这些记录。
12.1.2 游标的优点
- 允许程序对由查询语句select返回的行集合中的每一行执行相同或不同的操作,而不是对整个行集合执行同一个操作
- 提供对基于游标位置的表中的行进行删除和更新的能力
游标实际上作为面向集合的数据库管理系统(RDBMS)和面向行的程序设计之间的桥梁,使这两种处理方式通过游标沟通起来
12.1.3 游标的分类
Transact-SQL游标
- 应用程序编程接口(API)服务器游标
-
12.2 游标的基本操作
12.2.1 声明游标
语法:DECLARE <游标名>CURSOR FOR
- 事例:
DECLARE cursor_fruit CURSOR FOR
SELECT f_name,f_price FROM fruits;—命令已成功完成。
12.2.2 打开游标
- 语法:OPEN 名称
事例:OPEN cursor_fruit;—命令已成功完成。
12.2.3 读取游标中的数据
语法:FETCH [ NEXT | PRIOR | FIRST | LAST] FROM { 游标名 | @游标变量名 } [ INTO @变量名 [,…] ]
- 说明:NEXT 取下一行的数据,并把下一行作为当前行(递增)。由于打开游标后,行指针是指向该游标第1行之前,所以第一次执行FETCH NEXT操作将取得游标集中的第1行数据。NEXT为默认的游标提取选项。
INTO @变量名[,…] 把提取操作的列数据放到局部变量中
- 事例:
FETCH NEXT FROM cursor_fruit;
WHILE @@FETCH_STATUS = 0
BEGIN
FETCH NEXT FROM cursor_fruit
END
12.2.4 关闭游标
- 语法:CLOSE 名称
事例:CLOSE cursor_fruit;—命令已成功完成。
12.2.5 释放游标
语法:DEALLOCATE 名称
事例:DEALLOCATE cursor_fruit;—命令已成功完成。
12.3 游标的运用
12.3.1 使用游标变量
DECLARE @VarCursor Cursor —声明游标变量
DECLARE cursor_fruit CURSOR FOR —创建游标
SELECT f_name, f_price FROM fruits
OPEN cursor_fruit —打开游标
SET @VarCursor = cursor_fruit —为游标变量赋值
FETCH NEXT FROM @VarCursor —从游标变量中读取值
WHILE @@FETCH_STATUS = 0 —判断FETCH语句是否执行成功
BEGIN
FETCH NEXT FROM @VarCursor —读取游标变量中的数据
END
CLOSE @VarCursor —关闭游标
DEALLOCATE @VarCursor —释放游标12.3.2 使用游标为变量赋值
DECLARE @fruitName VARCHAR,@fruitPrice DECIMAL —声明游标变量
DECLARE cursor_variable CURSOR FOR —创建游标
SELECT f_name,f_price FROM fruits WHERE s_id = 101;
OPEN cursor_variable —打开游标
FETCH NEXT FROM cursor_variable —从游标中读取值
INTO @fruitName,@fruitPrice —赋值给变量
PRINT ‘编号为101的供应商提供的水果种类和价格为:’
PRINT ‘类型:’+’ 价格:’
WHILE @@FETCH_STATUS = 0 —判断FETCH语句是否执行成功
BEGIN
PRINT @fruitName+’ ‘+STR(@fruitPrice,8,2)
FETCH NEXT FROM cursor_variable —从游标中读取值
INTO @fruitName,@fruitPrice —赋值给变量
END
CLOSE cursor_variable —关闭游标
DEALLOCATE cursor_variable —释放游标
—编号为101的供应商提供的水果种类和价格为:
类型: 价格:
a 5.00
b 10.0012.3.3 用ORDER BY改变游标中行的顺序
DECLARE cursor_order CURSOR FOR
SELECT f_id,f_name,f_price FROM fruits
ORDER BY f_price DESC
OPEN cursor_order
FETCH NEXT FROM cursor_order
WHILE @@FETCH_STATUS = 0
FETCH NEXT FROM cursor_order
CLOSE cursor_order
DEALLOCATE cursor_order12.3.4 用游标修改数据
SELECT FROM fruits WHERE s_id = 106
DECLARE @sID INT
DECLARE @ID INT = 106
DECLARE cursor_fruit CURSOR FOR
SELECT s_id FROM fruits;
OPEN cursor_fruit
FETCH NEXT FROM cursor_fruit INTO @sID
WHILE @@FETCH_STATUS = 0
BEGIN
IF @sID = @ID
BEGIN
UPDATE fruits SET f_price = 16.7 WHERE s_id=@ID
END
FETCH NEXT FROM cursor_fruit INTO @sID
END
CLOSE cursor_fruit
DEALLOCATE cursor_fruit
SELECT FROM fruits WHERE s_id = 106
—M2 106 mango 15.60
—M2 106 mango 16.7012.3.5 用游标删除数据
DECLARE @sID INT
DECLARE @ID INT = 106
DECLARE cursor_delete CURSOR FOR
SELECT f_id FROM fruits;
OPEN cursor_delete
FETCH NEXT FROM cursor_delete INTO @sID
WHILE @@FETCH_STATUS = 0
BEGIN
IF @sID = @ID
BEGIN
DELETE FROM fruits WHERE s_id=@ID
END
FETCH NEXT FROM cursor_delete INTO @sID
END
CLOSE cursor_delete
DEALLOCATE cursor_delete
SELECT * FROM fruits WHERE s_id = 10612.4 使用系统存储过程管理游标
12.4.1 sp_cursor_list存储过程
—声明游标
DECLARE testcur CURSOR FOR
SELECT f_name FROM sample.dbo.fruits WHERE f_name LIKE ‘B%’
—打开游标
OPEN testcur
—声明游标变量
DECLARE @Report CURSOR
—执行sp_cursor_list存储过程,将结果保存到@Report游标变量中
EXEC sp_cursor_list @cursor_return = @Report OUTPUT, @cursor_scope = 2
