- 一、大纲
- 二、模块
- mouse callback function
- 2.3 Core Operations
- 2.4 Image Processing in OpenCV
- 2.4.1 Changing Colorspaces
- 2.4.2 Geometric Transformations of Images
- 2.4.3 Image Thresholding
- 2.4.4 Smoothing Images
- 2.4.5 Morphological Transformations
- 2.4.6 Image Gradients
- 2.4.7 Canny Edge Detection
- 2.4.8 Image Pyramids
- 2.4.9 Contours in OpenCV
- 2.4.10 Histograms in OpenCV
- 2.4.11 Image Transforms in OpenCV
- 2.4.12 Template Matching
- 2.4.13 Hough Line Transform
- 2.4.14 Hough Circle Transfor
- 2.4.15 Image Segmentation with Watershed Algorithm
- 2.4.16 Interactive Foreground Extraction using GrabCut Algorithm
- 2.5 Feature Detection and Description
- 2.6 Video analysis (video module)
- 2.7 Camera Calibration and 3D Reconstruction
- 2.8 Machine Learning
- 2.9 Computational Photography
- 2.10 Object Detection (objdetect module)
- 2.11 OpenCV-Python Bindings
一、大纲
- Introduction to OpenCV学习如何在环境中配置OpenCV-Python库;
- Gui Features in OpenCV学习如何显示/保存图像、视频、控制鼠标事件和创建轨迹条;
- Core Operations本节将学习图像的基本操作,如编辑像素、几何变换、代码优化和一些数学工具等;
- Image Processing in OpenCV本节将学习OpenCV中的图像处理功能;
- Feature Detection and Description本节将学习特征检测器和描述符;
- Video analysis (video module)本节将学习视频分析处理技术,如目标追踪等;
- Camera Calibration and 3D Reconstruction本节将学习相机校准、立体成像等;
- Machine Learning机器学习
- Computational Photography本节将学习计算摄影技术,如图像去噪等;
- Object Detection (objdetect module)本节将学习目标检测技术,如人脸检测等;
- OpenCV-Python Bindings本节将了解如何生成OpenCV-Python库
二、模块
2.1 Introduction to OpenCV
2.1.1 Introduction to OpenCV-Python Tutorials
OpenCV
OpenCV于1999年由Gary Bradsky在英特尔创立,第一个版本于2000年发布。Vadim Pisarevsky加入Gary Bradsky管理英特尔的俄罗斯软件OpenCV团队。2005年,OpenCV被用于机器人斯坦利,这赢得了2005年DARPA大挑战赛。后来,该项目在Willow Garage的支持下继续积极开发,由Gary Bradsky和Vadim Pisarevsky领导。OpenCV现在支持多种与计算机视觉和机器学习相关的算法,并且正在日益扩展。
OpenCV支持多种编程语言,如C++、Python、Java等,并可在不同的平台上使用,包括Windows、Linux、OS X、Android和iOS。基于CUDA和OpenCL的高速GPU操作接口也在积极开发中。
OpenCV Python是OpenCV的Python API,结合了OpenCV C++API和Python语言的最佳特性。OpenCV-Python
OpenCV Python是一个Python库,旨在解决计算机视觉问题。
Python是由Guido van Rossum发起的一种通用编程语言,它很快变得非常流行,主要是因为它的简单性和代码可读性。它使程序员能够在不降低可读性的情况下,用更少的代码行表达想法。
与C/C++等语言相比,Python速度较慢。也就是说,Python可以很容易地用C/C++进行扩展,这允许我们用C/C++编写计算密集型代码,并创建可以用作Python模块的Python包装器。这给了我们两个优势:第一,代码与原始C/C++代码一样快(因为它是在后台工作的实际C++代码);第二,用Python编写代码比C/C++更容易。OpenCV-Python是原始OpenCV C++实现的Python包装器。
OpenCV-Python使用Numpy,这是一个高度优化的数值运算库,具有MATLAB风格的语法。将所有数组和Numpy结构转换为OpenCV。这也使得它更容易与其他使用Numpy的库集成,比如SciPy和Matplotlib。OpenCV-Python Tutorials
OpenCV引入了一组新的教程,将指导您使用OpenCV Python中的各种函数。本指南主要关注OpenCV 3.x版本(尽管大多数教程也适用于OpenCV 2.x)。
建议您先了解Python和Numpy,因为本教程将不介绍它们。为了使用OpenCV Python编写优化的代码,必须熟练使用Numpy。
本教程最初由Abid Rahman K.在 Alexander Mordvintsev的指导下开始。OpenCV Needs You !!!
由于OpenCV是一个开源项目,所以欢迎所有人对库、文档和教程做出贡献。如果您在本教程中发现任何错误(从一个小的拼写错误到代码或概念中的严重错误),可以通过在GitHub中克隆OpenCV并提交一个pull请求来进行更正。OpenCV开发人员将检查您的pull请求,向您提供重要反馈,并且(一旦通过审核人的批准),它将被合并到OpenCV中。然后你将成为一名开源贡献者:-)
随着OpenCV Python中添加了新模块,本教程将不得不进行扩展。如果你熟悉一个特定的算法,请写一篇教程,包括算法的基本理论和显示示例用法的代码。
记住,我们一起可以使这个项目取得巨大成功!!!Contributors
以下为OpenCV-Python提交教程的贡献者列表:
- Alexander Mordvintsev (GSoC-2013 mentor)
Abid Rahman K. (GSoC-2013 intern)
Additional Resources
A Quick guide to Python - A Byte of Python
- NumPy Quickstart tutorial
- NumPy Reference
- OpenCV Documentation
- OpenCV Forum
2.1.2 Install OpenCV-Python in Windows
2.1.3 Install OpenCV-Python in Fedora
2.1.4 Install OpenCV-Python in Ubuntu
2.2 Gui Features in OpenCV
2.2.1 Getting Started with Images
目标
- 从文件中读取图像 ( cv::imread)
- 在窗口中显示图像 ( cv::imshow)
将图像写入文件 ( cv::imwrite)
源码
import cv2 as cvimport sysimg = cv.imread(cv.samples.findFile("starry_night.jpg"))if img is None:sys.exit("Could not read the image.")cv.imshow("Display window", img)k = cv.waitKey(0)if k == ord("s"):cv.imwrite("starry_night.png", img)
说明
首先,导入OpenCV-Python库。正确的方法是为它另外指定一个别名cv,在下文中用于引用库。
import cv2 as cvimport sys
现在,让我们分析主代码。作为第一步,我们阅读OpenCV样本中的图像“starry_night.jpg”。为此,对cv::imread函数的调用使用第一个参数指定的文件路径加载图像。第二个参数是可选的,用于指定图像的格式。支持:
IMREAD_COLOR以BGR 8位格式加载图像。此处使用的默认值。
- IMREAD_UNCHANGED按原样加载图像(包括alpha通道,如果存在)
- IMREAD_GRAYSCALE将图像作为强度加载
读入图像后,数据将存储在cv::Mat 对象中。
img = cv.imread(cv.samples.findFile("starry_night.jpg"))
:::info
备注:
OpenCV支持Windows位图(bmp)、便携式图像格式(pbm、pgm、ppm)和太阳光栅(sr、ras)的图像格式。在插件的帮助下(如果你自己构建库,你需要指定使用它们,但是在我们默认提供的软件包中),你也可以加载JPEG(JPEG,jpg,jpe)、JPEG 2000(jp2——在CMake中代号为Jasper)、TIFF文件(TIFF,tif)和便携式网络图形(png)等图像格式。此外,OpenEXR也是一种可能性。
:::
之后,如果图像加载正确,则执行检查。
if img is None:sys.exit("Could not read the image.")