—输出游标变量中的每一行
FETCH NEXT FROM @Report
WHILE (@@FETCH_STATUS <> -1)
BEGIN
FETCH NEXT FROM @Report
END
—关闭并释放游标变量
CLOSE @Report
DEALLOCATE @Report
GO
—关闭并释放原始游标
CLOSE testcur
DEALLOCATE testcur
GO12.4.2 sp_describe_cursor存储过程
—声明游标
DECLARE testcur CURSOR FOR
SELECT f_name FROM sample.dbo.fruits
—打开游标
OPEN testcur
—声明游标变量
DECLARE @Report CURSOR
—执行sp_describe_cursor存储过程,将结果保存到@Report游标变量中
EXEC sp_describe_cursor @cursor_return = @Report OUTPUT
, @cursor_source = N’global’, @cursor_identity = N’testcur’
—输出游标变量中的每一行
FETCH NEXT FROM @Report
WHILE (@@FETCH_STATUS <> -1)
BEGIN
FETCH NEXT FROM @Report
END
—关闭并释放游标变量
CLOSE @Report
DEALLOCATE @Report
GO
—关闭并释放原始游标
CLOSE testcur
DEALLOCATE testcur
GO
12.4.3 sp_describe_cursor_columns存储过程
—声明游标
DECLARE testcur CURSOR FOR
SELECT f_name FROM sample.dbo.fruits
—打开游标
OPEN testcur
—声明游标变量
DECLARE @Report CURSOR
—执行sp_describe_cursor_columns存储过程,将结果保存到@Report游标变量中
EXEC master.dbo.sp_describe_cursor_columns @cursor_return = @Report OUTPUT
, @cursor_source = N’global’, @cursor_identity = N’testcur’
—输出游标变量中的每一行
FETCH NEXT FROM @Report
WHILE (@@FETCH_STATUS <> -1)
BEGIN
FETCH NEXT FROM @Report
END
—关闭并释放游标变量
CLOSE @Report
DEALLOCATE @Report
GO
—关闭并释放原始游标
CLOSE testcur
DEALLOCATE testcur
GO
12.4.4 sp_describe_cursor_tables存储过程
—声明游标
DECLARE testcur CURSOR FOR
SELECT f_name FROM sample.dbo.fruits WHERE f_name LIKE ‘B%’
—打开游标
OPEN testcur
—声明游标变量
DECLARE @Report CURSOR
—执行sp_describe_cursor_tables存储过程,将结果保存到@Report游标变量中
EXEC sp_describe_cursor_tables @cursor_return = @Report OUTPUT
, @cursor_source = N’global’, @cursor_identity = N’testcur’
—输出游标变量中的每一行
FETCH NEXT FROM @Report
WHILE (@@FETCH_STATUS <> -1)
BEGIN
FETCH NEXT FROM @Report
END
—关闭并释放游标变量
CLOSE @Report
DEALLOCATE @Report
GO
—关闭并释放原始游标
CLOSE testcur
DEALLOCATE testcur
GO
13 存储过程和自定义函数
13.1 存储过程概述
系统存储过程是SQL Server 2012系统创建的存储过程,它的母的在于能够方便地从系统表中查询信息,或者完成与更新数据库表相关的管理任务或其他的系统管理任务。
Transact-SQL语句是SQL Server 2012数据库与应用程序之间的编译接口。在很多情况下,一些代码会被开发者重复的编写多次,如果每次都编写相同功能的代码,不但繁琐,容易出错,而且由于SQL Server 2012 逐条地执行语句会降低系统的运行效率。13.2 存储过程分类
13.2.1 系统存储过程
以sp_开头,用来进行系统的各项设定.取得信息.相关管理工作
13.2.2 本地存储过程
用户创建的存储过程是由用户创建并完成某一特定功能的存储过程,事实上一般所说的存储过程就是指本地存储过程
13.2.3 临时存储过程
分为两种存储过程: 一是本地临时存储过程,以井字号(#)作为其名称的第一个字符,则该存储过程将成为一个存放在tempdb数据库中的本地临时存储过程,且只有创建它的用户才能执行它; 二是全局临时存储过程,以两个井字号(##)号开始,则该存储过程将成为一个存储在tempdb数据库中的全局临时存储过程,全局临时存储过程一旦创建,以后连接到服务器的任意用户都可以执行它,而且不需要特定的权限
13.2.4 远程存储过程
在SQL Server2005中,远程存储过程(Remote Stored Procedures)是位于远程服务器上的存储…
13.3 创建存储过程
13.3.1 创建存储过程-CREATE PROCEDURE
创建查询水果明细的存储过程
CREATE PROCEDURE SelProc
AS
SELECT * FROM fruits;
GO
- 创建查询水果明细总数的存储过程
CREATE PROCEDURE CountProc
AS
SELECT COUNT(*) AS 总数 FROM fruits;
GO
13.3.2 存储过程调用-EXECUTE
- 调用如上创建的两个存储过程
13.3.3 创建带输入参数的存储过程
- 创建带参数的存储过程
CREATE PROCEDURE QueryById @sId INT
AS
SELECT * FROM fruits WHERE s_id = @sId;
GO
- 执行带参数的存储过程
- EXECUTE QueryById 101;
- EXEC QueryByID @sId = 101;
- 创建带默认参数的存储过程
CREATE PROCEDURE QueryById2 @sId INT = 101
AS
SELECT * FROM fruits WHERE s_id = @sId;
GO
- 调用带默认参数的存储过程
13.3.4 创建带输出参数的存储过程
- 创建带输出参数的存储过程
CREATE PROCEDURE QueryById3
@sId INT = 101,
@fruitscount INT OUTPUT
AS
SELECT @fruitscount = COUNT (fruits.s_id) FROM fruits WHERE s_id = @sId;
GO
- 调用带输出参数的存储过程
DECLARE @fruitscount INT;
DECLARE @sId INT = 101;
EXECUTE QueryById3 @sId, @fruitscount OUTPUT
SELECT ‘该供应商一共提供了’ +LTRIM(STR(@fruitscount)) +’种水果’
GO
—该供应商一共提供了2种水果
13.4 管理存储过程
13.4.1 修改存储过程
- 修改存储过程结果按s_id分组
USE [sample]
GO
/** Object: StoredProcedure [dbo].[CountProc] Script Date: 12/18/2020 15:57:08 **/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER PROCEDURE [dbo].[CountProc]
AS
SELECT COUNT(*) AS 总数 FROM fruits GROUP BY s_id;
GO
13.4.2 查询存储过程信息
- 查询存储过程属性的三种方法
SELECT OBJECT_DEFINITION(OBJECT_ID(‘CountProc’));
EXEC sp_help CountProc;
EXECUTE sp_helptext CountProc;
13.4.3 删除存储过程
13.5 扩展存储过程
13.5.1 描述
扩展措辞过程使用户能够在变成语言(例如C、C++)中创建自己的外部例程。扩展存储过程的显示方式和执行方式与常规存储过程一样。可以将参数传递给扩展存储过程,而且扩展存储过程也可以返回结果和状态。
13.5.2 事例
- 查看系统的版本信息
13.6 自定义函数
13.6.1 创建标量函数
CREATE FUNCTION GetStuNameById (@stuid INT)
RETURNS VARCHAR (30)
AS
BEGIN
DECLARE @stuName CHAR(30)
SELECT @stuName = (SELECT s_name FROM stu_info WHERE s_id = @stuid)
RETURN @stuName
END
13.6.2 创建表值函数
- 创建表值函数
CREATE FUNCTION getStuRecordBySex (@stuSex CHAR(2))
RETURNS TABLE
AS
RETURN
(
SELECT s_id, s_name, s_sex, (s_score-10) AS newScore FROM stu_info WHERE s_sex = @stuSex
)
- 执行表值函数
SELECT * FROM getStuRecordBySex (‘男’);
13.6.3 删除函数
- 语法:DROP FUNCTION 函数名
事例:DROP FUNCTION getStuRecordBySex;
14 视图操作
14.1 视图概述
14.1.1 视图的概念
视图是一个虚拟表,是从数据库中一个或多个表中导出来的表。视图还可以在已经存在的视图的基础上定义。
视图一经定义便存储在数据库中,与其相对应的数据并没有像表那样在数据库中再存储一份,通过视图看到的数据只是存放在基本表中的数据。对视图的操作与对表的操作一样,可以对其进行查询、修改和删除。
当对通过视图看到的数据进行修改时,相应的基本表的数据也要发生变化,同时,若基本表的数据发生变化,则这种变化也可以自动地反映到视图中。14.1.2 视图的分类
标准视图
- 索引视图
-
14.1.3 视图的优点和作用
简单化
- 安全会
-
14.2 创建视图
14.2.1 使用视图设计器创建视图
路径:选中视图—>右键新建视图—>选中表—>添加表—>关闭表—>选择字段—>保存—>重命名视图

14.2.2 使用T-SQL命令创建视图
14.2.2.1 新建一个表t并赋值
CREATE TABLE t (quantity INT,price INT);
INSERT INTO t VALUES (3,50);
14.2.2.2 创建表t的视图View_t
CREATE VIEW View_t
AS SELECT quantity,price, quantityprice AS Total_price
FROM sample.dbo.t;
GO
USE sample
SELECT FROM View_t;
/ quantity price Total_price
3 50 150 /
14.2.2.3 创建两个表student、stu_detail
CREATE TABLE student
(
s_id INT
,name VARCHAR(40)
);
CREATE TABLE stu_detail
(
s_id INT
,glass VARCHAR(40)
,addr VARCHAR(90)
);
14.2.2.4 给表student、stu_detail赋值
INSERT INTO student VALUES (1,’wanglinl’),(2,’gaoli’),(3,’zhnaghai’);
INSERT INTO stu_detail VALUES (1,’wuban’,’henan’),(2,’liuban’,’hebei’),(3,’qiban’,’shandong’);
14.2.2.5 创建两个表的关联视图
CREATE VIEW stu_glass (id,name,glass)
AS SELECT student.s_id, student.name, stu_detail.glass
FROM student,stu_detail
WHERE student.s_id = stu_detail.s_id;
GO
SELECT FROM stu_glass;
/ id name glass
1 wanglinl wuban
2 gaoli liuban
3 zhnaghai qiban */
14.3 修改视图
SQL Server中提供了两种修改视图的方法:
- 在SQL Server管理平台中,鼠标右击要修改的视图,从弹出的菜单中选择“设计”选项,出现视图修改对话框。该对话框与创建视图的对话框相同,可以按照创建视图的方法修改视图。
使用ALTER VIEW语句修改视图,但首先必须拥有使用视图的权限,然后才能使用ALTER VIEW语句。ALTER VIEW语句的语法格式与CREATE VIEW语法格式基本相同,除了关键字不同。
14.3.1 修改视图-ALTER VIEW
ALTER VIEW View_t AS SELECT quantity FROM t;
14.4 查看视图信息
14.4.1 使用SSMS图形化工具查看
14.4.2 使用系统存储过程查看视图定义信息
查询视图属性信息的两种方法-ESEC sp_help
EXEC sp_help ‘sample.dbo.View_t’;
EXEC sp_helptext ‘sample.dbo.View_t’;14.5 使用视图修改数据
14.5.1 通过视图向基表中插入数据
CREATE VIEW view_stuinfo (编号,名字,成绩,性别)
AS SELECT s_id, s_name, s_score, s_sex FROM stu_info WHERE s_name = ‘张霞’;
GO
SELECT FROM stu_info;
INSERT INTO view_stuinfo VALUES (13, ‘雷永’, 90, ‘男’);
SELECT FROM stu_info;
14.5.2 通过视图修改基表中的数据
SELECT FROM view_stuinfo;