然后,通过调用cv::imshow函数来显示图像。第一个参数是窗口的标题,第二个参数是将显示的cv::Mat对象。
因为我们希望在用户按下某个键之前显示窗口(否则程序结束得太快),所以我们使用cv::waitKey函数,它唯一的参数是它应该等待用户输入多长时间(以毫秒为单位)。零意味着永远等待。返回值是按下的键。
cv.imshow("Display window", img)k = cv.waitKey(0)
最后,如果按下的键是“s”键,图像将被写入文件。为此,将调用cv::imwrite函数,该函数将文件路径和cv::Mat对象作为参数。
if k == ord("s"):cv.imwrite("starry_night.png", img)
2.2.2 Getting Started with Videos
目标
- 学习读取、显示和保存视频
- 学习从相机获取视频并显示
您将学习以下功能 : cv.VideoCapture(), cv.VideoWriter()
从摄像机获取视频
源码
通常,我们必须用摄像机捕捉实时流。OpenCV提供了一个非常简单的界面来实现这一点。让我们从相机中捕捉一段视频(我正在使用笔记本电脑上的内置摄像头),将其转换为灰度视频并显示出来。这只是一个简单的开始。
要捕获视频,需要创建一个VideoCapture对象。它的参数可以是设备索引或视频文件的名称。设备索引只是指定哪个摄像头的数字。通常会连接一个摄像头(如我的情况)。所以我只需通过0(或-1)。可以通过传递1来选择第二个摄影机,依此类推。之后,你可以一帧一帧地抓拍。但在最后,别忘了释放捕获。import numpy as npimport cv2 as cvcap = cv.VideoCapture(0)if not cap.isOpened():print("Cannot open camera")exit()while True:# Capture frame-by-frameret, frame = cap.read()# if frame is read correctly ret is Trueif not ret:print("Can't receive frame (stream end?). Exiting ...")break# Our operations on the frame come heregray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)# Display the resulting framecv.imshow('frame', gray)if cv.waitKey(1) == ord('q'):break# When everything done, release the capturecap.release()cv.destroyAllWindows()
说明
cap.read()返回bool值(True/False)。如果帧读取正确,则为真。所以可以通过返回值检查是否已至视频末尾。
有时,cap可能没有初始化采集。在这种情况下,代码将报错,你可以通过cap.isOpened()方法检查是否初始化,如果返回真值,则初始化正确,否则需要先使用cap.open()打开。
您也可以使用cap.get(propId)方法访问视频的一些特征。其中propId为0~18之间的数字,每个数字对应视频的一项属性(如果此视频适用)。完整的细节可以参见 cv::VideoCapture::get()。其中部分值可以通过cap.set(propId, value)修改为您想设定的值。
例如,通过cap.get(cv.CAP_PROP_FRAME_WIDTH)和cap.get(cv.CAP_PROP_FRAME_HEIGHT)可以确认一帧图像的宽和高,默认返回640×480。可以适用ret = cap.set(cv.CAP_PROP_FRAME_WIDTH,320)和ret = cap.set(cv.CAP_PROP_FRAME_HEIGHT,240)将其修改为320×240。 :::info 备注:
如果出现了错误,请先使用其他任何相机应用程序(如Linux中的Cheese)确保相机工作正常。 :::从文件播放视频
源码
从文件播放视频与从相机捕获视频是一样的,只需将相机索引更改为视频文件名即可。此外,在显示帧时,请适当使用cv.waitKey()。如果设置太小,视频速度会非常快,如果太高,视频速度会很慢(这就是以慢动作显示视频的方式)。正常情况下25毫秒就可以了。
import numpy as npimport cv2 as cvcap = cv.VideoCapture('vtest.avi')while cap.isOpened():ret, frame = cap.read()# if frame is read correctly ret is Trueif not ret:print("Can't receive frame (stream end?). Exiting ...")breakgray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)cv.imshow('frame', gray)if cv.waitKey(1) == ord('q'):breakcap.release()cv.destroyAllWindows()
:::info 备注:
需要确保已安装正确版本的ffmpeg或gstreamer。安装错误将会导致视频捕获出错。 :::保存视频
源码
当视频捕获并已逐帧处理完毕后,需要保存视频。保存图像可简单实用cv.imwrite()。保存视频则需要更多的工作。
首先需要创建一个VideoWriter对象,并指明输出文件名称(例如output.avi)。然后还需要指明FourCC码(详见下文)。接着需要传入每秒播放帧数目(fps)和帧大小。最后需要设置isColor标识符,如果设置为真,则编码器预期为彩色帧,否则默认为灰度帧。
FourCC为专用于视频编/解码的4字节编码。可在fourcc.org查找可用编码列表。它来自独立平台。下述编解码器为OpenCV适配的列表:Fedora:DIVX,XVID,MJPG,X264,WMV1,WMV2,(推荐XVID,MJPG适用于大尺寸视频,X264适用于小尺寸视频);
- Windows:DIVX(更多内容待测试后添加);
- OS X:MJPG(.mp4),DIVX(.avi),X264(.mkv);
FourCC码可以通过`cv.VideoWriter_fourcc(‘M’,’J’,’P’,’G’)或cv.VideoWriter_fourcc(*’MJPG’)形式设置MJPG。
下述代码为从摄像机获取视频,并且每一帧沿垂直方向翻转,之后保存视频。
import numpy as npimport cv2 as cvcap = cv.VideoCapture(0)# Define the codec and create VideoWriter objectfourcc = cv.VideoWriter_fourcc(*'XVID')out = cv.VideoWriter('output.avi', fourcc, 20.0, (640, 480))while cap.isOpened():ret, frame = cap.read()if not ret:print("Can't receive frame (stream end?). Exiting ...")breakframe = cv.flip(frame, 0)# write the flipped frameout.write(frame)cv.imshow('frame', frame)if cv.waitKey(1) == ord('q'):break# Release everything if job is finishedcap.release()out.release()cv.destroyAllWindows()
2.2.3 Drawing Functions in OpenCV
目标
- 学习适用OpenCV绘制不同几何形状;
cv.line(), cv.circle(), cv.rectangle(), cv.ellipse(), cv.putText()等等;
源码
在上述所有函数中,常用到以下所示的一些参数:
img:指明所绘制几何形状的图像;
- color:指明几何形状的颜色。对于BGR将使用元组传递数值(例如(255,0,0)为蓝色),对于灰度,仅传递标量数值即可;
- thickness:指明线、圆等线的厚度。如果设定闭合形状为-1,则将填充内部。默认值为1;
lineType:指明线的类型,是否为八连通、抗锯齿线等。默认使用八连通。cv.LINE_AA提供了更适合曲线显示的抗锯齿线。
绘制直线
当绘制一条直线时,需要传入直线的起点和终点坐标。此处将在黑色图像中创建一条从左上至右下的蓝色对角线。
import numpy as npimport cv2 as cv# Create a black imageimg = np.zeros((512,512,3), np.uint8)# Draw a diagonal blue line with thickness of 5 pxcv.line(img,(0,0),(511,511),(255,0,0),5)
绘制矩形
当绘制一个矩形时,需要传入矩形的左上角点和右下角点坐标。此处将在图像右上角绘制一个绿色的矩形。
cv.rectangle(img,(384,0),(510,128),(0,255,0),3)
绘制圆形
当绘制一个圆形,需要传入圆心坐标和半径。此处将在所绘矩形上方绘制一个红色圆形。
cv.circle(img,(447,63), 63, (0,0,255), -1)
绘制椭圆
当绘制一个椭圆时,需要传入多个参数,第一个参数为中心坐标(x,y),第二个参数为轴长度(长轴长度,短轴长度)。角度是椭圆沿逆时针方向旋转的角度。startAngle和endAngle将指定椭圆长轴沿顺时针旋转方向的起始角度和结束角度(弧的起点和终点),例如输入(0,360)则为完整椭圆。详情请见cv.ellipse()文档。此处示例为在图像中心处绘制一个半圆。
cv.ellipse(img,(256,256),(100,50),0,0,180,255,-1)
绘制多边形
当绘制一个多边形时,首先需要依次传入顶点坐标,顶点坐标需要以rows ×1 ×2 形式排列int32数组,并且rows即为顶点数目。此处将绘制一个黄色的小四边形。
pts = np.array([[10,5],[20,30],[70,20],[50,10]], np.int32)pts = pts.reshape((-1,1,2))cv.polylines(img,[pts],True,(0,255,255))
:::info 备注:
如果第三个参数设置为False,将会得到所有顶点间的连线,而非闭合形状。
cv.polylines()同样可用于多条直线的绘制,仅需创建一个线的列表并传入函数,所有线将被独立绘制。此方法优于通过调用cv.line()绘制每条线。 :::图像添加文字
当在图像上添加文本时,需要指定以下内容:
需要写入的文本数据
- 文本框位置坐标(即数据开始的左下角点坐标)
- 字体类型:可查阅 cv.putText() 文档寻找支持字体
- 字体比例:指明字体的大小
- 常规设置:如颜色、厚度、线型等。为了效果更好,建议将线型设置为cv.LINE_AA
此处将在图像上添加白色OpenCV文本。
font = cv.FONT_HERSHEY_SIMPLEXcv.putText(img,'OpenCV',(10,500), font, 4,(255,255,255),2,cv.LINE_AA)
2.2.4 Mouse as a Paint-Brush
目标
- 学习OpenCV中的鼠标事件处理
- cv.setMouseCallback()
示例
此处将创建一个简单的应用程序,允许在图像上任何位置双击绘制一个圆形。
首先,需要创建一个鼠标回调函数,当鼠标事件发生时将执行此函数。鼠标事件可以指代任何与鼠标相关的事件,例如左键点击、左键弹起,左键双击等。将返回每个鼠标事件的坐标(x,y)。获取此事件和位置后,可配合进行任何操作。需要列出所有可用事件,请在Python 终端中运行以下代码:
创建鼠标回调函数有特定的格式,在任何地方都是统一的。仅在函数作用上有所不同。此处鼠标回调函数仅完成在鼠标双击位置绘制一个圆形的任务。下述代码中的注释已不言自明。import cv2 as cvevents = [i for i in dir(cv) if 'EVENT' in i]print( events )
import numpy as npimport cv2 as cv# mouse callback functiondef draw_circle(event,x,y,flags,param):if event == cv.EVENT_LBUTTONDBLCLK:cv.circle(img,(x,y),100,(255,0,0),-1)# Create a black image, a window and bind the function to windowimg = np.zeros((512,512,3), np.uint8)cv.namedWindow('image')cv.setMouseCallback('image',draw_circle)while(1):cv.imshow('image',img)if cv.waitKey(20) & 0xFF == 27:breakcv.destroyAllWindows()
高级示例
此处展示一个更好的应用程序。在这种情况下,将通过拖动鼠标以绘制矩形或圆形(取决于选择的模式),例如上边的示例。因此此处鼠标回调函数分为两部分,一部分用于绘制矩形,另一部分用于绘制圆形。示例将有助于创建和理解一些交互式应用程序,如目标追踪、图像分割等。 ```python import numpy as np import cv2 as cv drawing = False # true if mouse is pressed mode = True # if True, draw rectangle. Press ‘m’ to toggle to curve ix,iy = -1,-1mouse callback function
def draw_circle(event,x,y,flags,param): global ix,iy,drawing,mode if event == cv.EVENT_LBUTTONDOWN:
elif event == cv.EVENT_MOUSEMOVE:drawing = Trueix,iy = x,y
elif event == cv.EVENT_LBUTTONUP:if drawing == True:if mode == True:cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)else:cv.circle(img,(x,y),5,(0,0,255),-1)
Next we have to bind this mouse callback function to OpenCV window. In the main loop, we should set a keyboard binding for key ‘m’ to toggle between rectangle and circle.drawing = Falseif mode == True:cv.rectangle(img,(ix,iy),(x,y),(0,255,0),-1)else:cv.circle(img,(x,y),5,(0,0,255),-1)
img = np.zeros((512,512,3), np.uint8) cv.namedWindow(‘image’) cv.setMouseCallback(‘image’,draw_circle) while(1): cv.imshow(‘image’,img) k = cv.waitKey(1) & 0xFF if k == ord(‘m’): mode = not mode elif k == 27: break cv.destroyAllWindows()