UPDATE view_stuinfo SET 成绩 = 88 WHERE 名字 = ‘张霞’;
SELECT FROM stu_info;14.5.3 通过视图删除基表中的数据
DELETE view_stuinfo WHERE 名字 = ‘张霞’;
SELECT FROM view_stuinfo;
SELECT FROM stu_info;14.6 删除视图
14.6.1 使用对象资源管理器删除视图
14.6.2 使用T-SQL命令删除视图
15 触发器
15.1 触发器概述
15.1.1 什么是触发器
触发器是一个在修改制定表值的数据时执行的存储过程,不同的是执行存储过程要使用EXEC语句来调用,而触发器的执行不需要使用EXEC语句来调用,通过创建触发器可以保证不同表中的逻辑相关数据的应用完整性和一致性。
15.1.2 触发器作用
触发器的主要作用就是其能够实现有主键和外键所不能保证的复杂的参照完整性和数据的一致性,它能够对数据库中的相关表进行级联修改,能够提供比CHECK约束更复杂的数据完整性,并自定义错误信息。
15.1.3 触发器分类
数据操作语言触发器
-
15.2 创建DML触发器
15.2.1 INSERT触发器
15.2.1.1 新建触发器
CREATE TRIGGER Insert_Student
ON stu_info
AFTER INSERT
AS
BEGIN
IF OBJECT_ID (N’stu_sum’, N’U’) IS NULL
CREATE TABLE stu_sum (number INT DEFAULT 0);
DECLARE @stuNumber INT;
SELECT @stuNumber = COUNT () FROM stu_info;
IF NOT EXISTS (SELECT FROM stu_sum)
INSERT INTO stu_sum VALUES (0);
UPDATE stu_sum SET number = @stuNumber;
END
GO15.2.1.2 插入数据并查询
SELECT COUNT() FROM stu_info;
INSERT INTO stu_info (s_id, s_name, s_score, s_sex, s_age) VALUES (15, ‘杨过’, 90, ‘男’, 21);
SELECT COUNT() FROM stu_info;
SELECT number AS stu_Sum表中总人数 FROM stu_Sum;15.2.1.3 创建插入触发器
CREATE TRIGGER Insert_forbidden
ON stu_Sum
AFTER INSERT
AS
BEGIN
RAISERROR (‘不允许直接向该表插入记录,操作被禁止’,1,1)
ROLLBACK TRANSACTION
END15.2.1.4 插入数据测试
INSERT INTO stu_Sum VALUES (5);
/不允许直接向该表插入记录,操作被禁止
消息 50000,级别 1,状态 1
消息 3609,级别 16,状态 1,第 1 行
事务在触发器中结束。批处理已中止。/15.2.2 DELETE触发器
15.2.2.1 创建删除触发器
CREATE TRIGGER Delete_Student
ON stu_info
AFTER DELETE
AS
BEGIN
SELECT s_id AS 已删除学生编号, s_name, s_score,s_sex, s_age
FROM DELETED
END
GO15.2.2.2 删除数据测试
DELETE FROM stu_info WHERE s_id = 15;
/已删除学生编号 s_name s_score s_sex s_age
15 杨过 90 男 21/15.2.3 UPDATE触发器
15.2.3.1 创建更新触发器
CREATE TRIGGER Update_Student
ON stu_info
AFTER UPDATE
AS
BEGIN
DECLARE @stuCount INT;
SELECT @stuCount = COUNT(*) FROM stu_info;
UPDATE stu_Sum SET number = @stuCount;
SELECT s_id AS 更新前学生编号, s_name AS 更新前学生姓名 FROM DELETED
SELECT s_id AS 更新后学生编号, s_name AS 更新后学生姓名 FROM INSERTED
END
GO15.2.3.2 更新触发器测试
UPDATE stu_info SET s_name = ‘张淼’ WHERE s_id = 1;
/更新前学生编号 更新前学生姓名
1 许三
更新后学生编号 更新后学生姓名
1 张淼/15.2.4 替代触发器
15.2.4.1 创建替代触发器
CREATE TRIGGER INSERADOfInsert_Student
ON stu_info
INSTEAD OF INSERT
AS
BEGIN
DECLARE @stuScore INT;
SELECT @stuScore = (SELECT s_score FROM inserted)
IF @stuScore > 100
SELECT ‘插入成绩错误’ AS 失败原因
END
GO15.2.4.2 替代触发器测试
INSERT INTO stu_info (s_id, s_name, s_score, s_sex, s_age)
VALUES (15, ‘周翡’, 110, ‘男’, 20);
SELECT FROM stu_info;
/失败原因
插入成绩错误
s_id s_name s_score s_sex s_age
1 张淼 98 男 18
2 张靓 70 女 19
3 王宝 25 男 18
4 马华 10 男 20
5 李岩 65 女 18
6 刘杰 88 男 19
7 鹏飞 60 男 18
8 王岚 90 男 19
9 路飞 80 男 18
11 魏波 70 男 19
12 李婷 74 女 18
13 雷永 90 男 NULL
14 白雪 87 女 20*/15.2.5 允许使用嵌套触发器
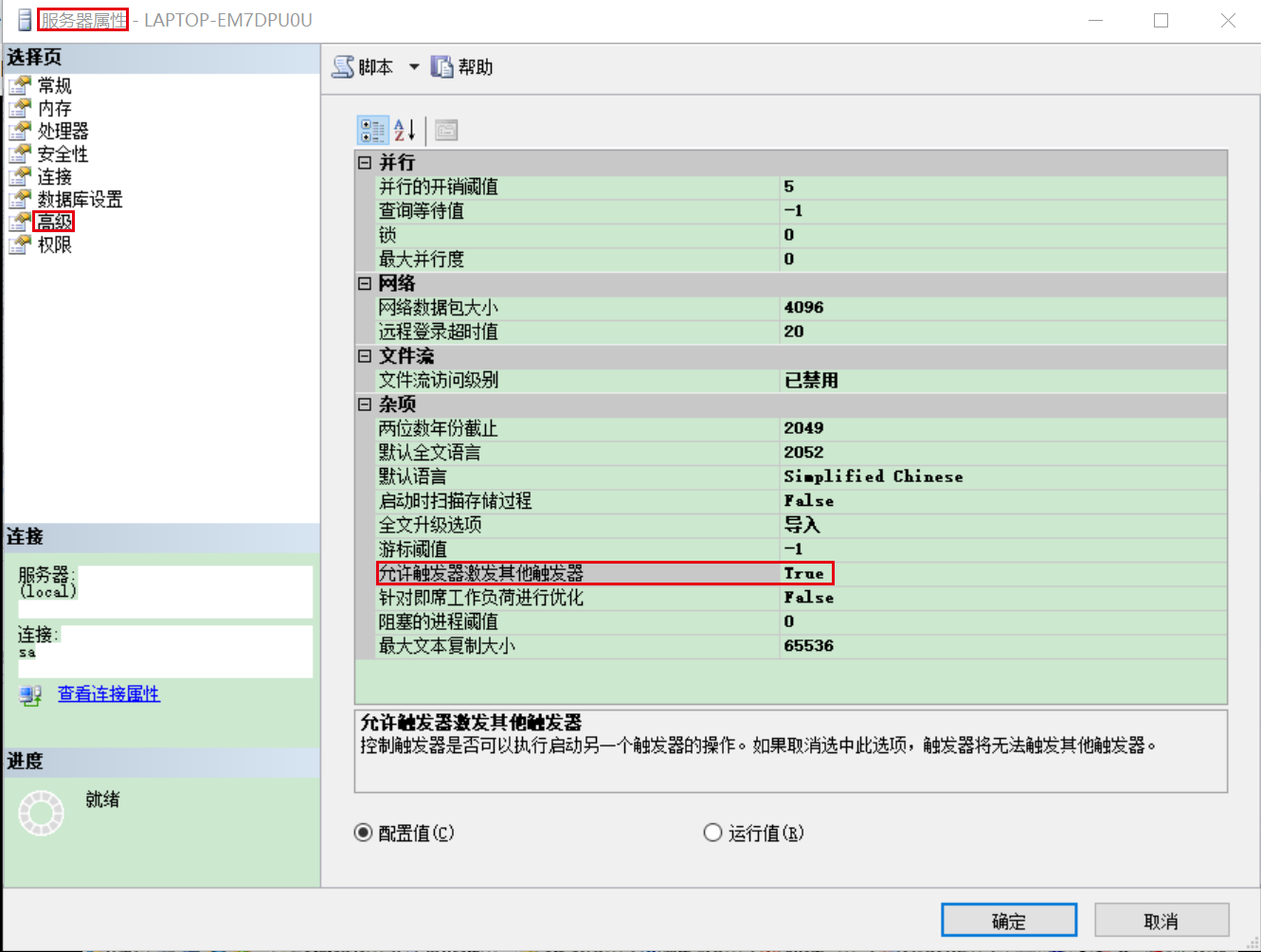
15.2.5.1 配置路径
选中服务器—>右键属性—>高级—>杂项—>允许触发器激发其他触发器—>true
15.2.5.2 截图显示
15.2.6 递归触发器
15.2.6.1 配置路径
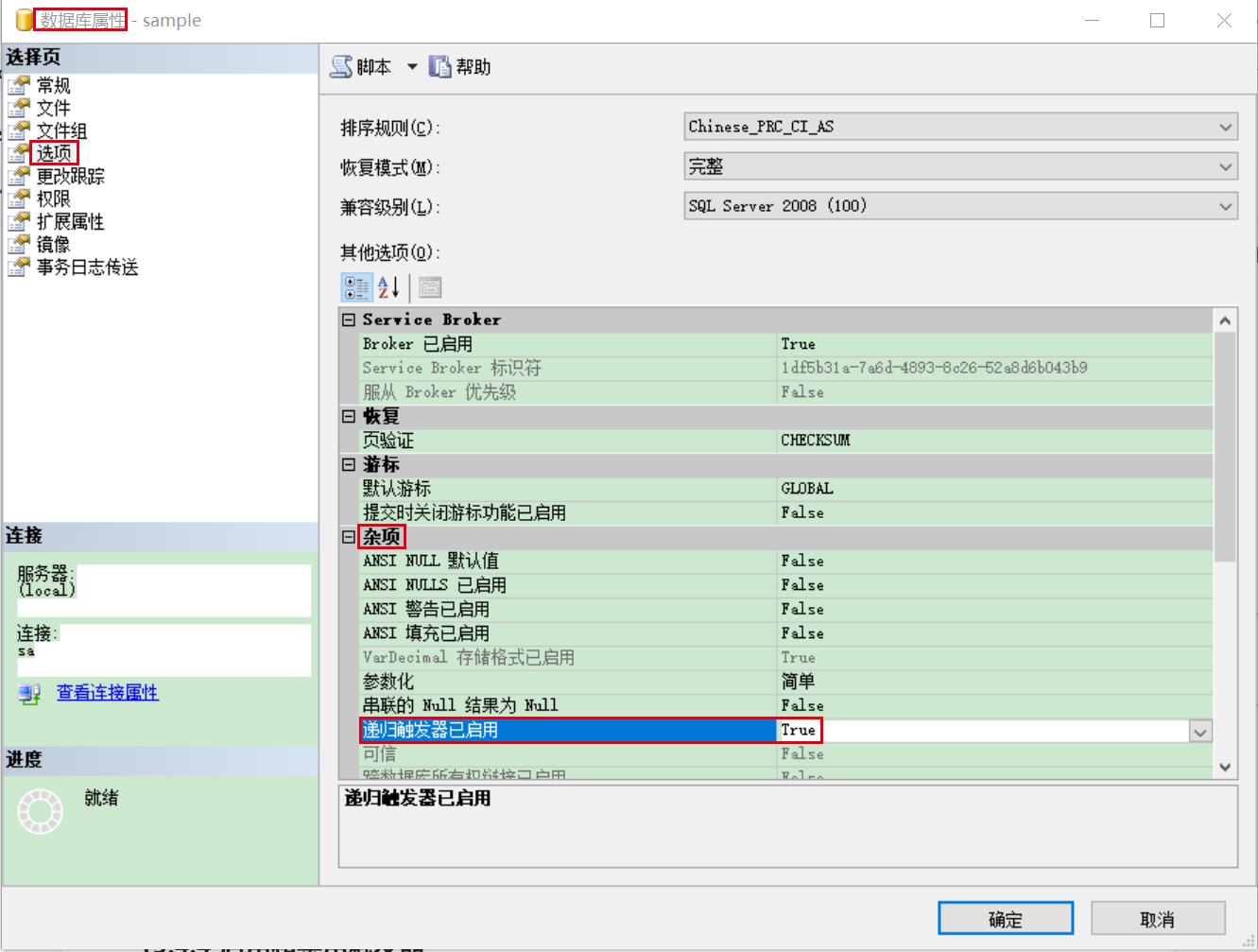
选中数据库—>右键属性—>选项—>杂项—>递归触发器已启用—>true
15.2.6.2 截图显示
15.3 创建DDL触发器
15.3.1 创建DDL触发器的语法
CREATE TRIGGER trigger_name
ON { ALL SERVER | DATABASE } ——-全部服务器 | 当前数据库
WITH ENCRYPTION ——-是否加密
{ FOR | AFTER | {event_type}
AS
sql_statement15.3.2 创建服务器作用域的DDL触发器
15.3.2.1 创建触发器
USE sample;
GO
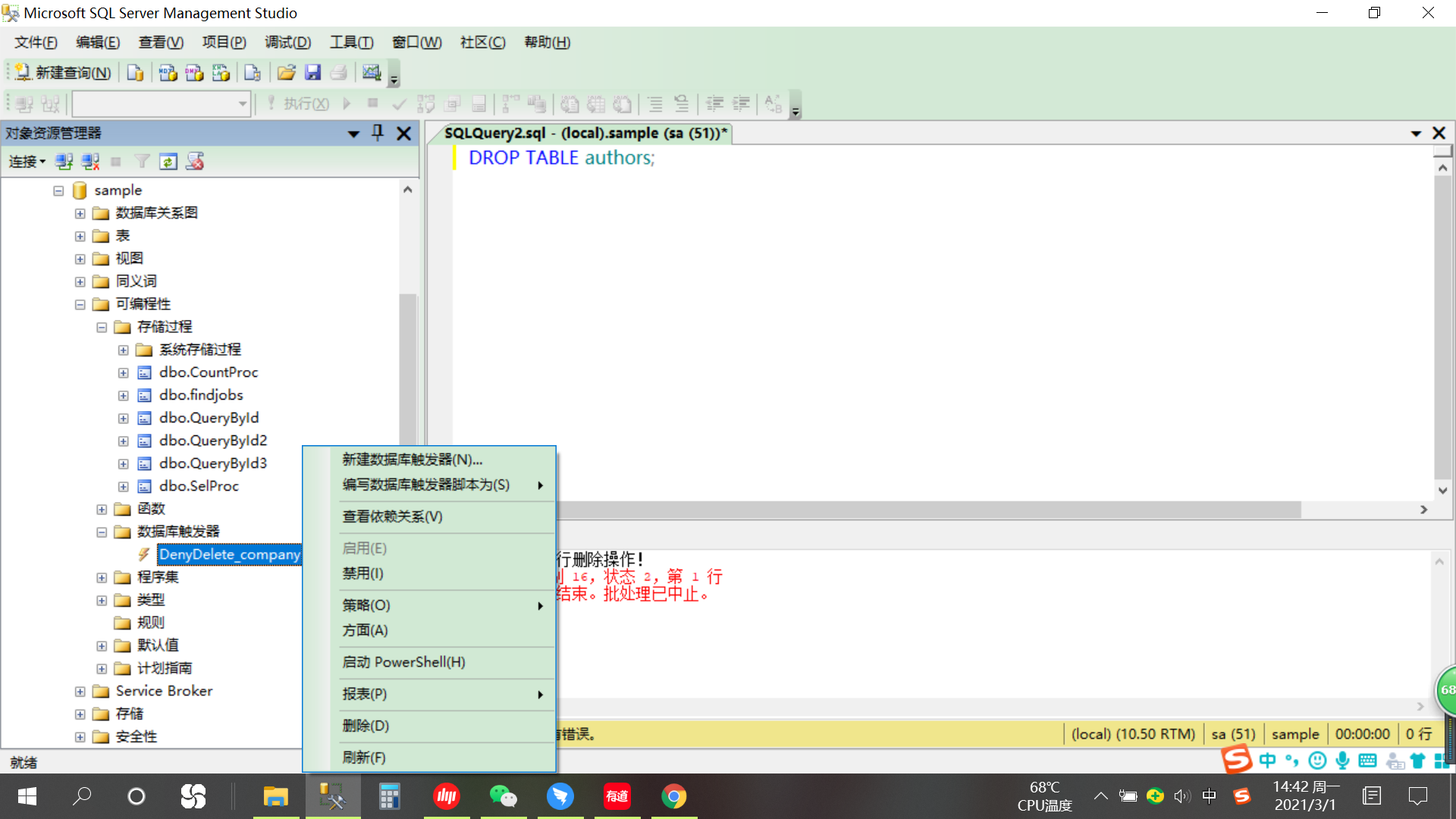
CREATE TRIGGER DenyDelete_company
ON DATABASE
FOR DROP_TABLE, ALTER_TABLE
AS
BEGIN
PRINT ‘用户没有权限执行删除操作!’
ROLLBACK TRANSACTION
END
GO15.3.2.2 删除触发器测试
DROP TABLE authors;
/用户没有权限执行删除操作!
消息 3609,级别 16,状态 2,第 1 行
事务在触发器中结束。批处理已中止。/15.4 管理触发器
15.4.1 查看触发器
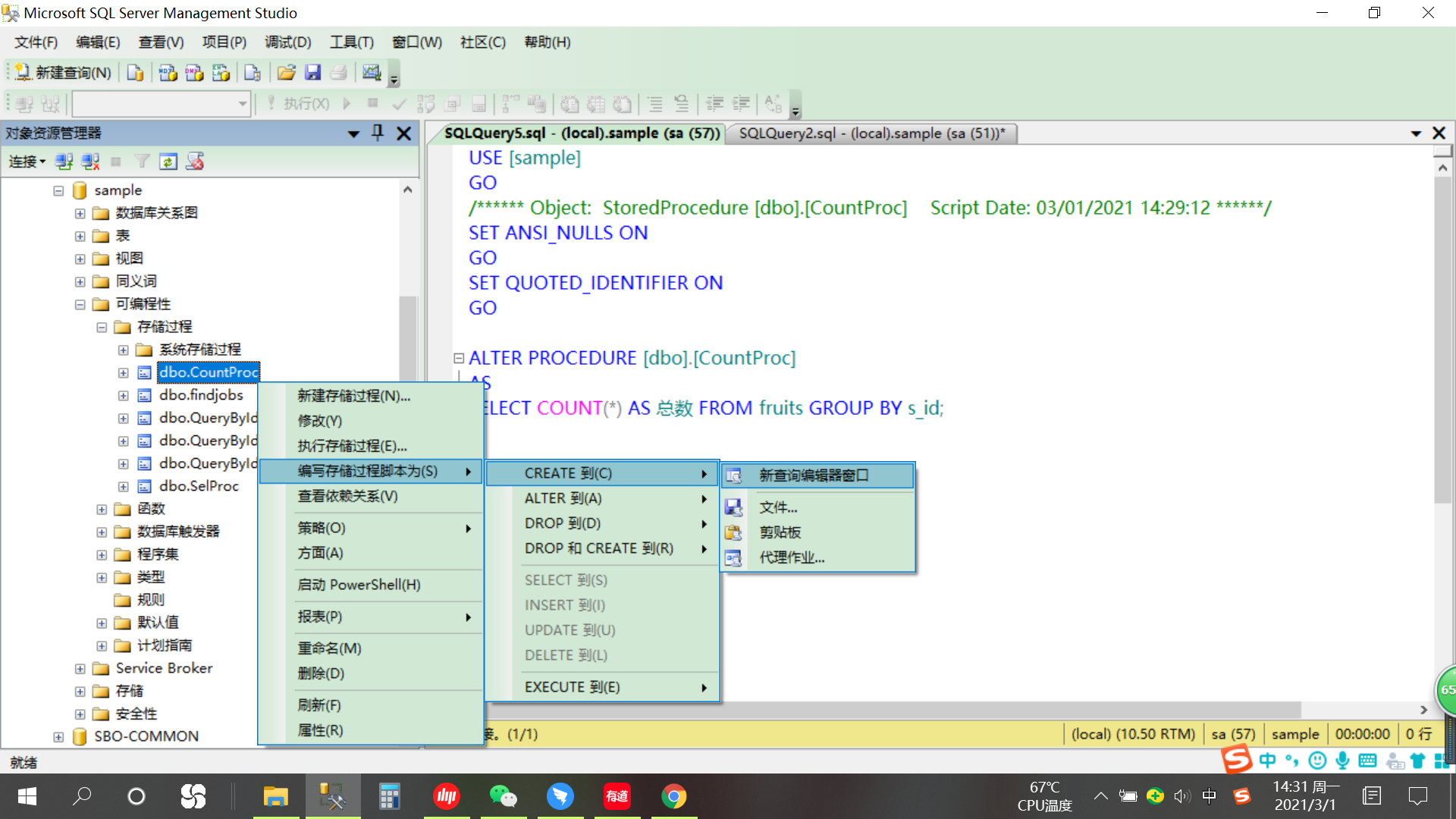
15.4.1.1 路径
选中数据库—> 可编程性—>存储过程—>系统存储过程—>选中触发器—>编写存储过程脚本为—>CREATE到—>新查询编辑器窗口
15.4.1.2 截图
15.4.2 修改触发器
15.4.2.1 路径
选中数据库—> 可编程性—>存储过程—>系统存储过程—>选中触发器—>修改
15.4.3 删除触发器
15.4.3.1 路径
选中数据库—> 可编程性—>存储过程—>系统存储过程—>选中触发器—>删除
15.4.4 启用和禁用触发器
15.4.4.1 路径
15.4.4.2 截图
16 SQL Server 2012的安全机制
16.1 SQL Server安全性概述
16.1.1 SQL Server 2012的安全机制简介
SQL Server 2012整个安全体系结构从顺序上可以分为认证和授权两个部分,其安全机制可以分为5个层级:
客户机安全机制
- 网络运输的安全机制
- 实力级别安全机制
- 数据库级别安全机制
-
16.1.2 级别安全术语
数据库所有者:简称DBO,是数据库的创建者。每个数据库只有一个所有者。
- 数据库对象:包括表、索引、视图、触发器、规则和存储过程。
- 域:计算的集合
- 数据库组
- 系统管理员:简称sa
- 许可:可以增加SQL Server的安全性
- 用户名:登录ID的名称
- 主体
- 角色:一个角色可以分配给多个实体
16.2 安全验证方式
16.2.1 Windows验证模式
16.2.2 混合模式
16.2.3 设置验证模式
16.3 SQL Server登录名
16.3.1 创建登录名CREATE LOGIN
16.3.1.1 使用SSMS创建登录名