接下来,必须将此鼠标回调函数绑定至OpenCV窗口中。在主循环中,为按键"m"设置一个绑定,便于在矩形和圆形之间切换。```pythonimg = np.zeros((512,512,3), np.uint8)cv.namedWindow('image')cv.setMouseCallback('image',draw_circle)while(1):cv.imshow('image',img)k = cv.waitKey(1) & 0xFFif k == ord('m'):mode = not modeelif k == 27:breakcv.destroyAllWindows()
2.2.5 Trackbar as the Color Palette
目标
-
示例Demo
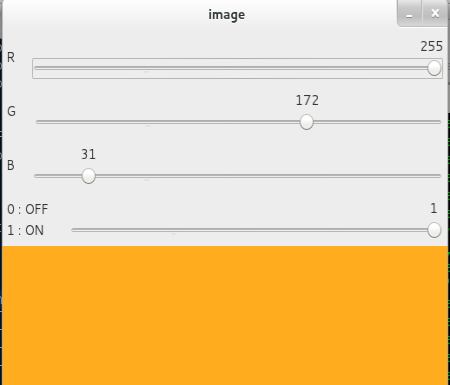
此处将创建一个简单的应用程序,用于显示您指定的颜色。将创建一个显示颜色的窗口和三个轨迹条分别指定B、G、R颜色数值。通过滑动轨迹条,相应地改变窗口显示颜色。默认情况下,初始颜色为黑色。
cv.createTrackbar()函数中,第一个参数为轨迹条名称,第二个参数是它所附加的窗口名称,第三个参数是默认值,第四个参数是最大值,第五个参数是回调参数,每次修改轨迹条数值时都会执行。回调函数始终有一个默认参数,即轨迹条位置。此处示例中,函数什么都不做,仅作为传递。
轨迹条的另一个重要应用是将其用作按钮或开关。默认情况下,OpenCV没有按钮功能。依次可以使用轨迹条模拟按钮功能。此应用程序中将创建一个开关,仅开关打开时,应用程序才能工作,否则屏幕总是显示黑色。import numpy as npimport cv2 as cvdef nothing(x):pass# Create a black image, a windowimg = np.zeros((300,512,3), np.uint8)cv.namedWindow('image')# create trackbars for color changecv.createTrackbar('R','image',0,255,nothing)cv.createTrackbar('G','image',0,255,nothing)cv.createTrackbar('B','image',0,255,nothing)# create switch for ON/OFF functionalityswitch = '0 : OFF \n1 : ON'cv.createTrackbar(switch, 'image',0,1,nothing)while(1):cv.imshow('image',img)k = cv.waitKey(1) & 0xFFif k == 27:break# get current positions of four trackbarsr = cv.getTrackbarPos('R','image')g = cv.getTrackbarPos('G','image')b = cv.getTrackbarPos('B','image')s = cv.getTrackbarPos(switch,'image')if s == 0:img[:] = 0else:img[:] = [b,g,r]cv.destroyAllWindows()
2.3 Core Operations
2.3.1 Basic Operations on Images
目标
访问并修改像素值
- 访问图像属性
- 设置感兴趣区域(ROI)
- 图像的分割和合并
本节所有操作主要与Numpy有关,而非OpenCV。因此掌握Numpy有助于优化OpenCV的代码编写。
以下示例均在Python终端中运行显示,因为大多数仅有单行代码。
访问并修改像素值
首先加载一幅彩色图像:
>>> import numpy as np>>> import cv2 as cv>>> img = cv.imread('messi5.jpg')
可以通过像素的行、列坐标访问单一像素值。对于BGR图像,将返回一个包含蓝色、绿色和红色值得数组。对于灰度图像,仅返回当前像素对应的强度值。
>>> px = img[100,100]>>> print( px )[157 166 200]# accessing only blue pixel>>> blue = img[100,100,0]>>> print( blue )157
以相同的方式修改指定像素值
>>> img[100,100] = [255,255,255]>>> print( img[100,100] )[255 255 255]
:::danger
警告:
Numpy是一个用于优化矩阵计算的库。因此不鼓励单一访问每一个像素值并修改,此过程非常缓慢。
:::
:::info
备注:
上述方法通常用于指定数组中的某个区域,例如前五行或和后三列。对于单一像素访问,Numpy推荐array.item()和array.itemset()两种方法。通常会返回一个标量值,如果需要访问所有B,G,R值,需要独立为每个值调用array.item()
:::
更好的像素访问和编辑方法:
# accessing RED value>>> img.item(10,10,2)59# modifying RED value>>> img.itemset((10,10,2),100)>>> img.item(10,10,2)100
访问图像属性
图像属性包含行数、列数和通道数;图像数据类型;像素数等。
通过img.shape访问图像的形状,将返回一个行数、列数和通道数(如果是彩色图像)的元组。
>>> print( img.shape )(342, 548, 3)
:::info
备注:
如果图像是灰度图像,返回元组仅包含行数和列数,因此此方法也可被用于判断所加载图像是否为灰度图像。
:::
通过img.size()访问图像的像素总数:
>>> print( img.size )562248
通过img.dtype()访问图像的数据类型:
>>> print( img.dtype )uint8
:::info
备注:
图像数据类型在程序调试中异常重要,因为OpenCV-Python代码中大量错误均因无效数据类型引起。
:::
图像感兴趣区域
通常仅需处理图像中的一部分区域。对于图像中人眼检测,首先需要对整幅图像进行人脸检测,当检测出人脸后,仅需选中面部区域并在其中搜索眼睛即可,而无需搜索整幅图像。有助于提高准确性(因为眼睛总是在人脸内)和性能(因为在小区域内搜索)。
将再次通过Numpy图像索引获取ROI。此处将演示在图像中搜索球,并复制至零一区域。
>>> ball = img[280:340, 330:390]>>> img[273:333, 100:160] = ball

图像分割和合并
有时,需要分别处理图像中的B、G、R通道。这种情况下,需要将彩色BGR图像分割为单通道。在其它情况下,可能需要合并这些单通道以获取彩色BGR图像。可参考下述示例进行:
>>> b,g,r = cv.split(img)>>> img = cv.merge((b,g,r))
或者
>>> b = img[:,:,0]
如果要设置红色通道像素值为0——则不需要分割通道单独操作,使用Numpy图像索引更高效。
>>> img[:,:,2] = 0
:::danger
警告:
cv.split()是一个时间开销大的操作。因此如非必要,请使用Numpy图像索引。
:::
填充图像边框
如需在图像周围创建边框,比如相框,可以使用cv.copyMakeBorder(),它更擅长于卷积运算、零填充等方面。此函数采用以下参数:
- 源 - 输入图像
- 上,下,左,右 - 对应方向上的边框宽度(像素数目)
- 边框类型 - 定义要添加的边框类型标志
- cv.BORDER_CONSTANT - 添加固定颜色的边框。颜色作为下一个参数值传入
- cv.BORDER_REFLECT - 边框将以边缘像素镜像显示,类似fedcba|abcdefgh|hgfedcb
- cv.BORDER_REFLECT_101或 cv.BORDER_DEFAULT - 与上种类型相同,但有一些区别,类似gfedcb|abcdefgh|gfedcba
- cv.BORDER_REPLICATE - 最后一个像素将被始终复制,类似aaaaaa|abcdefgh|hhhhhhh
- cv.BORDER_WRAP - 不便解释,类似cdefgh|abcdefgh|abcdefg
- 值 - 如果边框类型为cv.BORDER_CONSTANT时的边框颜色值
下述是一个简单示例,有助于更好地理解所有边框类型
import cv2 as cvimport numpy as npfrom matplotlib import pyplot as pltBLUE = [255,0,0]img1 = cv.imread('opencv-logo.png')replicate = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REPLICATE)reflect = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REFLECT)reflect101 = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_REFLECT_101)wrap = cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_WRAP)constant= cv.copyMakeBorder(img1,10,10,10,10,cv.BORDER_CONSTANT,value=BLUE)plt.subplot(231),plt.imshow(img1,'gray'),plt.title('ORIGINAL')plt.subplot(232),plt.imshow(replicate,'gray'),plt.title('REPLICATE')plt.subplot(233),plt.imshow(reflect,'gray'),plt.title('REFLECT')plt.subplot(234),plt.imshow(reflect101,'gray'),plt.title('REFLECT_101')plt.subplot(235),plt.imshow(wrap,'gray'),plt.title('WRAP')plt.subplot(236),plt.imshow(constant,'gray'),plt.title('CONSTANT')plt.show()
请参见下述结果。(图像用matplotlib显示。因此红色和蓝色通道将互换(BGR2RGB))
2.3.2 Arithmetic Operations on Images
目标
- 学习图像的算术运算,例如加法、减法、位运算等;
-
图像叠加
可以使用OpenCV提供的cv.add()将两幅图像相加,或者使用更为简单的Numpy操作res = img1 + img2。相加的两幅图像需要保证深度和类型一致,或者第二幅图像仅包含标量值。 :::info 备注:
OpenCV的加法和Numpy的加法存在差异,OpenCV的加法是一种饱和运算,而Numpy的加法则是一种模运算。 ::: 参考下述示例加深理解:>>> x = np.uint8([250])>>> y = np.uint8([10])>>> print( cv.add(x,y) ) # 250+10 = 260 => 255[[255]]>>> print( x+y ) # 250+10 = 260 % 256 = 4[4]
使用两幅图像相加会使得差异更加明显。建议使用OpenCV提供的方法。
图像融合
基本类似图像相加,不同的是为图像赋予权重,以此达到混合或透明的效果。依照下述等式进行融合。

随着 从
从 ,可以得到一幅图像到另一幅图像的变换。
,可以得到一幅图像到另一幅图像的变换。
当两幅图像融合时,可以参考下述等式,通过 cv.addWeighted()函数设定第一幅图像权重为0.7,第二幅图像设置为0.3。
此处, 取零。
取零。img1 = cv.imread('ml.png')img2 = cv.imread('opencv-logo.png')dst = cv.addWeighted(img1,0.7,img2,0.3,0)cv.imshow('dst',dst)cv.waitKey(0)cv.destroyAllWindows()
位运算
包括与(AND)、或(OR)、非(NOT)和异或(XOR)操作。在提取任意部分的图像、定义或使用非矩形ROI等情况时非常有效,此处将演示如何修改图像中特定区域的示例。
计划将OpenCV Logo覆盖于图像之上。如果两幅图像相加,将改变原有颜色。如果融合两幅图像,将呈现透明效果。如果是矩形区域,可以参考先前的ROI定义方式进行,但是OpenCV Logo不是一个规则矩形,因此需要使用下述位运算实现。# Load two imagesimg1 = cv.imread('messi5.jpg')img2 = cv.imread('opencv-logo-white.png')# I want to put logo on top-left corner, So I create a ROIrows,cols,channels = img2.shaperoi = img1[0:rows, 0:cols]# Now create a mask of logo and create its inverse mask alsoimg2gray = cv.cvtColor(img2,cv.COLOR_BGR2GRAY)ret, mask = cv.threshold(img2gray, 10, 255, cv.THRESH_BINARY)mask_inv = cv.bitwise_not(mask)# Now black-out the area of logo in ROIimg1_bg = cv.bitwise_and(roi,roi,mask = mask_inv)# Take only region of logo from logo image.img2_fg = cv.bitwise_and(img2,img2,mask = mask)# Put logo in ROI and modify the main imagedst = cv.add(img1_bg,img2_fg)img1[0:rows, 0:cols ] = dstcv.imshow('res',img1)cv.waitKey(0)cv.destroyAllWindows()
请参见下述结果,左图显示创建的遮罩。右图显示最终结果。为便于理解,请显示上述代码中的所有过程图像,尤其是img1_bg和img2_fg。

2.3.3 Performance Measurement and Improvement Techniques
目标
在图像处理中,由于每秒需要处理大量操作,因此大吗不仅需要提供正确的解决方案,而且要以最高效率执行。
衡量代码的性能;
- 提升代码性能的技巧;
- cv.getTickCount,cv.getTickFrequency等;

除OpenCV外,Python也提供time模块,有助于衡量代码的执行效率。另一个profile模块将帮助获取关于代码的详细报告,比如代码中每个函数耗时、调用次数等。但是,如果使用的IPython,所有功能将被以交互式呈现。可通过查阅附加资料链接,了解更多重要的细节。
衡量OpenCV性能
cv.getTickCount函数将返回从一个参考事件(例如机器打开瞬间)到调用此函数时的时钟周期数。因此,如果在函数执行之前和之后调用它,就可以得到函数执行所耗费的时钟周期数。
cv.getTickFrequency函数将返回时钟周期的频率,或每秒的时钟周期数。因此,要以秒为单位计算执行时间,可以执行下述操作。
e1 = cv.getTickCount()# your code executione2 = cv.getTickCount()time = (e2 - e1)/ cv.getTickFrequency()
下述示例演示实际应用方式。示例中使用了中值滤波,窗口大小为5至49之间的奇数。(不用担心结果,这并非目标)。
img1 = cv.imread('messi5.jpg')e1 = cv.getTickCount()for i in range(5,49,2):img1 = cv.medianBlur(img1,i)e2 = cv.getTickCount()t = (e2 - e1)/cv.getTickFrequency()print( t )# Result I got is 0.521107655 seconds