路径:开始->控制面板->管理工具->计算机管理->系统工具->本地用户和组->用户(右键新建用户)16.3.1.2 使用T-SQL创建登录名
CREATE LOGIN [MANGODataBaseAdmin]
WITH PASSWORD=’!QAZ2wsx’,DEFAULT_DATABASE=test;
说明:设置后需要重启登录16.3.2 修改登录名CREATE LOGIN
16.3.2.1 使用SSMS创建登录名
路径:选中登录名—>右键重命名16.3.2.2 使用T-SQL创建登录名
CREATE LOGIN MANGODataBaseAdmin WITH NAME = ‘MangoDataBaseAdmin’;16.3.3 删除登录名DROP LOGIN
16.3.3.1 使用SSMS创建登录名
路径:选中登录名—>右键删除16.3.3.2 使用T-SQL创建登录名
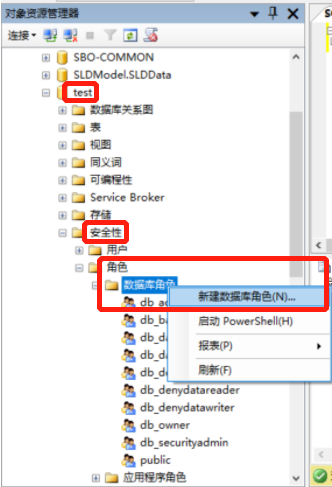
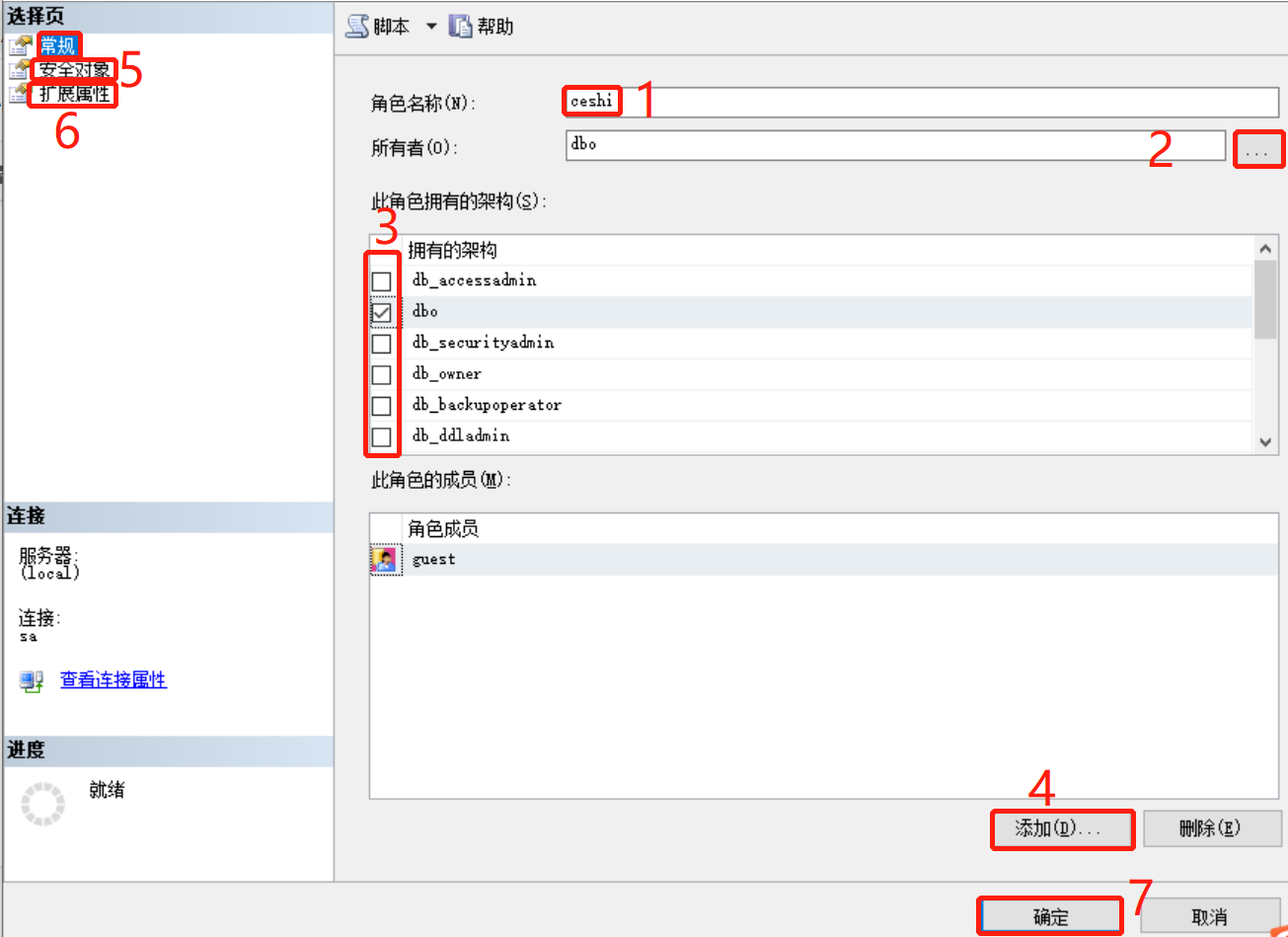
DROP LOGIN MangoDataBaseAdmin;16.4 SQL Server2012的角色与权限
16.4.1 CREATE APPLICATION ROLE—创建数据库角色(两种方法)
CREATE APPLICATION ROLE App_User WITH PASSWORD = ‘!QAZ2wsx’;16.4.2 sp_setapprole激活角色
sp_setapprole ‘App_User’,@PASSWORD = ‘!QAZ2wsx’
USE test
GO
SELECT * FROM fruits16.4.3 GRANT授予角色权限
USE test
GRANT SELECT,INSERT,UPDATE,DELETE
ON fruits
TO App_User
GO17.2 备份设备
17.2.1 管理器备份路径
服务器对象-备份设备-右键-新建备份设备-输入备份名称-确定文件路径-确定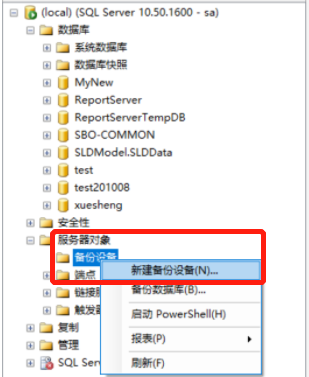