:::info
备注:
同样可以使用time模块代替 cv.getTickCount,通过两次调用time.time()获取差值。
:::
OpenCV默认优化
许多OpenCV函数已使用SSE2、AVX等指令集进行优化,同样包含了未优化的代码。如果系统支持(几乎所有现代处理器都支持),应该运用这些特性。在编译过程中,默认会启用。除非禁用,否则OpenCV将优先运行优化的代码。可以通过调用cv.useOptimized()检查状态是否启用,并且可通过cv.setUseOptimized()设置启用/禁用。此处给出一个简单示例。
# check if optimization is enabledIn [5]: cv.useOptimized()Out[5]: TrueIn [6]: %timeit res = cv.medianBlur(img,49)10 loops, best of 3: 34.9 ms per loop# Disable itIn [7]: cv.setUseOptimized(False)In [8]: cv.useOptimized()Out[8]: FalseIn [9]: %timeit res = cv.medianBlur(img,49)10 loops, best of 3: 64.1 ms per loop
如上所示,优化后的中值滤波是未优化版本执行效率的两倍,如果查看源码,可以发现中值滤波是基于SIMD优化的,因此可以在使用代码中启用优化。(默认处于启用状态)
衡量IPython性能
有时需要比较两个类似操作的性能时。IPython提供了一个神奇的命令timeit达到此目标。通过多次运行代码以获得更精确的衡量结果。此命令同样适用于衡量单行代码的性能。
例如,需要比较以下加法运算性能时,可以通过IPython Shell进行。


 或
或
可以看到,In [10]: x = 5In [11]: %timeit y=x**210000000 loops, best of 3: 73 ns per loopIn [12]: %timeit y=x*x10000000 loops, best of 3: 58.3 ns per loopIn [15]: z = np.uint8([5])In [17]: %timeit y=z*z1000000 loops, best of 3: 1.25 us per loopIn [19]: %timeit y=np.square(z)1000000 loops, best of 3: 1.16 us per loop
 是最快的,比Numpy快20倍左右。如果考虑通过创建数组计算,可以达到100倍。(Numpy开发者正在研究这个问题)
:::info
备注:
是最快的,比Numpy快20倍左右。如果考虑通过创建数组计算,可以达到100倍。(Numpy开发者正在研究这个问题)
:::info
备注:
Python标量操作比Numpy标量操作效率。因此,对于仅包含一两个元素的操作,Python标量优于Numpy数组。当数组较大时,Numpy具有优势。 ::: 此处举例说明,比较cv.countNonZero()和np.count_nonzero() 在处理统一图像时的性能。
OpenCV函数较Numpy函数提升了25倍效率。 :::info 备注:In [35]: %timeit z = cv.countNonZero(img)100000 loops, best of 3: 15.8 us per loopIn [36]: %timeit z = np.count_nonzero(img)1000 loops, best of 3: 370 us per loop
通常OpenCV函数会比Numpy函数更快。因此,对于相同的操作,首选OpenCV函数。但是当使用Numpy视图(浅拷贝)而不是拷贝(深拷贝)的时候例外。 :::更多IPython命令
还有一些命令用于衡量性能、分析、行分析、内存检测等,均可查阅相应文档。这里不再赘述。性能优化技术
有一些技术和编码方法将最大限度利用Python和Numpy的性能。此处仅注明相关信息,并提供重要的访问链接。需要注意的是,实现算法过程中,首先尝试以简单方式实现,等到完成时,再分析找出瓶颈,并对其进行优化。
- 尽量避免在Python中使用循环,尤其是双重、三重循环等,天生效率低。
- 尽量将算法/代码向量化,Numpy和OpenCV针对向量操作均进行了优化。
- 利用缓存一致性。
- 除非必要,尽量不要拷贝数组,尝试使用数组视图,拷贝数组时空开销很大。
如果代码在完成上述操作后仍然很慢,或者不可避免使用大循环,请使用Cython等附加库加速。
额外资源
- Python Optimization Techniques
- Scipy Lecture Notes - Advanced Numpy
- Timing and Profiling in IPython
2.4 Image Processing in OpenCV
2.4.1 Changing Colorspaces
目标
- 学习如何将图像从一个颜色空间转换为另一个颜色空间 BGR ↔ Gray, BGR ↔ HSV等;
- 除此之外,还将创建一个应用程序从视频中提取彩色目标;
-
转变颜色空间
OpenCV中提供了超过150中颜色空间转换方法。此处仅介绍常用的两种,BGR↔GRAY和BGR↔HSV。
可以通过调用cv.cvtColor(input_image, flag)实现颜色转换,其中flag决定转换类型。
当设置flag为cv.COLOR_BGR2GRAY可以实现图像从BGR转化为GRAY,BGR→HSV也相似,需要设置flag为cv.COLOR_BGR2HSV,需要查阅其他flag类型,可以在Python终端中运行下述代码:>>> import cv2 as cv>>> flags = [i for i in dir(cv) if i.startswith('COLOR_')]>>> print( flags )
:::info 备注:
对于HSV,色调范围为[0, 179],饱和度范围[0, 255],值范围[0, 255]。不同软件可能使用不同尺度。因此,如果需要将OpenCV的数值设定范围与之进行匹配。 :::目标追踪
在BGR图像转换为HSV的基础上,可以将此用于提取彩色目标。HSV比BGR颜色空间中更易于表现颜色。此处示例尝试提取蓝色目标,以下为方法:
提取视频中的每一帧;
- 将BGR图像转换为HSV颜色空间;
- 针对HSV图像设置蓝色范围阈值;
- 从图像中单独提取蓝色目标;
下述为详细注释的代码:
import cv2 as cvimport numpy as npcap = cv.VideoCapture(0)while(1):# Take each frame_, frame = cap.read()# Convert BGR to HSVhsv = cv.cvtColor(frame, cv.COLOR_BGR2HSV)# define range of blue color in HSVlower_blue = np.array([110,50,50])upper_blue = np.array([130,255,255])# Threshold the HSV image to get only blue colorsmask = cv.inRange(hsv, lower_blue, upper_blue)# Bitwise-AND mask and original imageres = cv.bitwise_and(frame,frame, mask= mask)cv.imshow('frame',frame)cv.imshow('mask',mask)cv.imshow('res',res)k = cv.waitKey(5) & 0xFFif k == 27:breakcv.destroyAllWindows()
 :::info
备注:
:::info
备注:
图像中通常有一些噪声干扰,后续将介绍如何移除。
这是目标追踪中最简单的方法,通过学习轮廓提取功能,可以完成很多诸如通过质心定位追踪物体、捕捉手势绘制图表等进阶功能。
:::
如何定位所需追踪的HSV值?