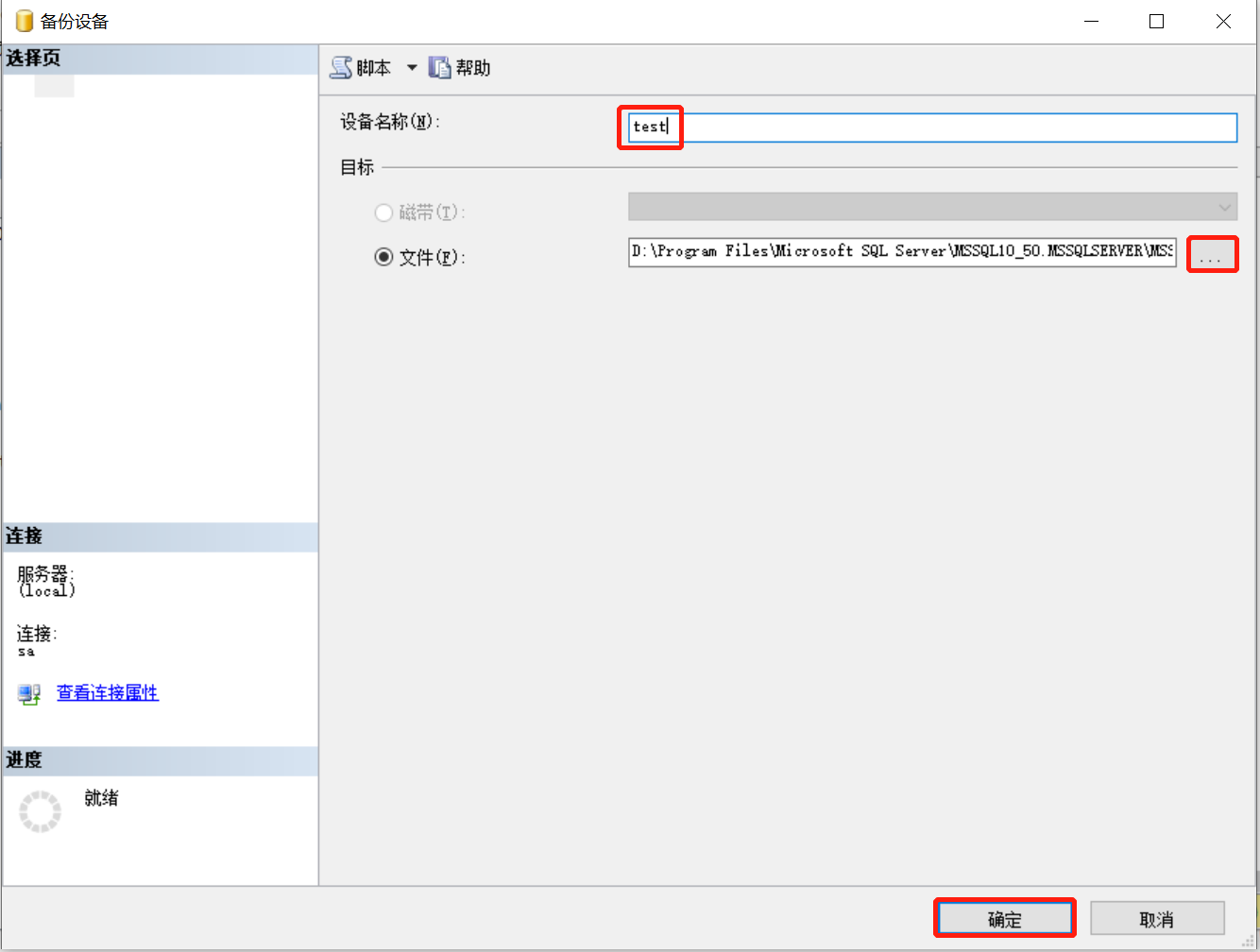
17.2.2 EXEC sp_addumpdevice ‘disk’创建备份设备
USE test;
GO
EXEC sp_addumpdevice ‘disk’,’mydiskdump’,’D:\Download\testdump.bak’;17.2.3 sp_helpdevice查看备份设备
sp_helpdevice
/device_name physical_name description status cntrltype size
mydiskdump D:\Download\testdump.bak disk, backup device 16 2 0/17.2.4 EXEC-spdropdevice删除设备设备
EXEC sp_dropdevice mydiskdump;—设备已除去。17.3 使用T-SQL 语言备份数据库
17.3.1 BACKUP DATABASE备份数据库
BACKUP DATABASE test —选择备份数据库名称
TO mydiskdump —选择备份设备名称
WITH INIT,
NAME = ‘test’,
DESCRIPTION = ‘该文件为test数据库的完整备份’;
BACKUP DATABASE test
TO mydiskdump
WITH DIFFERENTIAL, NOINIT,
NAME = ‘test’,
DESCRIPTION = ‘该文件为test数据库的差异备份’;17.3.2 备份文件和文件组路径

17.3.3 BACKUP LOG备份日志
BACKUP LOG test
TO mydiskdump
WITH NOINIT,
NAME = ‘test数据库事务日志备份’,
DESCRIPTION = ‘该文件为test数据库事务日志备份’;17.4 在SQL Server Managerment Studio中还原数据库
17.4.1 RESTORE VERIFYONLY检查备注是否存在
RESTORE VERIFYONLY FROM mydiskdump;—文件 1 上的备份集有效。17.4.2 原数据库或文件和文件组
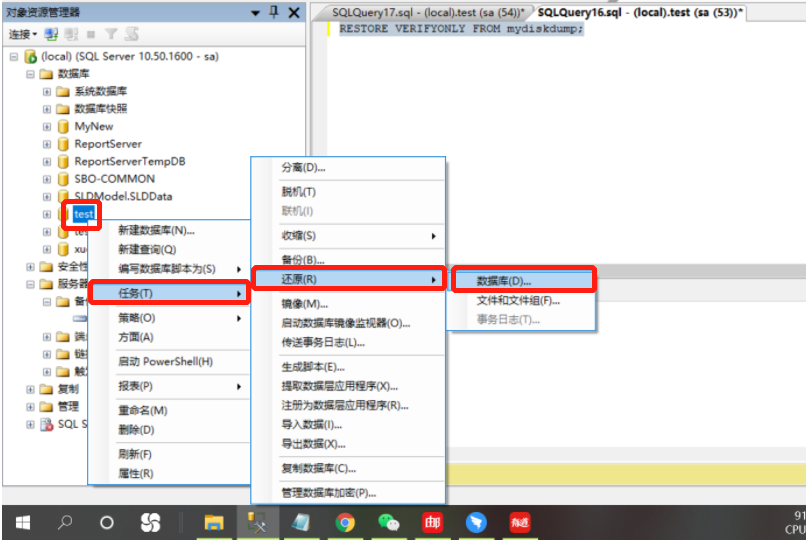
17.5 用T-SQL语言还原数据库
17.5.1 覆盖方式还原完整备份数据库
USE test
GO
RESTORE DATABASE test FROM mydiskdump
WITH REPLACE;17.5.2 还原差异备份数据库
USE test
GO
RESTORE DATABASE test FROM mydiskdump
WITH FILE = 1,NORECOVERY, REPLACE
GO
RESTORE DATABASE test FROM mydiskdump
WITH FILE = 2
GO17.5.3 事务日志备份
BACKUP LOG test
TO mydiskdump;17.5.4 还原一个新数据库
USE test
GO
RESTORE DATABASE newtest
FROM mydiskdump
WITH FILE = 1,
MOVE ‘test’ TO ‘D:\Download\test.mdf’,
MOVE ‘test_log’ TO ‘D:Download\test_log.ldf’;17.6 建立自动备份的维护计划
数据库备份非常重要,并且有些数据的备份非常频繁,例如事务日志,如果每次都把备份的流程执行一遍,将花费大量的时间,非常繁琐和没有效率。所以自动备份尤为重要。17.6.1 启动
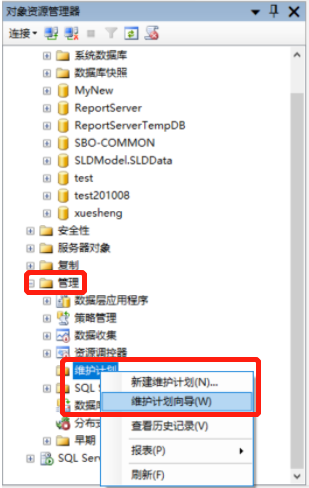
管理器中SQL Server代理-右键启动17.6.2 维护
管理-维护计划-右键选择维护计划向导\或新建维护计划17.6.3 截图
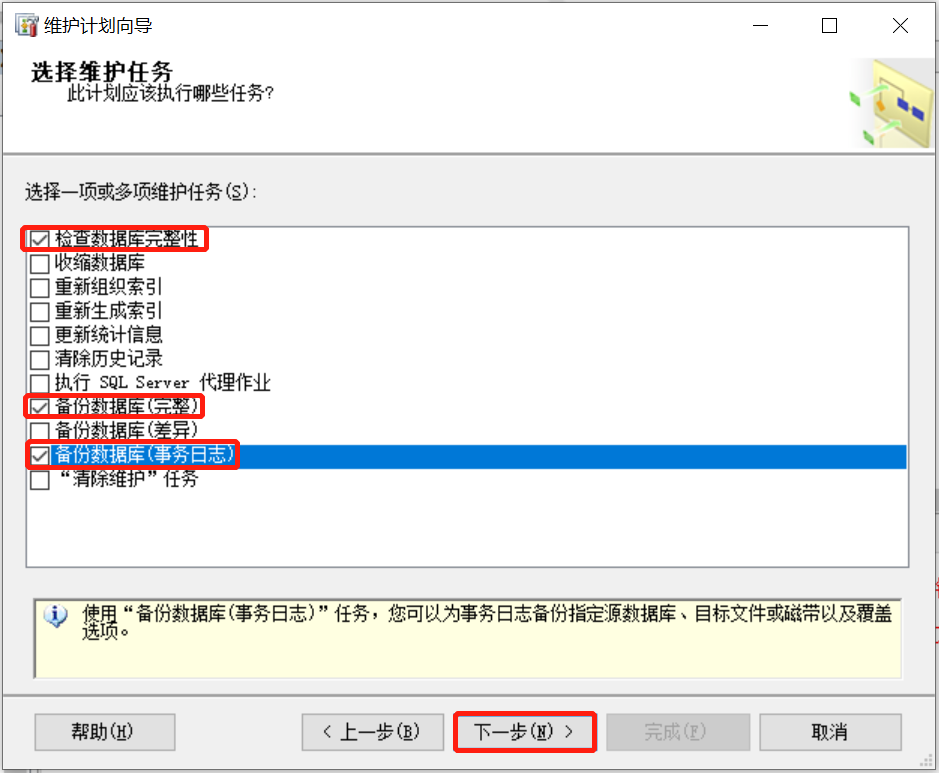
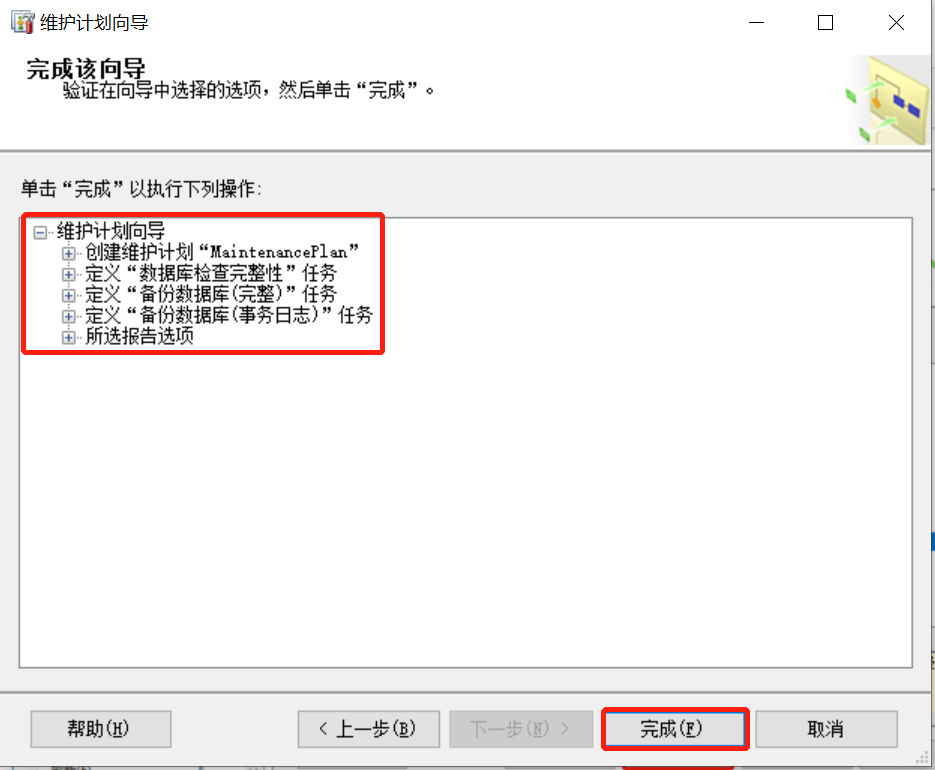
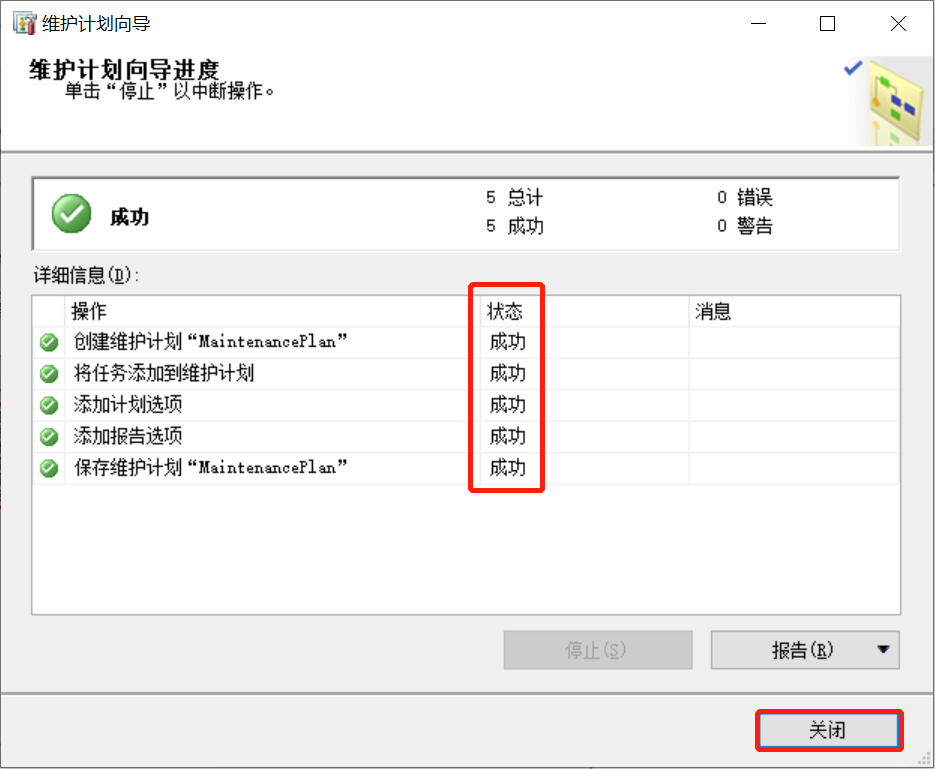

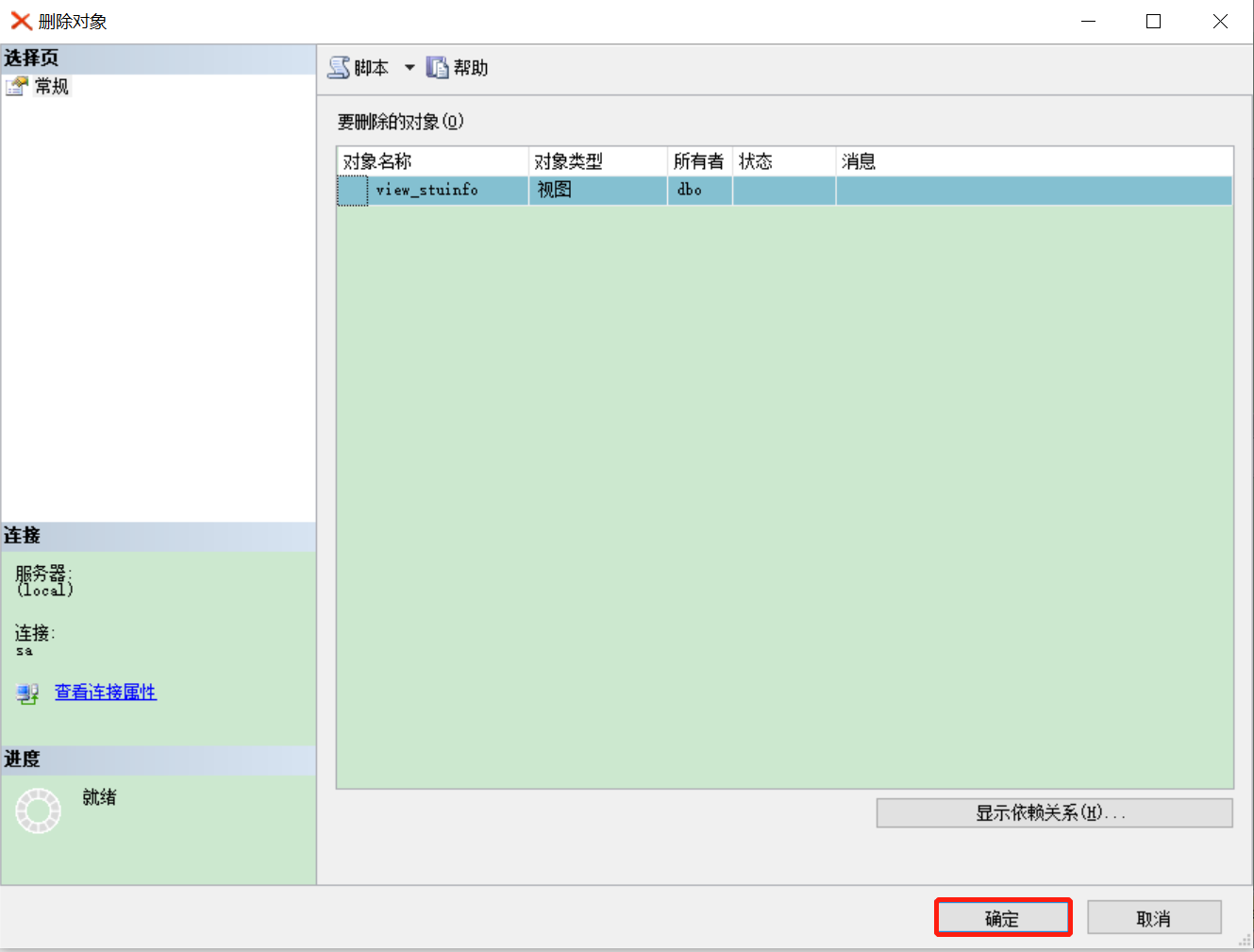

若有收获,就点个赞吧
0 人点赞