这是stackoverflow.com上的常见问题,可以通过调用cv.cvtColor()简单实现。需要传入BGR中需要的值,而非整幅图像。例如想要定位HSV中的绿色值,可以在Python终端中运行下述代码:
>>> green = np.uint8([[[0,255,0 ]]])>>> hsv_green = cv.cvtColor(green,cv.COLOR_BGR2HSV)>>> print( hsv_green )[[[ 60 255 255]]]
可以分别将[H-10, 100, 100]和[H+10, 255, 255]设置为上、下限以筛选对应颜色目标。除此之外,也可以使用类似GIMP或其它在线转换器定位HSV值,切记调整HSV范围。
2.4.2 Geometric Transformations of Images
目标
- 学习对图像应用不同几何变换,如平移、旋转、仿射变换等;
-
变换
OpenCV提供了两种变换方法, cv.warpAffine和cv.warpPerspective,可以通过调用实现多种变换。
cv.warpAffine采用2×3变换矩阵作为输入,cv.warpPerspective则采用3×3变换矩阵。缩放
缩放仅用于调整图像大小。通过调用OpenCV提供的cv.resize(),可以实现手动指定图像大小或指定缩放比例因子。与此同时,还需设置采用插值方法的类型。优先推荐cv.INTER_AREA(收缩)、 cv.INTER_CUBIC (慢速)和cv.INTER_LINEAR(快速)。默认在所有调整图像尺寸均使用cv.INTER_LINEAR方法插值。此处示例为调整图像方法:
import numpy as npimport cv2 as cvimg = cv.imread('messi5.jpg')res = cv.resize(img,None,fx=2, fy=2, interpolation = cv.INTER_CUBIC)#ORheight, width = img.shape[:2]res = cv.resize(img,(2*width, 2*height), interpolation = cv.INTER_CUBIC)
平移
平移仅改变目标位置。如果已知
 方向偏移量,可设为
方向偏移量,可设为 ,并以此构建下述矩阵
,并以此构建下述矩阵 :
:
可以将其输入Numpy的数组中,类型为float32,并传入cv.warpAffine()。此处示例为平移(100, 50):import numpy as npimport cv2 as cvimg = cv.imread('messi5.jpg',0)rows,cols = img.shapeM = np.float32([[1,0,100],[0,1,50]])dst = cv.warpAffine(img,M,(cols,rows))cv.imshow('img',dst)cv.waitKey(0)cv.destroyAllWindows()
:::danger 警告:
cv.warpAffine()函数中第三个参数为输出图像大小,形式应该为”(宽度,高度)“,切记宽度=列数,高度=行数 :::
旋转
图像旋转
 角度的本质是通过下述的矩阵变换实现的:
角度的本质是通过下述的矩阵变换实现的:
OpenCV额外提供旋转中心和缩放因子的设置,支持丰富旋转方式。修改后变换矩阵为:
其中:
通过调用OpenCV提取的cv.getRotationMatrix2D可以查看旋转矩阵。此处示例为沿图像中心旋转90°,无任何缩放。img = cv.imread('messi5.jpg',0)rows,cols = img.shape# cols-1 and rows-1 are the coordinate limits.M = cv.getRotationMatrix2D(((cols-1)/2.0,(rows-1)/2.0),90,1)dst = cv.warpAffine(img,M,(cols,rows))
仿射变换
仿射变换中,原始图像的所有平行线,在变换输出图像中仍将保持平行。为确定变换矩阵,需要在原始图像中提取三个点及对应输出图像中的位置。cv.getAffineTransform将创建2×3的矩阵并作为参数传入 cv.warpAffine。
img = cv.imread('drawing.png')rows,cols,ch = img.shapepts1 = np.float32([[50,50],[200,50],[50,200]])pts2 = np.float32([[10,100],[200,50],[100,250]])M = cv.getAffineTransform(pts1,pts2)dst = cv.warpAffine(img,M,(cols,rows))plt.subplot(121),plt.imshow(img),plt.title('Input')plt.subplot(122),plt.imshow(dst),plt.title('Output')plt.show()
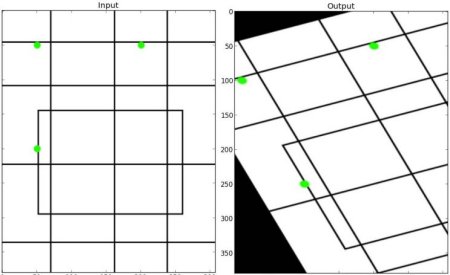
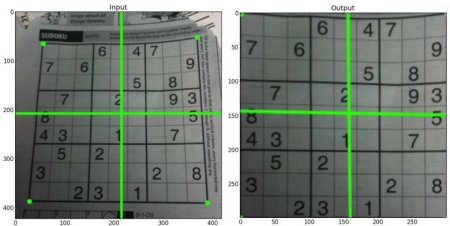
透视变换
透视变换则需要3×3变换矩阵。直线在透视变换仍将保持笔直。要计算变换矩阵,需要输入图像上4个点和对应输出图像的位置。在这四个点中,应保证至少三个点不共线。然后通过调用cv.getPerspectiveTransform可以求解变换矩阵。最后将3×3变换矩阵作为参数传入cv.warpPerspective
下述为示例代码:img = cv.imread('sudoku.png')rows,cols,ch = img.shapepts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])M = cv.getPerspectiveTransform(pts1,pts2)dst = cv.warpPerspective(img,M,(300,300))plt.subplot(121),plt.imshow(img),plt.title('Input')plt.subplot(122),plt.imshow(dst),plt.title('Output')plt.show()
2.4.3 Image Thresholding
目标
学习为图像设置单一阈值、自适应阈值和Otsu阈值;
cv.threshold和cv.adaptiveThreshold;
单一阈值
在二值化处理图像过程中,原理比较简单,对于每个像素,应用相同的阈值。如果像素值小于阈值,则将其设置为0,否则将其设置为最大值,通过调用cv.threshold设置阈值。第一个参数为输入原图像(应为灰度图像),第二个参数为用于像素值分类的阈值,第三个参数为超出阈值的像素最大值,第四个参数为OpenCV提供的阈值计算类型。如上所述,通常使用cv.THRESH_BINARY设置类型,所有简单阈值类型如下:
- cv.THRESH_BINARY_INV
- cv.THRESH_TRUNC
- cv.THRESH_TOZERO
- cv.THRESH_TOZERO_INV

请通过访问链接查阅不同类型间的差异。
此方法返回两个参数,第一个为使用阈值,第二个为二值化处理后的图像。
此处将演示不同单一阈值类型的示例:
import cv2 as cvimport numpy as npfrom matplotlib import pyplot as pltimg = cv.imread('gradient.png',0)ret,thresh1 = cv.threshold(img,127,255,cv.THRESH_BINARY)ret,thresh2 = cv.threshold(img,127,255,cv.THRESH_BINARY_INV)ret,thresh3 = cv.threshold(img,127,255,cv.THRESH_TRUNC)ret,thresh4 = cv.threshold(img,127,255,cv.THRESH_TOZERO)ret,thresh5 = cv.threshold(img,127,255,cv.THRESH_TOZERO_INV)titles = ['Original Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']images = [img, thresh1, thresh2, thresh3, thresh4, thresh5]for i in range(6):plt.subplot(2,3,i+1),plt.imshow(images[i],'gray',vmin=0,vmax=255)plt.title(titles[i])plt.xticks([]),plt.yticks([])plt.show()
 :::info
备注:
:::info
备注:
为了绘制多幅图像,实例中使用了plt.subplot()函数,请查阅matplotlib文档以了解更多。
:::
自适应阈值
在上述部分介绍了使用一个全局量作为阈值,但在某些情况下可能效果不好,例如,图像不同区域内亮度不一致。在这种情况下,推荐使用自适应阈值。本算法基于像素周围区域来确定像素的阈值。对于同一幅图像中的不同区域,可以获取不同阈值,这对于具有不同亮度的图像,将提供更好的效果。
除上述单一阈值提及的参数外,cv.adaptiveThreshold还需要三个输入参数:
选取的自适应方法将决定计算阈值的方法:
- cv.ADAPTIVE_THRESH_MEAN_C:阈值 = 邻域内平均值 - 常数C
- cv.ADAPTIVE_THRESH_GAUSSIAN_C:阈值 = 领域高斯加权和 -常数C(getGaussianKernel)
blockSize将决定邻域区域大小,C是从邻域像素的平均值或加权和中减去的常数。
此处示例比较了具有不同亮度的图像使用全局阈值和自适应阈值的区别。
import cv2 as cvimport numpy as npfrom matplotlib import pyplot as pltimg = cv.imread('sudoku.png',0)img = cv.medianBlur(img,5)ret,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)th2 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_MEAN_C,\cv.THRESH_BINARY,11,2)th3 = cv.adaptiveThreshold(img,255,cv.ADAPTIVE_THRESH_GAUSSIAN_C,\cv.THRESH_BINARY,11,2)titles = ['Original Image', 'Global Thresholding (v = 127)','Adaptive Mean Thresholding', 'Adaptive Gaussian Thresholding']images = [img, th1, th2, th3]for i in range(4):plt.subplot(2,2,i+1),plt.imshow(images[i],'gray')plt.title(titles[i])plt.xticks([]),plt.yticks([])plt.show()

Otsu二值化
在全局阈值中必须使用指定值作为阈值。相比之下,Otsu的方法可以通过自动确定避免这种情况。
考虑到当一幅图像仅有两个不同像素值(双峰图像),其中直方图仅包含两个峰值。最佳阈值应该在两个峰值的中间。类似地,Otsu的算法就是从图像直方图中确定最佳阈值来实现的。
通过调用cv.threshold(),并将cv.THRESH_OTSU作为额外的标志传入,阈值将被自由选择。执行后获取地第一个返回值即为最佳阈值。
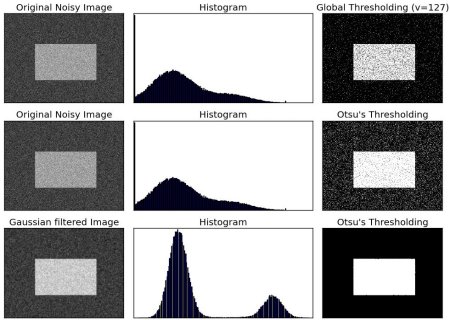
此处示例中输入图像为有噪声地图像。在第一种情况下,应用值127的全局阈值。在第二种情况下,直接应用Otsu阈值。在第三种情况下,首先使用5×5高斯内核对图像进行滤波以去除噪声,然后再应用Otsu阈值。可以看到噪声滤波是如何提升效果的。
import cv2 as cvimport numpy as npfrom matplotlib import pyplot as pltimg = cv.imread('noisy2.png',0)# global thresholdingret1,th1 = cv.threshold(img,127,255,cv.THRESH_BINARY)# Otsu's thresholdingret2,th2 = cv.threshold(img,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)# Otsu's thresholding after Gaussian filteringblur = cv.GaussianBlur(img,(5,5),0)ret3,th3 = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)# plot all the images and their histogramsimages = [img, 0, th1,img, 0, th2,blur, 0, th3]titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)','Original Noisy Image','Histogram',"Otsu's Thresholding",'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]for i in range(3):plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])plt.show()
Otsu二值化原理
此处将演示Otsu二值化的Python实现过程,以及算法的工作原理。如果不感兴趣可以直接略过。
由于正在处理的为双峰图像,Otsu算法尝试找到一个阈值 ,以保证关系式给出的加权类内方差最小化:
,以保证关系式给出的加权类内方差最小化:
其中,
实际上,是找到了位于两个峰值之间的一个t值,使得两个类的方差都是最小的,通过Python实现方式,如下所示:
img = cv.imread('noisy2.png',0)blur = cv.GaussianBlur(img,(5,5),0)# find normalized_histogram, and its cumulative distribution functionhist = cv.calcHist([blur],[0],None,[256],[0,256])hist_norm = hist.ravel()/hist.sum()Q = hist_norm.cumsum()bins = np.arange(256)fn_min = np.infthresh = -1for i in range(1,256):p1,p2 = np.hsplit(hist_norm,[i]) # probabilitiesq1,q2 = Q[i],Q[255]-Q[i] # cum sum of classesif q1 < 1.e-6 or q2 < 1.e-6:continueb1,b2 = np.hsplit(bins,[i]) # weights# finding means and variancesm1,m2 = np.sum(p1*b1)/q1, np.sum(p2*b2)/q2v1,v2 = np.sum(((b1-m1)**2)*p1)/q1,np.sum(((b2-m2)**2)*p2)/q2# calculates the minimization functionfn = v1*q1 + v2*q2if fn < fn_min:fn_min = fnthresh = i# find otsu's threshold value with OpenCV functionret, otsu = cv.threshold(blur,0,255,cv.THRESH_BINARY+cv.THRESH_OTSU)print( "{} {}".format(thresh,ret) )
2.4.4 Smoothing Images
目标
2.4.5 Morphological Transformations
2.4.6 Image Gradients
2.4.7 Canny Edge Detection
2.4.8 Image Pyramids
2.4.9 Contours in OpenCV
2.4.10 Histograms in OpenCV
2.4.11 Image Transforms in OpenCV
2.4.12 Template Matching
2.4.13 Hough Line Transform
2.4.14 Hough Circle Transfor
2.4.15 Image Segmentation with Watershed Algorithm
2.4.16 Interactive Foreground Extraction using GrabCut Algorithm
2.5 Feature Detection and Description
2.6 Video analysis (video module)
2.7 Camera Calibration and 3D Reconstruction
2.8 Machine Learning
2.9 Computational Photography
2.10 Object Detection (objdetect module)
2.11 OpenCV-Python Bindings

若有收获,就点个赞吧
0 人点赞
